
重点概述
数据分片是指将数据拆分到多台计算机上,可以是水平分片,也可以是垂直分片;数据分区是指将数据拆分为不同的数据子集,但都保存在单个数据库实例中。
Database Plus 概念用于创建分布式数据库系统,其含义并不仅仅局限于分片,定位也在数据库管理系统之上。
作为分布式数据库中间件,Apache ShardingSphere 为解决数据分片问题而生,并支持数据加密、影子库、分布式系统认证和分布式治理等功能。
ShardingSphere 架构包括四层, 即基础层、存储层、功能层及解决方案层。
ShardingSphere 还持 DistSQL(全称:Distributed SQL),这种 SQL 方言被用于操作和管理 ShardingSphere 的所有功能。
当下,手机和互联网已经成为人们的日常工作和生活的必需品,每时每刻都在产生巨量的数据。对于网站和商业服务而言,每周拥有数十亿级别的访问体量并不罕见——当然,这还只是冰山一角。
例如北美的『黑色星期五』和国内的『11.11』等购物狂欢节,则是传统零售业适应数字化世界的绝佳案例。正如零售行业的转型一样,如今的传统企业必须学会从容应对新的需求和挑战,才能成功实现其商业目标。
因此,传统企业必须想清楚一个问题,即在特定节日举办线上促销活动,往往会汇聚难以想象的流量到达数据库集群。这对企业的数据库性能带来了极大的考验,能否在段时间内处理掉这些巨量数据,将是直接决定这次线上促销活动的关键因素。
谈到数据库解决方案,不同的商业案例有不同的选择,包括从 NoSQL 产品(如 MongoDB 、 Cassandra 、 Amazon DynamoDB 等),到 NewSQL 产品( 如最近流行的Amazon Aurora 或 CockroachDB )。但除了这些优秀的解决方案外,一些行业也会考虑在现有数据库集群的基础上进行面向业务的透明化分片操作。根据 DB-Engines 发布的数据库流行趋势排名来看,尽管许多新型数据库产品正在冲击全球数据库市场,但传统关系型数据库仍然占据着相当大的市场份额。
考虑到数据库所面临的新挑战,我们认为,通过新的实用理念,以一种高效且低成本的方式来优化各类数据库的使用体验,增强现有数据库的性能,数据库透明化分片是最佳答案之一。
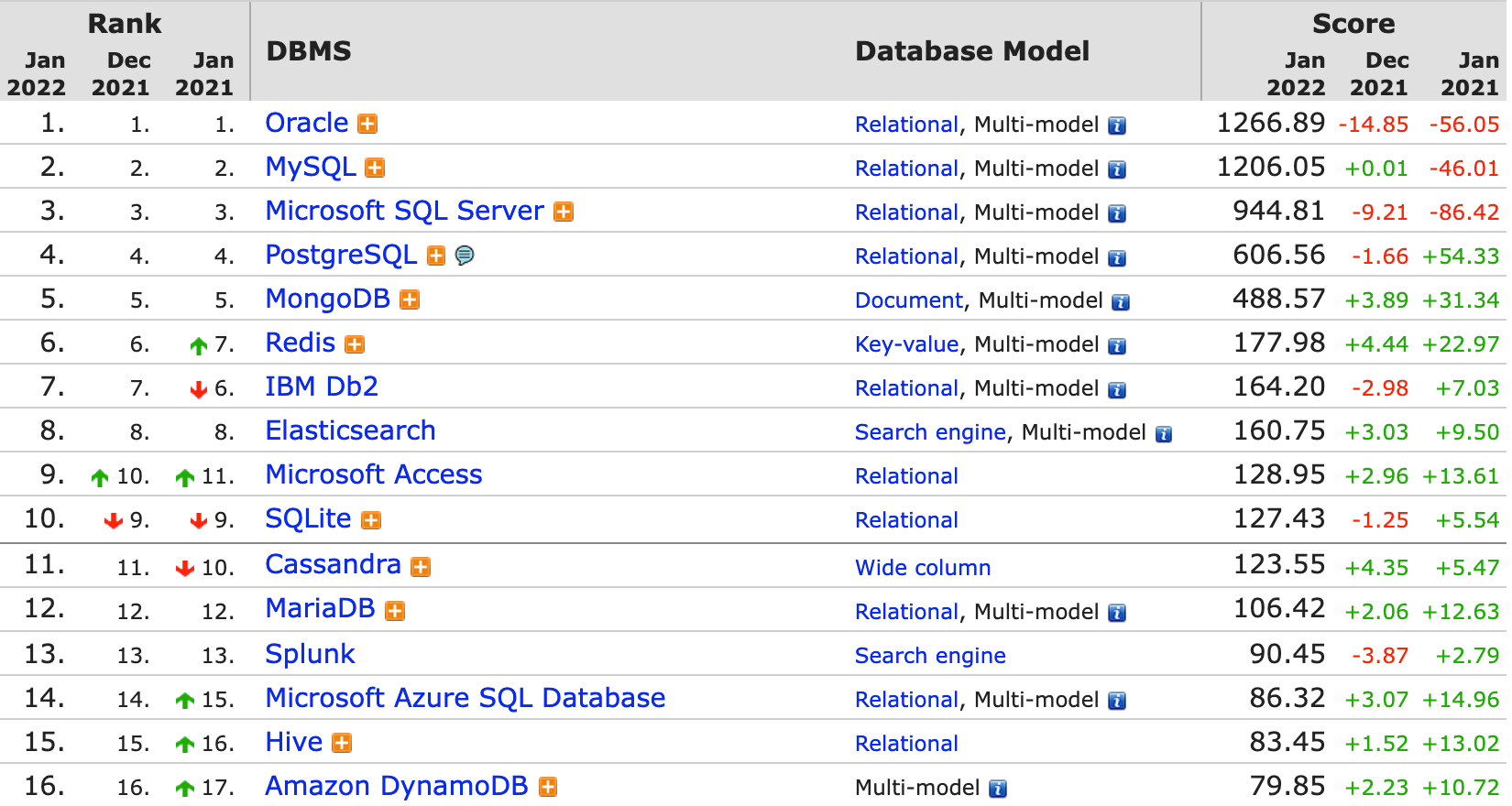
DB-Engines 发布的数据库流行趋势排名
