
FreeWheel 是一家负责高端视频广告的投放的公司,主要业务是整合美国的传统电视和数字电视。作为 FreeWheel 的重要客户之一,Charter 是仅次于 Comcast 的美国第二大有线电视运营商。
准确地预测在 Charter 的流量内各个电视频道在未来某一小时内可能给出的广告曝光(impression)是我们的主要目标,我们可以通过获取用户的观看行为达到更精准的广告投放。
通过将预测数据在时间、地区、频道、站点分类等各个维度上进行聚合,不仅用以给广告主提供售前售卖参考,还可以在售中为广告投放提供决策支持。
本文介绍了我们在数据上的发现和基于数据与业务对模型做出的改进,通过构建深度学习模型以达到精准预测的目的。
“异常”数据对模型训练带来的挑战
时序预测的主要思路是通过历史数据和预测数据的相关性,从中学习到行为 pattern 从而做出预测。对于模型来说,越稳定、规律性越强的时序序列预测得越准确。
而突变的“异常”时序序列由于出现频率低、规律性弱则难以被准确地预测。因此时序序列中“异常”序列的预测是我们的一大挑战。
在 Charter 所包含的流量内,我们随机挑选了一个站点,观察它在今年 4~6 月份的流量数据。横坐标是每天的日期,纵坐标是当天该站点的流量。
从图上可以看到在一定周期内,流量的走势有着不小的相似性。在这种流量稳定的情况下,模型通过对近期历史数据的学习,可以充分学习到流量的 pattern,对未来一段时间内的观看行为做出较为精确的预测。
