
10 月 25 日,第一届中国云计算基础架构开发者大会在长沙召开,星环科技与众多国内外厂商共同就“云原生”、“安全与容错”和“管理与优化”等云计算领域话题进行了深入交流和探讨。星环科技容器云研发工程师关于"基于 Kubernetes 的复杂工作负载混合调度器思考与实践"相关内容进行了分享,本文是对会议上内容的整理。
近年来,云原生的概念席卷了整个云计算领域,以 Kubernetes 为代表的云原生技术所带来的变革引发了企业深思,越来越多的企业逐步将基础架构向云原生架构迁移,业务应用也以遵从云原生十二要素标准进行开发部署。技术交付理念的变革同时也加快了企业数字化和智能化转型的过程。
云原生技术初期天然适合微服务架构,而随着整个云原生技术的快速发展和云原生基础架构的不断夯实,企业逐渐开始将传统大数据的分析型应用和计算型应用“搬上”云原生架构。至此,云原生基础架构作为企业内部的统一基础架构已成为必然趋势。然而,将云原生基础架构作为统一的基础架构也势必面临着基础平台整合后的兼容性问题,例如:传统大数据任务如何在云原生架构下进行编排和调度、大数据中所提倡的计算数据本地化如何在云原生架构下完美落地等。因此,虽然统一云原生基础架构是大势所趋,但依然有很长的路要走。
星环科技是云原生技术的早期实践者,为推动统一云原生基础架构进行了多方面探索,数据云平台产品 TDC 即是星环在统一云原生基础架构方面多年积累和实践的产物。TDC 覆盖了分析云、数据云、应用云三方面功能,在一个平台内满足企业对于三类云平台的建设要求,包含数据仓库、流式引擎、分析工具、DevOps 等应用,能够同时应对多样、复杂的工作负载场景。为此,星环科技底层云平台多年来做了不少工作,接下来就分享下我们在统一云原生基础架构下关于复杂工作负载混合调度器的思考与实践。
统一云原生基础架构
在统一云原生基础架构的概念出现后,如何解决多类型工作负载的编排和调度成为了一个亟待解决的问题,包括但不限于 MicroService、BigData、AI、HPC 类型的工作负载。对于 MicroService 则是云原生架构天然支持的,所以如何满足其余类型的工作负载的编排、调度是迫切需要解决的,典型的如 Spark、TensorFlow 等社区代表计算任务,HDFS、HBase 等大数据存储服务。而以 Kubernetes 为核心的开源社区针对这些需求也做了相应的尝试,比如通过 Spark
Operator 以及 TensorFlow Operator 等解决了任务编排的问题,但是调度相关的能力仍然有缺失的。除此之外还有一些大数据生态的企业级特性也是原生 Kubernetes 调度能力无法支持的。为此,我们针对如何解决在统一基础架构背景下 Kubernetes 所缺失的调度能力进行了调研和思考。
大数据 / AI 生态调度器
让我们来回顾下在大数据/AI 生态的相关调度器的特性,主要调研对象为 Mesos 和 YARN。
Mesos