说到这个话题,联想到的最佳技术之一就是将数据分成独立的行和列。这种将大型数据库表分成多个小表的做法被称为分片,根据技术实现的不同,可以被分为垂直分片和水平分片两种。标记这些表的术语可以主观地定义为“VS1”代表垂直分片,“HS1”代表水平分片, “1” 代表第一个表或第一个对象集合,以此类推。这些数据子集被称为该表的原集。
分片和分区的区别是什么?分片和分区都是将大型数据集分解成较小的数据集,但两者区别的关键在于,分片意味着数据分布在多台计算机上,无论水平分片还是垂直分片。而分区则是指数据库被分成不同的子集,但保存在一个数据库中,也被称为数据库实例。
由于数据分片是将数据切开并存储在不同的机器下,因此其具有以下优点:
可使多个独立的数据库管理系统成为分布式系统
扩展数据库系统的存储容量
流量均匀分布在不同分片上
高可用
然而,分片架构并不完美,也具有以下问题:
具有复杂的路由/查询拓扑
使分布式数据库集群管理复杂化
查询开销相对较大
不完全支持所有本地 SQL。在已有的分布式数据库系统上采用分片架构还可能会导致 SQL 兼容性问题。新创建的分片数据库后,此前运行良好的 SQL 有可能无法运行。
分片:从一到多
绝大多数情况下,无论技术领域还是生活中,能够适应各种场合的“银弹”解决方案是不存在的。因此应在全面分析的基础上,完全了解需求和场景后才能做出最佳选择。
一般来说,分片架构的优势是大于其劣势的。数据库行业中,许多优秀产品都采用的分片架构,比如 Citus或 Vitess 。虽有在架构层面上有各自的定义,但其在本质上都是基于数据库分片架构。
Citus 通过管理协调器(代理)集群来分布 PostgreSQL 集群,而 Vitess 则对 MySQL 进行分片,Citus 和 Vitess 都专注于为传统但被广泛应用的关系型数据库提供高效且低成本的分布式解决方案。实际上,分片架构也是大多数 NoSQL 和 NewSQL 产品的基础,不过,这就是另一个关于 NoSQL 和 NewSQL 的分片话题。本文重点讨论关系型数据库的分片以及经典分片技术的创新。
数据分片的起因在于数据库对分布式需求越来越高。随着业务的发展,越来越多与数据库相关配套的服务能力开始引起企业的关注,如隐私保护、SQL 审计、租户、分布式认证等。这些能力无一例外都反映出现实世界对数据库的新需求。如何处理这些新需求是所有不同类型的数据库产品不可避免要回答的问题。那,这些问题是否可以通过数据库分片解决方案来解决?
