
本文要点
多云是不可避免,而非可有可无的。86%的组织已经在多云环境中运营,这是由现代化和金融科技竞争驱动的现实。
延迟需要代码级优化,包括压缩、批处理优化、校准超时和基于帐户的分区。
弹性的范围不止在于即时可用性。事件存储、全面的政策和系统的重播有助于在故障中幸存并自动恢复。
事件排序和复制需要多层防御:使用延迟处理、唯一 ID、幂等配置和重复检查来应用序号。
从小做起,保持全面的可观察性,拥抱失败,并投资于强大的事件骨干和团队培训。
*下文中的所有想法和观点都是我个人的,并不代表我雇主的观点。
想象一下:现在是凌晨 3 点,你的手机因为报警消息而持续震动。一个关键的金融交易处理系统已经宕机,而麻烦在于:故障蔓延到了亚马逊云科技、Azure 和你的本地基础设施之间。无论是故障还是你的调试会话都不会尊重那些云边界。
欢迎来到多云事件驱动架构的世界。事件驱动架构——现代分布式系统的支柱,在多云环境中面临一系列特别的挑战。
“触发事件然后忘记”的优雅简单性变成了跨供应商边界的延迟优化、故障恢复和数据一致性的复杂编排。然而,如果把事情做正确,多云事件驱动架构就能提供前所未有的弹性、性能和业务敏捷性。
本文涵盖了在多个云提供商之间构建事件驱动系统的诸多现实挑战。
我们将通过实际的代码示例和经过验证的解决方案,探索多云复杂性、延迟优化、弹性模式、事件排序和复制处理等四个关键领域。
通过一个现实的金融服务案例研究,你将学习到管理跨云通信和针对在多供应商环境中蓬勃发展的系统的可操作策略。
多云现实
如果你还在争论多云的回报是否值得其复杂性的代价,你问错了问题,那艘船已经开走了。已经有 86%的组织在多个云提供商上运营,问题不是你是否会在云边界上构建分布式系统,而是你能做好这件事,还是要在一个又一个深夜排除排除级联故障。
Flexera 2025 年云现状报告提供了一个严峻的现实描述:只有 12%的组织在单一云提供商上运营,仅有 2%维持单一私有云环境。剩下的 86%已经采用了多云策略,其中 70%使用了将本地系统与多个云提供商编织在一起的混合架构。
这不是一个趋势,这是我们构建系统方式的根本转变。但为什么多云变得不可避免而不是可选的呢?
答案在于业务需求和技术现实之间的碰撞:
监管要求通常规定数据驻留在不同地区和供应商之间。
最合适的那些服务分散在众多供应商之间。例如,一个特定的组织可能更喜欢亚马逊云科技的安全性,Azure 的 AI,Google Cloud 的分析能力来满足他们的用例。
对集中风险的缓解措施需要避免在供应商层面的单点故障。
对遗留技术的现代化路径创建了基于负载特性的,迈向不同云服务的自然迁移路径。
当你不被锁定在单一供应商时,你对供应商的谈判能力会增加。
然而,大多数架构讨论仍然将多云视为边缘情况,而不是默认场景。
虚构案例研究:FinBank 的多云之旅
让我们通过一个虚构的银行(我们称之为 FinBank)来模拟一个现实的场景,这是一个有着百年历史的传统银行,正在将其基础设施现代化,以与敏捷的 FinTech 初创公司竞争,同时保持严格的监管合规性。
FinBank 的原始架构中可以看到过去几十年的演变过程:核心银行能力、信贷决策和卡服务被包装在微服务中,并通过 API 网关暴露。他们的本地、事件驱动架构有很多微服务来发出事件,也有一些日志到平台服务,有数百个相互连接的组件处理客户参与、分析、业务智能、监管报告和第三方集成。

