

总体架构
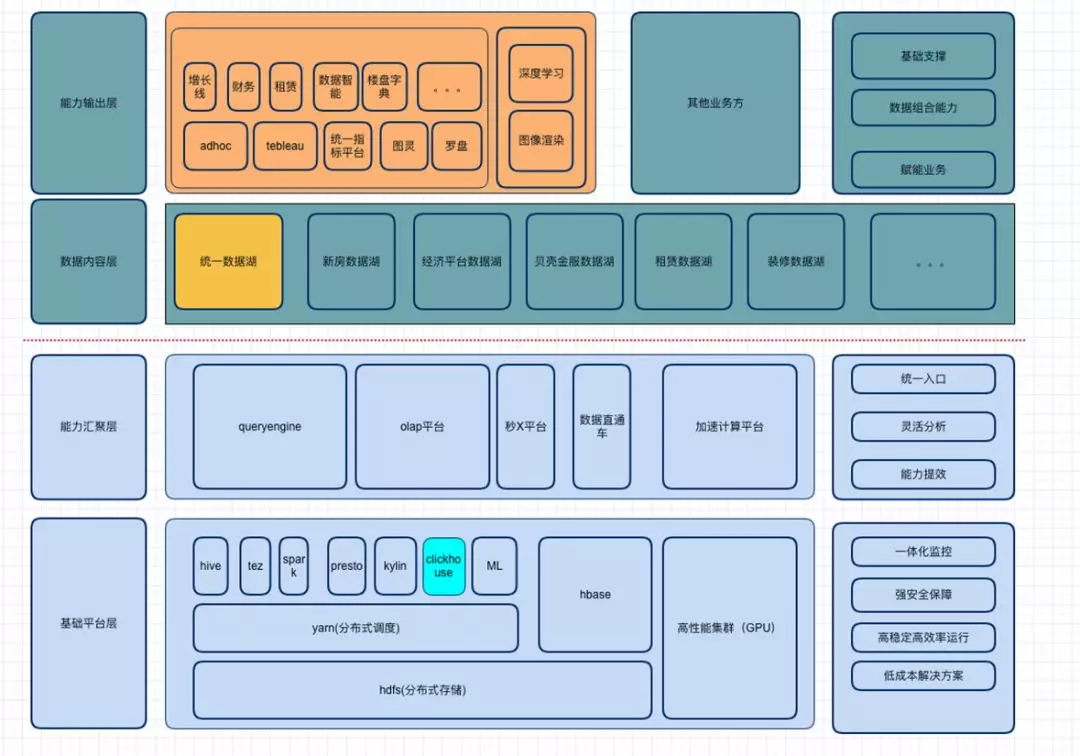
贝壳找房大数据的整体架构,从下到上分为四层:
基础平台层。这一层应用的都是比较常见的技术:HDFS 分布式存储,yarn 分布式调度,以及 HBase 存储,另外还有一些计算引擎,如 hive、tez、spark、presto、kylin、clickhouse、SparkML 等来满足各种各样的基础需求,同时还有高性能的计算机集群。
基础平台层的工作总结起来包括:
一体化监控
提供强安全保障
高稳定高效率运行
低成本解决方案
能力汇聚层。大家知道每年都有大量的开源组件,那么如何让上层的业务方更好的应用这些组件,就是能力汇聚层要完成的工作:
Queryengine,可以通过 queryengine 使用 hive、tez、spark、presto 来查询整个底层存储的数据。
Olap 平台,通过封装 kylin(预构建)、HBase、Phoenix、presto、clickhouse(流量分析)等引擎能力,打造统一的 olap 平台来满足业务方不同的需求。
流式计算平台,这个是今天要分享的主题,包括流式计算产品天眼(原秒 X 平台);然后是数据直通车,它是贝壳平台打造的一个数据接入平台,可以进行实时接入和离线接入。
加速计算平台,底层有高性能集群,上层就需要有加速计算平台,来满足业务方机器学习或者深度学习的需求。
能力汇聚层的工作总结起来包括:
统一入口
灵活分析
能力提效
更上层就是数据仓库做的事情:
数据内容层。这层主要是做统一数据湖,新房数据湖等等一些数据治理的工作来构建数据仓库,以满足更上层业务方的需求。
能力输出层。
Adhoc 即席查询,比如贝壳找房这边有些城市站,有运营市场,adhoc 可以直接写一些 sql,调用 queryengine,最终通过各种各样引擎的能力,来满足即席查询的需求。
我们还引进了 Tebleau 软件,可以用来做 BI 分析,它的底层也是调用 queryengine 查询数据内容层的数据。
同时我们也构建了统一指标平台;图灵,满足经纪人的需求;罗盘,满足一些流量分析的需求。
能力输出层的工作总结起来包括:
基础支撑
数据组合能力
赋能业务
数据流流程
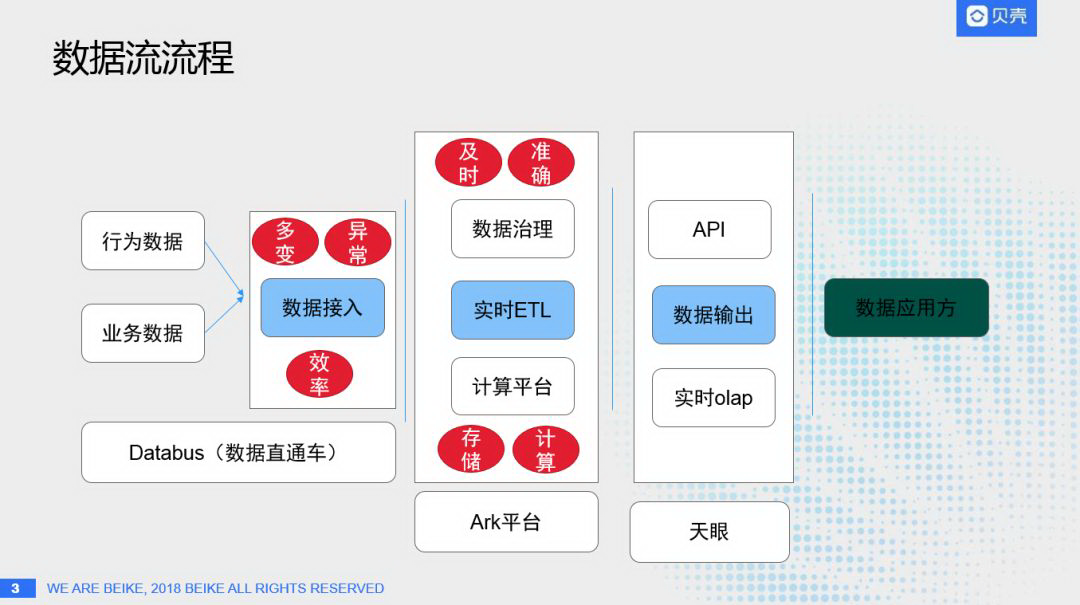
要理解流式数据,首先要知道数据流的流程:
数据接入。为了做好数据分析,同时给用户画像、数据挖掘等提供数据物料,就需要做好数据接入层,一般情况下我们面临的问题主要有:
① 多变:数据来源有业务 DB、MySQL、Oracle、sql server、第三方存储 Redis 等多种数据源,怎么对多变的数据源做统一的、及时的接入。
② 异常:举个例子,某些业务方经常在半夜刷新数据,这对数据接入的实时性和准确性产生了很大的影响。
③ 效率:
A. 离线数据接入,如何更快的把数据接入进来。
B. 实时数据接入,如何准确的接入,并及时提供需求数据。
针对这些问题,贝壳找房的解决方案就是 Databus(数据直通车),通过数据直通车来解决上述的三个问题,把行为数据和业务数据及时、高效的接入计算平台层,来满足流式数据的计算和需求。
