

导读:阿里小蜜是阿里巴巴服务领域的重要人工智能产品,是服务于阿里巴巴经济体、商家、企业和政府的对话机器人家族,包括阿里小蜜、店小蜜、云小蜜。小蜜机器人是基于大数据和人工智能技术形成的智能化、体系化客服系统,可以辅助企业智能决策、节约服务成本、提高服务效率、提升用户体验。作为阿里小蜜的基石,知识是小蜜体系中不可或缺的组成部分。小蜜的知识不仅仅包括常见的 FAQ,还包括词组、知识图谱、机器阅读文档等丰富的结构形态。本文主要分享阿里小蜜体系中知识的结构化以及在实际场景中的应用。
本文的主要内容包括以下几点:
阿里小蜜的简介
知识的结构化
基于结构化知识的应用:KBQA 和 EBQA
展望和挑战
阿里小蜜的简介
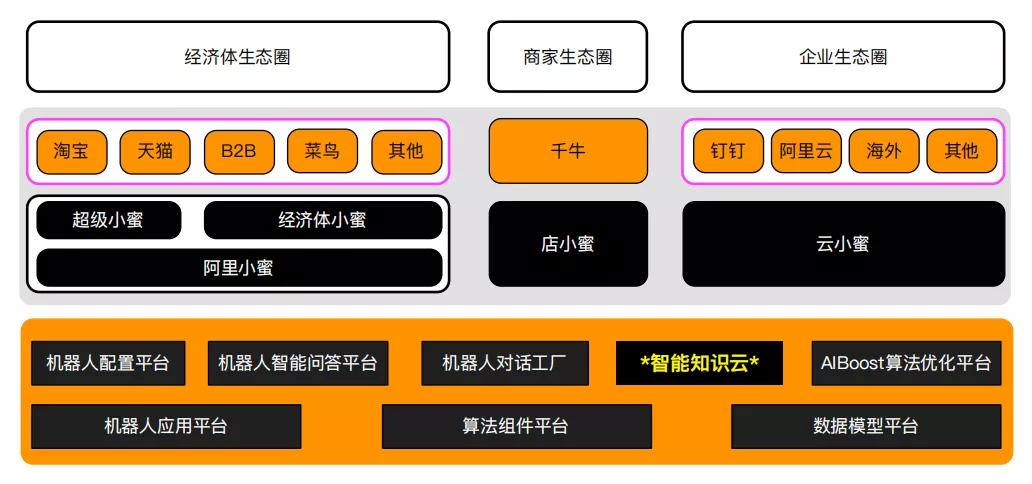
阿里小蜜机器人是一个对话机器人家族体系,不仅是指支持经济体生态的阿里小蜜,还包括了支持商家生态的店小蜜以及支持企业生态的云小蜜。在机器人的底座,是一套体系化的支撑平台,涵盖机器人的开发、配置、训练和知识等重要方面。其中,本文主要介绍的知识云是阿里小蜜的新一代知识库系统,支持基于词组、FAQ、知识图谱、机器阅读文档在内的丰富的知识体系,为阿里小蜜提供高效可靠的知识服务。
知识的结构化
小蜜的 AI 闭环
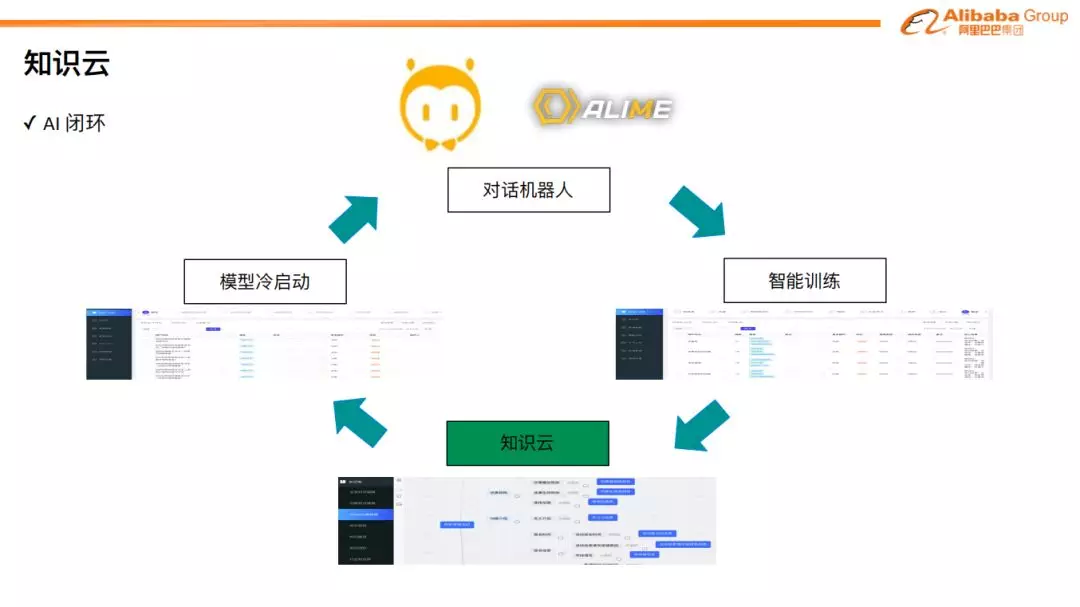
在小蜜的体系中,我们通常基于知识来开发算法模型。在模型的冷启动阶段,我们会借助智能辅助产品 AIBoost,通过人工标注、算法推荐、数据增广相结合的方式,来产生模型的训练语料。在模型开发上线以后,针对模型不能回答的问题,我们会回流补充到训练数据集中,继续训练和优化模型。如果发现是因为知识缺失造成不能回答,我们会对知识进行相应的补充。整个过程构成了一个完整的 “AI 闭环”。
知识结构的演进

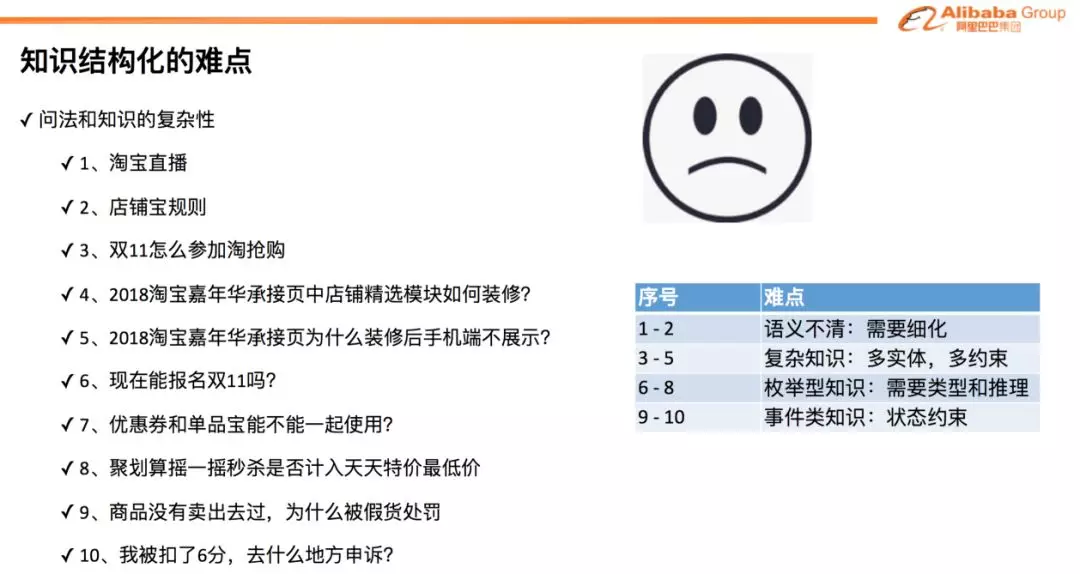
