

深度学习(深度神经网络)作为机器学习的一个重要分支,持续推动了很多领域的研究和应用取得新的进展,其中包括文本处理领域的情感分类问题。由于可以对文本进行更有效的编码及表达,基于深度学习的情感分类对比传统的浅层机器学习和统计学方法,可以取得更高的分类准确率。当前,情感分析在互联网业务中已经具有比较广泛的应用场景,成为了一个重要的业务支持能力。本文结合腾讯鹅漫 U 品业务在中文文本情感分类上的应用和实践经验,与读者一起学习及探讨。
一、 文本情感分析的发展与挑战
1. 情感分析的发展
情感分析(Sentiment Analysis),也称为情感分类,属于自然语言处理(Natural Language Processing,NLP)领域的一个分支任务,随着互联网的发展而兴起。多数情况下该任务分析一个文本所呈现的信息是正面、负面或者中性,也有一些研究会区分得更细,例如在正负极性中再进行分级,区分不同情感强度。
在 2000 年之前,因为互联网相对今天没有那么发达,所积累的文本数据不多,因此,这个问题相对被研究得较少。2000 年以后,随着互联网大潮的推进,文本信息快速积累,文本情感分析也开始快速增加,早期主要是针对英文,比较有代表性的,是 Pang, Lee and Vaithyanathan (2002) ,第一次采用了 Naive Bayes(朴素贝叶斯), Maximum Entropy(最大熵)和 SVM(Support Vector Machine, 支持向量机)对电影评论进行了情感分类,将之分为正面或者负面。2000-2010 年期间,情感分析主要基于传统的统计和浅层机器学习。由于这些方法不是本文阐述的重点,因此,本文就不再展开介绍。
2010 年以后,随着深度学习的崛起和发展,情感分析逐渐过渡到了采用基于深度学习的方法,并且证明其相对于传统的机器学习方法能够得到更好的识别准确率。
2. 中文文本情感分析的难点
由于汉语的博大精深,从传统方法的角度来看,中文文本的情感分析有多个难点:
(1)分词不准确:中文句子由单个汉字组成,通常第一个要解决的问题,就是如何“分词”。但是,由于汉字组合的歧义性,分词的准确率一直难以达到完美,而不准确的分词结果会直接影响最终分析的结果。在本文后面章节,本文会适当展开介绍。
(2)缺乏标准完整的情感词库:与中文相比,英文目前有相对比较完整的情感词库,对每个词语标注了比较全面的情感类型、情感强度等。但是,中文目前比较缺乏这样的情感词库。同时考虑到语言的持续发展的特性,往往持续不断地产生新的词语和表达方式,例如,“陈独秀,坐下”,“666”,它们原本都不是情感词,在当今的互联网环境下被赋予了情感极性,需要被情感词库收录。
(3)否定词问题:例如,“我不是很喜欢这个商品”和“我很喜欢这个商品”,如果基于情感词的分析,它们的核心情感词都是“喜欢”,但是整个句子却表达了相反的情感。这种否定词表达的组合非常丰富,即使我们将分词和情感词库的问题彻底解决好,针对否定词否定范围的分析也会是一个难点。
