
1. 网络抖动背景
延时高,网络卡,卡住了美好!应用抖,业务惊,惊扰了谁的心?当你在观看世界杯梅西主罚点球突然视频中断了几秒钟;当你在游戏中奋力厮杀突然手机在转圈圈无法响应;当你守候多时为了抢一张化妆品优惠券突然迟迟加载不出来……
我们经常在观看视频、手机游戏、网上购物时,会遇到上面这些烦心事,作为用户,我们总有被卡在“临门一脚”的感觉,此时的你,是否有种想把手机或电视砸掉的冲动?或者破口大骂网络服务商的线路不稳定?是的,这种现象一般是网络抖动引起的。
“高频率、难攻克”一直是业界对抖动问题的评价,特别是在我们云计算场景下,复杂的网络拓扑,众多的业务承载形态,容器、虚拟机和传统的物理机并存,业务的应用也出现了微服务众多、多语言开发、多通信协议的鲜明特征,这给我们定位这类问题带来非常大的挑战。
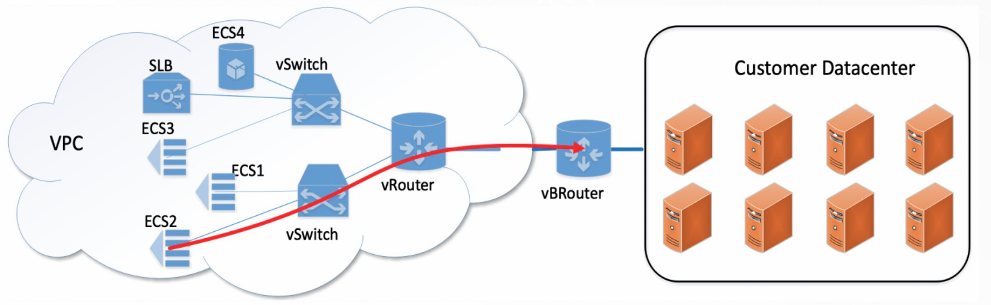
试想从我们的手机或者 PC 浏览器发出的一个付款请求,可能要经过你的家庭路由器,运营商网络,云服务商物理网络、虚拟网络,以及电商服务器,容器或者虚拟机,最后才是具体的服务程序对请求进行处理,这里面每个节点都可能存在延迟。
购物、游戏、视频、金融等领域,受限于传统的 IDC 物理网络的环境因素,多样化的云网络场景,以及业务系统的复杂性,所有涉及到网络请求和处理的地方,都会存在业务网络抖动的情况。
在云服务商内部,业务所在的 ECS 服务器,日志的存储和上传、数据库访问,可能分散在不同的节点,节点之间也有各种网关和内部网络。当出现抖动时,每个功能模块都只能维护自己的节点诊断信息,无法通过统一平台呈现具体时延信息,相互之间的自证清白的能力比较弱。
到具体业务和应用处理上,由于操作系统上面跑着各种任务,相互之间的调度和处理都会有干扰,内存分配、报文解析、IO 访问延迟等等,都给我们分析抖动问题带来困难。
2. 网络抖动的定义
2.1 网络抖动的定义和现象
前面我们一直在提延迟,提抖动,以及抖动如何难分析。现在我们回到一个最初的问题,什么是网络延迟?什么是网络抖动?云计算场景中抖动都有哪些具体的现象?
网络延迟是指报文在网络中传输所用的时间,即从报文开始进入网络到它开始离开网络所经历的时间。各式各样的数据在网络介质中通过网络协议(如 TCP/IP)进行传输,如果信息量过大不加以限制,超额的网络流量就会导致设备反应缓慢,从而造成网络延迟。
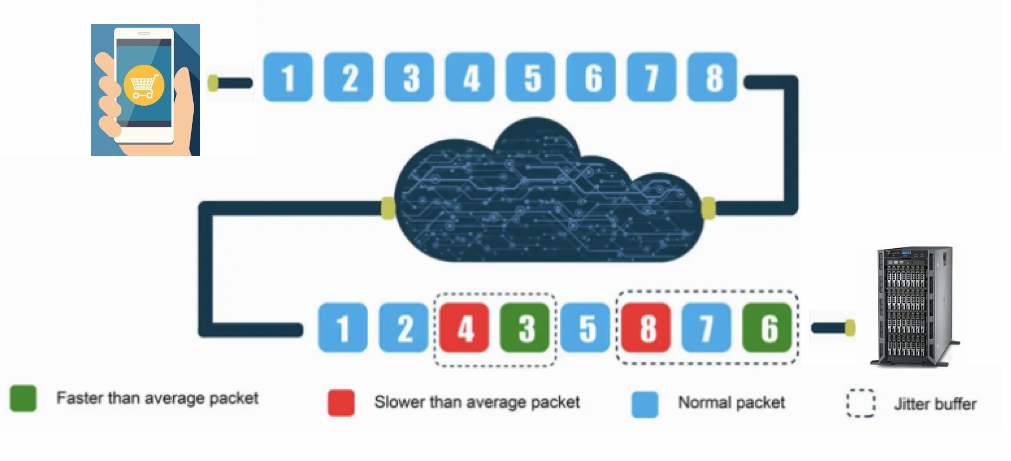
而抖动是 Qos 里面常用的一个概念,当报文经过交换机、路由器等设备时,容易出现网络拥塞,通常报文会进行排队,这个排队延迟将影响端到端的延迟,并导致通过同一个连接进行传输的报文经历的延迟各不相同,所以抖动,就是用来描述这样一延迟变化的程度。网络抖动值越小说明网络质量越稳定。举例说明,假设 A 网络最大延迟是 15 毫秒,最小延迟为 5 毫秒,那么网络抖动值是 10 毫秒。