图 1:Finbank 的架构
我故意展示了这个复杂的架构,重点是为了说明这不仅仅是一个高层次的架构图,它是一个有数百个相互连接组件的活生生的生态系统。想象一下将这些不同的相互连接的组件迁移到多云环境有多麻烦。他们正在处理这种复杂性。
他们的迁移策略遵循实用的方法:
由于监管要求和迁移复杂性,核心银行系统会保留在本地。
风险管理组件迁移到亚马逊云科技,以利用他们全面的安全服务和合规认证。
高级分析和业务智能转移到 Azure,以获得强大的数据和 AI 能力。
DevOps 服务在 Azure 中集中,以提供跨所有环境的统一管道部署。

图 2:Finbank 的多云策略
从这种看似简单的迁移路径中立刻就能看出来每个多云架构师必须解决的一些复杂挑战。真正的问题不是这些挑战是否会出现,而是你是否准备好了。多云事件驱动架构中的挑战
延迟
多云延迟不仅取决于网络速度,它还涉及到跨云边界的架构决策的复合效应。考虑一个需要从本地环境传输到亚马逊云科技进行风险评估,然后到 Azure 进行分析处理,再回到本地环境进行核心银行更新的交易。每个跳转都会引入延迟,但累积效应可能会将一个不到 100 毫秒的交易转变为多秒操作。
不同的云服务提供商有不同的机制来处理组件之间的连接问题。例如,Azure 提供了 ExpressRoute,而亚马逊云科技有 Direct Connect。它们提供可靠的专用链接,帮助你绕过公共互联网,实现不同组件之间的高性能、低延迟连接。
但仅靠网络改进并不能解决代码层面的低效问题。你还需要确保在代码层面考虑到延迟问题。
以下是一个忽略了多云现实的典型交易服务实现:
------------------------Publisher:public TransactionService(IKafkaProducer kafkaProducer){ _kafkaProducer = kafkaProducer;}public async Task CreateTransaction(Transaction transaction){ // Create and publish event immediately var transactionEvent = new TransactionCreatedEvent { TransactionId = transaction.Id, AccountId = transaction.AccountId, Amount = transaction.Amount, Timestamp = DateTime.UtcNow }; await _kafkaProducer.ProduceAsync("transactions", transactionEvent);}--------------------------------Subscribers:------------------------------private async Task ProcessTransactionEvent(TransactionCreatedEvent