实时 ETL。主要分为上层的数据治理和下层的计算平台。数据接入进来之后,采用什么样的形式存储,更好的做数据分析,而实时计算又采用什么样的方式存储,这里都是通过 Ark 平台来做实时处理。
数据输出。如何把数据更好的提供给用户,这里主要会介绍日志流产品化的平台天眼。
挑战

流式数据平台面临的挑战:
流式元数据管理。公司到底有哪些流式数据?比如 kafka 接了一批日志,MySQL 产生了一批 binlog,各种事务中也产生了一些流式数据。这些流式数据来自哪些业务方?数据类型是什么?有什么样的属性?以贝壳为例,是新房的数据?还是二手房的数据?还是经纪人的数据?还是客户的数据?里面数据的格式是什么样的?如何存储的?如何解析?都需要统一的流式元数据管理平台,来更好的理解并处理这些数据。
流式数据处理平台。常见的 Flink、spark streaming 等,对于需求方来说,不可能总写相应的代码,来完成操作,这样成本比较高。如何让业务方尽可能简单的、可配置的进行流式处理操作,这里主要是通过 Ark 流处理平台完成,后面会重点介绍。
流式数据应用产品。贝壳拥有多个场景,如日志分析、数据挖掘等,每个场景对流式数据都有不同的需求,这就需要我们针对不同需求做不同的产品。
流式计算平台及应用
数据直通车
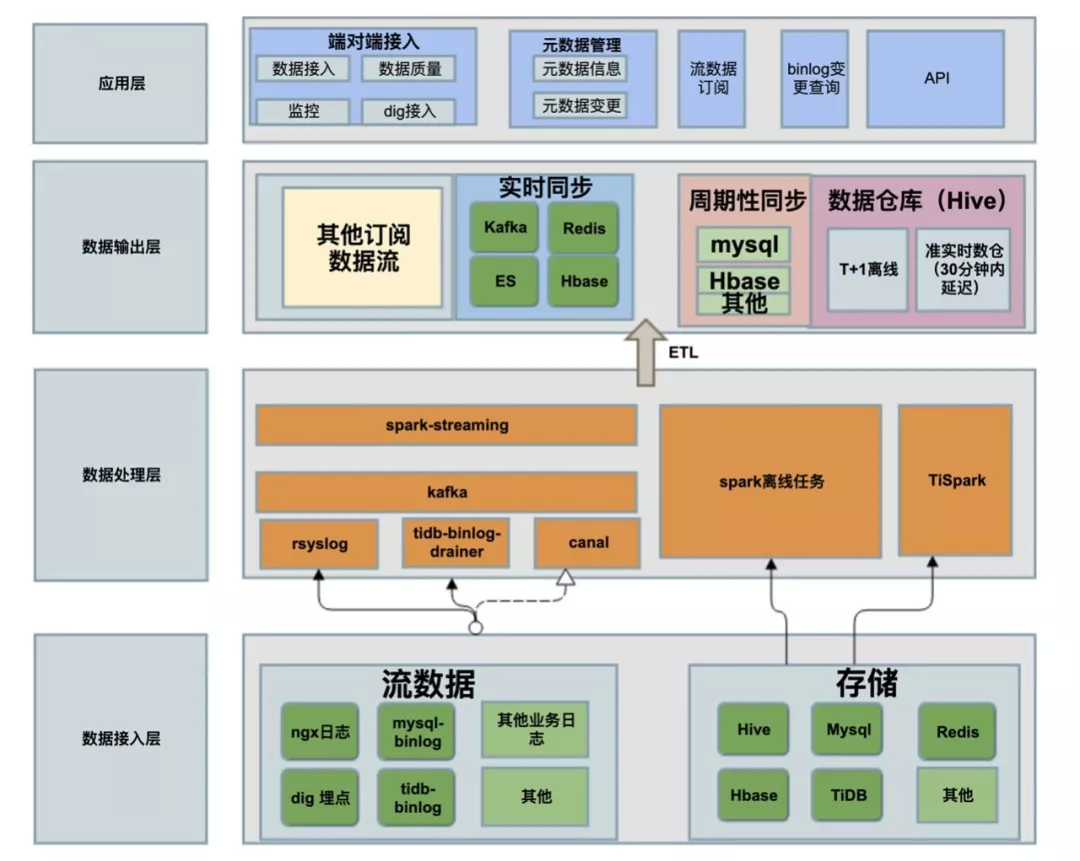
数据直通车的架构:
数据接入层分为:
① 流数据接入:贝壳的流数据包括,ngx 日志、dig 埋点、mysql-binlog、tidb-binlog、其他业务日志等,把这些流数据通过 rsyslog、tidb-binlog-drainer、canal 等接入 kafka。
② 存储接入:离线数据可能存在 Hive、Mysql、redis、HBase、TiDb 等多种数据存储源,通过 spark 离线任务、TiSpark 把数据接入到更上层的数据输出层。
流式数据接入之后,就可以做订阅,如何 kafka、redis、ES(检索操作)、HBase(大数据量 KV 操作)等,还可以做周期性同步,T+1 级别的数据,还有我们探索实现的准实时仓库,目前可以做到 5 分钟的延迟。
依赖于整个数据接入层、处理层、输出层的工作,可以满足:
① 建设完元数据之后,通过应用层就可以查询到所有元数据的信息,并且知道元数据的变更情况(如果不知道元数据的变更情况,那么数据可是不准确的,和真实的数据是对应不上的)。通过数据直通车,就可以满足我们的第一个挑战,完成了所有元数据的管理。可以及时、准确、高效的把数据接入到存储层,或者为数据处理层准备好数据物料。
② 流数据订阅
③ binlog 变更查询等。
元数据与数据仓库的能力:
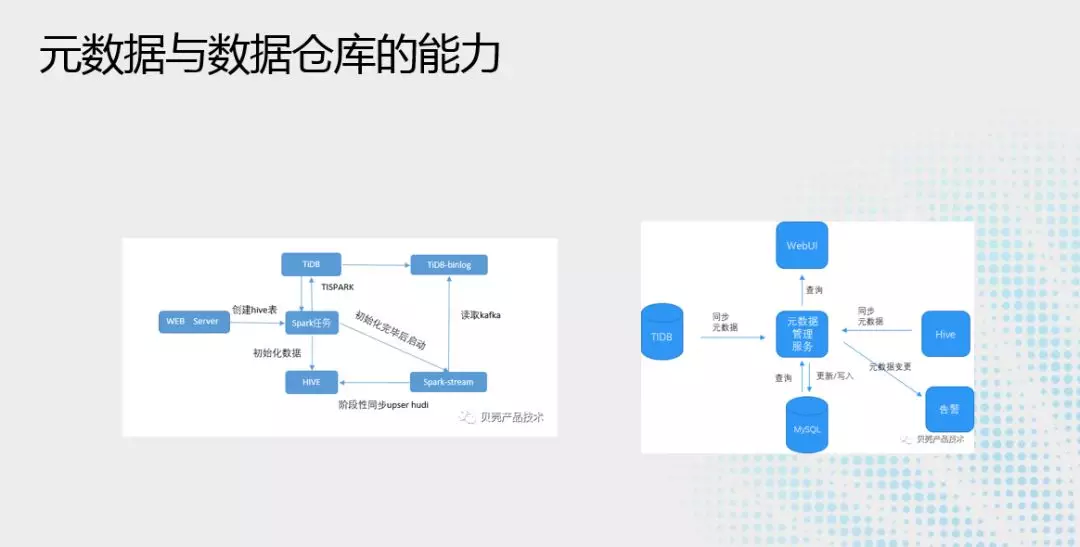
简单说下元数据管理服务,见右图,主要通过 TiDB-binlog,获取业务数据之后,把数据直接同步到 mysql,变更之后如果能自动处理就自动处理,如果不能自动处理就会发出告警,由人为来操作,这样来保证业务数据是统一的,同时通过 WebUI 接口给用户来查看,也可以通过 API 接口给其他业务来调用。比如后面要讲的 Ark 平台就可以直接调用 API 来使用流式数据。
