
ClickHouse 是一款面向大数据场景下的 OLAP 数据库,相比于传统的基于 Hadoop 生态圈的 OLAP 大数据分析系统,ClickHouse 具有极致的查询性能、轻量级的架构设计及维护简单等优势。目前社区活跃度高,业界应用实践日趋广泛。
一、业务介绍
京东能源管理平台是京东科技 IoT 产品部面向政企客户推出的一款利用物联网、大数据和 AI 技术实现用能企事业单位对能源大数据进行采集、监测、分析和告警的能耗分析产品,旨在帮助客户实现节能减排,降低单位产品能耗。
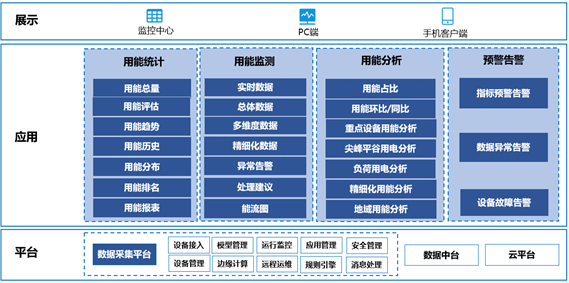
能源指标包括用电量、用水量和用天然气量,维度有时间维度(年、月、周、日、时)、厂家、车间、生产线类型、生产线、设备。针对这些指标和维度,提供了实时的数据多维分析与诊断服务。
二、技术选型
对于数据指标的多维度分析场景,上世纪业界就提出了 BI(商业智能)的概念。相较于 OLTP(联机事务)系统,业界把此类面向 BI 的系统统称为 OLAP(联机分析)系统。伴随着计算机软件技术的发展、从单机工具的少量数据分析(如 Excel),到中等规模数据通过分析型关系数据库构建(如微软的 SSAS)的 OLAP,再到今日的大数据时代,海量数据的实时 OLAP 分析引擎,技术上的推陈出新,工具系统上百花齐放百家争鸣,各有优势,但大体上可以将它们从架构模式上划分为两大类:
1. MPP 架构。MPP 架构特点是服务将接收到的查询请求发送到每个计算节点,待计算节点计算完成后,通过一个节点将最终结果汇总在一起得到最终结果。典型实现如 Presto、Impala、SparkSQL、Drill 等。MPP 架构的特点是支持灵活的数据模型,要达到较高性能对内存开销大。
2. 预计算系统。预计算的核心思想是利用空间换时间,通过深入业务理解,将需要查询的数据指标和维度组合进行预处理,将计算好的结果存入数据库并建立对应索引,实现查询加速。典型实现如 Kylin、Druid。预计算系统特点是性能较高,但灵活性较差,一般对数据模型调整会涉及到历史数据的重跑,维护困难。

从上表可知,目前业界还没有一个 OLAP 引擎能够同时兼顾性能和灵活性的要求,京东能源管理平台在做技术选型的时候,综合考虑了模型的灵活性、部署的难易程度、开发成本、可维护性以及是否适合云端部署等因素,最终决定使用基于 MPP 架构的 ClickHouse 作为我们的 OLAP 引擎。
三、ClickHouse 的应用
1、系统架构
京东能源管理平台主要是对各种表计(水表、电表、天然气表等)设备上报的计数进行多维度分析统计、AI 诊断和出具能耗报表等。表计的原始数据通常都是累计值,如电量度数就是一个从电表安装以来,所有耗电量的一个累计。因此,我们在数据接入前会引入一个差分器对数据进行预处理,使得进入 ClickHouse 的指标数据变成可直接累加的指标,方便利用 SQL 对接 ClickHouse 实现多维的查询服务。架构图如下:
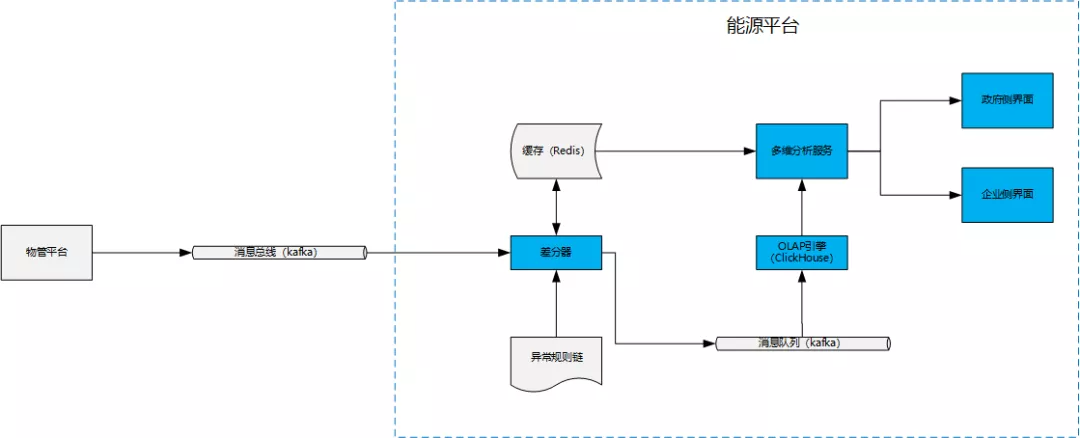
说明:
物管平台:对设备的管理,管理物模型及设备状态、采集设备数据。
消息总线:kafka 消息队列,利用 JSON 格式数据实现物管平台和能平台的数据交互。
