

9 月 7 日,云+社区(腾讯云官方开发者社区)主办的技术沙龙——AI 术原理与实践,在上海成功举行。5 位腾讯云技术专家,在现场与开发者们面对面交流,并深度讲解了腾讯云云智天枢人工智能服务平台、OCR、NLP、机器学习、智能对话平台等多个技术领域背后架构设计理念与实践方法。本文内容整理自腾讯云高级研究员尹迪,为大家带来的主题为“智能钛机器学习平台在工业和金融行业的落地”的分享。
在人工智能领域,有一个技术是无论如何也避不开的,那就是机器学习。
腾讯云高级研究员尹迪老师,从工业、金融等行业实践出发,为大家讲解算法人员如何借助智能钛机器学习平台解决用户的实际问题。
本文内容整体分为三部分:
智能钛机器学习平台介绍
机器学习平台在工业面板行业的落地
智能钛机器机器学习平台在金融行业的落地
智能钛机器学习平台介绍

1.什么是智能钛机器学习平台?
智能钛机器学习平台是面向广大开发者的一站式机器学习平台,覆盖了数据预处理、特征工程、模型训练、模型推理、一键部署等机器学习建模全流程功能。包括了传统机器学习算法、时间序列算法、NLP 算法、图处理算法、计算机视觉等。产品既适合于算法新手,也适合于 AI 爱好者和算法专家。产品有私有化部署的版本,所以也适合企业内部机器学习团队在企业内部搭建自己的机器学习平台使用。同时,公有云版本可以支持开设有 AI 课程的院校、算法大赛赞助等工作。
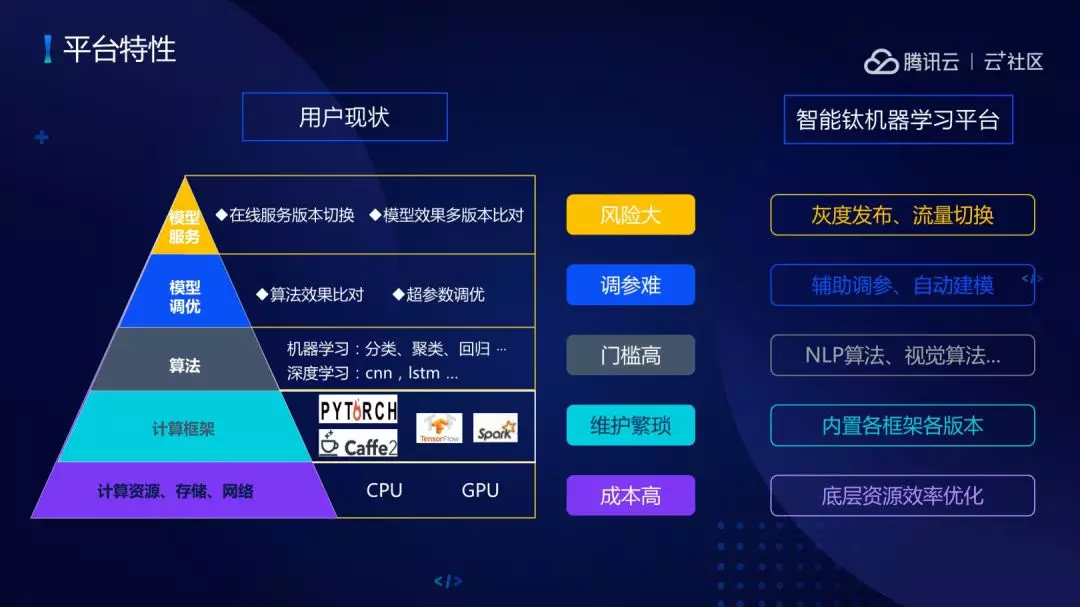
2.对不用我们平台的用户而言需要考虑五方面的问题:
(1)计算资源、存储、网络,如果个人用户管理调度资源和网络的话成本会比较高。
(2)计算框架,做算法建模、场景建模往往需要选择不同的框架、不同的框架版本,这个时候维护是比较烦琐的工作。
(3)算法,做建模工作的首先点就是该选择什么样的算法,其次选择了算法之后怎么样优化算法、改进算法。门槛还是有点高的,特别是改进算法。
(4)模型调优。
(5)模型服务。当我们把场景模型建立好之后,模型上线服务时对在线服务版本进行切换以及模型效果多版本进行对比风险比较大
3.针对风险大、调不参难、门槛高、维护烦琐、成本高智能钛机器学习平台专门进行优化。
