
自 Dataiku 12.6.2 版本起,用户可在 Dataiku 的 LLM 配方中直接调用 Snowflake Cortex 模型。该功能实现了无需迁移数据的无代码 AI 应用,在保障数据安全的同时显著提升了易用性。
然而,Snowflake Cortex 提供的 LLM 种类繁多且性能各异。此外,Dataiku Cloud 不同区域可用的 LLM 也存在差异。目前缺乏以日语系统汇总可用 LLM 及模型性能的相关资料。
为此,我们特别面向日本 Dataiku Cloud 用户,针对东京区域运行的 Dataiku 平台可通过 Snowflake Cortex 调用的 LLM 进行了性能对比分析(截至 2025 年 7 月)。
在东京区域运行的 Dataiku 中可用的 Snowflake Cortex LLM
在东京区域运行的 Dataiku 平台上可用的 Snowflake Cortex 大语言模型包括:
文本生成模型:
● Llama 3.1 70B
● Mistral Large 2
● Mixtral-8x7B
● Mistral 7B
● Mistral Large
嵌入模型:
● E5-base-v2
● Snowflake Arctic Embed M
综上所述,在处理日语数据时,Mistral Large 2 在文本生成领域、Snowflake Arctic Embed M 在文本嵌入领域均展现出最优性能。
各模型概述与特点
本博客将清晰阐述各模型的概况与特点,并系统梳理其优势与不足。
文本生成模型
Llama 3.1 70B
Llama 3.1 70B 是由 Meta 公司推出的开源大语言模型,其中“3.1”代表 LLM 版本号,“70B”指参数量(700 亿)。
在多项基准测试中,其性能现均优于 Mixtral-8x7B 和 GPT-3.5 Turbo。
但该模型支持的 8 种语言不包含日语。
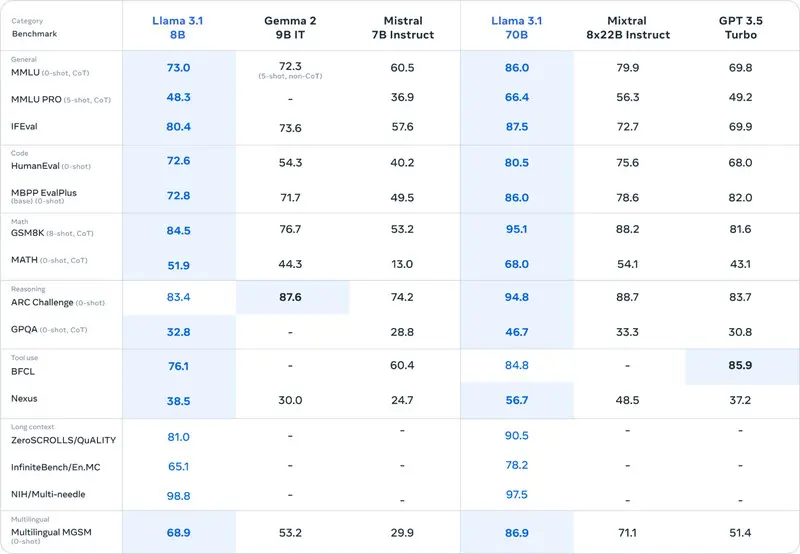
Llama 3.1 70B 基准测试性能对比图表
来源:Introducing Llama 3.1: Our most capable models to date(https://ai.meta.com/blog/meta-llama-3-1/)
Llama 3.1 70B 的优势
● 具备卓越的性能,发挥出色
Llama 3.1 70B 的优势
● 其支持的 8 种语言中未包含日语
Mistral Large 2
Mistral Large 2 是由 Mistral AI 公司开发的 1230 亿参数规模大型语言模型。
该模型具备 128K 令牌的超长上下文处理窗口,在长文本处理任务中展现出卓越性能。
其语言支持覆盖范围广泛,除日语外,还全面支持英语、法语、德语、西班牙语、意大利语、葡萄牙语、阿拉伯语、印地语、俄语、汉语、韩语等多国语言,在多语言处理能力方面表现突出。
此外,该模型还支持包括 Python、Java、C、C++、JavaScript、Bash 在内的 80 余种编程语言,在代码生成与补全等任务中展现出显著优势。
在训练阶段,通过专门优化有效减少了幻觉现象(即缺乏事实依据的输出),从而实现了较高的可靠性。
与 Llama 3.1 (405B) 相比,尽管参数规模仅为约四分之一,但被评估达到同等级别的性能。
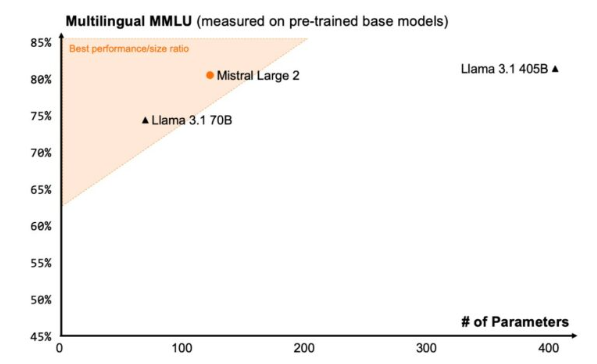
Mistral Large 2 基准测试图表
数据来源:Large Enough(https://mistral.ai/news/mistral-large-2407)
Mistral Large 2 的核心优势
● 在多项基准测试中展现出超越 Llama3.1 70B 的卓越性能;
● 原生支持日语等多语言处理能力。
Mistral Large 2 的显著局限
● 模型参数量级庞大;
● 实际部署运维成本较高。
Mistral-8x7B
Mixtral(Mistral-8x7B)是一款高质量的开放权重稀疏专家混合模型。