总结起来,网络抖动是指在某一时刻业务的流量下跌、正常业务指标受损,网络出现延迟等。延时和抖动主要的后果是影响用户体验,特别是在游戏场景中更是来不得半点抖。试想当你在打怪买装备时抖了那么 20ms,装备没了,此时捶胸顿足砸键盘也于事无补啊。
另外,云场景下,用户不仅关心正常场景的平均延迟,对异常场景下的长尾延迟,也越来越关注。影响长尾延迟的因素,如宕机、网络延时、磁盘抖动、系统夯机等等。长尾延迟还存在着放大效应,比如系统 A 串行向系统 B 发送 5 个请求,前一个请求返回才能进行后一个请求,当系统 B 出现一个慢请求时,会堵住后面 4 个请求,系统 B 中的 1 个 Slow IO 可能会造成系统 A 的 5 个 Slow IO。所以,每个节点的每一个系统服务都有义务主动减少或降低处理延迟。
我们通常说的网络抖动,拿云计算场景来看,可能有如下现象:
1、两台 ECS 服务器之间从发出 ping request 到 reply 回复的正常水平是 5ms,在某个时间点突然发生抖动,增加至 50ms,随后马上恢复。
2、负载均衡 SLB 上的 HTTP 请求平均延迟的正常水平在 10ms,在某个时间点突然发生抖动,整体延迟增加至 100ms,随后马上恢复。
3、通过 ECS 访问 RDS 数据库,在某个时间点突然打印大量日志如"SocketTimeOut"、"Request timeout" 等,持续时间为秒级,随后马上恢复。
从上述现象可以看出,网络抖动在云计算场景下有了新的理解,它产生的原因可能是由于发送端和接收端之间的链路、系统内部的一个瞬时抖动,比如业务所在 Linux 系统 crash、链路有丢包重传、网卡 up/down、交换机缓存瞬时打满等。
我们先看一下解决网络延迟和抖动的一般方法:
1、交换机和路由器等设备,主动避免网络报文排队和处理时间。
2、云网络及上云等网关设备主动降低处理延迟,通过硬件提高转发速度,通过 RDMA 技术降低时延。
3、业务应用所在的虚拟机或者容器的内核协议栈打开 tso 等硬件加速方案,采用零拷贝等技术降低延迟。
2.2 网络抖动的分类
在云计算场景下,通过对抖动问题进行分析,根据抖动发生的时刻和是否可复现,将抖动分成三大类:
1、当前还在发生的抖动问题,且这个现象还继续存在,我们称之为 Current 当前抖动。这类问题一般由于链路中有持续性或周期性丢包、Qos 限流引起。
2、过去某一时刻出现的抖动,当前现象已不存在,我们称之为历史抖动。这类抖动问题一般在日志中打印“socket timeout”,或者有重传报文记录,这类问题相对来说少,很难定位。
3、通过 ping 包去检测连通性或网络状态,经常有几十甚至上百 ms 的延迟,而正常情况是几个 ms 不到。ping 毛刺问题,有可能该现象还一直存在,或者是间歇性地出现。这类问题一般是业务负载高(load 高),系统卡顿,或者存在虚拟化环境中的 CPU 争抢问题。

一般的,丢包和重传会引起当前和历史抖动问题,拿 tcp 协议来说,只要从 tcp 发出去的报文在链路上出现了丢包,内核协议栈就会对该报文进行重传,大量的重传会导致业务超时和引起网络抖动。因此,丢包问题,也是网络抖动的头号宿敌。