分片似乎需要进一步发展才能应对这些挑战,而这就是本文的主题:数据库分片架构的下一代演进发展,将迈向何方?
我的答案是将 Database Plus 作为创建分布式数据库系统的指导性概念,其不仅仅是面向分片,更是定位在数据库系统层面之上。
Database Plus 构想是一种分布式数据库系统的设计理念,在已经呈现出碎片化趋势的数据库之上建立使用和交互的标准层与生态层,在数据库之上构建全新的连接关系。通过提供统一标准化的数据库使用规范,Database Plus 理念可面向上层应用提供无感知的数据增强服务,是所有应用和数据库之间的交互直接面向 Database Plus 所构建的标准层,从而屏蔽数据库碎片化对上层业务带来的差异化影响。最终形成一个生态环境,其中的应用程序只需要与标准化服务对话,而非为不同数据库提供不同的服务。
这个想法是由 Apache ShardingSpherePMC 提出,在历经一年左右时间发布的 5.0.0 GA 版本中在架构层实现了 Database Plus 理念。
早在 3.x 和 4.x 发布阶段,Apache ShardingSphere 就被定义为分布式数据库中间件(分片架构),只用于解决分片问题。但随着社区的发展,越来越多开发者的加入,Apache ShardingSphere 已局限于分片领域,数据加密、影子库、分布式认证、分布式治理等众多功能的上线正在将 Apache ShardingSphere 推向解决数据库行业新挑战的最前沿。这些功能的变化无一例外都超出了传统分片概念的范畴,所以,分片只是 Database Plus 的其中一部分。
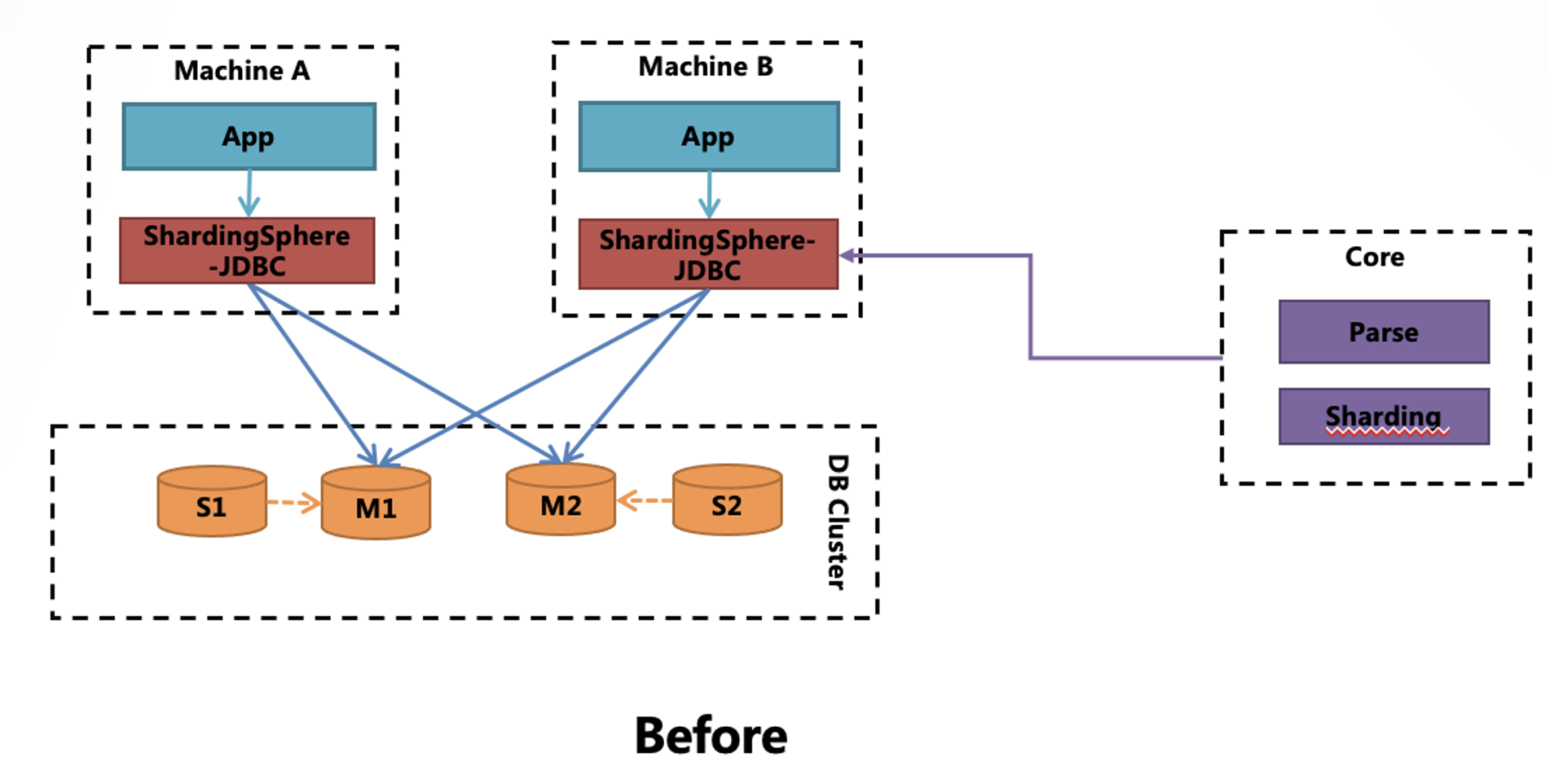
Apache ShardingSphere 的 Database Plus 架构演变之路
Apache ShardingSphere 作为案例支持了我的论点:简单而经典的分片架构,其潜力和所能实现的可能将会大大超出预期。其内核机制通过代理或驱动程序引导所有流量,然后通过解析 SQL 并定位每个数据库的位置,它就能轻而易举地执行以下任务:
理解用户的数据期望
劫持并修改流量
将修改后的查询重新路由到某个数据库
合并或修改某一个结果的元数据和数据
监控计算节点(代理)和存储节点(数据库)的状态
收集分布式系统的变化或常规信息
使用机器学习(Machine Learning)技术提供定制化建议
正是基于这些内核作业,Apache ShardingSphere 的产品才能解决用户面临的数据库产品痛点。
