

随着人工智能, IoT 等技术的推广普及,智能监控,智能制造等新兴领域蓬勃发展,涌现出了越来越多的海量非结构化数据存储需求。举例来说,服务于公安机关的智能监控程序,不仅需要存储视频,而且还需要存储因使用人脸识别技术而产生的人脸截图等文件。这一类的小图像通常只有几个 KiB 到 几十个 KiB 大小,但是数目巨大,动辄十亿甚至百亿规模。
这类业务,并不需要文件系统提供的复杂语义。相反,只需要存取(PUT / GET)的简单操作模式,使得这类业务非常适合使用对象存储。虽然对象存储相比文件存储更擅长处理数目巨大的非结构化数据,但对于十亿甚至百亿的规模,依然会对现有的系统(如软件定义存储中最常用的 Ceph)造成严重的性能和可用性的冲击。本文将介绍如何通过引入 adCache、PhxKV 等自研组件,成功支持百亿级别的海量小对象存储。
基于 Ceph 方案处理海量小对象的问题
为了说明 Ceph 处理小对象合并的问题,我们首先简要回顾 RADOS Gateway ( RGW, Ceph 的对象存储接口)的工作原理。 RGW 工作在 Ceph 的底层存储 RADOS 之上。RADOS 对外提供存取 RADOS Object (为了区分对象存储,我们把 RADOS Object 称为 R-obj )的接口。一个 R-obj 除去数据之外,还可以维护一定数量的 KV 形式表示的元数据( omap )。RGW 就是利用 RADOS 的接口,构建了对象存储。其中,一个对象,会有三类与之相关的 R-obj。
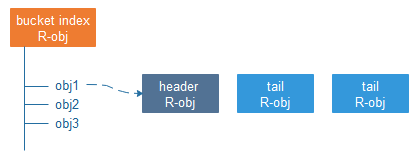
如上图所示,对象存储中的每个桶,都会有一个对应的 bucket index R-obj,桶中的每一个对象,都会对应该 R-obj 的一条 omap,存储诸如创建时间,权限信息等系统元数据。由于 R-obj 大小的限制,对象的数据和用户自定义元数据部分,被切割之后存储在一个 header R-obj 和若干个 tail R-obj 中。Bucket index R-obj 肩负着索引功能,以及冲突处理的逻辑,所以,每个写操作都需要操作 bucket index R-obj。
Ceph 底层存储 RADOS 的一致性协议,为其处理海量小对象带来了很大的问题。 RADOS 在维护复制组 ( PG , Placement Group )的一致性时,要求复制组内所有在线(状态为 up )的 OSD 都返回成功,一个 op 才算完成。而 OSD 的状态,是由 monitor 监控 OSD 超时,更新视图并扩散至全集群的。
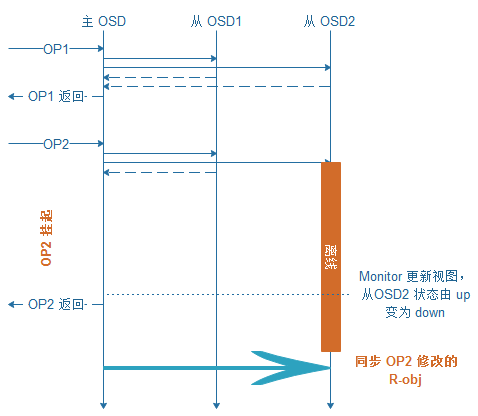
在上图的例子中,OP2 在处理过程中,从 OSD2 发生离线故障,这时,由于从 OSD2 仍然被认为在线,导致 OP2 被挂起,直到 monitor 更新从 OSD2 的状态,OP2 才可以被返回。当 OSD2 从离线状态重新上线时,会执行修复操作,同步自己和主 OSD 的状态。
