

本文由 dbaplus 社群授权转载。
老马也有失蹄时,万万没想到,这次当了一回“头痛医头,脚痛医脚”的庸医。先来介绍下这次当庸医的情况吧:客户的一套三节点的 RAC,上线了三年时间,随着业务量越来越大,数据库运行越来越慢。客户为了缓解特殊时间段的业务促销压力,决定搭建一套单机的 ADG 来分摊原生产库上的一部分查询压力。
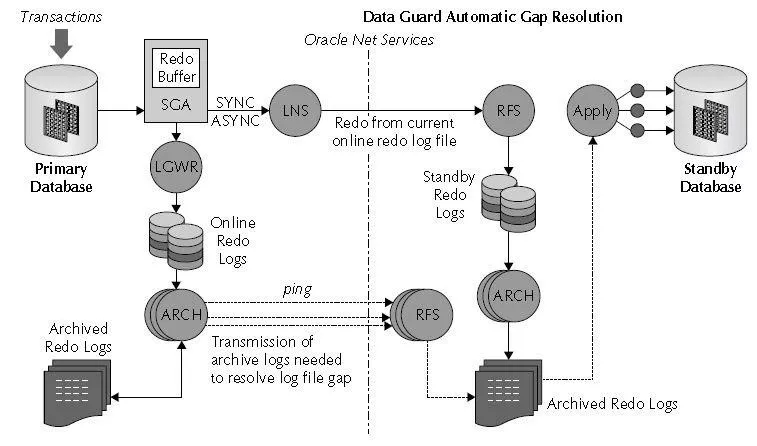
▲ Data Guard 架构
由于业务的实时性较高,ADG 配置采取了 LGWR 和 ASYNC 的模式来进行 Redo 变化的传输。在搭建环境之后的第二天,一个只读查询业务便迁移了过来。该业务的特点是并发高,实时性要求高。由于上线比较仓促,业务刚迁上去 2-3 天之内相继出现了不少问题,并且数据库还连续宕机了几次。面对问题,我们是出现一个处理一个,但这种被动式的处理方式非常低效。
我们先来看看都出现了哪些问题。
问题 1 监听连接问题
当把一个只读业务迁移之后,监听出现大量的短连接冲击,出现一些 TNS 错误。
1、操作系统参数设置过低,导致资源不足
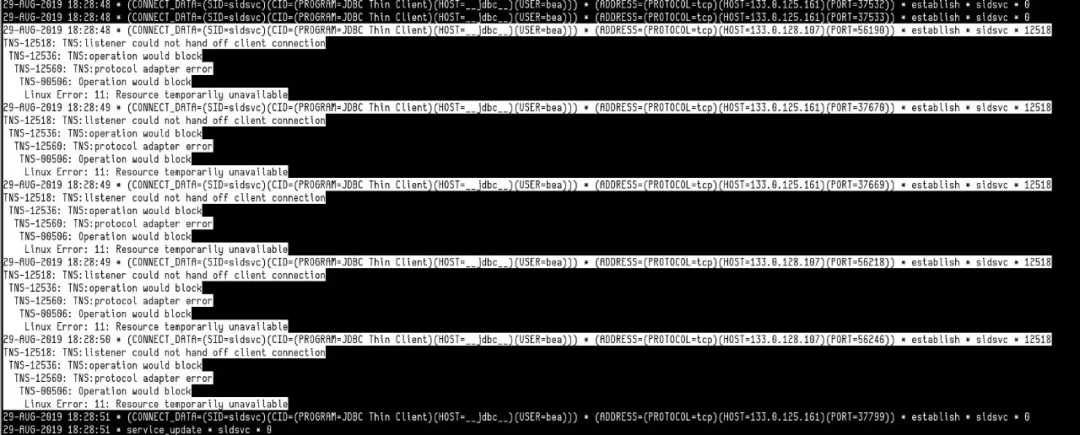
这里的错误主要是 Linux Error: 11: Resource temporarily unavailable,需要通过调整操作系统参数 nproc 来解决。在 Redhat/CentOS 7 的系统中调整位置发生了变化,修改指定用户的 nproc 在/etc/security/limits.d/20-nproc.conf 文件中配置,可参考官方文档:https://access.redhat.com/documentation/en-us/red_hat_enterprise_linux/7/html/migration_planning_guide/sect-red_hat_enterprise_linux-migration_planning_guide-system_management
不过还要注意一点,当你调整了 nproc,也不一定能达到它最大的值。这是由于内核参数 pid_max 设置过小导致的,还需要把 kernel.pid_max 参数设大一点。
