

关键词
写在前面
近些年来,学术界和工业界陆续开展了多项让排序模型变的 wider and deeper 的相关工作,其中,wider(更宽)意味着一个模型包含更多不同的子模型,如 xDeepFM[1]包括了 LR, DNN 和 CIN 三种组件,分别建模一阶显示特征交叉(LR),高阶隐式特征交叉(DNN)和高阶显示特征交叉(CIN);deeper(更深)意味着通过增加模型复杂性来提升模型性能,一些在 NLP 和 CV 领域使用的复杂组件开始被引入排序模型,如 xDeepFM 的 CIN 其实是利用卷积神经网络来建模特征交叉, BST[2]利用 Transformer 建模用户行为序列的表征。然而,更深更宽的模型在提升模型效果的同时,往往伴随着模型推理效率的下降。
爱奇艺提出的在线知识蒸馏方法来平衡模型效果和推理效率,并在短视频信息流和图文信息流两个重要场景上线后都获得了明显的正向效果。其中,在爱奇艺短视频场景时长指标+6.5%,点击率指标+2.3%;图文推荐场景时长指标+4.5%,点击率指标+14% 。
深度学习时代排序模型的演进
从建模特征组合这个角度去介绍深度学习时代排序模型的演进,按照时间的发展经历了三个时期(萌芽期、中兴期和突破期),具体如下:
a. 萌芽期:DNN 开始被引入推荐排序模型,其优点在于神经网络能隐式建模不同特征间的高阶特征组合。国内最早应用案例是百度等公司在 2013 年左右开始将 DNN 用作 CTR 模型;
b. 中兴期:深度排序模型开始被广泛接受,代表模型为 WDL[3]和 DeepFM[4]等,这些模型的优势在于在 DNN 基础上,增加了显示的一阶或二阶特征组合。其中 WDL 几乎成了推荐广告 CTR 模型从传统机器学习时代过渡到深度学习的敲门砖,应用这一模型既能尝到深度学习的甜头,又能复用已有的排序模型成果进一步提升模型性能;
c. 突破:从 DCN[5],xDeepFM 开始,深度排序模型开始变的更深更宽,尤其重视使用 DL 组件来显示建模高阶特征交叉,其显示的高阶特征组合更符合算法工程师对排序模型的期许。通过模型本身来进行特征组合可以避免人工特征组合的一些弊端,如工程代价和人力成本。
上面介绍的深度排序模型可以归类为如下表格,显示的高阶 vector-wise 交叉相对更 make sense, 也是最近一些排序模型工作的核心优化点:

排序模型优化动机
爱奇艺排序模型从 GBDT+FM 等机器学习模型跨入到深度学习时代也是从 WDL 开始的,但是爱奇艺在此基础上做了一些改进,最终排序模型结构如下图 1, Wide 侧是 FM, GBDT 输出是 FM 输入,Deep Model 是 DNN 和 FM 的 stacking。