transactionEvent){ try { // Perform risk analysis var riskScore = await PerformRiskAnalysis(transactionEvent); // Take action based on risk score if (riskScore > RiskThreshold) { await FlagForReview(transactionEvent); } } catch (Exception ex) { // Log error and continue _logger.LogError(ex, "Error processing transaction event"); }}-----------------------------private async Task ProcessTransactionEvent(TransactionCreatedEvent transactionEvent){ try { // Process analytics var insights = await GenerateInsights(transactionEvent); // Store in data lake await _dataLakeClient.StoreAsync("transaction-insights", insights); } catch (Exception ex) { // Log error and continue _logger.LogError(ex, "Error processing transaction for analytics"); }} --------------------------------------这个简单的实现没有考虑到多云之间的延迟。你如何修复它?你可以实现几种优化。
优化包括:
压缩配置,以减少事件跨云边界时的带宽使用,因为每个字节都影响延迟
批量优化,使用更大的批量大小,即使考虑到大批量的延迟,也能将端到端延迟减少 40%到 60%。
用校准的超时值来优化持续时间;默认超时设置导致超时时间过长,浪费资源,或过短,导致过早重试和级联故障。
基于账户的分区,确保相关交易遵循定义的路线,实现有效的缓存策略。
发布者的修复样板:
------------------public async Task CreateTransaction(Transaction transaction){ #region Create Event... // Configure message with appropriate settings for multi-cloud var producerConfig = new ProducerConfig { // Compression to reduce bandwidth usage CompressionType = CompressionType.Snappy, // Batch optimization for cross-cloud transfers BatchSize = 32768, // Larger batches for