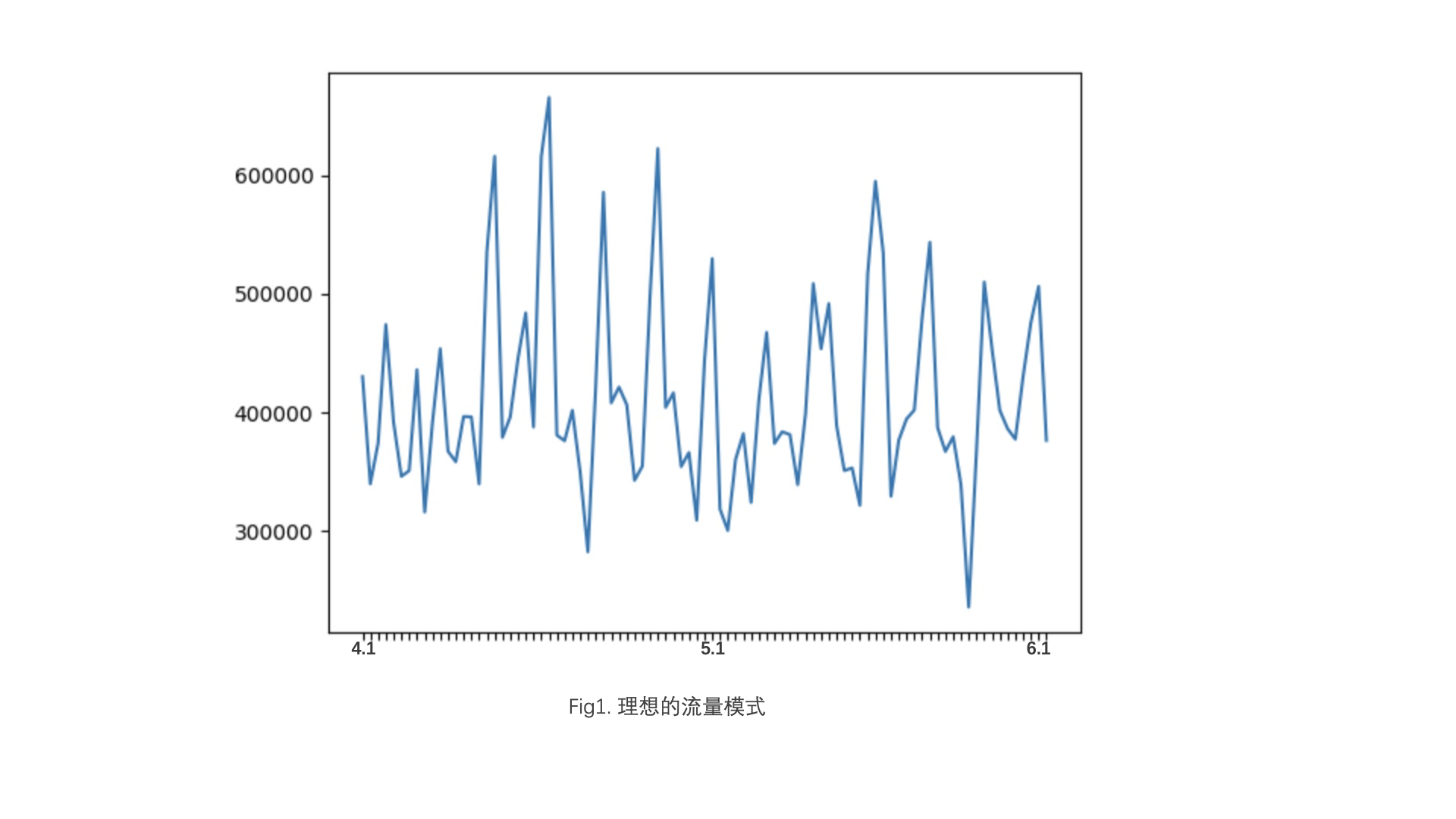
但是如果存在突发的事件导致用户的观看行为发生改变(例如大型的节假日,人们选择出游或宅在家中看电视,都会使得节假日期间的观看行为与日常不同),那么模型仅仅通过近期的历史数据是不能对此做出反应的,这在模型看来就是一些“异常”的行为。
如图我们选取的相同站点内 12 月到次年 2 月的流量数据,对比于 4-6 月份用户的观看行为,可以看到在圣诞至年初这段时间流量的 pattern 发生了变化,新年附近的曲线其他时期会更加。
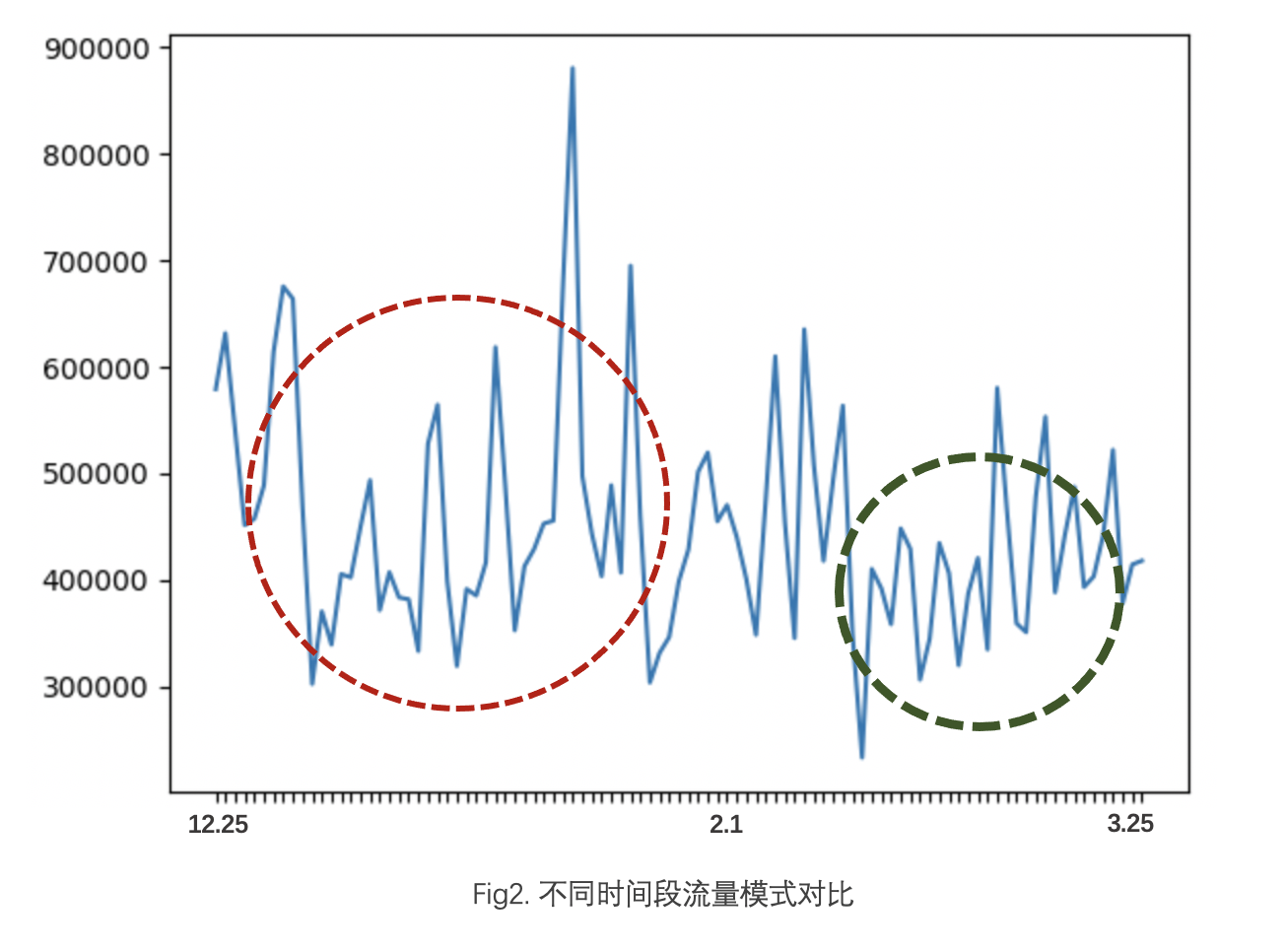
更细粒度地去观察节假日与非节假日流量每天的变化情况,下图中横坐标表示每天的 0 点到 23 点,纵坐标表示当前小时流量的情况。可以看到非节假日期间(左图)每天的流量曲线走势相似,在新年期间(右图)产生的流量更为离散。
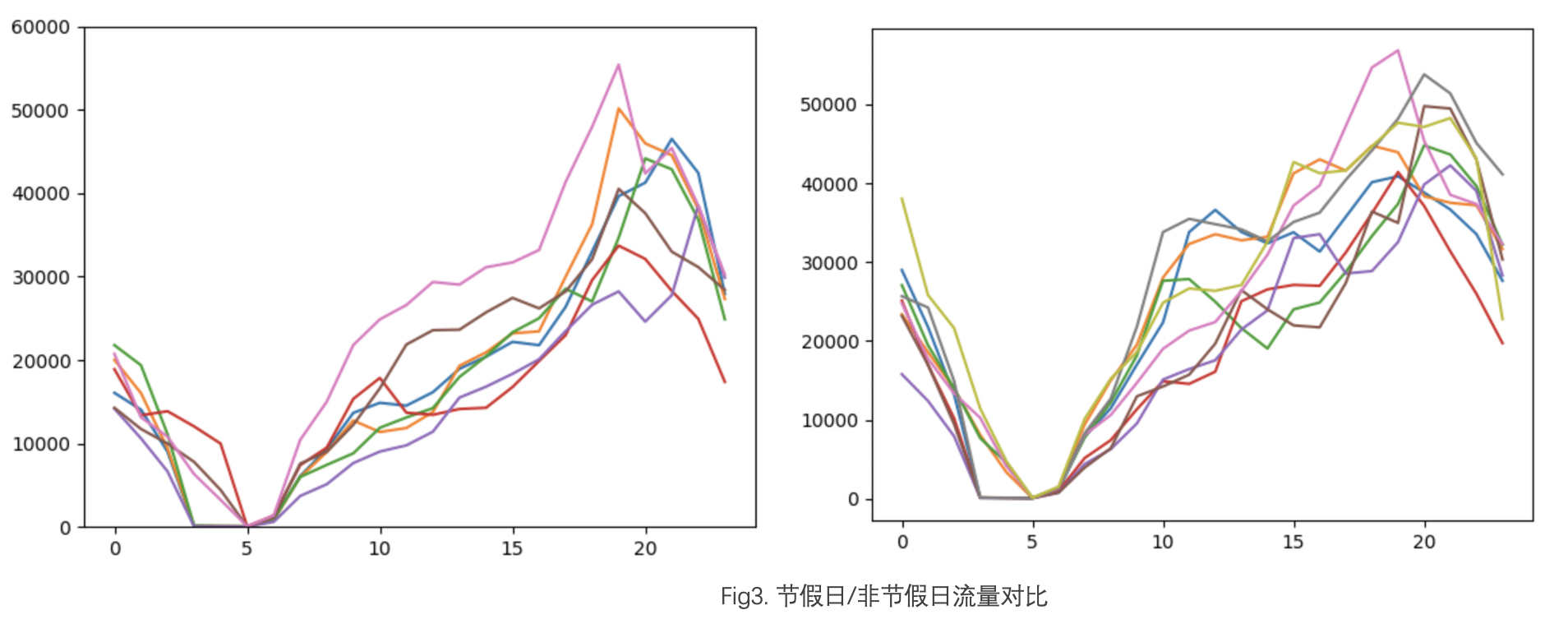
这是因为用户相较于往常会有更多的休闲时间来观看电视,导致观看行为出现了改变,由其产生的流量曲线间的相似度也随之降低。
因此如何处理时序预测中存在的“异常”行为,提高模型对于节假日等等具有周期特点事件的感知能力,是我们需要关注的一个问题。
针对“异常”数据的模型优化
同比数据的注入
在时序预测中,通常的做法是选取距离预测日期较近的环比数据,因为距离越近,自然与预测结果的相关性越高。但是考虑节日和一些大事件带来的异常,我们在考虑环比数据的同时,也可以对去年同期(同比)数据进行学习。