为了修复复制组中离线的 OSD ,重新上线的 OSD 会比对自身和主 OSD 中的 op log ,定位出离线期间发生修改的 R-obj ,并从主 OSD 中复制这些 R-obj 的副本。注意,RADOS 中 op log 的作用只为定位发生改变的 R-obj ,并不能通过 replay op log 的方式进行数据恢复。所以,发生变化的 R-obj 都需要进行全量修复。即使 bucket index R-obj 只是在从 OSD2 离线时插入了一条 omap,修复 bucket index R-obj 的过程中,依然需要复制整个 bucket index R-obj 的 omap 列表,且修复过程也会阻塞业务 I/O。
讲到此处,我们已经不难看出 RGW 处理海量小对象时,元数据处理带来的问题:
OSD 短暂离线,造成 bucket index R-obj 无法访问时,会阻塞业务 I/O。
如果离线时间超过了心跳超时,触发视图变更,业务恢复,但是会导致 OSD 重新上线时全量修复 bucket index R-obj。海量小对象场景下,bucket index R-obj 拥有数量巨大的 omap,修复耗时,进一步增加挂起请求的时间。当网络不稳定,视图变更频繁时,不仅请求挂起,还会产生巨大的不必要修复流量,消耗系统资源。
使用 PhxKV 承载海量小对象
我们已经说明了 RADOS 的一致性协议和修复机制在海量小对象场景中带来的问题,接下来,我们将说明深信服企业级分布式存储 EDS 是如何通过自研的分布式 KV —— PhxKV 来支撑海量小对象的元数据存储。我们首先介绍区分于 RADOS 一致性协议的 RAFT 协议,之后介绍我们如何以 RAFT 协议为基础,构建了 PhxKV 分布式 KV 系统。
RAFT 一致性协议
RAFT 协议有三个重要组成部分:Log,状态机,和一致性模块。一个 RAFT 组中有多个 peer,其中一个为 leader,其他为 followers。
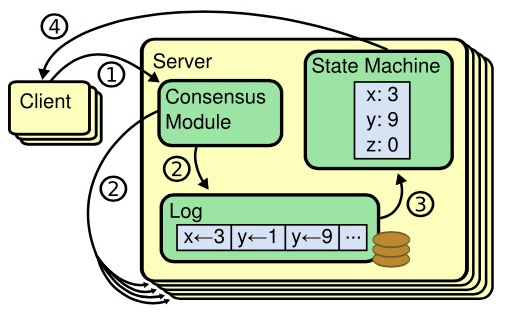
如上图所示,客户端将 op 发送至 leader 的一致性模块,之后 leader 请求所有的 peer 将该 op append 至 Log 中,当大部分(例如,三个 peer 中的两个)append 成功时,就可以认为 op 已经 commit,这时,leader 更新状态机,并返回请求。至于 followers , leader 会在后续的 op 中指示其将已经 commit 的 op log 执行,更新状态机。
当 leader 发生故障,或者 leader 所在分片中的 peer 数少于大部分 peer 数导致 leader
下台时,RAFT 协议通过各 peer 间心跳的超时来触发选主流程,从而进行视图的变更。
RAFT 协议的具体细节和故障处理方面比较复杂,我们就不在此赘述,有兴趣的读者可以移步去阅读论文 In Search of an Understandable Consensus Algorithm 。我们在此归纳 RAFT 协议的以下特点:
RAFT 协议中,一个 op 成功的条件更容易被满足:当复制组中大部分节点返回成功时,一个 op 即被认为处理成功,这一特征,使得某些节点网络不稳定或者主机重启时,I/O 能够不被阻塞;
