

1 背景
起初,在网盘快速发展期,为了快速上线,采用了服务单体化 + 主干开发模式进行研发,随着用户规模爆发式的增长以及产品形态的丰富,单体化的不足就体现出来了,于是架构上采用了微服务架构,开始对业务逻辑进行拆分部署。
服务拆分之后,也引入了新的问题,具体如下:
请求路由:服务部署从物理机向虚拟化方式迁移中,有大量的切流量操作,需要相关的上游都进行升级上线修改,效率低下;
故障管理:单实例异常、服务级别异常、机房故障异常、网络异常等,严重缺失或者不完善,同时配套的故障定位也没有,服务稳定性不足;
流量转发:不同的服务采用了不同的框架,甚至裸框架,策略不完善,导致负载不均衡;
研发效率:相同的功能点,需要在不同的语言框架上实现一次,浪费人力,同时升级周期比较长,收敛效率低
2 解决方案 - UFC
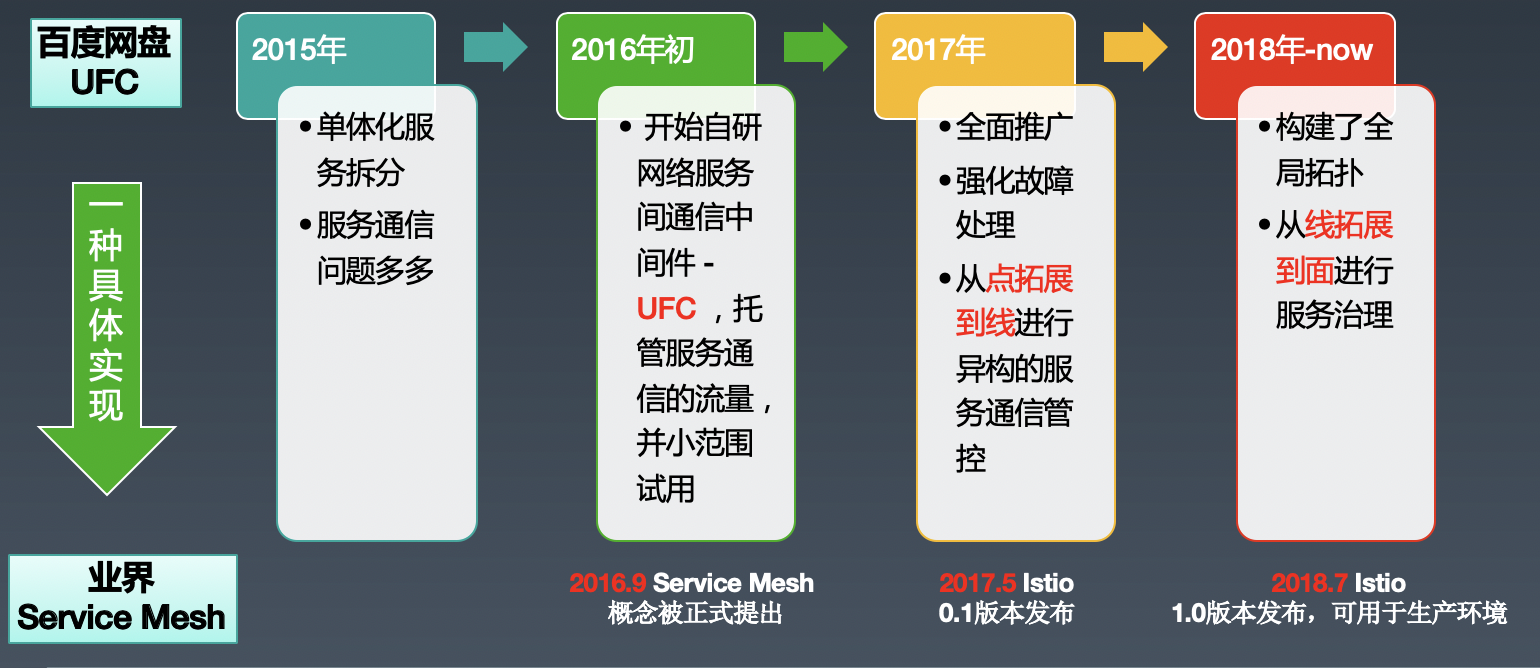
2.1 UFC 发展史
为了解决这个问题,从 2015 年底开始思考解决方案,确定了解决问题的核心在于管控请求流量,在 2016 年开始自研网络流量转发中间件 - UFC(Unified Flow Control),业务通过同机部署的 agent 进行服务通信,相关的发展史如下:
2.2 UFC 和 Service Mesh 的关系
后来在调研业界相关技术的时候,发现了 istio(业界 Service Mesh 的典型代表),从而发现了 Service Mesh 的存在,而它的定义是在 2016.9 由 Buoyant 公司的 CEO William Morgan 提出的:
Service Mesh 是一个专门用来处理服务和服务之间通信的基础设施。它负责确保在一个由复杂服务构成的拓扑的现代云应用中,请求能够被稳定的传递。在实践中,Service Mesh 通常通过一系列轻量级的代理来进行实现。这些代理和应用同机部署,而应用不需要感知到代理的存在。
A service mesh is a dedicated infrastructure layer for handling service-to-service communication. It’s responsible for the reliable delivery of requests through the complex topology of services that comprise a modern, cloud native application. In practice, the service mesh is typically implemented as an array of lightweight network proxies that are deployed alongside application code, without the application needing to be aware.
从定义上,我们不难发现 UFC 和 Service Mesh 的设计理念是一致的,都是基于 sidecar 模式,有着控制面板和数据面板,UFC 是 Service Mesh 的一种实现。感慨的说,历史的发展潮流是一致的,不管你在哪里。
目前 UFC 应用于网盘过千个服务上,涉及虚拟化实例数量超过 20W,千亿 PV,机器规模 10W+(网盘+其它产品线机器),10 个 IDC,从已知的实例规模上看,是国内最大的 Service Mesh 的实践落地。
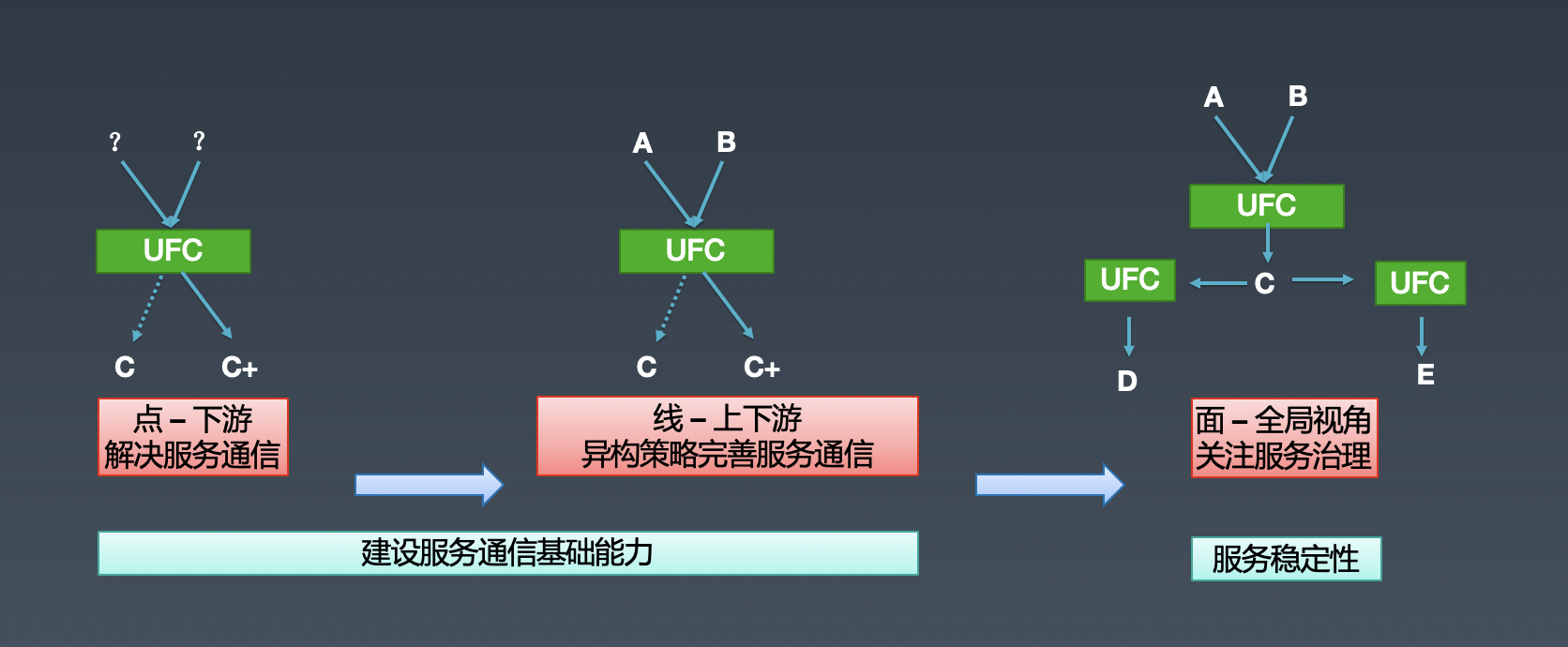