从最初的分片功能到数据加密 、影子库 、分布式认证、分布式治理等都是基于以上的必要步骤。Apache ShardingSphere 的架构基于 Database Plus 概念,所有的功能都以插件形式呈现,在这个分布式系统中用户可根据自身需要随时添加或删除功能插件,因此这些增强功能具有极强的灵活性。有些用户可能只想使用数据库分片功能,而有些用户可能只需要数据加密。用户需求是多种多样且从未停止变化的,为此,Database Plus 可以完全面向用户定制,并不断开发新的插件(功能),使其能够具体灵活地逐一满足用户的不同需求。
架构
ShardingSphere 的四层架构如下图 1 所示:
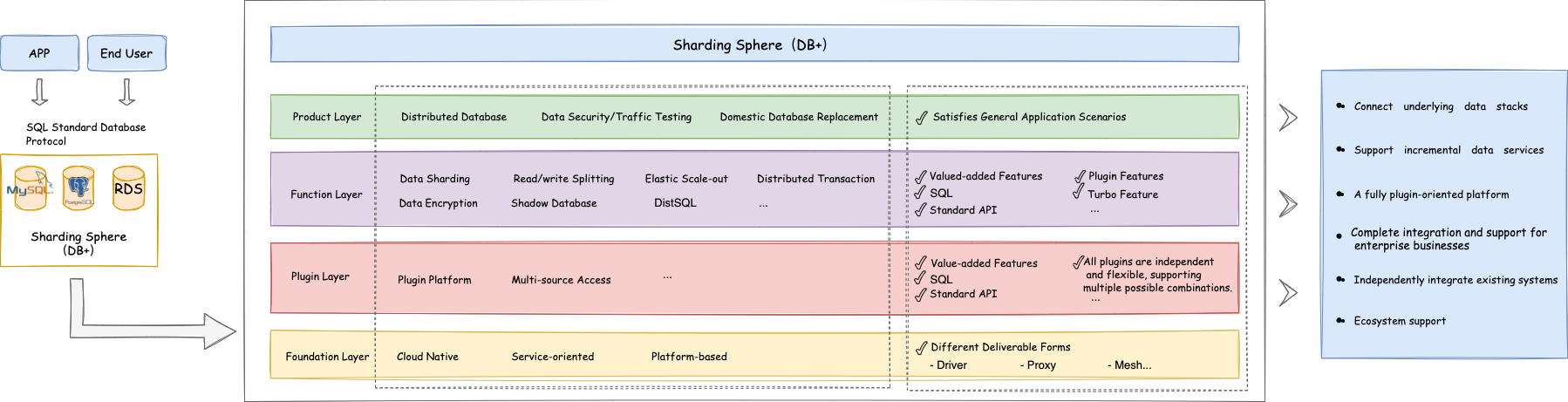
ShardingSphere 的四层架构
基础层: 提供驱动或代理等多种接入端,灵活地满足用户在不同场景下的需求。
存储层:支持所有数据库功能,并有可能支持更多的功能。
功能层:提供各种满足用户需求的功能插件,用户可高度灵活地选择和组合插件。
解决方案层:为终端用户提供面向具体行业(包括金融、电子商务和娱乐等)和面向特定场景的标准化产品解决方案(如分布式数据库解决方案、数据库加密解决方案或数据库网关解决方案)。
多接入端混合模式生产可用
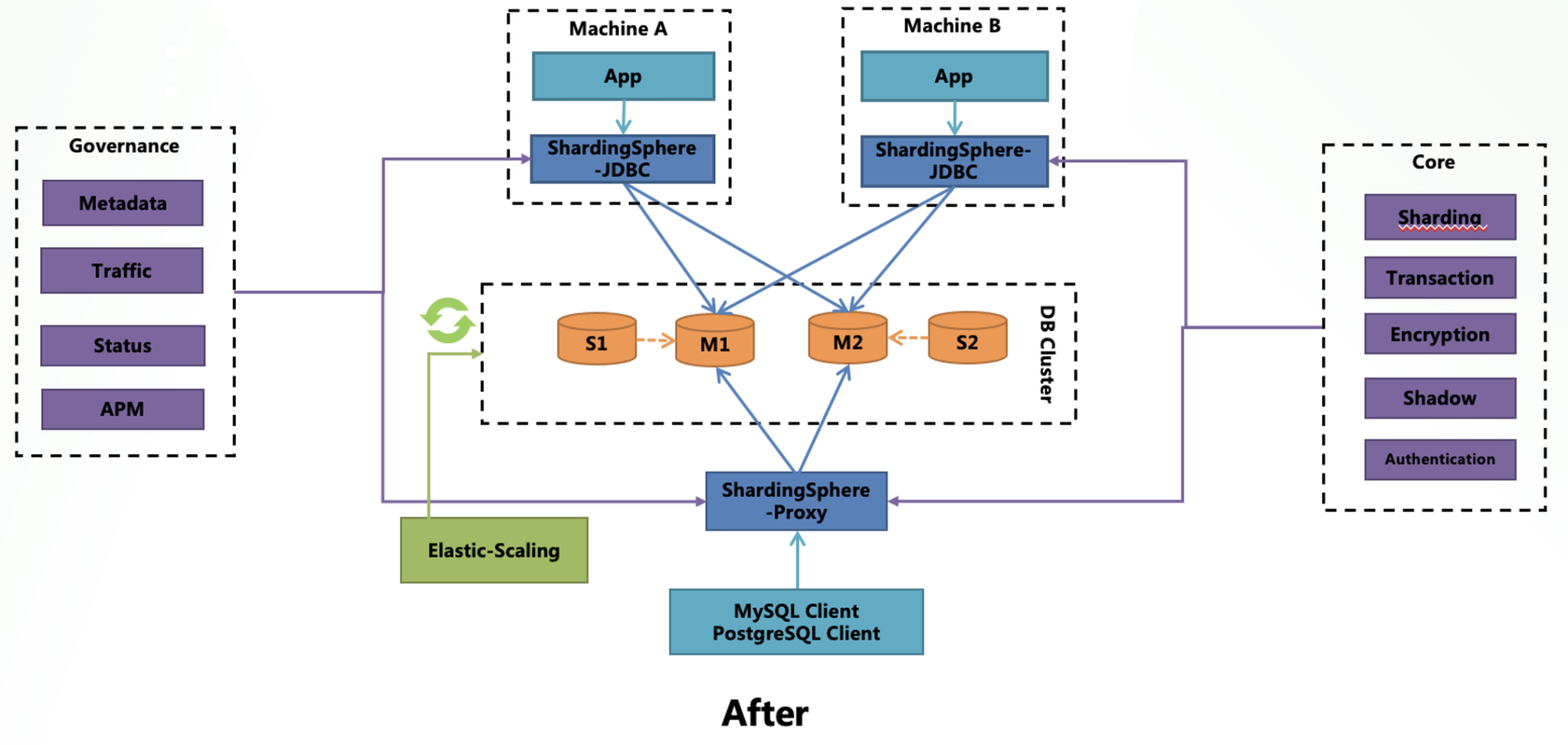
ShardingSphere-JDBC 和 ShardingSphere-Proxy 经过五年的打磨和测试,目前已经可以投入生产使用,很多社区用户已提供了相关的用户案例,其可行性也已经得到了验证。
不同 ShardingSphere 客户端之间可共享核心功能,因此用户可以选择混合部署模式,平衡查询性能和管理便利性(如下图 2 所示)。
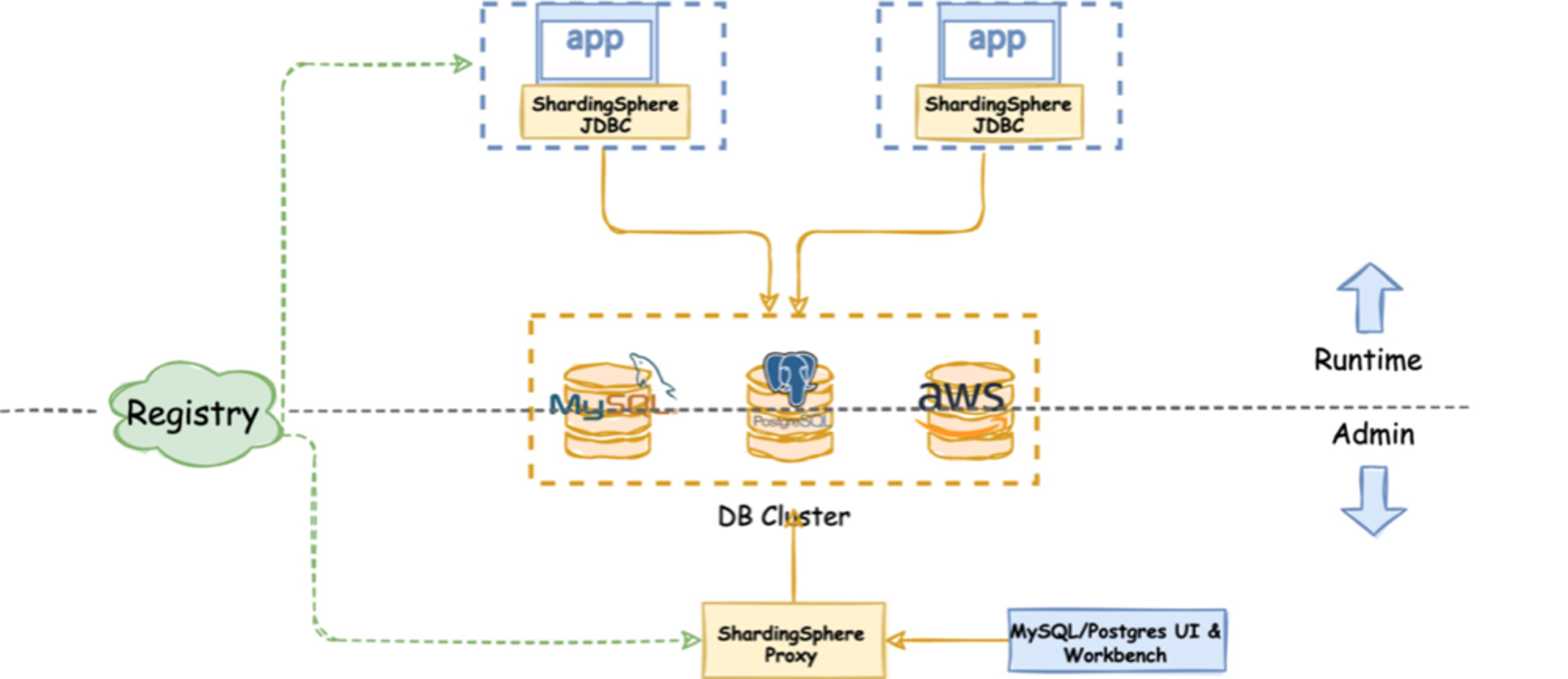
ShardingSphere-JDBC 和 ShardingSphere-Proxy 的混合部署
DistSQL 用于标准化集群管理
Apache ShardingSphere 社区实现了一种新的 SQL 方言,即 DistSQL (全称为 Distributed SQL),用于操作管理 ShardingSphere 的所有功能。
SQL 是与数据库交互的传统标准方法。然而,在分布式数据库系统中有许多新的功能驱动我们创造出一种 SQL 方言来配置和使用这些新功能。