在开始阶段,小蜜采用 QA 体系作为主要的知识结构,并且取得了非常不错的效果。QA 结构具有简单易用、冷启动方便、算法成熟的一系列优点。但是,随着场景越来越丰富和复杂,QA 的解决能力遇到了瓶颈的问题。这是由于 QA 体系存在着一些缺陷。其一是知识的类似性或者冗余性。例如,“双 11 的报名入口在哪” 和 “双 12 的报名入口在哪”,这两条知识都是关于 “报名入口”,但是属于不同的活动。如果采用 QA 的方式,每个活动这种类似的知识都必须单独枚举出来,实际业务中不仅需要大量的知识维护成本,同时对算法模型的定位匹配也会造成很大的干扰。另一个缺点是 QA 缺乏推理能力,例如,“我现在还能不能参加今年的双 11” 这个问题,是一个关于时间节点的知识。其实,在双 11 的知识条目里面,已经清楚的描述了参与报名的时间段。但是,在传统的 QA 体系下,这个问题是没法去进行推理和准确回答的。
知识图谱
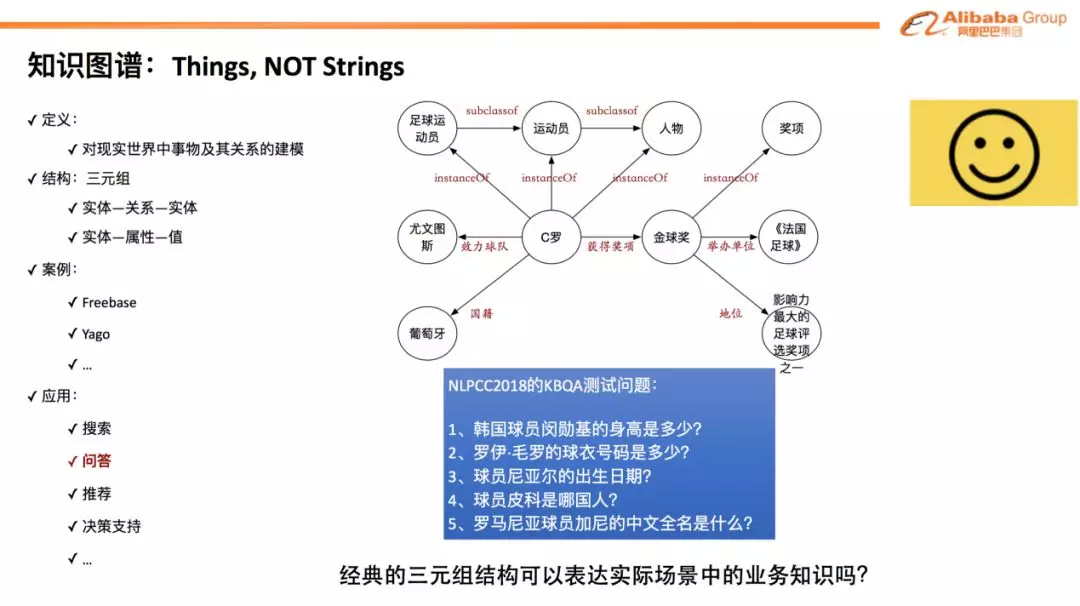
提到知识的结构化,我们首先会想到的通常是知识图谱 ( KG ) 和经典的三元组结构:“实体-关系-实体” 和 “实体-属性-值” 这样的表达。但遗憾的是,这样的经典三元组结构表达能力是有限的,在实际场景中无法全面的表达业务知识。下图列举了实际场景中的一些 QA 知识,并总结了知识结构化的一些难点。
知识的结构化表示
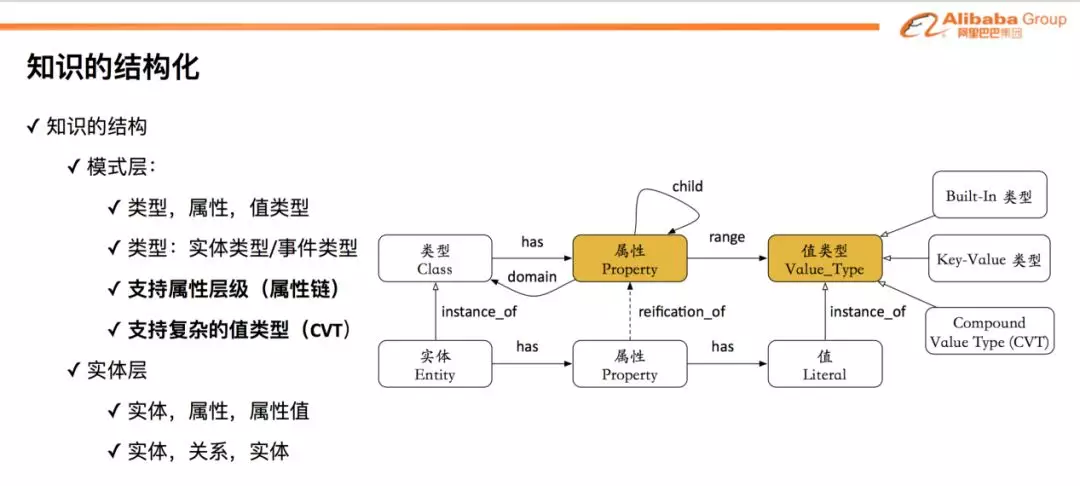
因为经典三元组表达能力的局限,在阿里小蜜中我们重新设计了知识结构。主要分为两个层级:模式层和实体层
❶ 模式层
在模式层里面,我们定义类型、属性和值 ( 以及关系 )。其中类型可以包括实体类型和事件类型;对于属性,我们也做了一个扩展,支持子属性,也就是说我们的属性是有层级关系的,可以组成属性链;对于值的定义除了保留原来 Text/字符串 ( Built-In 类型 ) 外,还加入两个新的类型:Key-Value 类型和 Compound Value Type ( CVT ) 类型。我们的这些扩展,可以充分增强 KG 的表达能力,应用于实际业务知识的表达和建模。
❷ 实体层
实体层是对模式层的实例化。在实体层里面,我们采用类似的 “实体-属性-值” 和 “实体-关系-实体” 来对知识进行建模。