2.3 基于 Service Mesh 之上的服务治理
百度网盘的实践落地并不只局限于 Service Mesh,首先是构建了从点延伸到线的 Service Mesh 进行服务通信管控,然后是在 UFC 这个 Service Mesh 的基础之上,站在全局视角对服务进行治理,保障服务的稳定性,相关能力等发展如下:
点:关注与下游进行通信,不关注上游的情况;
线:加入上游的标识,基于上游做异构的通信策略;
面:多条线组成面,站着全局视角进行服务治理;
2.4 本文概要
本文将会先介绍 UFC(如何实现一个 Service Mesh),然后是基于 UFC 做服务治理(基于 Service Mesh 的实践应用)
3 UFC 外部视角简介
3.1 用户使用视角
只需要做两个事情:
服务注册:需要先确保自己的服务(上游)和要访问的服务(下游)已经注册过了,没注册过,则需要服务的 owner 进行服务注册;
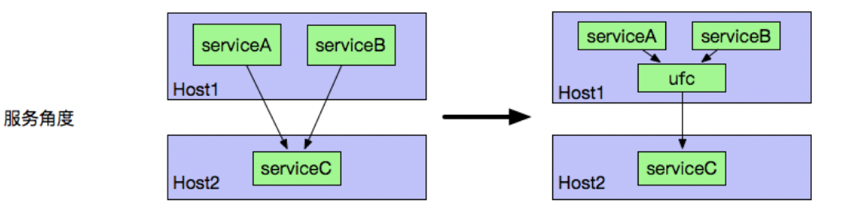
服务通信:用户通过单机 agent 进行服务通信访问下游,下图显示了用户从直接访问下游变成了通过同机 agent 访问下游
3.1.1 服务注册
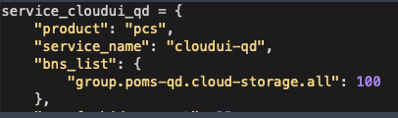
UFC 为每个注册的服务分配一个 service_name,service_name 是这个服务的唯一标识。同时需要对这个 service_name 配置它的相关配置:比如 destination 来源、负载均衡、熔断、超时重试等策略
3.1.2 服务通信
访问下游的时候,只需要访问本机固定端口,带上下游服务的 service_name、自身标记、trace 等信息,例如下面就是一个发请求的 demo 例子:
3.2 UFC 能力视角
介绍 UFC 基于点和线视角的相关能力,从服务声明、请求路由、流量转发、故障处理、故障定位、安全等维度和 istio 做了一个比较。而 istio 是大部分是基于下游这个点进行相关通信能力设计,线视角能力很少(比如权限认证等)
总结来说,istio 是能力全面,但是具体实现上策略比较简单,而 UFC 是更贴近实际的业务场景(具体的可以看后面的介绍内容)
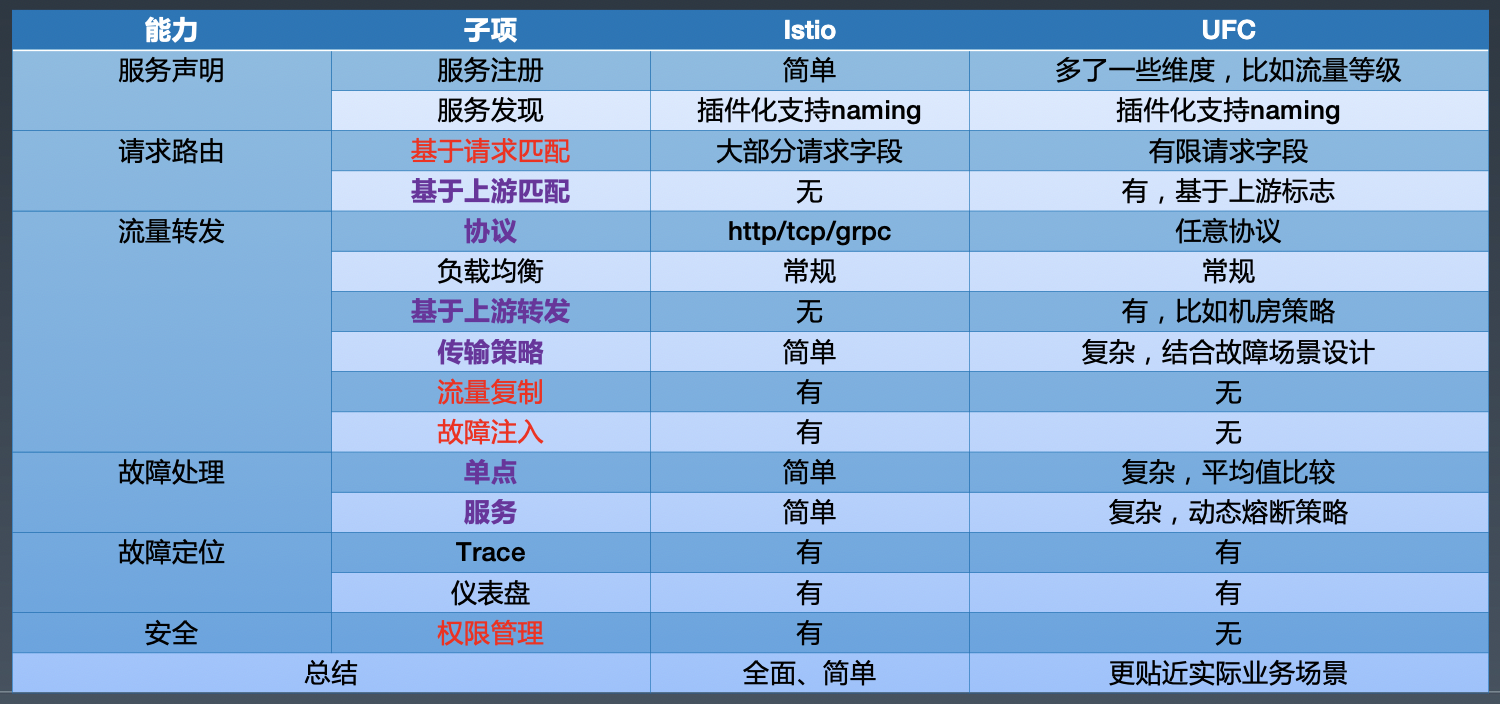
PS: 有些能力(比如流量复制/权限管理)UFC 没有,并代表百度网盘没有这方面的能力,只是因为历史原因,通过其它的方案解决了。但是故障注入这块,的确是 UFC 需要考虑的,有了这块的能力,混沌工程也更容易的落地。
4 UFC 内部视角简介
主要是介绍架构和相关具体能力的实现设计初衷
4.1 架构设计
整个架构和 Service Mesh 一样,都是采用了同机 Sidecar 进行了流量的转发 + 中心化控制。
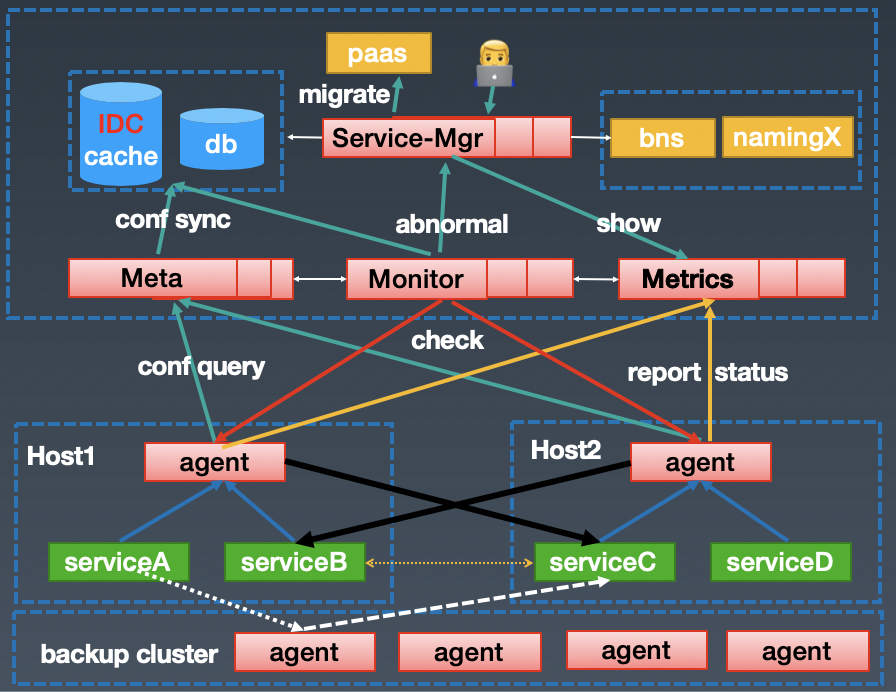
4.1.1 核心流程图
UFC 组件
Service-Mgr: 服务(实例)管理,提供服务的增删改查(存储到 db + cache)。定期从 naming 服务拉取 destination 列表,写入 cache(多个 idc cache)。此外还会和 paas 进行协作(比如通知 paas 迁移异常的实例);
Agent:每台机器部署一个,四个功能:1)通信代理:为服务提供通信代理 2)配置同步:从同机房的 meta 模块同步配置 3) 上报:异常和统计数据 4)系统异常监控:接收中心的监控检测,包括 agent 存活和配置同步时效性;