但还得明确一个概念:网络丢包可能造成业务超时,但是业务超时的原因不一定是丢包。原因前面也提到过,包括链路上的硬件转发或路由等设备,以及其上的系统及应用软件的每一个环节都存在引起业务超时的情况。
2.3 网络抖动的衡量指标
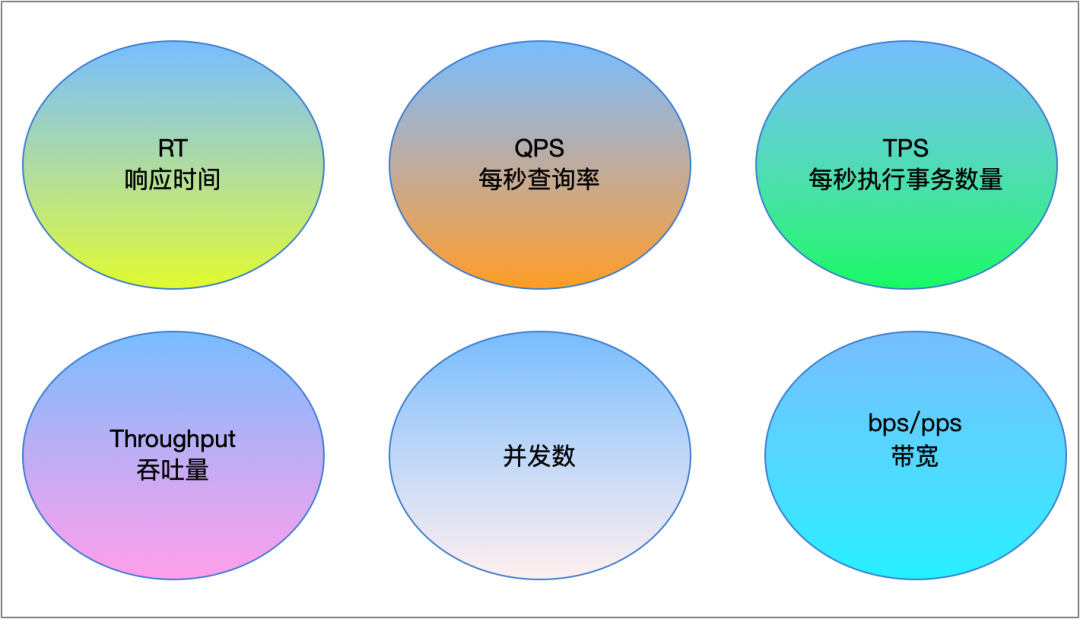
衡量“网络抖动”的指标,大家能想到的肯定是看业务的请求和回复报文的延迟是多少,即 latency 或者 RT(Reponse Time),在云计算场景中,具体化到了一些特定的网络指标,比如 RT、请求数、连接数、bps、pps 等。其中一些指标的含义如下:
1. 响应时间(RT Response Time)
响应时间是指执行一个请求从开始到最后收到响应数据所花费的总体时间,即从客户端发起请求到收到服务器响应结果的时间。RT 是一个系统最重要的指标之一,它的数值大小直接反映了系统的快慢。
对于一个游戏软件来说,RT 小于 100 毫秒应该是不错的,RT 在 1 秒左右可能属于勉强可以接受,如果 RT 达到 3 秒就完全难以接受了。而对于编译系统来说,完整编译一个较大规模软件的源代码可能需要几十分钟甚至更长时间,但这些 RT 对于用户来说都是可以接受的。所以 RT 的多少,对不同系统的感受是不一样的。
2. 吞吐量(Throughput)
吞吐量是指系统在单位时间内处理请求的数量。
系统的吞吐量(承压能力)与 request 对 CPU 的消耗、外部接口、IO 等紧密关联。单个 request 对 CPU 消耗越高,外部系统接口、IO 速度越慢,系统吞吐能力越低,反之越高。影响系统吞吐量几个重要参数:QPS(TPS)、并发数、响应时间。
3. 并发数
并发数是指系统同时能处理的请求数量,这个也是反映了系统的负载能力。一个系统能同时处理的请求数量,连接数量都有一个规格要求,当请求数越多时,系统处理的速度就会出现瓶颈。
4、QPS 每秒查询数量(Query Per Second)
QPS 是一台服务器每秒能够响应的查询次数,是对一个特定的查询服务器在规定时间内所处理流量多少的衡量标准。
5、TPS 每秒执行的事务数量(throughput per second)
TPS 代表每秒执行的事务数量,可基于测试周期内完成的事务数量计算得出。一个事务是指一个客户机向服务器发送请求然后服务器做出反应的过程。例如,用户每分钟执行 6 个事务,TPS 为 6 / 60s = 0.10 TPS。
指标:
QPS(TPS):每秒钟的请求/事务数
并发数:系统同时处理的请求/事务数
响应时间:一般取平均响应时间
这三者之间的关系:
QPS(TPS) = 并发数/平均响应时间
并发数 = QPS * 平均响应时间
为了描述更广泛意义上的网络抖动,云场景中我们一般用 RT 这个术语,我们会有监控检测某个业务的 RT 值,比如 nginx 服务的 RT 值。一般本文所述的延迟、超时、响应慢、卡顿等词汇,只要影响到了用户的体验,都认为是抖动问题。