差分器:对每次上报的累计值同上一次上报的累计值做差值计算,得到可累加指标。
异常规则链:提供一个异常规则集,用于差分器判定上报数据是否异常,如异常则进行记录,数据不作处理。
OLAP 引擎:基于 ClickHouse 实现的 OLAP 引擎。
多维分析服务:提供通用的数据多维分析查询服务,能够通过统一的 API 实现各种维度和指标的组合查询。
政府和企业界面:政企客户的 WEB 界面。
2、ClickHouse 应用
通过上面的架构图可以看出,能源平台采用 ClickHouse 作为 OLAP 引擎提供多维查询服务。下面重点从数据的接入、存储以及通用化接口设计方面谈一谈
ClickHouse 的应用:
数据接入
ClickHouse 基于 kafka 引擎表的数据接入可以看做是一个典型的 ETL 过程,数据的抽取(Extract)是通过建立一张 kafka 引擎表,产生消费端订阅 kafka topic 实现;数据的转换(Transform)通过物化视图实现;数据最终加载(Load)进 MergeTree 表,实现实际数据存储。
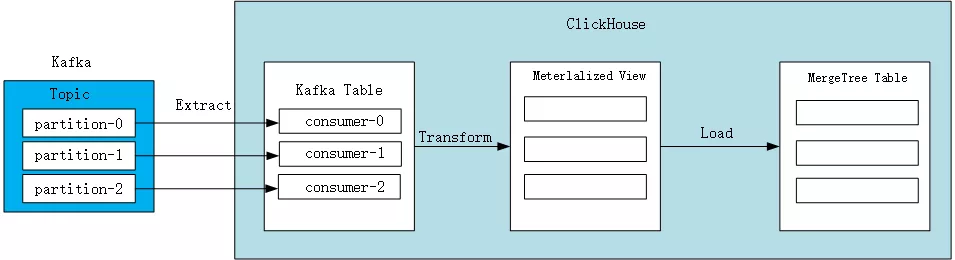
创建 Kafka 表示例:
1CREATE TABLE statistics_kafka ON CLUSTER '{cluster}' ( 2 timestamp UInt64, 3 level String, 4 message String 5 ) ENGINE = Kafka SETTINGS kafka_broker_list = 'kafka.jd.com:9092', 6 kafka_topic_list = 'statistics', 7 kafka_group_name = 'gp-st', 8 kafka_format = 'JSONEachRow', 9 kafka_skip_broken_messages = 1, 10 kafka_num_consumers = 3;<左右滑动以查看完整代码>
kafka_broker_list: kafka broker 地址。
kafka_topic_list:消费的 topic。
kafka_group_name:消费 groupId。
kafka_format:数据格式 JSONEachRow 表示消息体为 JSON 格式。
kafka_skip_broken_messages:表示忽略的 kafka 异常消息条数,默认为 0。
kafka_num_consumers:消费者个数,默认值为 1,建议同 kafka 分区数对应。
创建物化视图示例:
1CREATE MATERIALIZED VIEW statistics_view ON CLUSTER '{cluster}' TO statistics_replica AS2SELECT timestamp,3 level,4 message5FROM statistics_kafka;<左右滑动以查看完整代码>
创建 MergeTree 引擎表示例:
1CREATE TABLE statistics_replica ON CLUSTER '{cluster}'{2 timestamp UInt64,3 dt String,4 deviceId String,5 level String,6 message String7} ENGINE = ReplicatedMergeTree('/clickhouse/tables/{shard}/statistics_replica','{replica}')8PARTITION BY dt9ORDER BY (dt,deviceId,level);存储
a. ClickHouse 表类型
本地表:实际数据存储的表,如上示例表 statistics_replica。
分布式表:一个逻辑上的表, 可以理解为数据库中的视图, 一般查询都查询分布式表. 分布式表引擎会将我们的查询请求路由本地表进行查询, 然后进行汇总最终返回给用户。创建分布式表示例:
1CREATE TABLE statistics ON CLUSTER '{cluster}' AS statistics_replica 2ENGINE = Distributed(ck_cluster_1,test,events_local,rand());
b. Replication 和 Sharding
Replication 是 ClickHouse 提供的副本机制,对于 Replicated MergeTree 系列复制表,可以设置每个表有多份完全一样的数据存放在不同的计算节点上,每一份数据都是完整的,并且称为一个副本。
Shard:将表中的数据按照一定的规则拆分为多个部分,每个部分的数据均存储在不同的计算节点上,每个计算节点上的数据称为一个分片。
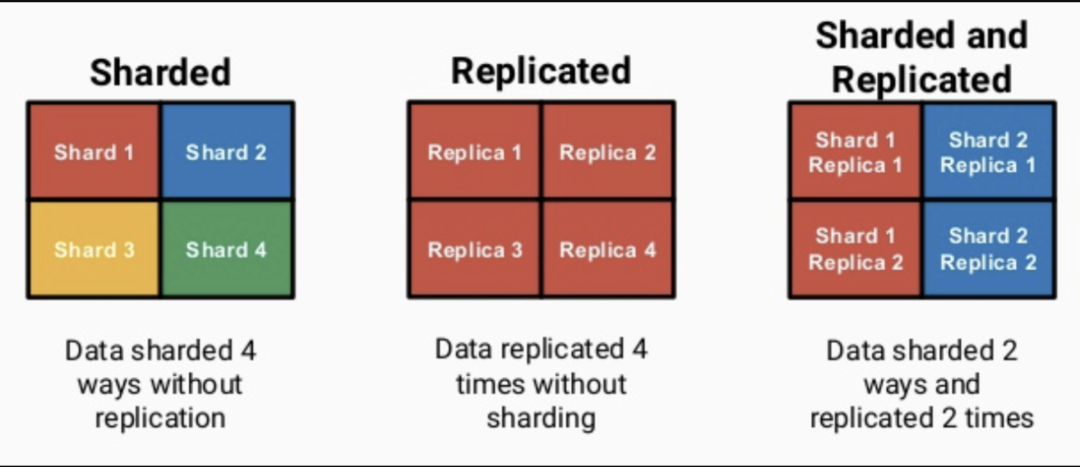
ClickHouse 基于 Replicated MergeTree 引擎与 Zookeeper 实现了复制表机制,在创建表时,可以决定表是否高可用。上一节的 statistics_replica 表,其中/clickhouse/tables/{shard}/statistics_replica 表示 Zookeeper 中对应副本表的 node。当数据写入 ReplicatedMergeTree 表时,过程如下:
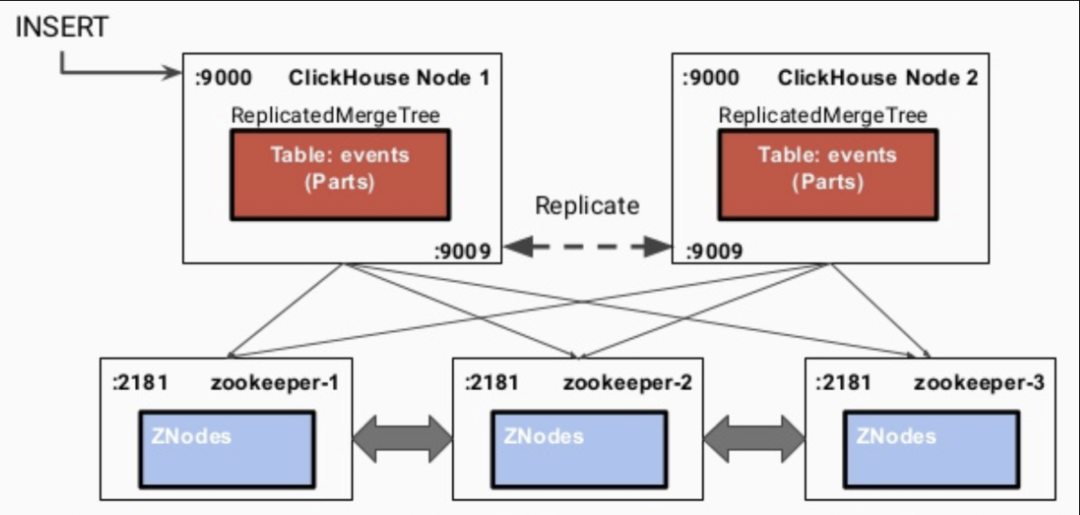
某一个 ClickHouse 节点接收到数据写入请求。
通过 interserver HTTP port 端口同步到其他实例。
更新 Zookeeper 集群上的 node 信息。
3、OLAP 通用接口设计
ClickHouse 提供标准的 SQL 查询引擎,通过 JDBC 引用程序可以实现多 ClickHouse 的基本操作。OLAP 的常规操作如上卷、下钻和切片会涉及到多种维度自由组合、多种指标交叉剖析的过程,如果服务端采用 Mybatis 或 JPA 等常规 ORM 操作,工程师很容易根据不同的查询场景要求设计出对应的接口,亦或是根据大量的分支操作设计出复杂的判定性接口,鉴于此,作者从 mdx 思想获得启示,设计一套对 OLAP 优化的通用多维服务查询接口。
首先,一个典型的分析类 SQL 语句如下:
1SELECT day_str, 2 factory_name, 3 workshop_name, 4 prodline_name, 5 device_id, 6 SUM(w_total) AS total 7FROM statistics 8WHERE day_str BETWEEN '2020-10-01' AND '2020-12-31' 9GROUP BY day_str,factory_name,workshop_name,prodline_name,device_id10ORDER BY day_str ASC;<左右滑动以查看完整代码>
如上语句,我们翻译成业务语言为『分别查询 2020 年 4 季度全厂所有设备的耗电量』,从这里我们可以清楚的知道这里的维度是指『设备名称』,指标为『耗电量』,基于此,可以进一步归类,维度通常出现在 SQL 语句的 SELECT、WHERE、GROUP BY 和 ORDER BY 后面,指标则通常出现在 SELECT 后面,也就是可以总结如下模式:
1SELECT {维度},{指标}2FROM table_name3WHERE {维度}='xxx'4GROUP BY {维度}5ORDER BY {维度};因此,我们可以设计如下通用接口方法:
1//通用方法2List<Map<String,Object>> queryStatisticsResult(Query query);34//Query类5public class Query {6 private static final long serialVersionUID = 4904019884726531900L;7 /**8 * 维度9 */10 private List<String> dimensions;11 /**12 * 指标13 */14 private List<Measure> measures;15 /**16 * 过滤条件17 */18 private List<Filter> where;19}2021//Measure类22public class Measure implements Serializable {2324 private static final long serialVersionUID = -8556179136317748835L;25 /**26 * 指标名称27 */28 @NonNull29 private String name;30 /**31 * 列名32 */33 @NonNull34 private String field;35 /**36 * 聚合类型37 */38 @NonNull39 private AggregationEnum expression;40}4142//聚合枚举43public enum AggregationEnum {44 SUM,AVG,COUNT,MIN,MAX,COUNT_DISTINCT,PERCENTILE;45}四、总结
本文重点介绍了京东综合能源管理平台多维数据分析引擎的架构和设计,从数据接入、存储和多维分析服务设计的角度,阐述了 ClickHouse 的一种典型应用场景。希望通过本文让读者在应对大数据实时 OLAP 领域,提供一种思路和方法。当然,限于篇幅和本人水平有限,没有进一步展开阐述更多的可能性方案,随着我们对于业务的深入,系统的迭代升级,适宜于将来更优方案势必会步步推出,也请期待。
文章转载自:京东数科技术说(ID:JDDTechTalk)