该模型结构[7]在爱奇艺推荐的各个场景都作为 baseline model 使用,线上表现一直不错。从 2019 年开始,团队开始尝试推动模型的实时性和端到端建模,同时引入一些最新的研究成果来提升模型性能。但在实践过程中,发现 baseline model 存在如下弊端:
GBDT 是 CTR 模型外的预处理组件,不适合实时训练和更新。若 GBDT 更新,整个排序模型也需要更新,无法进行端到端训练;
若去掉 GBDT, 端到端建模要解决两类原始特征(稀疏特征和稠密特征)之间的高阶特征组合。现有模型对稀疏特征和稠密特征是隔离处理,稀疏特征只进入了 Wide Model,现有模型不支持稀疏特征的显示高阶建模;
现在的模型结构无法自适应引入一些新的排序模型组件,因为其结构过于的大而全,而缺少了灵活性。
爱奇艺首先尝试了最近提出的一些复杂模型来取代 baseline model,如 DCN, xDeepFM 等,但发现需要平衡 large model 的模型效果和推理性能是有待解决的比较关键的问题。
如以下图表格所示,xDeepFM 比较难落地:
推理性能:同等情况下,在 CPU 上推理,xDeepFM 与 baselinemodel 相比,耗时是其 2.5~3.5 倍;
使用 GPU 时,只有在大 batch 下,xDeepFM 推理性能才符合要求。
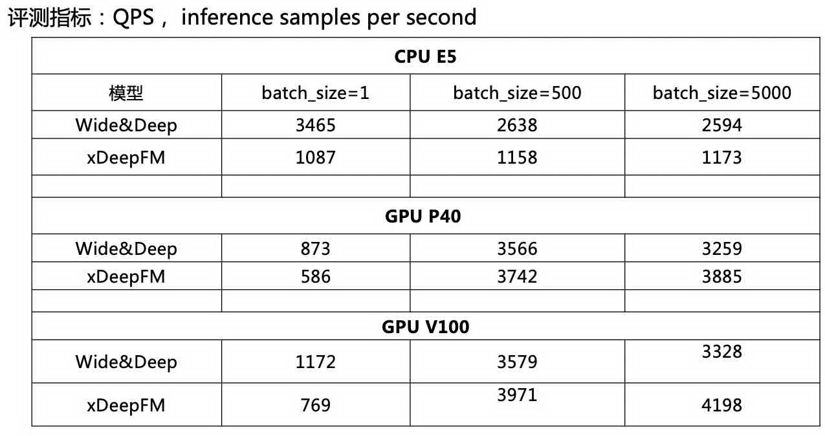
当使用和现有 baseline model 一样的 CPU 推理资源时,像 xDeepFM 这样的复杂深度模型无法上线。若使用 GPU 进行推理, ROI 并不高。与这两种情况相比,知识蒸馏[6]这一类模型压缩方法是解决这类问题的良药,可以将复杂模型的知识迁移到简单模型。
到这里总结出了下一代排序模型的优化方向:
1. 升级现有基准排序模型
去掉 GBDT;
探索最新的一些排序模型进展,提升排序模型性能;
2. 大规模稀疏特征的交叉
用模型显示建模不同高维稀疏特征的交叉;
vector-wise 交叉;
一个模型可以容纳各种特征交叉组件;
3. 高性能的复杂深度模型如何落地
低投入高产出:不高于现有资源投入,获得更好的线上效果;
模型压缩:复杂模型知识迁移到简单模型。
双 DNN 排序模型
通过实践,爱奇艺提出了一种新的排序模型框架: 双 DNN 排序模型,其核心在于提出了新的联合训练方法,从而解决了高性能复杂模型的上线问题,该框架的特点和优势总结如下
:1. 双 DNN
左侧 DNN:模型性能更好的复杂模型,推理性能差;