Meta:提供服务配置元信息的查询,多个 IDC 地域部署;
Monitor:worker 模式,定期发起监控系统和业务是否存在异常,系统层面监控单机 agent 存活率/配置同步等,业务层面监控异常实例/服务等;
Metrics:聚会后的数据,数据来源来 agent 和 monitor;
4.1.2 相关设计说明
4.1.2.1 高可用
服务单点
Agent: 单机 agent 肯定会挂断,解决思路是基于如何避免请求受损出发点,1) 基于 backup 集群临时访问:业务使用 sdk 进行访问的时候,当访问本机 agent 失败之后,会通过访问远端的 backup agent 集群进行访问下游 2)基于探活屏蔽+修复: Monitor 会检测单机 agent 的存活性,当单机 agent 异常的时候,Monitor 会通知 meta 服务屏蔽单机上的实例,避免上游访问该机器,同时进行 agent 修复;
Meta: 每个 IDC 独立部署,另外 IDC 内部通过多实例 + 无状态设计解决单点问题;
Monitor: 每个 IDC 独立部署,另外 IDC 内部通过多实例 + 分布式锁互斥设计解决单点问题;
Metrics: 多实例,前面有一层 proxy,将 service 进行一致性 hash 进行服务拆分,单机统计聚合数据;
Service-Mgr:多实例 + 无状态设计解决单点问题;
IDC cache:当某个 IDC 的 cache 异常之后,通过 Meta 切换读取 backup IDC 的 cache 解决
机房链路故障:
会导致配置更新异常,解决方案是通过接入层将 IDC 流量切空,不在 UFC 这层考虑解决问题
业务实例异常:
除了通过 UFC 自身的故障屏蔽解决之外,还会联动 paas 将长期处于异常的实例通过迁移恢复,实现异常处理的闭环
4.1.2.2 扩展性
paas 扩展性:很容易融入不同的 paas 平台,只需要兼容不同的 naming 系统即可。
业务协议:支持任意业务协议,通过 bypass 旁路式解决(后面的能力会进行相关介绍)。
4.1.2.3 监控
系统:各种系统的异常点,比如单机 agent 的存活和配置同步情况,中心配置定时器同步。
业务:服务单点异常、服务实例存活率、服务 sla 等业务指标仪表盘监控。
4.1.2.4 配置同步
单机上的配置是全量的,通过版本号进行增量同步(全局的版本号+服务级别的版本号),同时会通过 monitor 监控配置是否同步成功
4.1.2.5 具体实现
数据面板:基于 OpenResty 开发。从理论角度:nginx 转发性能本身就好,同时在 2016 年的时候 Go 的 gc 问题还比较严重,从实际压测:OpenResty 要优于 Go。
控制面板:基于 Go 开发,比较好实现并发编程。
4.1.2.6 实时 debug
对于一个实时运行的系统,如何实时获取相关的 stat 数据,用于问题定位呢?比如想获取当前封禁后端列表之类的。
为了满足需求,增加了一个获取数据的接口,获取内存里指定字段的数据,以^为分隔符。比如以下 demo 就获取了一个服务的动态数据,包括了请求次数,更新时间,失败次数等信息。
4.2 功能设计
主要介绍 UFC 基于点和线的相关能力细节以及设计出发点
4.2.1 请求路由
提供相关的匹配能力,根据匹配条件进行后续相关的操作,比如设置后端的权重等进行多版本灰度测试、流量迁移等功能。
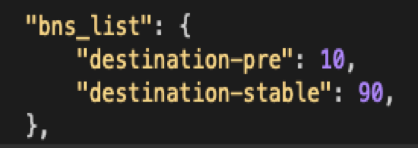