下图是衡量指标的汇总:
3. Linux 内核网络抖动
3.1 内核网络抖动点
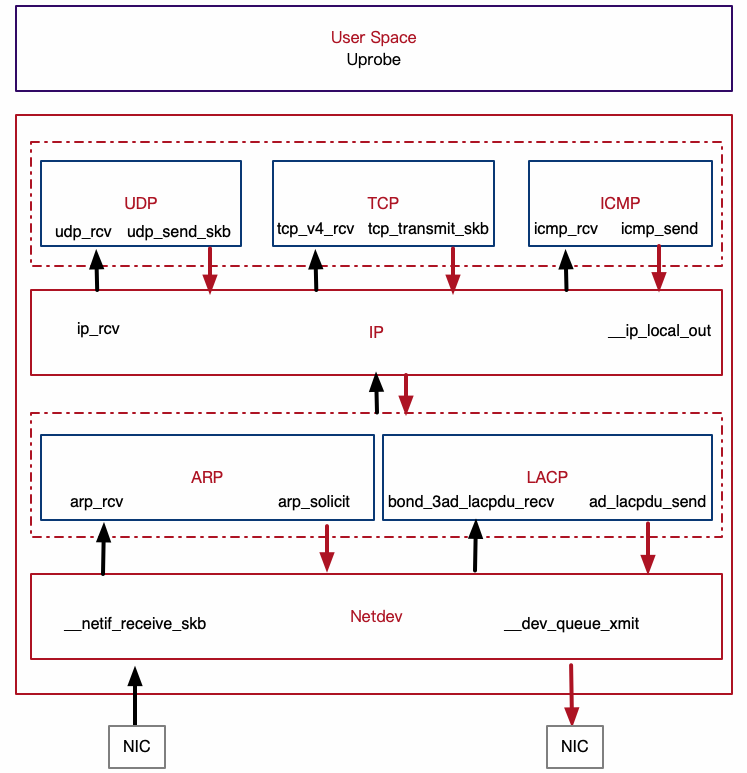
用户的业务部署在云上,一般运行在容器里或者直接部署在 guest OS 上,前面也提到过,操作系统内部、业务进程的调度运行、业务的请求和处理也会存在网络抖动的点。其中,报文的收发过程也存在诸多耗时的地方。首先看一个 Linux 内核网络协议栈的分层架构图。
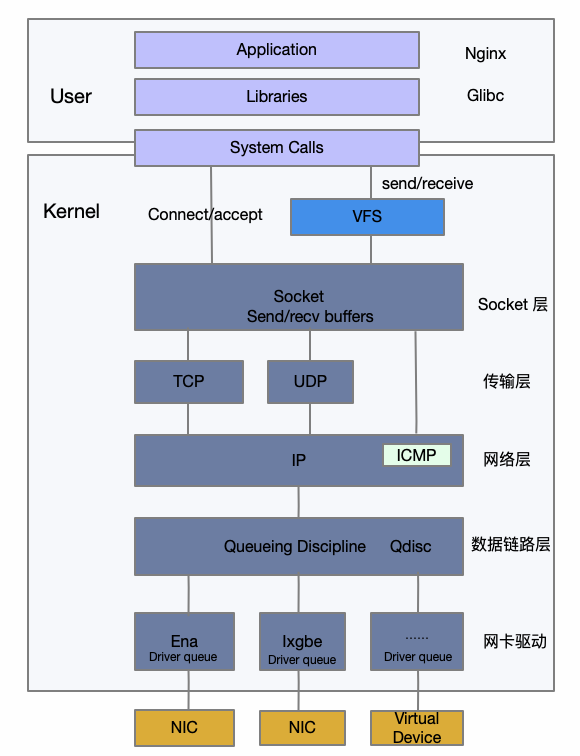
我们先来回顾一下 Linux 的网络收包流程:
1、数据报文从外部网络到达网卡。
2、网卡把数据帧通过 DMA 送到系统内存保存。
3、硬中断通知 CPU 有报文到达。
4、CPU 响应硬中断,简单处理后发出软中断。
5、软中断或者通过 ksoftirqd 内核线程处理报文,然后通过网卡 poll 函数开始收包。
6、帧被从 Ringbuffer 上摘下来保存为一个 skb。
7、协议层开始处理网络帧,经过 netdev、IP、tcp 层处理。
8、协议层处理完之后,把数据放在 socket 的接收队列中,然后通过唤醒用户进程来进行收包。
9、用户进程经过操作系统的调度获得 CPU,开始从内核拷贝数据包到用户态进行处理。
Linux 网络的发包流程如下:
1、应用程序通过 send 系统调用发送数据包,从用户态陷入到内核态,内核会申请一个 sk_buff,然后将用户待发送的数据拷贝到 sk_buff ,并将其加入到发送缓冲区。
2、网络协议栈从 Socket 发送缓冲区中取出 sk_buff,并按照协议栈从上到下逐层处理,最后报文进入网络接口层处理。
3、网络接口层会通过 ARP 协议获得下一跳的 MAC 地址,然后对 sk_buff 填充帧头和帧尾,接着将 sk_buff 放到网卡的发送队列中,一般使用 qdisc 设置排队规则,进行入队和出队处理。
4、网卡驱动会从发送队列中读取 sk_buff,将这个 sk_buff 挂到 RingBuffer 中,接着将 sk_buff 数据映射到网卡可访问的内存 DMA 区域,最后触发真实的发送。
5、当发送完成的时候,网卡设备会触发一个硬中断来释放内存,主要是释放 sk_buff 内存和 RingBuffer 内存的清理。
处理流程如下图所示,数字编号不一定完全对应。
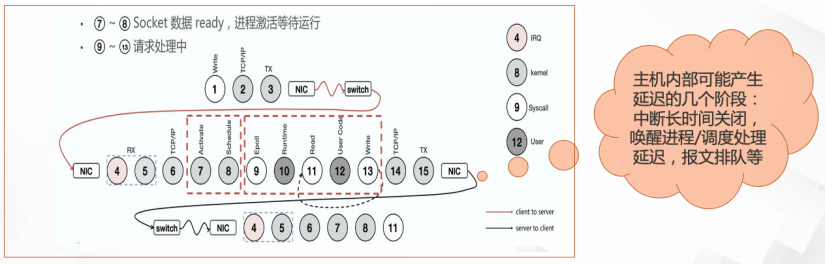
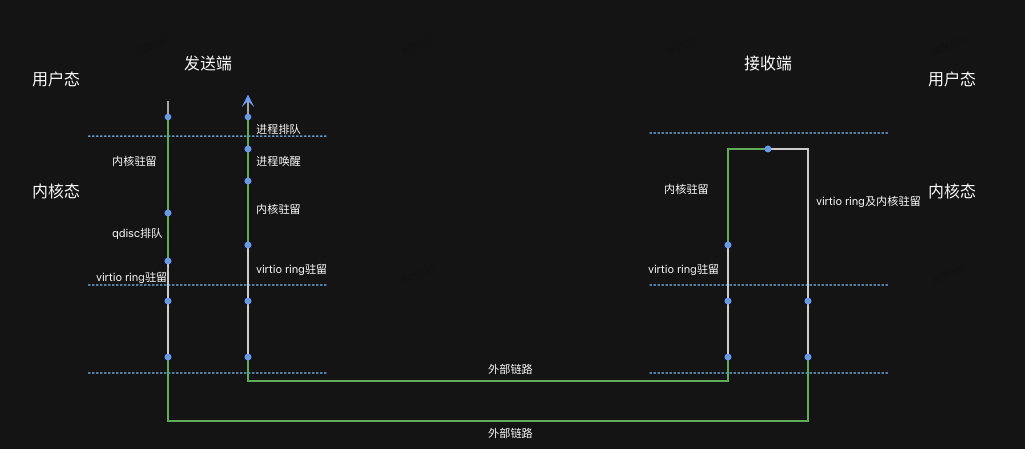
上面所述的报文收发过程,存在网络抖动的地方是:协议栈和驱动的入口和出口处,以及内核态和用户态的衔接处。比如接收报文到达后发出中断到报文真正得到处理这段时间的耗时,这个耗时很多时候都是由于某个进程长时间关中断导致中断和软中断处理延迟;另一个是数据到达接收队列后,唤醒用户进程到真正调用 recvmsg 收包处理的这段时间的耗时,这个主要由于系统繁忙而出现调度延迟,被唤醒的进程长时间未能真正去处理收到的包。