DistSQL 允许用户使用类似 SQL 的命令来创建、修改或删除分布式数据库和表,或者对数据进行加解密,此外包括上文提到的所有功能都可以用 DistSQL 来进行。
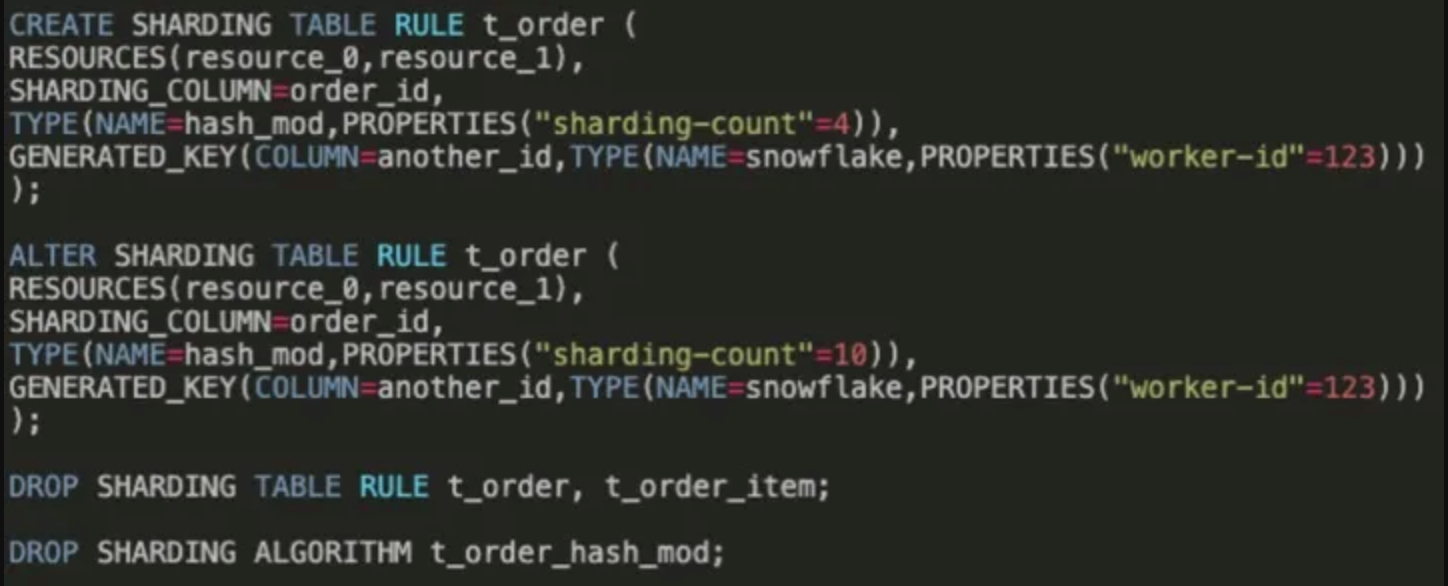
使用中的 DistSQL
分布式治理能力
分布式数据库系统治理能力是减轻分布式集群管理难题的必要条件。在计算和存储分离的 ShardingSphere 生态系统中,在 5.0 新版本中对分布式治理能力进行了极大增强:
数据库(即存储节点)和 Proxy/JDBC(即计算节点)的分布式治理
在线用户元数据 DDL 变更
开/关运行中的存储节点和计算节点
熔断及停用
高可用
此外,计划中的新功能分布式也将在近期发布。
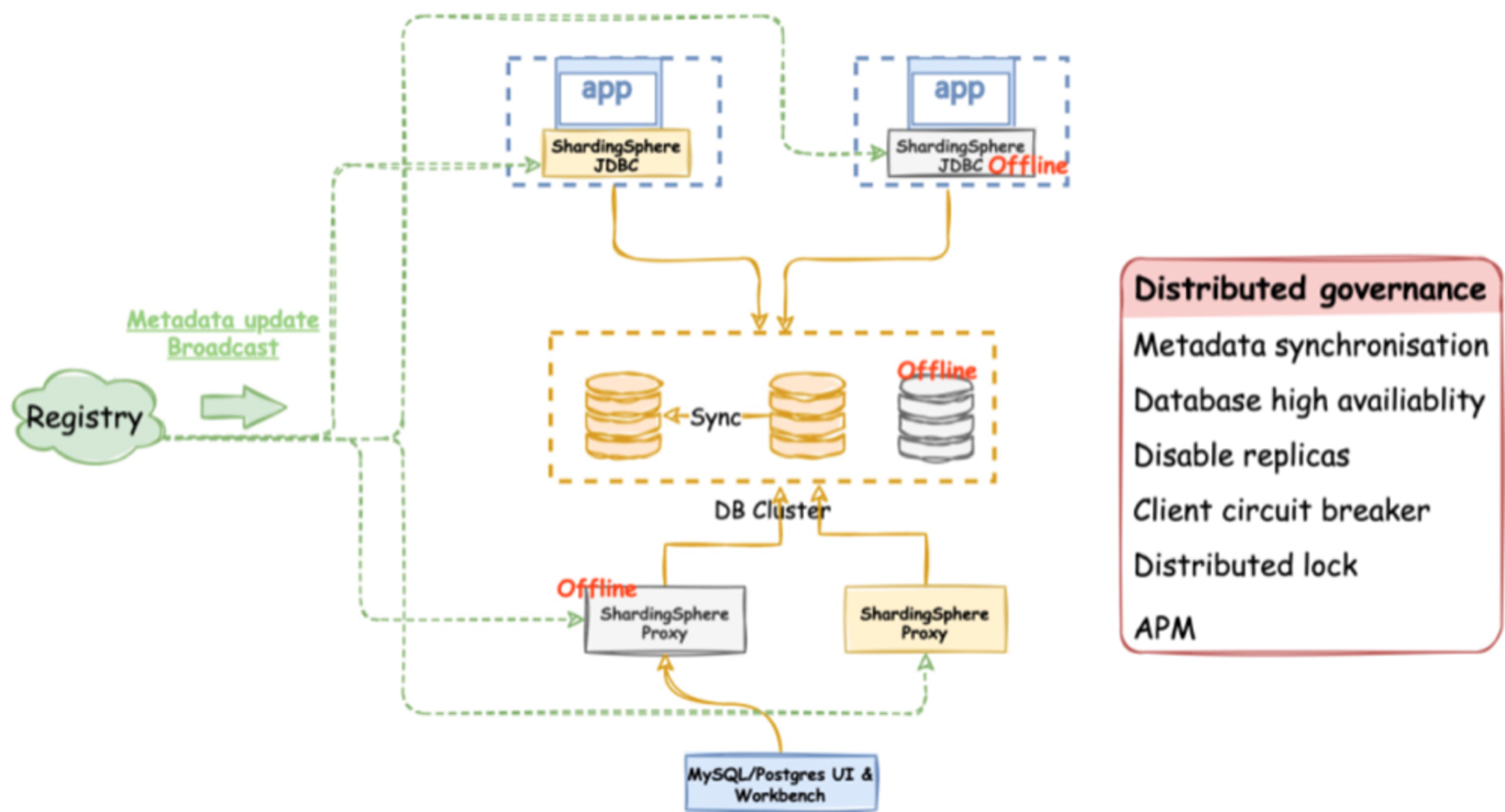
ShardingSphere 的分布式治理
部署注意事项
虽然上面列举了许多 Apache ShardingSphere 的优点,但是也有一些限制需要提前考虑。在部署 ShardingSphere 之前,请仔细考虑以下事项:
一些复杂的本地 SQL,特别是关联不同分片的 SQL 语句,在执行可能存在耗时长、成本高等相关问题。所以建议采用面向业务的分片策略来预防这类情况的发生,避免处理过于的复杂 SQL。
Proxy 模式会产生更多地网络资源开销,因此官方更推荐使用 混合模式部署 。
分布式事务会大大降低 TPS 或 QPS。
在分片之间获得一致的时间点快照是很有挑战性的。
实际案例
本节将提供两个实际案例,演示如何用可连接 ShardingSphere 生态中一切元素的 DistSQL 创建一个分布式数据库和加密表。
分布式数据库解决方案
这一部分将通过案例演示如何利用 DistSQL 来创建一个分布式数据库。用户和应用程序可访问 Proxy 来创建逻辑表(即分布式表),该表已经在不同的服务器之间被分片,用户没有必要关注这些分片,应用程序会自动操作管理该逻辑表。
前提条件:
部署 MySQL 实例并创建两个 MySQL 数据库
部署 ShardingSphere Proxy
过程:
登录代理 CLI 需执行此 SQL 命令:
mysql -h127.0.0.1 -uroot -P3307 -proot
使用 DistSQL 注册两个 MySQL 数据库。
