

导读:今天我们谈谈用户行为序列上的推荐模型。首先我们对序列推荐问题做一个定义和描述,然后主要讲述可以用在序列推荐任务中的 NN 模型,最后给出一点个人看法以及文中相关的参考文献供参阅。
用户行为大多数情况下都是存在时间上的先后关系的,在某一个时刻向用户推荐哪些物品一般是根据当前时刻之前用户的行为来做决策的,我们可以将序列推荐问题看做是在时间维度去学习一个模型策略来根据用户过去的行为历史来预测用户将来感兴趣的物品。
相对基于序列的推荐模型则是非序列化的推荐模型,如经典的矩阵分解模型和图模型,如图 1。这两种模型主要考虑通过节点之间的邻接关系进行建模,时序通常是作为其中一个的隐式特征或者约束加入模型中来进行学习的。而在序列模型中,时间先后顺序是作为一个显式的强制约束加入模型中的 ( t 时刻根据之前的行为进行学习,然后 t+1 时刻根据之前的行为进行学习 ),因此序列模型中可以防止 future information leakage,对于 next items recommendation 的任务是比较适合的模型。
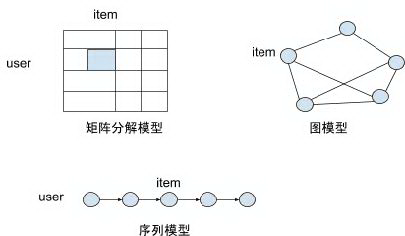
图 1 序列推荐模型与非序列推荐模型
序列模型在我们的日常生活当中也存在着不少应用场景。比如金融交易中的股票涨跌预测以及自然语言处理中的语言模型。可以把一个用户在过去一段时间内发生过行为的物品集合 S 定义为:
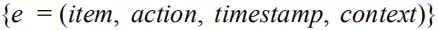
其中 item 表示物品信息,如物品 ID 以及相关属性,action 表示用户行为信息,如行为类型:浏览 ( impression ),点击 ( click ),购买 ( buy ) 等,timestamp 表示行为发生的时间。context 为事件的上下文信息。将 S 中的元素根据 timestamp 从前到后排序后得到用户的有序行为序列 S’=
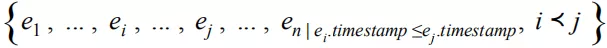
接下来我们主要讨论的序列推荐则可以看做是在序列 S’ 上学习的一个预测模型 P:
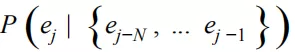
相对于矩阵分解和图推荐,在序列上学习推荐模型最重要的一点是用户某个时刻的行为只受该时刻之前的行为影响,不受用户之后的行为影响,如图 2,t4 时刻我们预测用户行为物品,预测的输入只包括:
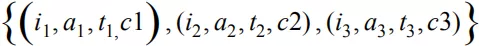
不包括 t5 时刻的行为。

图 2 用户序列行为的相互影响
数据准备
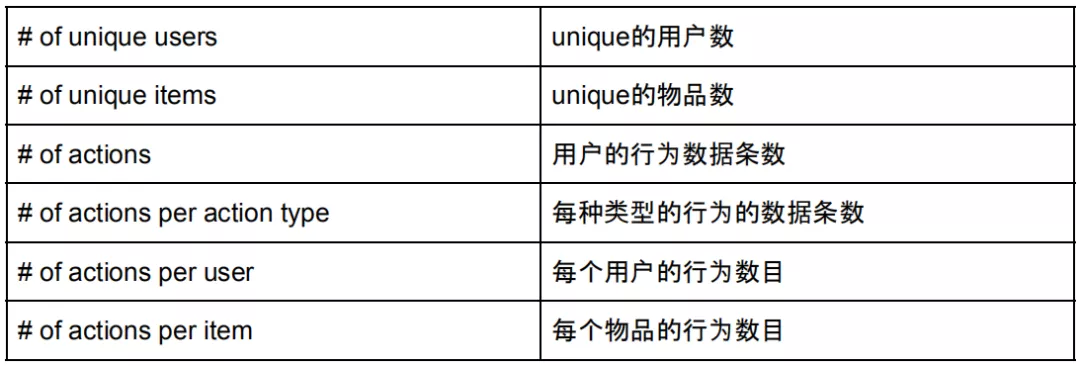
在开始模型训练之前,我们需要准备训练和测试数据。序列推荐模型的输入是用户的行为序列数据,在多数情况下对训练数据进行预处理对模型性能有一定帮助。我们可以先对数据中的序列信息进行一个简单统计,进行可视化显示以帮助我们对数据有一个总体认识,下表给出一些可以进行统计的数据范例:
针对以上的统计量,我们可以进行以下的数据过滤和处理工作:
❶ 无效用户过滤,如 robot ,网站爬虫等。这些用户的行为条目数通常远大于正常用户的行为数,可以结合用户行为数目的直方图,通过一些基于统计的异常点检测算法 ( 如检测,MAD-基于绝对离差中位数,基于密度的检测方法等 ) 找到这些用户并过滤掉;
❷ 热门用户和热门物品的处理,可以对热门用户和物品对应的数据进行降采样,或者是进行降权,以减少热门度对推荐结果的影响;长序列可以根据时间进行切分,减少长序列对模型收敛性的影响。
接着我们需要把预处理后的数据分成训练集和测试集。如论文[14]中提到的,随机的将数据集分成训练和测试集合对于 next-item 的推荐会造成 future information leakage,一个可行方式是在用户的行为序列上选取一个时间点作为训练和测试集的分割点,用户之前的行为加入训练集,之后的行为放入测试集,如果我们只关注非重复物品的推荐,那么同一用户的行为物品需要在训练和测试集之间进行去重。
数据准备好以后,下面开始模型工作。首先我们需要明确模型需要完成什么任务,是召回还是排序,并且针对具体任务定义模型的优化指标。如果是召回,可以采用 precision_recall,F 值,如果是排序,可以采用 AUC,NDCG,MAP。在序列上做召回相当于在某个时刻去预测整个物品空间集合内用户对各个物品发生行为反馈的概率,即一个多分类的问题,ground truth label 是该时刻用户实际发生反馈的物品。在召回的物品集合中,接下来可以进行一个更为精细的排序,输入是更为精细的用户行为特征信息以及相对较小的候选物品集合, ground truth label 是用户对候选物品的反馈行为,然后在这个小的集合内对每一个物品进行打分,作为用户对物品发生反馈的概率。具体构建召回和排序的流程和框架,读者可以参看论文[14]。
MLP
下面即谈下可以在序列推荐中使用的模型。首先第一个模型是 Multi-layer Perceptron ( 多层感知机 ),也是模型结构相对简单但在工业界运用比较广泛的深度模型。MLP 模型是包含多个全连接隐藏层的前向反馈模型, 输入是之前用户的最近 N 次行为的数据,输出是一个固定长度的向量来表示用户的历史行为信息。如将图 2 中的序列展开后生成的模型输入为:[([e1], e2)),([e1, e2], e3),([e1,e2,e3], e4),([e1, e2, e3, e4], e5)],每个 tuple 的第一个元素是前 N 个时刻的行为信息,第二个元素为当前时刻的行为信息。模型先对输入的这 N 个时刻的行为信息进行 embedding,然后通过 pooling 将这 N 个 embedding 进行聚合,生成低维度的向量,最后经过一层或者多层的全连接层生成输出向量。
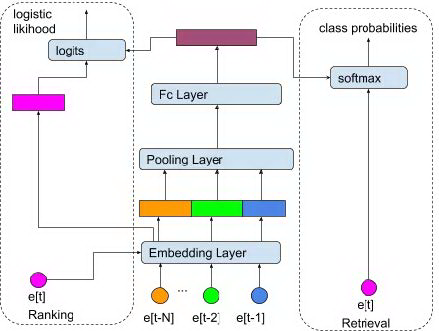
图 3 recall & ranking via MLP