因此,Linux 内核里,网络抖动一般是在中断和软中断处理的延迟,进程的睡眠和唤醒延迟,qdisc 排队延迟,Netfilter 处理延迟,tcp 的超时重传延迟等。
3.2 三类抖动的根因探寻和解决之道
云计算涉及到的网络节点较多,且每个点都有发生抖动的可能,限于篇幅,同时由于操作系统和业务最贴合,本文只基于节点内部操作系统的视角。针对前面提到的三类抖动:当前抖动、历史抖动、ping 毛刺,来讨论一下如何去发现和解决这三类抖动的问题。
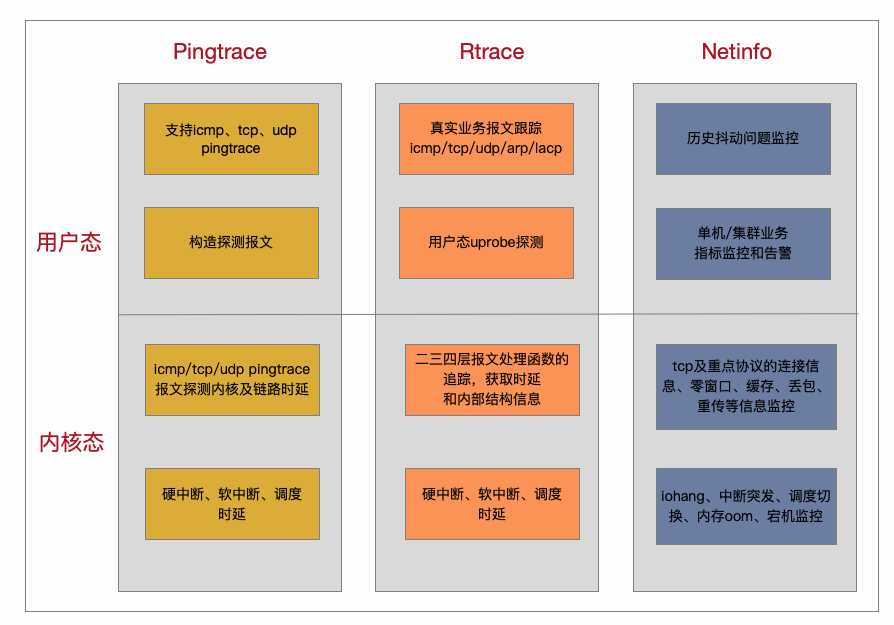
经过我们在实践中的摸索和分析总结,提出以下抖动根因的探测方法和抖动问题解决之道:
1. 针对 Ping 毛刺问题,提出在用户态构造报文进行探测的方法:Pingtrace。不同于大家常用的 ping 程序,Pingtrace 通过在 icmp/tcp/udp 的基础上增加 pingtrace 协议头,在 pingtrcace 报文沿途经过的节点填上对应的收发时间戳,最后通过计算各个节点的延时信息,构建一个拓扑来描绘节点详细信息,从而找到抖动的节点和抖动原因。
2. 针对当前抖动问题,对真实报文直接跟踪挖掘时延:Rtrace。它对真实业务报文所经过的内核处理函数特别是协议栈处理函数进行 tracing, 得到每个函数点的时间戳信息,支持 icmp/tcp/udp/lacp/arp 等协议报文调用路径的获取和时延信息的统计,还能清楚知道某个协议包在哪里由于什么原因丢包的,或者哪个函数处理慢了。
3. 针对历史抖动问题,提出常态化抖动监控系统:Netinfo。它对容器(pod)、流、逻辑接口的各项指标进行监控,追踪业务抖动的根因,进行集群和单机的告警上报。深度加工丢包、重传、拥塞控制、窗口变化、流量突发、中断延迟等指标进行分析,归一化成简单的健康度指标;同时在数据处理中心进行离群检测,找出影响抖动的几个重点指标和具有集群共性的指标。
4. 针对不同的业务应用,提出应用观测引擎 Raptor。业务应用的内在问题是客户直接能看到的,但是如何与系统指标关联,是当今观测领域的难点,它通过把应用内部的细节进行展开,结合系统的 profiling 剖析,能找到应用抖动的密码。
通过网络抖动三剑客和应用观测引擎 Raptor,我们能系统的监控和观测在节点内部出现的抖动,同时能定界出是业务应用自身的问题,还是外部网络的问题。下面的章节我们将简单介绍网络抖动三剑客的原理。
4. 瞬时毛刺的主动探测:Pingtrace
4.1 背景
在碰到网络联通性较差或者系统比较卡时,我们喜欢用系统自带的 ping 命令向目标地址发送请求包进行检测,然后通过目标机回复的响应包来判断是否出现了延迟,这种方法简单又高效。但有时我们想知道,这个 ping 包延迟了,和业务的关系怎样?是否延迟高了或者又丢包了,业务应用就真的出问题了?延迟和丢包的具体点在什么地方?是系统内部还是外部链路?原因是什么?