右侧 DNN:模型性能一般的简单模型,推理性能佳;
2. Fine-Tune
右侧 DNN 复用左侧 DNN 的 inputrepresentation layer;
3. 联合训练
复杂 DNN 监督指导简单 DNN 的学习;
KD on the fly, one stage;
训练稳定性,大网络性能天花板不受小网络影响。
排序模型结构如下:
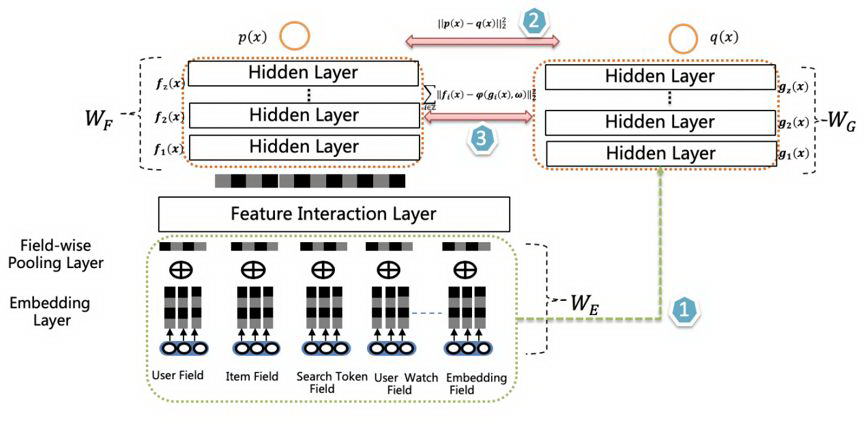
双 DNN 排序模型由两个 DNN CTR Model 组成,左侧是 Teacher,右侧是 Student,Student 模型是最终用于上线推理的 CTR 模型。两者共享特征输入和表示,但是左侧相比右侧多了 Feature Interaction Layer。左侧和右侧有各自独立的 MLP , 其包含多层 Hidden Layer。主要 Layer 的介绍如下:
Embedding Layer:输入表示层,不同特征按 Field 组织,稀疏 Field ID embedding 化后通过 average pooling 得到 field 的 embedding 表示;
Feature Interaction Layer:这是左侧模型核心,其可以容纳各种形式的特征组合组件,二阶或高阶特征组合都可以放置在其中;
Classifier Layer:两个 DNNCTR 模型的 Classifier,一般是多层 DNN。
双 DNN 排序模型的优势
双 DNN 的优势在于联合训练,通过联合训练迁移左侧复杂 DNN 知识到右侧简单 DNN,关键部分是以下 3 点:
1. Feature Transfer:正如模型结构图中的标注 1 所示,两个 DNN 共享特征表示层,相当于右侧 DNN 使用了 copy and freeze 的特征迁移范式;
2. KD One the Fly: 知识蒸馏(KnowledgeDistillation, KD)是两阶段训练,我们将其改为使用联合训练时进行知识迁移,训练时使用 teacher 的预测结果指导 student;
3. Classifier 迁移:仅有第二点还无法让右侧模型性能逼近左侧,因为右侧网络结构偏弱,无法直接学到左侧模型的输出, 于是让 teacher 的 hiddenlayer 作为监督信号指导 student 的 hiddenlayer。
双 DNN 排序模型训练架构
在端到端模型结构确定后,通过引入在线学习实现了模型的实时性。下图是双 DNN 排序模型的训练架构。
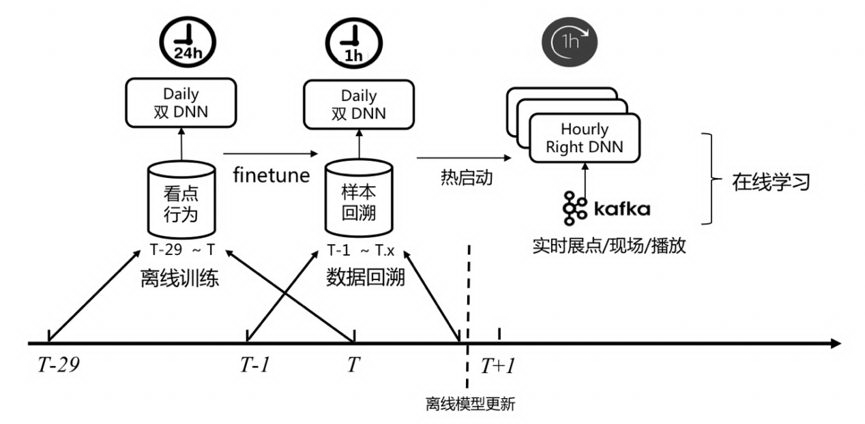