RAFT 协议中的视图变更,不需要额外的 monitor 进程来触发,而是通过复制组内各 peer 心跳超时触发的选主操作来进行,视图变更更加快速。触发视图变更的条件更苛刻(单个 follower 离线不会导致视图变更),即使极端情况下,也能在较短时间内选出新主,快速恢复业务;
RAFT 能够通过复制和 replay log 来实现不同 peer 间 Log 和状态机的同步。例如,一个重新上线的 peer 执行的最新 op 为 op10000,此时,leader 执行到 op10003,为了同步状态,该 peer 只需从 leader 处复制 op10001 ~ op10003 的 log,并在本地执行,即可和 leader 同步状态机。增量修复和全量修复相比,可以大幅减少修复时间,并节省大量的网络和 I/O 资源。
承接第一点和第三点,peer 修复的过程对上层透明,并不会阻塞业务 I/O。
PhxKV 架构
接下来,我们介绍如何基于 RAFT 协议构建 PhxKV 系统。
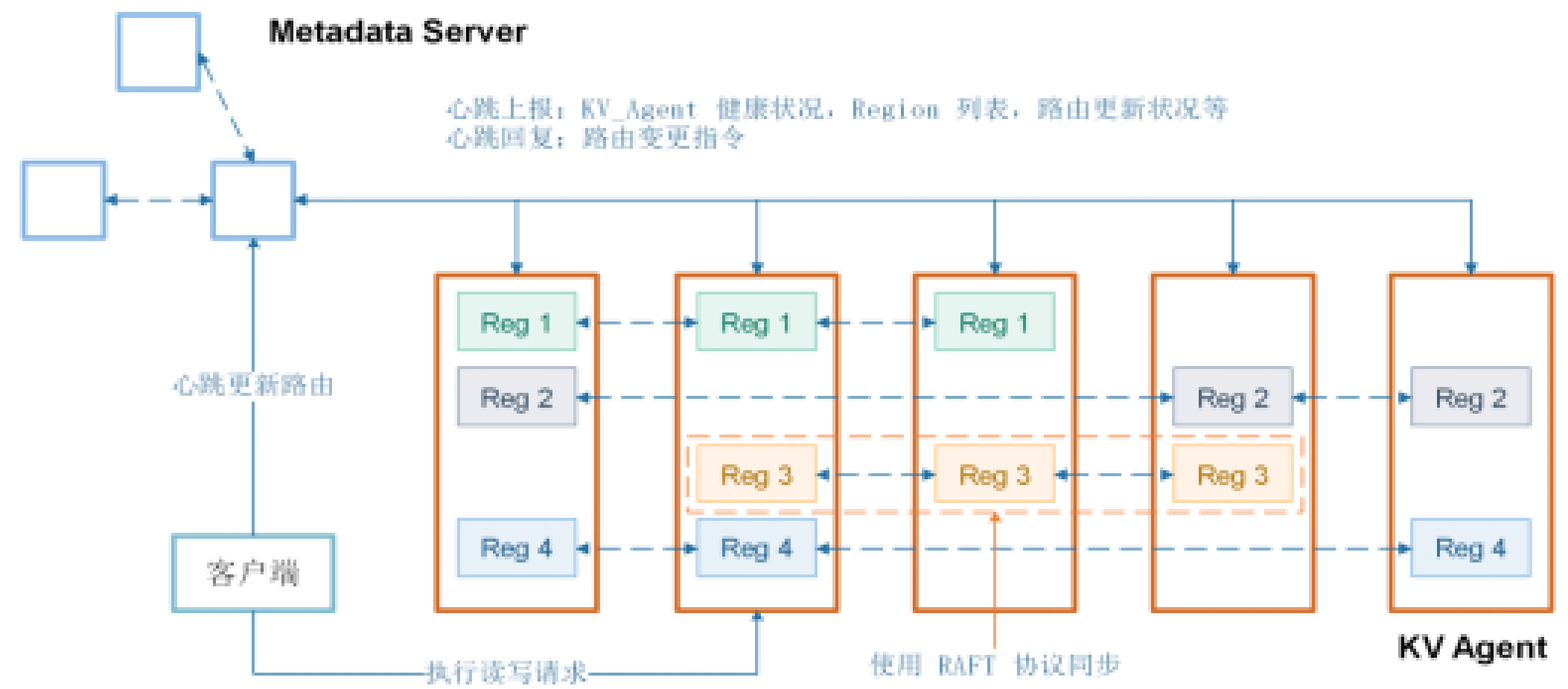
PhxKV 的架构如上图所示,PhxKV 提供和本地 KV 引擎类似的增删改查和批量操作的同步异步接口。PhxKV 的 key 空间被一致性哈希映射到若干个 region 中,各 region 管理的 key 没有重合,每个 region 对应一个 RAFT 复制组,通过 RAFT 协议维护一致性。 PhxKV 采用 RocksDB 作为底层引擎,提供本地的 KV 接口。
PhxKV 的主要组件和角色如下所述:
KV agent 是 PhxKV 的服务端进程,管理存储在相同物理介质上的 regions 。出于对故障域的考虑,不同 KV agent 管理的物理空间处在不同的 SSD 上。相同 region 的不同副本存储在不同 KV agent 上,并通过 RAFT 协议进行同步。
Metadata server 管理元数据。通过 KV agent 定时的心跳上报收集 KV agent 和 region 的健康状况,及时通过心跳回复下达负载均衡和修复操作。出于容错考虑,metadata server 也有多个进程运行在不同主机上,并通过 RAFT 协议进行同步。
客户端执行 I/O 操作。客户端通过被动定时心跳和主动心跳从 metadata server 拉取各 Region 的路由信息,之后,根据路由从对应的 KV Agent 中执行对应的增删改查操作。
PhxKV 针对业务特征,还进行了一系列深度优化:
RocksDB 为了提供高性能和高可靠性的写入操作,在写操作时,op log 先顺序写入 WAL( write-ahead log )进行持久化,数据部分则只是在内存中更新 memtable,后续才以大块 I/O 的形式刷入底层 SST 文件。
事实上,RAFT 协议中的 Log 可以作为状态机的 WAL 使用。我们通过 RocksDB 的 disable WAL 配置项关闭了状态机的 WAL,这样,状态机的更新只需操作内存,减少了一半的落盘操作,大大降低了时延。不过作为代价,在掉电的情况下重启,状态机会发生数据丢失,我们首先需要利用 RAFT Log 来扮演 WAL,将状态机恢复至重启前的状态。