这样模型在做预测是时候不仅能够学习到用户近期的观看模式,还能通过参考同比数据,判断未来是否会存在一些”异常“ 的观看模式。
在时序预测任务中,主要以下两种类型的机器学习模型:以 ARIMA 为代表的传统时序预测模型和基于 RNN 的深度学习模型。
随着预测任务的维度越来越高,传统的时序预测模型很难达到业务所需的精度,因此深度学习模型在现在的时序预测场景中是更为常见的选择。
网络结构图如图所示,我们以 Cross&Deep 为模型原型,针对业务需求和数据的特点对模型做出相应的改动,将经典的双塔结构更改为三塔结构,并对模型细节作出了相应的优化。
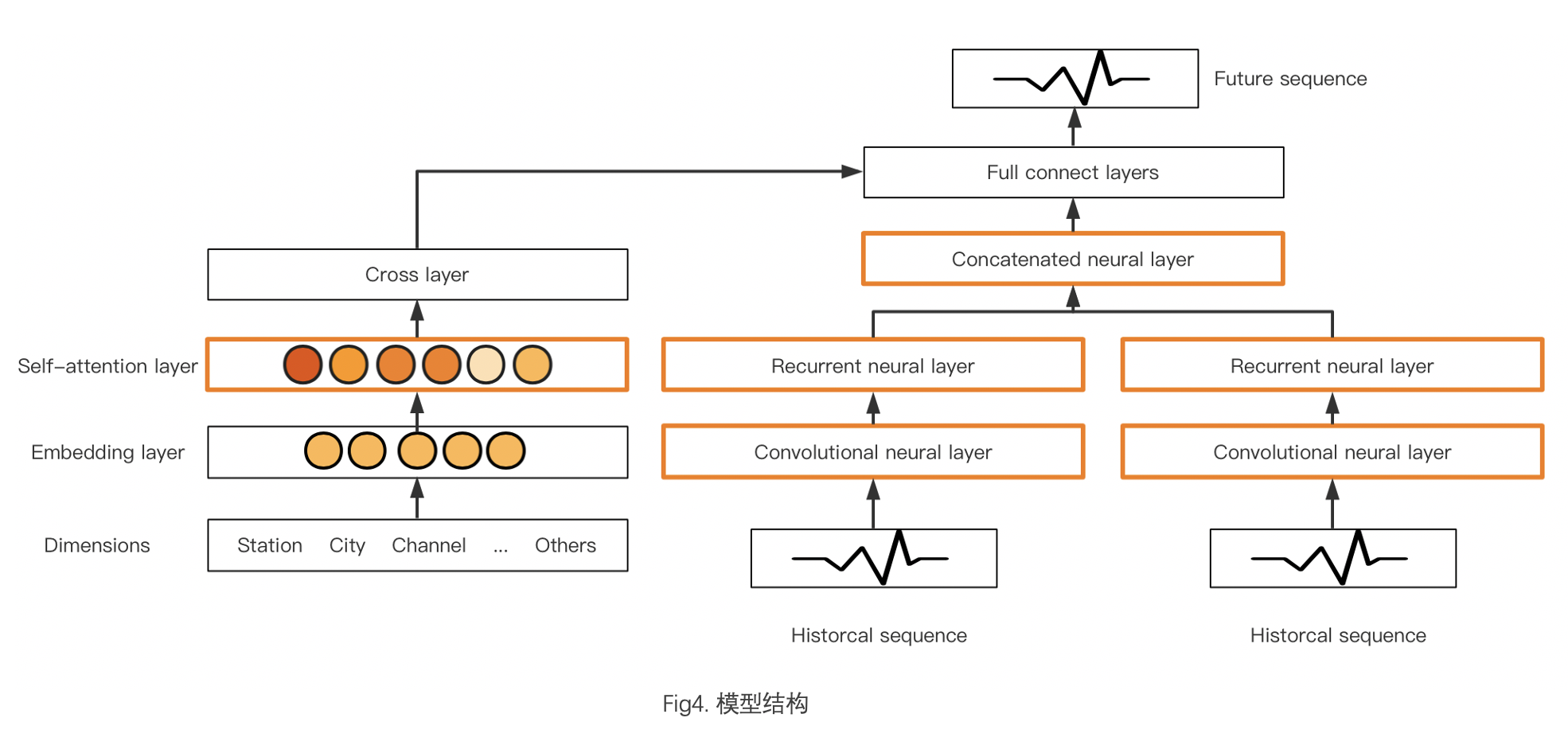
注意力机制的引入
在 Cross&Deep 模型中,Cross network 是用来处理离散型特征,如用户 id、频道 id 等等。Cross network 会先对离散类信息做向量化,再通过交叉层完成特征组合,以此加大特征之间的交互力度。
然而,在实验中我们发现,由于用户 id 信息过于庞大,在和频道、地区等信息做叉乘之后,过高的数据空间维度会在一定程度上影响模型的拟合效果。
在梯度传播的时候,离散型特征的参数往往不能达到有效的梯度下降,模型很难达到最优解的搜索。如果降低数据空间的维度,又很容易导致模型对于离散类特征的编码不足。
