

今天聊的任务调度系统,在开源领域中近似的就是 Ansible 了。Ansible 通过在集群上执行命令解决各类业务问题,从而管理千台规模的集群,自身安装和维护都非常简单,因此得到迅速普及,深受运维人员喜欢。
下图就是 Ansible 的典型场景,在 Ansible-Server 上,对一组机器列表下发指定的命令并回收执行结果,从而完成一次任务的执行。
在大型的互联网公司中,任务调度系统多以自研为主,本文希望借助于任务调度系统,能够将隔离这个话题,讲的较为透彻一些。
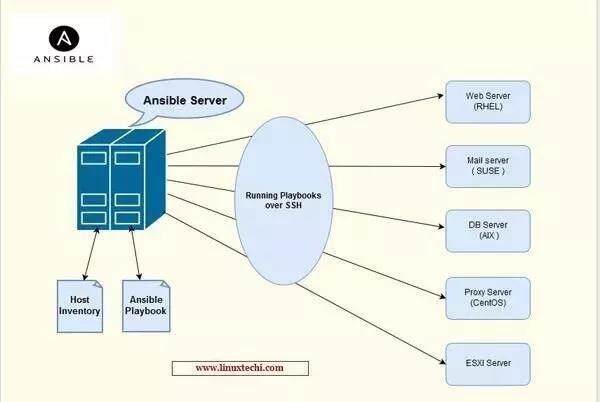
从隔离的角度看任务调度系统的高可用
任务调度系统要支持公司内部的各个场景,如上线,配置修改,数据备份,文件传输,批处理命令等等,每天数以万计的任务量,这里面任何的任务失败,可能都会导致较为严重的后果,例如关键报表任务故障,重大新闻素材推送失败,紧急回滚功能故障等等。因此任务调度系统的高可用能力一定是面面俱到的。
那为什么本文要从隔离角度来看任务调度系统的高可用呢?因为隔离能力是以下高可用能力的前提和基础:
灰度发布
异地多活
故障隔离
混沌工程
因此,接下来,我们主要从隔离角度对任务调度系统进行分析
任务调度系统的隔离能力建设
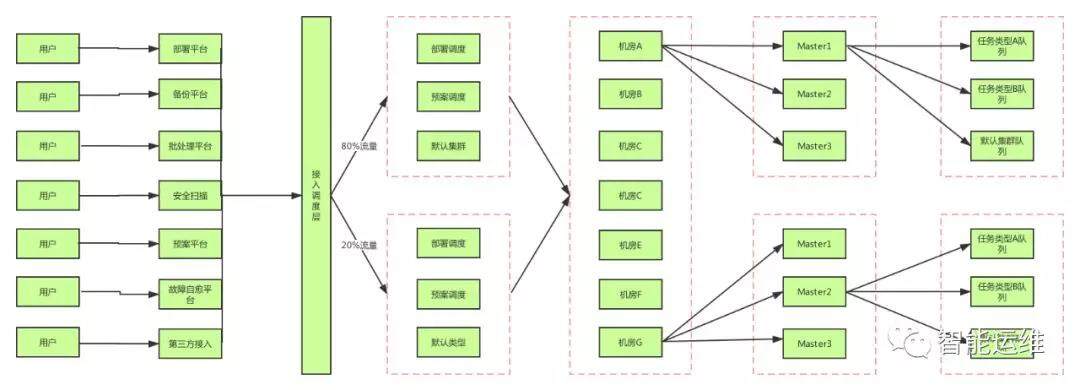
下图是典型的任务调度系统的架构示意图,数据流如下:
用户请求:用户通过上层各种业务平台发起请求
接入调度层:基于用户在上层平台的 TAG 标记进行任务类型的识别,并将任务分配到合适的任务处理平台,同时,接入层还起到鉴权,配额管理,合规性,流量控制和流量调度的作用。
任务调度层:用户发起的任务,通过接入层的检查放行后,就被分发到不同任务类型的调度集群上,然后按照任务的机器列表要求,分发到各个机房对应的 Master 上
任务执行层:调度层会预先基于 IP 地址进行拆分,将一个机房的机器列表,按照确定的规则分发给不同的 Master,每个 Master 又将各类任务划分为不同的队列进行处理
租户隔离,适用于不同的业务场景
举例来说,每天的凌晨整点开始,会发起大量的备份任务,涉及线上绝大部分机器,此时,如果不进行隔离,那么同时段发起的上线任务可能就会受到影响。通过对不同的租户进行隔离,同样的情形下,因为备份和上线的集群是独立的,且每个集群都有相应的配额,因此两者之间不会互相影响,单个租户也不会影响整套系统。换言之,备份任务所在的集群宕机,也不会影响到上线的任务。
类似的一些租户隔离的场景
PC,移动端和 APP 的流量进行隔离
报表系统和用户请求流量进行隔离
线上环境和线下环境隔离
重要性隔离,适用于同一类业务场景
以当下较为热门的直播应用为例,不同主播的访问量相差极大,对于热门主播,可能随便一次直播都可以带来百万用户的访问量,那么假设直播应用主播的信息均匀分布存储于 Redis 中,数据以三副本存储,那么对于这种百万直播的场景,因为热门主播的数据分散存储于整个集群当中,极有可能会将整个 Redis 集群压垮,进而导致所有主播的业务都无法使用。基于重要性隔离的思路,就需要将这类热门主播的数据,存储于独立的 Redis 集群,并将副本数调整到较高的数量,进而满足大压力的要求。虽然副本数增加,但因为热门主播数量毕竟有限,因此整体的存储成本未必会增加许多。而一般的主播虽然访问量较小,但其基数较大,继续沿用之前的三副本策略,也能够满足需求。