4.2.1.1 基于请求匹配
基于请求特征做路由匹配,例如 http request header: headers[“x-http-flow-control”],可以按随机比例 或者 等价 进行匹配
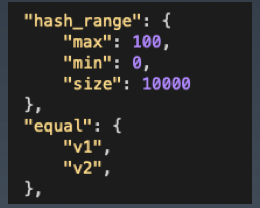
类似于 istio 的路由规则

4.2.1.2 基于上游匹配
基于上游匹配是从线视角出发,UFC 的线视角如下:
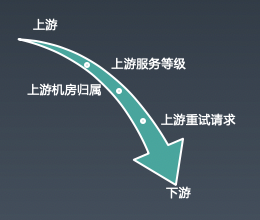
为啥要做基于上游匹配,出发点如下:
流量等级:
不同的上游服务重要性也不一样,产生请求的重要性也不一样,于是基于上游的标志设置异构的策略就很有必要。比如网盘的用户文件列表展示服务和多端列表同步服务一样会访问数据库,显然前者比后者重要,用户直接感知,需要区别对待。而如果是重试请求,这里面的重要性又不一样了,为了简化策略配置,目前在将请求权重化,根据若干个请求因素的计算出请求权重,然后根据请求权重执行不同的策略。
具体的实践落地:请求权重可以用于细粒度的降级策略。
机房策略:
上游访问下游,默认是不关注上游请求的来源机房,也不关注下游 endpoint 的机房归属,流量在机房之间是混连的,那么当时候,要切空机房流量异常麻烦。基于上游请求的机房的标识设置机房路由规则就很有必要了。
具体的实践落地:可以定制机房转发策略,比如流量在同一个物理 或者 逻辑机房内转发,详见下文流量转发里的基于上游转发。
4.2.2 流量转发
从协议、负载均衡、基于上游转发、传输策略四个方面介绍
4.2.2.1 协议
Istio 只支持 http/tcp/grpc 协议,而业务使用的协议肯定不止这些协议,比如 redis/mysql 等,如果都支持这些协议以及后续的其它协议,那么兼容的研发成本将非常的高,在用户需求和研发成本之间,UFC 找到了折衷的解决方案实现了支持任意协议,具体上是以穿透式和旁路式进行落地的。
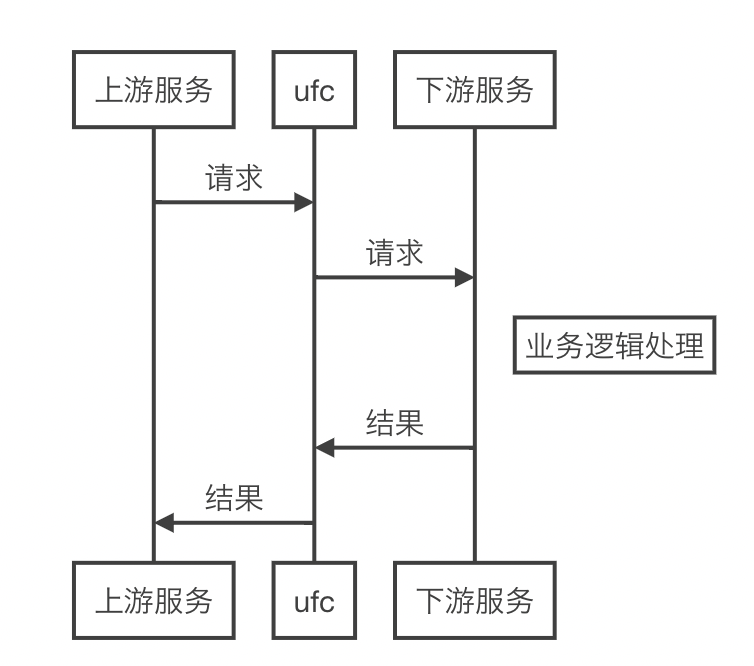
穿透式请求: 适用场景为 http 协议控制流,和 istio 的使用方式一样
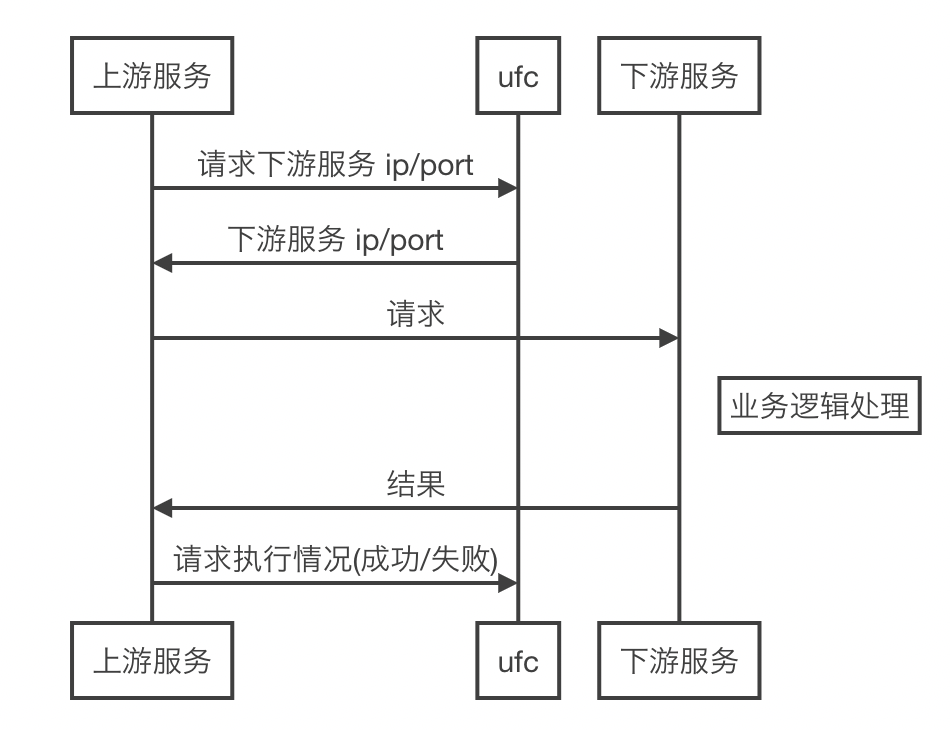
旁路式请求: 加强版的 DNS,适用场景为 http 协议数据流 or 非 http 协议,业务先从 UFC 拿到一个后端地址,然后业务自己通过这个后端地址访问后端,最后需要回调 UFC 告知 UFC 这次通信的结果,方便 UFC 更新相关数据(比如该后端的访问成功率等,决策是否需要封禁之类的)。通过旁路式解决了任意协议的场景,同时对后端流量进行了管控。
4.2.2.2 负载均衡
采用了比较常见的负载均衡策略,比如轮询、随机、一致性 hash(根据业务定义的字段进行 hash)
4.2.2.3 基于上游转发
主要的应用在于上下游 IDC 流量路由上,比如设置完下面的路由表之后,就实现了同(逻辑/物理)机房的流量转发:

4.2.2.4 传输策略
主要是从连接策略、超时策略,重试策略介绍的
连接策略:
上游:短连接、长连接
下游:短连接、长连接
超时策略:
基本功能:设置与下游的连接/读写超时,可以被上游请求里的指定参数覆盖超时时间。
自动切换:两套超时策略配置,结合故障处理自动切换。常规下 T1 超时策略(客户端可覆盖),雪崩下 T2 超时策略。当雪崩的时候自动切换到 T2 超时策略。这样既可以照顾到常规情况下的请求长尾,又避免了雪崩等场景下下游服务拖跨上游访问。
重试策略:
什么场景下重试:需要分清楚重试的边界。从功能角度看,Service Mesh 的功能是保障服务通信成功,所以 UFC 只在与后端通信失败场景(连接/写/读失败)下才重试,对于业务语义层面的错误,由业务发起重试,UFC 不介入重试逻辑。另外,从性能的角度出发,也不该把业务层面的重试下沉到 Service Mesh 这个基础组件上来,因为涉及到对返回的 body 做反序列化,这个会影响其它的请求,增加请求耗时。
基本功能:设置与下游交互失败的重试次数。
自动切换:两套重试策略,结合故障处理自动切换。常规下重试,雪崩下不重试,当雪崩的时候自动切换到不重试。这样既可以照顾到常规情况下少量的异常,又避免了雪崩等场景下加剧下游的雪崩,减少无意义的重试请求。
4.2.3 故障处理
从故障的范围影响上分成:
单点故障:少量后端异常,比如进程因为 oom 挂掉 或者 因为机器异常导致进程异常。
服务级别故障:当多个单点故障之后,就引发了服务级别的故障,比如服务雪崩。另外业务自身异常(比如全部返回 5xx)不在处理范畴内。
从故障处理流程上分成:
发现故障: 怎么定位故障的发生,包括单点/服务级别故障。
处理故障:怎么处理使得单点/服务故障能够恢复。
4.2.3.1 单点故障
故障处理具体发现故障和解决故障两方面的内容,难点在于发现单点故障的准确性,是否存在漏判。
发现故障
基于请求:
单次异常:连接异常(连接超时/拒绝/Reset 等)、读写异常(读写超时等)
判断标准:N 次请求里 M 次请求异常
基于业务:
业务维度:http status code、耗时等
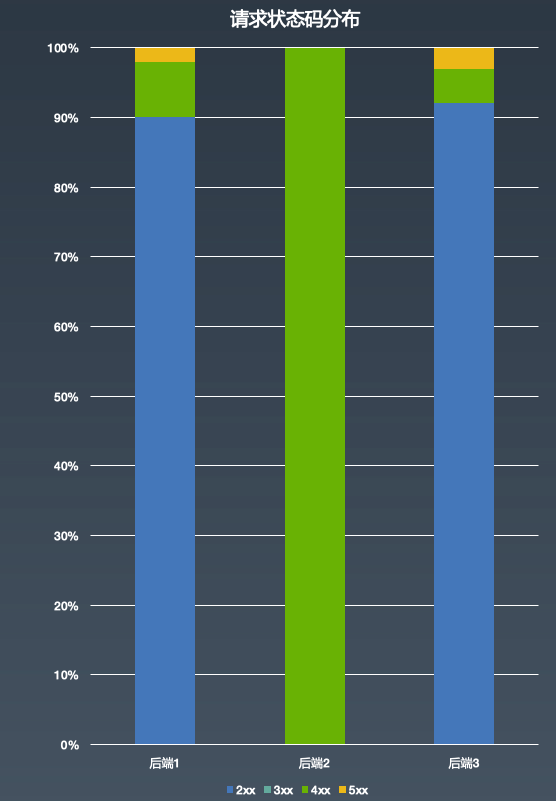
判断标准:单个后端和平均值(算平均值的时候需要排除掉比较对象的数据)做比较,看哪个后端严重偏离平均值,比如状态码区间比例之类的。这里没有采用单次异常判断是因为有些场景下,通过单次请求是无法判断为异常的,比如一个后端返回 404 的 http status code,这个是符合预期的?没人知道,因为常规情况下业务也会返回 404,而在 LNMP 架构里,如果单个实例磁盘问题导致 PHP 文件丢失,Nginx 找不到 PHP 文件,也会返回 404,这是一个混沌的状态。UFC 的解决方案,就是和平均值进行比较,看是否偏离平均值。以 下图后端状态码区间比例统计为例子,后端 2 4xx 的 http code 达到了 100%,而其它的后端这个比例也只有不到 5%,那么大概率后端 2 就存在问题。
解决故障
处理:初始封禁 T 时间
封禁收敛:后端连续封禁时间翻倍,解决异常后端被反复解封、封禁的场景
封禁闭环:长时间封禁的后端,通知 paas 进行异常实例的迁移
封禁 backup 机制:达到最大封禁比例,通知人工介入处理
恢复:当封禁时间到了之后,检测端口是否可用,可用则解封
4.2.3.2 服务故障
主要是针对雪崩过载的场景下如何尽量保障服务可用,也是从发现故障和解决故障进行介绍的,难点在于如何减少故障带来的业务流量损失。
发现故障
基于通信成功率:下游服务 N 次请求里成功率低于 X%
基于业务语义成功率: UFC 没采用的原因是不能越俎代庖做自己能力之外的事情,Service Mesh 核心在于流量控制,它的能力是流量控制来避免下游过载,防止雪崩,例如业务代码 bug 导致的成功率下降,Service Mesh 也没有办法。

解决故障
PS: 动态熔断的思想是借鉴了网络,当雪崩过载的时候,相当于发生了请求的拥塞,和网络拥塞是一样的特征行为,网络链路都带宽相当于服务的容量