(4)不同场景和领域的难题:部分中性的非情感词在特定业务场景下可能具有情感倾向。例如,如下图的一条评论“(手机)蓝屏,充不了电”,蓝屏是一个中性名词,但是,如果该词在手机或者电脑的购买评价中如果,它其实表达了“负面”的情感,而在某些其他场景下还有可能呈现出正面的情感。因此,即使我们可以编撰一个完整的“中文情感词典”,也无法解决此类场景和领域带来的问题。

上述挑战广泛存在于传统的机器学习乃至深度学习方法中。但是,在深度学习中,其中某些问题可以得到一定程度的改善。
3. 深度学习简介
深度学习(Deep Learning)最早是由 Hinton、Bengio 等为首的科学家们在 2006 年提出,是机器学习的重要分支,它一定程度上参考了人脑的“神经元”结构和交互方式。人的智能来源于人的大脑,大脑虽然复杂,但是组成大脑的基本细胞却比较简单,大脑皮层以及整个神经系统,都是由神经元细胞组成的。而一个神经元细胞,是由树突和轴突组成,它们分别代表输入和输出。
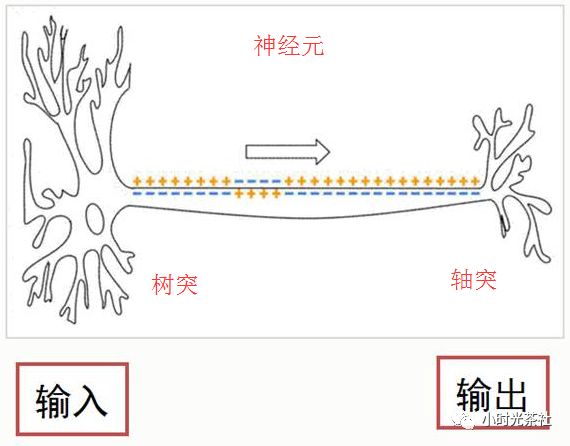
树突和轴突都有大量的分支,轴突的末端通常连接到其他神经元细胞的树突上,连接点上是一个叫“突触”的结构。一个神经元的输出通过突触传递给成千上万个下游的神经元,神经元可以调整突触的结合强度,有的突触是促进下游细胞的兴奋,有的则是抑制。下游神经元连接成千上万个上游神经元,积累它们的输入,产生输出。
人脑有大约 1000 亿个神经元,1000 万亿个突触,它们组成人脑中庞大的神经网络,我们在深度学习中常常提到的“深度/多层神经网络”的概念来源就是从这里产生的。
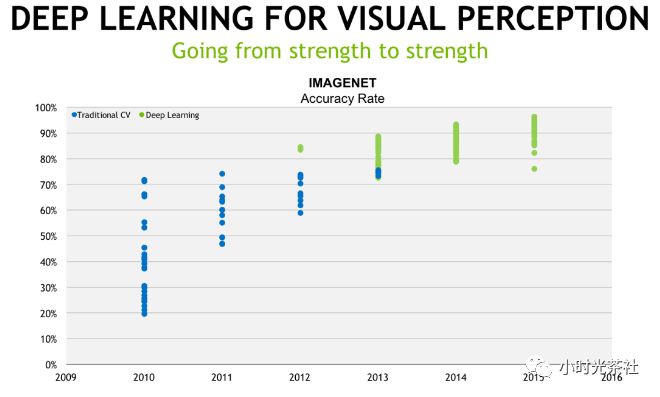
虽然深度学习在 2006 年即被提出,但是在当时并没有引起人们的广泛关注,真正得到工业界重视其实到了 2012 年。当年在 ImageNet 图片识别大赛中,深度学习算法将图片分类识别准确率从传统机器学习方法的 74%提升到 84%,获得大幅领先的比赛成绩。在随后几年,研究人员通过进一步对深度学习算法的优化,迅速将 ImageNet 图片分类识别准确率提升到 97.3%(2017 年),超越了人类的识别水平(大约 95%)。
下图是 ImageNet 历年的比赛成绩,其中绿色的点是深度学习的成绩,蓝色的点代表传统机器学习方法:
在图片识别领域之外,深度学习在语音识别、翻译等其他领域的成绩比传统机器学习算法也有较大幅度的提高,例如,Google 在 2017 年 12 月发布的端到端语音识别系统(State-of-the-art Speech Recognition With Sequence-to-Sequence Models),引入 DeepCNN,从 2013 年到现在性能提升了 20%,错词率降低至 5.6%。由于深度学习在 2012 年 ImageNet 的比赛成绩引起的广泛关注,对深度学习的大规模投入随之而来,以 Google 为代表的美国科技巨头们,较早期就在深度学习领域做出重大投入。2016 年发生的标志性事件“AlphaGo 击败围棋世界冠军李世石”一石激起千层浪,使得深度学习和人工智能全面进入大众视野,将其从单纯的学术和工业界关注转变为全民关注,“人工智能”的概念也开始在资本界被炒得热火朝天。
二、 中文分词概述
