

本文为 Robin.ly 授权转载,文章版权归原作者所有,转载请联系原作者。
2019 年计算机视觉顶会 CVPR 前不久刚在美国长滩闭幕。Robin.ly 在大会现场独家采访 20 多位热点论文作者,为大家解读论文干货。本篇继续推出三篇计算机视觉研究相关的热门研讨会、论文解读:
研讨会:语义视觉导航中的深度学习方法
Deep Learning for Semantic Visual Navigation
论文:未知环境中的导航
Scene Memory Transformer for Embodied Agents in Long-Horizon Tasks
研讨会:场景变换时的视觉定位
Long Term Visual Localization Under Changing Conditions
论文: 计算机视觉中的无监督/弱监督学习
FineGAN: Unsupervised Hierarchical Disentanglement for Fine-Grained Object Generation and Discovery

语义视觉导航中的深度学习方法
深度学习是一种以人工神经网络为架构,对数据进行表征学习的算法。至今已有数种深度学习框架被应用在计算机视觉、语音识别、自然语言处理、音频识别与生物信息学等领域并获取了极好的效果。
“Deep Learning for Semantic Visual Navigation”研讨会探讨了深度学习在语义视觉导航领域的研究与挑战。来自 Google 的资深研究员 Alexander Toshev 是研讨会的组织者之一,同时也是李飞飞的合作研究者。下文是他在 CVPR 大会现场与 Robin.ly 的访谈文字与视频。

Alexander Toshev 在美国长滩 CVPR2019 现场接受 Robin.ly 访谈
Wenli:非常感谢您接受我们的采访。能不能介绍一下这个研讨会?
Alexander Toshev:
这是一个值得关注的领域。机器学习的核心问题包括对大型物理空间进行推理并根据视觉输入做出决策的能力。如果我们能够整合各种技术就可以研发出能在自然环境中工作的自主系统。
Wenli:在考虑举办研讨会的时候您邀请了哪些协办单位和演讲嘉宾?
Alexander Toshev:
这个想法来自我在 Google 的一位同事,我们也联系了公司外部的一些合作者。探索路径或者导航是一个比较老的问题,近几年大家尝试从不同角度重新定义了这个概念,不仅仅关于在几何空间中进行规划,还包括视觉空间推理。如何在可以做出许多决定的空间中进行推理,有许多方面需要考虑。如果我们所掌握的空间变化的知识不够完善,就必须依靠更复杂的推理决策。但现在大家似乎没有意识到这一点,所以我们实际上并没有问题的定义上达成共识。
Wenli:从您的角度来看,深度学习在语义理解领域的应用是什么?目前面临着什么挑战?
Alexander Toshev:
我认为大多数机器人在静态的,熟悉的环境中通常能够很好的工作,但是一旦取消了这些限制,问题就变得非常复杂。比如你有一个建筑详细的三维地图,机器人很容易就能从一个地方移动到另一个地方。但是如果没有这些限制,没有地图,在陌生的环境里还有很多人在四处走动,在这种情况下让机器人去拿一杯咖啡,用经典系统是无法实现的。所以主要的应用就让智能体适应信息较少且动态的环境,理解语义。
针对语义导航、视觉导航,人们理解的方式多种多样,很多问题几乎没有明确的定义。所以找到确切的基准来推动相关项目的研究面临着一系列挑战。人们应该深入研究如何在未开发的环境中通过类别标签寻找对象或者位置。
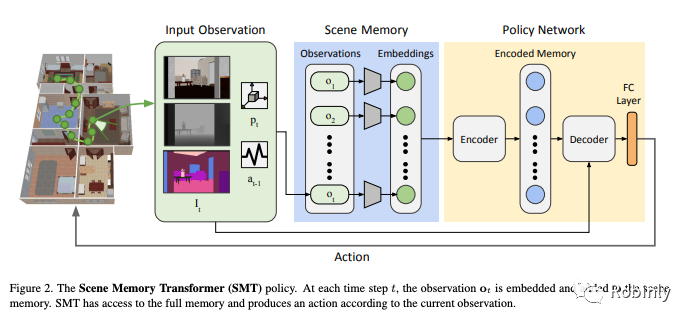
场景记忆转化模型图示,来源:Scene Memory Transformer for Embodied Agents in Long-Horizon Tasks
Wenli: 我们知道您今年有一篇论文被 CVPR 接收了,题目叫做“Scene Memory Transformer for Embodied Agents in Long-Horizon Tasks” 也是和李飞飞一起合作的论文。能介绍一下这篇论文吗?
Alexander Toshev:
我们正在研究在未知环境中进行导航的问题。其中一个目标就是希望有一个控制器能够接收新的观察输入和动作输出,帮助机器人接近目标对象。
有一类算法可用于解决通用的机器人问题,比如通过强化学习来训练神经网络。对于许多机器人问题,即使不利用过去的经验也能完成目标。但是对于导航,我们就需要利用拥有历史记忆的模型。在这篇论文中,我们设计了一个具有外部存储器的神经网络,然后用外部存储器训练这个神经网络,依靠强化学习进行导航。与没有存储器或存储空间非常小的神经网络相比,我们的系统性能得到了明显优化。
Wenli:您是否感受到了在学术界和工业界研究实验室工作的差异?
Alexander Toshev:
很难将二者做比较。但总的来说,在工业界,很多公司也在解决计算机视觉中的一些基本问题。我们正处在一个非常激动人心的工业时代,让有能力和自由选择解决那些重要的问题。
讲座信息
Deep Learning for Semantic Visual Navigation
组织者:Alexander Toshev,Anelia Angelova,Niko Sünderhauf,Ronald Clark,Andrew Davison
信息链接:
https://sites.google.com/view/sem-vis-nav
论文信息
Scene Memory Transformer for Embodied Agents in Long-Horizon Tasks
作者:Kuan Fang,Alexander Toshev, Li Fei-Fei,Silvio Savarese
组织机构:Stanford University,Google Brain
论文链接:
场景变换时的视觉定位
视觉定位问题是近些年来计算机视觉领域的研究热点,同时非常具有挑战性,其在机器人视觉导航、公共场景监控、增强现实、交互虚拟现实、智能交通等诸多领域都具有十分重要的意义。
CVPR 视觉定位相关的研讨会“Long Term Visual Localization Under Changing Conditions”的组织者之一,瑞典查尔姆斯理工大学(Chalmers University of Technology)的副教授 Torsten Sattler,在大会现场接受 Robin.ly 专访,介绍了他的最新研究以及该领域所面临挑战。以下是访谈实录和视频。