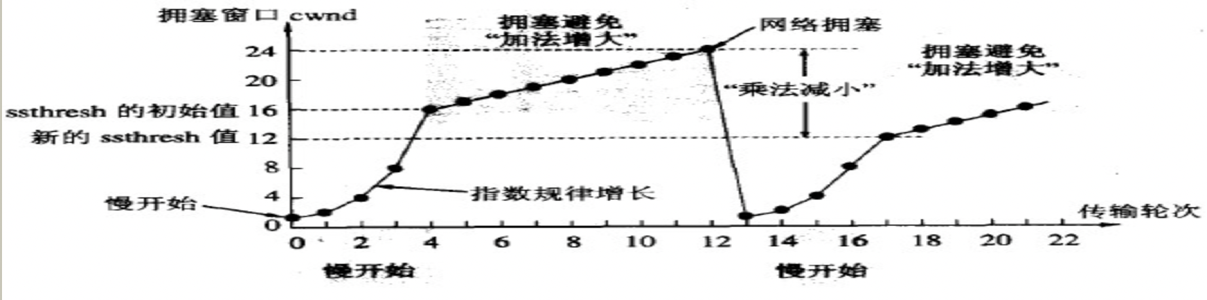
4.2.4 仪表盘
仪表盘基于数据源进行分析得到以下内容:
分布式服务的日志追踪;
业务度量数据的收集/分析/展示。
4.2.4.1 数据源
有两方面的数据源:
服务通信 access 日志:通过日志传输进行聚合分析。
何时由上游 A 对下游 B 进行访问,请求通过了后端 X1/X2 进行访问,重试了 N 次,耗时为 T1/T2 等,状态码为 S1/S2 等,
异常行为:业务层面比如服务熔断等,系统层面比如封禁计数器异常等,由 agent 实时上报到中心做聚合分析
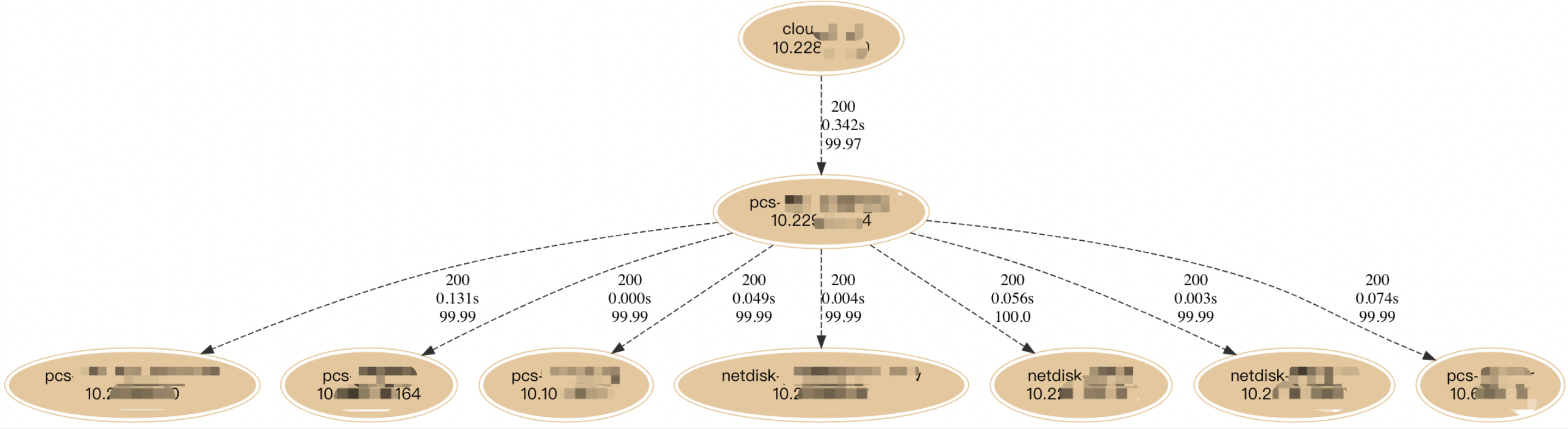
4.2.4.2 distributed traces
首先基于服务通信 access 日志做链路分析,然后将链路信息存入 Elasticsearch 方便检索,比如下图就是一个链路检索
4.2.4.3 metrics
从点、线、面视角上进行数据的聚合分析。
点视角:后端维度
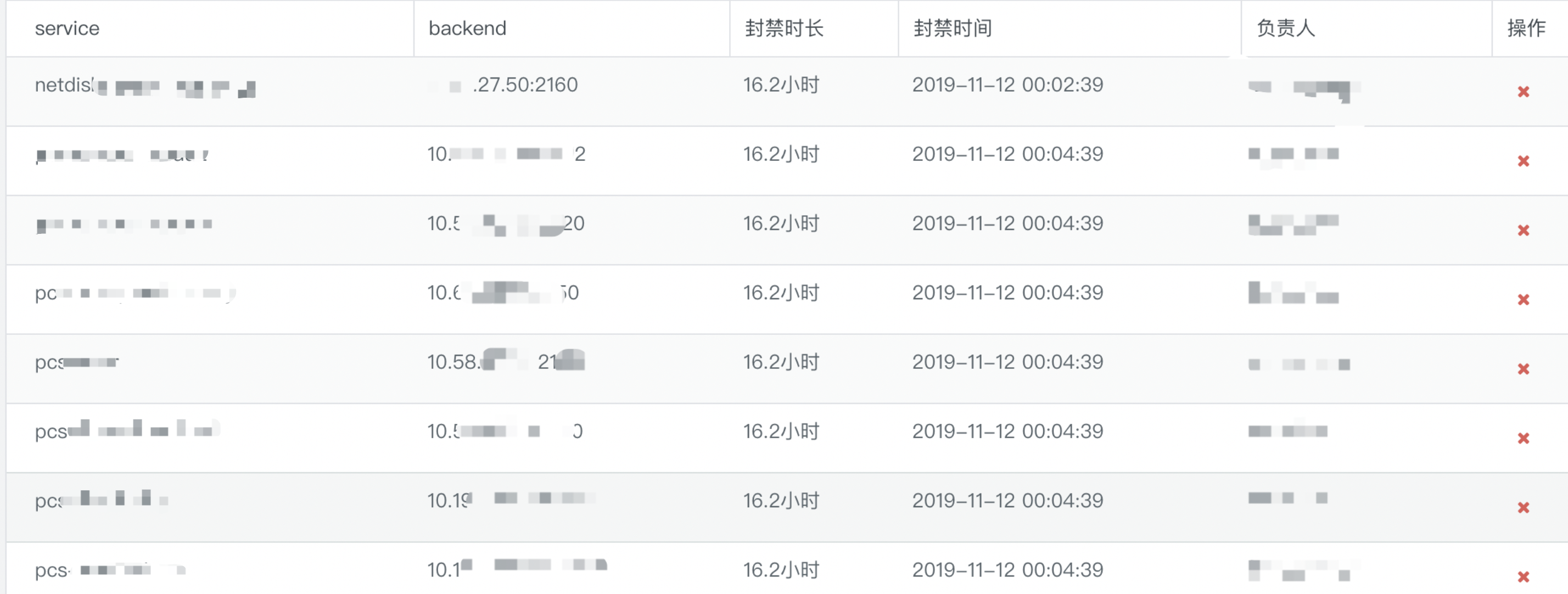
服务后端异常监控:
单实例异常触发封禁:触发封禁的后端,长时间封禁走 paas 迁移流程。
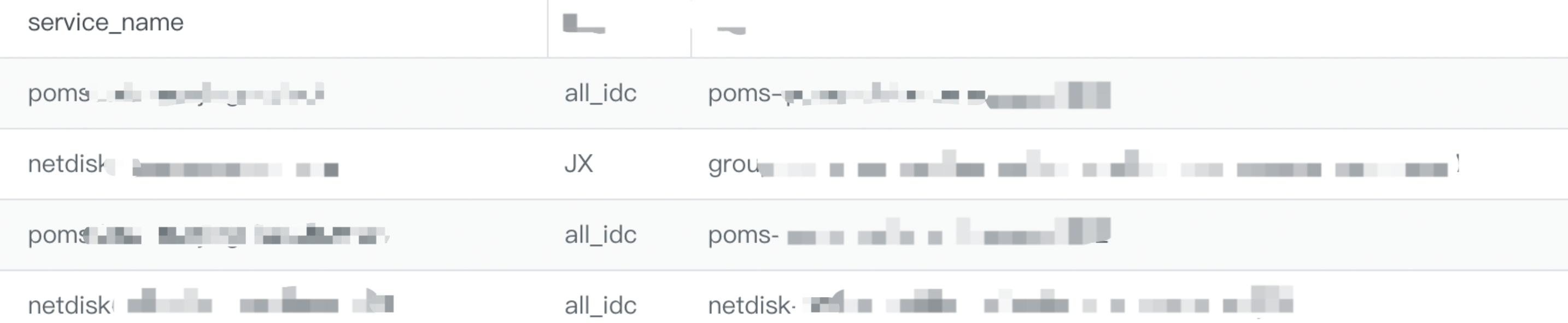
服务触发熔断:触发服务动态熔断降级。
线视角:上下游维度
服务下游监控:服务访问所有下游的概貌,支持按 http 状态码和 idc 做过滤,同时支持环比(昨天/一周前)。下面以视频转码为例子,展示对若干个下游的访问概貌。
请求数: 可以根据曲线分析是否存在异常。
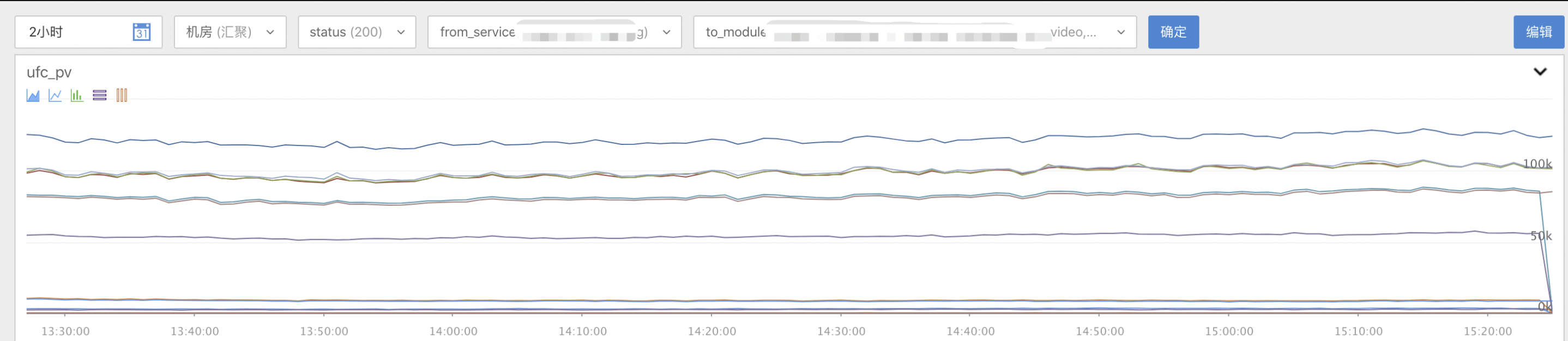
请求失败数:根据失败数量可以算出上游对下游的请求 sla

请求耗时: 可以比较昨天/上周的耗时数据,看是否存在异常

服务上游监控:服务被所有上游访问的概貌,可以按 http 状态码和 idc 粒度进行过滤,同时支持环比(昨天/一周前)。下面以一个异步化服务为例子,被一堆的上游访问,统计这些上游的访问概貌。
请求数: 在定位服务的请求数突增,可以很容易识别出是哪个上游导致的。

请求失败数:如果一些上游访问失败数比较高,可以联系业务进行分析定位。

请求耗时: 可以比较昨天/上周的耗时数据,看是否存在异常

面视角:全局视角
核心功能链路 SLA 监控:当链路 sla 降低的时候,可以很快定位到是哪个链路分支出现的异常。
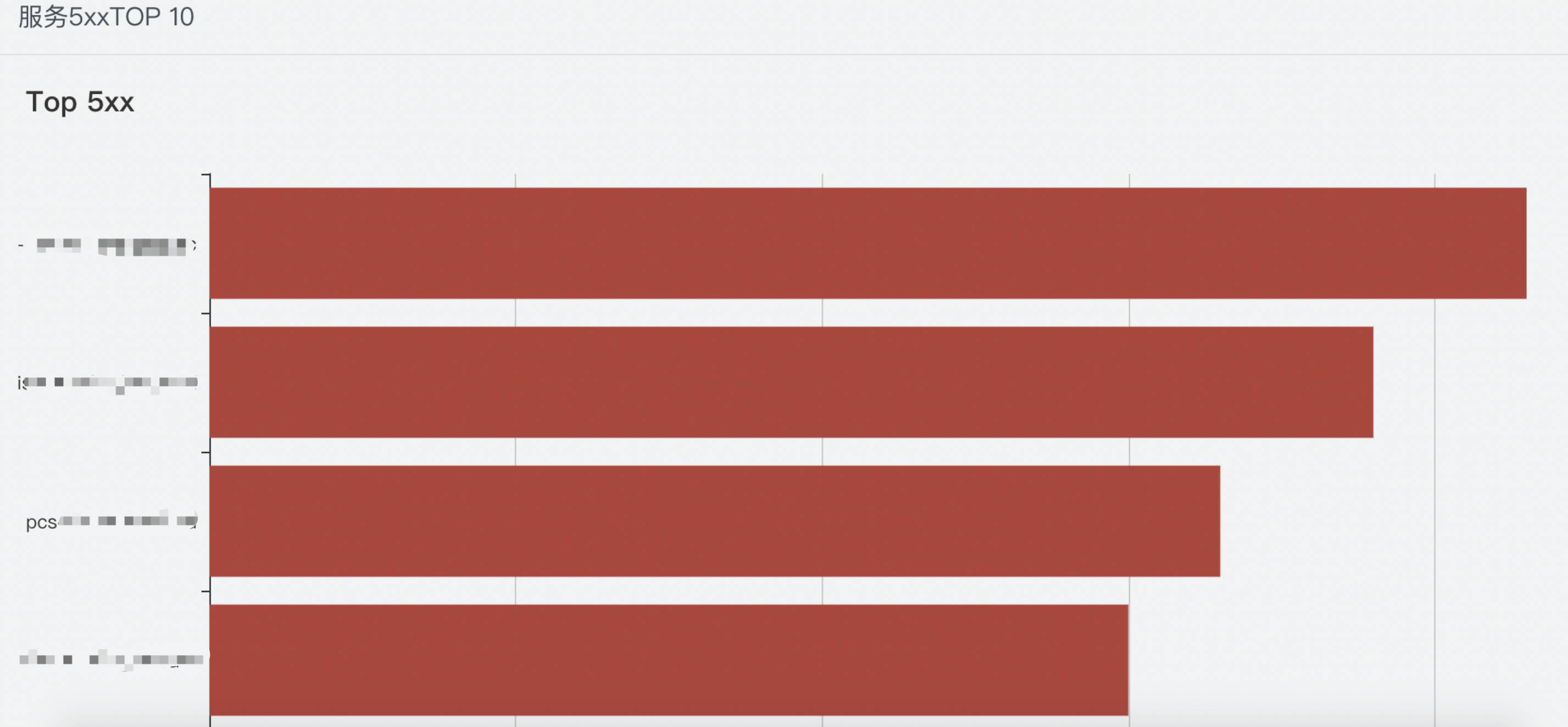
耗时维度:全部服务里,耗时增加 top 10 业务,快速知晓业务概貌。

业务失败率维度: 全部服务里,失败数最多的 top 10 业务,快速知晓业务概貌。
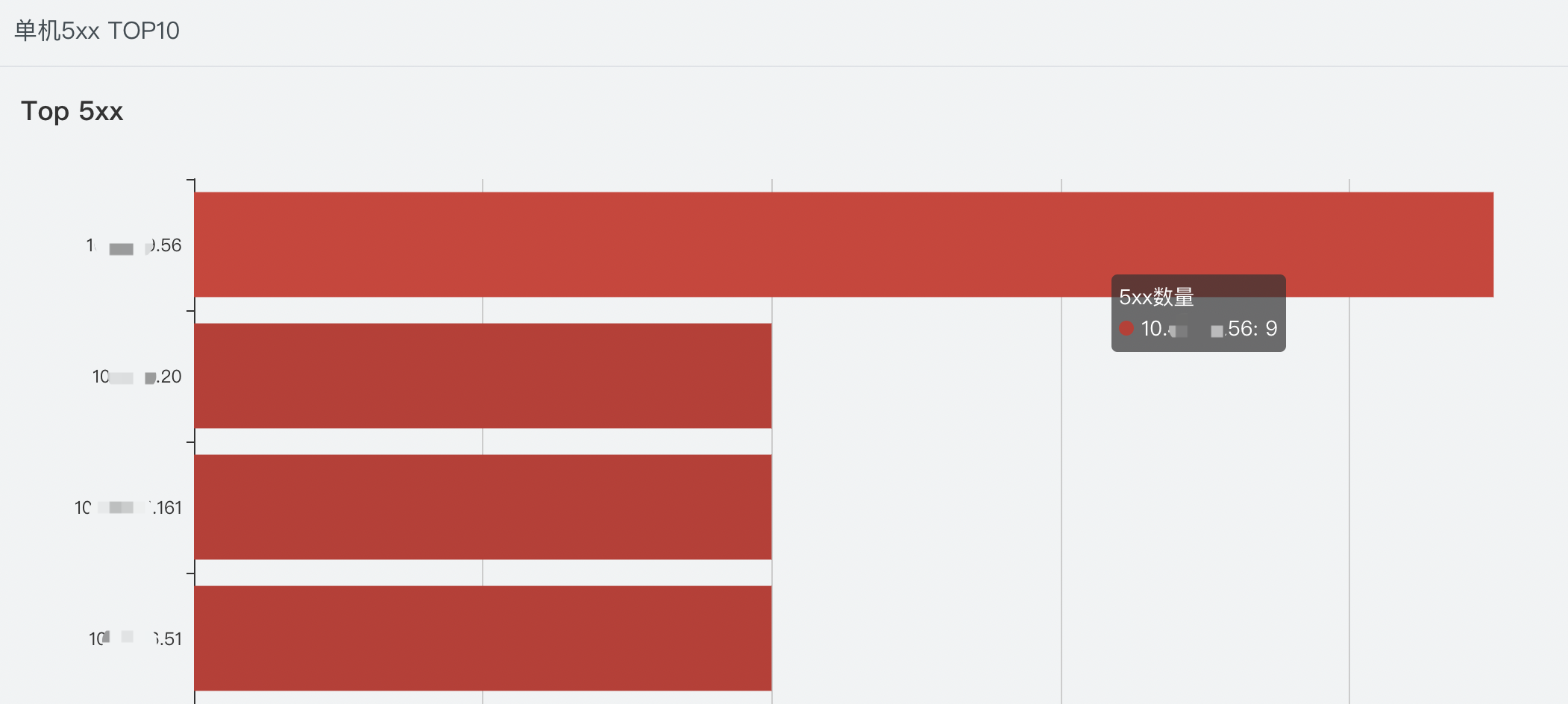
机器维度:全部机器里,请求 5xx 失败最高的机器 top 10,快速知晓机器异常。
5 服务治理
5.1 服务治理的定义
如前文所述,服务治理是建立在 Service Mesh 基础能力之上的,站在全局视角统筹规划,以保障服务稳定性为出发点。
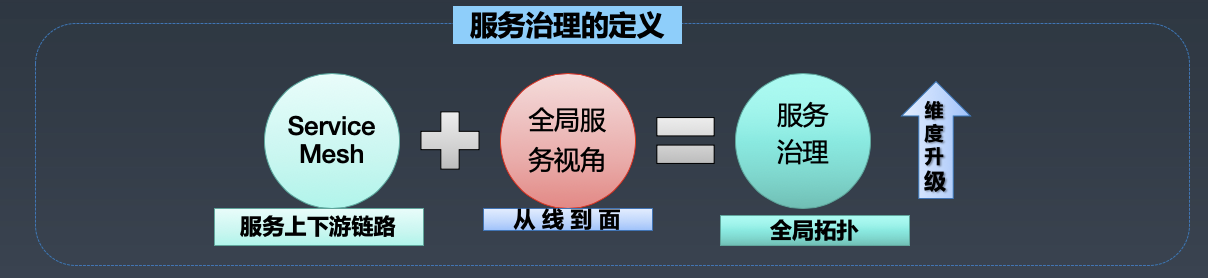
5.2 具体实践
服务治理的意义:如下图所示,百度网盘全局拓扑异常复杂,靠传统的人工套路去保障服务稳定性,效率和覆盖面都有很大的缺陷,基于流量控制的 service mesh 进行服务治理才是王道,具体从故障预防、故障定位和故障处理出发。