一般情况下,中文文本的情感分类通常依赖于分析句子中词语的表达和构成,因此需要先对句子进行分词处理。不同于英文句子中天然存在空格,单词之间存在明确的界限,中文词语之间的界限并不明晰,良好的分词结果往往是进行中文语言处理的先决条件。
中文分词一般有两个难点,其一是“歧义消解”,因为中文博大精深的表达方式,中文的语句在不同的分词方式下,可以表达截然不同的意思。有趣地是,正因如此,相当一部分学者持有一种观点,认为中文并不能算作一种逻辑表达严谨的语言。其二难点是“新词识别”,由于语言的持续发展,新的词汇被不断创造出来,从而极大影响分词结果,尤其是针对某个领域内的效果。下文从是否使用词典的角度简单介绍传统的两类中文分词方法。
1. 基于词典的分词方法
基于词典的分词方法,需要先构建和维护一套中文词典,然后通过词典匹配的方式,完成句子的分词,基于词典的分词方法有速度快、效率高、能更好地控制词典和切分规则等特性,因此被工业界广泛作为基线工具采用。基于词典的分词方法包含多种算法。比较早被提出的有“正向最大匹配算法”(Forward Maximum Matching,MM),FMM 算法从句子的左边到右边依次匹配,从而完成分词任务。但是,人们在应用中发现 FMM 算法会产生大量分词错误,后来又提出了“逆向最大匹配算法”(Reverse Maximum Matching,RMM),从句子右边往左边依次匹配词典完成分词任务。从应用的效果看,RMM 的匹配算法表现,要略为优于 MM 的匹配算法表现。
一个典型的分词案例“结婚的和尚未结婚的”:
FMM:结婚/的/和尚/未/结婚/的 (分词有误的)
RMM:结婚/的/和/尚未/结婚/的 (分词正确的)
为了进一步提升分词匹配的准确率,研究者后来又提出了出了同时兼顾 FMM 和 RMM 分词结果的“双向最大匹配算法” (Bi-directctional Matching,BM ),以及兼顾了词的出现频率的“最佳匹配法”(Optimum Matching,OM)。
2. 基于统计的分词方法
基于统计的分词方法,往往又被称作“无词典分词”法。因为中文文本由汉字组成,词一般是几个汉字的稳定组合,因此在一定的上下文环境下,相邻的几个字出现的次数越多,它就越有可能成为“词”。基于这个规则可以通过算法构建出隐式的“词典”(模型),从而基于它完成分词操作。该类型的方法包括基于互信息或条件熵为基础的无监督学习方法,以及 N 元文法(N-gram)、隐马尔可夫模型(Hiden Markov Model,HMM)、最大熵模型(Maximum Entropy,ME)、条件随机场模型(Conditional Random Fields,CRF)等基于监督学习的模型。这些模型往往作用于单个汉字,需要一定规模的语料支持模型的训练,其中监督学习的方法通过薛念文在 2003 年第一届 SIGHAN Bakeoff 上发表的论文所展现出的结果开始持续引起业内关注。效果上,这些模型往往很善于发现未登录词,可以通过对大量汉字之间关系的建模有效“学习”到新的词语,是对基于词典方法的有益补充。然而它在实际的工业应用中也存在一定的问题,例如分词效率,切分结果一致性差等。
三、 基于多层 LSTM 的中文情感分类模型原理
