

问题现象
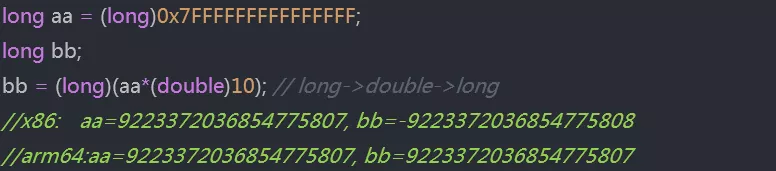
某客户在软件测试发现,一个超出 long 型范围的 double 数值再次转回 long 时,数值在 x86 和 arm64 上表现不一致;(x86 为<0,arm64 为>0),代码样例如下:
问题分析
0x7FFFFFFFFFFFFFFF 是 long(有符号 64 位整数)所能表示的正数最大值,在乘以 10 以后超过了 long 类型能表示的最大值。表达式“aa*(double)10”将会放在一个 double 类型的临时变量中存储(ARM 下使用 d 系列寄存器,x86 使用 xmm 系列的 128 位寄存器),当这个超出 long 范围的 double 数值再赋值到 long 类型的变量 bb 时,会发生一次数据类型转换。而经过测试验证,鲲鹏与 x86 处理器在数据类型转换时,处理的方式不同。
说明:
double 类型变量到 long 的数据类型转换,ARM 下的指令为 fcvtzs,x86 下为 cvttsd2si。需要详细了解可以参考相关指令说明。
问题原因
在两个平台下,是两套 CPU 架构,其中的算数逻辑单元的实现可能会有差异,操作系统、编译器的实现都会有所不同。x86(指令集)中的浮点到整型的转换指令,定义了一个 indefinite integer value——“不确定数值”(64bit:0x8000000000000000),大多数情况下 x86 平台确实都在遵循这个原则,但是在从 double 向无符号整型转换时,又出现了不同的结果。鲲鹏的处理则非常清晰和简单,在上溢出或下溢出时,保留整型能表示的最大值或最小值,开发者并不会面对不确定或无法预期的结果。详细转换情况如下:
在 double 型数据向 long 转换时,如果浮点型数值超出有符号整型的取值范围,在鲲鹏处理器和 x86 处理器的处理不同,详细转换关系参照下表:

在 double 数据向 unsigned long 转换时,如果浮点型数值超出有符号整型的取值范围,在鲲鹏处理器依然遵从 double 低于 unsigned long 最小值则 unsigned long 保留最小值 0,大于最大值为 unsigned long 类型保留最大值。而 x86 处理器的处理没有明显的规律,当 double 大于 unsigned long 最大值时,为 unsigned long 保留最小值 0,当 double 是负值且低于 unsigned long 最小值时却保留 indefinite integer value,参照下表:

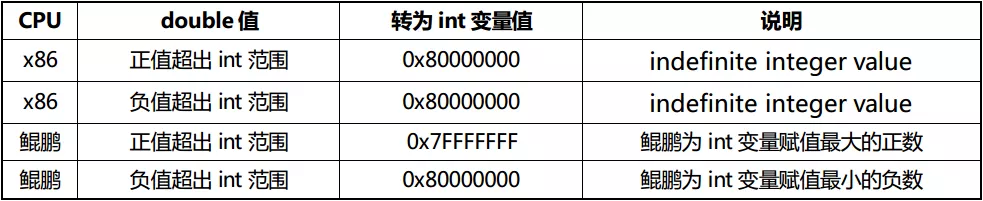
在 double 数据向 int 转换时,规则与 double 向 long 类型转换类似。x86 为 int 变量始终赋予最小的负数值,鲲鹏遵循保留最大或最小值的原则,参考下表:
在 double 数据向 unsigned int 转换时,x86 是截断 double 小数部分,整数部分向 2 的 32 次方取余。鲲鹏遵循保留最大或最小值的原则,参考下表:

其他问题
在某大数据组件的一个测试用例中,有一项关于表达式的测试,测试用例代码片段如下:

x86 处理器,return 的预期值为 2 的 31 次方(0x80000000),是 x86 所定义的 indefinite integer value——不确定值。在鲲鹏处理器下 return 的值为 int 的最大值:0x7FFFFFFF((2^31)-1)。而程序外部使用(2^32)来检测这个返回值,其实是将 x86 定义的这个“不确定数值”,当做一个正常的整数在计算(作为有符号整数,0x80000000 的十进制值为:-2147483648,这个值其实是为最小的负值,也并非程序的预期)。
扩展知识
一.浮点数的表示方式
为了更好的理解这个问题,先复习一下浮点数的表示方式。20 世纪 80 年代以来,几乎所有的计算机都遵循 IEEE 754 的浮点数运算标准。IEEE 754 定义了四种浮点数值方式:单精确度(32 位)、双精确度(64 位)、延伸单精确度(43 比特以上,很少使用)与延伸双精确度(79 比特以上,通常以 80 位实现),本文主要介绍单精度和双精度浮点数。还定义了表示浮点数的格式(包括负零-0)与反常值(denormal number),一些特殊数值((无穷(Inf)与非数值(NaN)),以及这些数值的“浮点数运算符”;它也指明了四种数值舍入规则和五种例外状况(包括例外发生的时机与处理方式)。
浮点数在计算机中的表示分为三个部分:符号位(sign)、指数位(exponent)和尾数(fraction)。

单精度浮点数 32 位:符号位 1 位,指数位 8 位,尾数 23 位
双精度浮点数 64 位:符号位 1 位,指数位 11 位,尾数 53 位
指数部分使用偏差表示,单精度偏差为 127,双精度为 1023。指数部分表示的实际值将是 exponent-偏差。
在浮点数的规格化表示中,小数点前一位始终是 1,所以这一位不会显示存储,而是由硬件在计算时实现。
几种浮点数值的分类:
1.如果指数部分为非 0,也非全 1,则表示正常的规格化浮点数;
2.如果指数部分全 0,则为非规格化浮点数。非规格化浮点数用于表示 0,或者无限接近 0 的数。
3.指数部分全部为 1 表示特殊数值:
(a)无穷大:指数部分全部为 1,并且尾数部分全部为 0。无穷大常用来表示溢出的结果;(b)NaN:not a number,计算异常。指数部分全部为 1,尾数部分不为 0。当某些计算的异常结果无法用 0,也无法用无穷大来标识时,或者某些未初始化的数据,我们就需要使用 NaN 这样的特殊数值来表示。
说明:
尾数部分的第一个 1 由硬件计算时实现,所以规格化表示的浮点数无法表示 0,因此我们需要非规格化表示 0.
浮点数的舍入:任何有效数上的运算结果,通常都存放在较长的寄存器中,x86 使用 128 位寄存器计算双精度浮点数,ARM 使用 64 位寄存器计算浮点数。当结果被放回浮点格式时,必须将多出来的比特丢弃。有多种方法可以用来运行舍入作业,实际上 IEEE 标准列出 4 种不同的方法:
Roundtoward nearest:舍入到最接近,在一样接近的情况下偶数优先(TiesTo Even,这是默认的舍入方式):会将结果舍入为最接近且可以表示的值,但是当存在两个数一样接近的时候,则取其中的偶数(在二进制中是以 0 结尾的)。
Roundtoward+∞:会将结果朝正无限大的方向舍入。
Roundtoward -∞:会将结果朝负无限大的方向舍入。
Roundtoward zero:会将结果朝 0 的方向舍入。
说明:
根据部分网上的资料参考,x86 默认使用舍入到最近,而 ARM 的浮点到整型转换指令使用。
二.整数的补码表示
计算机系统中的整型全部是用补码的方式表示,零和正数的补码是其自身,而负数的补码则需要简单的计算转换。为了简单,以 4 位的二进制数补码为例来示例:
1011=-12^3+02^2+12^1+12^0=-8+0+2+1=-5
补码的最大优点是可以在加法或减法处理中,不需因为数字的正负而使用不同的计算方式。只要一种加法电路就可以处理各种有号数加法,而且减法可以用一个数加上另一个数的补码来表示,因此只要有加法电路及补码电路即可完成各种有号数加法及减法,在电路设计上相当方便。
熟悉了补码的表示方式,在处理数值相关的一些问题时,面对计算机中的负数,更容易发现一些线索。
本文转载自公众号华为开发者社区(ID:Huawei_Developer)。
原文链接:
https://mp.weixin.qq.com/s/SdyU4lLw7aE2E_fNB0sS6A

分布式云行业实践指南(2023)
业内首个分布式云行业实践方法论、工具箱。







评论