图 3 中右边部分,输出向量送给 softmax 层产生物品全集中每个物品的概率,t 时刻的物品 ID 作为 groud truth,loss 使用 sofmax cross entropy loss ( 如果物品的数目特别多,一般考虑做 sampled softmax )。物品向量即对应 softmax 权重矩阵中的列向量,然后可以用第三方平台 ( 如 fuss ) 建立向量索引。线上服务时用户的历史行为序列的模型向量作为 key, 通过 nearest neighbor search 完成召回。
上图左边部分对应在候选集合中进行排序。类比[18]中的 DSSM 结构,模型产生的输出向量与目标物品 embedding 之间的相关性作为目标物品的排序分数,其中计算相关性可以采用以下方法:
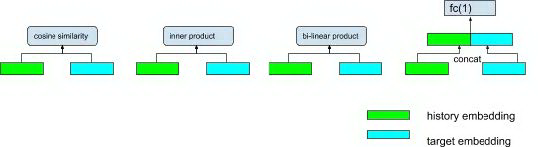
图 4 combine embedding for prediction score
其中 history embedding ( 历史行为向量 ) 表示为 H, target embedding ( 预测物品向量 ) 表示为 T,图 4 中的几个计算方式可以简单表示为:
cosine similarity:
inner product:
bi-linear product:
fully-connected layer:
在实际排序过程中,除了事件中的物品 ID 可以作为特征之外,物品本身的属性以及事件上下文也可以用到模型中。可以如图 5,把这些特征通过 embedding 层之后进行聚合,拼接成一个长向量,然后输入到多层全连接网络。
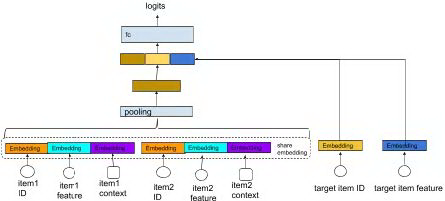
图 5 combine input embedding via concatenation
也可以每个特征在序列维度单独进行 embedding 和 pooling ( 各个特征的 pooling 方式可以不一样 ),然后在输入全连接层之前进行聚合。
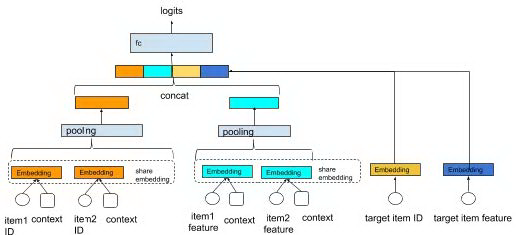
图 6 concatenate pooling output
图 6 中的几个模块可以单独说一下:
❶ Embedding 层
embedding 层的作用是:将序列中的事件信息映射为一个浮点数向量。每个事件的信息包括物品特征信息以及上下文信息,其中物品的特征包括离散型特征 ( 物品的 ID 编号,物品的类别,物品的标签等 ) 和连续型特征 ( 物品的历史热度等 ),其中物品的 ID 和类别是每个物品唯一标识,属于 univalent 离散特征,而每个物品包含的标签不止一个,为 multivalent 离散特征。
离散特征的向量化可以采用两种方式:1. embedding lookup;2. onehot。embedding lookup 通过 ID 在一个大小为 M x d 的矩阵中查找到该特征编号所对应的行,作为特征的向量,其中 M 是该离散特征的取值个数,d 是特征向量的维度。onehot 则是定义一个 0-1 向量,其中向量长度是特征所有取值的个数,而特征的具体值对应向量中的下标,该下标对应的 one-hot 元素值为 1,其他位置下标的值为 0。如果是 multivalent 特征,则将各个特征取值对应的向量进行相加,得到特征的向量。
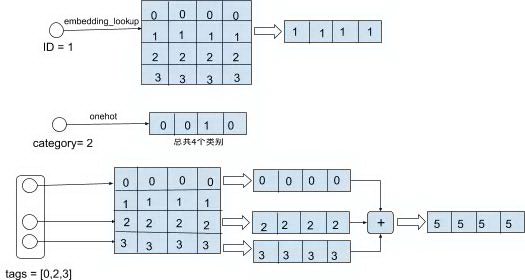
图 7 embedding lookup and onehot
连续型的数值特征可以直接使用,使用前一般会做归一化,使得特征归一到(0,1)之间。物品的文字描述和图片等属于高维特征,通常需要先降维到一个低维度的向量再使用。文字描述一般可以经过分词去停用词等预处理过程,然后将每个词映射为词向量。词向量可使用预训练的词向量模型 ( 如 word2vec,glove ),也可以使用随机初始化的词向量。词向量的序列然后经过 LSTM 等语言序列模型后,生成整个物品的文字描述向量。图片的原始数据通过预处理后经过一个预训练的模型 ( 如 vgg,inception ),取其某一层的输出作为图片向量 ( 如 vgg 的 fc6 )。实际中发现预训练模型的最后几层输出维度比较高但是数据比较稀疏,可以加一个全连接层将高维的稀疏向量映射为一个低维向量,作为最终输出的图片向量。
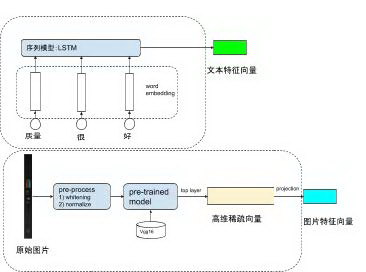
图 8 产生图片和文字向量
除了物品特征信息之外,我们也可以引入事件上下文信息对用户的时序行为进行建模,主要包括事件发生时间,地点以及事件行为类型。上下文信息的建模方式同离散特征建模方式类似,通常上下文信息取值范围不会太大,可以直接使用 one_hot 编码。上下文信息中事件的时间是比较重要的信息:如前提到的,序列推荐相对于自然语言中的序列模型虽然没有非常强的先后依赖关系,但是对于刻画用户的长期行为和短期行为以及用户行为随时间的变化趋势,时间上下文还是非常重要的。我们通常不直接使用时间戳的绝对值,而是对时间进行分桶,如我们可以在事件发生的时间与目标预测的时间之间取一个相对间隔:,其中 t 是当前目标预测时间戳,是事件的时间戳,是时间间隔单位,然后对这个间隔进行分桶。分桶方式可以根据自身需求进行设计,如论文[19]中提到了一种以 2 的幂次方来进行分桶的方式:
时间间隔映射到上述范围的结果作为分桶结果:。
得到上下文向量后,如何与物品的特征向量进行整合?简单的方式是直接与特征向量进行拼接,参见论文[14]。另外一种方法是建立上下文与物品特征的 low-rank relationship:将上下文向量分别映射到物品各个特征的向量空间内,然后与物品的特征向量进行求和 ( + ),参见论文[12];或者进行点乘 ( * ),参见论文[16]。
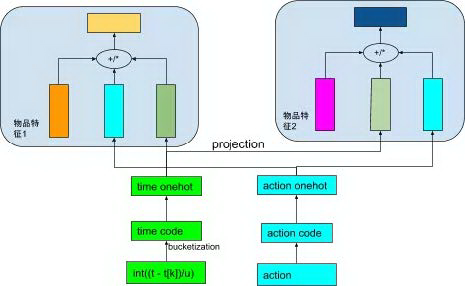
图 9 上下文向量与特征向量结合
我们为什么要将上下文信息映射到各个物品特征的向量空间内,而不是统一使用一个向量呢?因为每个特征受上下文的影响程度不同,如有些特征受时间的影响比较大,如价格,而有些特征对时间没有那么敏感,比如物品的 ID 和文字描述等。将统一的上下文信息进行细粒度的划分,能够更好的刻画用户的兴趣的变化趋势。