Torsten Sattler 在美国长滩 CVPR2019 现场接受 Robin.ly 访谈
Wenli: 非常感谢您接受我们的采访。能介绍一下这个研讨会吗?
Torsten Sattler:
视觉定位问题(visual localization)就是在已知场景中给出图像,找出该图像在场景中的位置。这一技术拥有重要的应用。比如要打造一辆无人车或者一款清洁机器人,它们需要知道自己的位置,然后才知道要往哪个方向走。再比如设计一个增强/混合现实产品,我们需要知道用户在立体空间中的位置和相对于虚拟对象的位置,从而将虚拟对象准确投影到用户的视野中。人们围绕这个课题已经做了大量研究。但是我们往往只捕捉一次场景,然后就认为该场景永远不变,这显然是不可能的。场景中会发生很多变化,比如季节循环,树木在夏天有叶子但冬天没有,地面上可能有雪,昼夜更替,或者有家具移动过的室内场景。定位算法需要具备足够的鲁棒性来应对这样的变化。这也是举办本次研讨会的初衷。整个研讨会包含两个环节:来自工业界和学术界专家的演讲,以及一个挑战——参会者可以在我们的数据集上测试他们的算法,然后评选出能够准确定位图像并能应对场景中的各种变化最佳算法。
Wenli:您在组织这个研讨会的时候邀请了哪些数据行业的专家?
Torsten Sattler:
我们邀请了北卡罗来纳大学 Chapel Hill 分校的 Jan-Michael Frahm,目前他也在 Facebook 任职。他对 3D 重建和时变场景领域做了很多重要贡献。我们还邀请了 Google 的 Bernhard Zeisl,他是所在部门的技术主管,负责构建视觉定位算法所需的核心单元,比如你晃一晃手机就会显示出你的位置并指出你要去的地方。除此之外,还有机器人领域的 Niko Sünderhauf。我们希望将计算机视觉和机器人技术相结合,让来自不同领域的人实现合作。再就是犹他大学的 Srikumar Ramalingam,现在也在 Google 任职,他在语义定位方面做了很多有趣的研究。
实际上我们成为这次研讨会的组织者主要是因为我们在 2017 年提交的一篇介绍我们所构建的部分基准测试的论文被拒绝了。于是我们跟其他几个志同道合的同行联合起来,希望打造一个大型团队继续推动相关工作。这也从侧面说明了文章未被接收也不见得是坏事。
Wenli:你们现在面临的挑战是什么?实现了哪些突破?
Torsten Sattler:
一个挑战是如何将夜间图像与白天建立的场景表征对应起来。目前我们有多个数据集,每个都包含我们在某个季节的某一天获取的参考表征信息,再结合夜间以及在不同的天气条件下不同季节的图像,就可以对所有细节进行细致的评估。如何将夜间图像与从白天建立的表征场景对应起来一直是个亟待解决的难题。
另一个挑战就是场景中包含很多植物的情况。比如草木之类的植物会随着时间变化荣枯,目前还没有人能提供应对这种情况的解决方案。我认为机器学习在预测这些变化的方面很有潜力,比如某个季节应该对应什么样的景象,从而帮助我们更好的处理这些场景。
我自 2011 年以来就一直在研究这个课题。我认为将解决方案扩展到城市规模,并弄清楚在设计可扩展算法处理方面还存在哪些挑战是很重要的。场景越大处理起来就越复杂,其中可能包含很多重复性的元素,了解如何处理重复元素也是一件非常有趣的事情。我也很高兴看到机器学习算法开始取代我们早年设计的手工管道中的一些组件,并实现了性能的大幅提升。

