
自 2003 年创立至今,LinkedIn 全球用户数已经从第一周的 2700 增长到了现在的 3 个多亿。它每天每秒都要提供成千上万的网页请求,而且移动账户已经占据了全球50% 的流量。所有这些请求都是从他们的后台系统获取数据,而这个后台系统每秒需要处理数以百万计的查询。近日,LinkedIn 高级工程经理 Josh Clemm 撰文介绍了LinkedIn 架构10 多年来的演进。
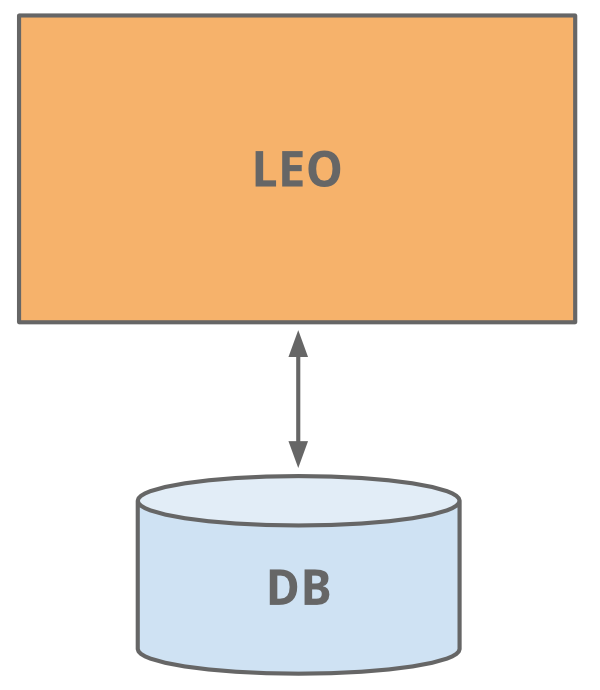
Leo
最开始的时候,LinkedIn 是一个他们称之为“Leo”的单体应用。该应用托管着所有各种页面的 Web Servlet,处理业务逻辑,并连接到少量的 LinkedIn 数据库。
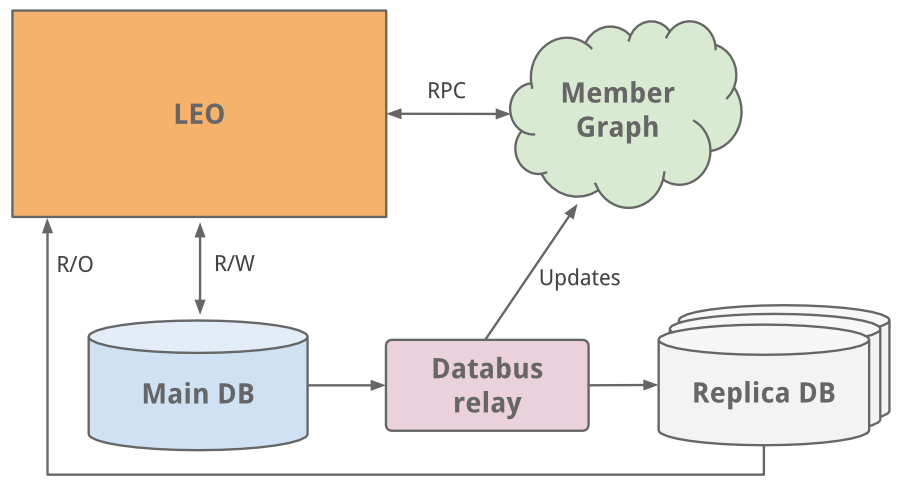
“会员图(Member Graph)”
作为一个社交网络,他们做的第一件事是管理会员之间的连接关系。他们需要一个系统,使用图遍历的方式查询连接数据,并且要常驻内存,以保证效率和性能。同时,它还需要能够独立于 Leo 进行扩展。因此,他们为实现会员图创建了一个单独的系统 Cloud。LinkedIn 的第一个服务就此诞生。为了实现图服务与 Leo 的分离,他们使用了 Java RPC 通信。大约正是这个时候,他们产生了搜索功能需求。他们的会员图服务开始向一个新的运行 Lucene 的搜索服务提供数据。
只读副本数据库
随着网站的发展,Leo 的功能越来越多,复杂性也越来越高。负载均衡可以帮助启动多个 Leo 实例。但新增的负载使 LinkedIn 最关键的系统不堪负重——会员资料数据库。
这个问题可以通过简单地增加 CPU 和内存来解决。他们这么做了,但还是不够。资料数据库需要同时处理读写流量,所以为了扩展,他们引入了从属副本数据库。该库是会员数据库的一个副本,二者之间使用 databus (现已开源)的早期版本保持同步。副本数据库负责处理所有的读流量,而且他们构建了一个逻辑,用于确定什么时候从副本读取是安全的。
但随着流量越来越大,作为单体应用的Leo 经常宕掉,而且很难诊断和恢复,新代码也不容易发布。对LinkedIn 而言,高可用性非常关键。显然,他们需要需要将Leo 分解成许多小功能和无状态服务。
面向服务的架构
