

引言
ByConity 是一个由字节跳动开源的云原生数据仓库引擎,采用存储计算分离的架构,实现了读写分离和弹性扩缩容。这款引擎支持多个关键功能特性,如资源隔离、无感扩缩容、高性能和数据的强一致性等。该架构确保读写操作不会相互影响,同时使计算资源和存储资源解耦,两者可以按需独立扩缩容,实现资源高效利用。ByConity 适用于多租户环境,支持多租户资源隔离功能,保证不同租户之间不会互相影响。另外,ByConity 采用主流的 OLAP 引擎优化技术,如列存储、向量化执行、MPP 执行和查询优化等,为用户提供优异的读写性能。
ByConity 存储计算分离架构
为了让大家更好的理解需要部署的组件,这里简单介绍下 ByConity 的架构。想更深入了解请参考另一篇文章《谈谈ByConity存储计算分离架构和优势》。ByConity 的存储计算分离架构主要分为三层:共享服务层、计算层和云存储层。共享服务层是所有查询的入口,主要组件是 Cloud Service 和 Metadata Storage,它会对查询进行解析和优化,并负责一些服务、组件和事务的管理和元数据的管理。计算层是计算资源组,主要组件是 Virtual Warehouse(VW),包括 Read VW 和 Writer VW。云存储层是分布式统一存储系统,ByConity 所有的数据都存储在这一层,在计算层进行查询时,会从云存储层中读取数据,具体实现可以采用各种云存储服务,如 HDFS、S3 等。此外,ByConity 还包括 TSO、Daemon Manager、Resource Manager、后台任务和服务发现等共享服务组件,为整个系统提供稳定的支持和管理。
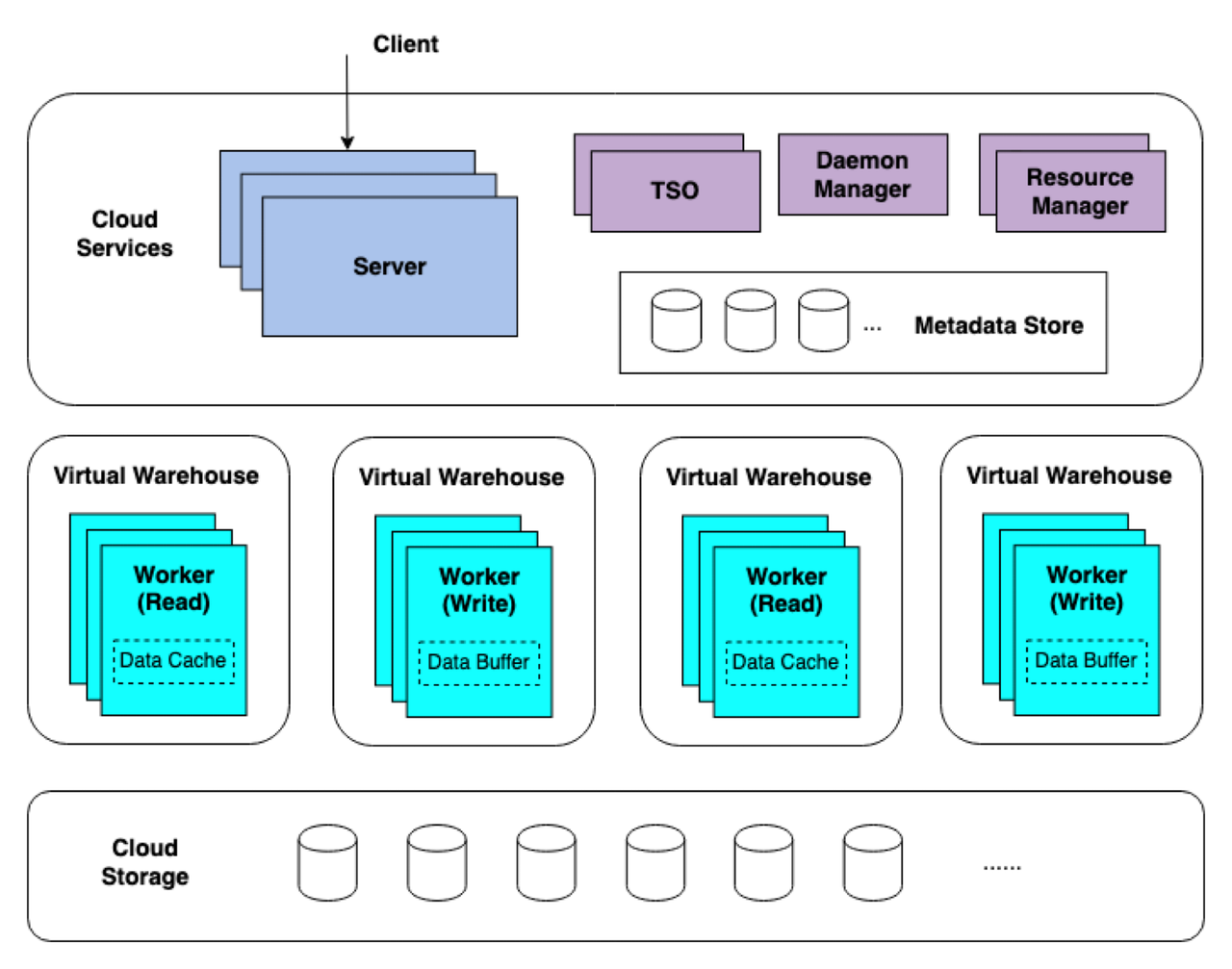
图 1 ByConity 三层技术架构
ByConity 如何在 Kubernetes 上部署和操作
Kubernetes 是一个开源的容器编排平台,可以自动管理和部署容器化应用程序,并提供高可用性和弹性的部署模式。将 ByConity 部署在 Kubernetes 上,可以享受 Kubernetes 提供的可伸缩性、高可用性、负载均衡、容错性等,同时简化管理和部署的过程。下面将给大家详细介绍下,如何在 Kubernetes 上部署 ByConity。
硬件配置:
用户需要部署和购买自己的 Kubernetes 集群,且要求在不影响测试性能前提下的最低硬件配置如下表:
同时,我们也给出一个生产环境下建议的硬件配置,供大家参考:
工具安装:
本地安装 Kubernetes 命令行工具 kubectl,用于管理 Kubernetes 集群
本地安装用于管理 Kubernetes 应用程序的包管理工具 helm
本地安装 byconity-deploy 代码:
配置存储
为了获得最佳的 TCO(https://en.wikipedia.org/wiki/Total_cost_of_ownership) 和性能,本地存储最好与 ByConity Server 和 Worker 一起使用。
ByConity Server 和 Worker 的存储仅用于磁盘缓存,可以随时删除它们。
您可以使用 OpenEBS local PV (https://openebs.io/docs/concepts/localpv)等存储.
配置 helm
可以从安装的 byconity-deploy 的目录复制./chart/byconity/values.yml 文件,并进行修改适配,需要修改的地方如下:
storageClassName
timezone
replicas for server/worker
hdfs storage request
部署 ByConity 集群
等待 Pod 启动:
完成部署,启动 client:
测试 ByConity 集群
执行一些 SQL 语句测试:
手动更新 ByConity 集群
这里举例说明如何增加新的计算组(Virtual Warehouse),假如用户希望增加两个计算组,5 个副本用户读取(my-new-vw-default )2 个副本用户写入(my-new-vw-write )。
