本次 11.11 策划,我们邀请了 1 号店来分享他们关于电商搜索的经验,另外,在本次 ArchSummit 全球架构师峰会北京站,设置了《电商专题:系统架构如何应对业务爆发式增长》《阿里双11 技术架构突破》专题,来深入解读双11 等大促背后的技术故事,大会将于2016 年12 月2 日-3 日在北京国际会议中心召开,欢迎关注。
背景
1 号店的搜索 Ranking Model 一直在朝着精细化方向深化,我们希望在提升用户满意度的同时,也能提升网站的流量转化率。在实践机器排序学习之前,1 号店网站的搜索 Ranking Model 已经经历了 4 个阶段:通用排序模型 (Universal Ranking Model)、基于区域的排序模型 (Region-based Ranking Model)、基于品类的排序模型 (Category-based Ranking Model) 和基于用户的排序模型 (User-based Ranking Model)。
在这个过程中,需要对搜索、浏览、点击、购买,评论等几十个行为特征进行细粒度的分解和重组,这就需要人工去分析用户的搜索行为和流量效率之间的关系,并通过人工调整排序模型来优化效果。在细分了区域和品类之后,为了更有效地提升排序模型的优化效率,我们开始考虑使用机器排序学习算法。
机器排序学习的一般分为两个流程,其中“training data -> learning algorithm -> ranking model”是一个离线训练过程,包含数据清洗、特征抽取、模型训练和模型优化等环节。而“user query -> top-k retrieval -> ranking model -> results page”则是在线应用过程,表示利用离线训练得到的模型进行预估。
机器排序学习有如下优点:
- 人工规则排序是通过构造排序函数,并通过不断的实验确定最佳的参数组合,以此形成排序规则对搜索结果进行排序。但是在数据量较大、排序特征较多的情况下,依靠人工很难充分发现数据中隐藏的信息,而机器排序则可以较好地解决这个问题;
- 机器学习可以基于持续的数据反馈进行自我学习和迭代,不断地挖掘业务价值,对目标问题进行持续优化;
设计原则
从一开始,我们就没有考虑将机器排序学习作为人工规则排序的替代者,而是致力于将两者作为互为补充的排序模型,不同品类采用不同的排序策略,这也体现在了我们的搜索排序架构上。
图 1 表示目前 1 号店现在生产环境上机器排序学习的框架,包含两个部分:离线训练和在线应用。离线部分主要是根据历史数据以及训练目标,产生一个可用于在线预测的排序模型;而在线部分则是利用离线产生的排序模型,根据在线用户的 Context 完成实际的排序。
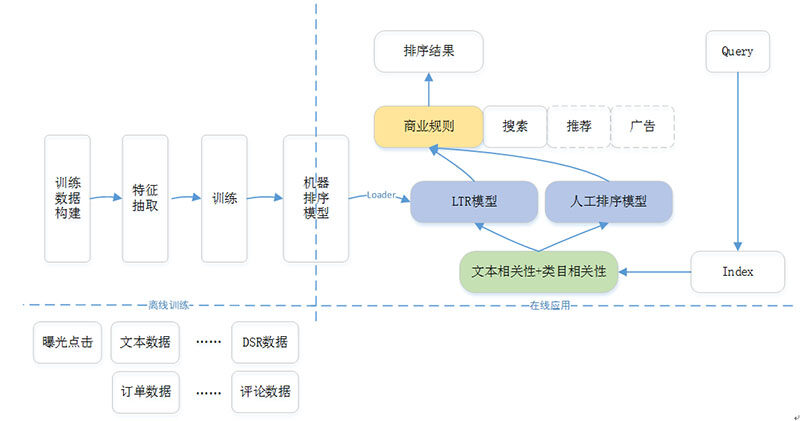
图 1 - 机器排序学习框架
在整个机器排序框架中,整个在线排序模块分为 3 层。
第一层称为一排(也称为粗排),主要是根据用户 Query 从索引库中召回所有相关商品,然后依据文本相关性和类目相关性得分,完成第 1 轮商品筛选,形成上层排序模型的候选商品集;
第二层称为二排(也称为精排),主要是以一排的候选商品集为基础,应用 LTR 模型或者人工排序模型,完成基于排序特征的重新排序;
第三层称为三排,主要是根据各种商业需求对二排的排序结果进行调整,如类目打散、商品推广等;
在整个机器排序框架中,离线部分需要模型评测环境,而在线部分更需要数据收集模块和 A/B Test 模块。这两点并没有在图 1 的框架中列出,但是在后续的介绍中会给出相应的说明。
机器排序学习离线训练过程