在前述分词过程完成后,就可以进行情感分类了。我们的情感分类模型是一个基于深度学习(多层 LSTM)的有监督学习分类任务,输入是一段已经分好词的中文文本,输出是这段文本是正面和负面的概率分布。整个项目的流程,分为数据准备、模型搭建、模型训练和结果校验四个步骤,在下文中一一展开。由于本文模型依赖于已切分的中文文本,对于想要动手实现代码的读者,如果没有分词工具,我们建议读者使用网上开源的工具。
1. 数据准备
我们基于 40 多万条真实的鹅漫用户评论数据建立了语料库,为了让正面和负面的学习样本尽可能均衡,我们实际抽样了其中的 7 万条评论数据作为学习样本。一般情况下,对于机器学习的分类任务,我们建议将学习样本比例按照分类规划为 1:1,以此更好地训练无偏差的模型。
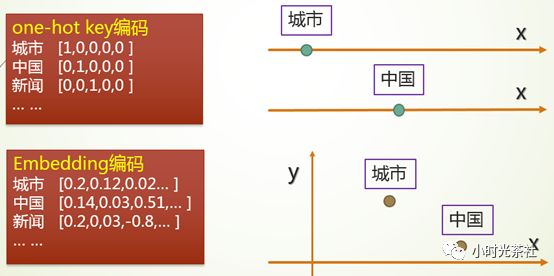
模型的输入是一段已经分词的中文文本,但它无法被模型直接识别,因此,我们要将它转换成一种能被模型识别的数学表达。最直接的方式是将这些文本中的词语用“One-Hot Key”进行编码。One-Hot Key 是一种比较简单的编码方式,假设我们一共只有 5 个词,则可以简单地编码为如下图所示:

在一般的深度学习任务中,非连续数值型特征基本采用了上述编码方式。但是,One-HotKey 的编码方式通常会造成内存占用过大的问题。我们基于 40 多万条用户评论分词后获得超过 38000 个不同的词,使用 One-Hot Key 方式会造成极大的内存开销。下图是对 40 多万条评论分词后的部分结果:
因此,我们的模型引入了词向量(word embeddings)来解决这个问题,每一个词以多维向量方式编码。我们在模型中将词向量编码维度配置为 128 维,对比 One-Hot Key 编码的 38000 多维,无论是在内存占用还是计算开销都更节省机器资源。作为对比,One-Hot key 可以粗略地被理解为用一条线表示 1 个词,线上只有一个位置是 1,其它点都是 0,而词向量则是用多个维度表示 1 个词。(这里给大家安利一个很好的资源,由腾讯 AI Lab 去年 10 月发布的大规模中文词向量https://ai.tencent.com/ailab/nlp/embedding.html,可以对超过 800 万词进行高质量的词向量映射,从而有效提升后续任务的性能。)
假设我们将词向量设置为 2 维,它的表达则可以用二维平面图画出来,如下图所示:
2. 模型搭建
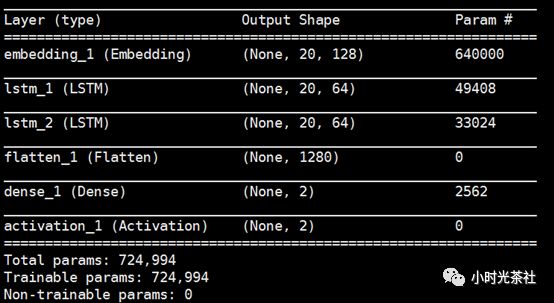
本项目的代码采用了 Keras 实现,底层框架是 Google 开源的 TensorFlow。整个模型包含 6 层,核心层包括 Embedding 输入层、中间层(LSTM)、输出层(Softmax)。模型中的 Flatten 和 Dense 层用于做数据维度变换,将上一层输出数据变换为相应的输出格式,最终的输出是一个二维数组,用于表达输入文本是正面或者负面的概率分布,格式形如[0.8, 0.2]。
Keras 的模型核心代码和参数如下:
模型架构如下图:
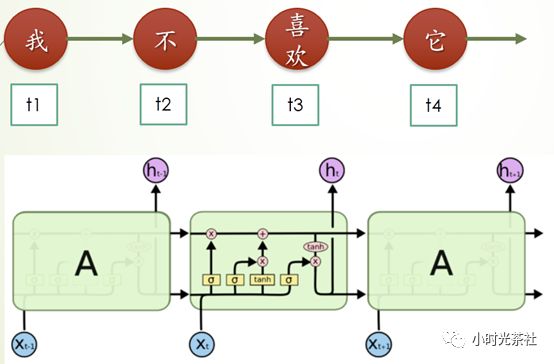