efficient transfer LingerMs = 20, // Small delay to improve batching // Network optimizations for cross-cloud latency SocketTimeoutMs = 30000, // Longer socket timeout for cross-cloud DeliveryTimeoutMs = 30000, // Extended timeout for cross-cloud SocketNagleDisable = true // Disable Nagle's algorithm }; // Use account-based partitioning for consistent routing string topic = $"transactions-{transaction.AccountId % 10}"; string key = transaction.AccountId.ToString(); // Publish to Kafka with configured message settings await _kafkaProducer.ProduceAsync(topic, transactionEvent, key, producerConfig);} ----------------订阅者的修复样板:
----------------public async Task CreateTransaction(Transaction transaction){ #region Create Event... // Configure message with appropriate settings for multi-cloud var producerConfig = new ProducerConfig { // Compression to reduce bandwidth usage CompressionType = CompressionType.Snappy, // Batch optimization for cross-cloud transfers BatchSize = 32768, // Larger batches for efficient transfer LingerMs = 20, // Small delay to improve batching // Network optimizations for cross-cloud latency SocketTimeoutMs = 30000, // Longer socket timeout for cross-cloud DeliveryTimeoutMs = 30000, // Extended timeout for cross-cloud SocketNagleDisable = true // Disable Nagle's algorithm }; // Use account-based partitioning for consistent routing string