因此虽然 cross layer 做了高维的特征交叉,模型依然难以达到有效的特征提取。基于该问题,我们在做特征交叉之前,引入了自注意力机制来提高模型对特征空间有效数据的关注度。
它是一个全局信息重要性的捕捉器,随着 Transformer 问世,它更广泛地被用来代替 RNN,使用在一些对于顺序信息不太敏感的场景。离散类特征的抽取相较于时序信息的捕捉,对于位置信息是弱依赖,自注意力机制在这个场景下具有天然的优势。
自注意力机制的计算主要有两个阶段:一是计算 query 和 key 的相似性,二是通过对输入计算 query 和 key 之间的权重,得到输入信息的重要性分布。
因此在特征交叉之前引入自注意力机制,可以有效地捕捉特征类信息内部间的相关性,筛选出更重要、更相关的信息参与特征交互,提高特征交叉时数据空间的有效浓度。这样既能充分对离散类特征进行编码,又能降低数据空间在最优解搜索上的复杂度。
时序信息的抽取
在 Deep network 中,我们将同比和环比的数据分别用两个 Deep network 去训练。然而 DNN 并不能很好地捕捉时序数据中的时序信息,在 hour-wise 的预测粒度下结果并不准确,因此我们在 DNN 中加入了 CNN 和 RNN 增强 DNN 模块对时序信息的捕捉。
这里我们将输入的时序按照一定的周期做了折叠。第一是因为我们的预测粒度细,并且周期较长,将所有的时序数据放在一个维度下,对后续 RNN 在时间步的计算上会增加计算的负担,也随之会带来信息丢失的风险。