该模型的核心层采用 LSTM (Long short-term memory,长短记忆模型),LSTM 是 RNN(Recurrent neural network,循环神经网络)的一种实现形式,具有“记忆时序”的特点,可以学习到数据上下文之间的关联关系。例如,在含有前置否定词的句子“我喜欢”和“我不是很喜欢”中,虽然“喜欢”这个词表达了正面的情感含义,但是句子前面出现的否定词却更重要,否定词会使语句表达的情感截然相反。LSTM 可以通过上下文学习到这种组合规律,从而提高分类准确率。
模型其他几个层的含义本文也简单列出:
Flatten(压平层),在本模型中负责将 2 阶张量压缩为 1 阶级张量(20*64 = 1280):

Dense(全连接层),通常用于做维度变换,在本模型中将 1280 维变为 2 维。

Activation(激活函数),本模型采用 Softmax,它负责将数值约束到 0-1 之间,并且以概率分布的方式输出。
3. 模型训练
由于我们的模型架构比较简单,模型的训练耗时不高,在一台 8 核 8G 内存的 CPU 机器上完成一轮 7 万多个评论样本的训练只需 3 分钟左右。训练得到的模型在测试集上可以获得大约 96%的情感分类准确率,而基于传统机器学习方法的准确率通常只有 75-90%。值得注意的是,本模型并不是一个可以识别任意文本的通用模型,因为我们构建的学习样本基本上只覆盖鹅漫用户评论语料范围内的词,超出语料范围的分类准确率可能会显著降低。
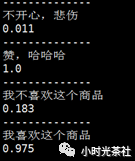
测试集情感分类的部分结果(数值代表该评论是正面情感的概率):

文本表述中含有否定词的识别场景:
关于部分“中性词”在某些业务情景下拥有情感倾向的问题,利用本文的模型可以较好地处理,因为本文的模型可以通过学习得到所有词(包括情感词和一般词)的情感倾向。
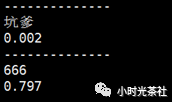
例如,下图中的“坑爹”一词,在模型中已经被明显地识别为“负面”情感词(0.002 表示该词属于正面情感的概率仅有千分之二),而“666”则被识别为正面情感词(概率系数大于 0.5 则属于正面情感)。
四、 业务应用场景与扩展展望
1. 业务应用场景
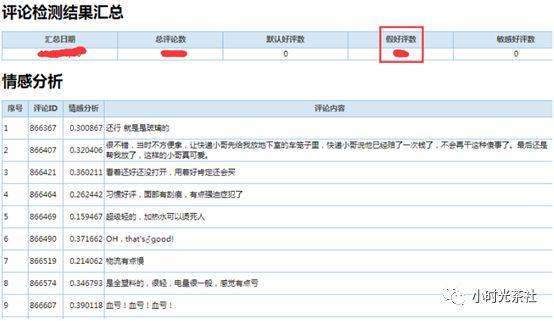
在鹅漫 U 品业务场景中,用户完成商品购买后通常会对商品进行评论,一般情况下,我们的客服和商家会对差评评论进行一定处理和回复。但是,真实的用户评论数据中存在一种特殊的好评,我们称之为“假好评”,用户评论表述的内容是差评,可能由于页面点击失误或者其他原因却在评论分类上选择了“好评”,从而导致这种评论没有被正确归类,因此,客服和商家同学没办法处理到这类评论。从鹅漫的评论数据看,这类“假好评”的比例大概占据全部评论数据的 3%。考虑到鹅漫业务每天产生巨量评论,如果依靠人工甄别的处理方式将非常费时费力,通过自动情感分类的则可以有效解决该问题。