Mesos 诞生于加州大学伯克利分校,后经开源后在 Twitter 被大规模使用,技术原型参考 Google 内部的调度器进行设计实现。Mesos 是一个具有两级调度架构的框架,其本身主要专注于做基于 DRF 算法的资源分配,具体提交的任务资源如何管控和分配则是由特定的 Framework 实现。因此,在如此灵活的架构下,开发者们有非常广阔的发挥空间。但是由于其自身并没有能够提供太多功能特性导致没有建立起相应的生态,使得越来越多使用者望而却步,转而寻求其他项目。Mesos 的特性总结如下:
两级调度架构,更加灵活
专注于基于 DRF 算法的资源分配
可自定义 Framework 来实现特定任务的资源调度和管理
支持在线、离线、HPC 类型任务调度
YARN
YARN 是 Hadoop 2.0 版本中发布的一款原生的资源管理和调度框架。随着 YARN 的发布,Hadoop 彻底确立了自己在大数据领域的核心地位,所有的大数据组件和服务均可以由 YARN 进行调度和管理。虽然其架构相比 Mesos 不够灵活,但是 YARN 相比 Mesos 有 Hadoop 强大的生态背书,其发展可谓顺风顺水,相关特性和能力也被企业所推崇,解决了企业中关于资源调度和管理的诸多问题。其特性总结如下:
单级调度架构,不够灵活
支持层次化的资源队列,可以映射多租户和企业组织架构
支持资源共享、弹性调度、公平调度
支持多种大数据任务编排调度
支持在线、离线、HPC 类型任务调度
Kubernetes 原生调度器
相比于大数据/AI 生态调度器,Kubernetes 原生调度器在微服务、无状态应用等领域具有得天独厚的优势,而在统一云原生基础架构背景下,Kubernetes 原生调度器所显露出的能力不足则被不断放大。下面列举了一些 Kubernetes 原生调度器的不足点:
不支持多租户模型下的资源调度
不支持大数据、AI 类型任务的调度
不支持资源队列
不支持资源共享和弹性调度
不支持细粒度资源管控
不支持应用感知调度
调度排序算法单一
Kubernetes 生态调度器
Volcano
Volcano(https://volcano.sh/zh/)项目是华为云开源的 Kubernetes 原生批处理系统,可以支持批处理任务调度,补足了 Kubernetes 原生调度器在这方面的能力缺失。Volcano 的架构如下所示:
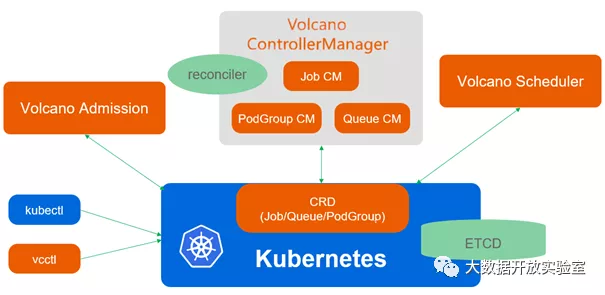
其主要特性包括但不限于如下:
支持批处理任务、MPI 任务、AI 任务调度
支持统一 Workload 定义,通过新增 CRD Job 来编排和调度不同工作负载
支持单一 Job 异构 Pod 模板定义,打破 Kubernetes 原生资源束缚
支持资源队列、资源共享和弹性调度
支持组调度、公平调度等多种调度策略
虽然 Volcano 项目本身足够优秀,提供了很多 Kubernetes 原生调度器不具备的新特性,但在统一云原生基础架构这样的背景下,仍然可能会存在一些限制,比如:
部署形式为如果多调度器形式(与 Kubernetes 原生调度器共存),则可能出现和原生调度器的资源调度冲突问题,因此更适合于在专有集群部署;
当前版本中不支持多级层次化的资源队列,使得在企业多租户场景下不能够很好的进行映射。
YuniKorn
YuniKorn(https://yunikorn.apache.org/)项目为 Cloudera 发起并开源的项目,定位于跨平台的通用调度器,其三层架构设计能够实现对底层多种平台的适配,当前可以支持 Kubernetes,YARN 的支持还在开发中。YuniKorn 项目的诞生是为了能够实现批处理任务、长时运行服务以及有状态服务都可以由统一调度器调度。YuniKorn 的架构如下所示:
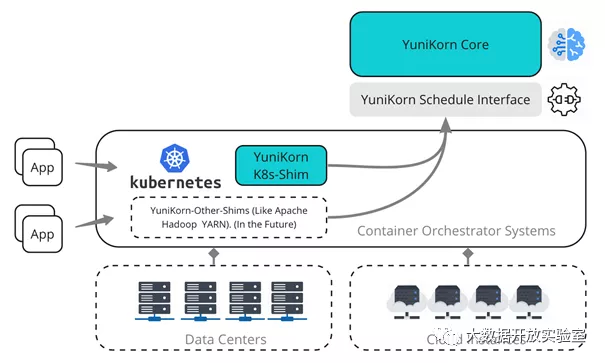
其主要特性包括但不限于如下:
架构设计灵活,可以实现跨平台
支持批处理任务、长时运行服务、有状态服务调度
支持层次化的资源池/队列定义
支持队列间的资源公平调度
支持基于公平策略的跨队列的资源抢占
支持 GPU 资源调度
YuniKorn 项目创建之初也是调研了如 kube-batch(Volcano 中的核心功能实现)这样的项目后进行设计,因此设计层面相比 kube-batch 多了一些考虑,优秀的设计进一步也为统一调度器的实现奠定了基础。但由于其 shim 层为适配各个底层平台需要不断补齐这一层的能力,以此来跟上社区的节奏,因此也不能算是完全兼容 Kubernetes 原生的调度器。
Scheduling Framework v2
在 Kubernetes 生态发展火热的同时,社区也没有停下脚步。从 Kubernetesv1.16 版本开始引入新的 Scheduling Framework,从而进一步解放对于调度器的扩展能力。核心思想是将 Pod 调度过程中的每个环节都尽可能插件化,并把原有的调度算法/策略全部用插件的形式重写,从而来适配新的 Scheduling Framework。扩展点如下图所示:
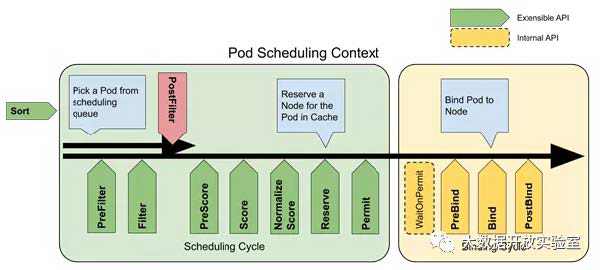
基于这样的扩展能力,社区兴趣小组也发起了 Scheduler-Plugins(https://github.com/kubernetes-sigs/scheduler-plugins)项目,来呈现出基于 Scheduling Framework v2 可以实现哪些 Kubernetes 原生调度器不具备的能力。当前已经实现了如 GangScheduling、ElasticQuota、CapacityScheduling、LoadAwareScheduling 等插件。开发者可以直接基于该项目编译 scheduler 或将该项目插件引入自定义的 scheduler 进行编译,从而保证既能完全兼容 Kubernetes 原生调度器的全部能力,又可以享受到扩展插件带来的好处。
TDC 中的思考与实践
