
“在 AI 超节点系统的设计上,不应该再依照惯性思维,过分追求规模,而是应该从客户视角出发,把 token 交互速度作为关键衡量指标,这是智能体时代 AI 超节点的核心商业价值。”这是浪潮信息首席 AI 战略官刘军近期接受采访时,反复强调的一点。

浪潮信息首席 AI 战略官刘军
智能体时代,速度就是金钱
规模扩展定律(Scaling Law)一直是驱动大模型智能持续增长的底层逻辑,推动着模型参数量从百亿、千亿迈向现在的万亿。在后训练阶段更多的算力投入,能显著提升模型的推理能力,而以推理能力为代表的复杂思维的涌现,是构建智能体应用的基础。另一方面,以 DeepSeek 为代表的开源大模型极大的降低了创新门槛,加速了智能体产业化的到来。
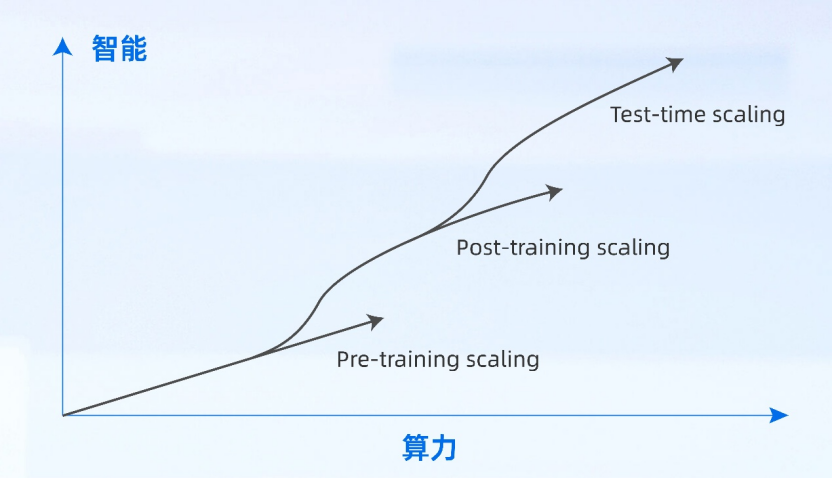
Scaling Law 驱动智能持续进化
刘军指出,“智能体产业化的核心三要素是能力、速度和成本。其中,token 交互速度决定了智能体的商业价值。在当下最常见的人机对话场景中,基本上按照大概 50 毫秒的水平,就是每秒输出 20 个 token,人的阅读速度就能跟得上。但很多人还没意识到,未来的智能体时代会更多的出现机器与机器之间的交互场景,对于智能体之间的交互而言,这个速度远远不够,比如说直播电商、量化交易、欺诈防控等特定业务场景中,对 token 生成速度的最低要求都是 10 毫秒以下。”
以高强度、实时互动的直播电商场景为例。2024 年底,某知名直播电商平台进行了专家组合智能体的 A/B 实验,实验组部署了经过深度优化的智能体,对照组则使用未经优化的标准版本智能体,优化后的智能体平均响应延迟相较于对照组降低了 38%。实验结果表明,部署了低延迟智能体的直播间,其商品交易总额(GMV)平均提升了 11.4%,同时用户的复购率也取得了 7.8%的显著增长。
38%的延迟降低,并非提升了智能体回答内容的质量,而是确保了这些回答能够被精准地投递在用户购买意图最为强烈的“黄金窗口”期内。在直播电商这类场景中,用户的购买意图是瞬时且易逝的。一个高延迟的回答意味着当智能体还在“思考”时,用户的注意力可能已经转移,或者主播已经开始介绍下一件商品,从而错失了最佳的销售转化窗口。
“在智能体时代,快,不再是可选项,而是商业成功的刚性约束。”刘军强调,“只有当智能体的响应快于业务决策的窗口期,快于用户耐心消逝的临界点……AI 才能真正成为核心生产力。”
token 交互速度正在重塑 AI 算力价值评估体系