ADD RESOURCE ds_0( HOST=127.0.0.1, PORT=3306, DB=demo_ds_0, USER=root, PASSWORD=root );
ADD RESOURCE ds_1 ( HOST=127.0.0.1, PORT=3306, DB=demo_ds_1, USER=root, PASSWORD=root );

使用 DistSQL 创建分片规则
CREATE SHARDING TABLE RULE t_order( RESOURCES(ds_0,ds_1), SHARDING_COLUMN=order_id, TYPE(NAME=hash_mod,PROPERTIES("sharding-count"=4)), GENERATED_KEY(COLUMN=order_id,TYPE(NAME=snowflake,PROPERTIES("worker-id"=123))) );

基于前一步的分片规则去创建分片表
CREATE TABLE `t_order` ( `order_id` int NOT NULL, `user_id` int NOT NULL, `status` varchar(45) DEFAULT NULL, PRIMARY KEY (`order_id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;

显示资源、分片数据库及分片表
sql SHOW SCHEMA RESOURCES;
SHOW DATABASES;
SHOW TABLES;
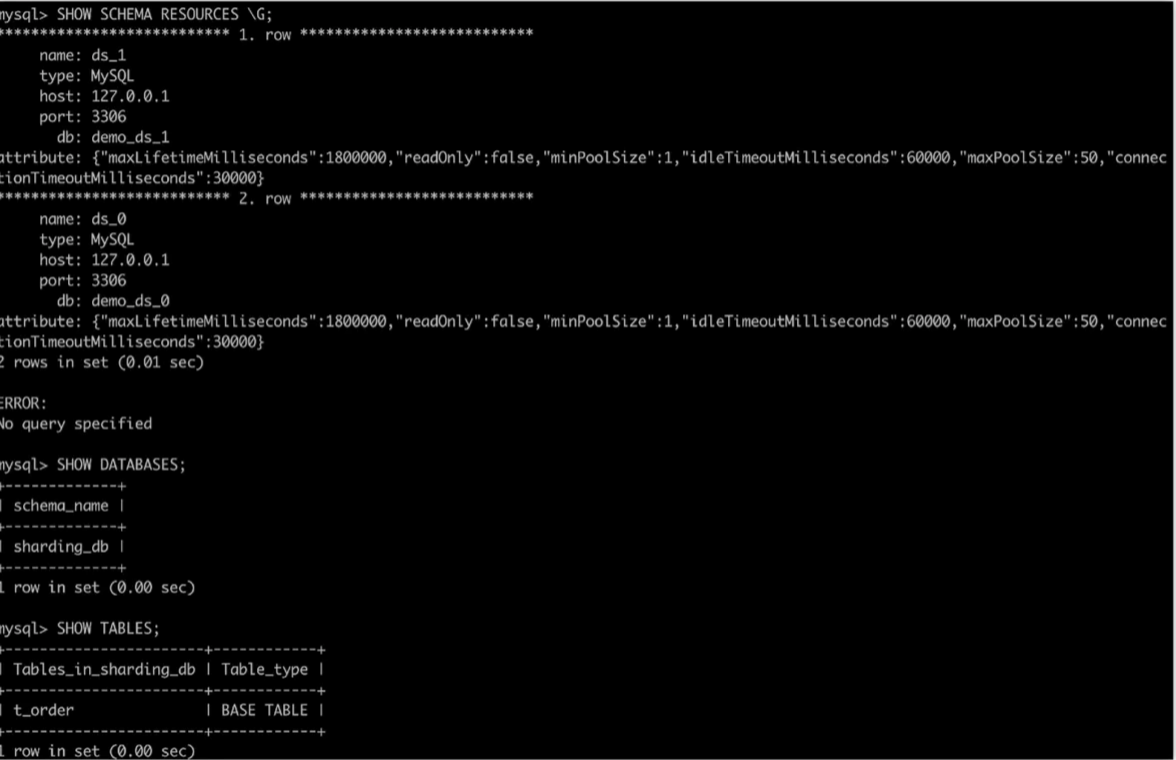
显示分片表
SHOW TABLES;
以下是 MySQL 中的表:
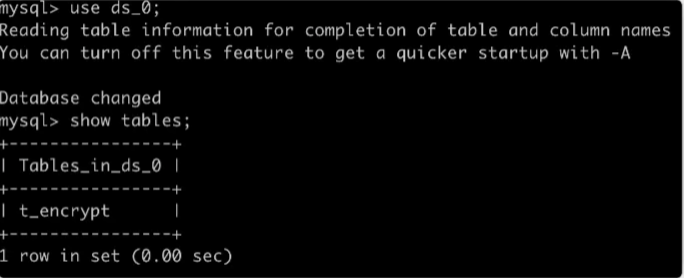
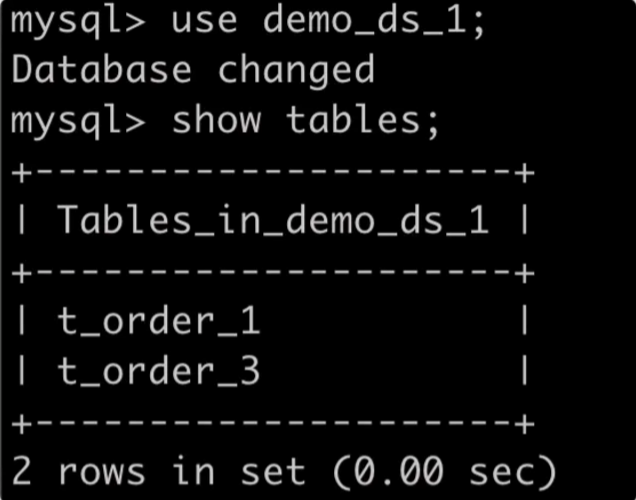
以下是 ShardingSphere-Proxy 中的表:
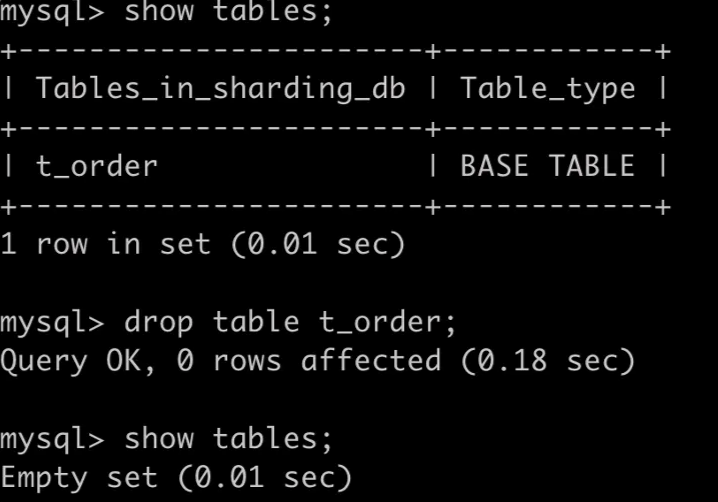
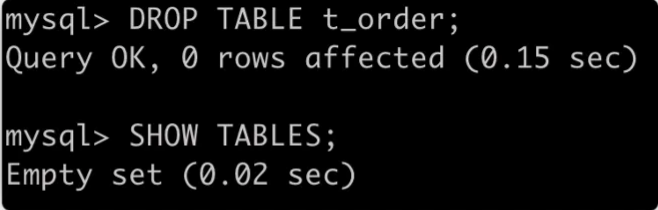
删除分片表
DROP TABLE t_order;
数据加密
这个例子将演示如何用 DistSQL 创建加密表。在 Apache ShardingSphere 中,是通过 ShardingSphere-Proxy 来实现数据加解密的功能,因此应用程序不需要进行任何编码重构,只需将明文发送到 Proxy 端就会被加密,之后 Proxy 端会将加密文本重新发送到数据库中。此外,用户也可自定义配置选择哪张表的哪一列,以及何种加密算法来实现数据加密。