我们选择开源的 RankLib[2] 作为机器排序学习的工具包。在离线训练过程中,我们测试了 RankNet, LambdaMART 和 Random Forests,根据评测结果,我们选择了 LambdaMART(具体采用哪种模型,需要根据实际业务场景和训练结果而定)。该算法是一种有监督学习 (Supervised Learning) 的迭代决策回归树排序算法,目前已经被广泛应用到数据挖掘的诸多领域。
LambdaMART 模型可以分成 Lambda 和 MART 两部分,底层模型训练用的是 MART(Multiple Additive Regression Tree),也叫 GBDT(Gradient Boosting Decision Tree),它的核心是每一棵树学习的是之前所有树结论和的残差,这个残差 + 当前的预测值就能得到真实值。而 Lambda 是 MART 求解过程使用的梯度,其物理含义是一个待排序的文档下一次迭代应该排序的方向和强度。具体 LambdaMART 的算法和工作原理可以参考 [4]。
下面我们以 LambdaMART 为基础算法来介绍机器排序学习的整个过程。
3.1 训练目标数据
离线训练目标数据的获取有 2 种方法,人工标注和点击日志。两者都是为了构建出 <q, p, r-score> 的数值 pair 对,作为机器学习的训练数据集。这里 q 表示用户的查询 query,p 表示通过 q 召回的商品 product,r-score 表示商品 p 在查询 q 条件下的相关性得分。
其中人工标注一般步骤为,根据给定的 query 商品对, 判断商品和 query 是否相关,以及相关强度。该强度值可以用数值序列来表示,常见的是用 5 档评分,如 1- 差,2- 一般,3- 好,4- 优秀,5- 完美。人工标注一方面是标注者的主观判断,会受标注者背景、爱好等因素的影响,另一方面,实际查询的 query 和相关商品数量比较多,所以全部靠人工标注工作量大,一般很少采用。
因此,在我们的实践探索中,寻找获取方便且具有代表性的相关性的度量指标则成为重中之重。经过初期的探索,我们确定以 CTR 为基础,实现了低成本的 query-product 相关性标注(虽然不完美,但在实际工程中切实可行)。具体步骤如下:从用户真实的搜索和点击日志中,挖掘出同一个 query 下,商品的排序位置以及在这个位置上的点击数,如 query_1 有 3 个排好序的商品 a, b 和 c,但是 b 得到了更多的点击,那么 b 的相关性可能好于 a。点击数据隐式地反映了相同 query 下搜索结果相关性的好坏。
在搭建相关性数据的过程中,需要避免“展示位置偏见”position bias 现象,即在搜索结果中,排序靠前的结果被点击的概率会大于排序靠后的结果;在我们的训练模型中,如图 2 所示,第 6 位开始的商品点击数相比前 5 位有明显的下降,所以我们会直接去除搜索结果前 5 个商品的点击数 [5]。
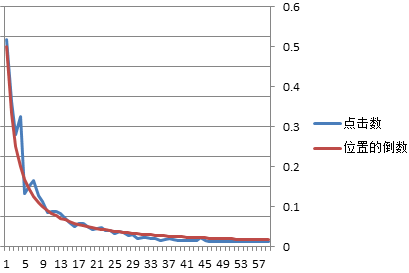
图 2 – 位置偏见的示意图
同时在实际场景中,搜索日志也通常含有噪音,只有足够多的点击次数才能体现商品相关性的大小。因此为了提升训练效率和训练效果,我们也针对 Click 数少于某个阈值的情况(即少于某个阈值的点击,我们就直接忽略)进行了测试,分别为 2,3,4,5,6,7,8。经过离线分析,在阈值为 4 的情况下,NDCG 分别有 20%-30% 的提升(这是 NDCG@60 on validation data 和当前线上的 NDCG 相比),效果提升比较明显。
表格 1 - Click 数对训练目标的影响
2
3
4
5
6
7