我们调用了腾讯内部的资源调度平台 Gaia。通过多模块方式内置各种板块框架,包括了 PYtorch、Caffe2、Spark 等。支持自动调参:半自动支持学习调参、全自动机器学习调参。支持灰度发布、流量切换。
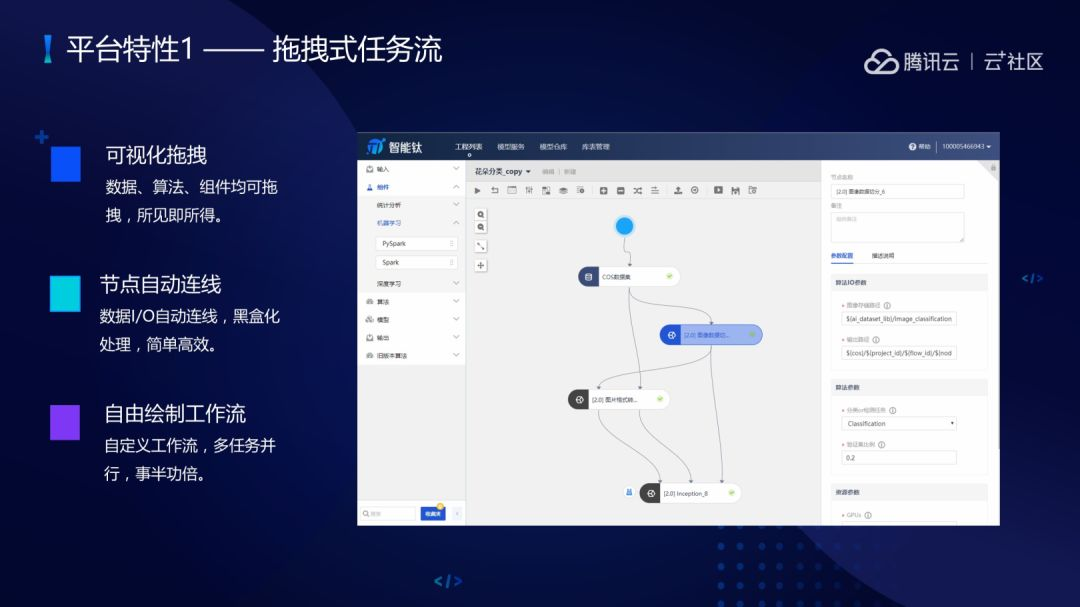
(1)拖拽式任务流,包括算法、内置的组件都可以进行拖拽,所见即所得。数据 I/O 都可以自动连线,人工可以不填。可以自由地定制工作流,多个任务一起运行,事半功备。
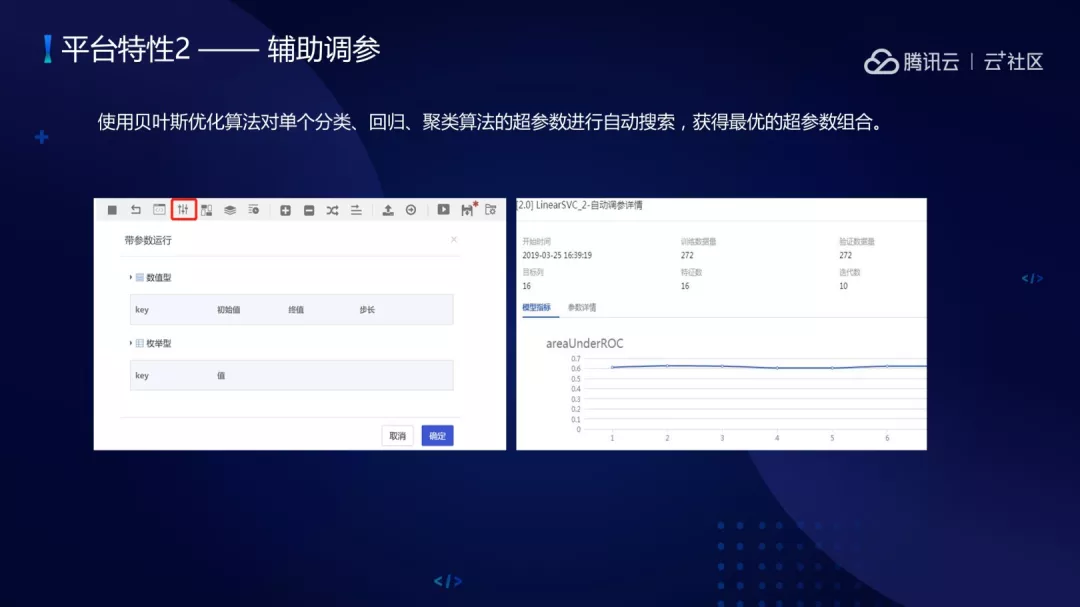
(2)辅助调参,使用贝叶斯优化算法对单个分类、回归、聚类算法的超参数进行自动搜索,获得最优的超参数组合。
自动建模在现在非常火爆,阿里的 Pai 平台使用遗传算法的方式来做,我们的平台虽然是用贝叶斯优化的方式来做,但其实我们还提供了多种方式,包括 Smac、遗传算法等另外的算法来优化。我们做单个算法超参数调优只需要把超参数的范围、可选项进行自动调参,最终得到相对或者最优的结果。
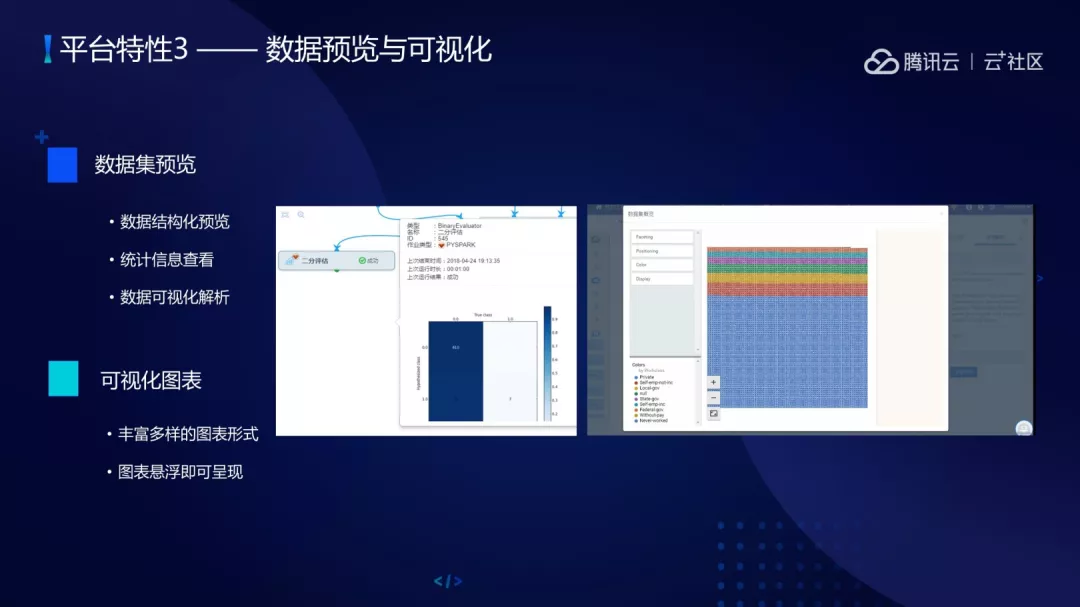
(3)数据预览与可视化。包括结构化数据的预览、统计信息查看、数据可视化解析。也包括丰富的图表形式、图表悬浮功能。
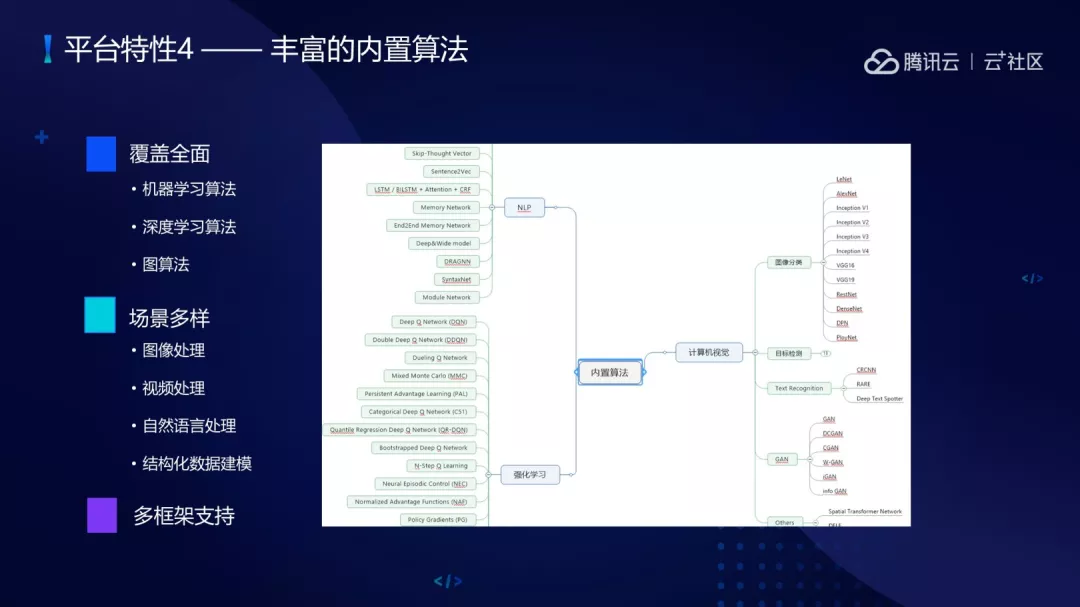
(4)丰富的内置算法。有开源的算法、改进算法、自研算法,主要包含了分布式机器学习、深度学习算法、图算法,图算法是基于腾讯开源的 Angel 框架做的图算法。场景方面主要支持图像处理、视频处理、自然语言处理、结构化数据建模。也支持多种框架,包括 TensorFlow、Pytorch。
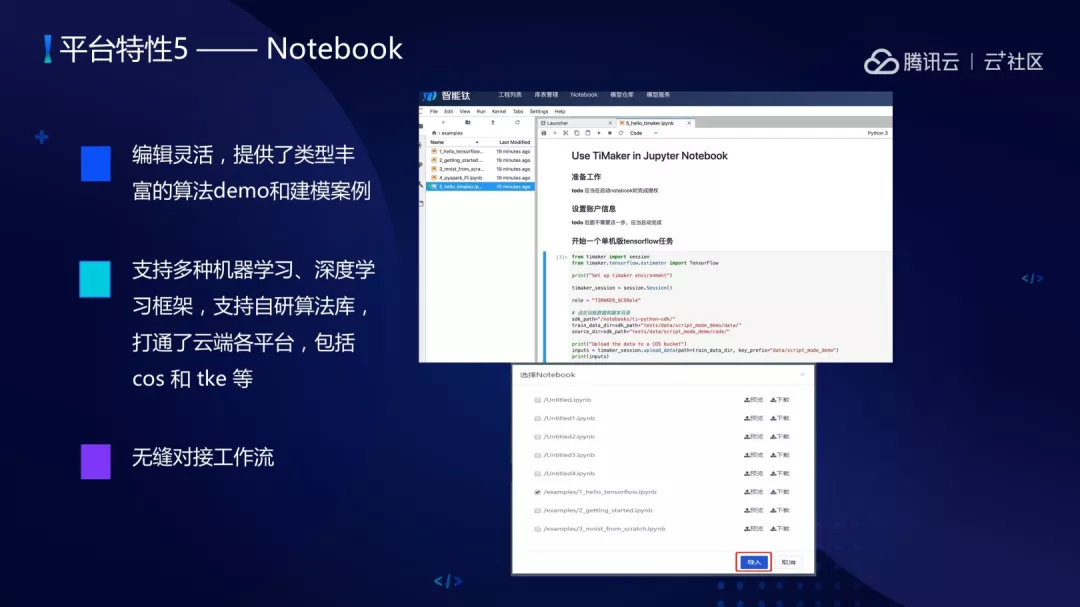
(5)Notebook,内置的 Notebook 编辑比较灵活,提供了非常多的算法 demo 和建模案例,支持多种机器学习、深度学习,包括分类、聚类、回归、图像分类、目标检测等。同时支持多种机器学习、深度学习框架,支持自研 Java 算法库,在云端打通了各个平台,包括 COS 和 TKE。Notebook 里把代码编好之后可以一键导入到平台上作为拖拽式节点进行运行。