topic = $"transactions-{transaction.AccountId % 10}"; string key = transaction.AccountId.ToString(); // Publish to Kafka with configured message settings await _kafkaProducer.ProduceAsync(topic, transactionEvent, key, producerConfig);}------------------------这些是你在考虑多云分布式环境中的延迟时应考虑的因素。所有这些设置都根据你的应用程序的具体需求和消息吞吐量需求而有所不同。关键是要认识到你需要有意识的代码级优化来解决多云场景中的延迟问题。
这些延迟优化并不是微观优化,它们是决定你的系统在负载下是否能够优雅扩展或失败的根本性架构决策。弹性:超越即时可用性
这是一个令人不安的事实:大多数弹性策略都关注的是错误的问题。作为工程师,我们通常将精力投入到处理在中断期间或服务组件故障时发生的故障。同样重要的是你在中断结束后如何从这些故障中恢复。这种恢复方法创建了“快速失败”但“永不恢复”的系统。
考虑在典型的多云中断期间会发生什么:

图 3:多云中断场景
没有适当的弹性设计:
失败的事件会永远丢失
服务在没有断路器的情况下继续对失败的依赖项进行重试
在中断后,缺少重放能力意味着数据不一致性会无限期地持续存在
在多云环境中,这个问题变得更加复杂,不同的提供商有不同的故障模式、恢复时间和 SLA 保证。你的系统的弹性只和其最弱的跨云依赖一样弱。
构建全面的弹性需要系统化的方法:
事件存储,如使用 Outbox 模式的持久存储、专用存储或 Kafka 保留
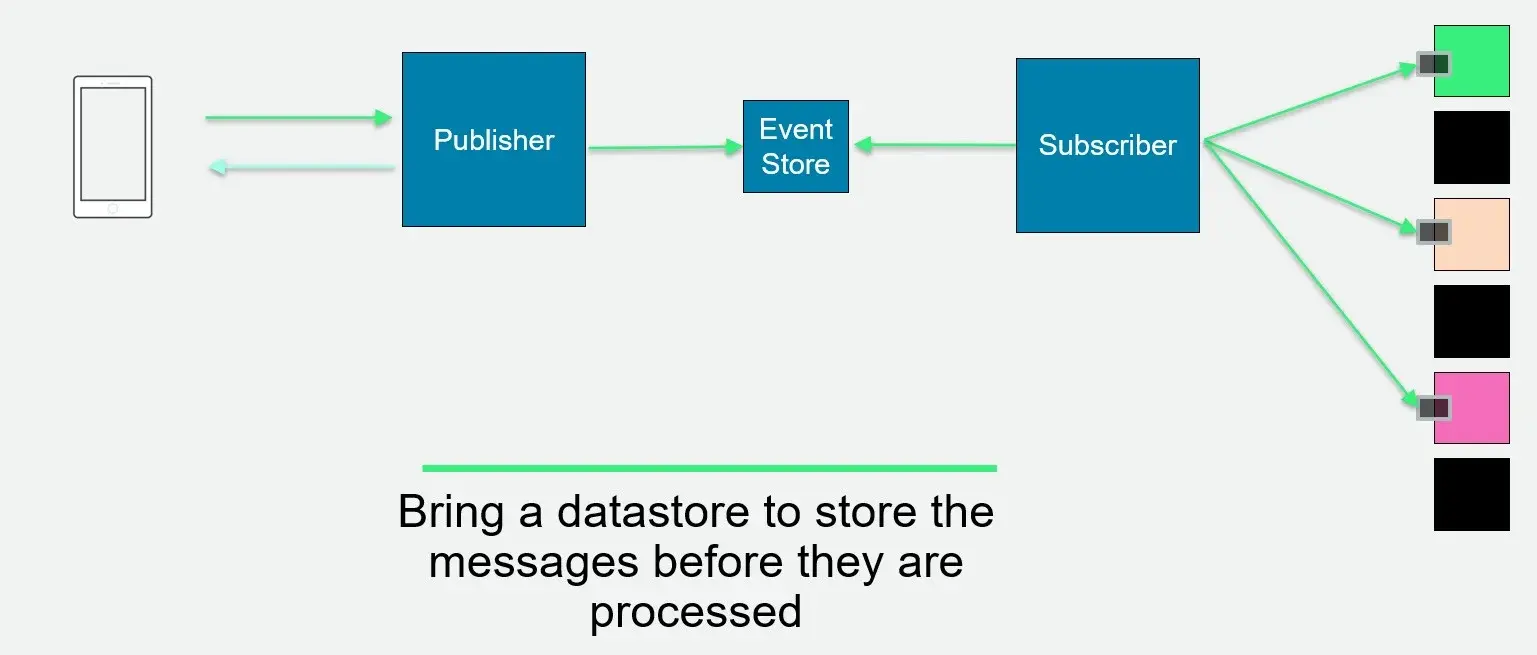
图 4:EDA 中的事件存储
断路器在依赖项不健康时快速失败,从而防止级联故障
系统性重放,包括在中断后恢复丢失事件的自动恢复机制
以下代码示例展示了带有上述修复的示例实现:
------------public async Task CreateTransaction(Transaction transaction){ // Save to database first await _transactionRepository.SaveAsync(transaction); // Event Creation - Same as before // Latency settings from previous example // Use resilience policy with retry pattern for publishing await _resiliencePolicy .WaitAndRetryAsync( 5, // Configurable, Retry 5 times at application level attempt => TimeSpan.FromSeconds(Math.Pow(2, attempt)), // Exponential backoff onRetry: (ex, timeSpan, attempt, ctx) => { _logger.LogWarning(ex, "Retry {Attempt} publishing transaction event {TransactionId}", attempt, transaction.Id); }) .ExecuteAsync(async () => { // Partitioning strategy for consistent routing var topic = $"transactions-{transaction.AccountId % 10}"; var key = transaction.AccountId.ToString(); // Publish with delivery handler to confirm delivery var deliveryResult = await _kafkaProducer.ProduceAsync( topic, transactionEvent, key, producerConfig); if (deliveryResult.Status != PersistenceStatus.Persisted) { throw new KafkaDeliveryException( $"Failed to deliver message: {deliveryResult.Status}"); } // Log successful delivery _logger.LogInformation( "Transaction event published successfully: {TransactionId}, Partition: {Partition}, Offset: {Offset}", transaction.Id, deliveryResult.Partition, deliveryResult.Offset); });} ----------------------事件存储、弹性策略和系统性事件重放能力的结合,创建了一个不仅能够承受故障,而且能够自动恢复的分布式系统,这对于多云架构是一个关键要求。
事件排序
在单节点系统中,事件排序是微不足道的事情;事件按照它们发生的顺序被处理。在分布式系统中,尤其是在具有不同网络特性的云提供商之间,事件排序变成了一个复杂的协调问题。
考虑这个场景:一个本地系统同时向亚马逊云科技和 Azure 发送一个“交易”事件。由于网络延迟差异,Azure 首先接收并处理事件,执行欺诈分析,并将结果发送给亚马逊云科技,所有这些都在亚马逊云科技接收到原始创建事件之前完成。
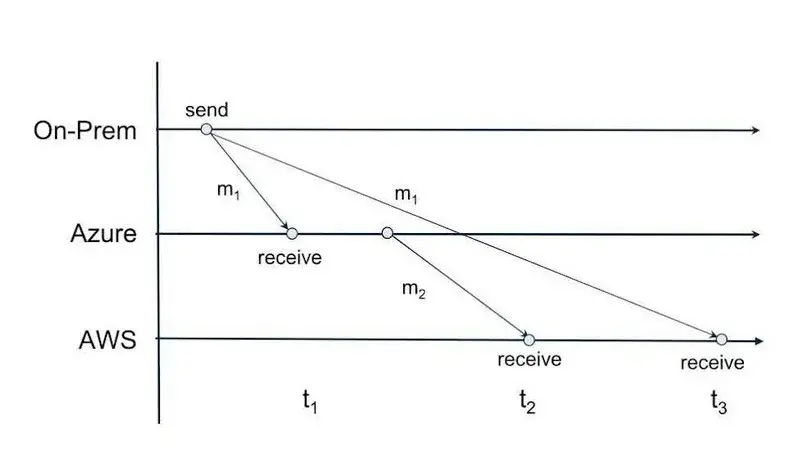
图 5:事件排序场景
后果是严重的:
风险管理系统按顺序处理事件
欺诈检查在交易验证之前完成
监管报告包含不一致的数据
由于时间不一致,财务审计失败
传统的解决方案,如分布式锁或共识算法,由于其延迟和可用性权衡,在跨云边界时效果不佳。相反,成功的多云架构使用多层次方法。
在发布者级别,创建你的交易的发布者应确保每个事件都有一个严格递增的序列号。发布者有责任确保任何发出的事件都应该有一个严格递增的序列号。