8
AverageOverlapScore
0.2779563
0.2622574
0.2927366
0.2605555
0.3292106
0.2570833
0.2815816
RBOScore
0.3660776
0.3278322
0.3587360
0.3362893
0.3906409
0.3456386
0.3614653
LikeNDCG1
3918.920
4529.955
4345.691
4550.222
3970.641
3555.782
3418.661
LikeNDCG2
203.5713
250.1454
235.3356
244.135
209.4407
217.9441
207.5903
NDCG@60 on training data
0.4734
0.4479
0.502
0.4846
0.4983
0.621
0.643
NDCG@60 on validation data
0.4896
0.4727
0.536
0.4743
0.4928
0.5015
0.4864
3.2 特征抽取
LTR 使用的排序特征(也称为 Feature),和人工规则排序使用的特征基本相同。按照数据特性的差异,我们将其分为 2 大类,如表 1 所示,当然不同类型的数据价值和反映用户意图的强弱也不尽相同。
表格 2 - 特征抽取部分样例
Feature**** 类别
Feature**** 项
查询相关性 **** 特征
查询相关性
text relevance, category relevance
商品特征
商品静态特征
title, sub-title, attribute (brand, category, size, color, flavor) 等
商品动态特征
price, promotion 等
订单特征
sales volume by day/week/month, GMV by day/week/month 等
行为特征
CTR (list->detail, detail->shopping)
售后特征
number of review, positive rate of review, complain rate, return rate 等
商家服务特征
DSR, online duration, online instant response 等
特征数据分几类或者怎么分类都不是重要问题,这里主要是说明要尽可能抽取多的特征数据,供后续训练使用。同时对于机器排序学习而言,这里的行为特征都需要跟踪到 Query 维度,所以在数据采集的时候,需要预先处理好,这样才能体现 Query 对应的排序影响。如果能将订单特征也区分到 Query 维度会更好,但是我们现在还没有做到这一点,以后还会继续实验。
除了商品静态特征以外,商品动态特征、订单特征、行为特征、售后特征、商家服务特征都需要细分到品类和区域,幸运的是,在人工规则的排序模型阶段,就已经为我们准备好了 profile-based 的特征数据。为了能在人工规则排序和机器排序学习之间共享这些特征数据,我们将这些特征数据存储在基于 HBase 的 Item Feature Repository 数据库中。目前这些特征数据还是以天为单位进行批处理,而非实时完成。
在得到相关度数据和特征数据后,就可以根据 LambdaMART 训练数据的格式(如下所示),构建完整的训练数据集。每一行代表一个训练数据,项与项之间用空格分隔,其中
<target> qid:<qid> <feature>:<value> <feature>:<value> ... <feature>:<value> # <info>图 3 表示项目中使用的实际训练数据(这里选取了其中 10 个特征作为示例,#后面可以增加 Query 和商品名称,方便分析时的查看):