事实上,对于 token 交互速度的考量正在重构 AI 算力系统的价值评估体系。最近广受关注的 InferenceMax™ 开源 AI 基准测试,正在创造一种动态追踪模型更迭的算力评估体系,试图在真实 AI 推理环境下衡量各类 AI 算力系统的综合效率。在这一基准测试中,token 生成速度被列为最重要的一项衡量指标。
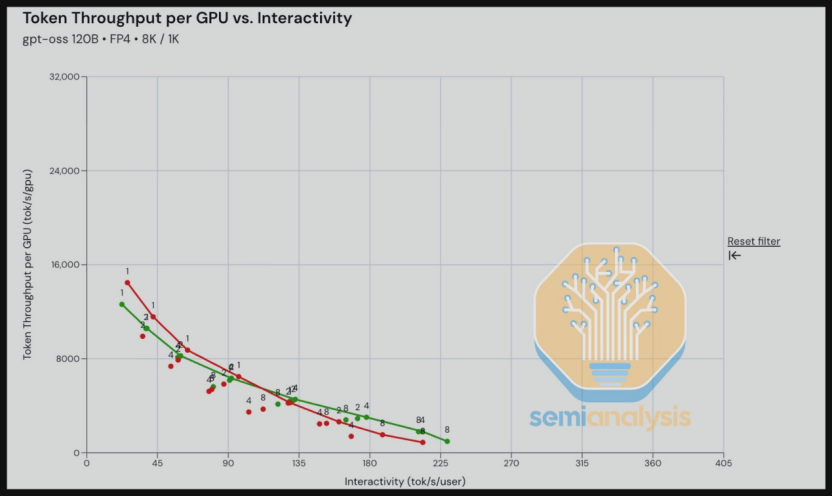
SemiAnalysis InferenceMAX™ 开源 AI 基准测试
横轴:交互速度(Interactivity,单位:tok/s/user);纵轴:单位 GPU token 吞吐量(Token Throughput per GPU,单位:tok/s/gpu)
同时,清华大学与中国软件评测中心(CSTC)对 20 余家主流大模型服务提供商的综合表现进行了全面评估,联合发布了大模型服务性能排行榜,明确指出延迟指标是用户体验的核心,直接决定用户留存,是平台差异化竞争的首要技术门槛。因此,速度同样也成为了大模型 API 服务提供商的核心竞争力。当前,全球主要大模型 API 服务商的 token 生成速度,基本维持在 10~20 毫秒左右,而国内的生成速度普遍高于 30 毫秒。
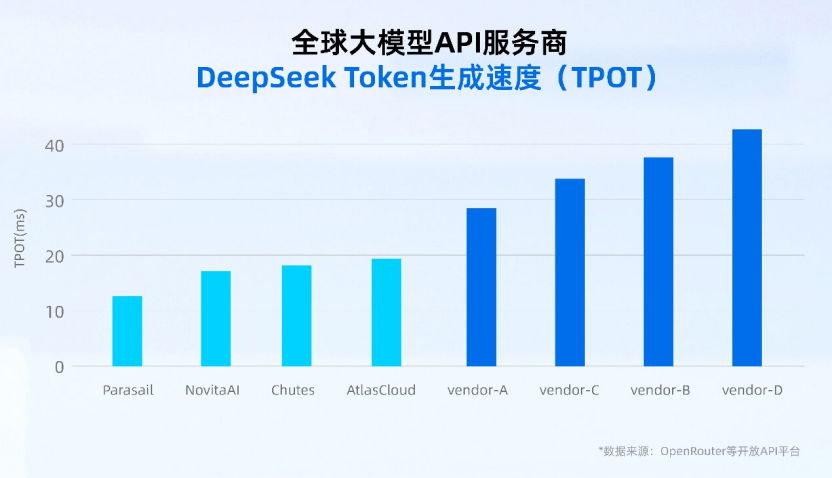
全球大模型 API 服务商 DeepSeek Token 生成速度
元脑 SD200 将 token 生成速度带入“10 毫秒时代”
要实现更低延迟的 token 生成能力,必然要求底层算力基础设施在系统架构、互联协议、软件框架等关键点上进行协同创新。
浪潮信息对元脑 SD200 超节点 AI 服务器进行了大量的软硬件协同创新与优化,实现 DeepSeek R1 大模型单 token 生成速度低至 8.9 毫秒,带动国内 AI 服务器 token 生成速度率先进入“10 毫秒时代”。

元脑 SD200 超节点 AI 服务器
对于为何能在 token 生成速度上实现如此出色的性能,刘军表示,智能体中各个模型之间的交互,很多时候通信数据包并不是很大,超高的带宽会出现浪费,“就像是从 a 地到 b 地修了 16 车道的高速公路,但是车辆在 16 车道上只跑了很短的距离,反而在上高速和下高速这两个节点花了很长时间。浪潮信息的优化重点,就是解决车辆上高速和下高速的卡点问题,让车辆直通上来,直通下去。”
元脑 SD200 采用了独创的多主机 3D Mesh 系统架构,实现单机 64 路本土 AI 芯片高密度算力扩展,原生支持开放加速模组 OAM,兼容多元 AI 芯片。同时,元脑 SD200 通过远端 GPU 虚拟映射技术创新,突破跨主机域统一编址难题,实现显存统一地址空间扩增 8 倍,单机可以提供最大 4TB 显存和 64TB 内存,为万亿参数、超长序列大模型提供充足键值缓存空间。基于创新的系统架构设计,元脑 SD200 单机即可承载 4 万亿单体模型,或者同时部署由多个万亿参数模型构成的智能体,多模协作执行复杂任务。