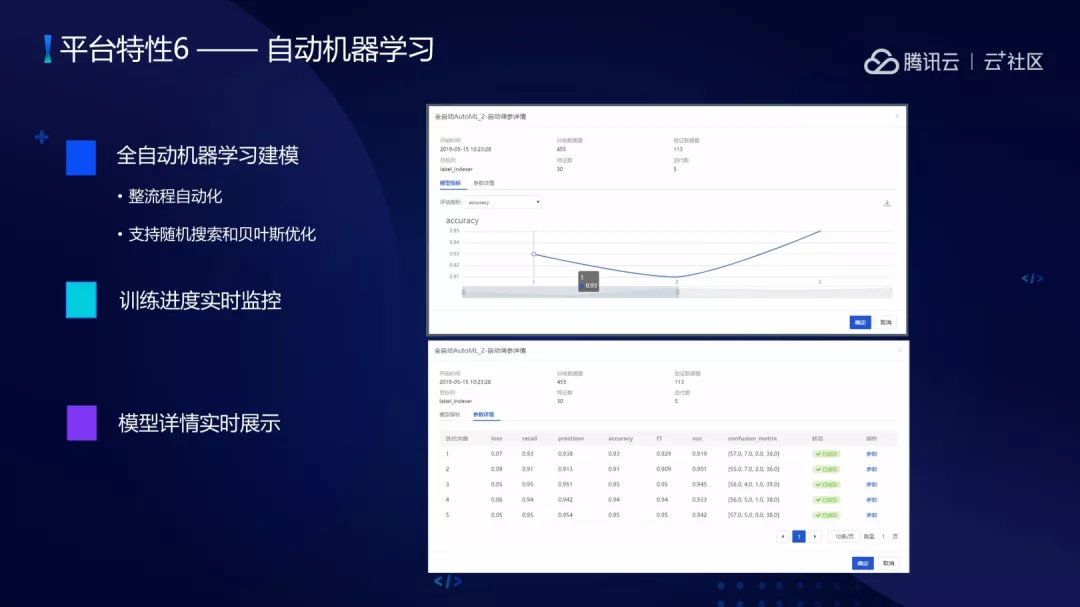
(6)全自动机器学习的过程。对机器学习有数据预处理、特征工程、分类、聚类,pipeline 是整体流程,包含两方面的选择:算法选择、算法超参数的选择。全自动机器学习建模就是数据喂进来之后会对它自动进行算法选择、超参数选择的完全自动化的过程。支持随机搜索、贝叶斯优化和遗传算法。全自动化建模的进度可以实时监控,模型详情可以实时进行展示,同时全自动 Pipeline 流程也可以一键导入到平台上作为可拖拽式的方式进行运行。
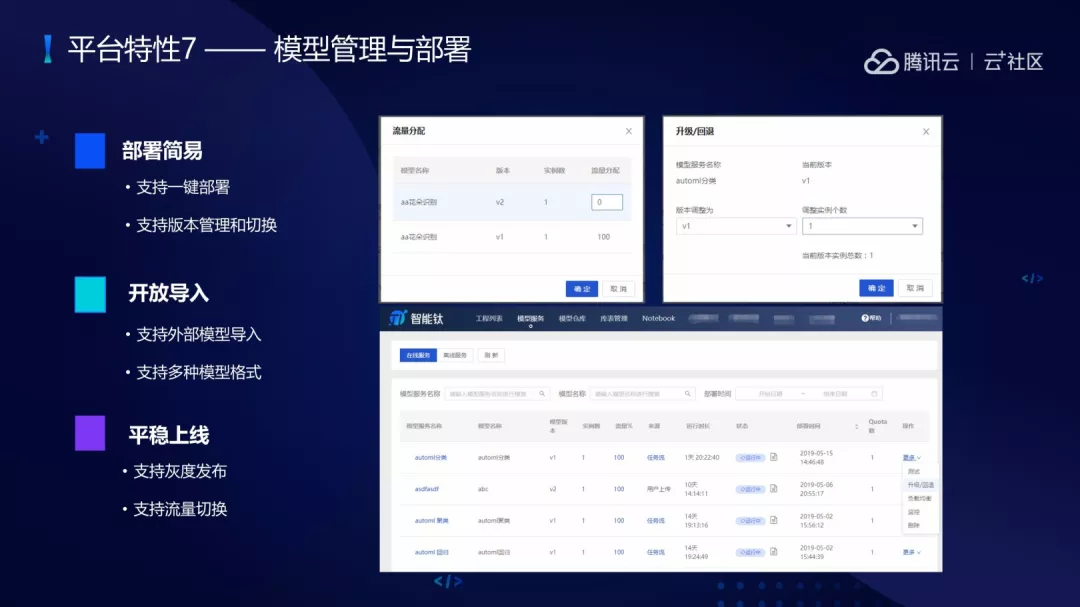
(7)模型管理与部署。如果业务非常多的时候包含的模型会非常多,这个时候对模型进行管理显得特别重要。平台支持多版本不同框架的模型管理,同时支持模型的一键部署,支持部署版本的管理和切换,同时支持外部模型的导入,主要是公共格式的模型导入,像 TensorFlow PB 文件、pmml 文件等。模型上线之后支持灰度发布、流量切换。做 A/B 测试的时候对模型进行 A/B 测试,很多时候需要有流量切换,包括多层次的流量切换。
这是智能钛机器学习平台 TI-ONE 的基础功能,不仅仅包含拖拽式平台,还包含了推理平台,包含了工业界解决方案的产品平台,后面讲工业场景的时候会介绍到另外的产品。

机器学习平台在工业面板行业的落地
下面会讲一下在工业面板行业的落地,主要给面板行业做的工作是针对与华星光电、厦门天马和武汉天马等标杆客户。
面板行业面临的困境比较多,从用户的角度来看生产工程师不会数据分析、数据挖掘、图像处理、目标检测等工作。他们没有机器学习的基础,算法学习门槛比较高。算法工程师有什么缺陷呢?对站点数据不熟悉,对制程的经验不足,数据不理解,没有办法进行相应的分析和建模。从数据的角度来看,面板行业数据维度高,因子杂乱。数据类型种类多、识别困难。在找真实因子和真实原因都是在海量数据中隐藏的,很难找到相应的因素。
像字符型数据包含的信息也很丰富,在一般机器学习建模过程中字符型数据往往会忽略掉类别型重要特征。
实践角度主要有四个点:
该用哪些算法?