准实时数仓,见左图,引入 hudi 能力,通过 hudi 和 TiDB 可以准实时的把数据导入数据仓库之中,用户可以在 5 分钟延迟的情况下来满足对于业务数据的统计、监控、分析的需求。
产品化展示:
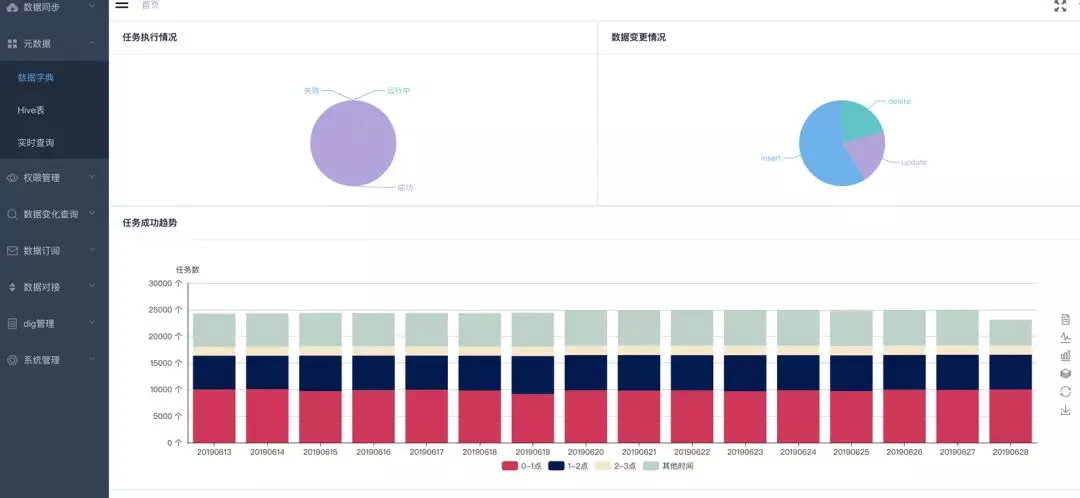
这是平台的首页,第一个图可以提供业务的执行情况,第二个图告诉我们数据的变更情况,第三个图是整个业务成功的情况。
左边栏:数据字典,元数据能力;实时查询,准实时数仓查询的能力;以及埋点管理,数据订阅管理、数据变化查询等。
通过数据直通车,解决了数据接入和元数据的管理问题。
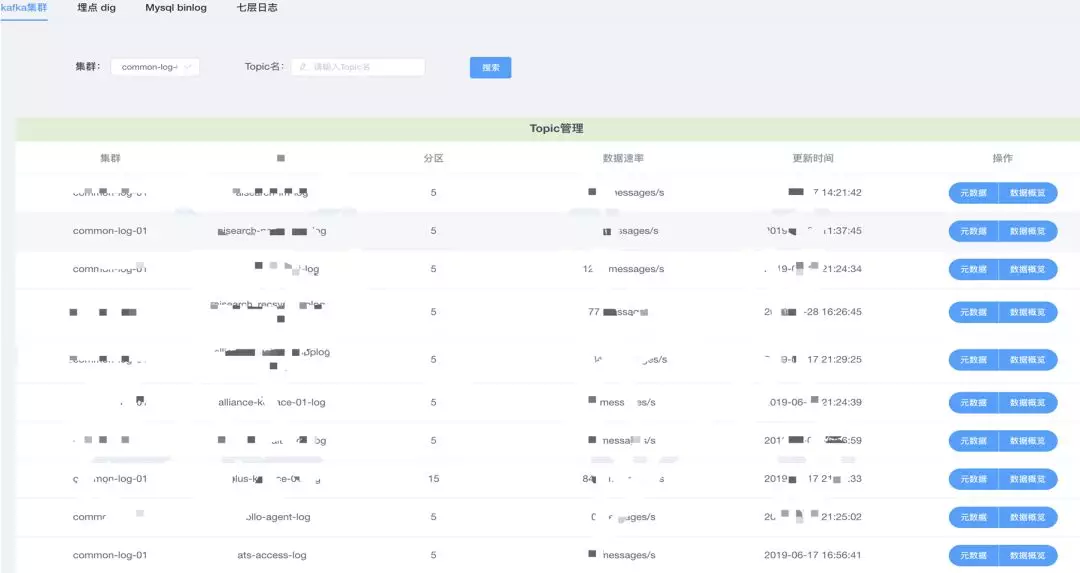
目前可以做到 kafka 集群、埋点 dig、Mysql binlog、七层日志的元数据管理。
Ark 流处理平台
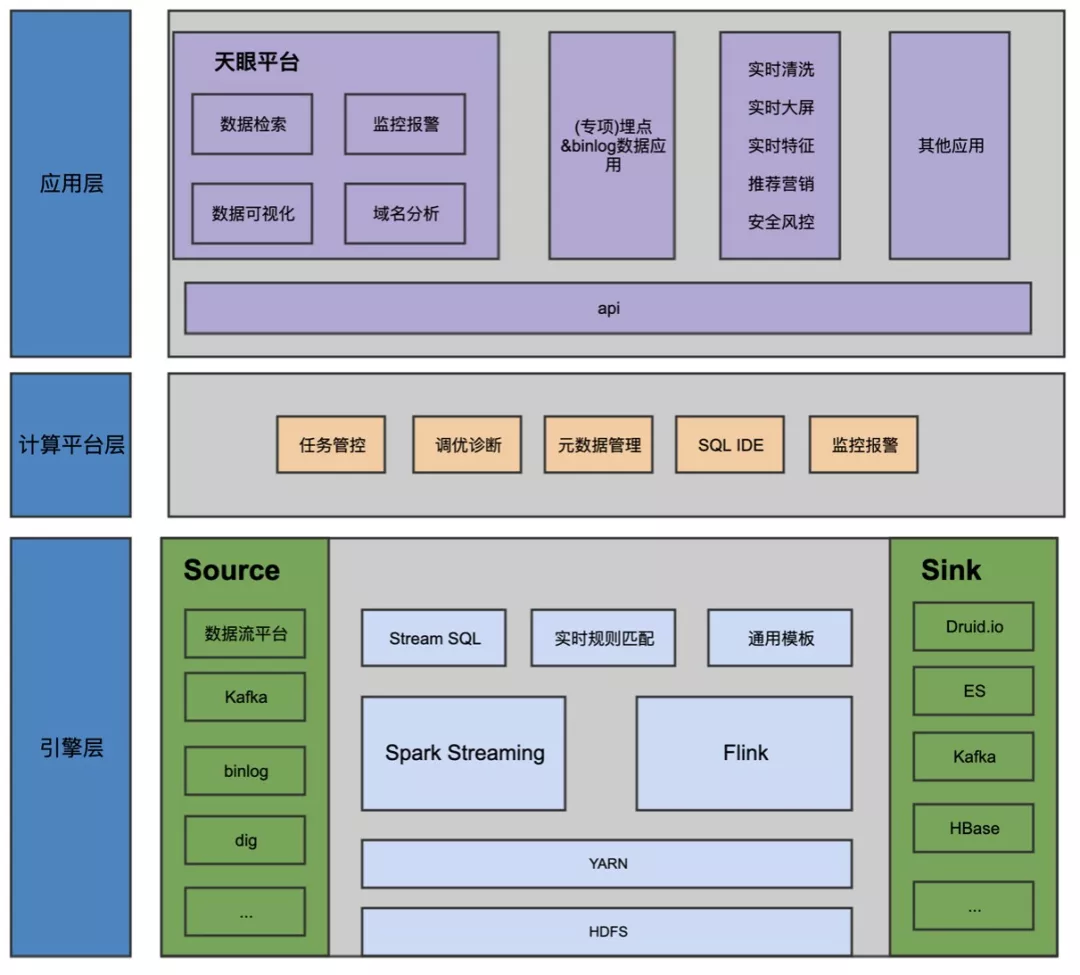
Ark 整体架构:
引擎层:
① 把数据接入到 Source 源,如 kafka、binlog、dig 等。
② 数据接入之后,在引擎层进行处理,主要方式有三种:Stream SQL、实时规则匹配、通用模板,其底层依赖于 Spark Streaming 和 Flink。
③ 最终可以把数据输出到 Sink 中,如:Druid.io、ES、kafka、HBase 等,这时用户可以直接调用。