他们抽取微服务和业务逻辑,然后按领域抽取展示层。对于新产品,他们会在Leo 之外创建全新的服务。他们构建了前端服务器,用于从不同的域中获取数据、处理展示逻辑以及通过JSP 构建HTML。他们构建了中间层服务,提供访问数据模型和后端数据服务的API,实现对数据库的一致性访问。到2010 年,他们已经有超过150 个单独的服务。现在,他们有超过750 个服务。
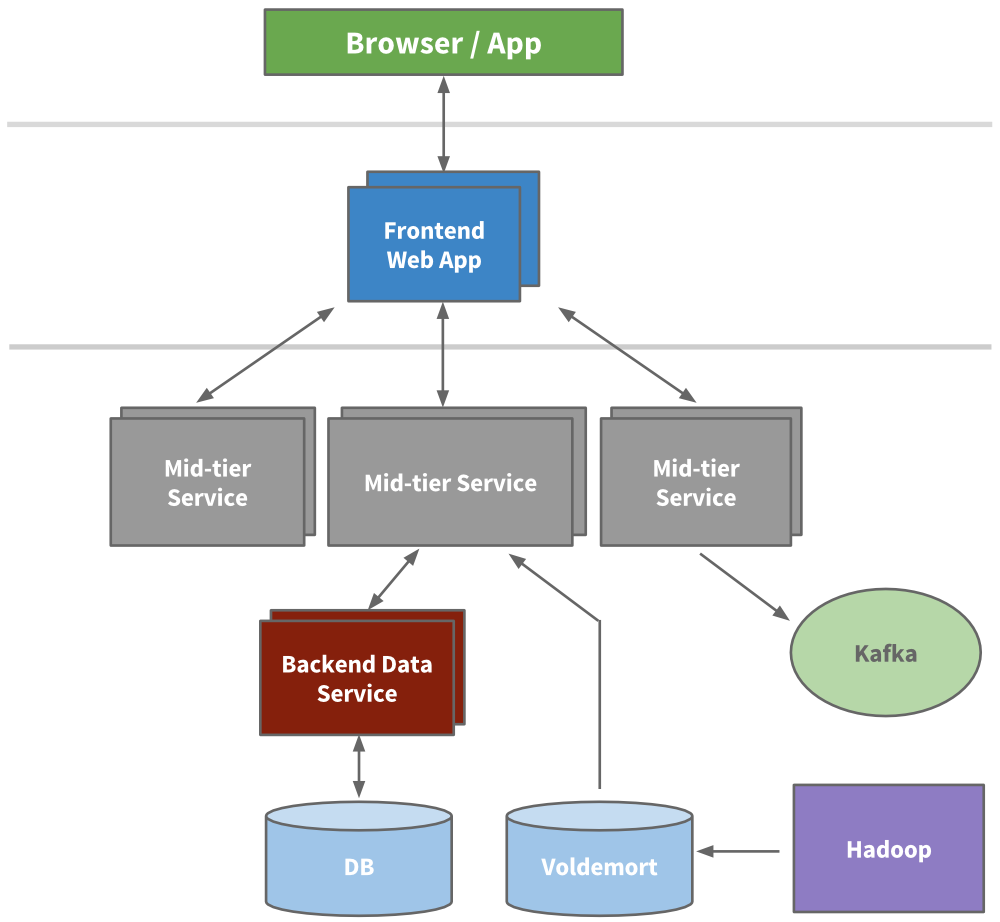
至此,他们已可以针对单个服务进行扩展。期间,他们还构建了早期的配置和性能监控功能。
缓存
由于发展迅猛,LinkedIn 需要进一步扩展。他们通过增加更多的缓存层来减少整体负载。比如,引入类似 memcache 或 couchbase 的中间层缓存,向数据层添加缓存,并在必要的时候使用 Voldemort 进行预计算。但实际上,随着时间推移,考虑到缓存失效增加了系统复杂性,而“调用图(call graph)”难以管理,他们又去掉了许多中间层缓存,而只保留了离数据存储最近的缓存,在保证低延迟和横向扩展能力的同时,降低了认知负荷。
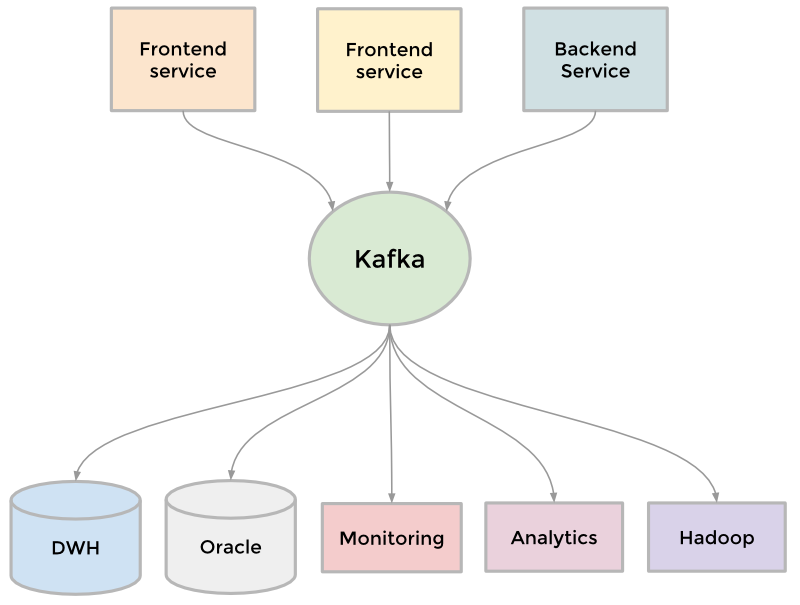
Kafka
为了收集日益增长的数据量,LinkedIn 开发了许多自定义的数据管道,用于对数据进行流式处理。例如,他们需要让数据流入数据仓库,需要将数据批量发送给 Hadoop 工作流用于分析,需要收集和汇总每个服务的日志信息,等等。随着网站的发展,这样的自定义管道越来越多。如果网站需要扩展,每个管道都需要扩展。因此,他们基于提交日志的概念开发了一个分布式的发布订阅消息平台 Kafka ,作为通用的数据管道。该平台支持对任何数据源的准实时访问,有效地支撑了 Hadoop 作业和实时分析,极大了提升了站点监控和预警功能,使他们可以可视化和跟踪调用图。现在,Kafka每天处理超过5000 亿事件。
Inversion
2011 年底,LinkedIn 启动一个名为 Inversion 的内部项目,暂停了所有的功能开发,整个工程组织全部致力于改进工具、部署基础设施和开发效率。
Rest.li