个性化案例怎么分析?
如何通过 AI 手段改善生产问题?
如何汇报自己的建模方法,怎么解释是什么原因造成了问题的发生。
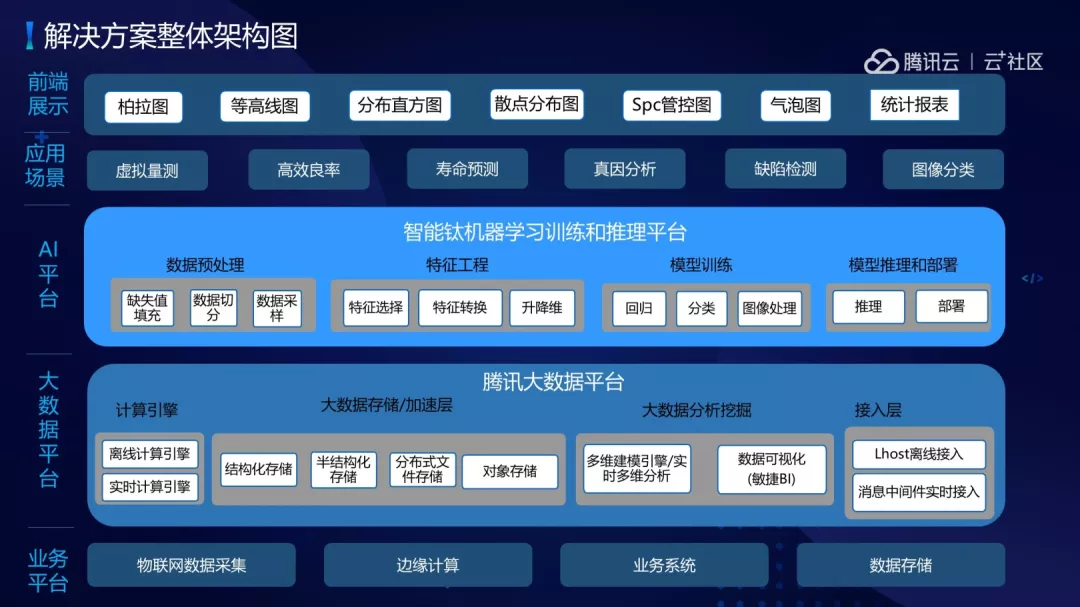
整体解决方案分为五大块:
(1)业务平台,包括物联网数据收集、边缘计算、业务系统、数据存储。
(2)大数据平台,包含了计算引擎、大数据存储/加速层、大数据分析挖掘、消息接入层。
(3)AI 平台,包含了智能钛机器学习训练平台和推理平台,提供了数据预处理、特征工程、模型训练、模型推理和部署工作。
(4)应用场景,有虚拟量测、高效良率、寿命预测、真因分析、缺陷检测、图像分类等。
(5)前端展示,包括伯拉图、等高线图、散点图等。
现阶段用到的包括异常数据检测,包括时间序列数据检测、全特征数据检测、异常图片智能检测。还包括最优路径的搜索,包括良率测算、异常解析。异常解析主要是进行平台追溯,就是出现异常后追溯造成异常的主要原因是什么。
系统自动监控和告警。
(2)提高工作效率,因为解决异常通过系统可以从 6 小时缩短到 1 小时。
(3)提升良率品质,不管做异常检测、数据分析最终的目的就是提高良率,提高产品良品率,主要是通过异常因子分析、图像异常检测等方式达到提高良率的效果。
(4)减少人力投入。
(5)策略参考。
(6)降低失效成本提升效益。
下面进行一个案例分析,背景是传统面板生产线上,由人工进行抽样质量检测,企业会面临诸多挑战。主要有四方面问题:人力成本、人员培训、漏检率高、缺陷错误率高。
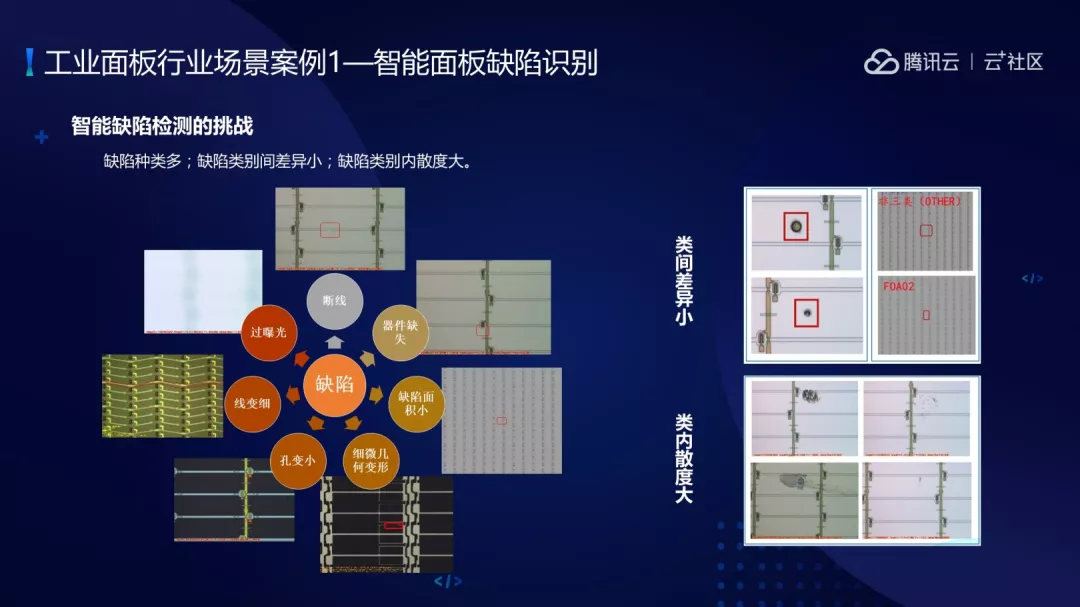
针对缺陷提出来智能面板缺陷的识别方案及方案将人工抽检升级为自动化全检,节省了人力成本,降低了漏检率的同提高了覆盖率。
智能面板推荐识别遇到的挑战主要有三方面:
(1)缺陷种类多,缺陷包含断线缺陷、器件缺失等缺陷。
(2)缺陷类别差距小。
(3)同一种缺陷内部散度大。