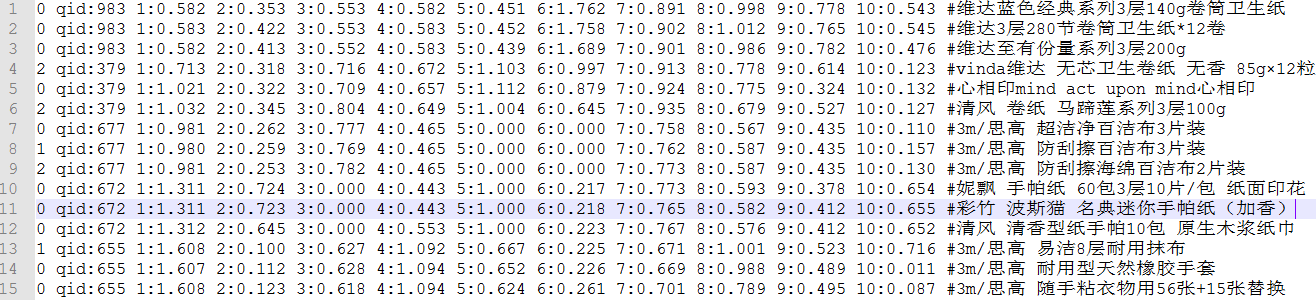
图 3 - LambdaMART 训练样本
3.3 离线训练
LambdaMART 学习过程的主要步骤可以参考 [4],数学推导不是本文的重点:
- 先遍历所有的训练数据,计算每个 pair 互换位置导致的指标变化 deltaNDCG 以及 lambda;
- 创建回归树拟合第一步生成的 lambda,生成一颗叶子节点数为 L 的回归树;
- 对这棵树的每个叶子节点通过预测的 regression lambda 计算每个叶子节点的输出值;
- 更新模型,将当前学习到的回归树加到已有的模型中,用学习率 shrinkage 系数做 regularization;

图 4 - LambdaMART 训练过程
RankLib 提供了简单的命令行,只需根据实际的需要配置好参数,就可以实现训练模型、保存模型的功能。下面是我们在工程中使用的参数配置示例:
java -jar ~/bin/RankLib.jar -train ~/train_all.csv -gmax 4 -tvs 0.8 -norm zscore -ranker 6 -metric2t NDCG@60 -tree 1000 -leaf 10 -shrinkage 0.1 -save ~/models/learned_lambdamart_model.mod 参数说明
-train 是必须的,表示训练样本所在的文件名;
-ranker 是必须的,表示指定的机器学习算法,而 6 就是 LambdaMART;
-gmax 是可选的,指定训练目标相关性的最大等级,默认是 4,代表 5 档评分,即{0,1,2,3,4};
-tvs 是可选的,设置样本中用于训练的数据比例,即 train 数据:validation 的比是 0.8:0.2;
-norm 是可选的,指定特征归一化的方法,默认没有归一化,zscore 代表采用均方误差来归一化;
-metric2t 是可选的,训练数据的评测方法,默认是 ERR@10;
-tree 是可选的,指定 lambdamart 使用的树的数目,默认是 1000;
-leaf 是可选的,指定 lambdamart 每棵树的叶节点数,默认是 10;
-shrinkage 是可选的,指定 lambdamart 的学习率,默认是 0.1;
-save 是可选的,用于保存模型;
上述命令执行结束后会在 -save 指定的目录下产生一个如图 6 的模型文件,该模型文件也就是可以用于生产环境的机器排序模型。
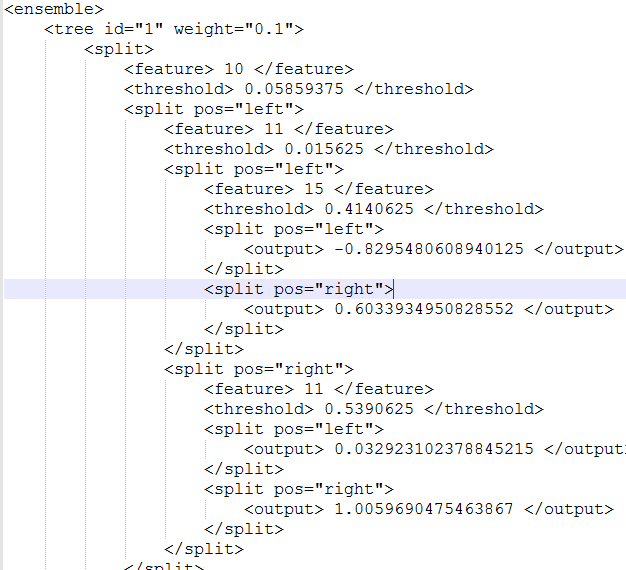
图 5 - LambdaMART 训练产生的模型
3.4 离线评测
在排序模型训练完成之后,我们需要准备与训练样本相同数据格式的离线测试样本,这个测试样本尽量选取和训练样本不同的数据集。
java -jar ~/bin/RankLib.jar -load ~/models/learned_lambdamart_model.mod -test ~/test_samples.csv -metric2T NDCG@60 -score ~/rerank_scores.txt这里 -load 对应的参数就是在离线训练中得到的排序模型,-test 对应的参数就是测试样本集,-metric2T 使用和训练过程相同的评价方式,-score 对应的参数就是保存测试样本集中每个 query 下商品的得分。