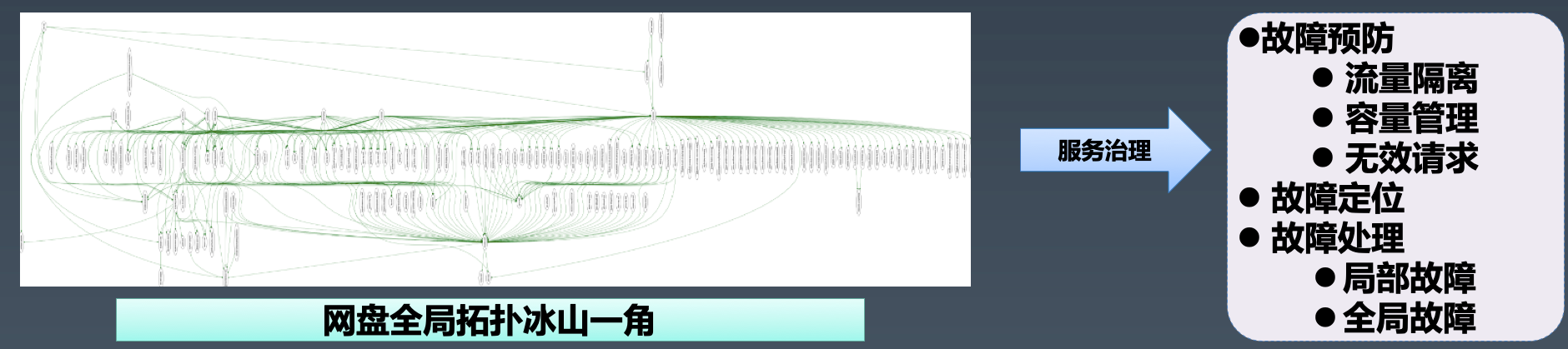
5.2.1 故障预防
故障预防从以下三个维度进行:
流量隔离:如何规避低优先级的请求流量影响高优先级的请求,避免喧宾夺主;
容量管理:如何保障服务容量满足实际需求,避免容量不足导致雪崩;
无效请求: 如何减少无效的请求,避免服务陷入雪崩的危机之中
5.2.1.1 流量隔离
具体落地中又分成机房流量隔离以及在离线流量隔离:
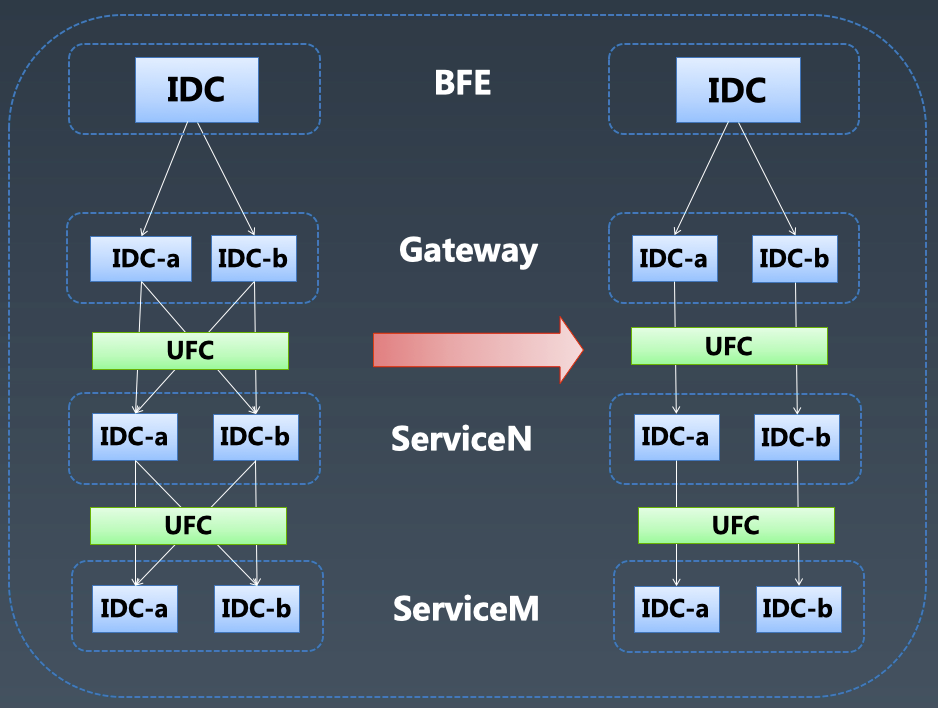
机房流量隔离:统一网盘所有服务逻辑 IDC 映射关系,UFC 自动识别上游所在机房,将请求转发到下游服务相应机房,从入口到请求终端,以逻辑 IDC 机房维度进行了流量隔离。当发生机房故障的时候,入口处切流量即可解决机房故障。
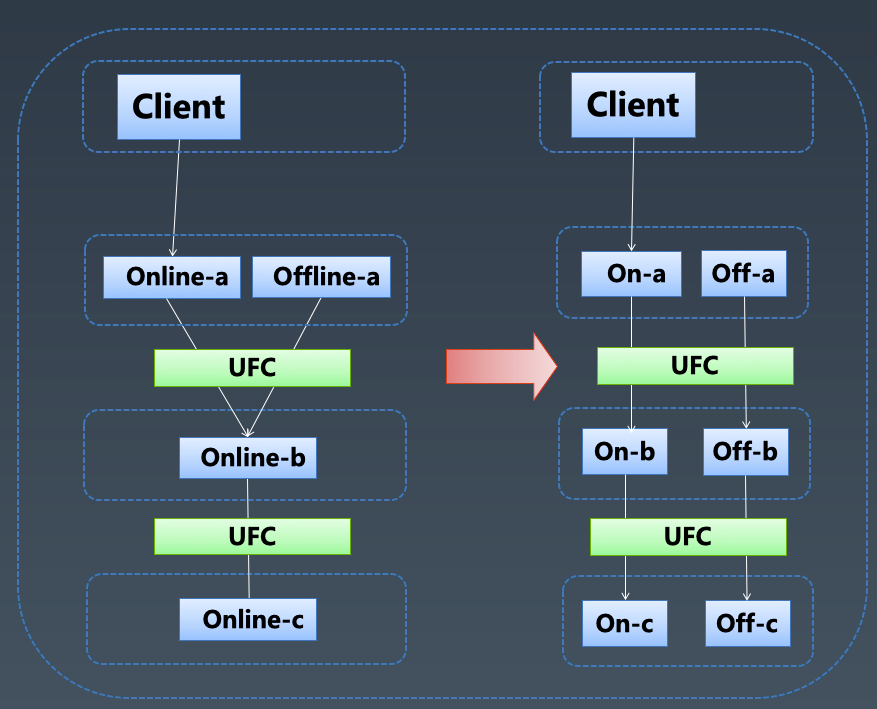
在离线流量隔离:定义网盘所有服务的等级,包括在离线标记,UFC 根据全局流量拓扑,可以发现是否存在在离线混连情况,避免低优先级的请求流量影响高优先级的请求,导致喧宾夺主。比如下图中,Online-a 和 Offline-a 都访问 Online-b 服务,这样 Offline-a 有可能引发 Online-b 服务异常,而从影响 Online-a 与 Online-b 的请求,间接影响用户请求。发现这种在离线混连的情况,需要对服务进行拆分,Online-b/Onine-c 各自拆分成 Onine 和 Offline 两套服务,进行在离线流量的隔离。
5.2.1.2 容量管理
具体落地中又分成容量评估以及容量压测,前置是根据链路拓扑做评估,后者是通过压测实践验证评估的准确性:
容量评估:通过链路上的 qps,分析出每个服务需要增加的 qps,进一步推算出需要扩容多少实例(PS:需要解决环路的问题)
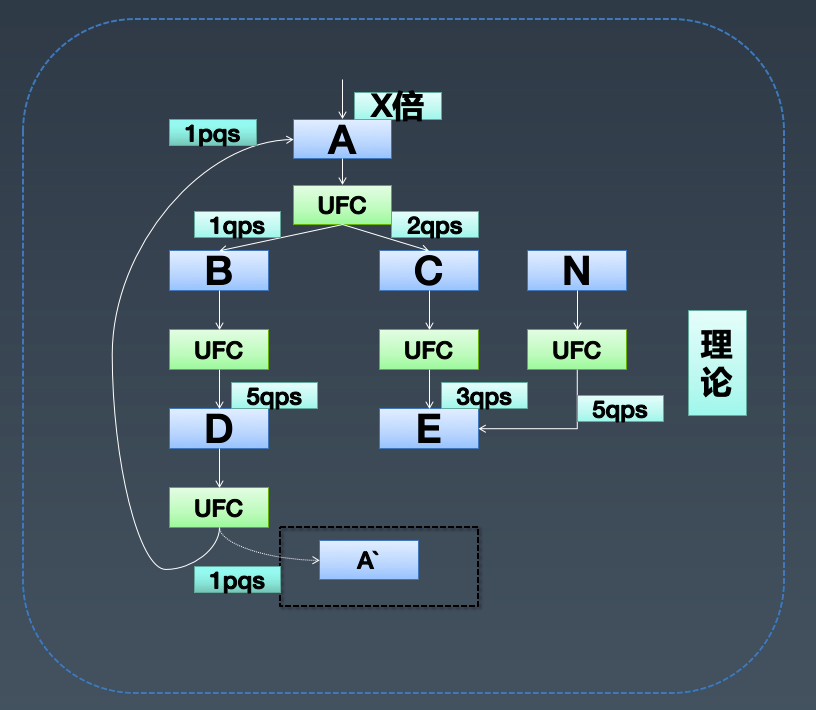
容量压测: 通过以线上流量以机房切流量逐渐加压的方式来压测,期间监控服务 sla,低于某个阈值之后,自动停止压测
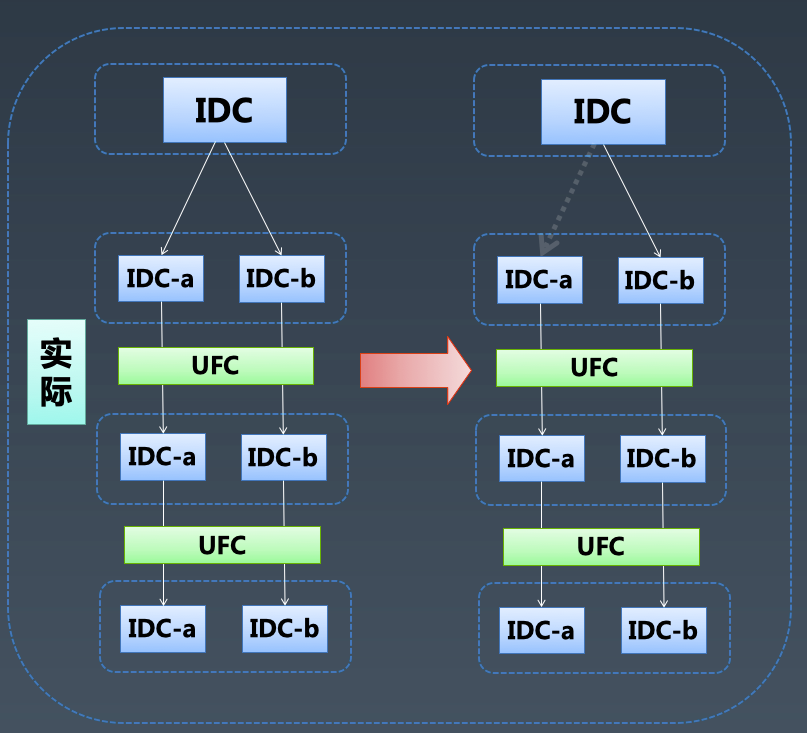
5.2.1.3 无效请求
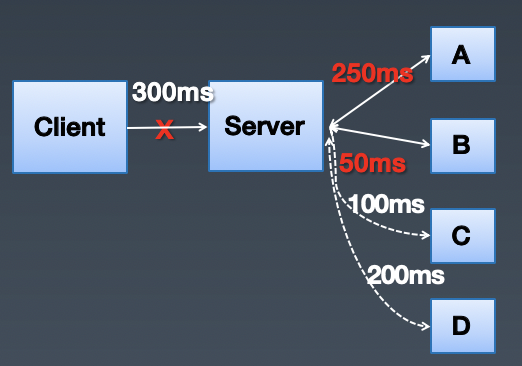
无效请求产生的背景:当 client 断开连接之后,server 还在继续访问其它的后端,进行无效的请求。比如下图中,client 以 300ms 的超时时间访问 server,server 在访问 A 和 B 之后,已经用掉了 300ms,这个时候 client 已经断开了和 server 的连接,但是 server 却继续访问 C 和 D,进行无效的请求。当这种无效请求在整个链路蔓延开,client 又在大量的重试的时候,就是雪崩降临的时刻。
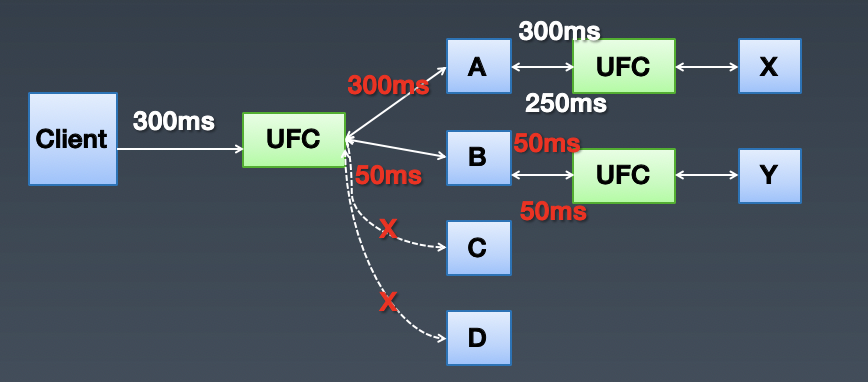
解决方案 - 基本思路:基于链路的智能超时,设置整个链路的超时时间,当发现超时时间已经到了,就不再访问其它的下游服务,避免无效请求。上游需要传递给下游执行超时时间(采用相对时间,避免机器之间的时钟不同步),用于下游判断执行时间是否已经到了。
解决方案 - 基于业务:不需要使用 service mesh,业务自己维护当前的超时时间,业务改造的成本比较大。
解决方案 - 基于 service mesh:UFC 以唯一 ID 映射到一个请求到所有后端交互的链路上,UFC 自动维护剩余的请求耗时,实现对业务近视 0 侵入(PS:还未用于生产环境)。