刚开始是用目标检测的方法解决问题,主要包括 Faster-RCNN、Mask-RCNN 等技术。但这种技术缺点非常明显,不能解决目标形态多样性的问题。所以我们提出了多阶段建模的方式,第一阶段将图片进行目标分隔,分离之后对缺陷区域做聚类操作,得到主要的缺陷之后把它放在分类网络里,最终判断分类的缺陷种类。
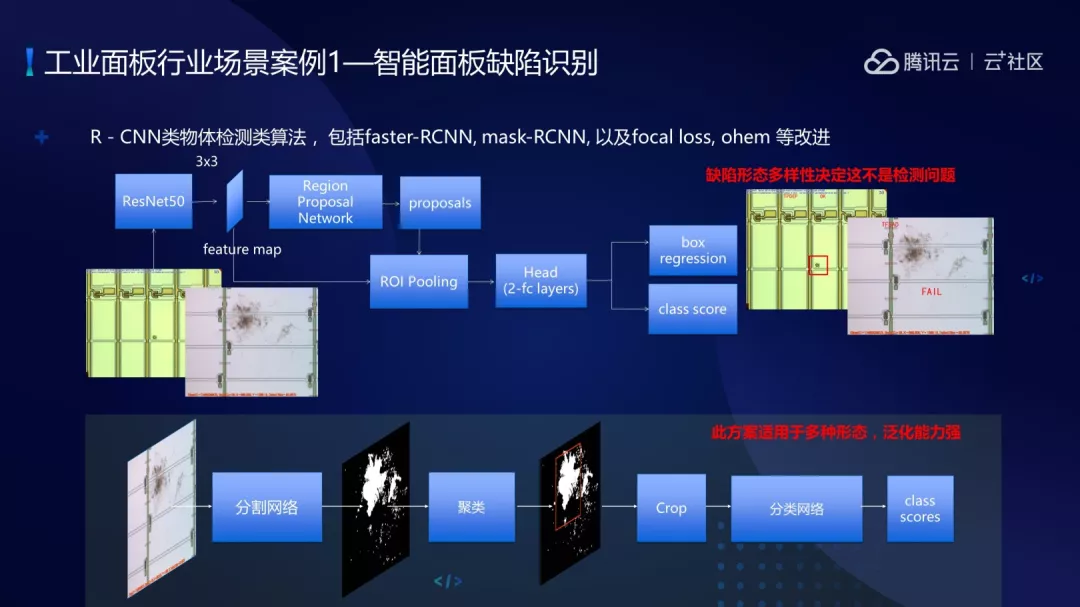
最终的解决方案是包括对过曝光图进行过曝光的检测,进行网络分隔、聚类、最终分类。我们试了很多方法,包括 FCN 等,最终选定的是 Pspnet。
面板行业多因子分析的场景,随着工厂长能提升,得到实时数据量很大,但实时数据并没有得到充分的运用。所以运用多分子分析系统把工厂数据实现智能、快速、准确的分析,挖掘出来关键因子,将相关模型算法内化,提升内部数据分析能力。
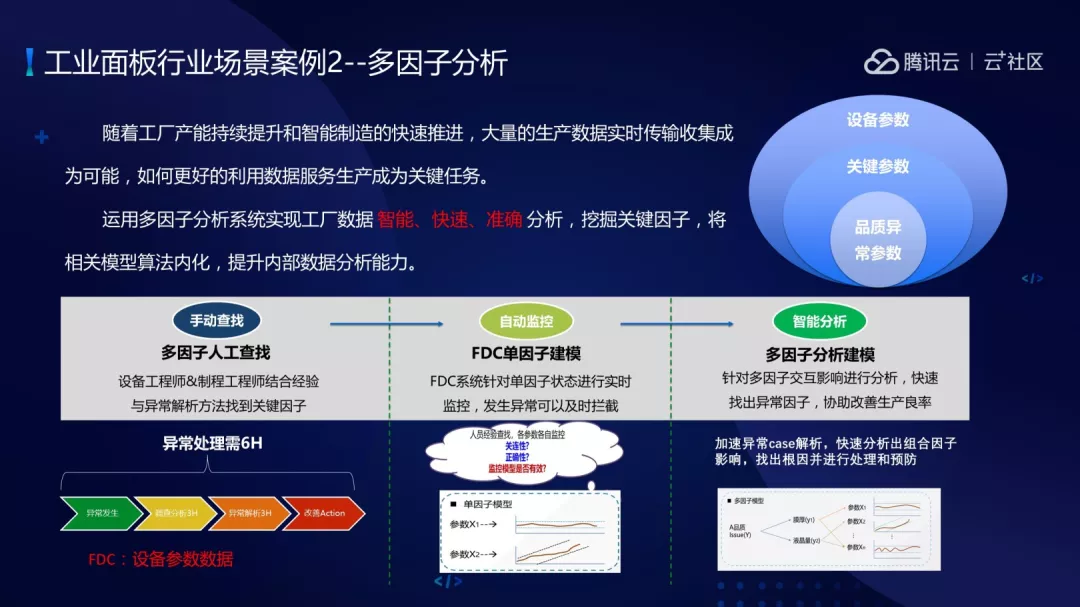
在系统上之前,厂方做因子分析主要是设置查看,当异常发现的时候会人工调查分析异常出现在哪里,最后对异常进行解析,针对解析的结果做改善性 Action。第二阶段是做了 FDC 单因子建模,FDC 建模对单因子进行实时监控,发现异常可以进行及时拦截。最终实现智能分析多因子分析建模,针对多因子交互影响进行分析,快速找出异常因子,协助改善良率提升。
举一个例子,对某某产品异常放电的监控。对某某产品高发的异常放电,在 DRY 设备端发生宕机的情况下漏到后道,产生严重的碎片宕机,造成严重的 Loss 甚至批量的刮伤、砸伤。
建立虚拟参数,把差值预值过滤后就可以认为是异常的,经过多次的模型优化,现阶段针对大板树枝状拦截达到百分之百。