❷ Pooling 层
通过 embedding 层得到序列向量后,pooling 层将序列向量聚合为定长的向量,一方面后继全连接层的输入需要固定长度的向量,另一方面通过 pooling 层我们可以获取到用户历史行为序列的全局信息。pooling 层通常采用的方式有 sum pooling 或者是 average pooling。sum pooling 将序列中每个元素的向量进行累加,average pooling 则是将 sum pooling 得到的向量进行平均。简单定义如下:
k 表示向量的第 k 维,d 为向量维度。
❸ FC 层
FC 层相对比较简单:pooling 层的输出向量经过多个全连接层,最终输出用户对候选物品的兴趣的预估:P(y|x1,x2,…xn)。全连接层的输出维度一般是逐渐变小,一方面起到降维的作用,并且通过全连接去学习不同特征之间的高阶关联关系,全连接层采用非线性激活函数将所有特征向量单元之间的关联进行非线性化抽象,从而提升模型的描述能力。
❹ 注意力机制
上述 MLP 模型对物品序列的建模是独立于预测的候选物品的,我们最终形成用户行为序列向量的时候是一碗水端平的去考虑历史行为影响的。这样如论文[4]中提到的,我们没有考虑到用户兴趣存在多样性,其不同类型的历史行为对用户当前的决策影响程度也是不一样的,比如当前用户要买书,那么在用户的历史购买行为中,我们应该去多关注该用户之前都买什么样的书,而该用户在其他方面的购买记录就相对显得没有那么重要。因此一个很自然的想法是给用户的不同历史行为赋予不同权重。图 10 对上述的 MLP 模型进行了一定修改,在各个特征的 pooling 层中引入注意力机制,从过去的序列向量平均变成序列向量的加权求和,序列向量的权重由候选物品与行为物品之间的相关度决定。
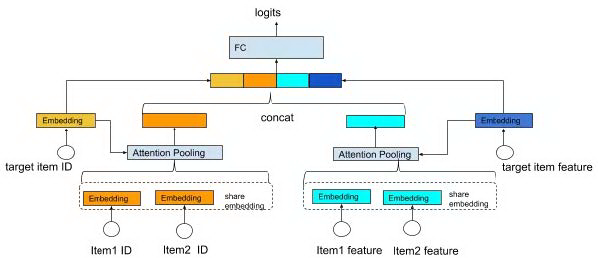
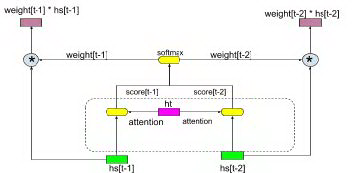
图 10 attention pooling
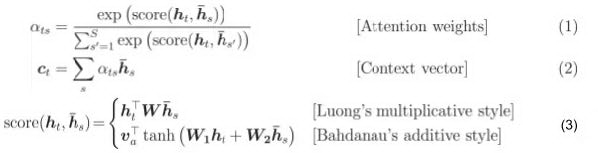
上图为 attention 的示例和公式,score(h_t,{\bar h_s)) 计算预测物品与历史序列物品之间的相关度,score(h_t,{\bar h_s)) 经过 softmax 归一化后生成序列中每个物品对应的注意力权重 ats,序列中物品向量进行带权重的求和得到整个序列的向量 ct。
注意力分数的计算除了 multiplicative 和 additive 两种计算方式外,在论文[4]中采用了基于浅层网络的方式,其中 和 通过 , 计算出候选物品与历史物品的组合向量,生成的组合向量与原始向量进行拼接,先经过一个非线性激活函数的全连接层进行降维,最终经过一个线性层输出注意力分数,这样通过向量组合和浅层网络生成注意力分数,可以尽量减少物品之间交互信息的损失。具体公式读者可以参见源论文[4]。
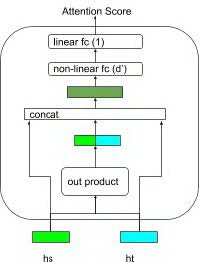
图 11 attention score from fully-connected layers
CNN
从上面 MLP 模型我们可以看到,用户历史序列的向量是通过全局 pooling 的方式得到的,相当于对用户的历史行为做了一个全局描述。但是在用户的历史行为中会存在着一些局部的连续行为模式,比如用户在过去几天内连续买过婴儿用品,那么在推荐中我们可以根据这个信息向用户推荐一些跟育儿相关的商品。在全局的 pooling 层我们有可能会丢失这些局部行为信息,因此可以建立模型来对用户行为中的局部行为模式进行建模,而局部信息建模的一个理想候选模型则是卷积神经网络 ( Convolution Neural Network )。
论文[5]讲述了如何通过卷积神经网络对用户行为序列进行建模,其建模思想同论文[6]通过卷积神经网络对句子序列进行建模完成句子分类的工作,即 TextCNN。图 12 给出 TextCNN 如何通过提取句子序列信息完成句子分类:
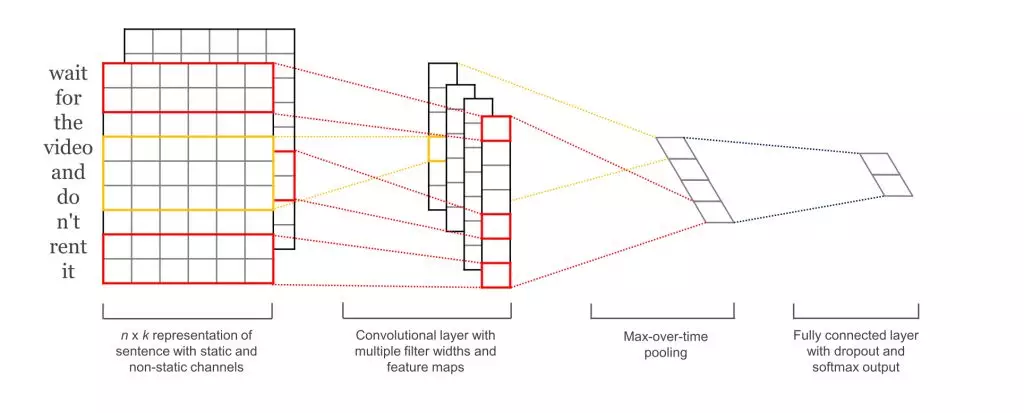
图 12 TextCNN 示意图
图中输入句子分词后的序列是 “wait fro the video and do n’t rent it”,建模步骤从左至右:第一步先将每个词映射为词向量,生成一个 n x k 的二维矩阵,其中 n 是句子的长度,k 是词向量的维度;第二步在 n x k 的矩阵上进行卷积。卷积核 [卷积高度,卷积宽度,输入维度,输出维度 ] 中卷积高度是一个超参数,由调用方指定每次卷积要覆盖的连续词的个数,卷积宽度需要跟词向量的维度一致,这是因为每一个向量代表一个词,在抽取特征的过程中,词做为文本的最小粒度,应该保证其信息的完整性。输入维度为 1,输出维度由调用者指定。一般情况下,我们会使用多个卷积核,如上图中的红色和黄色部分,分别对应卷积高度等于 2 和卷积高度等于 3 的卷积核。多个卷积核在不同的局部范围内运用相邻连续词的上下文进行建模,从而从不同的粒度去刻画句子序列的信息 ( 一般情况下,卷积高度我们一般取 2 或者 3,对应 bi-gram 和 tri-gram )。每个卷积核的输出通过池化层进行降维,通常使用最大值池化 ( max-pooling ),最后各个池化层的输出拼接在一起,送到全连接 softmax 层。
所以用卷积神经网络对句子序列的建模主要包括:1. 卷积;2. 池化;3. 拼接;4. 全连接。同样的方法也可以运用在用户的行为序列建模中。我们可以复用 MLP 的模型结构,只是在 pooling 层对输入的行为序列使用卷积和池化,其模型结构如图 13:
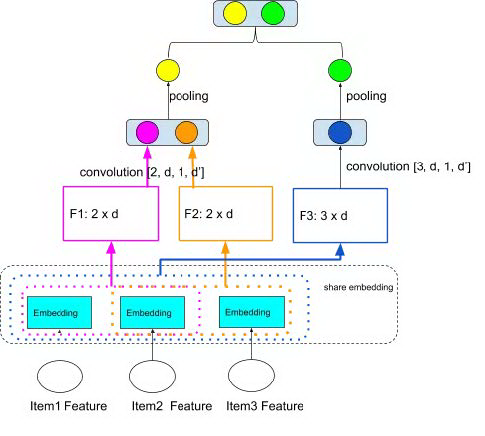
图 13 Convolution on user sequence
以下伪代码是对上图过程做一个简单描述:
CNN 和 MLP 也可以结合在一起使用,在 pooling 层采用全局的 pooling 提取用户行为序列的全局信息,同时通过卷积提取序列的局部信息,然后将两者拼接在一起作为全连接层的输入,论文[5]中提到的结合 horizontal convolution 和 vertical convolution 的方法即是采用了这种结合全局和局部信息的思想。