在统一云原生基础架构背景下,TDC 也面临着如何解决多种工作负载混合调度的问题。基于对开源社区相关项目的调研和 TDC 自身痛点的思考,针对调度器提出了如下需求:
全局唯一的调度器,防止资源调度冲突
支持多租户场景下的资源调度
支持多种工作负载的合理调度
支持资源共享和弹性调度
支持细粒度的资源管控
支持多种调度算法
支持应用感知调度
支持多种调度策略
结合上述 Kubernetes 生态调度器的发展和现状,我们基于社区原生的扩展能力 Scheduling Framework v2 设计了一款适合 TDC 需求场景的调度器 -- Transwarp Scheduler。
Transwarp Scheduler 设计
借鉴社区优秀开源项目的设计思想,Transwarp Scheduler 中有两个核心:一是完全基于 Scheduling Framework 进行扩展实现,保证对社区原有能力的完全兼容性;二是在此基础上进行抽象封装,增加资源队列的定义来满足 TDC 在资源调度层面的功能需求。而为减少用户在使用 Transwarp Scheduler 时的迁移和学习成本,Transwarp Scheduler 中没有增加新的 Workload 相关的 CRD。
资源队列
资源队列是一个 CRD,我们将其命名为 Queue。其具有如下特性:
支持层次化定义
支持队列间按权重资源共享
支持队列间的资源借用和回收
支持队列间的公平调度
支持队列内的细粒度资源管控
支持队列内的多种排序算法
通过这样的资源队列定义,可以利用其层次化定义能力来模拟企业多租户场景中的资源配额管理,并做到共享和弹性配额,以突破原生 Kubernetes 中所支持的 ResourceQuota 的硬配额限制,实现更细粒度的资源管控。同时,每个队列内部又可以指定精确的排序算法,从而满足不同组织部门的特定需求,在支持原生 Kubernetes 调度器能力的基础上不断补齐在大数据/AI 场景下通常需要的资源队列的调度管理能力。为了可以在调度过程中将 Pod 的调度和资源队列进行关联,我们通过扩展 SchedulingFramework 的插件来实现,主要插件如下:
QueueSort 插件: 实现 Sort 扩展点,根据 Pod 所属 Queue 的排序算法进行排序,默认不同队列之间基于 HDRF 算法进行公平调度。
QueueCapacityCheck 插件: 实现 PreFilter 扩展点,对 Queue 的资源使用情况进行检查和预处理。
QueueCapacityReserve 插件: 实现 Reserve 扩展点,对确定使用 Queue 的资源进行锁定;实现 UnReserve 扩展点,对调度/绑定失败但是已经锁定的 Queue 资源进行释放。
QueuePreemption 插件: PostFilter 扩展点,实现资源回收时的抢占功能。
资源队列绑定