第二阶段是隐形站点分析以及相关站点的集中性分析找到相关的高发参数,我们找的例子是 ET-TEMP 和 CU+浓度是差异性超参数,针对两个相关因子会做强相关的交互作用分析,建立管控值,通过左边和右边的图给出参数的建议管控范围,比如说高浓度低温和低浓度高温,最后会对模型进行模型修正,FDC 可即使拦截异常,避免损失扩大。当前站点的拦检不一定是当前站点本身的问题,有可能是其他问题造成的,所以结合多因子分析系统进行因子分析,得到最主要的因子。
面板行业案例是针对智能钛机器学习平台一进行了定制化,定制产品就叫“TI-Insight”提供两方面功能:推理、训练。
推理主要解决算法服务如何部署的问题、解决 AI 算法微服务高可用的问题、解决负载问题、解决自动扩缩容问题、解决 AI 推理框架模型算法优化问题、可以自动释放资源以及请求队列问题、资源高效利用以及虚拟化资源高效利用、自动启停的问题。主要解决的问题是:怎么管控数据?怎么训练模型?针对模型更新、迭代进行管理。
智能钛机器机器学习平台在金融行业的落地
金融行业对 AI 来说比较简单,主要包含三方面:营销、运营、风控。
营销方面主要有客户获取/价值提示、多渠道交互分析、客户动态信息视图。运营方面是精准营销、目标客户快速定位、资金管理跟踪;风控主要有贷款风险评估、反洗钱、实时欺诈。
主要是四方面:客户、产品、运营、风险。客户方面像获取新客户、虚拟产品经理、存款流失预测消息。风险方面有金融风险分析、授信客户风险分析、贷款风险评估等。
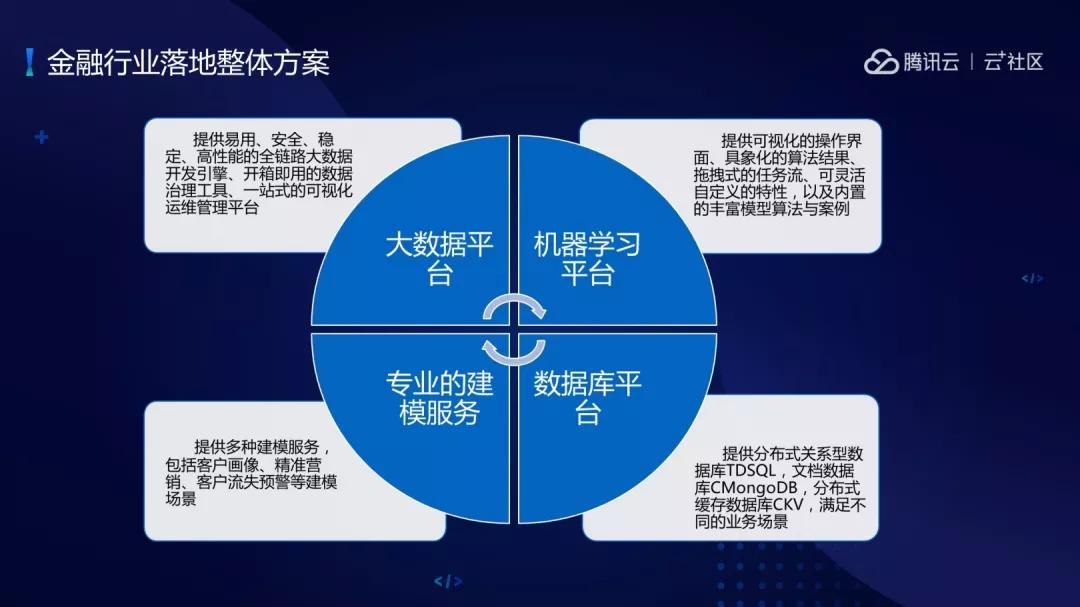
怎么解决金融行业落地问题?主要是四方面:
(1)数据库平台,提供分布式的关系数据库、文档数据库满足不同的业务场景。
(2)大数据平台,提供易用、安全、稳定、高性能的全链路大数据开发引擎。
(3)机器学习平台,提供可视化操作界面、具像化的算法结果、拖拽式的任务流。
(4)专业模型建模。
这就是整体的解决方案,案例的内容是对工客户购买理财产品预测,目标是提高对公客户理财产品销售,提升对公客户贴性,降低理财产品销售成本。思路是利用大数据及人工智能技术,挖掘对公客户购买模式,实现精准销售及预测。解决方案比较简单,构建二分类问题,洞察购买理财产品客户,实现对客户理财产品销售预测。