以下是单一业务场景内,基于重要性不同进行隔离的例子:
付费用户和免费用户隔离
广告系统中,将公益广告和付费广告隔离
冷热数据的隔离
将正常请求和爬虫请求、安全扫描、压测请求、灰度请求等进行隔离
读写隔离,避免突发的读/写请求影响服务
对于任务调度系统来讲,必然会有任务执行结果查询的需求。因此,在接入调度层,将查询类需求,全部调度到特定的集群上,即可以满足用户的各类查询需求,也不会因为查询压力过大而导致任务发起功能受到影响
类似的,读写隔离应用最广的场景是在数据库中。通过读写隔离,可以大幅降低数据库的故障率,是数据库优化中最常见也是最重要的手段之一
地域隔离,最小化故障的影响范围
如果北京联通网络异常,不太会影响到济南联通用户;中西部地区的地震,其震感也不会传导到华北等区域;而每年的洪灾,也主要集中在长江中下游地区;华中地区夏季电力供应紧张,也不会要求华北地区拉闸限电。
地域隔离,主要是参照故障域的概念(有些地方叫做隔离域),处于一个地域的用户,共享该地域的基础设施如骨干网,运营商等,同时自然灾害也会呈现地域范围的特点。将一众共享同一故障域的用户,其流量集中在一个集群中进行处理,既可以最小化故障的影响范围,同时,也能够降低故障处理的难度。
在实际的执行中,不同公司的地域划分不尽相同,其划分标准不仅仅会考虑故障域,同时也会考虑到各地的请求分布,时延以及 IDC 布局等因素。
类似的,一个公司的基础设施如 DNS、LB 等也都是按照机房粒度进行部署的,也可以理解是一种地域隔离的场景。
队列隔离
在任务执行层,是以机房为粒度,处理该机房所有类型的任务,因此势必会出现一个实例要处理各种类型的任务,如果所有的任务使用默认的队列,那么一旦某类任务因为种种原因开始积压,在达到队列长度限制后,后续新增的任务就会被丢弃,这时候,是这个机房的所有任务均被无差别的伤害了。如果对每类任务创建一个队列并基于任务类型的特点和重要性设置队列长度,则能够有效避免单一任务类型的异常导致所有类型任务失败的问题
资源隔离,避免单机多进程间的资源竞争
这是最基本的隔离要求,当下的硬件设备,手机都 8 核 8G 内存了,就更别说服务器了。因此单一进程很难占满整个服务器的资源,这样,势必就会出现混部需求。那么两个进程部署在同一个服务器上,可能就会出现各种资源竞争了。可能某个进程因为流量突增,把 CPU 资源占满这都是家常便饭了,但你把 CPU 资源耗光了,你让人家怎么活。
因此资源隔离技术,就开始应运而生,对 CPU、内存、磁盘空间、IO、网卡等进行隔离,从而避免单个物理机上多个进程间互相影响。较为简单的有通过 taskset、ulimit 等命令对 CPU 和 MEM 进行限制,也有更好的 Cgroup 的隔离,当然,直接上 Docker 这种解决方案更为方便一些。
数据隔离
在进行了基于租户、重要性、地域隔离之后,对应的隔离的集群,其数据也需要做到完整的隔离,避免单个集群异常后,导致所有集群的数据被破坏而无法使用,进而实现了真正的多活。

中国开发者画像洞察研究报告 2024
分析开发者的行为模式、工作价值、职业发展等内容,帮助整个行业生态更深入地理解开发者,为他们提供更精准...













评论