前提条件:
部署 MySQL 实例并创建两个 MySQL 数据库
部署 ShardingSphere-Proxy
过程:
登录 Proxy CLI 需执行以下命令:
mysql -h127.0.0.1 -uroot -P3307 -proot
通过 DistSQL 添加资源。
ADD RESOURCE ds_0 ( HOST=127.0.0.1, PORT=3306, DB=ds_0, USER=root, PASSWORD=root );

创建加密规则。
CREATE ENCRYPT RULE t_encrypt ( COLUMNS( (NAME=user_id,PLAIN=user_plain,CIPHER=user_cipher,TYPE(NAME=AES,PROPERTIES('aes-key-value'='123456abc')))));

SHOW ENCRYPT TABLE RULE t_encrypt;

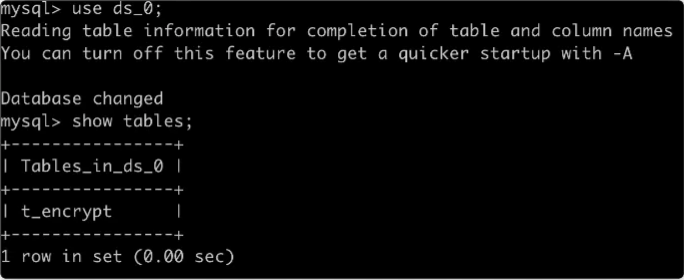
创建加密表
CREATE TABLE `t_encrypt` ( `order_id` int NOT NULL, `user_plain` varchar(45) DEFAULT NULL, `user_cipher` varchar(45) DEFAULT NULL, PRIMARY KEY (`order_id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;

以下是 MySQL 中的结果:
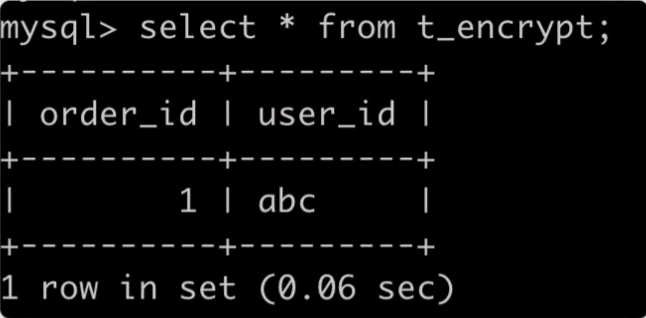
在此表中插入数据:
INSERT INTO `t_encrypt` VALUES(1,"abc");
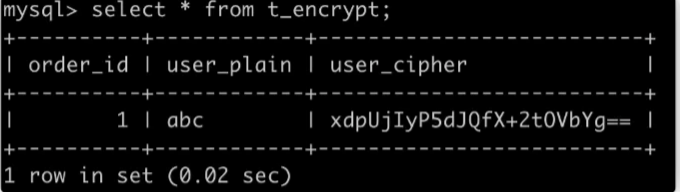
在 MySQL 中实现的内容包括:
修改加密规则
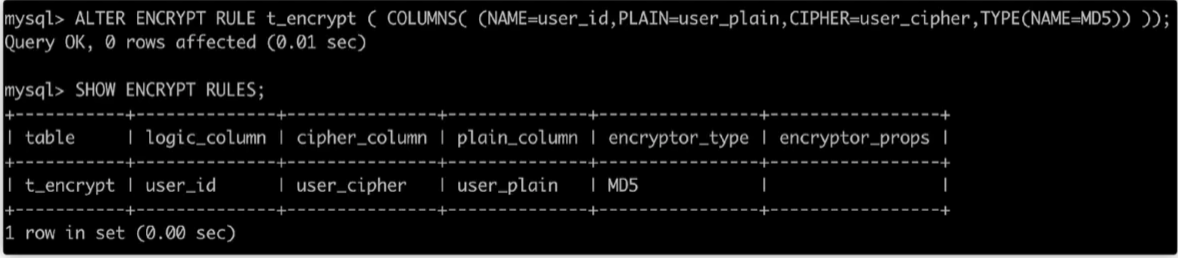
ALTER ENCRYPT RULE t_encrypt ( COLUMNS( (NAME=user_id,PLAIN=user_plain,CIPHER=user_cipher,TYPE(NAME=MD5)) ));