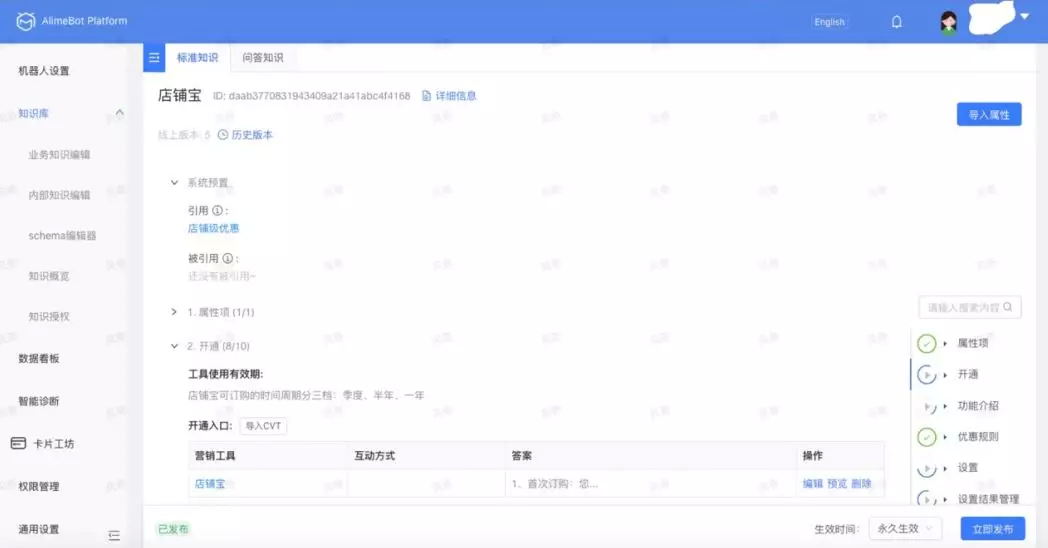
下图是结构化知识表示的一个示例。其中,“营销工具” 是一个类型,店铺宝是一个实例,一种具体的营销工具。“定义”,“预热”,“收费标准”,“优惠规则” 是属性。其中,“预热” 的属性值是一个 KV 结构 ( 可以支持更为精细的定位 ),收费标准的属性值是一个 CVT ( 不同的 BU 不同的商家类型收费标准不一样 ),“优惠叠加规则” 和 “优惠限购规则” 是 “优惠规则” 的子属性。
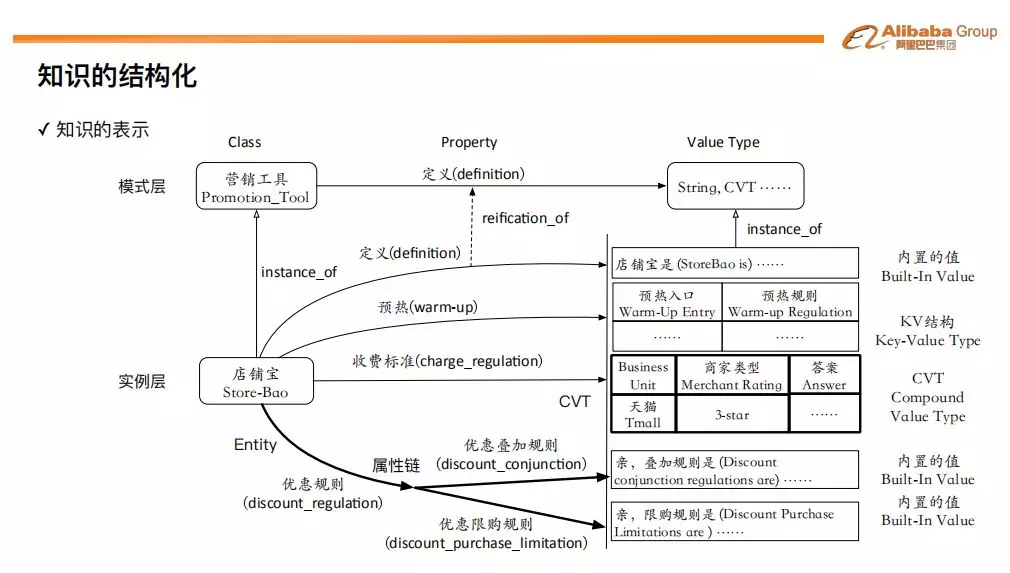
知识的结构化实践

在实际的落地过程中,我们从 QA 知识和语料出发来进行具体的知识结构化。整体步骤是先进行基于短语的领域词挖掘,然后基于挖掘的领域词进行概念/实体提取,进一步获得属性和关系,然后人工校验并且设计更为精细和复杂的 CVT 结构。下面分别对每一步骤进行详细介绍。
❶ 领域词(短语挖掘)
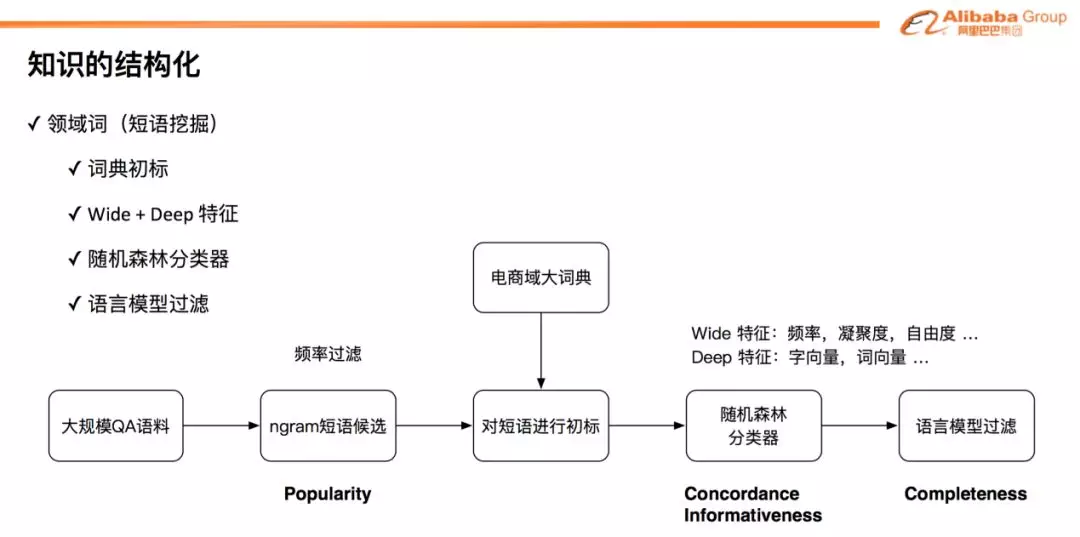
对于基于短语的领域词挖掘,我们先从语料库中自动产生大量的 n-gram 候选集 ( n 是一个正整数,例如 2~8 ),然后使用电商词典对候选集进行初标,得到一个训练样本集。以此为基础,我们采用随机森林,采样正负样本训练多棵树来构建分类器,以对候选短语的质量进行评分。分类器的特征包含两类:一类是 Wide 统计特征:频率、凝聚度、自由度等等;另一类是 Deep 语义特征:字向量、词向量、基于词向量的内部相似度等。最后,我们使用预训练的 BERT 领域语言模型对前述分类的候选短语进行修剪 ( pruning ) 得到领域词。
❷ 概念/实体提取 ( Chunking )
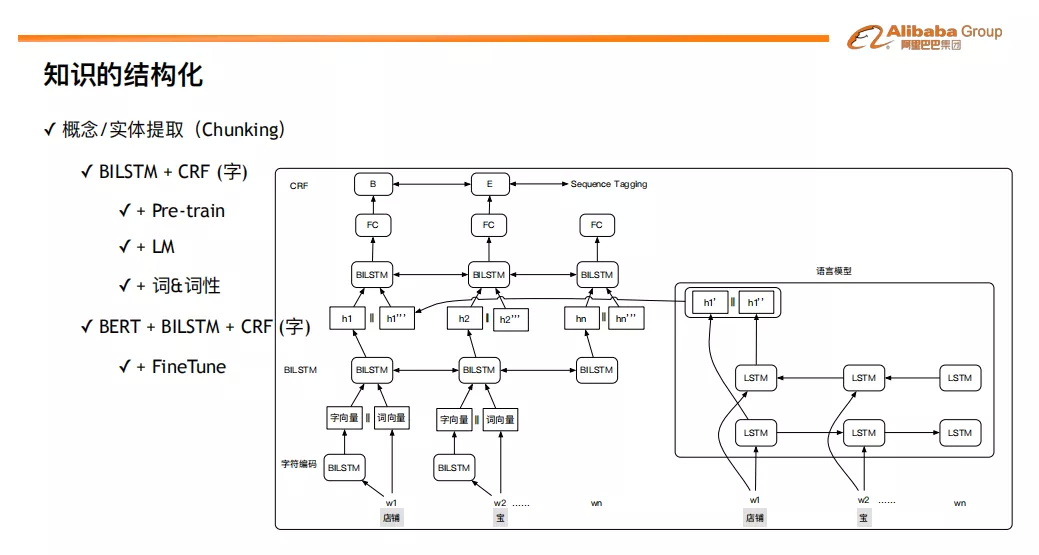