鹅漫另外一个业务场景是自动提取“深度好评”:我们直接通过全量数据扫描获取正面情感系数高,并且评论字数较多的评论文本,将它们作为商品的“深度好评”。这类评论通常对产品的体验和描述较为详尽,适合放在商品页面更显眼的位置,能有效提升浏览用户对商品的了解。同时,自动提取评论也能一定程度上减轻商品运营人员撰写运营文案的工作量,尤其是在商品数量较多的情况下。反之亦如此,如果我们提取负面情感系数较高且字数较多的评论,则可以获得“深度差评”,它可以作为商品运营人员了解用户负面反馈的一种有效渠道。
例如下图的“弹幕”评论,就是我们自动提取的“好评”:
值得提出的是,目前,鹅漫也在使用腾讯 AILab 提供的通用版情感分类接口,它的模型不依赖于分词,直接以字为单元进行建模和训练,情感分类的准确率非常高,适用范围更广。我们通过联合使用两个不同模型的分类结果完成更高质量的情感分析。
2. 未来扩展方向
我们从海量的文本评论中,归类出了正面和负面情感的文本数据,在此基础上如果再通过针对商品不同方面(aspect)的评论的建模乃至句法依存分析(dependency parsing),进一步提炼文本的关键信息,就可以获得用户的关键表达意见。从中我们可以获得比较全面的商品评价信息,提炼出商品被大量用户正面评价和负面评价的主要观点,最终可以为运营人员和商家提供商品改进意见和运营决策指导。实现真正意义上的基于商品的舆情分析(opinion summary),提炼出用户的真实反馈和观点。
下图以“我们一直喜欢美丽的手办”为例,通过词法依存分析,获得了词与词之间的关系,进而分析出用户在评论中倾诉情绪的核心对象。在下图的评论中,用户对“手办”表达了正面的情感。
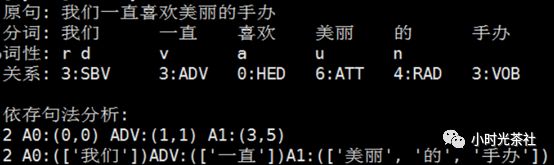
词法关系的含义:
SBV,主谓关系
ADV,修饰(状语)
HED,核心
ATT,修饰(定语)
RAD,右附加关系
VOB,直接宾语
结语:在互联网海量信息和数据面前,人的力量非常有限并且是成本高昂的,例如,鹅漫 U 品评论情感分类和提取的两项业务需求,就是面向海量文本信息处理的典型任务,如果通过人工完成,执行效率极为低下。深度学习模型使我们良好地满足了业务诉求。虽然深度学习并非完美,但是,它所提供的执行效率和帮助是显著的,并在一定的业务场景下成为辅助解决业务问题的新选择和新工具。
五、 参考
Google 开源的 TensorFlow: https://tensorflow.google.cn/
对 TensorFlow 的二次封装框架 Keras: https://keras.io/
作者简介:徐汉彬,腾讯信息流商业化数据算法团队 Leader,前鹅漫前台研发团队 Leader,T3-3 级工程师,负责鹅漫 U 品和 AMS 平台(高峰期 PV 超过 13 亿)的研发工作,在 Web 研发、活动运营服务领域有丰富的经验和积累。
指导作者:宋彦博士,腾讯 AI Lab 骨干科学家,T4 专家研究员。前微软小冰创始团队成员。发表 AI 领域顶级会议和期刊论文 50 余篇,多次担任 NLP 顶级会议(ACL、NAACL、EACL、EMNLP、COLING 等)程序委员会委员。主导了腾讯 2018 智能春联及 AI Lab 大规模中文词向量的构建工作。

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论 1 条评论