【实验样本】为了离线测试 LTR 的模型效果,选择了两个流量差异较大的类目,暂且称为类目 A 和类目 B,其中类目 A 的流量大约是类目 B 的 40 倍。同时选择不同平台、不同时间段内的数据作为训练样本。
【评测指标】除了使用评价排序效果的 NDCG 以外,出于商业因素的考虑,我们还选择了 4 个评价排序位置变动情况的指标,其中 AverageOverlapScore 和 RBOScore 指标越大表示正常排序和 LTR 排序越接近,LikeNDCG1 和 LikeNDCG2 指标越小表示正常排序和 LTR 排序越接近。
表格 3 - 类目 A 的离线评测效果
类目
A
训练数据平台
PC
PC + IOS + ANDROID
PC
PC
PC
训练数据时间段
一周
一周
两周
一周
一周
NDCG@60
on training data
0.5617
0.5365
0.5313
0.5253
0.5778
NDCG@60
on validation data
0.5391
0.5411
0.5605
0.5138
0.5372
AverageOverlapScore
0.3535
0.3751
0.3710
0.4254
0.3442
RBOScore
0.4236
0.42823
0.4306
0.4591
0.4005
LikeNDCG1
3001.8343
2997.8116
2957.3804
3591.0862
3108.4491
LikeNDCG2
148.5160
147.1333
141.9098
176.5259
156.8397
表格 4 - 类目 B 的离线评测效果
类目
B
训练数据平台
PC
PC + IOS + ANDROID
PC
PC
PC + IOS + ANDROID
训练数据时间段
一周
一周
两周
一周
一周
NDCG@60
on training data
0.6834
0.4882
0.6148
0.7887
0.4955
NDCG@60
on validation data
0.5193
0.5356
0.5549
0.5522
0.5042
AverageOverlapScore
0.2273
0.3438
0.3100
0.2207
0.1965
RBOScore
0.2597
0.3636
0.3495
0.2573
0.2344
LikeNDCG1
3166.5950
2765.4566
2022.0802
3202.8392
3142.5835
LikeNDCG2
208.9072
156.8297
110.9762
201.1636
188.5675
可以看出,同样用一周的数据,PC+IOS+Android 的评测效果在多个指标上要好于只用 PC 的效果;而同样在 PC 端,两周数据的评测效果也好于一周;但是这个结论并不是普遍性,对于不同类目,需要具体问题具体分析,进而确定表现较好的模型。
另外,为了验证 LambdaMART 的不同训练参数对预测效率和预测效果的差异,我们也进行了其它 4 组实验,分别是如下:
- 默认参数设置
- 在 1 的基础上调整 tvs 参数
- 在 2 的基础上调整 leaf 参数
- 在 3 的基础上调整 tree 和 shrinkage 参数
4 个模型的排序结果如下图所示,其中横坐标 PO1 表示线上排序 1-8,PO2 表示线上排序 9-16,纵坐标表示这 8 个位置与 LTR 排序下商品位置变动数量。
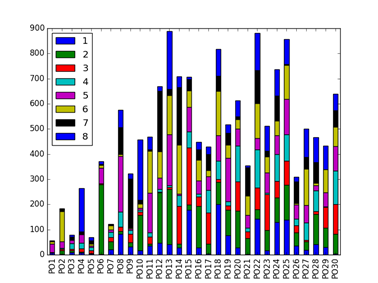
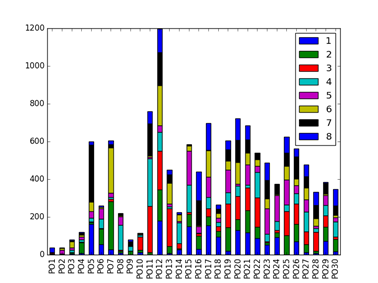