计算平台层:
通过封装的方式来构建计算平台,计算平台主要通过这样几件事儿来完成稳定性和通用性的需求,第一个是任务管控,需要管理好我们的任务,如何调度我们的任务,第二个是调优诊断,有些用户写的任务可能不是特别完善,我们可以自动判断他的任务是否需要优化,并给出优化建议,第三个可以引入 Databus 中的数据进行处理和使用,第四个是 SQL IDE,我们会尽可能多的生成 SQL,让用户尽可能写一些少的配置,来应用 Ark 平台,最后就是监控报警,监控整个任务的运行情况和延迟情况。
应用层:
通过 API 把我们 Ark 平台的能力输出出去:
① 数据清洗
② 实时大屏
③ 实时特征
④ 推荐营销
⑤ 安全风控
还有其他的一些应用,以及后面会讲到的天眼平台,通过对日志的流式处理统一化及产品化满足日志的各种诉求。
这就是整个 Ark 流处理平台提供的能力。
Ark 能力接口:
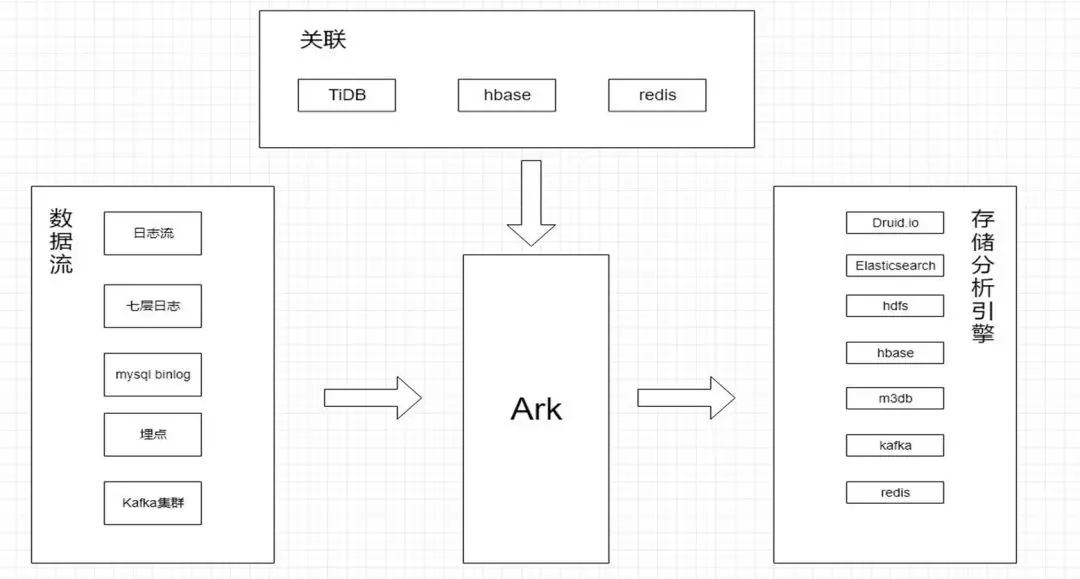
数据流(包括日志流、七层日志、mysql、埋点、kafka 集群等)通过 Ark 平台可以把数据清洗到多个分析引擎中,并且可以通过 TiDB、HBase、redis 做关联,根据不同的需求把数据关联到不同的存储分析引擎中。
产品化展示:
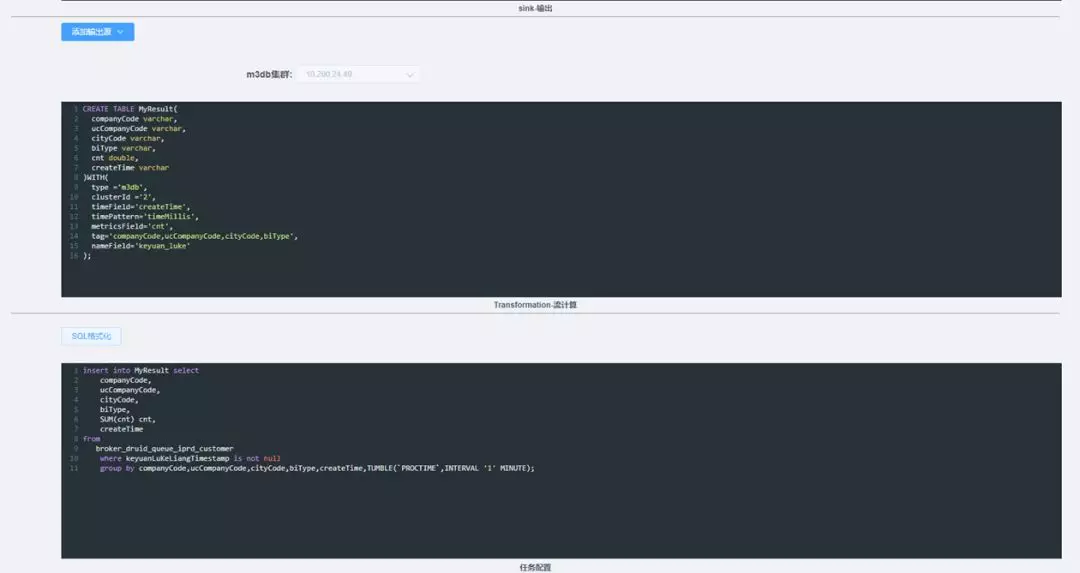