除了资源队列的 CRD 外,我们同样新增资源队列绑定的 CRD,命名 QueueBinding。之所以添加 QueueBinding 是为了使得资源队列的定义只专注于资源调度层面工作,而不必去关注和 Kubernetes 的资源本身关联性,如资源队列和哪个命名空间绑定、资源队列允许提交多少个 Pod 等。这样的限制条件本身并不是资源队列关注的,如果尝试耦合在资源队列中定义,将使得资源队列的控制器代码增加相应的变化处理。而通过 QueueBinding 这样的 CRD,可以使得资源队列从 Kubernetes 资源相关性中解耦出来,这部分的限制检查逻辑则由 QueueBinding 的控制器来完成。Queue、QueueBinding 和 Kubernetes 资源的关系如下所示:
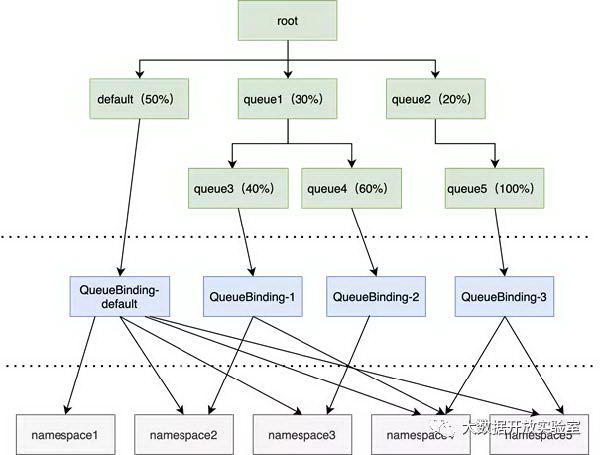
大数据/AI 调度能力扩展
基于上述引入的资源队列,我们在资源层面上进行更加精细完善的控制。但仅有资源管控是不够的,还需要有面向特定工作负载的调度策略,尤其是原生 Kubernetes 调度器并不专长的大数据/AI 领域。下述章节我们将以大数据/AI 领域主流的计算框架 Spark 和 TensorFlow 的工作负载为参考,简要说明在 Transwarp Scheduler 中实现相应的调度策略。
TensorFlow 作业调度
开源项目 KubeFlow 中的 tf-operator 解决了 TensorFlow 作业如何在 Kubernetes 中进行编排的问题,使得用户可以方便快捷的在 Kubernetes 中建立起单机或者分布式的 TensorFlow 作业运行。但是在 Pod 调度层面仍然有可能因为资源不足导致部分 TensorFlow 的 Worker Pod 被调度,而另一部分处于 Pending 状态等待资源。TensorFlow 框架本身由于 Worker 不能都同时启动运行,将导致整个训练任务 hang 住无法执行,因此造成了资源浪费。类似问题实际是因为在 Kubernetes 中缺乏 GangScheduling 的调度机制导致,无法实现作业的全部 Pod 要么都调度要么都不调度,从而将资源留给真正可以调度起来的作业。
为了弥补这样的能力缺失,kube-batch、Volcano、YuniKorn 等项目中都对 GangScheduling 的调度策略进行了实现,并对 TensorFlow 在 Kubernetes 的工作负载定义进行了适配,使得可以在应用对应的调度器时调度策略生效。同样的在 scheduler-plugins 项目中也对 GangScheduling/CoScheduling 相关调度功能进行了实现。在 Transwarp Scheduler 中参考上述几个项目实现的特点,通过扩展 QueueSort、PreFilter、Permit、PostBind 等插件来补足了 GangScheduling 的能力,以满足 TensorFlow 类型任务的调度需求。
Spark 作业调度