该模型在多数基准测试中实现了约 6 倍于 LLaMA 2 70B 的推理速度,同时展现出更优的性能。此外,在多项评估指标中其精度达到或超越了 GPT-3.5 水平。
该模型支持英语、法语、意大利语、德语及西班牙语,具备实用的多语言能力,但未包含日语支持。
与 Mistral Large 2 类似,该模型有效抑制了幻觉现象(即偏离事实的输出),能够提供可靠性较高的响应结果。
Mistral-8x7B 的核心优势
● 具备卓越的推理加速能力;
● 有效抑制幻觉现象生成。
Mistral-8x7B 的显著劣势
● 缺乏日语语言支持
Mistral 7B
Mistral 7B 是一款开源的高性能大语言模型。
在所有核心基准测试中,其表现均优于 Llama 2 13B。
该模型通过采用分组查询注意力机制,实现了推理速度的显著提升。
同时借助滑动窗口注意力技术,使其在长文本处理场景下仍能保持低成本、高效率的推理能力。
Mistral 7B 的优势
● 模型参数量级虽小但具备卓越性能;
● 对日语任务具备中等程度的处理能力。
Mistral 7B 的局限性
● 与 LLaMA 3.1 70B 等大规模参数模型相比仍存在性能差距
Mistral Large
Mistral Large 是一款性能超越 LLaMA 3.1(70B) 与 Claude 2 的大规模语言模型。
然而相较于 LLaMA 3.1(405B)及 Mistral Large 2 等更高性能模型仍存在差距。
该模型在多语言处理方面表现卓越,可原生级支持英语、法语、西班牙语、德语及意大利语。
同时具备日语处理能力,能够实现准确度达标的理解与内容生成。
此外,其配备 32K 令牌的上下文窗口,特别适用于长文档及代码处理场景。
Mistral Large 的核心优势
● 虽未达到 LLaMA 3.1 70B 水准,但具备卓越的模型性能;
● 支持多语言处理能力。
Mistral Large 的显著劣势
● 尽管支持日语处理,但在语言自然度与准确性方面较 GPT-4 等顶尖模型存在差距
嵌入模型
E5 Base v2
E5 Base v2 是专精于生成嵌入表示的模型,可应用于检索增强生成(RAG)、聚类分析及各类 NLP 任务中的特征提取。
该模型基于 MS MARCO 与 BEIR 数据集通过对比学习训练而成,其核心优势在于卓越的检索精度与聚类性能。
需注意的是,本模型不支持推理任务(如问答系统)及文本生成任务。
E5 Base v2 模型的优势
● 作为嵌入模型,在聚类与检索任务中展现出卓越的精度表现
E5 Base v2 的局限性
● 该模型专用于嵌入任务,不支持推理及生成类任务。
Snowflake Arctic Embed M
Snowflake Arctic Embed M 是一款模型规模达 110B 的嵌入模型。
与 OpenAI 的嵌入模型(text-embedding-3-large)相比,其参数量约为后者的 1/4,嵌入维度约为 1/3,但在检索性能方面展现出更优异的表现。
该模型尤其在日语基准测试中取得高分,在日语文本检索和相似度计算领域具有显著优势。
Snowflake Arctic Embed M 的优势
● 在嵌入模型中具备卓越性能;
● 在日语文本处理领域展现出尤为突出的精准度。
Snowflake Arctic Embed 的局限性
● 作为专用嵌入模型,不支持推理及生成类任务
总结
我们汇总了在东京区域运行的 Dataiku 中可用的 Snowflake Cortex 模型性能。
通过结合使用 Dataiku 与 Snowflake,可助力整个组织构建数据驱动的决策基础架构。
在处理日语数据的推理与生成任务时,我们建议优先考虑支持日语且高性能的 Mistral Large 2 模型。此外,下篇博客将详解如何在 Dataiku 中使用 Snowflake Cortex。
原文地址:
https://www.keywalker.co.jp/blog/dataiku-snowflake-cortex-llm-performance.html
点击链接立即报名注册:Ascent - Snowflake Platform Training - China