经过这么几个灵魂拷问之后,我们发现,对于瞬时 ping 延迟突然冲高的问题(ping 毛刺),传统的 ping 工具已经不能直观的拿到背后的信息。为此我们提出了通过构造新报文(pingtrace 报文)的方式进行主动的探测,通过在 pingtrace 沿途经过的点填充 timestamp 的方式,把系统内部的延迟精细化到用户态和内核态的函数处理点,然后通过可视化方式展现延迟高的模块。
4.2 pingtrace 功能介绍
Pingtrace 通过在用户态构造探测协议报文,在独有的 pingtrace 头部增加 icmp、 tcp 及 udp 协议头,可以进行多种协议探测,同时基于 eBPF 技术,可以做到无侵入的方式实现系统内部细节的窥探,开销远远小于 tcpdump 等已有工具,并可实时展示各个数据链路的时延信息,快速发现问题边界。
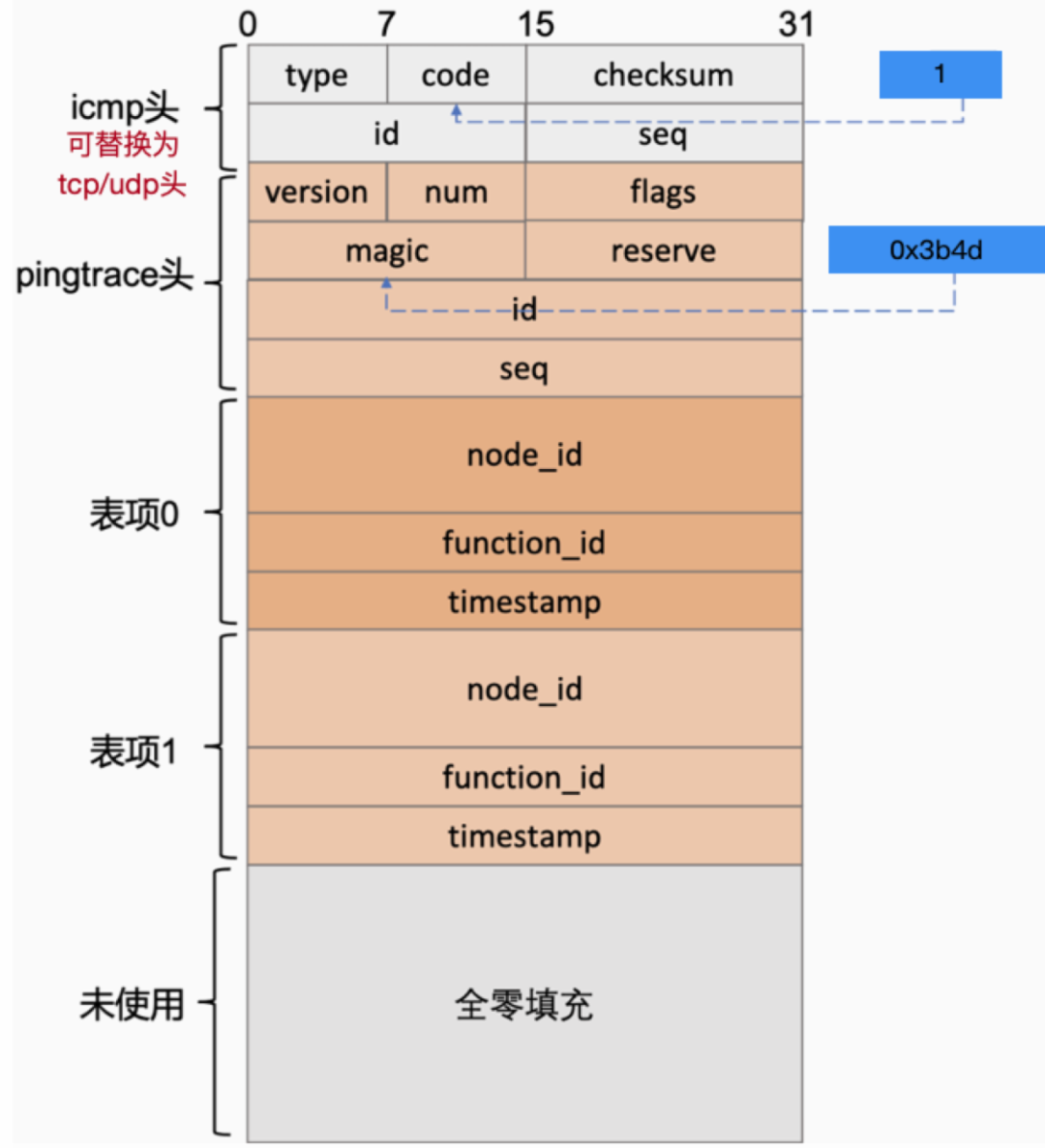
下图是 icmp pingtrace 的协议实现(icmp 头可以替换为 tcp 和 udp 协议头)。在各个节点,要求其他节点捕获到特定 pingtrace 报文时填入 node id 和 timestamp(变通的实现方法是通过 eBPF 把报文送到用户态,然后补发带有 timestamp 的报文回送到源端),为了让报文尽可能小于 1500 个字节,可以通过控制表项数量来避免沿途的 IP 报文分片。
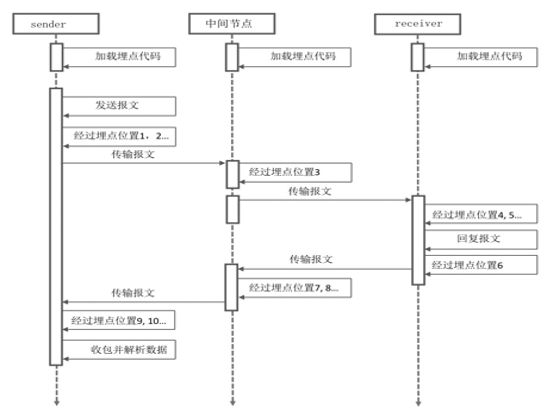
下图是其工作过程:
下图是最终呈现出来的效果,每个蓝点地方鼠标放过去会显示延时信息:
注意:很多人关心发送端和接收端的时钟源不统一,如何来进行延迟节点的判定。我们在边界点采取了相对延迟的计算方法,而不是像其他几个点的绝对延迟计算方法。
计算方法如下:通过对边界的两个采集点时间戳信息计算出差值,以最近 100 个报文中最小的差值作为基准值,对下一个报文的差值进行校正(校正就是用当前算出来的两台机器时间戳差值相减得到 delta,减去基准值 base 算出来的结果),最后得到相对延迟。如果发现相对延迟较高,则说明链路上出现了问题。
这个是 udp 的 pingtrace 探测:
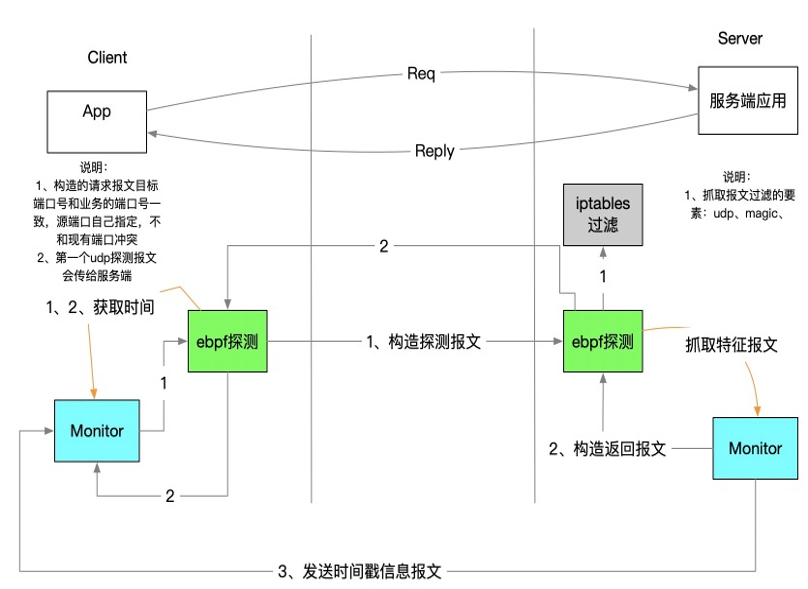
这个是 tcp 的 pingtrace 探测:
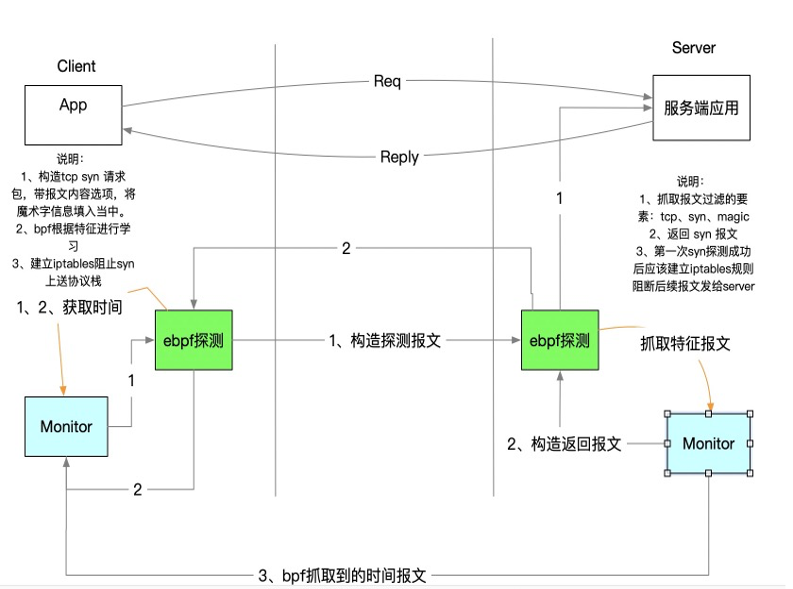
tcp 和 udp 的延迟探测,主要目的是为了探测系统 tcp 和 udp 处理路径是否出现延迟,因为绝大部分业务都会采用 tcp 和 udp(icmp pingtrace 不能满足此需求),由于端口号的原因,它主要多了一个端口探测和学习的过程。
4.3 pingtrace 如何进行探测