更新用户的 values.yaml 文件
使用新的 value.yml 文件,执行 helm upgrade
在 Byconity 中运行执行 DDL 语句
CREATE WAREHOUSE创建新的计算组
测试新的计算组
在 Kubernetes 上无感扩缩容
无感扩缩容是指在系统运行过程中,通过动态调整计算和存储资源的分配,以满足业务需求,同时不影响系统的正常运行和服务质量的一种扩容方式。无感扩缩容的目的是为了提高系统的可用性和可靠性,同时降低系统维护和运营的成本。下面介绍下如何利用 Kubernetes 对 ByConity 集群进行无感扩缩容:
部署 ByConity 集群:利用上面步骤在用户的 Kubernetes 集群上部署 ByConity
设定负载阈值:用户需要设定负载阈值,即当 ByConity 集群负载达到一定程度时需要进行扩容操作。可以通过 Kubernetes Horizontal Pod Autoscaler(HPA)对象进行设定,设置 CPU 使用率或内存使用率等指标作为负载阈值。例如,可以设置当 ByConity 集群的 CPU 使用率达到 80%时,自动进行扩容操作。
自动触发扩容:当 ByConity 集群负载达到设定的负载阈值时,Kubernetes HPA 会自动触发扩容操作,增加 ByConity 节点数量以满足业务需求。例如,当 ByConity 集群的 CPU 使用率达到 80%时,Kubernetes HPA 会自动增加节点数量,保证 ByConity 集群的性能和可用性。Kubernetes 会根据预设的规则和算法,自动增加或减少节点数量,并调整负载均衡策略,以保证系统的高性能和高可用性。
动态调整资源:Kubernetes 会根据实际负载情况,动态调整计算和存储资源的分配,以保证系统的高性能和高可用性。Kubernetes 会自动将负载均衡地分配到不同的 ByConity 节点上,同时保证数据的一致性和可靠性。
实时监控和报警:可以通过 Prometheus 等监控工具,实时监控 ByConity 集群负载和资源使用情况,当出现异常情况时会自动触发报警机制,通知管理员进行处理。
总结
总之,将 ByConity 部署在 Kubernetes 上,可以享受 Kubernetes 提供的可伸缩性、高可用性、负载均衡、容错性等,同时简化管理和部署的过程,同时 ByConity 可以利用 Kubernetes 进行无感扩缩容对用户带来的价值包括:
提高系统的可用性和可靠性:无感扩缩容可以根据实际负载情况动态调整计算和存储资源的分配,保证系统始终能够满足业务需求,避免因系统资源不足而导致的系统宕机或服务中断。
提高系统的灵活性和可扩展性:无感扩缩容可以根据业务需求动态地增加或减少计算或存储资源,不需要进行系统停机或重启,从而提高了系统的灵活性和可扩展性。
降低系统维护和运营成本:无感扩缩容可以自动调整系统资源,减少了系统管理员和运营人员的工作量,降低了系统维护和运营的成本。
同时 ByConity 也提供多种其他部署方式,欢迎社区开发者使用,并给我们提 issue:
单机版本方式:https://github.com/ByConity/byconity-docker
物理机部署模式:https://github.com/ByConity/ByConity/tree/master/packages
源代码编译方式: https://github.com/ByConity/ByConity#build-byconity
加入我们
ByConity 社区拥有大量的用户,同时是一个非常开放的社区,我们邀请大家和我们一起讨论共建,在 Github 上建立了 issue:https://github.com/ByConity/ByConity/issues/26。
延伸阅读:
字节跳动开源ByConity:基于ClickHouse的存算分离架构云原生数仓
ByConity与主流开源OLAP引擎(Clickhouse、Doris、Presto)性能对比分析

分布式云行业实践指南(2023)
业内首个分布式云行业实践方法论、工具箱。







评论