5.2.2 故障定位
定位的思路为:发现异常 –> 收集系统异常点/异常时间点相关变动 –> 定位原因。
除了基于 service mesh 采集系统的异常点,还需要联动其它的系统监控项,比如服务容量。
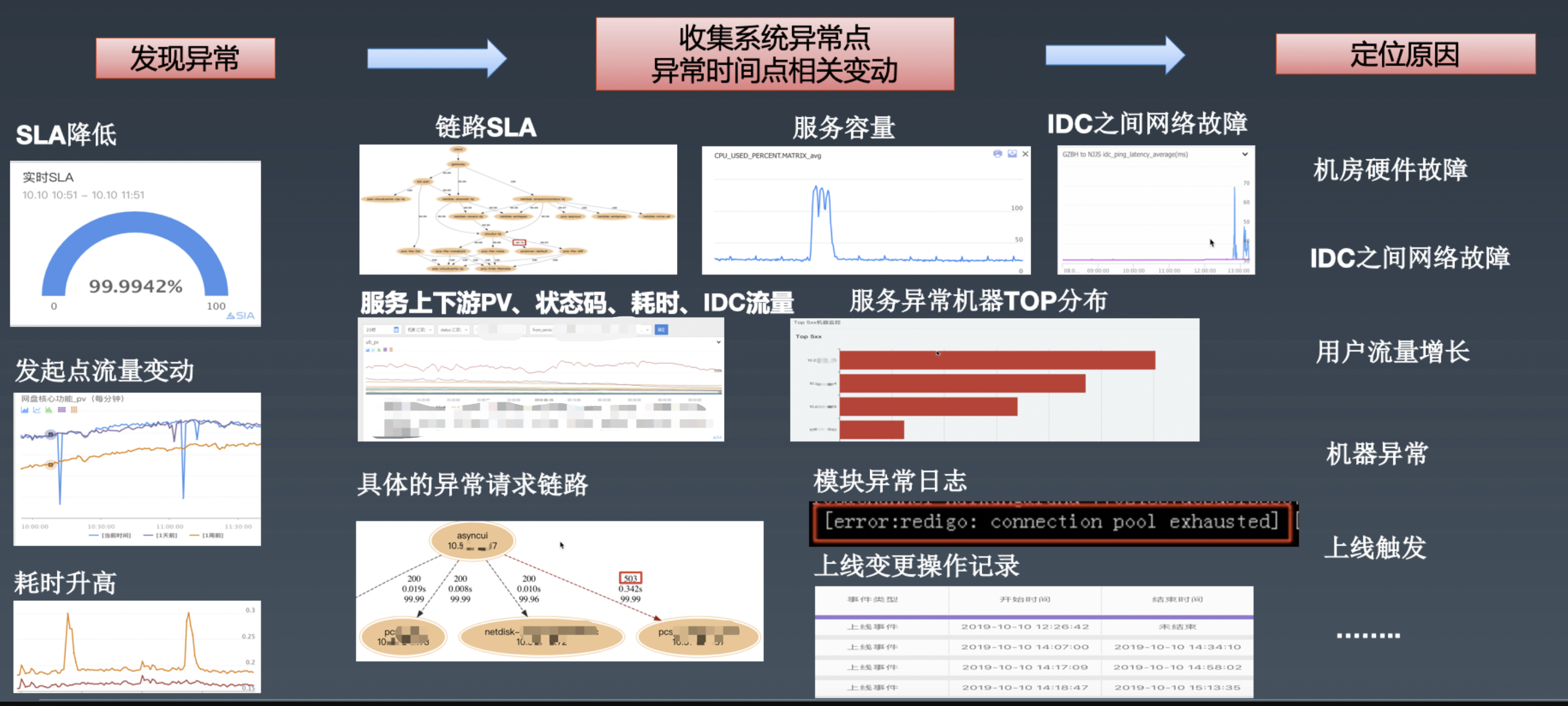
5.2.3 故障处理
根据故障的影响面可以分成局部/全局雪崩故障。
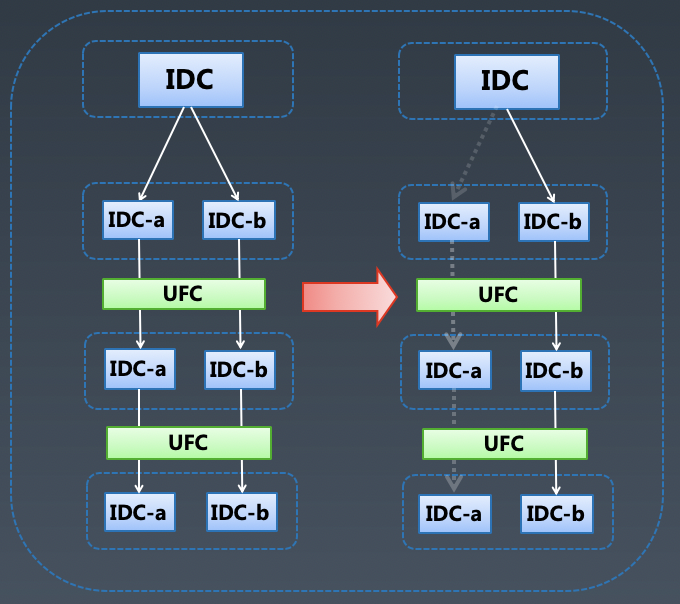
5.2.3.1 局部故障
前置条件:
部署:服务部署在多个逻辑机房;
上线:服务分级发布,单点 -> 单机房 -> 全机房。
场景:通过机房切流量快速解决机房硬件故障、小流量上线引发故障、后端异常封禁失败等局部异常
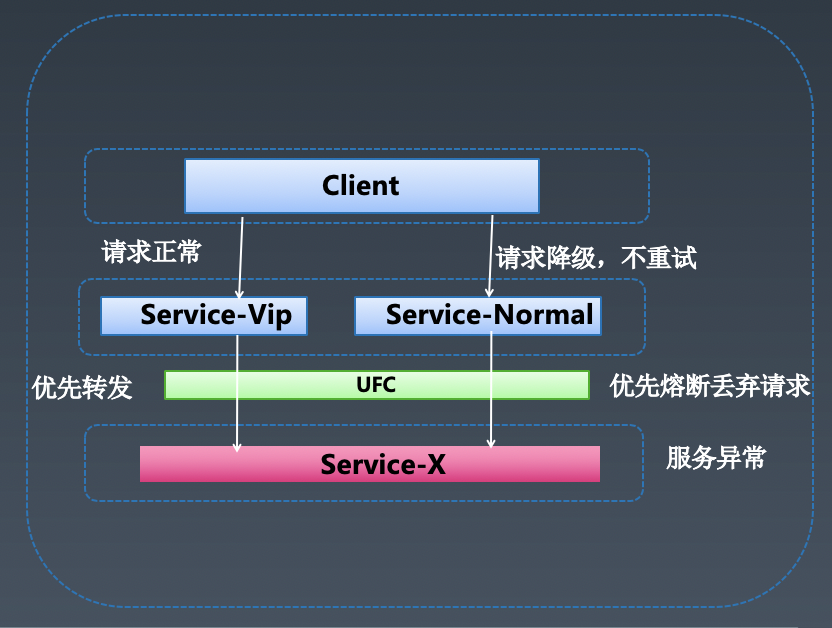
5.2.3.2 全局雪崩故障
前置条件:
等级:需要定义服务/流量的等级;
统一降级标记:统一所有服务的降级标记。
场景:通过全局动态熔断 + 异构降级 + 降级闭环策略解决服务引起的雪崩问题,尽量保障服务的可用度,具备自愈能力
6 总结与展望
在业务拆分面多众多问题的背景之下,百度网盘从 2015 年底开始思考解决方案,确定了解决问题的核心在于管控请求流量,在 2016 年开始自研网络流量转发中间件 - UFC(Unified Flow Control),业务通过同机部署的 agent 进行服务通信。后来通过调研借鉴业界技术的时候发现 UFC 和 Service Mesh 的设计理念是一致的,都是基于 sidecar 模式,有着控制面板和数据面板,UFC 是 Service Mesh 的一种实现。经过多年的线上实践验证,UFC 这个 Service Mesh 实现了动态熔断 + 异构降级 + 降级闭环等故障处理、结合故障/上游进行流量转发等创造性设计,满足业务的实际场景需求。但是百度网盘的实践落地并不只局限于 Service Mesh,首先是构建了从点延伸到线的 Service Mesh 进行服务通信管控,然后是在 UFC 这个 Service Mesh 的基础之上,站在全局视角对服务进行治理,保障服务的稳定性。
未来,UFC 将会加入故障注入等能力,同时基于该能力落地混沌工程,而这只是服务治理中预防的一部分。服务治理的目标是自愈,为了完成这个目标,还需要更加努力。

作者介绍:
本文作者李鸿斌,百度资深研发工程师。2011 年毕业后加入百度的基础架构部门,参与了百度分布式云存储的设计与开发,支撑了百度所有业务线的对象存储。2012 年至今,作为核心研发人员参与了网盘从 0 到 1 到 N 的基础架构演进,先后参与或负责对象存储 / 个人文件存储 / runtime 基础环境 / 资源管理 / 微服务架构,设计并实现了计算混布于万级别在线存储机器的资源模型以及服务资源调度,节省下了数万台服务器的计算资源,产品线资源利用率公司第一,同时从 2016 年至今主导了自研的 Service Mesh- UFC(Unified Flow Control),实现了从点到线到面的服务治理保障了网盘服务的高可用,近期专注于边缘计算方向,此外业余时间反哺社区,php-src/hhvm/beego 等源码贡献者。
原文链接:
https://developer.baidu.com/topic/show/290436

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论 4 条评论