第二是在普遍情况下,我们的数据在短周期内,观看行为具有一定的相似性。因此根据预测的粒度,我们在周的粒度上对输入的历史数据做折叠,对于 CNN 来说,每周的观看行为就是一个通道。这样对于卷积网络可以很方便地在短周期内做浅层信息的抽取,甚至可以隐式地完成一些统计信息的计算。
RNN 的加入则是为了加强对序列信息的刻画。由于时间步较长,为了缓解梯度消失,我们尝试使用 LSTM/Transformer 代替 RNN,但是在实验中,我们发现 LSTM 的增益并不如预期,并且选用 LSTM 大大增加了模型的训练时长。
而 Transformer 在时序问题中的表现并不理想,第一是时序问题对于位置关系的强依赖,而 Transformer 仅对位置信息做了简单的加和,Transformer 中的注意力机制对于序列位置的捕捉能力并不好。第二是 Transformer 很大程度上提高了模型的复杂度,对模型的计算和收敛都着不小的影响。
因此我们对数据进行了进一步的分析。用户的观看模式存在一定的稳定性,虽然每天的观看模式不完全相同,但是观看的行为都会集中在当天的某个时段。基于这个分析,我们对时序序列的信息抽取方式作出了调整。
对于时序的序列,当我们将短周期的粒度从周缩短到天,历史数据按照天的周期粒度进行折叠,卷积通过在当天的观看序列上进行滑动,来找观看的集中时段,这样能够大大降低时间步长,节省模型计算的时间,使用朴素的 RNN 就能完成序列信息的刻画。