如果你已经使用了基于账户的分区,这也有帮助,因为你有类似的交易通过类似的服务,为你提供了内部固有的消息排序。
在订阅者层面,你需要进行验证。每个订阅者都需要进行序列验证,确保事件按照正确的预期顺序进行处理。事件处理还需要被推迟。以我们的例子为例,亚马逊云科技比从本地环境更早地从 Azure 接收到消息,它需要推迟处理消息 2,直到它接收并完成处理消息 1。
在这些场景中,分布式系统的一致性也非常重要。你希望你的系统具有强一致性,还是可以接受最终一致性?这个选择伴随着真正的妥协:更强的一致性保证通常意味着性能更慢(由于协调开销)和成本更高(更复杂的基础设施、额外的网络调用和资源使用)。与此同时,最终一致性可以提供更好的性能和更低的成本,但需要你的应用程序处理临时的不一致性。不同的组件可能根据这些权衡有不同的一致性要求。解决方案取决于你的具体应用程序需求和你愿意做出的交易。
这里有一个这样的模式。
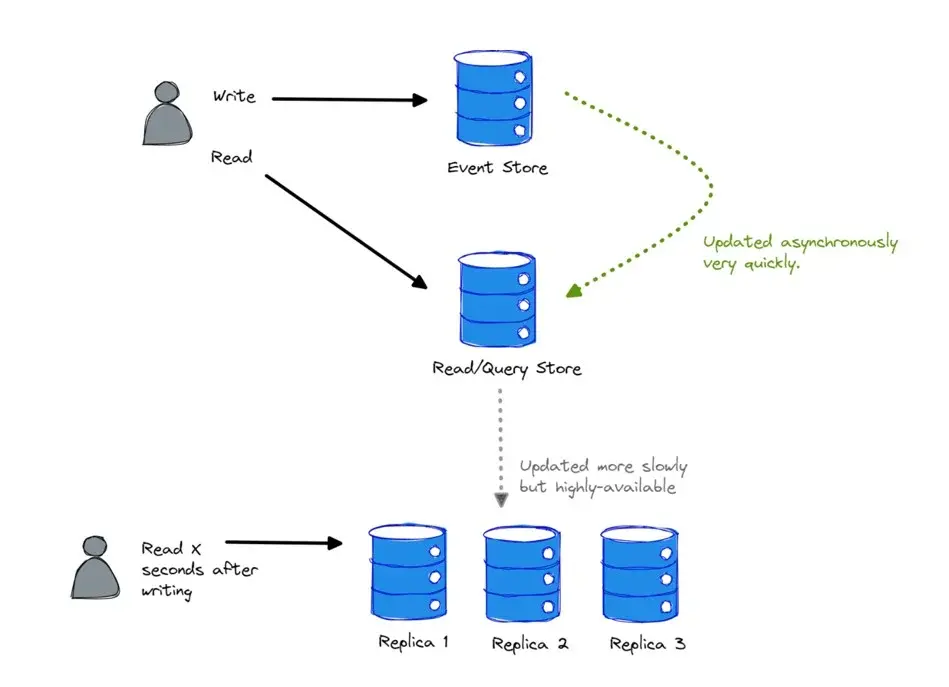
图 6:一致性模式
关键洞见:一致性不是二元的,它是一个谱系。例如,Azure Cosmos DB 有五个一致性级别,这是一个广泛的谱系,取决于你的应用程序需求以及你希望如何在分布式设置中处理它们。
重复事件
网络故障、重试和跨云通信本质上会产生重复事件。虽然重复风险处理只是浪费资源,但重复的金融交易会造成监管噩梦和审计失败。
在多云环境中,挑战成倍增加,不同的提供商有不同的重试策略、超时行为和故障模式。一个单一的业务交易可能会在云边界上触发多个技术事件,其中每个事件都可能被复制。
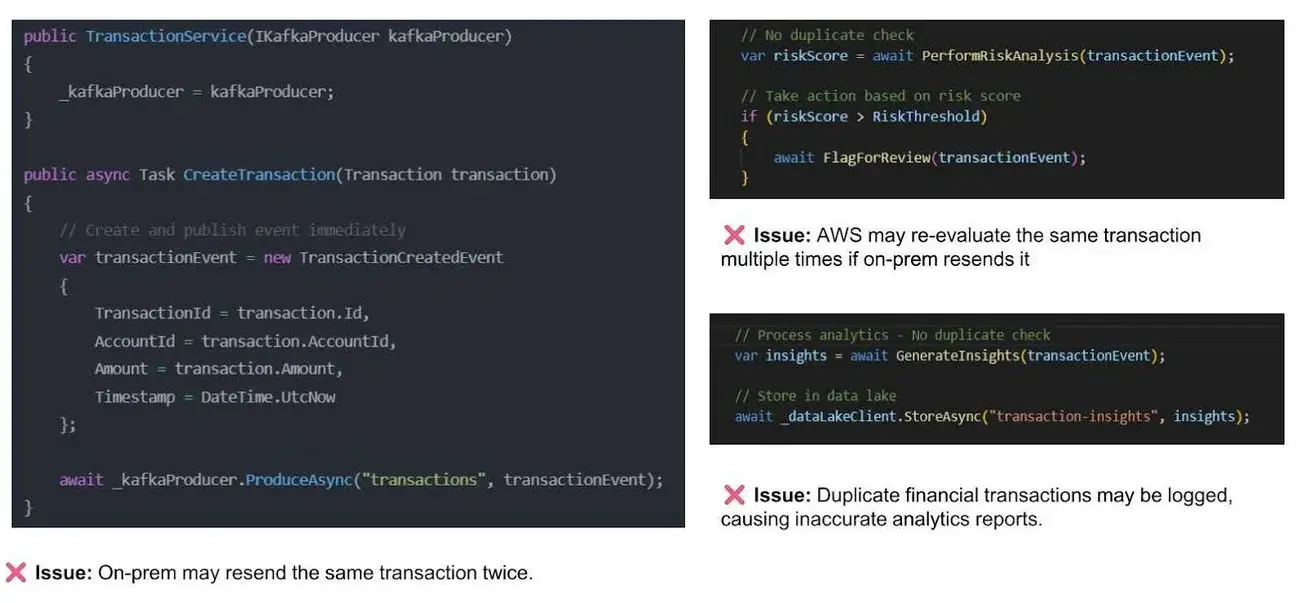
图 7:重复交易处理
成功的重复处理需要一个四层防御策略:
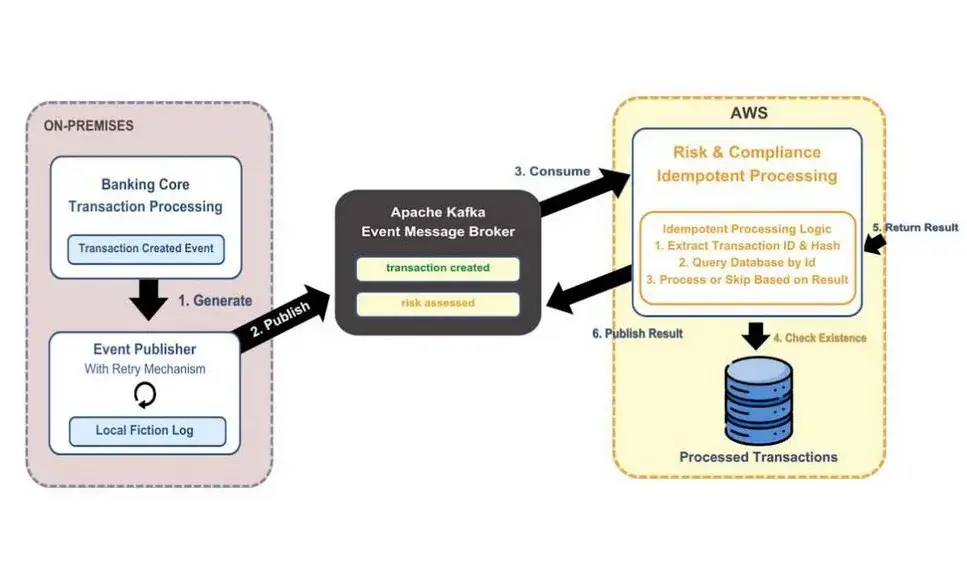
图 8:处理重复事件
首先,从你的发布者开始。生成事件的代码片段需要确保它创建了一个唯一的事件;例如,使用云事件模式,这是一个用于描述跨不同提供商使用的云事件的开放规范。其次是你的生产者配置级别。假设你使用 Kafka 作为发布消息的代理,在这种情况下,Kafka 有一个名为“幂等”的生产者配置设置,确保在网络中不会有重复事件。第三,在你的订阅者层面,处理你的实现中的重复事件。当你接收到事件时,首先检查你的进程表。如果你的交易存在那里,它是一个重复项,你就要忽略它。如果它不存在,请继续处理并在该交易日志表中添加一行,以便将来检查重复事件。最后,确保你的事件处理实现本身是幂等的,这意味着如果你为同一事件重新运行,它不应该对事件产生负面影响。这种深度防御方法认识到,在分布式系统中重复是不可避免的——目标是优雅地处理它们,而不是完全防止它们。
其他多云事项
我们也来看看一些在谈论多云时变得非常重要的其他考虑事项。
安全和合规性:扩大的攻击面
多云环境会成倍增加攻击面。每个云提供商都有不同的安全模型、IAM 系统、网络策略和合规框架。跨云通信中的安全漏洞可能会危及你的整个分布式系统。
模式演变:变更不造成破坏
事件驱动架构不可避免地需要模式变更。在多云环境中,模式演变变得更加复杂,因为不同的组件可能独立部署在不同的提供商上,具有不同的发布周期。