在从 Leo 转换到面向服务的架构的过程中,抽取出来的 API 采用了基于 Java 的 RPC 技术,不仅各团队不一致,而且与展示层紧耦合。为了解决这个问题,他们构建了一个新的 API 模型 Rest.li 。这是一种以数据模型为中心的架构,可以确保整个公司使用同一个无状态的Restful API 模型,而且非Java 客户端也可以轻松地使用。这一措施不仅实现了API 与展示层的解耦,而且解决了许多向后兼容的问题。此外,借助动态发现(D2),他们还针对每个服务API 实现了基于客户端的负载均衡、服务发现和扩展。现在,LinkedIn 有超过975 个Rest.li 资源和每天超过1000 亿次的Rest.li 调用。
(点击放大图像)

“超块(Super Blocks)
面向服务的架构可以解耦域及实现服务的独立扩展,但它也有缺点。他们的许多应用程序都需要获取许多类型的不同数据,发起数以百计的调用。所有的调用就构成了上文提到的“调用图”。该调用图非常难以管理,而且管理难度越来越大。为此,他们引入了“超块”的概念,为一组后端服务提供一个可以独立访问的API。这样,他们就可以有一个专门的团队对块进行优化,并控制每个客户端的调用图。
多数据中心
他们不仅要避免单个服务成为单点故障点,而且要避免整个站点成为单点故障点,因此多数据中心非常重要。现在LinkedIn 主要通过三个数据中心提供服务,并在全球范围内提供 PoPs 服务。
正如 Clemm 所言,他们的故事远不止这么简单。许多关键系统的背后都有一段丰富的历史,比如,会员图服务、搜索、通信平台、客户端模板等,感兴趣的读者可以进一步阅读。
查看原文: A Brief History of Scaling LinkedIn
感谢郭蕾对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ , @丁晓昀),微信(微信号: InfoQChina )关注我们,并与我们的编辑和其他读者朋友交流(欢迎加入 InfoQ 读者交流群 )。
)。
活动推荐:
2023年9月3-5日,「QCon全球软件开发大会·北京站」 将在北京•富力万丽酒店举办。此次大会以「启航·AIGC软件工程变革」为主题,策划了大前端融合提效、大模型应用落地、面向 AI 的存储、AIGC 浪潮下的研发效能提升、LLMOps、异构算力、微服务架构治理、业务安全技术、构建未来软件的编程语言、FinOps 等近30个精彩专题。咨询购票可联系票务经理 18514549229(微信同手机号)。

暂无签名

腾讯大规模云原生技术实践案例集
本案例集详细阐释了 QQ、腾讯会议、和平精英、小红书、斗鱼、微盟等十多个亿级用户产品背后的大规模云原生...













评论