PhxKV 在进行修复和扩容时,需要将 Region 内的全部数据进行复制和迁移。逐条复制性能较差,我们使用 RockDB 提供的 sst_file_writer 和 IngestExternalFiles 功能,进行整 Region 的批量插入,降低了逐条插入的锁操作对性能的影响,并消除了一致性隐患。
RocksDB 的删除操作是异步操作,并不能快速回收空间。当某个 KV agent 容量告急,迁移出 region 时,可能很久之后才会见效,影响负载均衡效果。我们深度订制了 RocksDB,通过改变数据组织形式,使得 Region 的删除操作可以同步快速回收空间。
PhxKV 在 EDS 海量小对象中的角色
除去 RADOS 一致性和修复带来的问题,元数据规模过大,底层数据的碎片化也是 RGW 面对小对象合并时的棘手问题。 EDS 使用另一组件,分布式缓存(adCache)和 PhxKV 双剑合璧,一起打造了海量小对象的解决方案。 AdCache 将数据暂时缓存在 SSD 盘上,后续再批量回刷至 RADOS,大幅降低了写请求的访问时延。
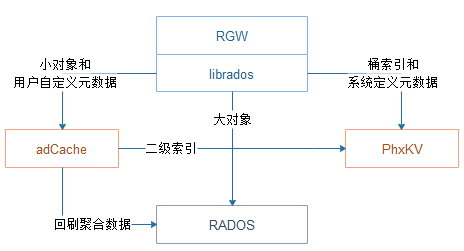
上图表示了小对象合并架构中的各组件关系。在 Ceph 的原始实现中,RGW 将对象的数据和元数据都直接存储在 RADOS 中,其中元数据以键值的形式存储在 R-obj 的 omap 中。RGW 使用 librados 和 RADOS 进行交互。
为了实现上述改造逻辑,我们劫持了 RGW 对数据部分和元数据部分的操作。其中,元数据部分被重定向至 PhxKV 中。此外,数据操作被重定向至 adCache,adCache 用异步合并回刷的原则,后续对存储的小对象被进一步聚合后,回刷至底层引擎 RADOS 中。同时,adCache 会生成二级索引,使得可以定位到小对象在合并后存储的位置和偏移,在数据回刷至 RADOS 时,二级索引也会作为元数据被批量写入到 PhxKV 中。
在采用了上述针对性的优化后,EDS 的小对象写入性能,相比原生系统有了数量级的飞跃。小对象合并引入的二级索引虽然增加了读取时的访问路径,但是由于减少了元数据的规模,也变相提升了 RADOS 的访问性能,因此,整体的读取性能并没有下降。由于 RAFT 协议更健壮的修复机制,修复时间相比原生系统有成数量级的下降,而且能够保持业务不中断,修复过程中几乎不出现业务性能的下降。
结论
海量小对象场景,是对象存储的新机会,也为现有架构提出了新的挑战。深信服 EDS 基于现有的架构,取长补短,合理引用新组件解决关键核心问题,并能够让老组件 RADOS 继续发挥特长,为海量小对象的存储打开了新思路。
作者介绍:
Eddison,从事分布式 KV 数据库 PhxKV 的研发工作。 香港中文大学博士,研究大数据存储系统的性能和可靠性,在 USENIX FAST, USENIX ATC 等顶级会议发表多篇学术论文。 从业以来,专注分布式一致性, KV 引擎,纠删码等领域,2018 年加入深信服科技。

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论