在概念/实体提取部分,我们在基于字的 BILSTM+CRF 框架基础之上,融入了词性、Pre-train 和语言模型知识。我们对嵌入层 ( Embedder ) 做了两点扩展:1. Embedder 的输入是已经分好词的句子,词的向量由两部分拼接组成,一部分是 Word2Vector 预训练好的词向量,另一部分是经过一个 BiLSTM 模型处理后的首尾字符拼接向量;2. 在第一层向量拼接之后,送入到第二层 BILSTM,然后其输出和我们预先训练好的 ELMO 领域语言模型的结果进行拼接。编码层 ( Encoder ) 采用一个 BILSTM 模型,并且我们用通用领域的语料进行了 Chunking 任务的预训练 ( Pre-training )。解码层 ( Decoder ) 采用 CRF。实验结果表明,词性、Pre-train,语言模型知识有助于效果的明显提升。在此基础上,我们进一步把嵌入层换成了基于领域预料微调的 BERT 模型,使用 BERT + BILSTM + CRF 的框架,效果得到了继续有效的提升。
❸ 关系抽取 ( 分类 )
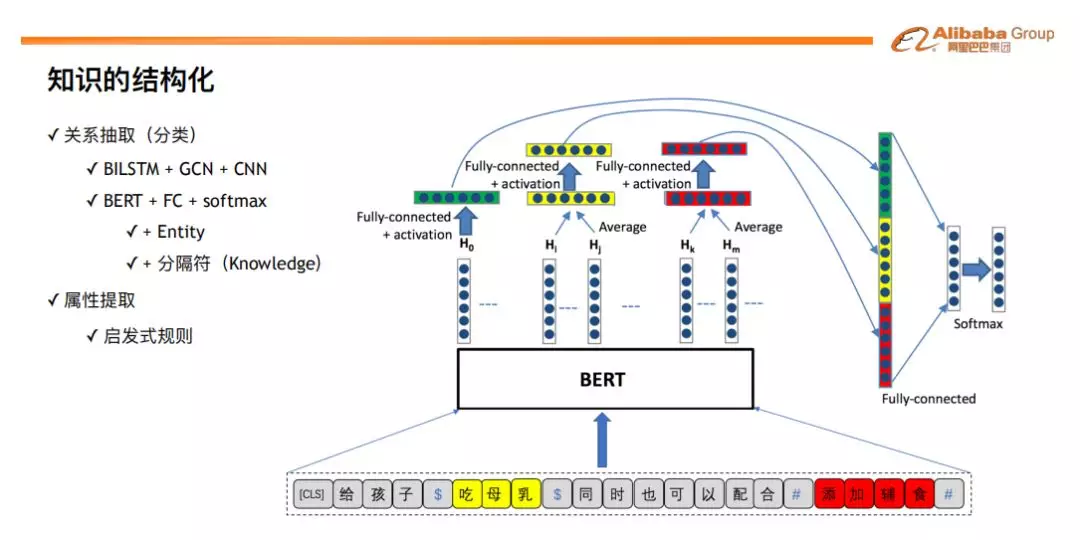
对于关系的抽取,我们尝试了图神经网络 GCN 和 BERT,BERT 的表现效果更好。在 BERT 的输入中,我们引入概念/实体信息 ( 图中的 “吃母乳” 和 “添加辅食”),对 BERT 的输出中实体对应的多个字向量进行 averaging 和 FC ( full-connection ) 操作;另外,我们尝在实体两侧加上分隔符 ( $ 和 # ) 来显示的告诉模型分隔符中间是概念/实体,可以进一步得到明显的提升。系列实验不仅证明了预训练语言模型的有效性,而且验证了引入实体知识可以有效的提升效果。
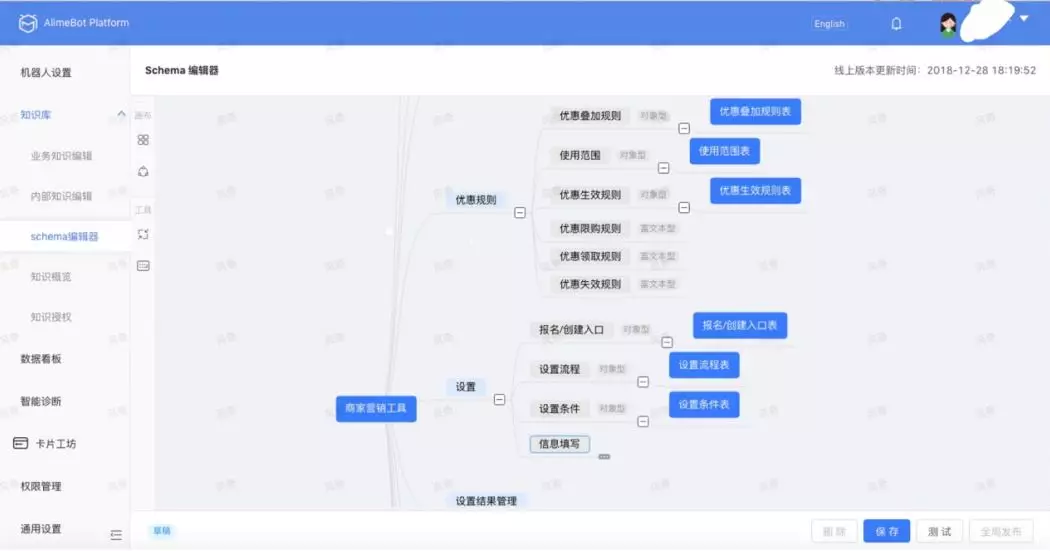
❹ Schema 编辑器
通过上述的短语挖掘、概念/实体提取、关系/属性提取,我们可以得到初步的知识结构。这个结构需要业务同学进行人工校验,同时对属性值的 CVT 结构进行设计和加工,最终形成我们的 Schema 结构,并且完成实体级别知识的录入。
❺ 实体编辑器
基于结构化知识的应用:KBQA