建模最重要的点对业务数据的理解,精准营销案例包含两方面的信息:企业画像用户、企业行为数据信息。画像信息主要包含了企业的基本信息、企业主基本信息、企业资产基本信息,行为信息主要包含理财产品、购买历史表等等。
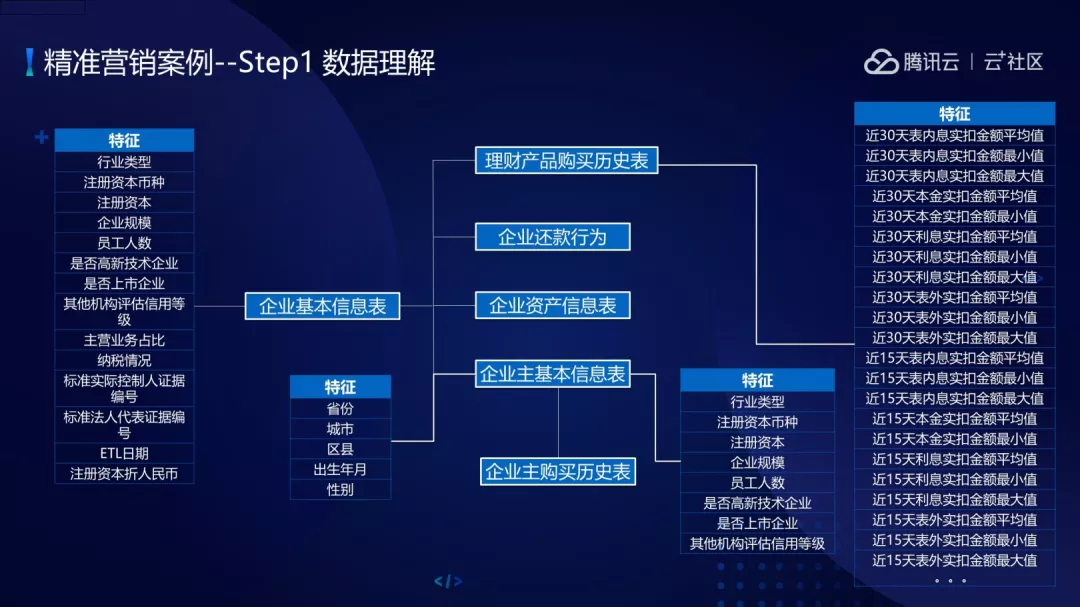
针对数据会做一些数据预处理工作,首先要做的工作是要抽样出来哪些是正样本、负样本,正样本是购买过理财产品的企业客户,未购买的作为负样本。这个案例里总共得到了 3426 个正样本,26707 个负样本,正负样本的比例在 1 比 8,所以我们要根据偏样本进行处理。
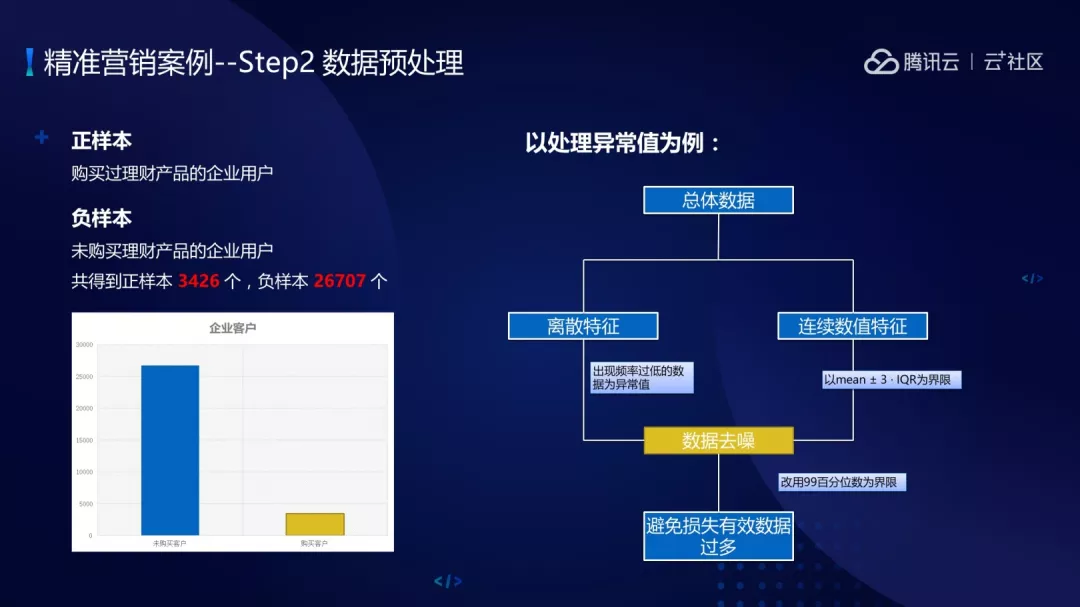
以异常值处理为例,针对离散特征会对频率过低数据认为是“异常值”处理掉,对于连续数据会用均值加 3 倍分位数间距进行界限作为异常值处理。当然有时候如果我们用均值加 3 倍分位数间距范围太大,可以改为 99 分位数作为界限对异常值进行处理。
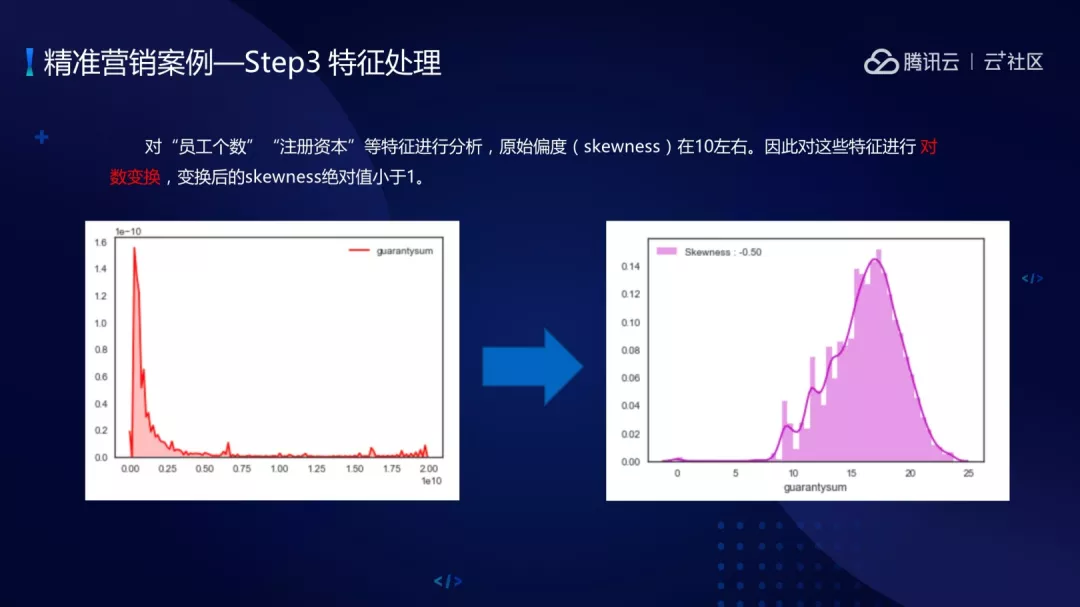
特征处理包括对特征进行转化,归一化。员工个数、注册资本这些特征刚开始的原始偏度在 10 左右,是比较大的。对这样的数据需要进行变换,把偏度转化为 1 左右,这样数字是接近正态分布的样式。
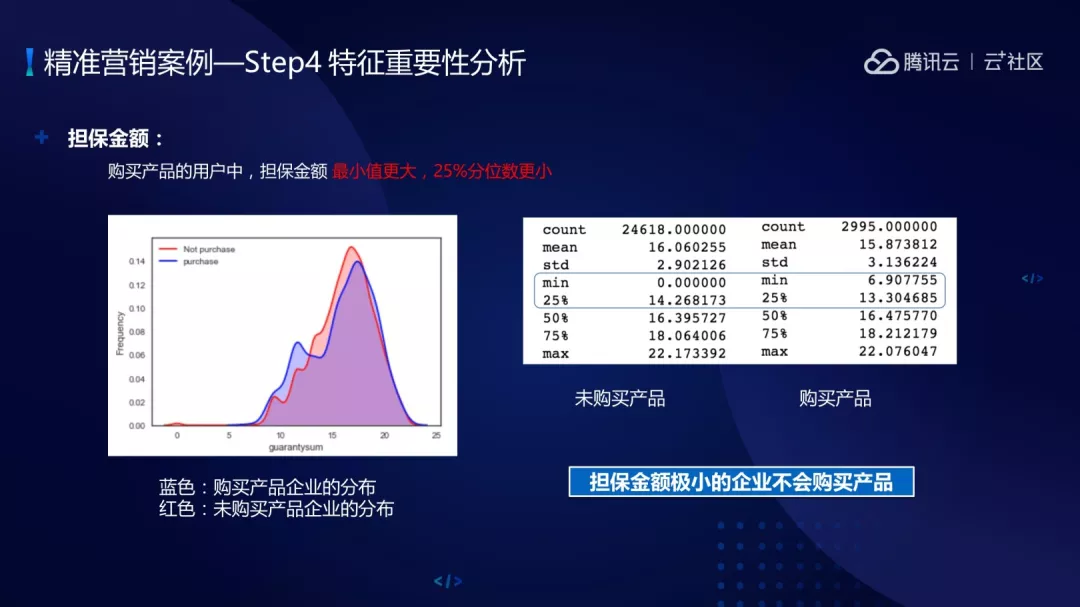
特征重要性分析,对购买产品用户的担保金额做分析,蓝色是购买产品企业的分布,红色是未购买产品的企业分布。从左边以及右边图可以看到,担保金额最小值更大,25%分位数更少的用户都是购买过产品的用户。在这个过程中可以得到结论,担保金额极小的企业不会购买产品,这是我们在做特征重要性分析时的一步重要工作。