2、监听短链接并发过高,出现连接 Refuse 和 Timeout
这里最常规的优化方法是改成长链接。但是由于历史原因没办法修改,所以还是从监听本身着手。
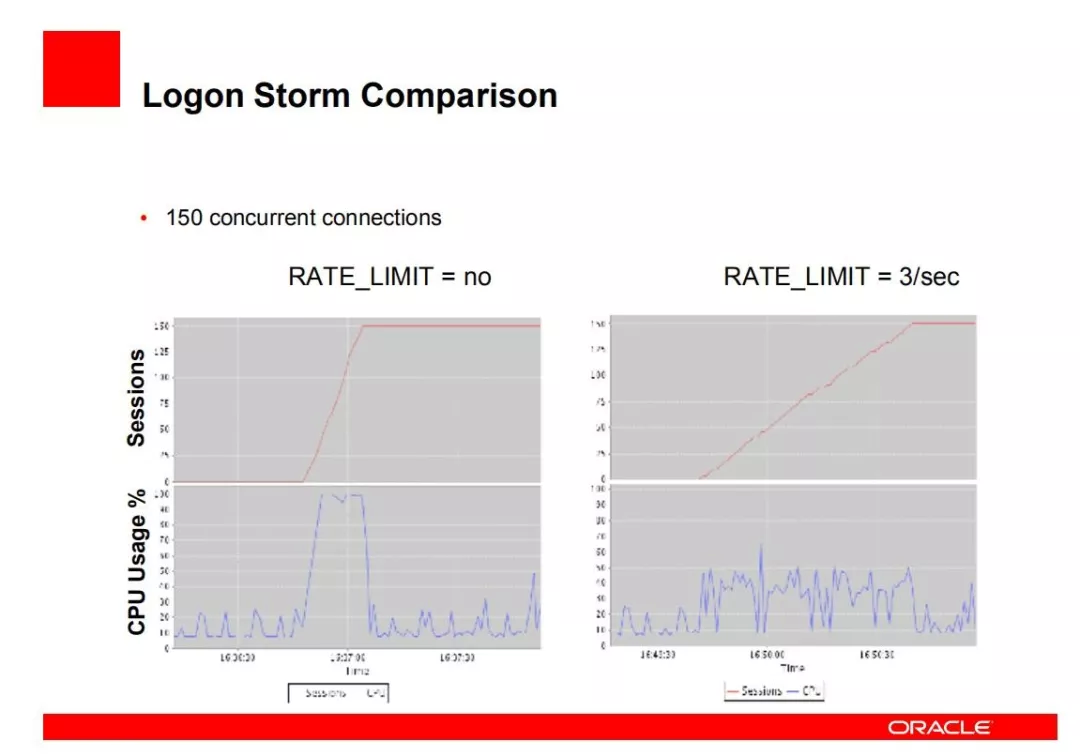
第一种是设置 RATE_LIMIT,如图所示,当限制为每秒 3 个时,同时并发连接超过 3 个就会报错。这种方法起到高并发连接的限制作用,超出了限制就会报错。而业务程序基本上每秒就超过 100 个并发连接,同时这些连接需要取最新实时的数据。我们就是为了让并发连接不报错。因此设置 RATE_LIMIT 参数并不符合要求。

第二种是在监听中增加 QUEUESIZE 参数,QUEUESIZE 参数是指监听器在建立连接时可以存储的并发连接请求数。如果传入请求数超过缓冲区大小,则请求连接的客户端将接收失败。在比较理想的情况下,此缓冲区大小应该等于或者大于预期并发请求的最大数量。Oracle 官方文档也提到了这个参数适用于处理大量并发连接的请求。
在 CentOS7平台我们可以通过 strace 命令查看默认的 QUEUESIZE 参数。
可以看到在 cenot7 和 11g 数据库版本中默认是 128,我们把这个设置成 512。
问题 2 ADG 数据库出现大量的 library cache lock 和 ORA-00600 错误
我们安装了和主库相同的 PSU,但是在运行的过程中数据库仍然会出现大量的 library cache lock 和 ORA-00600[kgllkde-bad-lock]及 ORA-00600[kss_get_type: bad control]等错误。可以通过安装单独的 patch 24385983 18515268、19180394、17608518 等来增强数据库的健壮性。
针对在 ADG 数据库上出现的 library cache lock,我们做了单独的补丁分析,参考了文档 WAITEVENT: “library cache lock” Reference Note (Doc ID 34578.1),如下 excel 列表所示,相关和容易触发问题的补丁都做了安装。
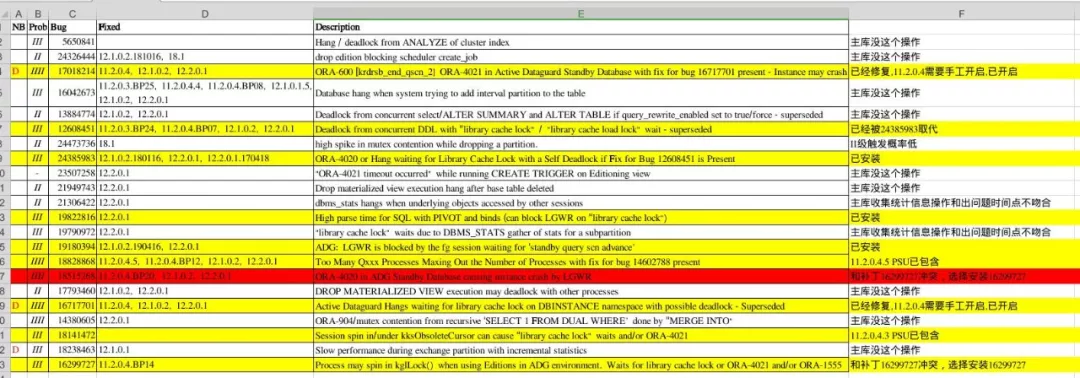
这里有几个小技巧的分享:
首先这里的一些 bug 是特殊操作才会触发的,例如添加 interval partition 分区。而数据库中根本没使用到 interval 的分区,所以这类 Bug 就不会触发。
其次 Prob 列代表触发的概率,分为 I,II,III,IIII 等等,IIII 是触发几率最高的。而 I,II 是触发几率最低的,这种触发较低的补丁可以考虑不安装。毕竟为了一个极低的概率去安装一些补丁获取的收益不大(除非这个极低的概率一直会触发)。
最后就是 NB 列。NB 代表安装了补丁,还需要做一些设置才能 enable 它的功能,例如设置 event 事件(注意:如果不设置事件或者相关参数,安装了补丁也不起作用)。
问题 3 Centos7 操作系统 cache 回收问题
通过观察操作系统我们发现当 free 内存值下降之后,系统会触发文件系统 cache 回收动作,这些动作会让 system cpu 变高。往往会造成主机 hang 住没办法操作。系统当前的 vm.dirty_background_ratio 和 vm.dirty_ratio 参数设置的是平衡模式,一般推荐使用这个方案。但是在出现问题的情况下,我们还是需要考虑做一些调整的。
首先我们来看两个参数的含义:
vm.dirty_ratio:内存中脏数据的限制,内存中的脏数据不能超过这个百分比的值,如果脏数据超出了这个数量。则会直接进行同步刷到磁盘。此时如果有新的 I/O 请求,将会被阻塞,需要等待脏数据写进磁盘。
dirty_background_ratio:这个参数指定了当文件系统缓存脏页数量达到系统内存百分之多少时(如 5%)就会触发 pdflush/flush/kdmflush 等后台回写进程运行,将一定缓存的脏页异步刷入磁盘中。
当前我们设置的参数:vm.dirty_background_ratio = 5 和 vm.dirty_ratio = 80。也就是当达到 5%的上限时,后台进程将立即开始异步 I/O 写入,但是不会强制同步 I/O。直到达到 80%的满载情况后,系统才会大量的同步写入。当大量同步写入的时候,此时观察到数据库就会出现大量的异常等待。
问题:这里我们考虑一下,如果我们把内存脏数据的限制从 80%下调到 10%,改成减少缓存的模式会怎么样呢?