同一场景的变化图示,来源:Long-Term Visual Localization
Wenli:今年您有几篇被接受的论文引起了很多关注。能简单介绍一下这些论文吗?**
Torsten Sattler:
我们昨天在会上介绍的第一篇论文叫“BAD SLAM”,目的是解决同时构建 3D 地图并确定位置的问题。我们设计了一种非常精确的新算法,用于通过图像构建地图并进行同步更新。
另一篇论文的主题类似机器学习算法定位,目的是理解绝对相机姿态回归的局限性。我们认为构建定位系统的一种方法是训练神经网络将图像作为输入,然后输出拍摄此图像的位置和方向。我们注意到这样做的效果不是很好,但它们的工作原理跟算法很类似,即采用一组图像来训练神经网络,找到输出结果中最接近的一个,获取其位置和方向信息得到一个近似值,作用与训练预测准确姿态的网络异曲同工。我希望这个结论能够引导社区开发出更好的算法。
过一会儿我还会在会上介绍一篇论文,叫做“D2-Net: A Trainable CNN for Joint Detection and Description of Local Features”,其核心思想是训练本地特征,在两个图像的像素之间建立对应关系。我们开发了一种新方法来检测这些特征的位置,通过一些数学计算和矢量表征来寻找两个图像之间相同的部分。这一方法在昼夜图像对比的工作中取得了出色的进展,让我们获得了之前无法得到的对应关系。一旦找到了两个图像中的相关像素,就可以推断出两个相机之间的对应位置关系。这是一项了不起的进步,是自动驾驶领域增强现实技术的基石。
讲座信息
Long-Term Visual Localization under Changing Conditions
组织机构:Scape Technologies,Chalmers University of Technology,Nuro,Imperial College London,Czech Technical University,ETH Zurich,Tokyo Tech
信息链接:
计算机视觉中的无监督/弱监督学习
无监督学习和弱监督学习已经在计算机视觉领域中有了广泛的应用。加州大学 Davis 分校的副教授 Yong Jae Lee 一直致力于研究无监督、弱监督学习。
Yong Jae Lee 教授在 CVPR2019 大会现场接受 Robin.ly 专访时,给大家介绍了他的最新研究成果。以下是访谈实录和视频。