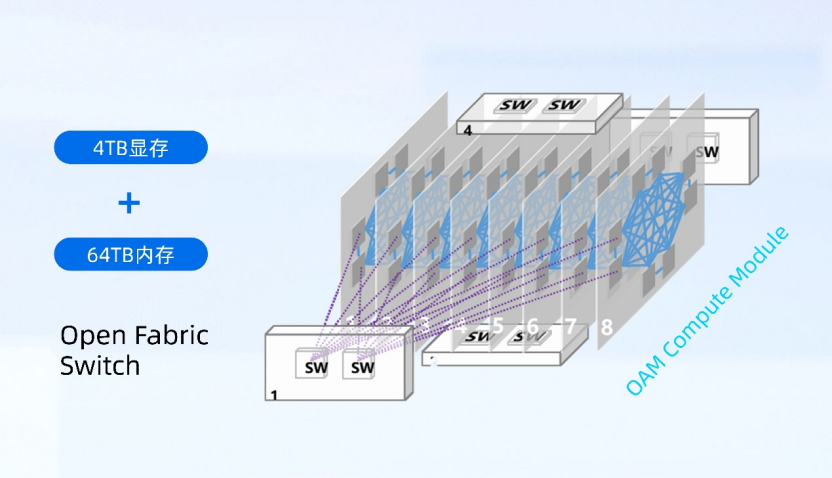
元脑 SD200 创新多主机 3D Mesh 系统架构
互连协议的设计是元脑 SD200 实现极低通信延迟的关键,浪潮信息做了大量的通信优化和技术创新,如采用极致精简的 3 层协议栈,并原生支持 Load/Store 等“内存语义”,让 GPU 可直接访问远端节点的显存或主存,将基础通信延迟缩短至百纳秒级;另外 Open Fabric 原生支持由硬件逻辑实现的链路层重传,重传延迟低至微秒级,特别是分布式、预防式的流控机制,实现全局任务均在发送前确保接收端有能力接收,从根本上避免了拥塞和丢包。
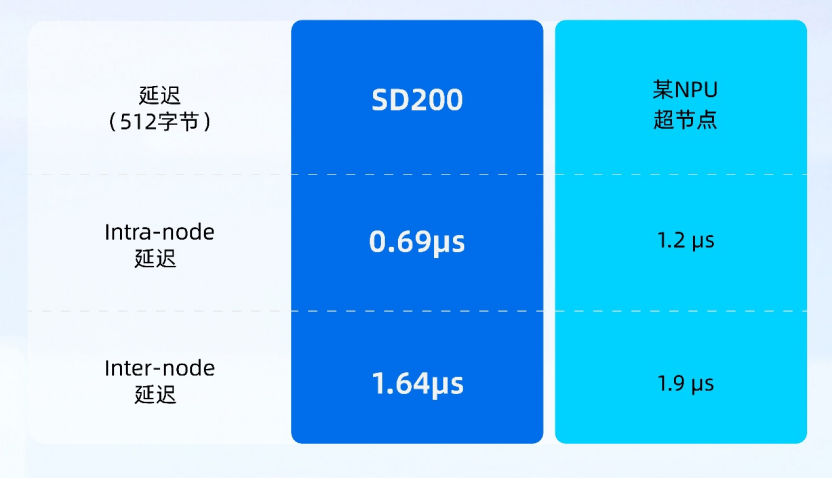
元脑 SD200 极低 Latency 通信
除了硬件方面的创新,浪潮信息也针对 DeepSeek、Kimi 等模型的计算特征和元脑 SD200 的硬件架构特征,完成了通信库、计算框架、PD 分离策略等多方面的优化,大幅提升了 DeepSeek、Kimi 等大模型的推理输出速度。通信库层面,针对 Allreduce、Allgather、Alltoall 等典型通信算子,浪潮信息制定了与元脑 SD200 深度适配的通信算法;框架层面,浪潮信息完成了并行方式、算子融合、多流水线等多方面优化,来保证计算的低延迟;在推理阶段,浪潮信息开发了预填充-解码 (Prefill-Decode) 分离软件,针对预填充与解码不同的计算特性,使用不同的并行计算策略、硬件配置等,提高系统整体的计算性能。
实测数据显示,元脑 SD200 搭载 64 张本土 AI 芯片运行 DeepSeek R1 大模型,当输入长度为 4096、输出长度为 1024 时,单用户 token 生成达到 112 tokens/s,每 token 生成时间仅为 8.9ms,率先实现国内 AI 服务器 token 生成速度低于 10ms,将推动万亿参数大模型在金融、科研、智能制造等领域快速落地。
未来十年 AI 经济的增长边界,从某种意义而言,将取决于整个行业在算法、软件和硬件层面协同攻克延迟挑战的能力。“速度就是金钱”不仅是一种新的商业主张,更是驱动下一代人工智能增长的核心经济逻辑。浪潮信息将面向智能体产业化需求,持续以架构创新激发产业创新活力,让 AI 成为百行千业的生产力和创新力。