修改成减少缓存的模式。将 vm.dirty_ratio 从 80 下调到 10,这样当开始强制同步 I/O 的时候,刷脏页是比较少的。虽然会频繁的就触发刷脏页,但是数量下降了,不会一下子刷很多。这样造成的 I/O 同步的延迟的时间就会变短。关于平衡模式和减少缓存模式的,可以参考 Bob Plankers 写的文章《Better Linux Disk Caching & Performance with vm.dirty_ratio & vm.dirty_background_ratio》。
同时系统还需要设置 min_free_kbytes,这个参数相当重要。当请求分配内存的时候,如果有足够的内存,则可以成功分配,当没有足够内存的时候,操作就会阻塞。他需要等待系统先去释放内存,再分配内存。而对于系统级别的一些原子性的请求,它是不能被阻塞的,如果分配不到内存的话,就会出现失败。内核为了避免原子请求失败,必须设置一块保留的内存。而这个就是通过这个参数来设置的。
上述参数设置完毕之后,我们还可以补充一个脚本手动来强制刷 cache。让 cache 没达到 vm.dirty_background_ratio 参数设置的 5%就强制刷脏页。
手动刷 cache,15 分钟 1 次。
问题 4 Centos 7 系统与 Oracle 软件不兼容问题
做完上述三个调整之后,业务切换到 ADG 上,白天不会出现问题,但是在半夜仍然会出现问题,同时系统 Oracle 后台报了大量的 trace。如果不清理基本上在一天内能占满 300GB。
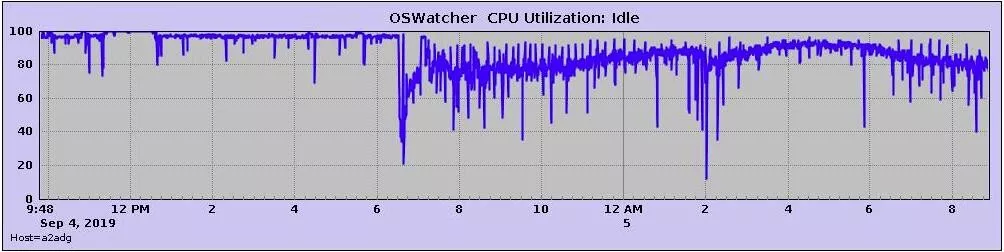
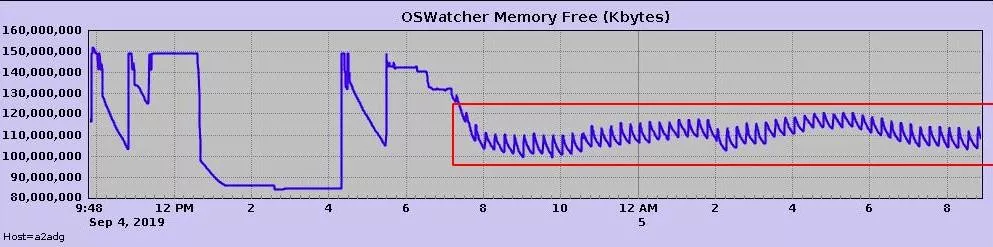
正常运行的 Oracle 软件不会出现这么多 trace,于是怀疑是 Oracle 11gR2 软件和 Centos 7.5 版本存在兼容性问题(主库是 Centos 6 和 Oracle 11g),通过使用另外的一套机器 RedHat6 搭建了一套新的 11g adg 环境后,彻底解决了半夜宕机的问题。通过 OSWatch 可以发现内存的波动是相对稳定的。
结论
其实解决了这么多问题,都只是一些表象,而真正的原因是通过一步一步的踩坑及补锅才能最终发现的。