在知识结构化之后,我们选择采用 KBQA 来在实际场景中进行落地。具体地,我们选择了 KBQA 的多约束图排序方案:通过识别用户问题中的实体、属性、约束 ( CVT 子属性 ),将用户的问题转换成可能的多个候选图,然后对候选图进行排序,选择得分最高的图,根据情况进行推理改写,并最终查询 KG 返回相应的结果。在这个过程中,可能还需要进行推荐或者反问以应对语义不清或者问题不完整的情况。下图展示展示了 KBQA 的基本问答流程。
KBQA 问答流程
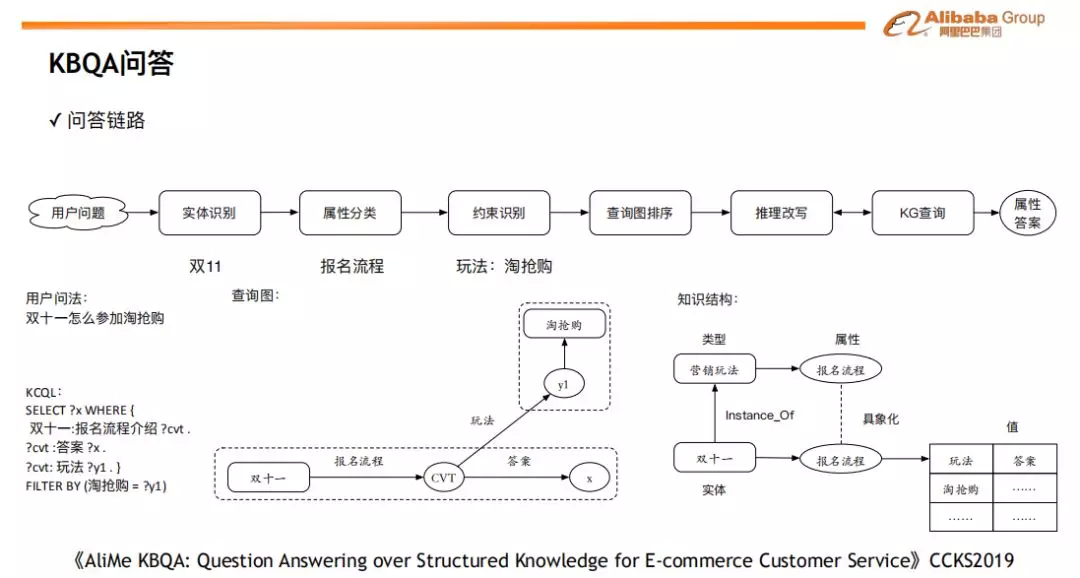
例如:用户问 “双十一怎么参加淘抢购” ( 淘抢购是双十一的一种玩法 ),这里面识别的主实体是 “双十一”,属性分类结果是 “报名流程”,约束识别是 “玩法:淘抢购”,最后根据这些片段组成的查询图,去 KG 中获取答案。
KBQA 定位
❶ 实体 &属性 &约束
对于 KBQA 的实体识别,我们采用了基于词典的规则方法和基于 CNN+CRF 的实体识别模型。对于属性识别,我们采用了基于 CNN+BiGRU+ Attention 等比较成熟的深度学习分类模型。对于约束识别,采用了关键词匹配和相似匹配的方法。
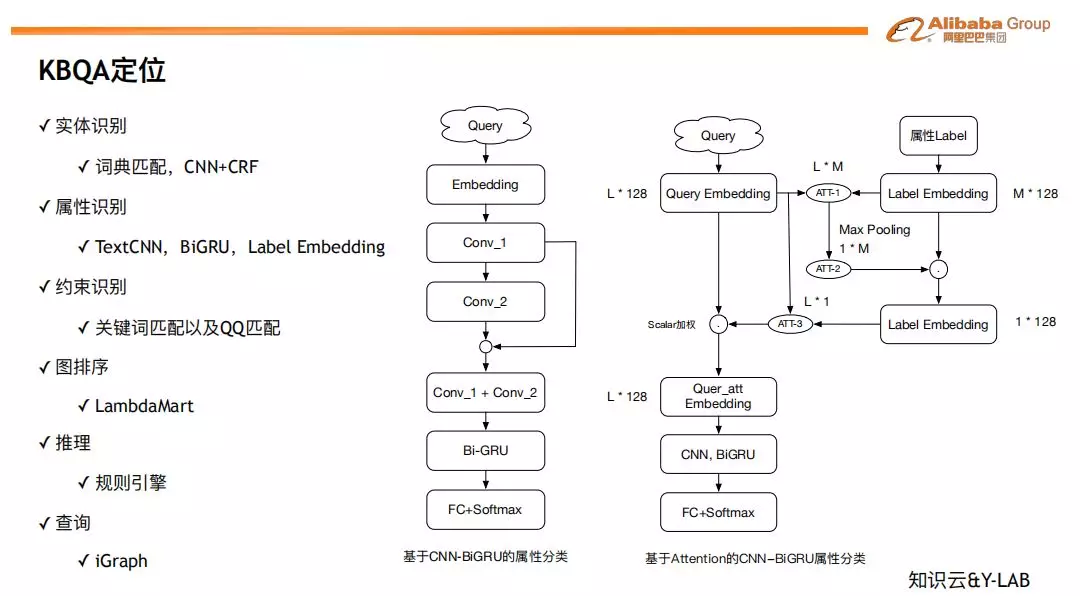
接下来我们着重对图排序、类型推理和推荐进行介绍:
❷ 图排序
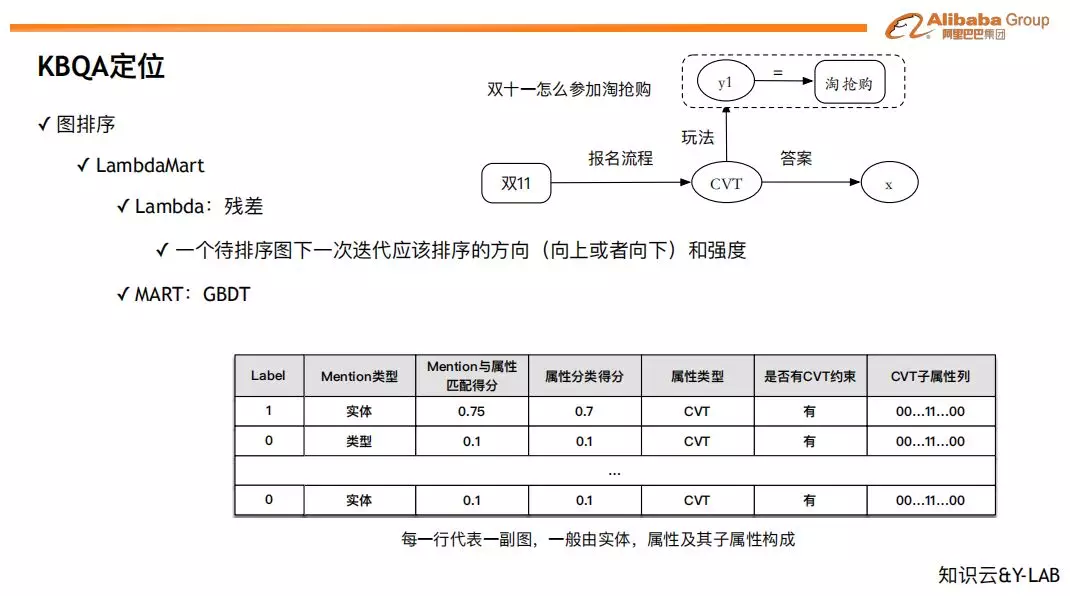
在识别出来实体、属性、约束的候选之后,我们会把相应的候选组合成一幅候选图。例如,上图右上角就对应了用户问题 “双十一怎么参加淘抢购” 的一个候选图。需要注意的是,因为实体、属性、约束都可能存在多个候选,所以这幅图仅仅是是多幅候选图中的一幅。
上图表格中的每一行都是对一幅候选图的特征刻画,Label 表示了当前图是否是对应的答案。我们采用 LambdaMart 进行排序,这里 Lambda 刻画了排序模型训练中每一幅候选图的梯度 ( 这幅图该向前排还向后排,以及朝这个方向移动多少 ),MART 就是我们熟悉的 GBDT,来学习这个梯度。
❸ 类型推理
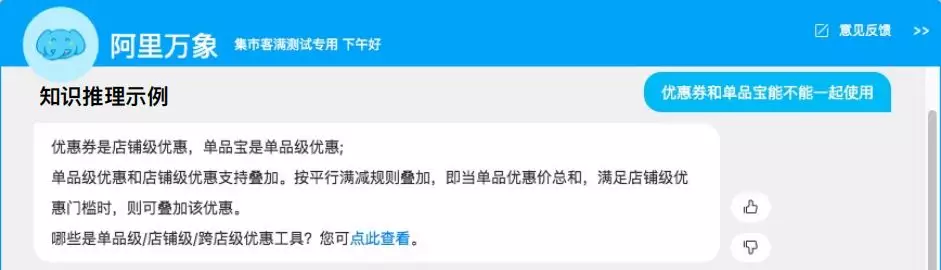