这个是 SQL IDE 的能力,90%的 SQL 都是自动生成的,大家只需要配置 m3db 地址,处理的类型等,就可以直接应用 Ark 流处理平台。这样就降低了很大的代价,因为 sql 的接入度是最强的。
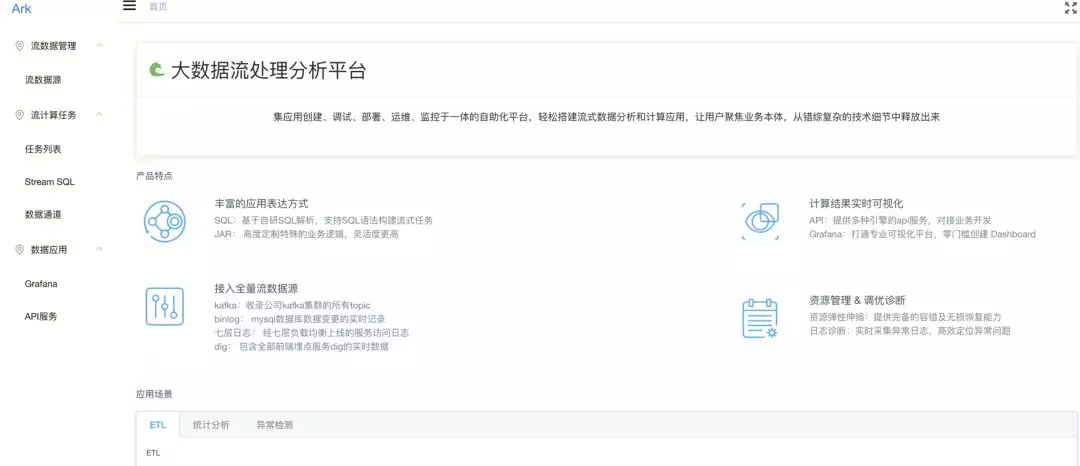
这个是 Ark 流处理平台的首页,我们简单介绍一下产品的能力特点:
丰富的应用表达方式
计算结果实时可视化
接入全量流数据源
资源管理 & 调优诊断
天眼
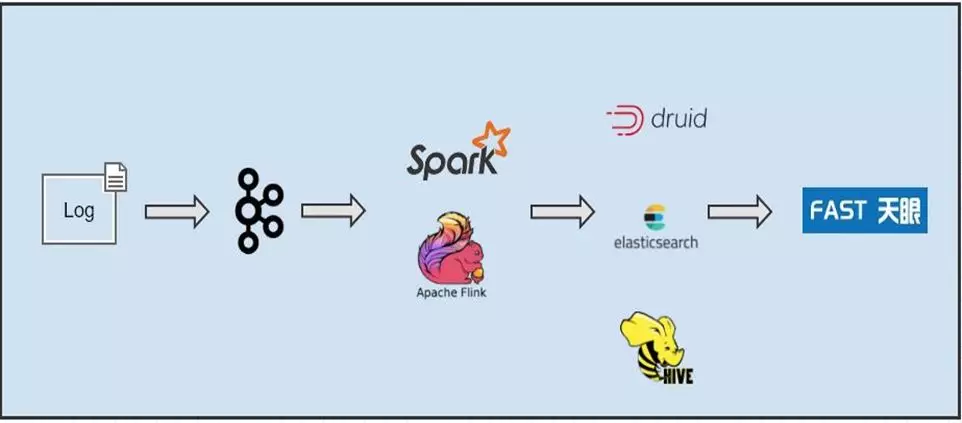
传统的方式,日志接入到 kafka,通过 spark streaming 或者 Apache flink,解析到 druid/es/hive 中来做分析,每次业务方都是按需来做这些事情,自己做数据清洗,自己在做应用,非常繁琐耗时,为了解决这个问题,我们把这些步骤集成到了一个产品天眼中。
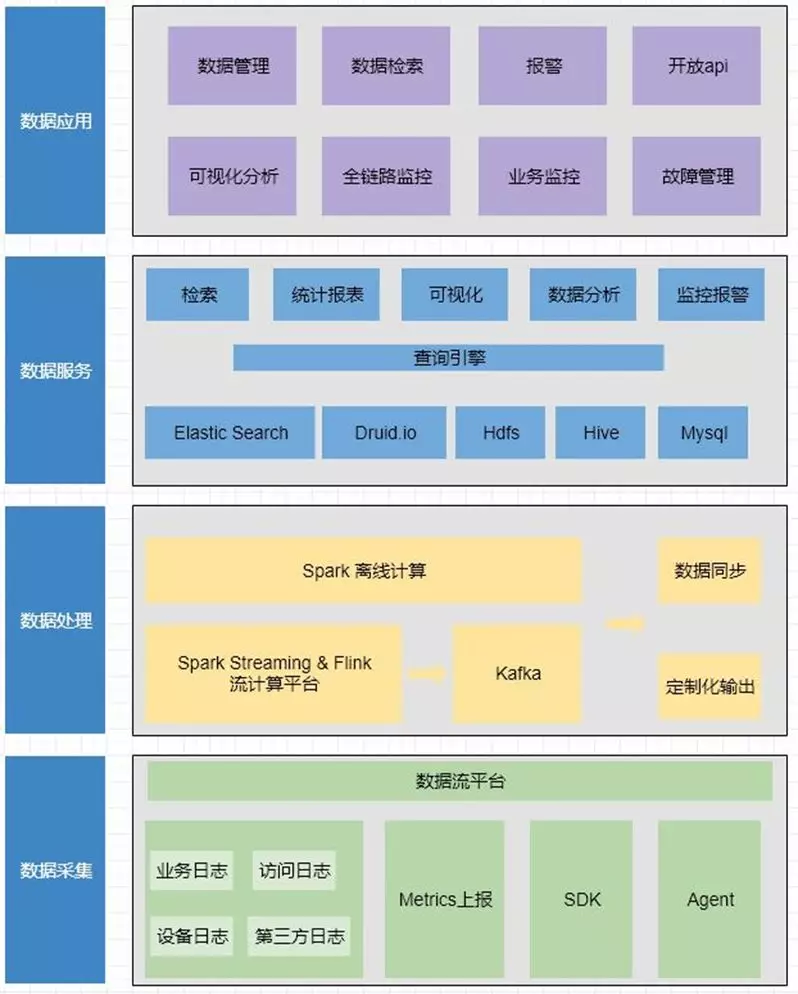
天眼架构:
数据采集:所有的业务日志、访问日志、设备日志以及第三方日志,Metrics 上报,SDK 埋点数据,Agent 数据,都可以通过 Databus 接入到数据处理层,然后再按需放入 Druid.io、HDFS、ES、Hive、Mysql 中,再通过查询引擎,可以做到检索、统计报表、可视化、数据分析、监控报警,最终根据数据采集、数据处理、数据服务三层的能力抽象出来多个数据应用,天眼可以做可视化分析、全链路监控、业务监控、故障管理,以及常见的数据管理、检索、报警,和开放的 API,让日志可以做到多种方式的应用到不同的场景。