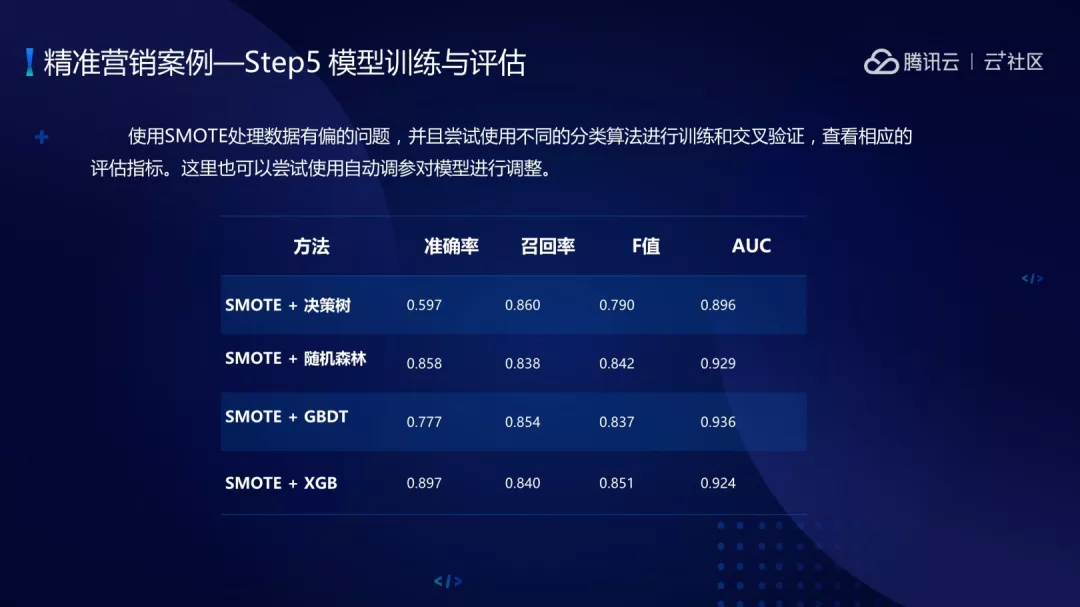
模型的训练与评估,使用 SMOTE 处理有偏的数据,正负样本是 1 比 8 的比例,用 SMOTE 进行数据生成,把数据变成非有偏的数据。尝试不同的分类算法进行训练和交叉验证,采用了多种分类算法包括决策树、随机森林、GBDT、XGB,总体来说集成学习的效果更好。
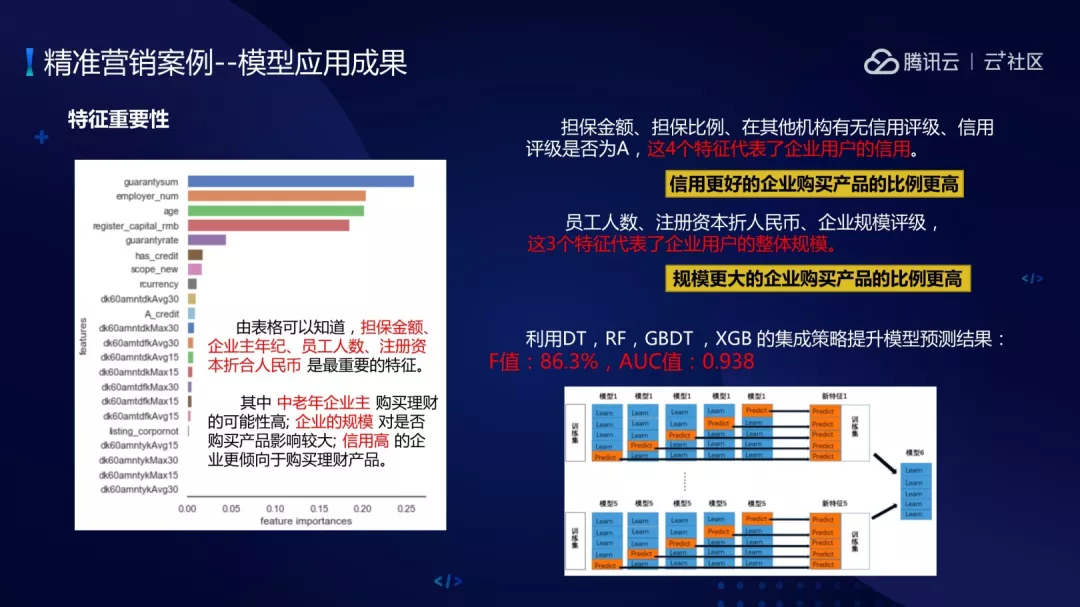
精准营销案例最终对重要性进行排序之后可以得到担保金额、企业主年纪、员工人数、注册资本折合人民币等特征,其中中老年企业主购买理财产品可能性高,企业规模对购买产品影响比较大,信用高的企业更倾向购买理财产品。
最终利用决策树、随机森林、GBDT、XGB 集成策略的方式训练出来多个模型,用多个模型做决策。最终模型预测 F 值是 86.3%,AUC 值是 0.938,整体效果可以达到生产上线的效果。
金融行业落地有哪些经验、归纳的地方呢?
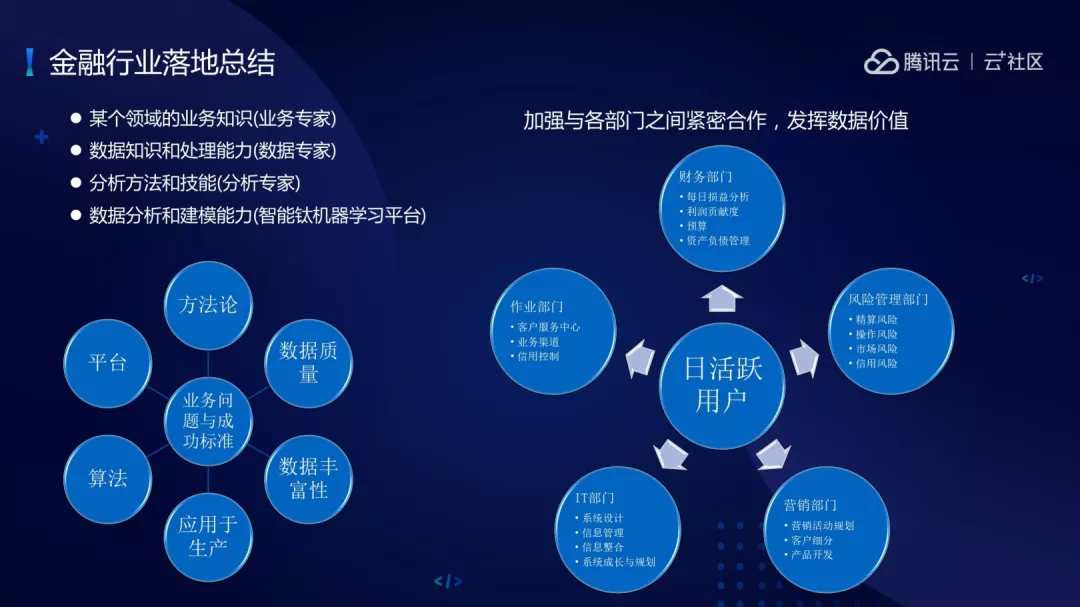
人是最根本的,需要业务专家了解领域的业务知识;需要数据专家了解数据的知识和脱敏能力;需要分析专家了解分析方法和技能;需要建模平台提供数据分析和建模能力。
业务问题成功的标准是什么?方法论、数据质量、数据丰富性、应用于生产、算法、平台是否稳定。这是业务问题成功与否的标准。很重要的一点是需要和金融领域其他部门进行紧密合作,最终发挥数据价值。
本文转载自公众号云加社区(ID:QcloudCommunity)。
原文链接:
https://mp.weixin.qq.com/s/ntnwkYdN-8zBS08Pij1lQw

中国开发者画像洞察报告 2022
本次报告为你深度解读开发者人群背景,分析开发者群体面临的挑战,洞察开发者人群特征,预测开发者生态发展...









评论