SHOW ENCRYPT RULES;
删除加密规则
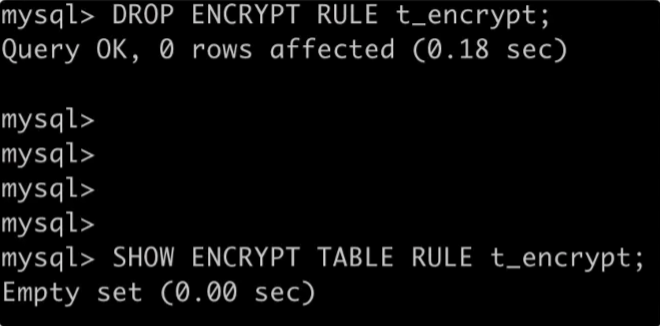
DROP ENCRYPT RULE t_encrypt;
基于 Database Plus 理念,将分片、加密等其它功能部署在数据库之上的生态中,不需对底层数据库做出任何改变,操作和使用成本都较低,对上层用户完全无感知,能够消除用户对底层数据架构不稳定的担忧,进而减轻企业采用全新分布式数据库过程中所带来的沉重负担,是满足用户不断变化的切实有效方法之一。
我作为 Apache ShardingSphere PMC 撰写此文可能会显得有些偏心,但我之所以选择全身心投入到这个开源项目中,是因为它具有极大的创新潜力去应用于各类生产场景中,从而能够解决现实世界数据库领域的相关问题。
纵观过去的职业生涯,在这个世界上互联网普及率最高的社会之一——中国,我一直在管理和利用公司的大数据,因此我很清楚不断调整的生产需求以及海量业务数据带来的挑战,对于当下已有数据库解决方案之间存在的矛盾与距离。
当然我也并没有绝对地说,Database Plus 就是解决云时代所面临新数据挑战的最佳或唯一的方法,但的确可以将其视为一种具有前景的创新解决方案。
最后,我想再分享关于数据分片的看法。分片是解决互联网发展所带来新挑战的众多方法之一,专家们可能会说,数据库分片架构已经过时了,但实际却并非如此。分片架构可能听起来不那么高大上,也没有没有其他解决方案的花里胡哨,但它兼具有效性和实用性的特点是毋庸置疑的。
近期分片架构实现了重大的创新,分片架构的发展超出了以往的想象。也许这就是为什么分片架构在希望实现高度可扩展性的区块链公司中越来越受欢迎的原因。
作者
潘娟 | Trista Pan
SphereEx 联合创始人兼 CTO; AWS Data Hero; Apache ShardingSphere PMC 成员; 中国木兰开源社区导师。曾任京东科技高级 DBA,负责京东数科的智能数据库平台的设计开发,目前专注于分布式数据库和中间件生态系统,以及开源社区运营。致力于开源事业,作为 Apache ShardingSphere 排名第二的贡献者,曾获得 “2020 年中国开源先锋 ” 和 “2021 年中国 OSCAR 开源先锋”荣誉,经常受邀参加数据库及数据库架构领域相关会议并发言分享个人见解。