产品化展示:
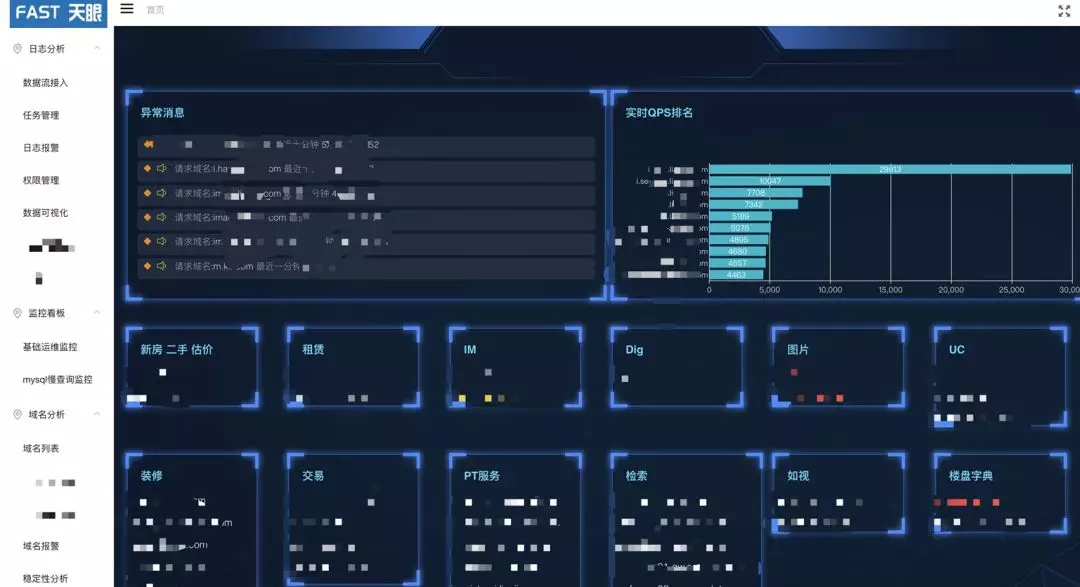
这是天眼的界面,包括实时 QPS 排名,以及多个业务方的域名,点击之后可以看到对应域名的整个实时大盘。左边栏为天眼能力的列表,通过我们的数据直通车、Ark 平台,对数据日志处理做了一站式的集成和能力的输出。
总结

① 做流数据处理,一定要先把流数据字典能力做出来,只有一个清晰的、完整的、可视的流数据字典能力才能让流数据应用的更好,方便用户的查询。
② 丰富的流处理能力,通过产品化的封装,比如 Spark streaming 和 Flink 有多种流处理能力,通过 Ark 封装,用户可以更简易、自主的配置。
③ 多场景适应能力,根据各种场景,把基础层提供的数据能力,做一个产品化的封装,满足不同场景应用的能力。除了刚刚讲的天眼日志分析外,流式处理还有各种的应用,如 AI 对实时的数据挖掘,实时的用户画像等。
今天主要为大家分享了贝壳找房的三个平台,以及流式数据处理的挑战和一些实战的经验。谢谢大家。
作者介绍:
赵国贤,贝壳大数据架构团队负责人。目前负责贝壳大数据架构团队,负责公司大数据存储平台、计算平台、实时数据流平台的架构、性能优化、研发等,提供高效的大数据 olap 引擎、以及大数据工具链组件研发,为公司提供稳定、高效、开放的大数据基础组件与基础平台。
本文来自 DataFun 社区
原文链接:

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论 1 条评论