可观察性、日志记录和分布式跟踪
我们需要记录所有云中的整个事件旅程,这意味着在这些环境中拥有良好的可观察性和分布式跟踪能力。有一些云原生平台可用于处理多云环境的复杂性。确保你识别出适合你不同分布式组件的可观察性的正确平台。
云原生与云不可知:永恒的权衡
利用各个云独有的功能与保持可移植性之间的紧张关系需要仔细的架构决策。云原生方法提供更好的性能和更深入的集成,而云不可知方法提供灵活性并减少供应商锁定。
可操作的洞察:DEPOSITS 框架
成功的多云事件驱动架构遵循这些原则:
为失败而设计。假设组件将在最坏可能的时候失败。从第一天起,将故障处理构建到你的系统的每个方面。
拥抱事件存储。持久的事件存储自然地解决了许多分布式系统的挑战,并带来了强大的恢复场景。
优先进行定期审查。持续审计你的架构以寻找优化机会。多云系统发展迅速,昨天的最优配置可能是今天的瓶颈。
首先确保可观察性。你无法调试你看不见的东西。在所有云边界上大力投资分布式跟踪、指标和日志。
从小规模开始,逐步扩展。同时迁移整个架构是灾难的源头。从隔离的、易于理解的负载开始。
投资于强大的事件骨干。你的消息基础设施是你分布式架构的神经系统。不要在可靠性、性能或操作工具上吝啬。
团队教育。分布式系统需要专业知识。云提供商快速创新,你的团队需要持续的技能提升以跟上步伐。
成功。遵循这些原则将导致系统在多云环境中蓬勃发展,而不仅仅是生存。
前进的道路:拥抱复杂性
多云事件驱动架构代表了我们设计和操作分布式系统方式的根本转变。相关挑战是真实的、复杂的,并且往往是违反直觉的。但是,避免多云架构的那些替代方案在当今的技术格局中是不可行的。
成功的组织会将多云复杂性视为设计约束而不是运维后才考虑的事项。他们投资于正确的抽象,从一开始就构建全面的故障处理,并培养具有深厚分布式系统专业知识的团队。
问题不在于多云是否值得其复杂性,而在于你是否会控制复杂性,否则它将控制你。选择权在你,但凌晨 3 点的电话不会等待你的决定。
从全面的可观察性开始,将失败视为学习机会,并投资于强大的技术基础设施和团队能力。最重要的是,记住成功的多云架构不是造出来的,而是在实战中演变、测试和持续改进的。
未来属于能够跨越云边界蓬勃发展的系统。现在就是开始构建它们的时候。
有关本文讨论主题的更多细节,你可以观看视频。
作者介绍
Teena Idnani 是一名技术领导者,目前在微软担任高级解决方案架构师。她通过构建可扩展的云原生架构来帮助组织进行数字化转型之旅,并为迁移到 Azure 的组织提供技术领导和架构指导。在她之前在 JPMC 的职位上,她负责在银行设置 Azure 平台,与他们的多云提供商战略保持一致,并在 Azure 上迁移和现代化应用程序时为各种团队提供支持。近年来,她对量子计算产生了浓厚的兴趣,并一直在研究和倡导其潜在应用,特别是在金融领域。她的技术之旅使她在各种行业会议上发言,在那里她分享了关于云迁移、应用程序现代化、事件驱动架构和量子技术在行业前景的见解。她还定期指导有抱负的技术专家,重点是支持技术领域的女性。
原文链接:Building Distributed Event-Driven Architectures Across Multi-Cloud Boundaries