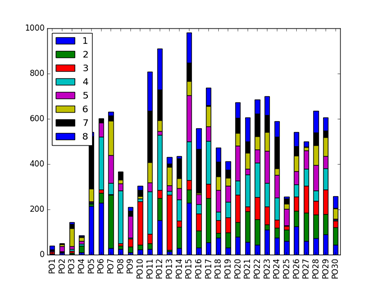
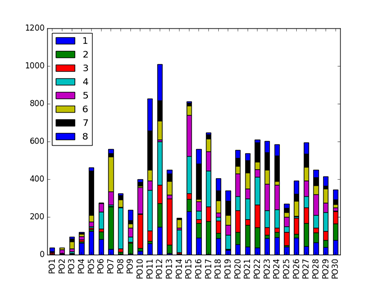
不同模型的指标对比如下,模型 2 的 4 个指标均为最佳。
表格 5 - 不同训练参数对训练结果的影响
模型
AverageOverlapScore
RBOScore
LikeNDCG1
LikeNDCG2
1
0.54369
0.580978
4739.148
189.846
2
0.67377
0.669086
4089.201
162.9705
3
0.574048
0.59842
4874.85
194.454
4
0.629045
0.64889
4186.75
166.738
综合 LambdaMART 在 Training Data 和 Validation Data 的迭代次数和训练时间来看,随着参数的增加,训练时间和迭代次数都有增加;但是当去除噪音 Click 的数据后,训练时间和迭代次数有明显的降低。
在线应用
【模型加载】离线测评时,可以用命令行的方式加载模型,读取数据文件,进而测试模型性能。显然这种方式并不适合在线应用,因此我们需要提取 RankLib 加载模型和在线打分的代码。为了有效进行系统地管理,我们将模型文件统一存放在 MySQL 表中,并利用字段区分类目和平台等信息。
【在线测试】为了排除用户固有行为特性的影响,从而更加准确地比较 LTR 排序和人工排序的各项指标,在进行 A/B Test 之前,我们首先进行了一段时间的 AA 测试,从而选出各项指标较为接近的桶,再比较这些桶在 LTR 排序和人工排序之间差异。
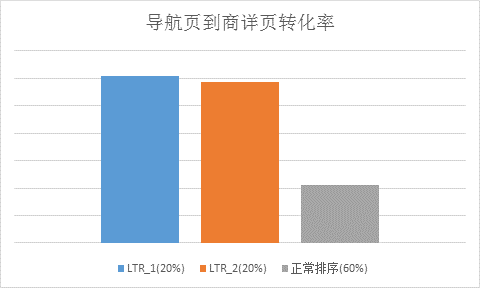
将训练后的 LTR 模型按照图 2 的框架应用到生产环境中,在整个测试期间,我们观察了不同时间周期、不同平台数据产生的多个模型。总体来讲,LTR 模型对“搜索导航页到商详页的 CTR”在 2016 年 11.11 活动期间有约 8.7% 的提升,并且“订单转化率”在 11.11 活动期间有约 4.5% 的提升。(其中 LTR_1 和 LTR_2 是我们设置的不同流量分桶,用于观测不同分桶对模型的影响)
总结
总的来说,人工规则与机器排序是紧密结合的。如果排序的量化目标不太明确,则人工规则就更适合。电商搜索不仅要考虑查询相关性,还要考虑销售额和订单转化率,因此电商搜索往往有较多的业务规则。如 eBay 和 Google 在搜索排序方面就结合了人工业务规则,而广告排序一般更依赖于机器排序,因为其优化目标比较明确。所以我们也会在当前成果的的基础上,将机器排序学习进一步应用到推荐和广告系统上。
参考文献
[1] https://en.wikipedia.org/wiki/Learning_to_rank
[2] https://sourceforge.net/p/lemur/wiki/RankLib/
[3] http://jmlr.org/proceedings/papers/v14/burges11a/burges11a.pdf
[4] http://research.microsoft.com/en-us/um/people/cburges/tech_reports/msr-tr-2010-82.pdf
[5] An experimental comparison of click position-bias models. In Proceedings of the 2008 International Conference on Web Search and Data Mining (pp. 87-94). ACM