上述是一个综合性的问题,首先是操作系统和数据库的兼容性有问题,在安装时使用了一些特殊的设置(Centos 7 安装 Oracle 11g),导致安装后,在高并发业务运行时出现问题,系统产生大量的 trace,短时间就能产生几百 GB。这些 trace 文件本身并不会导致问题,只是巧就巧在和系统设置的内存回收机制又有冲突,虽然操作系统一直是达到 5%就异步刷新脏页,但是处理能力远远不够。当达到设置的 80%时,大量同步刷脏页的时候,系统就会因为 I/O 请求发生阻塞。因而造成了 system cpu 变高,然后导致数据库出现各类异常等待事件触发 Bug,也会影响监听导致各种连接异常,最终造成数据库宕机影响了业务。
通过改成稳定的操作系统平台 Redhat6 和数据库 11gR2,优化了操作系统内核相关的内存参数,安装了 Oracle 相关补丁之后,系统再也没出现过类似问题,系统资源使用也相对稳定。
针对这次问题,其实我缺乏的是一种将”线索”串联起来的能力。就单对单线索处理的能力,我们是很强的,但是对于多个“线索”,如何串联起来我们往往有所欠缺。
第一:这个和个人职业经历及遇到的问题、场景是有关系的。如果经历过几次这样的事情,自己的大局观更加开阔,会更早就把问题串联起来进行分析。
第二:这个问题是可以提前预防和发现的,这要求就是多做几轮压力测试,然后再迁移上来。也可以考虑做灰度测试,开启两套程序,一套在生产上运行,一套在 ADG 上运行。
“庸医”对应的是“神医”,扁鹊在第一次见齐桓公的时候,就说出了:“君有疾在腠理,不治将恐深”。可见扁鹊厉害之处就在于他总能提前发现病情,防患于未然。当“君有疾在骨髓”的时候,扁鹊已经删库跑路了,根本就救不了齐桓公。
我一直认为,会解决问题不牛逼,能把问题扼杀在萌芽才是真正的牛逼,这就要求我们必须锻炼自己的大局观,把系统的整个架构,操作系统、网络、存储、数据库中间层、代理层及程序框架全面打通,就像武侠高手打通任督二脉一样。但这个靠个人学习是很难实现,至少就有 100 种产品等着我们去研究。
如何做到牛逼不苦逼?其实可以通过一些监控软件来实现大局观,虽然自己有些技术不懂,但通过监控知道哪里出现了问题,就可以联系人来解决。目前我所在公司就有 DPM 这样的数据库监控软件,有 IVORY 大数据日志分析平台,这些软件集成在一起就能帮助我迅速找出问题所在,并判断何为对的方向。
作者介绍:
袁伟翔,新炬网络高级专家,长期服务于运营商,精通 Oracle 数据库故障诊断、内核技术,具有 10 多年数据库开发运维经验。
原文链接:

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论 1 条评论