在同比数据和环比数据的融合上,我们选用了拼接向量的方式,而不是采用加和完成特征的融合。在正常的流量下,不同周期内用户的观看模式分布可能是相似的,但是如果存在异常流量,观看模式会发生抖动,从而产生数据分布的偏差,这个时候直接将不同分布的数据进行加和是不太得当的。
同时,在融合的向量后接上一个全连接层,可以作为一个简单的注意力机制,去有侧重的选择同比或环比的数据。
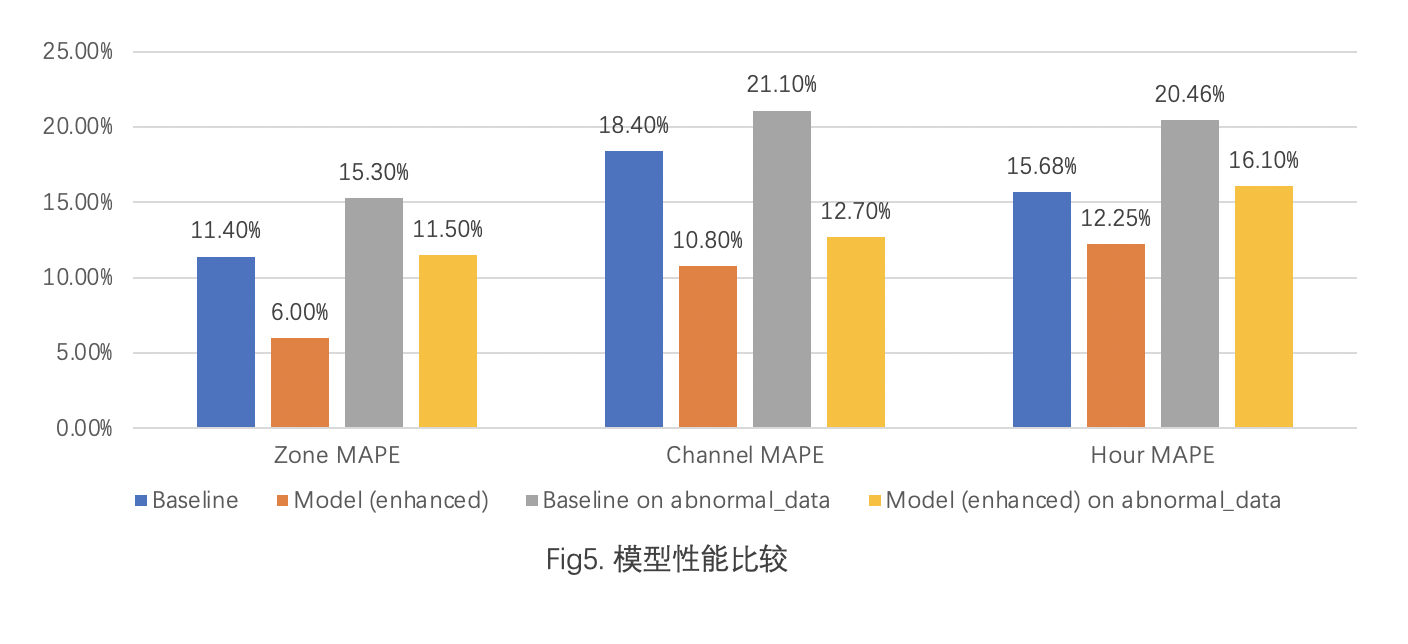
模型的评估指标上,我们选用 MAPE(mean absolute percentage error)作为衡量模型性能的指标,在 Zone、Channel 和 Hour 这三个不同粒度上做对比,可以看到优化后模型的效果对比于线上使用的模型,在日常预测和节假日异常数据的预测上,均有一定的指标提升。由此可见加入同比的数据,模型能够增强对一些“异常”数据的识别能力。
总结
本文阐述了我们在收视率预测的优化探索,通过对数据的周期性分析,尝试在模型中加入同比数据来提高模型对于长周期变化的感知,并根据数据的特性对模型细节做出相应的修改。
模型的优化没有止境,线上的模型可能随着数据的变化逐渐腐坏,没有一个模型能一直完美地满足业务的需求。因此我们需要时刻要求自己保持对数据的敏感和对业务的理解,才能更好地应对线上数据和业务需求的变化。
作者介绍:
黄夏钰,FreeWheel 机器学习团队工程师,从事计算广告业务中机器学习的算法调研与模型开发工作,并且热爱大数据处理分析技术。通过算法与工程的结合,让机器学习在计算广告领域有更多的落地。