在实际场景中,我们常常遇到很多需要枚举的实体型知识。例如,“优惠券和单品宝能不能一起使用?”,这里面 “优惠券” 和 “单品宝” 是两个实体,其中 “优惠券” 是店铺级的优惠,“单品宝” 是单品级的优惠。因为无论是店铺级,还是单品级的优惠,可能都存在很多种,如果我们进行枚举的话,不仅数量很大而难以维护,也容易相互干扰造成定位错误。
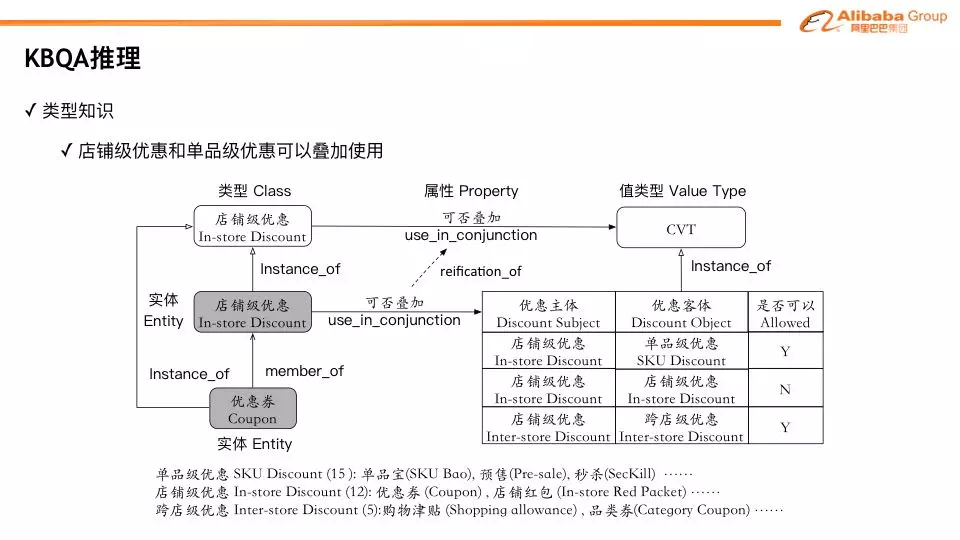
针对实体型知识,我们从实体级别抽象到类型级别,例如 “店铺级优惠和单品级优惠可以叠加使用”,进行相应的表示和推理来进行问答。上图展示了如何对类型级别的知识和实体级别的知识进行表示和关联。
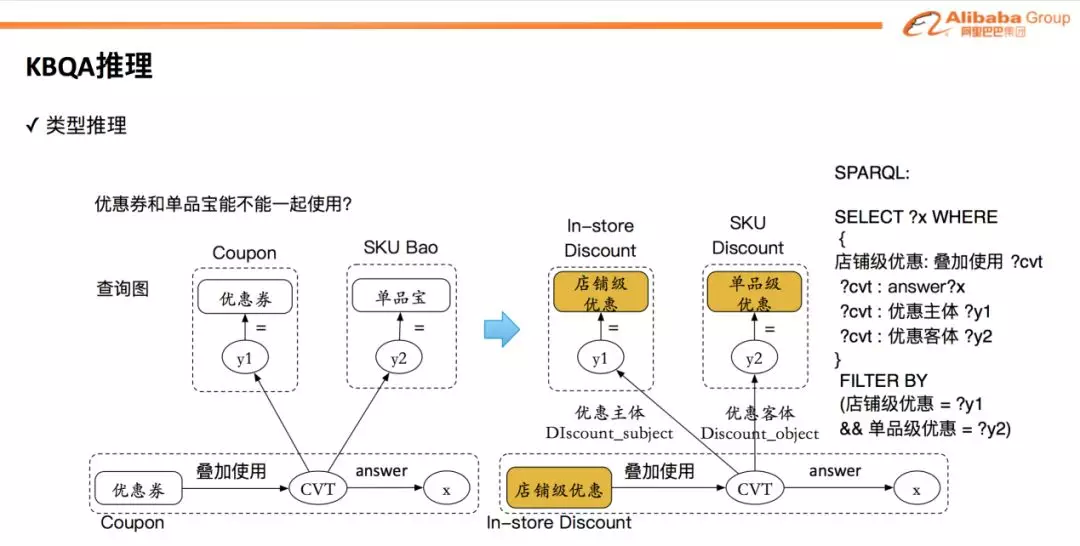
问答过程中,如上图所示,经过类型推理以后,问题 “优惠券和单品宝能不能一起使用?” 会被改写成 “店铺级优惠和单品级优惠能不能一起叠加使用”,并且最终通过查询 KG 返回对应的答案。
采用类型级别知识的表示和类型推理,一方面可以大幅降低需要维护的知识数量,同时可以有效的改善定位准确率,并且在答案中清晰的给出原因解释。
❹ KBQA 推荐
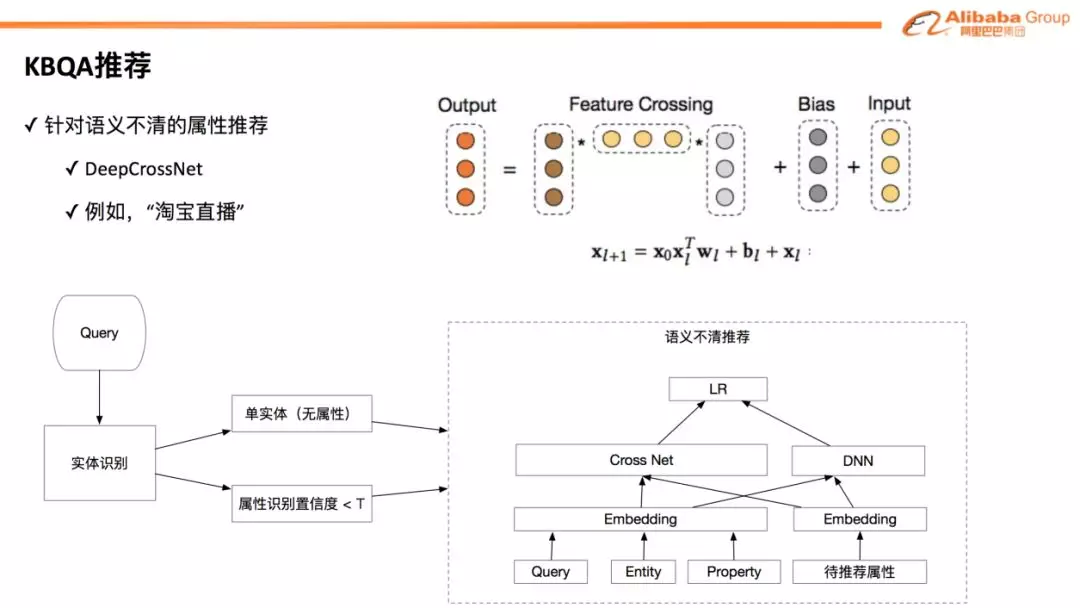
用户问题还有一个经常出现的情况就是 “语义不清”。例如,用户说了 “淘宝直播”,其实我们并不知道他具体想要问什么。这种情况下,一般做法是根据热点进行反问。在这里,我们做了进一步的扩展,采用了 DeepCrossNet 技术来进行推荐。我们对 Query 进行实体识别,然后基于热度、问题上下文、Schema 结构等信息对候选的属性进行排序推荐,有效的提升了推荐点击率。
KBQA 的 DEMO 示例
KBQA 目前已经在阿里小蜜的大促机器人、商家机器人 ( 万象 )、淘宝直播的直播小蜜机器人等场景实际落地,并且经受了双 11 的洗礼,取得了非常不错的效果。下列 Demo 对 KBQA 的问答效果进行了一个简单的展示。
基于类型推理的问答示例:
基于 KV 的问答示例:
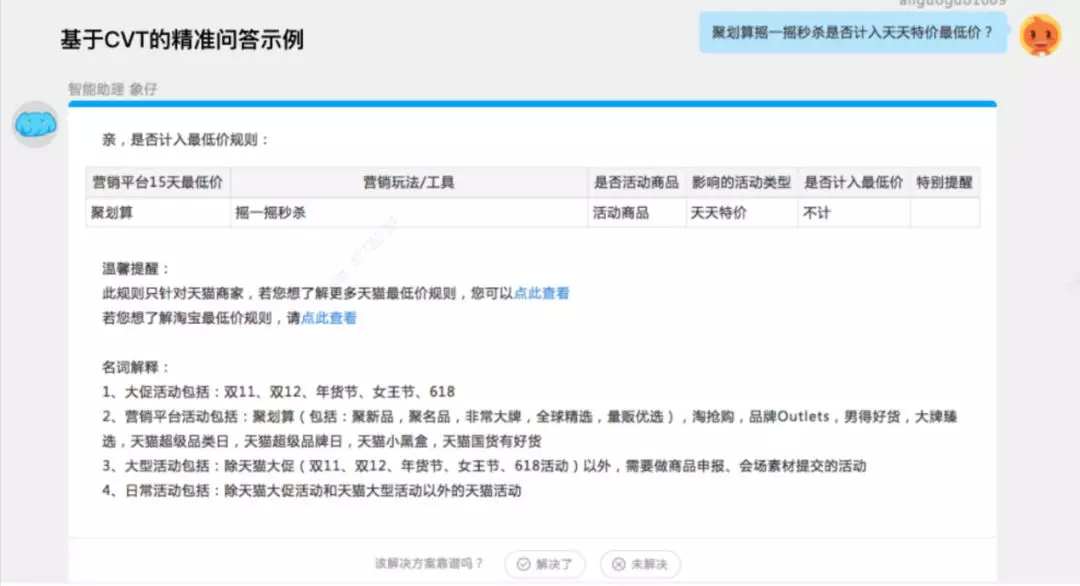
基于 CVT 的精准问答示例:
基于知识结构的推荐示例:
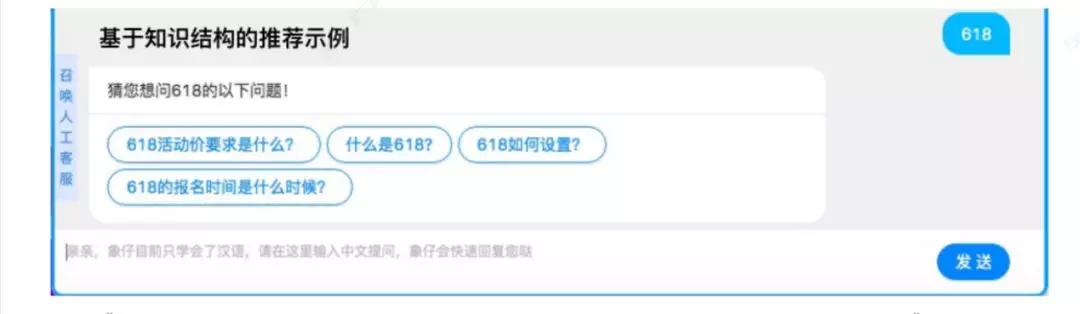
淘宝直播的问答示例:

基于结构化知识的应用:EBQA
KBQA 着重解决实体类知识问答。在我们的实际场景中,还经常存在事件类的知识问答场景 ( EBQA,Event-Based Question Answering )。事件问答场景,针对用户的 WHY、HOW、HOW NEXT、WHETHER 等类别的问题,不仅仅需要精确的给出答案 ( 能不能 ),通常还需要解释为什么 ( 为什么能或者为什么不能 )。这类问题,QA 体系也是很难有效支持的,除非把所有的情形及其组合进行枚举,但是这样做实际上是走不通的,必须通过对底层的知识结构进行改造。
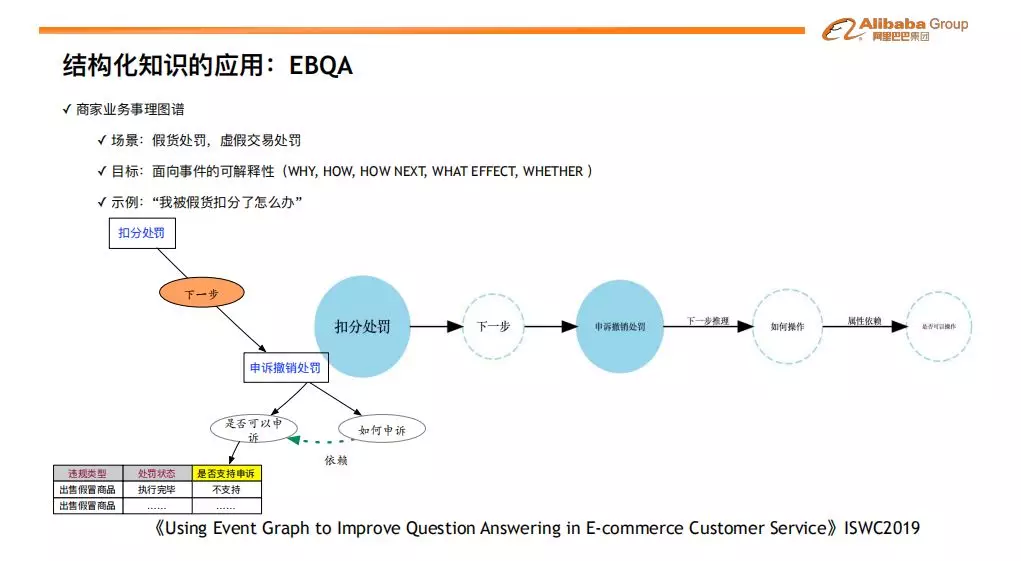
上图的左边展示了结构化以后的知识表示,右边部分展示了 EBQA 的定位和推理过程。针对用户的问题 “我被假货扣分了怎么办”,我们首先定位出目标事件 “扣分处罚” 以及相应的属性 “如何处理”。在我们的知识体系中,从 “扣分处理” 我们可以依据 “下一步” 关系推理到关联事件 “申诉撤销处罚”,然后根据 “如何处理” 关联到该事件对应的属性 “如何申诉”。因为 “如何申诉” 依赖于 “是否可以申诉”,我们需要进一步的推理,并最终根据 CVT 表格来获悉是否支持申诉,如果支持的话需要同时给出申诉入口 ( “如何申诉” 的属性值答案 ),如果不支持的话需要根据 CVT 结构给出对应的解释。
需要注意的是,EBQA 不仅支持针对已经发生事件的问答,还支持假设性的事件问答 ( “如果被假货扣分了,我应该怎么办?” )。
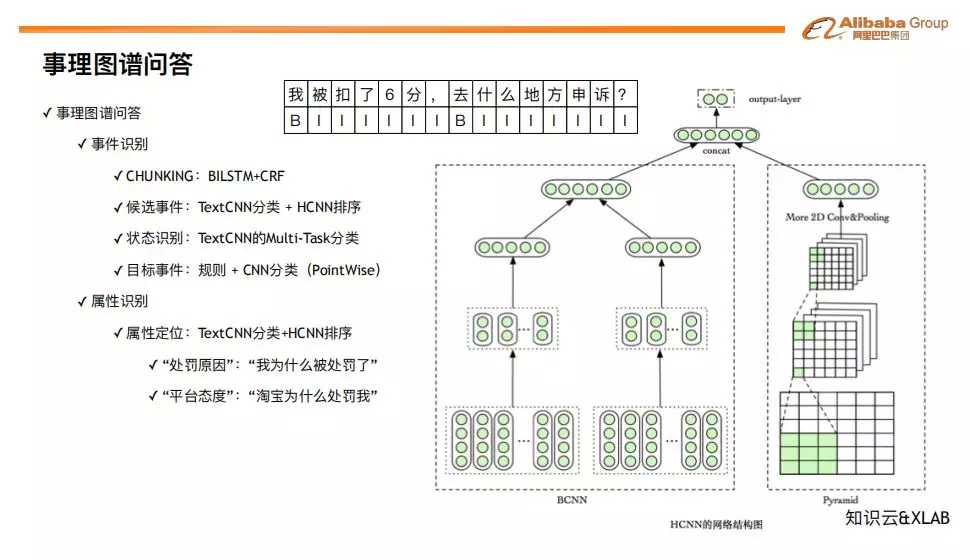
EBQA 和 KBQA 的问答流程链路大体相似,采用基于约束图排序的方案,但是在事件识别和属性/关系识别部分存在一些差异。
❶ 事件识别
事件识别时,我们首先采用 BILSTM+CRF 模型对句子断句,然后采用 TextCNN 分类+HCNN 排序的方法给出候选事件,最后根据规则和 CNN 分类来确定目标事件。需要注意的是,在给出候选事件的时候,我们同时也给出了候选事件的状态,是否已经发生,来协助 CVT 中条件的判断。