具体的使用上,有界面和命令行两种方式。界面方式只需要填入对应的源和目的 IP,它会自动下发安装命令到 client 和 server,然后开始进行诊断,诊断结果可以直接呈现是哪个节点的哪个阶段出现的延迟。

或者通过命令行方式:
sysak pingtrace_raw -c 127.0.0.1 -m 1000 -o log5. 真实业务报文延迟挖掘:Rtrace
使用自定义报文探测方式虽然可以了解当前的系统负载和链路情况,但很难说明对某个业务或者协议是否真的有影响,所以我们还需要对实际业务的报文,包括 tcp 、udp、icmp、arp 及 lacp 等报文进行跟踪确定报文走的路径和每个函数的耗时。
rtrace 是一款基于 eBPF 的网络诊断工具,利用 eBPF 技术动态打点来取得报文时间信息,以及每个网络层的详细信息,比如 tcp 常见的 memory 使用情况,拥塞和回复 ack 情况,记录在日志里,可以辅助问题的定界和丢包查看。如下图,rtrace 监控的部分协议栈处理函数点:
在云计算的集群环境里,抓取到的单个节点的延时和 tcp 连接信息,有时还是很难去判断是否真的有问题,如果能从集群的维度,或者多个节点的共性事件的方式,或许能收获更多。rtrace dump 功能还支持集中式抓包的能力,类似一键发起抓包功能,然后进行集中式分析,比如分析 tcp 的发送接和接收到 ack 时间,到底是慢在哪个节点上,通过对比 tcp 的 sequence 来汇总数据,很快就能得到结果。
6. 历史抖动监控:Netinfo
历史抖动问题,是几种抖动问题里最难解决的,由于问题不再复现,我们能想到的是增加一些监控手段,把历史某个时间点的系统状态、协议交互情况等信息收集起来是不是就能解决抖动问题了?答案是否定的。如果单纯从网络本身的丢包和 tcp 连接状态信息来判断,显然还不够。还需要看当时 IO 是否 hang 住,内存是否 oom,系统是否宕机,中断是否有突发,调度是否延迟等。
如何在上百个指标中快速找到异常点?Netinfo 在检测到抖动后(业务的 RT 值或者健康度指标),会先汇集所有指标进行组合,进行离群检测。最终把集群里的共性事件,通过离群统计算法来确定抖动根因。

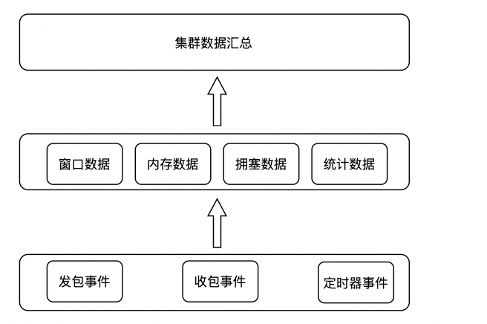
Netinfo 主要由数据采集和数据分析告警两部分功能组成:
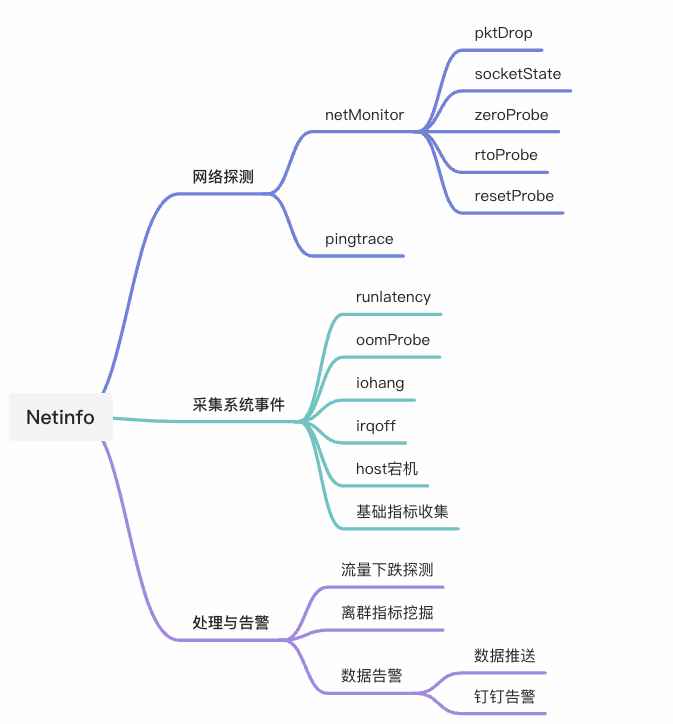
关于 Netinfo 可以参考文章 Netinfo:揭开网络抖动面纱的神器。Netinfo 的功能,后面会移到 SysAK 里,同时,后端的数据处理部分,也会移到 SysOM 统一平台分析。
SysOM 平台链接地址:
http://www.sysom.pro/welcome
7. 网络抖动探测标准化设想及未来展望