以上的 CNN 序列建模的一个特点是采用多个高度的卷积核来提取序列不同局部范围内的信息,每个高度的卷积只做一层,所以我们可以看做是 wide convolution。在其他领域中,我们也会采用多层的卷积神经网络来对输入的数据信息进行逐层的抽象。那么在序列推荐中,我们也可以使用同样的 deep convolution 来对历史序列信息进行处理,在后面我们会谈及相关的模型。
RNN
相对于 MLP 和 CNN 模型进行用户序列建模,循环神经网络 ( RNN ) 也许是相对更为直观的序列网络模型,可以直接去刻画用户兴趣随着时间的演化过程。循环网络可以扩展到更长的序列,相对于前馈神经网络,我们可以在不同的时间步上共享模型参数,同时循环神经网络也可用于在线实时更新。
利用循环神经网络对用户序列建模可以参见图 14:
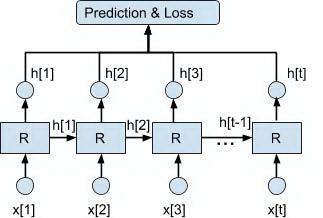
图 14 RNN 序列建模
其中 R 是展开的循环神经网络单元,可以是普通的 RNN 单元,也可以是 LSTM,GRU 等 advanced 的网络单元。x[1],x[2],… ,x[t] 是用户行为序列每个时间步上用户产生行为物品的 embedding,作为循环神经网络单元的输入,h[1],h[2],… ,h[t] 是每个时间步上循环神经网络单元的输出状态。在时间 t 用户对物品发生行为的概率为:
其中 h[t-1] 是上一时间步循环神经网络单元的输出状态,x[t] 是时间 t 用户行为的上下文信息,y 是时间 t 的 label 信息 ( 召回:第 t 个时间步用户发生行为物品的 ID;排序:第 t 个时间步用户对各个候选物品的行为的 label ),注意:我们在时间 t 进行预测时,不能将时间 t 的 label 信息 y 用到了模型训练中。
将循环神经网络运用到用户行为序列建模的一个工作来自论文[7]:将 GRU 模型 ( Gated Recurrent Unit ) 运用到用户会话上下文推荐当中。Youtube 也上线了 RNN 模型[18]并且在模型中融合了推荐的上下文信息来完成视频推荐。图 15 摘自论文[7],描述序列中每个时间步如何应用 GRU 来预测用户对物品发生行为的概率:
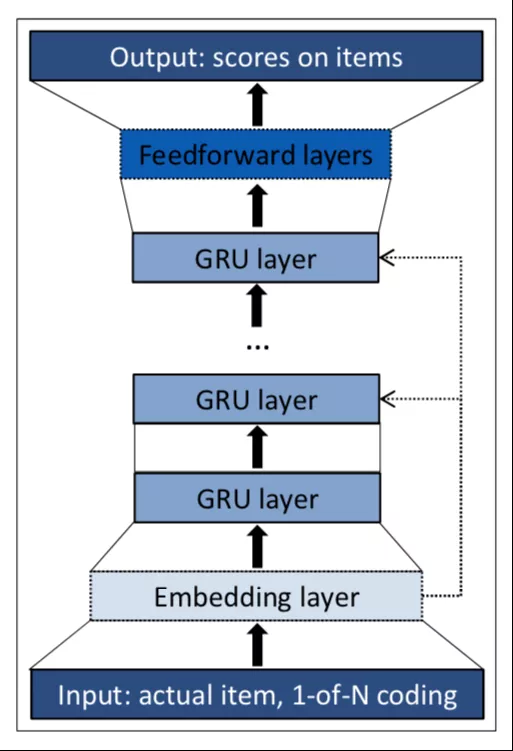
图 15 GRU 建模单元
序列中第 N 个时间步输入用户行为物品的 ID,ID 通过 embedding 层映射为向量,并进行归一化。embedding 之后经过一个或者多个 GRU 单元最后接一个 softmax 层获取每个物品的预估概率。为了防止梯度消失的问题,采用了残差网络结构,将上一个 GRU 单元的输出与 embedding 层的输出进行相加,作为下一个 GRU 单元的输入。
论文[7]对建模过程中一些具体的问题进行了讨论,如如何构建批次训练数据,如何构造训练损失函数等,感兴趣读者可以仔细阅读该论文。
上面基于 GRU 的序列推荐模型是基于物品的 ID 构建模型输入的,如果我们也希望将物品的特征信息以及上下文信息运用到模型中呢?论文[8]谈到了如何在模型中将物品的特征信息与 ID 信息结合在一起使用,如图 16:
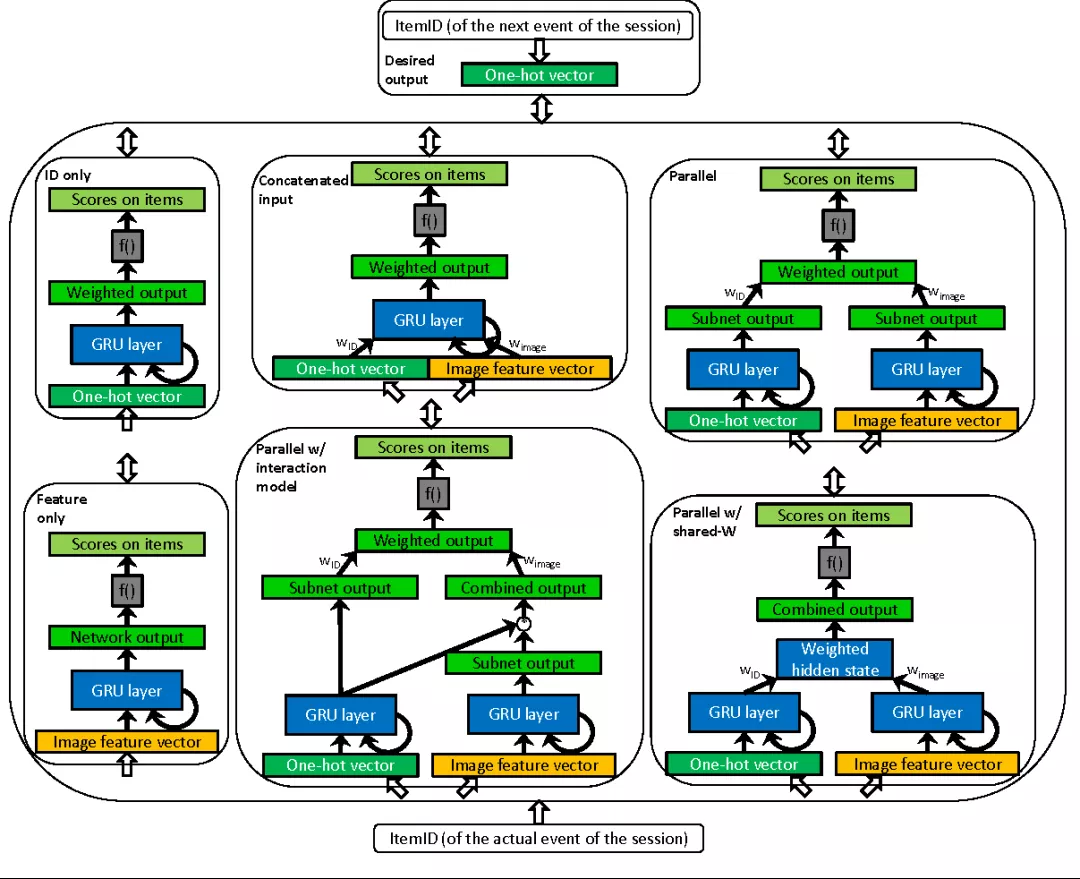
图 16 combine feature with ID in GRU
将上图的几种融合方式进行分解:
第一种也是最直接的方法是在输入端进行融合:将物品的 ID 向量和特征向量拼接为一个输入向量给到一个 GRU 单元:
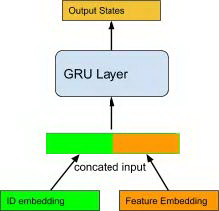
图 17 combine feature with ID in GRU inputs
第二种方法是在输出端进行融合:ID 向量和特征向量分别接不同的 GRU,然后将各个 GRU 的输出向量拼接在一起作为最终输出。相比于第一种方法, 这种方法对各个端的特征独立进行建模,在输出端进行拼接后通过后继的全连接层可以隐式加入特征之间的交互。
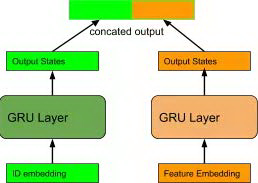
图 18 combine feature with ID in GRU outputs
第三种方法中,ID 向量和特征向量还是分别接不同的 GRU 单元,其相对于第二种方法的不同点在于显式考虑了物品 ID 和特征之间的交互。其建立交互的方式是将 ID 对应的 GRU 单元的输出状态与特征向量对应的 GRU 单元的输出状态进行点乘,作为特征部分的 GRU 的状态输出:feature_states = feature_states * id_states。可以理解为在模型中加入 ID 特征与物品特征的 low-rank relationship,从而提高模型的表达能力与泛化性。
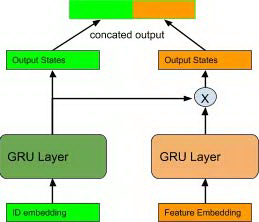
图 19 combine feature with ID via dot_product in GRU
第四种方法,ID 端和特征端的 GRU 输出状态通过一个共享的权重矩阵映射到一个输出状态向量:W * id_states + W * feature_states,相当于 ID 和特征各自的 GRU 输出状态通过带权重的求和方式进行融合,相比于前面三种方法各端的 GRU 输出是拼接在一起输入给后继模型的,各个 GRU 的输出向量不共享参数的,而第四种模型将在各端的模型输出之间共享权重矩阵,这样做的好处是减少模型的参数量,降低过拟合的风险。
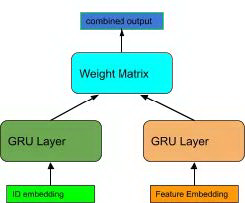
图 20 combine feature with ID via shared weight matrix in GRU
除了 item 信息之外,训练数据中的上下文信息如何集成到 RNN 模型中呢?论文[18]中提供了一种基于 dot product 的方式将上下文信息分别用在了 RNN 单元的输入和输出中,通过 dot product 去 model 用户行为的上下文信息和行为物品信息之间的 low-rank relationship,如下图:
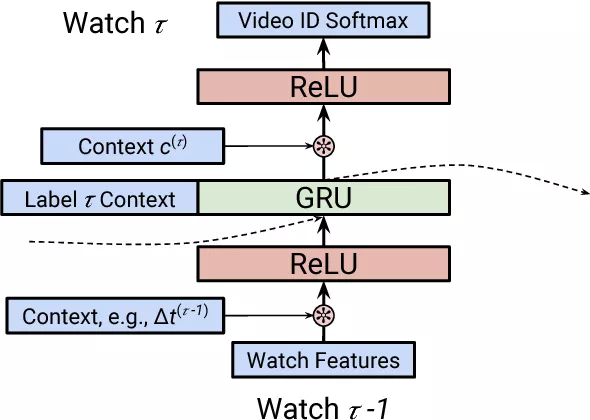
图 21 integrate context into GRU
图中模型需要预测 τ 步用户会观看哪部视频,采用的是 softmax 分类的方式完成 candidate generation。循环神经网络单元使用的是 GRU,可以看到,用到的特征包括两种:
第 τ -1 步用户观看视频的物品 feature 和上下文 feature c<τ-1>,两者做 dot product 作为 GRU 层的输入
第 τ 步的上下文信息_c_<τ>,与GRU的输出状态进行点积,作为softmax的输入。文中使用到的上下文信息包括时间,设备,访问页面。上下文信息具体加入的公式是:
Temporal CNN
RNN 结构用于序列建模的优点是结构简单,训练和预测的资源占用小,缺点是随着序列变长容易出现梯度消失的问题,同时 RNN 的训练不容易实现并行。前面我们谈了如何在时间序列上运用 CNN 进行输入序列建模,CNN 结构通过矩阵运算的并行性容易实现模型训练的并行化,同时相对不容易出现序列变长后的梯度消失问题。因此我们希望能够像 RNN 一样在整个时间序列上通过 CNN 进行建模,这样便产生了 TCN ( TemporalCNN ) [17]。TCN 采用多层的一维卷积架构在序列长度的维度进行卷积,通过 zero padding 保证每一层的长度相同。TCN 架构结合了 casual convolution ( 因果卷积 ),residual connection ( 残差连接 ) 以及 dilated convolution ( 空洞卷积 ),其特点包括:
采用因果卷积,保证训练过程中未来的信息不会泄露到过去时间的建模中;
将任意长度的序列如同 RNN 那样映射为相同长度的输出序列。
首先我们看看什么是因果卷积,如下图所示,在事件序列中每个时间步 t 的状态输出仅与前一层的 t 时刻以及 t 时刻之前的状态进行卷积:
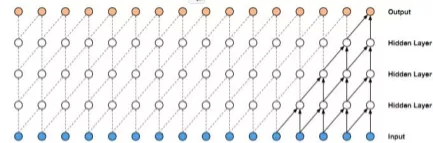
图 22 TCN causual convolution
在具体实现因果卷积时,我们可以采用在序列的开头进行补齐的方法保证输出序列的长度与输入序列保持一致,每层输入补齐的长度是:
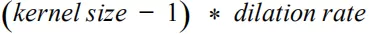
如下图所示:
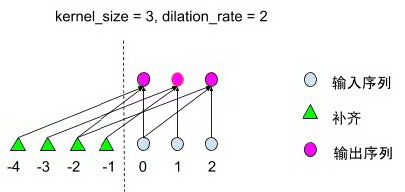
图 23 TCN padding
代码实现示例:
通过多层的因果卷积网络叠加,高层的感受野的大小与网络层数呈线性关系增加。但是为了捕捉更长的历史信息,我们可以在卷积网络中加入 dilated convolution ( 空洞卷积 )。空洞卷积通过有间隔的采样,通过较少的参数实现随着层数增加而指数级增大的感受野 ( receptive field )。相比原来的正常卷积,dilated convolution 多了一个 hyper-parameter 称之为 dilation rate ,对应 kernel 的采样间隔数量,即传统卷积核相邻之间插入 dilation rate-1 个空洞数。当 rate=1 时,相当于传统的卷积核。
当 dilation rate = d,kernel size = k 时,位置 i 的实际卷积窗口为:
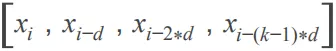
其窗口覆盖的范围大小为。空洞卷积的具体计算公式如下:
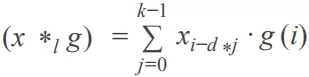
其中 g 是卷积函数, 表示只对过去时间的状态进行卷积。
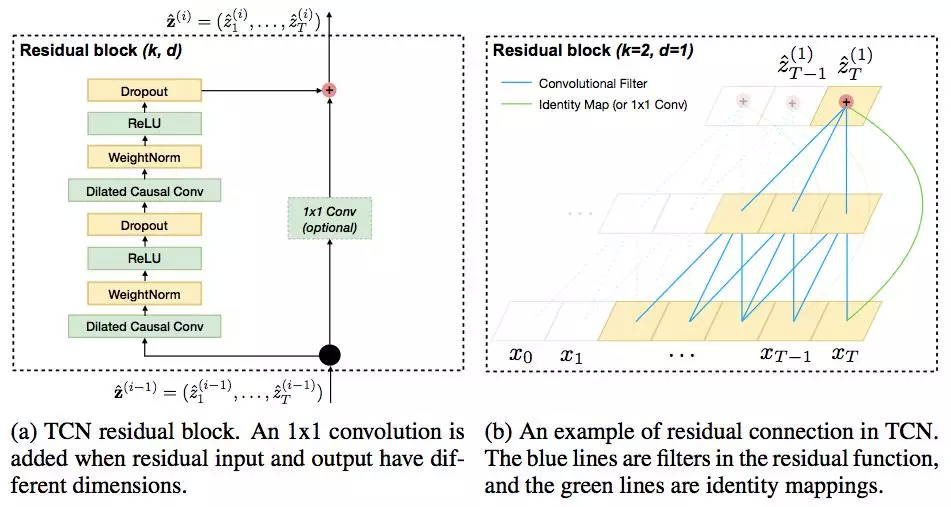
图 24 TCN residual connection
随着网络层次的加深,多层卷积结构中也可能存在梯度消失的问题,所以在 TCN 中在层与层之间引入了残差 ( residual connection )。如上图所示,一个残差结构块中包括了两个卷积结构,每个卷积结构采用因果卷积和空洞卷积,卷积后的输出进行归一化和非线性化。第二个卷积的输出维度与输入向量的维度有可能不同,因此加入了一个 1x1 的卷积将输入和输出的维度保持一致。
后来出现的 Trellis Network[11] 同 TCN 一样属于一种基于一维卷积的特殊时序网络,同样具有因果卷积 ( casual convolution ), 残差结构 ( residual connection ) 的特性,其相对 TCN 的不同点在于:
所有层之间实现权值共享;
整个网络的输入序列作为每层输入的一部分。
从下图 ( 摘自论文[14] ) 可以看到 Trellis Network 的基本结构 ( 图(a) ) 以及如何将基本结构扩展到整个序列 ( 图(b) )。
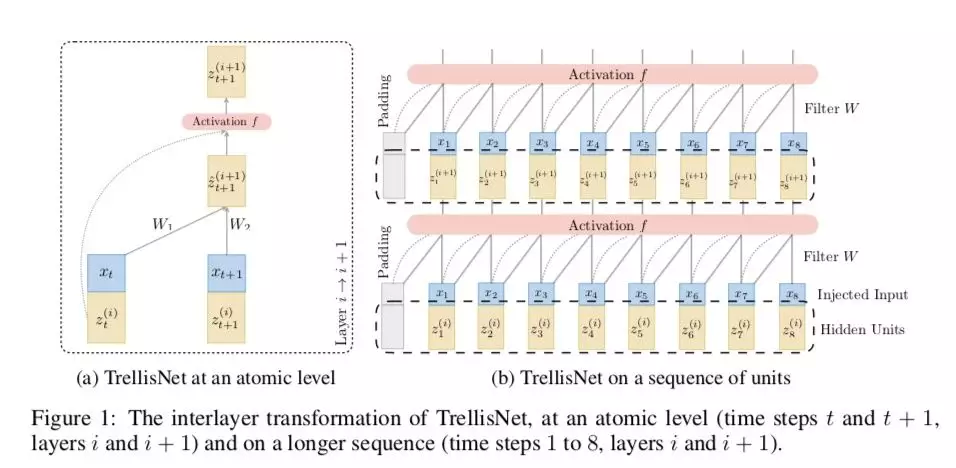
图 25 Trellis Network Architecture
TrellisNet 与 RNN 和 CNN 具有紧密的联系,因此 Trellis Network 上也可以运用 CNN 和 RNN 的某些建模技巧,例如:CNN 的大卷积核,空洞卷积,RNN 的 gated unit。关于其详细描述与证明请参见论文[11]。
Self-Attention
以上的 RNN 和 TCN 模型在建立序列模型时没有显式的去考虑各个时刻行为之间的相互关系,而各个时刻事件之间的相关性在预测任务中也是比较重要的信息,为了捕获序列中历史事件之间的相互关系,可以使用自注意力机制[12]。文中提出的 Transformer 结构在模型的 Encoder 端通过注意力机制显式计算句子序列中每个单词与其他单词之间的关联,利用层层叠加的自注意力层对每一个词得到其上下文信息的表征。Decoder 端也采用类似的机制,通过 attend 之前 Decode 端的输出以及 Encoder 端的输出产生下一步输出的文字。下图是 Transformer 中的基本 encoder-decoder 的结构:
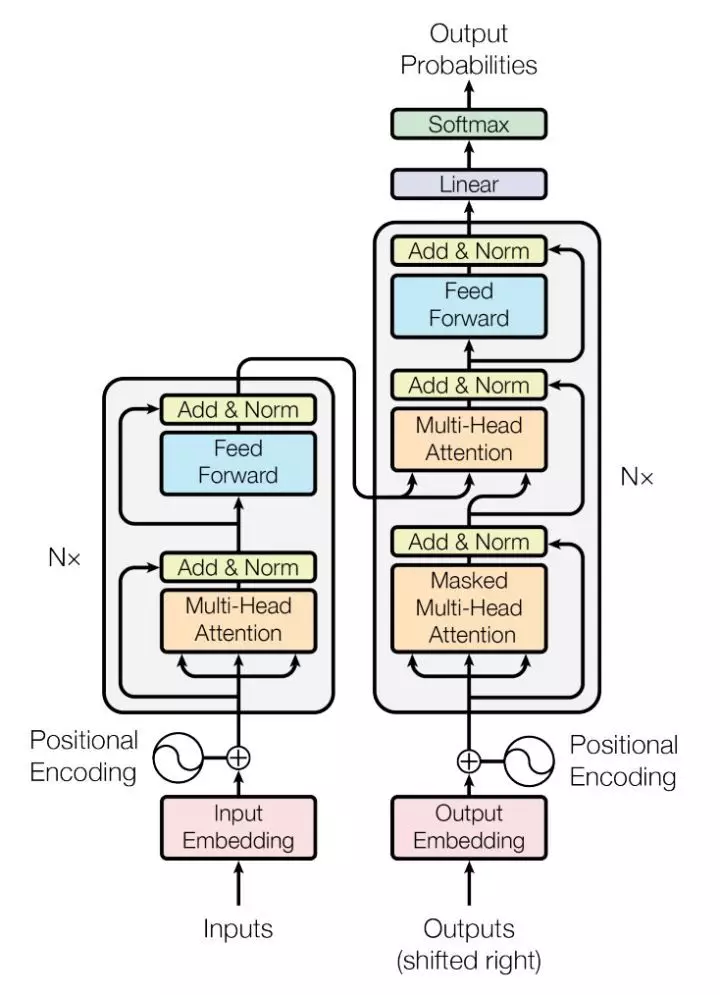
图 26 Transformer 结构
那么类似的,在用户行为序列中我们也可以运用上自注意力机制。在模型训练阶段,通过多层的自注意力模块学习序列中各个时刻事件的相互关系,最终输出序列中每个时刻的状态向量。在预测阶段,可以只用序列中最后一个位置的状态向量去表示整个序列的历史信息,如下图所示:
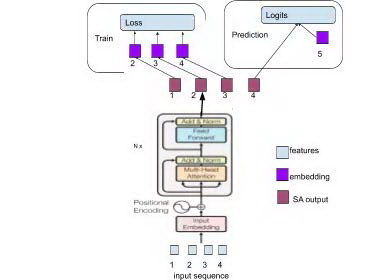
图 27 基于自注意力机制的序列模型示意
我们对模型中的几个主要部分进行讲解:
❶ Position Embedding
输入序列中的每个物品经过 input embedding layer 生成每个物品的特征向量,为了在自注意力模型中体现序列中事件发生的先后时序关系,通过 positional embedding 将序列中事件的先后顺序映射到向量空间,然后叠加到物品向量中。位置向量的生成方式可以像 transformer 一样用句中每个词在句子中的位置去做 embedding,或者通过正弦和余弦函数让网络能够理解相对位置关系 ( 对于正弦和余弦函数,pos + k 位置的 PE 可以表示成 pos 位置 PE 的一个线性变化 )。如果序列中每个事件都记录了发生的时间,那么我们可以使用事件发生的时间来做 positional embedding ( 先将事件的时间戳进行分桶,然后去做 embedding )。
❷ Self-attention Blocks
假设输入序列经过 embedding 后的向量是 X,X 的维度分别是 [B, L, H],其中 B 表示批处理的大小,L 是序列的长度,H 是隐层大小。输入序列向量经过一个或者多个自注意力模块,最终输出一个跟输入序列长度一样的输出序列:[B, L, H]。通过多个自注意力模块的叠加,逐渐让网络学习到序列中的各个事件之间更复杂的关系,迭代地构建输入序列的整体信息。
每个自注意力模块如上图所示可以分成两个部分:
① Multi-Head Attention
Multi-Head Attention 中学习事件之间的相互关系。多头 ( Multi-Head ) 类似 CNN 中不同 size 的 kernel,每个 head 对应一个特定的状态子空间,head 之间参数不共享。设置独立的 head 有两个好处:第一个好处是可训练参数更多,各个 head 专注于不同方面的信息,模型更具扩展性;另一个好处是特定 head 捕获输入之间的特定关系,为 Attention 赋予了多个表示子空间,极大提升模型表现能力,这是传统序列模型所不具备的。在实际计算中,我们先在隐层向量维度 ( H ) 切分出 head,然后在各个 head 空间内做 Attention。如下图,我们需要计算第 2 个事件 attention 后的向量,可以按照图示步骤来完成:
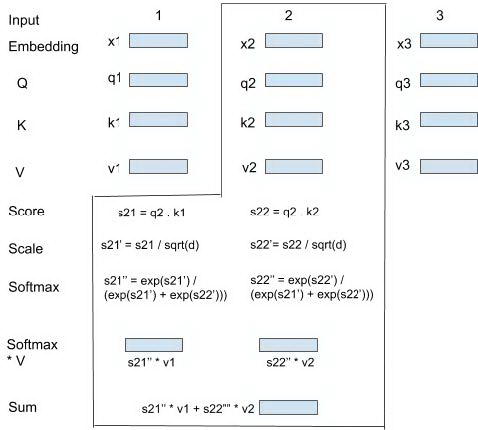
图 28 时刻 2 的 attention 示意
上图的核心可以用以下公式来概括:
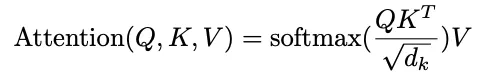
其中 Q, K, V 分别是输入 X 分别做线性映射得到的向量,对应 Attention 中的 query, key, value。除以 是因为在 Q,K 的维度比较大的时候,容易进入 softmax 饱和区,进行缩放可以保持梯度的稳定性。
另外需要注意的是,q2 只与当前以及之前位置即 k1, v1 和 k2, v2 进行 attention。在实际实现中我们可以在 后加上一个 mask 矩阵 M,M 矩阵是一个下三角矩阵,维度是 [B, L, L],M[b, i, j] 表示序列 b 中第 i 个位置是否能够与第 j 个位置进行 attention:
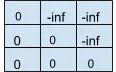
M[b, i, j] = 0,表示 i 可以与 j 做 attention,M[b, i, j] = -inf ( 一个很大的负数,eg . -1e9 ),表示 i 不能与 j 做 attention。设置一个很大的负数, + M 经过 softmax 后不能做 attention 的位置则变为 0。
每个 head 输出的 embedding 通过 concat 生成 Multi-Head Attention 的输出。

② Position-wise Feed Forward
Multi-Head Attention 的输出作为 Position-wise Feed-Forward Network 的输入。
每个 FFN 包括两个全连接层,第一个全连接层运用 ReLu 的激活函数,第二个全连接层是一个线性映射。

图 29 Position-wise Feed Forward
公式:
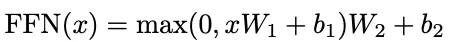
在该公式中, 在每个位置是共享的,各个位置的向量之间不相互作用。在 Multi-Head Attention 中各个 head 内部主要进行线性变换,head 和 head 之间相互独立。在 FFN 层通过非线性全连接网络在 head 信息中引入非线性性,并将各个 head 之间的信息进行关联, 类似于在 Deepfm 中通过 MLP 进行高维度的特征组合。
③ LayerNorm & Residual Connection
在 Multi-Head Attention 和 FFN 的输出中都加入了残差连接和 Layer Normalization。残差连接中将模块的输入加到模型的输出中,以防止随着模块层数加深出现的梯度消失问题。LN 对序列中每个位置的输出状态向量进行标准化,使得输出数据的整体分布更加稳定。自注意力模型中没有使用 Batch Normalzation,因为 BN 受到 batch size,sequence length 等因素的影响,并不适合序列模型。LN 和残差连接使用公式如下:
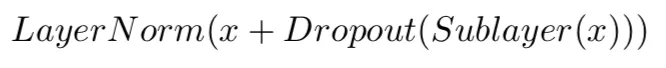
❸ Train
经过多层自注意力模块后,得到序列的输出向量 O:[B, L, H]。假设输入序列向量为 E:[B, L, H],我们使用点积 ⊙ 计算 O 与 E 的相关度:
R[b][t] 表示第 b 个序列中第 t 个时间步行为物品 ( positive item ) 的向量与 t 时刻之前位置的输出向量的相关度 ( 取 t-1 时刻来代表 t 时刻之前位置的信息 ),相当于是将 O 右移了一位,以保证我们用每个时刻之前的信息来预测在该时刻与行为物品的相关度,如图 27 中我们使用步骤 1,2,3 的输出状态去预测步骤 2,3,4。在 t 时刻我们可以随机 sample negative items 然后采用 pairwise rank loss,增大 postivie item 的相关度并减小 negative item 的相关度。
❹ Prediction
预测时,我们取序列的最后一个元素的输出向量 V,待预测的目标物品的向量为 W,使用点积 ⊙ 计算 V 与 W 的相关度:
predict_score =
自注意力模型本小节开始已经谈了其优点,能够在长序列上比较好的去建立各个时间之间的相关性,不过模型本身比较复杂,每层计算复杂度比较高,而且模型在数据量较小情况下不容易收敛,效果不一定比 GRU 这类简单模型好,因此在实际应用中需要对数据和工程做比较多的调整和优化。
强化学习
这一节我们换个角度去看序列推荐问题。如果我们将用户的行为序列看做是一个顺序的决策过程,那么我们可以用马尔科夫决策过程 ( MDP ) 来表示用户的行为序列。马尔科夫决策过程包含以下几个方面:
❶ 状态空间 S
在 t 时刻用户的状态 St 定义为用户在 t 时间之前的历史行为,如用户在 t 之前点击过的 N 个物品。马尔科夫决策过程中每个状态具有马尔科夫性,即
因此序列中用户在各个时刻的状态可以只根据前一时刻的状态得到。
❷ 动作空间 A
动作定义为可以给用户推荐的候选物品空间。agent 的一次推荐相当于在候选物品空间内选择一个或者多个物品返回给用户。
❸ 奖励 R
agent 推荐物品给用户之后,根据用户对推荐列表的反馈 ( 忽略或者点击 ) 来得到 ( 状态-行为 ) 的即时奖励 reward:
中 t+1 表示奖励具有延迟性,即在一个时刻发生行为,在下一个时刻收到环境的反馈。
❹ 转移概率 P
用户在 t 时刻的状态为用户最近点击的 N 个物品,定义为 。我们定义
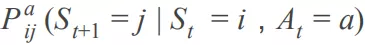
为用户在 t 时刻对物品 a 产生行为反馈后从状态 转移到状态 的概率。agent 为用户推荐了 K 个物品, 如果用户忽略了推荐的全部物品,那么下一个时刻的状态 和当前的状态保持一致。如果用户点击了其中一个推荐的物品,那么下一个时刻的状态 是在当前状态
的基础上,加入该点击的推荐物品并且将原来的 N 个物品中点击时间最久远的那个物品去掉 ( 可以理解为一个先进先出的队列 )。
❺ 折扣因子
实际情况下我们希望最大化的是长期回报而不仅是即时奖励。因此 t 时刻的回报为从该时间起的一个总折扣奖励,即
$G_t=R_{t+1}+\gamma R_{t+2}+\dots=\sum^{\infty}{k=0}\gamma^kR{t+k+1}$
折扣因子一般取 0 到 1 之间的一个数。
❻ 策略
有了状态和行为,我们会用策略 ( policy ) 来形式化的刻画用户的决策过程。策略描述了用户在某个状态 s 下采取某个行为 a 的概率:
可以理解为用户在某个时间点的状态 s 下对候选物品 a 产生行为的概率。
❼ 值函数
用值函数来刻画行为的回报。值函数分为两种,一种定义为从一个状态 s 开始的回报期望值:
它衡量的是从某个状态开始所能得到的累计回报的期望值。另外一种定义为从一个状态 s 开始,采取某个行为 a 后的回报期望值
对应用户在某个具体状态下采取某个具体行为的累计回报的期望值。至于如何求解 和 ,读者可以参阅相关的强化学习的资料。
回到序列推荐问题上来,我们的目标是找到一个最优的决策过程 ( policy ) 以最大化整个序列的期望回报:
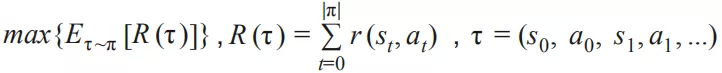
求解这个问题我们可以采用的方法包括:value-based 和 policy-based 方法。在实际应用中,由于物品空间一般比较大,采用 value-based 方法计算开销比较大,模型不易收敛,更多情况下会采用 policy-based 方法,如 policy gradient。Policy gradient 中每次策略采取某个动作的概率通过模型 θ 计算:
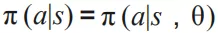
目标是求解模型 θ 使得整个行为序列的回报最大化:
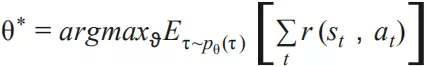
设
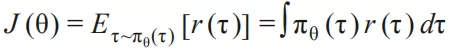
对 θ 求导:
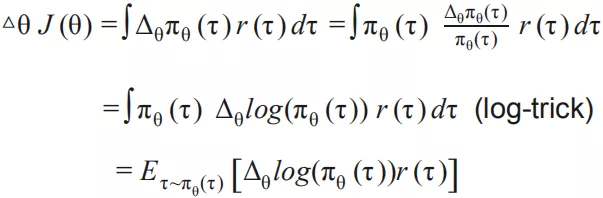
其中关键点是求 ,
设
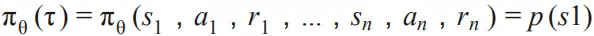
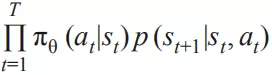
则
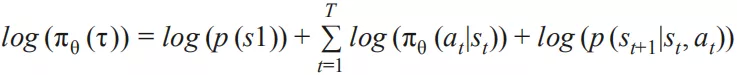
其中 和 跟 θ 无关,那么
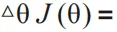
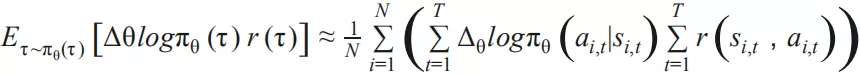
其中 对应模型的输出, 对应行为的回报期望。关于 policy gradient 的详细推导请参见[20]。
接下来需要定义的则是模型 θ 以及奖励 r。t 时刻的奖励 r 是从该时刻开始到将来某个时刻的回报的期望值。在实际应用中,比较直接的是采用 t 时刻的即时回报,如用户是否发生点击行为来作为奖励 r,同时可以考虑 t 时刻之后一段时间内用户的反馈行为,如用户的停留时长等。模型 θ 对 t 时刻的用户序列状态进行建模,输出该时刻的用户状态向量。论文[16]中 θ 采用的是 RNN 来对用户行为序列进行建模,如下图所示:
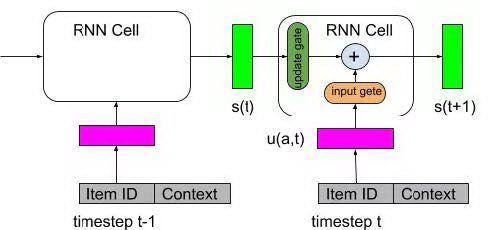
图 30 RNN cell for policy gradient
其中 s(t) 是第 t 步的输入状态,来自于第 t-1 步 RNN 单元的输出状态,同时在 t 步用户对推荐物品 a 产生行为,其中 a 对应的 embedding 是 u(a, t),包括 t 时刻物品的 embedding 和 t 时刻的上下文 embedding。将 s(t) 和 u(a, t) 输入第 t 步 RNN 单元的 update gate 和 input gate,产生输出状态 s(t+1):
根据用户的当前状态采用 sampled softmax 产生候选推荐物品,也就是策略 的输出:
v(a) 是候选物品的向量,上面这个公式即 youtube DNN 做召回的思想:在实际使用中,用 RNN 的输出状态做 k-nearest neighbor search, 得到一个相对较小的候选集合,然后再在这个候选集合中计算每一个候选物品的概率。
文[15]中采用的是 off-policy 的 RL ( 相对于 on-policy,off-policy 从不同分布的反馈数据中学习 ),需要考虑 bias correction。关于具体如何对 data bias 进行 correction,可以参看论文。
总结
综上所述,把对以上几个模型的一点个人认识归纳如下表,仅供参考:
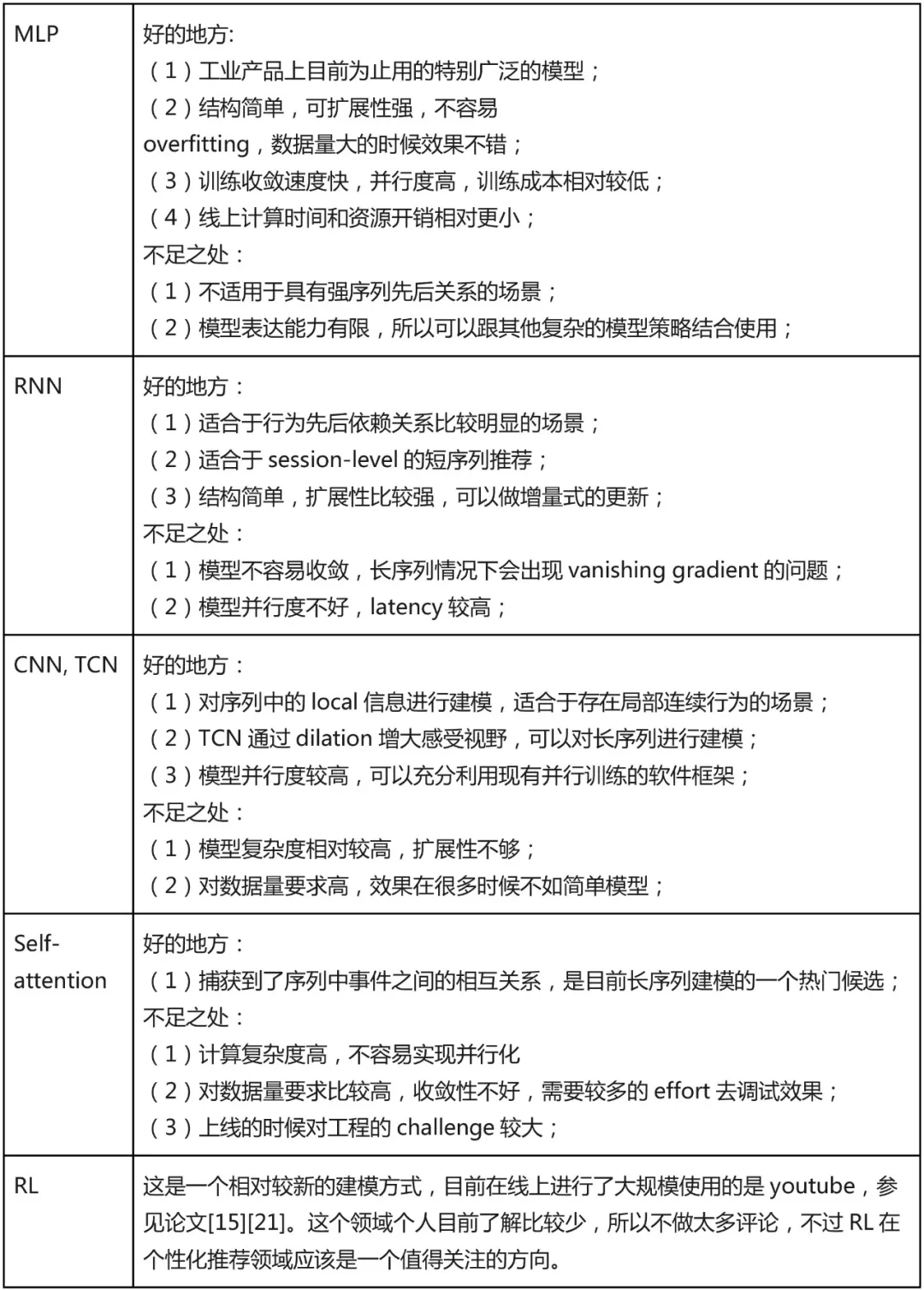
至于在具体选型时候,应该选哪个模型用到产品上,个人觉得可以参考以下两个建议:
找适合业务需求的:根据自身的业务目标,当前的数据量,数据中信息丰富程度,工程架构上的支持,训练成本,上线成本等来折中考虑。
先选简单的,简单的模型大部分情况下都 work 的比较好。
读者可以比较工业界和学术界发表的论文即可看出,工业界使用的模型大部分情况下都更简单易扩展,更多注重数据和工程实践。因此在选型时候,可以多参考现有的工业界的成果,快速搭建 baseline 系统,然后再逐渐改进。
参考文献
[1] Deep Learning based Recommender System: A Survey and New Perspectives
[2] Deep learning sequential recommendation systems
[3] Image Matters: Visually modeling user behaviors using Advanced Model Server
[4] Deep Interest Network for Click-Through Rate Prediction
[5] Convolutional Sequence Embedding Recommendation Model
[6] Convolutional Neural Networks for Sentence Classification
[7] Session-based recommendations with recurrent neural networks
[8] Parallel Recurrent Neural Network Architectures for Feature-rich Session-based Recommendations
[9] Hierarchical question-image co-attention for visual question answering
[10] An Empirical Evaluation of Generic Convolutional and Recurrent Networks for Sequence Modeling
[11] Trellis Networks for Sequence Modeling
[12] Attention Is All You Need
[13] Layer Normalization
[14] Deep Neural Networks for YouTube Recommendations
[15] Top-K Off-Policy Correction for a REINFORCE Recommender System
[16] Latent Cross: Making Use of Context in Recurrent Recommender Systems
[17] Convolutional sequence modeling revisited
[18] Learning Deep Structured Semantic Models for Web Search using Clickthrough Data
[19] ATRank: An Attention-Based User Behavior Modeling Framework for Recommendation
[20] A blog summarizing policy gradient:https://lilianweng.github.io/lil-log/2018/04/08/policy-gradient-algorithms.html
[21] Reinforcement Learning for Slate-based Recommender Systems: A Tractable Decomposition and Practical Methodology
本文来自 DataFunTalk
原文链接:
https://mp.weixin.qq.com/s/nqCJOstJlZv6CrMST-tH8g

Java 避坑指南:Java 高手笔记代码篇
本迷你书包括 86 个业务开发中常见踩坑点。每一个知识点都相当的实用,是程序员业务开发中的必备避坑指南...










评论