❷ 属性识别
对属性识别,我们也采用了 TextCNN 分类+HCNN 排序的方案。EBQA 中的事件识别和属性识别之所以采用分类+排序的叠加方式,是因为事件相关的问题表述非常 subtle。例如,“我该怎么处理” 和 “我该怎么办”,前者对应 “如何处理” 这个属性,而后者对应 “下一步” 这个关系。
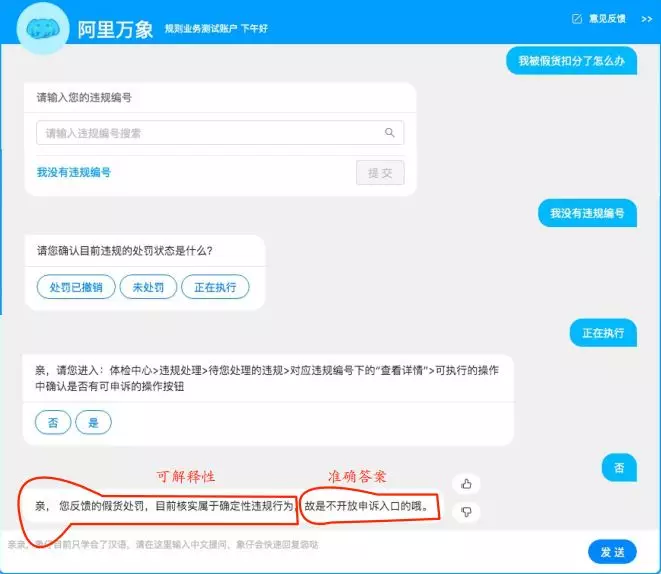
EBQA 的问答示例:
总结和展望
知识结构化的思考
经过在实际业务场景中的探索和实践,我们对知识的结构化及其应用有了比较深入的思考和认知。一方面,知识结构化有不少可观的优点,可以准确回答、支持推理、可解释、可复用等等;与此同时,她也存在其局限性,主要的一点是 Schema 的构建需要业务专家参与而难以规模化。
❶ 适合场景
适合实体或者事件比较多的场景
需要精细化回答的场景
需要推理、解释的场景
❷ 优点
模式层知识结构稳定,知识可以传承和培训
支持精细化问答,推理,可解释,支持针对语义不清的推荐,可以更好的解决用户问题
支持多样化的展示方式,更好的用户体验
训练语料可高度复用,新增实体不需要重新训练,可以快速上线
❸ 局限
Schema 成本:模式层构建成本较高 ( CVT ),规模化有较大挑战
附加成本:熟悉的门槛较高,配套的工具体系需要完善
展望和挑战
接下来,我们一方面致力于打磨算法和工具来降低业务知识图谱 Schema 的构建成本,另一方面会着眼于领域性常识知识图谱的构建,以商品和服务为核心,融合不同领域的常识性知识,以让小蜜能更好的理解和服务用户。这其中,低资源的挖掘,多模态的融合 ( 文本,图片,视频 ),知识的有效表示和融入等问题是我们需要着力解决的重要技术挑战。
作者介绍:
李凤麟 (风奇)
阿里巴巴 | 算法专家
本文来自 DataFunTalk
原文链接:

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论