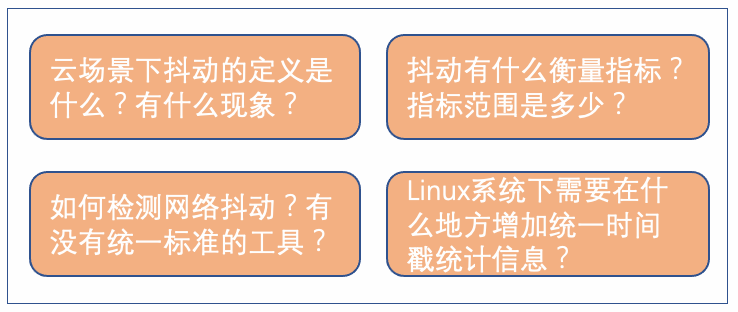
借助于网络抖动三剑客(Pingtrace、Rtrace、Netinfo),我们很容易知道系统的抖动点和原因。但是这些可能只是我们自己的理解,我们基于云场景做了很多探索,并把这些探索沉淀到了龙蜥操作系统,还进行了很多优化。而目前操作系统呈现百花齐放的态势,网络抖动的发现和检测方法不统一,将很难在一些指标评测和系统对接时,有一个有效的验收标准。
因此我们觉得有必要形成一个标准,比如:
1)云计算场景下抖动的定义和表现是什么?不同类型的业务有什么具体现象就算是抖动了?
2)抖动包含哪些内容和衡量指标?指标的范围是什么?
3)如何检测网络抖动?有没有统一的工具进行探测?探测哪些点合适?
4)需要在哪些点增加时间戳统计?比如 Linux 用户态到内核态的发包点,网卡的发包点。
针对网络抖动,每个人的理解可能不一样,上文 2.1 节提到抖动的几个现象,就是具体的案例。如果能结合具体的指标去衡量,就会有很大的可实操性。比如 RT 这个指标,我们选择 nginx 的业务作为衡量对象,RT 在多少范围算是异常的?10ms 或者 100ms 都可能,关键评判是不同用户场景,是否这个 RT 值影响到了用户体验,如果用户体验很差,就认为是发生了抖动。
当然最重要的,我们需要制定出一套方案和工具去进行探测,只要工具说探测到 nginx 业务的 RT 指标高了,那么就说明在同一个系统负载下,你的整个云服务网络抖动大,网络质量不太好,这个时候我们就要根据探测到的根因去解决问题。
回到操作系统层面,我们需要指定哪些探测点呢?只有大家形成一个统一认识,在 Linux 内核收发包的出入口进行时间戳信息的提取是合适的。例如在内核 sendmsg 系统调用函数和网卡发包的地方(比如 virtio-net 的 start_xmit 函数)增加时间戳信息。这样大家实现的工具,就能统一到一个衡量维度。
比如,我们在 virtio-ne 驱动里,我们也在积极推动增加一个时间戳的点,将有助于我们在发包处时间戳的统一:
+#define VIRTIO_NET_HDR_F_TSTAMP8. 总结
最后做一个总结,抖动的检测和治理是一个长期的任务,如果能将 Linux 系统内部的检测工作标准化起来,将有助于我们制定统一的性能评测方案,以及运维自动化的实现。
另外,上述工具几乎全部采用无侵入的方式实现,基于 eBPF 实现给了我们很大的发挥空间,它们将会在 SyaAK 里全部开源(目前已大部分开源)敬请关注,后面也会有系列文章再次详细介绍。
相关链接地址:
SysAK 的开源项目链接:
git@gitee.com:anolis/sysak.git
SysOM 的运维平台链接:
git@gitee.com:anolis/sysom.git