Yong Jae Lee 教授在美国长滩 CVPR2019 现场接受 Robin.ly 访谈
Wenli: 我们正在和 Yong Jae 一起讨论他新提交的论文“FineGAN: Unsupervised Hierarchical Disentanglement for Fine-Grained Object Generation and Discovery”。能简单介绍一下这篇论文吗?其创新之处在哪里?
Yong Jae Lee:
我们在这项工作中的目标是以无监督的方式对对象的精细粒度细节进行建模,比如鸟类的品种、外形、颜色和品种特有的纹理细节。我们能够在鸟类、汽车和犬类中实现这样的建模。
在这个无监督模型中,我们借鉴了前人很多伟大的工作。但我们工作的特点在于,我们有一个模型,能够模拟对象的层次结构,并以分层的方式利用各个变量因素生成图像。比如我们可以生成一只白色的鸭子,背景是一片水塘。但是我们可以通过改变一个颜色变量把它变成一只黑鸭子,但同时保留白色鸭子的背景和形状细节。
Wenli: 你当初为什么选择了这个领域?研究成果有哪些实际应用?
Yong Jae Lee:
我一直对无监督学习很感兴趣。之所以选择这个领域是因为我们注意到人们在初级分类的无监督建模方面已经做了大量工作。我所说的初级就是指能够区分汽车、狗和人类。但是在对更精细的对象细节进行建模或查找对象类别方面的工作并不多。我们想要打造一个无监督的模型,可以学习对于细粒度对象类别无监督分组比较有用的表征。
其中一个应用是我们当前工作的一种扩展,即模型的条件变体。目前这个过程是完全无监督的,利用无监督代码生成图像。我们正在进行的扩展工作可以让我们在真实图像上调整模型。比如你有三个图像,你可以提取图像 A 的背景,图像 B 中鸟的形貌,以及图像 C 中鸟的颜色和纹理来创建一个新图像。这种模型在电子商务或服装设计等领域有潜在的应用。
Wenli: 你是如何对视觉识别系统产生兴趣的?当初是看到了什么样的趋势?
Yong Jae Lee:
我在念大学的时候开始对计算机视觉产生了兴趣,在伊利诺伊大学 Urbana Champaign 分校参与研究的第一个项目就是人脸检测,那时候只能检测图像中所有面部的边界框。在读博士的时候,我是德克萨斯大学奥斯汀分校 Kristen Grauman 教授的学生,博士后期间又师从加州大学伯克利分校的 Alyosha Efros 教授。我很幸运能与这些伟大的研究人员合作,并能够更深入地探索庞大且有趣的计算机视觉领域。
就目前的趋势而言,我们已经取得了巨大的进步,特别是近年来在图像分类、对象检测、实例分割、动作识别等各种问题上。但是,最先进的方法通常都依赖于大量人类注释的训练数据。这种对标签数据的依赖已成为整个行业发展的瓶颈。我认为当前的趋势是,我们正在努力转向能够利用最少的人工监督进行学习的系统,减少对固定数据集的依赖,像人类和动物的学习方式靠拢。这就是我所看到该领域的发展方向,我们还有很长的路要走。
如果我们想检测到一个特定的瓶子,那么标记图像是有意义的,因为你有非常具体的目标。但是如果你想拥有一个可以与其他智能体,人类、动物在非结构化和新颖的环境中互动的系统,那么它还必须通过在陌生环境中学习来获得能够适应不熟悉事物的能力。
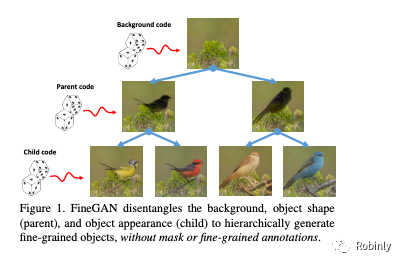
论文图示-分层解码,来源:FineGAN 论文,链接见下方
Wenli: 除了这篇论文之外,你还有很多其他论文也被 CVPR 接受了。其中一个是“You Reap What You Sow”。这篇文章具体是什么内容?
Yong Jae Lee:
在这篇文章中,我们试图在没有任何边界框注释的情况下训练物体检测器。我们提出的方法不需要像传统方法那样收集包含紧密贴合目标对象的注释边界框的训练图像,而是能够进行图像级的标签注释,让系统自动识别出目标对象的位置。
所有弱监督对象检测的最初步骤都是要生成候选对象区域,而这无异于大海捞针。我们建议与其生成一堆候选对象区域,使用静态外观线索,不如直接利用视频中的运动信息。我们可以在没有任何人为监督的情况下获取该信息,自动生成准确的定位,并将其用作初始化弱监督对象检测器的方法。将视频用于无监督学习的想法早有先例,但对于弱监督对象检测,把利用外观线索的对象建议边框的初始标准步骤替换为基于动作的方法正是该工作的主要创新之处。
Wenli: 还有其他想跟我们分享的论文吗?
Yong Jae Lee:
我最近很感兴趣的另一个问题是隐私保护视觉识别技术,在去年的 ECCV 会议上也发表过相关论文。我们希望创建一个能够识别视频中人类行为或活动的系统,让视频中的人物看起来完全不同,从而保护他们的隐私,还能以假乱真。我们希望这样的系统不仅能够迷惑人类,还能够欺骗其他机器学习分类器。
Wenli: 我听说你也是会议演示环节的主席 (Demo Chair)。能介绍一下这个职位的主要工作内容吗?
Yong Jae Lee:
演示环节让研究人员可以实时向现场观众呈现他们的研究成果。我在上学的时候还很少有人进行现场演示,而现在这样的环节很普遍。人们可以通过这个环节了解相关领域取得了什么样的进展。现在我们已经拥有可以实时工作的系统。我很高兴看到这样的进步。
论文信息
FineGAN: Unsupervised Hierarchical Disentanglement for Fine-Grained Object Generation and Discovery
作者:Krishna Kumar Singh,Utkarsh Ojha,Yong Jae Lee
组织机构:University of California, Davis
论文链接:
原文链接:

硅谷AI科技、创业、领导力访谈

中国开发者画像洞察研究报告 2024
分析开发者的行为模式、工作价值、职业发展等内容,帮助整个行业生态更深入地理解开发者,为他们提供更精准...













评论