Spark 项目同样有开源的 spark-operator 来解决其在 Kubernetes 上的编排问题,之所以 Spark 可以实现在 Kubernetes 上的运行,是因为 Spark 社区从 2.3 版本开始引入了 Kubernetes 作为 ResourceManager 的支持。但无论原生 Spark 对接 Kubernetes 的方式还是 spark-operator 部署 Spark 作业的方式,都和 TensorFlow 有相似的资源等待造成资源死锁或者浪费的问题。比如同时多个 Spark 作业提交,同一时间启动的 Spark 作业的 Driver Pod 把资源全部用尽,直接导致所有的 Spark 作业没有一个可以正常执行完成,造成了资源死锁问题。
该问题的解决方案类似 TensorFlow 的 GangScheduling 的调度策略,必须达成 All-Or-Nothing 的条件,不过 Spark 作业本身并没有要求所有的 Executor 必须全部启动才能开始计算,因此只需要保证至少有多少 ExecutorPod 可以调度时才能运行,否则 Driver Pod 也不应该被调度,从而做到有效且高效的调度。在 Transwarp Scheduler 中,通过在实现 GangScheduling 的基础上增加一定可变条件,从而满足 Spark 的作业调度。
Transwarp Scheduler 架构
根据上面的设计概述,Transwarp Scheduler 的架构和内部交互如下所示:
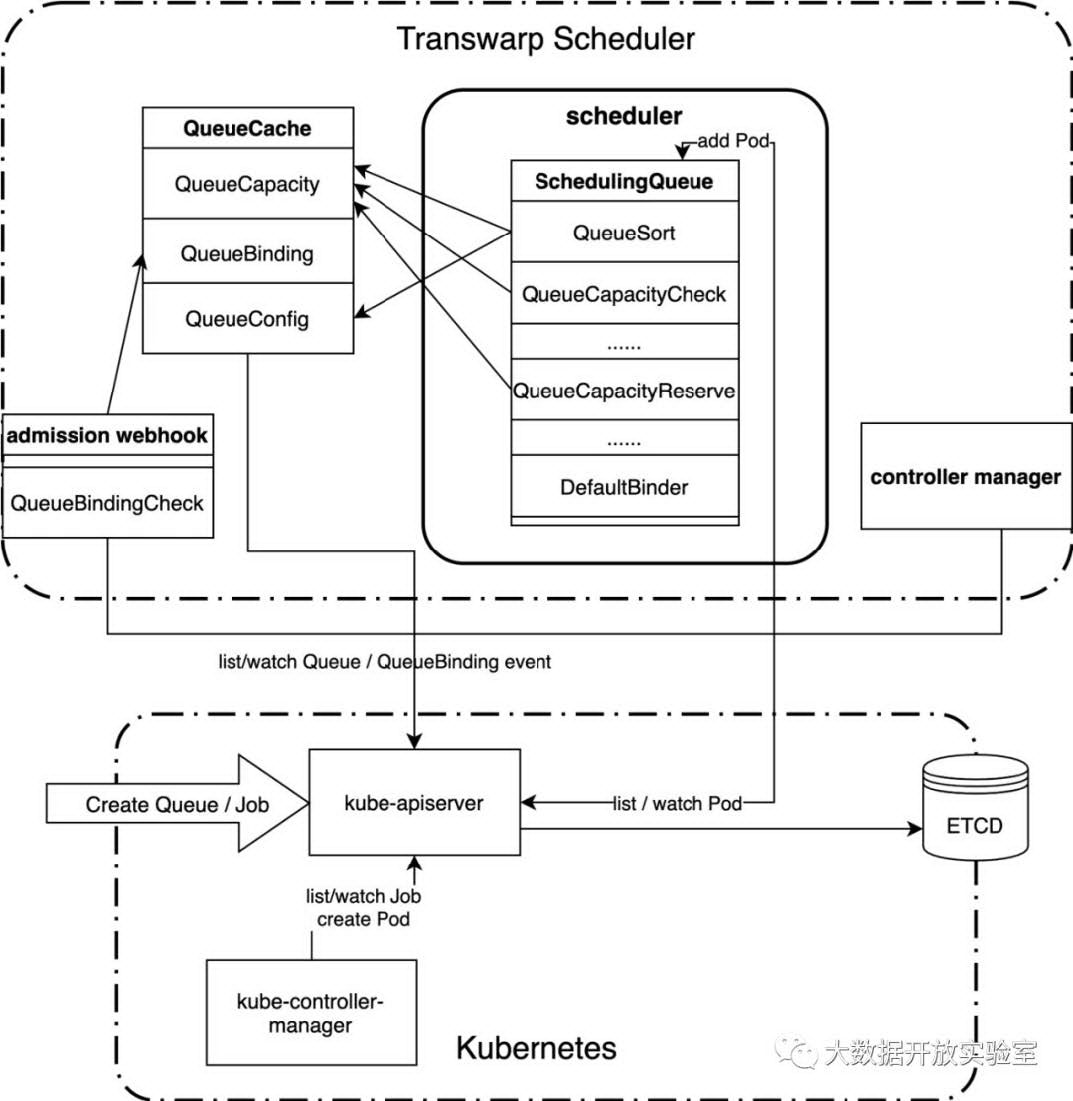
整个 Transwarp Scheduler 由三部分组成:
Scheduler: 基于 Scheduling Framework 实现调度器相关的核心功能,调度策略插件扩展均编译到 Scheduler。
Controller Manager: 新增 CRD Queue 的控制器和 CRD QueueBinding 的控制器。
Webhook: 新增 CRD Queue 的 admission webhook 扩展点和 CRD QueueBinding 的 admission webhook 扩展点。
未来展望
基于上述设计和实现,目前 Transwarp Scheduler 已经可以满足 TDC 产品诸多需求,解决了原生 Kubernetes 调度器无法支持的痛点,并会在后续的 TDC 版本中一同发布。除此之外,Transwarp Scheduler 将会不断探索一些更 High Level 的调度策略,如应用感知、负载感知等调度策略,也会积极采纳和吸收社区的意见并将一些通用的设计和实现反馈社区。
云原生的概念已被提出多年,伴随着生态的快速发展,其概念也在不断的被重新定义。星环科技的数据云平台产品 TDC 在云原生的浪潮中也在不断探索前进,为打造世界级的数据云平台产品而不断前行。
本文转载自公众号大数据开放实验室(ID:gh_2362567b4e0e)。
原文链接:




