

引言
推荐作为解决信息过载和挖掘用户潜在需求的技术手段,在美团点评这样业务丰富的生活服务电子商务平台,发挥着重要的作用。在美团 App 里,首页的“猜你喜欢”、运营区、酒店旅游推荐等重要的业务场景,都是推荐的用武之地。
图 1 美团首页“猜你喜欢”场景
目前,深度学习模型凭借其强大的表达能力和灵活的网络结构在诸多领域取得了重大突破,美团平台拥有海量的用户与商家数据,以及丰富的产品使用场景,也为深度学习的应用提供了必要的条件。本文将主要介绍深度学习模型在美团平台推荐排序场景下的应用和探索。
深度学习模型的应用与探索
美团推荐场景中每天活跃着千万级别的用户,这些用户与产品交互产生了海量的真实行为数据,每天能够提供十亿级别的有效训练样本。为处理大规模的训练样本和提高训练效率,我们基于 PS-Lite 研发了分布式训练的 DNN 模型,并基于该框架进行了很多的优化尝试,在排序场景下取得了显著的效果提升。
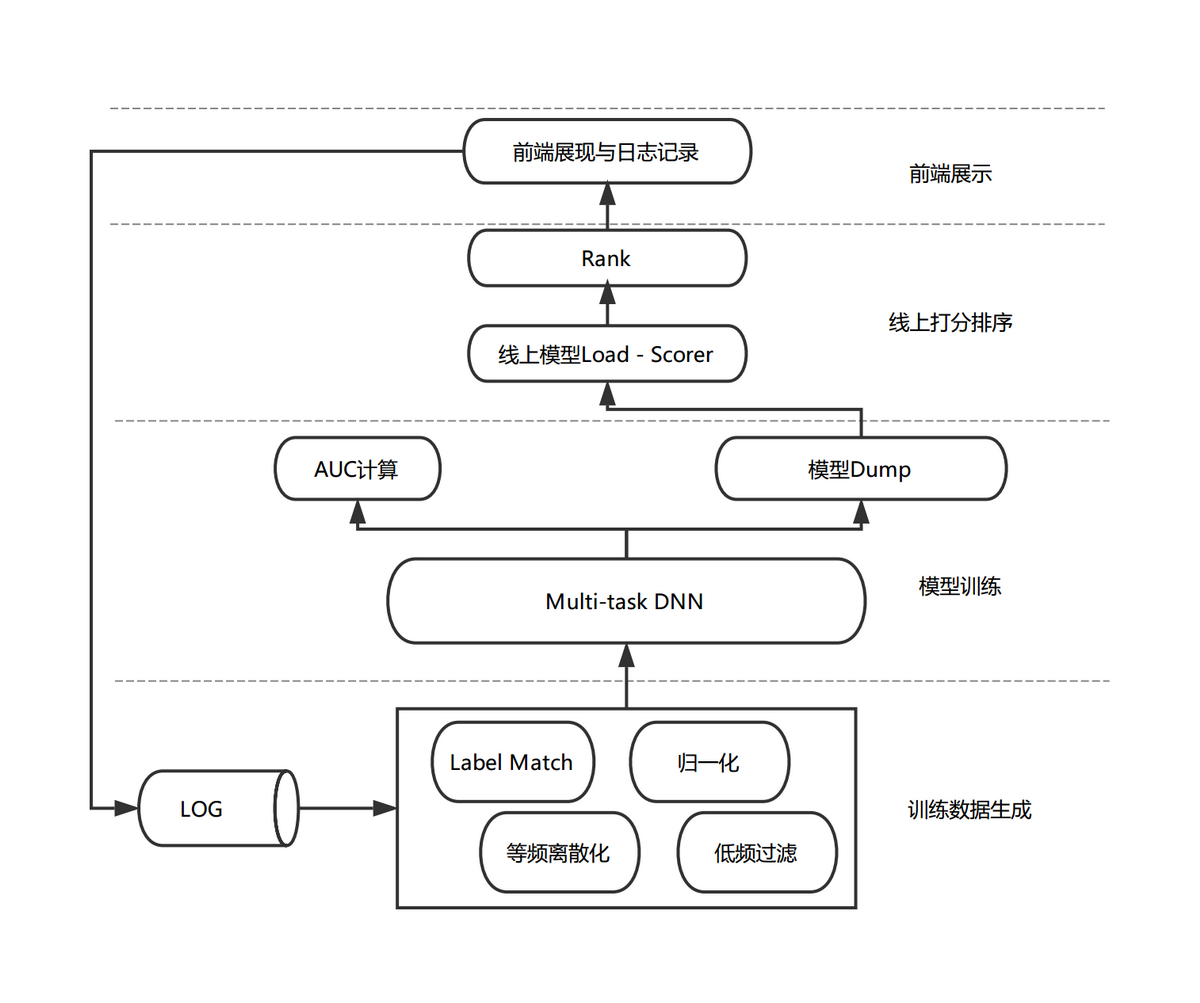
图 2 模型排序流程图
如上图所示,模型排序流程包括日志收集、训练数据生成、模型训练和线上打分等阶段。当推荐系统对浏览推荐场景的用户进行推荐时,会记录当时的商品特征、用户状态与上下文信息,并收集本次推荐的用户行为反馈。在经过标签匹配和特征处理流程后生成最终的训练数据。我们在离线运用 PS-Lite 框架对 Multi-task DNN 模型进行分布式训练,通过离线评测指标选出效果较好的模型并加载到线上,用于线上排序服务。
下面将着重介绍我们在特征处理和模型结构方面所做的优化与尝试。
特征处理
美团“猜你喜欢”场景接入了包括美食、酒店、旅游、外卖、民宿、交通等多种业务,这些业务各自有着丰富的内涵和特点,同时各业务的供给、需求与天气、时间、地理位置等条件交织,构成了 O2O 生活服务场景下特有的多样性和复杂性,这就给如何更高效地组织排序结果提出了更高的要求。构造更全面的特征、更准确高效地利用样本一直是我们优化的重点方向。
特征种类
User 特征:用户年龄,性别,婚否,有无孩子等
Item 特征:价格,折扣,品类和品牌相关特征,短期和长期统计类特征等
Context 特征:天气,时间,地理位置,温度等
用户行为:用户点击 Item 序列,下单 Item 序列等
除上述列举的几类特征外,我们还根据 O2O 领域的知识积累,对部分特征进行交叉,并针对学习效果对特征进行了进一步处理。具体的样本和特征处理流程如下:
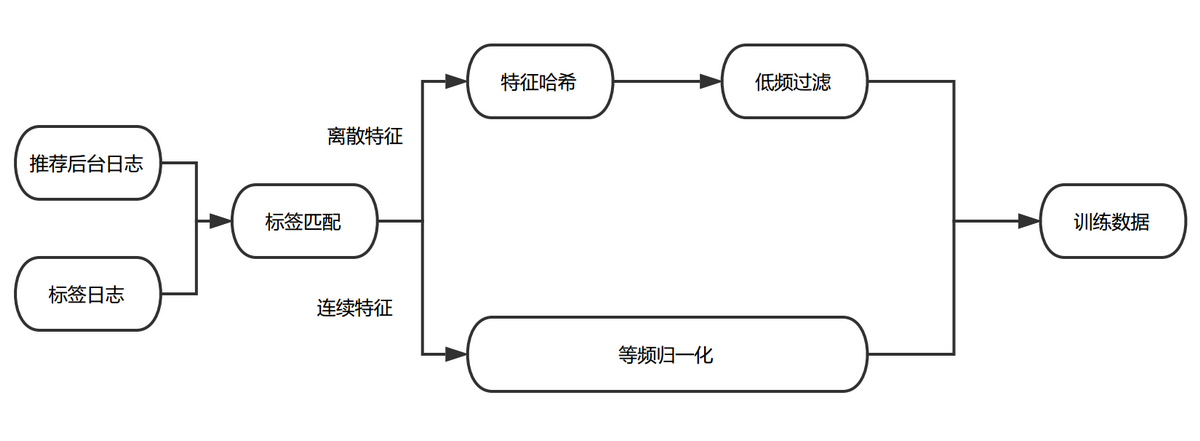
图 3 训练数据处理流程
标签匹配
推荐后台日志会记录当前样本对应的 User 特征、Item 特征与 Context 特征,Label 日志会捕获用户对于推荐项的行为反馈。我们把两份数据按照唯一 ID 拼接到一起,生成原始的训练日志。
等频归一化
通过对训练数据的分析,我们发现不同维度特征的取值分布、相同维度下特征值的差异都很大。例如距离、价格等特征的数据服从长尾分布,体现为大部分样本的特征值都比较小,存在少量样本的特征值非常大。常规的归一化方法(例如 min-max, z-score)都只是对数据的分布进行平移和拉伸,最后特征的分布仍然是长尾分布,这就导致大部分样本的特征值都集中在非常小的取值范围内,使得样本特征的区分度减小;与此同时,少量的大值特征可能造成训练时的波动,减缓收敛速度。此外也可以对特征值做对数转化,但由于不同维度间特征的分布不同,这种特征值处理的方式并不一定适用于其他维度的特征。
在实践中,我们参考了 Google 的 Wide & Deep Model[^6]中对于连续特征的处理方式,根据特征值在累计分布函数中的位置进行归一化。即将特征进行等频分桶,保证每个桶里的样本量基本相等,假设总共分了 n 个桶,而特征 xi 属于其中的第 bi(bi ∈ {0, …, n - 1}) 个桶,则特征 xi 最终会归一化成 bi/n。这种方法保证对于不同分布的特征都可以映射到近似均匀分布,从而保证样本间特征的区分度和数值的稳定性。
低频过滤
过多的极为稀疏的离散特征会在训练过程中造成过拟合问题,同时增加参数的储存数量。为避免该问题,我们对离散特征进行了低频过滤处理,丢掉小于出现频次阈值的特征。
经过上述特征抽取、标签匹配、特征处理后,我们会给特征分配对应的域,并对离散特征进行 Hash 处理,最终生成 LIBFFM 格式的数据,作为 Multi-task DNN 的训练样本。下面介绍针对业务目标所做的模型方面的优化尝试。
模型优化与尝试
在模型方面,我们借鉴工业界的成功经验,在 MLP 模型的基础上,针对推荐场景进行模型结构方面的优化。在深度学习中,很多方法和机制都具有通用性,比如 Attention 机制在机器翻译,图像标注等方向上取得了显著的效果提升,但并不是所有具体的模型结构都能够直接迁移,这就需要结合实际业务问题,对引入的模型网络结构进行了针对性调整,从而提高模型在具体场景中的效果。
Multi-task DNN
推荐场景上的优化目标要综合考虑用户的点击率和下单率。在过去我们使用 XGBoost 进行单目标训练的时候,通过把点击的样本和下单的样本都作为正样本,并对下单的样本进行上采样或者加权,来平衡点击率和下单率。但这种样本的加权方式也会有一些缺点,例如调整下单权重或者采样率的成本较高,每次调整都需要重新训练,并且对于模型来说较难用同一套参数来表达这两种混合的样本分布。针对上述问题,我们利用 DNN 灵活的网络结构引入了 Multi-task 训练。
根据业务目标,我们把点击率和下单率拆分出来,形成两个独立的训练目标,分别建立各自的 Loss Function,作为对模型训练的监督和指导。DNN 网络的前几层作为共享层,点击任务和下单任务共享其表达,并在 BP 阶段根据两个任务算出的梯度共同进行参数更新。网络在最后一个全连接层进行拆分,单独学习对应 Loss 的参数,从而更好地专注于拟合各自 Label 的分布。
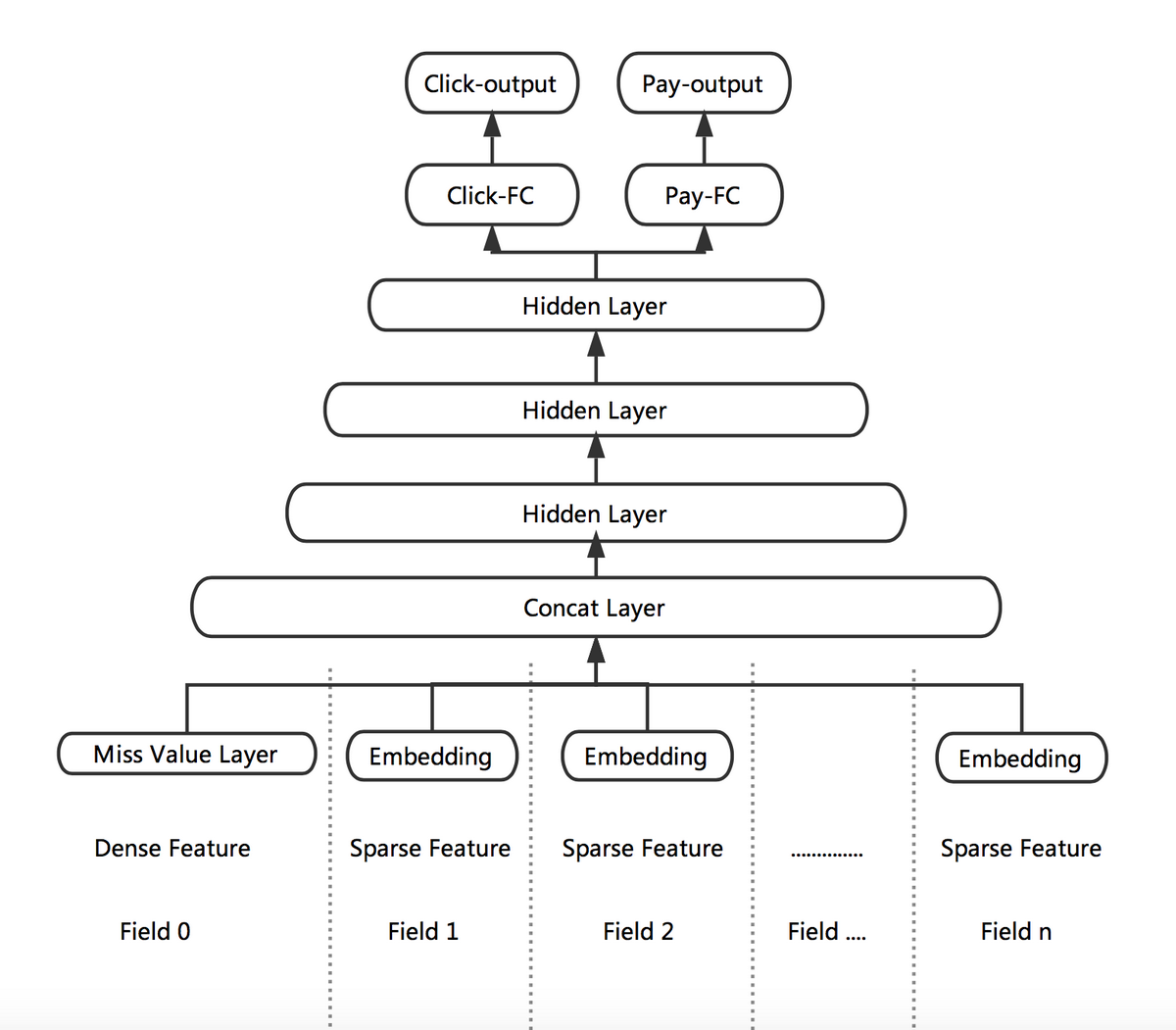
图 4 点击与下单多目标学习
Multi-task DNN 的网络结构如上图所示。线上预测时,我们将 Click-output 和 Pay-output 做一个线性融合。
在此结构的基础上,我们结合数据分布特点和业务目标进行了进一步的优化:针对特征缺失普遍存在的情况我们提出 Missing Value Layer,以用更合理的方式拟合线上数据分布;考虑将不同 task 的物理意义关联起来,我们提出 KL-divergence Bound,以减轻某单一目标的 Noise 的影响。下面我们就这两块工作做具体介绍。
Missing Value Layer
通常在训练样本中难以避免地有部分连续特征存在缺失值,更好地处理缺失值会对训练的收敛和最终效果都有一定帮助。通常处理连续特征缺失值的方式有:取零值,或者取该维特征的平均值。取零值会导致相应权重无法进行更新,收敛速度减慢。而取平均值也略显武断,毕竟不同的特征缺失所表示的含义可能不尽相同。一些非神经网络的模型能比较合理的处理缺失值,比如 XGBoost 会通过 Loss 的计算过程自适应地判断特征缺失的样本被划分到左子树还是右子树更优。受此启发,我们希望神经网络也可以通过学习的方式自适应地处理缺失值,而不是人为设置默认值。因此设计了如下的 Layer 来自适应的学习缺失值的权重:
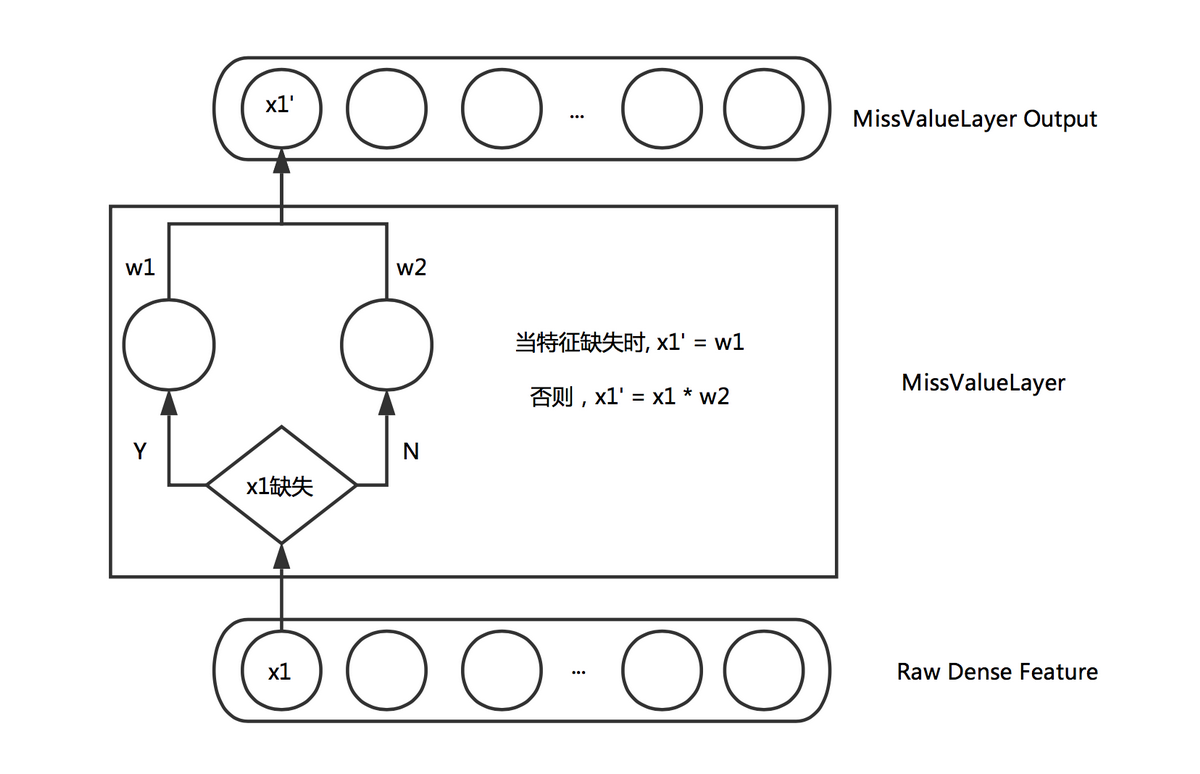
图 5 Miss Value Layer
通过上述的 Layer,缺失的特征可以根据对应特征的分布去自适应的学习出一个合理的取值。
通过离线调研,对于提升模型的训练效果,自适应学习特征缺失值的方法要远优于取零值、取均值的方式,模型离线 AUC 随训练轮数的变化如下图所示:
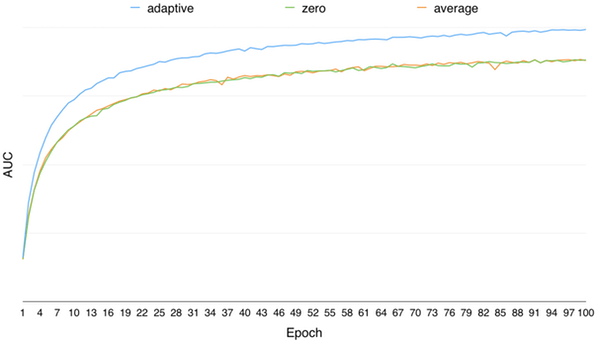
图 6 自适应学习特征缺失值与取 0 值和均值效果对比
AUC 相对值提升如下表所示:
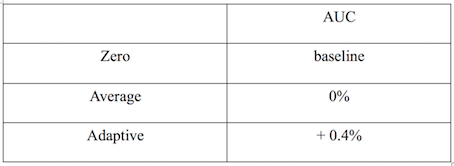
图 7 自适应学习特征缺失值 AUC 相对值提升
KL-divergence Bound
我们同时考虑到,不同的标签会带有不同的 Noise,如果能通过物理意义将有关系的 Label 关联起来,一定程度上可以提高模型学习的鲁棒性,减少单独标签的 Noise 对训练的影响。例如,可以通过 MTL 同时学习样本的点击率,下单率和转化率(下单/点击),三者满足 p(点击) * p(转化) = p(下单) 的意义。因此我们又加入了一个 KL 散度的 Bound,使得预测出来的 p(点击) * p(转化) 更接近于 p(下单)。但由于 KL 散度是非对称的,即 KL(p||q) != KL(q||p),因此真正使用的时候,优化的是 KL(p||q) + KL(q||p)。
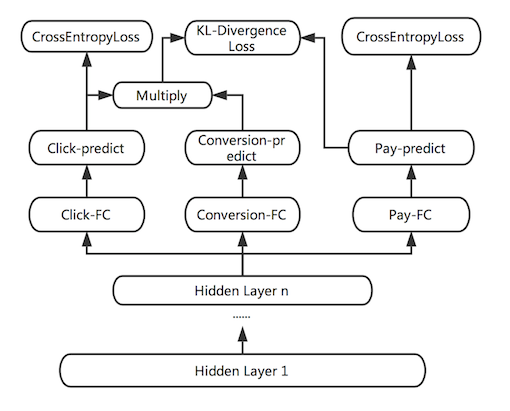
图 8 KL-divergence Bound
经过上述工作,Multi-tast DNN 模型效果稳定超过 XGBoost 模型,目前已经在美团首页“猜你喜欢”场景全量上线,在线上也取得了点击率的提升:
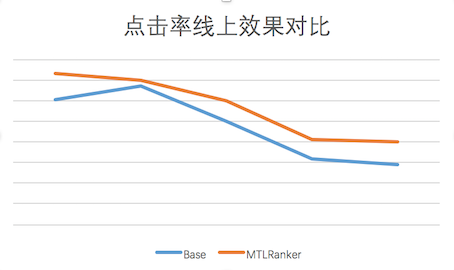
图 9 线上 CTR 效果与基线对比图
线上 CTR 相对值提升如下表所示:
图 10 线上 CTR 效果相对值提升
除了线上效果的提升,Multi-task 训练方式也很好的提高了 DNN 模型的扩展性,模型训练时可以同时考虑多个业务目标,方便我们加入业务约束。
更多探索
在 Multi-task DNN 模型上线后,为了进一步提升效果,我们利用 DNN 网络结构的灵活性,又做了多方面的优化尝试。下面就 NFM 和用户兴趣向量的探索做具体介绍。
NFM
为了引入 Low-order 特征组合,我们在 Multi-task DNN 的基础上进行了加入 NFM 的尝试。各个域的离散特征首先通过 Embedding 层学习得到相应的向量表达,作为 NFM 的输入,NFM 通过 Bi-Interaction Pooling 的方式对输入向量对应的每一维进行 2-order 的特征组合,最终输出一个跟输入维度相同的向量。我们把 NFM 学出的向量与 DNN 的隐层拼接在一起,作为样本的表达,进行后续的学习。
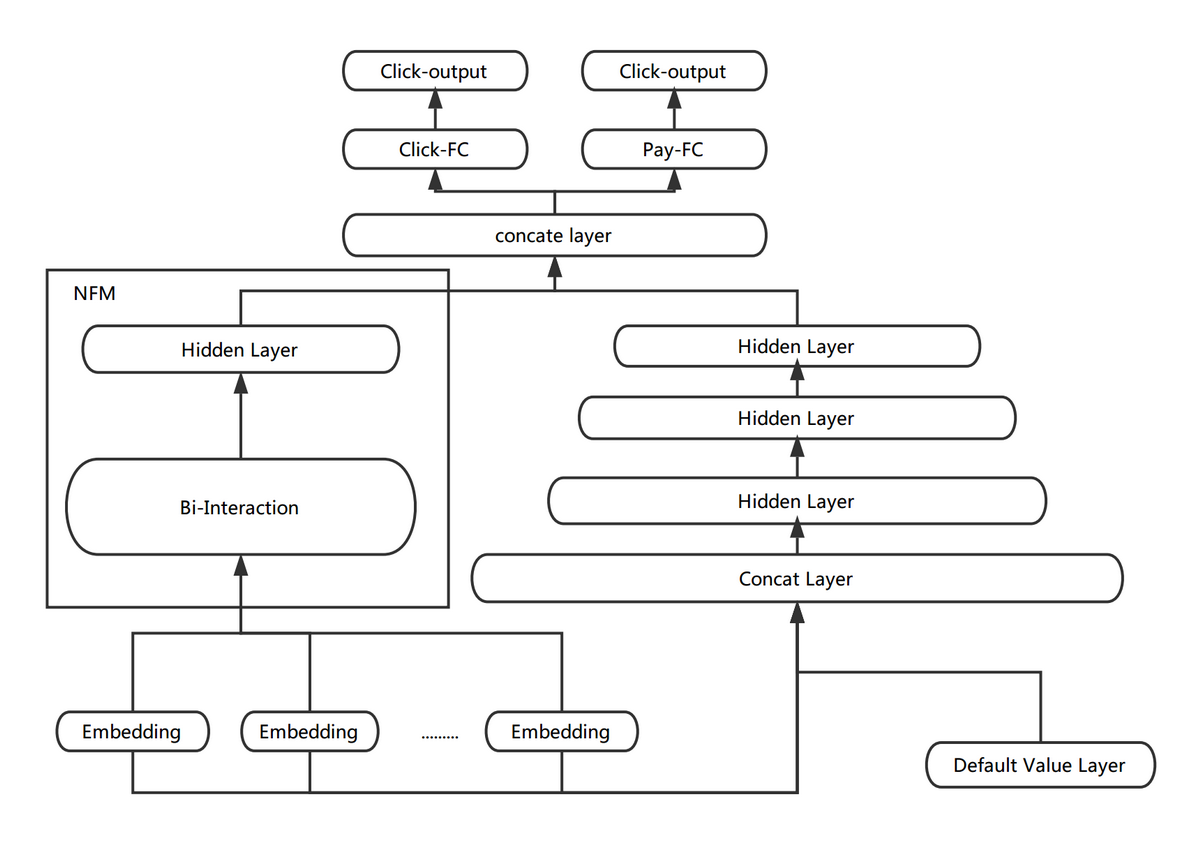
图 11 NFM + DNN
NFM 的输出结果为向量形式,很方便和 DNN 的隐层进行融合。而且从调研的过程中发现,NFM 能够加快训练的收敛速度,从而更有利于 Embedding 层的学习。因为 DNN 部分的层数较多,在训练的 BP 阶段,当梯度传到最底层的 Embedding 层时很容易出现梯度消失的问题,但 NFM 与 DNN 相比层数较浅,有利于梯度的传递,从而加快 Embedding 层的学习。
通过离线调研,加入 NFM 后,虽然训练的收敛速度加快,但 AUC 并没有明显提升。分析原因是由于目前加入 NFM 模型部分的特征还比较有限,限制了学习的效果。后续会尝试加入更多的特征域,以提供足够的信息帮助 NFM 学出有用的表达,深挖 NFM 的潜力。
用户兴趣向量
用户兴趣作为重要的特征,通常体现在用户的历史行为中。通过引入用户历史行为序列,我们尝试了多种方式对用户兴趣进行向量化表达。
Item 的向量化表达:线上打印的用户行为序列中的 Item 是以 ID 的形式存在,所以首先需要对 Item 进行 Embedding 获取其向量化的表达。最初我们尝试通过随机初始化 Item Embedding 向量,并在训练过程中更新其参数的方式进行学习。但由于 Item ID 的稀疏性,上述随机初始化的方式很容易出现过拟合。后来采用先生成 item Embedding 向量,用该向量进行初始化,并在训练过程中进行 fine tuning 的方式进行训练。
用户兴趣的向量化表达:为生成用户兴趣向量,我们对用户行为序列中的 Item 向量进行了包括 Average Pooling、 Max Pooling 与 Weighted Pooling 三种方式的融合。其中 Weighted Pooling 参考了 DIN 的实现,首先获取用户的行为序列,通过一层非线性网络(Attention Net)学出每个行为 Item 对于当前要预测 Item 的权重(Align Vector),根据学出的权重,对行为序列进行 Weighted Pooling,最终生成用户的兴趣向量。计算过程如下图所示:
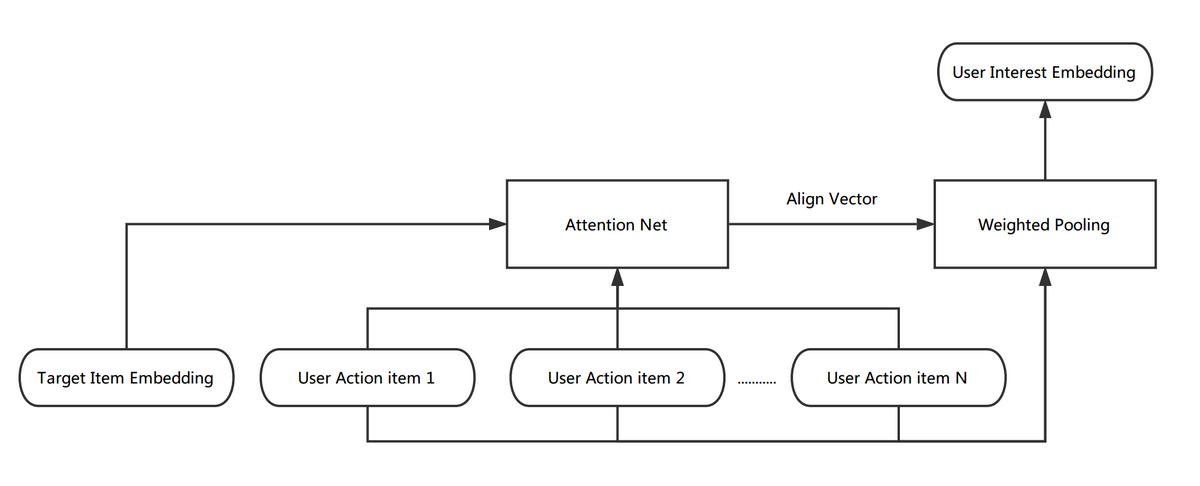
图 12 Weighted Pooling
通过离线 AUC 对比,针对目前的训练数据,Average Pooling 的效果为最优的。效果对比如下图所示:
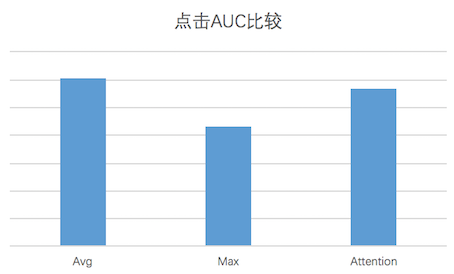
图 13 不同 Pooling 方式点击 AUC 对比
以上是我们在模型结构方面的优化经验和尝试,下面我们将介绍针对提高模型训练效率所做的框架性能优化工作。
训练效率优化
经过对开源框架的广泛调研和选型,我们选择了 PS-Lite 作为 DNN 模型的训练框架。PS-Lite 是 DMLC 开源的 Parameter Server 实现,主要包含 Server 和 Worker 两种角色,其中 Server 端负责模型参数的存储与更新,Worker 端负责读取训练数据、构建网络结构和进行梯度计算。相较于其他开源框架,其显著优点在于:
PS 框架:PS-Lite 的设计中可以更好的利用特征的稀疏性,适用于推荐这种有大量离散特征的场景。
封装合理:通信框架和算法解耦,API 强大且清晰,集成比较方便。
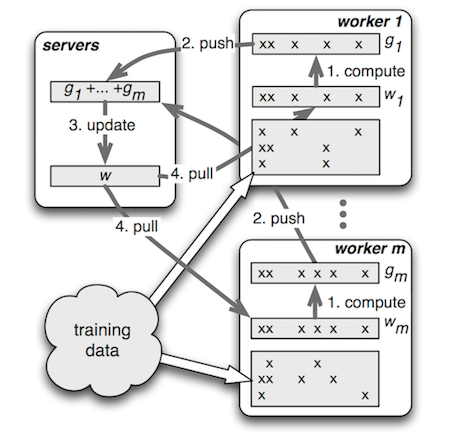
图 14 Parameter Server
在开发过程中,我们也遇到并解决了一些性能优化问题:
为了节约 Worker 的内存,通常不会将所有的数据储存在内存中,而是分 Batch 从硬盘中 Pre-fetch 数据,但这个过程中存在大量的数据解析过程,一些元数据的重复计算(大量的 key 排序去重等),累计起来也是比较可观的消耗。针对这个问题我们修改了数据的读取方式,将计算过的元数据也序列化到硬盘中,并通过多线程提前将数据 Pre-fetch 到对应的数据结构里,避免了在此处浪费大量的时间来进行重复计算。
在训练过程中 Worker 的计算效率受到宿主机实时负载和硬件条件的影响,不同的 Worker 之间的执行进度可能存在差异(如下图所示,对于实验测试数据,大部分 Worker 会在 700 秒完成一轮训练,而最慢的 Worker 会耗时 900 秒)。而通常每当训练完一个 Epoch 之后,需要进行模型的 Checkpoint、评测指标计算等需要同步的流程,因此最慢的节点会拖慢整个训练的流程。考虑到 Worker 的执行效率是大致服从高斯分布的,只有小部分的 Worker 是效率极低的,因此我们在训练流程中添加了一个中断机制:当大部分的机器已经执行完当前 Epoch 的时候,剩余的 Worker 进行中断,牺牲少量 Worker 上的部分训练数据来防止训练流程长时间的阻塞。而中断的 Worker 在下个 Epoch 开始时,会从中断时的 Batch 开始继续训练,保证慢节点也能利用所有的训练数据。
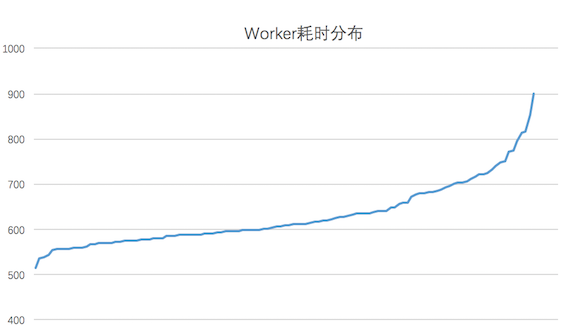
图 15 Worker 耗时分布
总结与展望
深度学习模型落地到推荐场景后,对业务指标有了明显的提升,今后我们还将深化对业务场景的理解,做进一步优化尝试。
在业务方面,我们将尝试对更多的业务规则进行抽象,以学习目标的方式加入到模型中。业务规则一般是我们短期解决业务问题时提出的,但解决问题的方式一般不够平滑,规则也不会随着场景的变化进行自适应。通过 Multi-task 方式,把业务的 Bias 抽象成学习目标,在训练过程中对模型的学习进行指导,从而可以比较优雅的通过模型解决业务问题。
在特征方面,我们会继续对特征的挖掘和利用进行深入调研。不同于其他推荐场景,对于 O2O 业务,Context 特征的作用非常显著,时间,地点,天气等因素都会影响用户的决策。今后会继续尝试挖掘多样的 Context 特征,并利用特征工程或者模型进行特征的组合,用于优化对样本的表达。
在模型方面,我们将持续进行网络结构的探索,尝试新的模型特性,并针对场景的特点进行契合。学术界和工业界的成功经验都很有价值,给我们提供了新的思路和方法,但由于面临的业务问题和场景积累的数据不同,还是需要进行针对场景的适配,以达到业务目标的提升。
参考文献
[1]: Mu Li, David G. Andersen, Alexander Smola, and Kai Yu. Communication Efficient Distributed Machine Learning with the Parameter Server. NIPS, 2014b.
[2]: Rich Caruana. Multitask Learning. Betascript Publishing, 1997.
[3]: Xiangnan He and Tat-Seng Chua. Neural Factorization Machines for Sparse Predictive Analytics. Proceedings of the 40th International ACM SIGIR conference on Research and Development in Information Retrieval(2017).
[4]: Guorui Zhou, Chengru Song, et al. Deep Interest Network for Click-Through Rate Prediction.arXiv preprint arXiv:1706.06978,2017.
[5]: Dzmitry Bahdanau, Kyunghyun Cho, and Yoshua Bengio. Neural Machine Translation by Jointly Learning to Align and Translate. ICLR ’15, May 2015.
[6]: H.-T. Cheng, L. Koc, J. Harmsen, T. Shaked, T. Chandra, H. Aradhye, G. Anderson, G. Corrado, W. Chai, M. Ispir, et al. Wide & deep learning for recommender systems. arXiv preprint arXiv:1606.07792, 2016.
作者简介
绍哲,2015 年校招入职原美团, 主要从事推荐排序模型相关的工作。
刘锐,先后在百度、阿里巴巴从事推荐业务相关工作,现就职于美团平台推荐技术中心,专注深度学习模型的研发工作。

Java 避坑指南:Java 高手笔记代码篇
本迷你书包括 86 个业务开发中常见踩坑点。每一个知识点都相当的实用,是程序员业务开发中的必备避坑指南...











评论