Finetune:每天例行使用 30 天窗口训练得到离线双 DNN 排序模型,训练完后再使用最新的样本 fine tune,使得模型能学到最新的用户行为 pattern。
在线学习热启动:正如之前在线学习实践[8]文章中所分享的,这里也是使用离线模型作为在线学习训练的热启动模型,这既能 oov 问题,也能防止在线学习长期运行带来的 bias。而这里的在线学习只使用实时数据更新双 DNN 的 Student 模型,因为真正用于推理的是 Student。
双 DNN 排序模型推理
如下图所示,依赖于公司提供的训练平台,双 DNN 模型的部署和推理实现了模型 Graph 和 Embedding 权重的解耦部署,其使得模型更新和部署超大模型变得更加方便,特别是在模型的大部分重要特征是大规模稀疏特征时。模型推理时,TF serving 通过定制化的 OP 访问存储 Embedding 矩阵的分布式 PS。
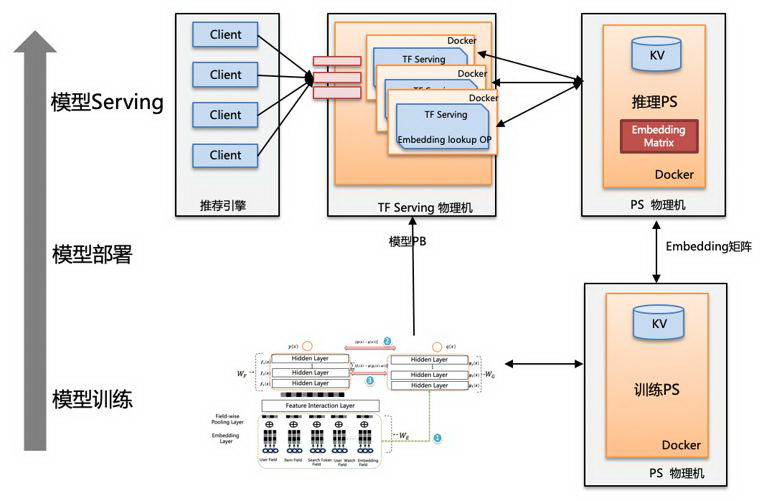
业界相关实践
百度
百度广告 CTR 模型的发展历程[9]如下:CTR-X 是一个用于粗排阶段的 DSSM, 其中 CTR 3.0 与我们的工作比较类似,也是用于精排阶段,但是训练两个结构差不多的 DNN 需要运用类似于特征迁移的方法,左侧 DNN 主要用来学习稀疏特征 embedding, 右侧 DNN 使用左侧训练得到的 embedding 和其他特征作为输入训练 CTR model。
阿里

阿里妈妈在 2018 年提出了 Rocket Launching 训练方法[10],将其用于广告算法模型压缩。该方法也是需要联合训练两个复杂度有明显差异的网络,其中简单的网络称为轻量网络(light net),复杂的网络称为助推器网络(booster net),两个网络共享表示层参数,方法和其核心区别在于如下两点:
Rocket Launching 只使用预测结果来指导简单模型的训练,我们的方法是让简单模型同时拟合预测结果和决策层的网络结构表示,两个网络的性能差距会进一步缩小;
Rocket Launching 联合训练时两个大小网络都会在反向传播时更新 EmbeddingLayer 参数, 我们的方法是让小网络直接 sharing, 不再更新,因为实验发现同时更新会拉低大网络性能。
实验部分
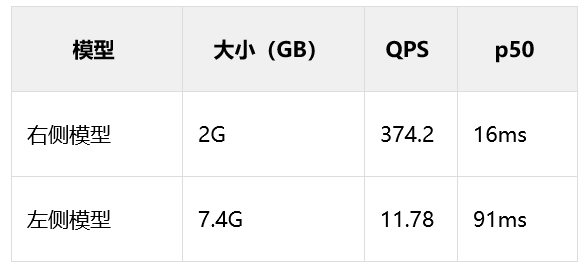
双 DNN 模型压测:在爱奇艺某个信息流推荐场景的测试数据来看,左侧模型是右侧模型推理时延的 5 倍左右, 模型大小压缩了超过 3 倍,右侧模型 QPS 也更高。因此同样资源情况下,使用右侧上线 ROI 更高。
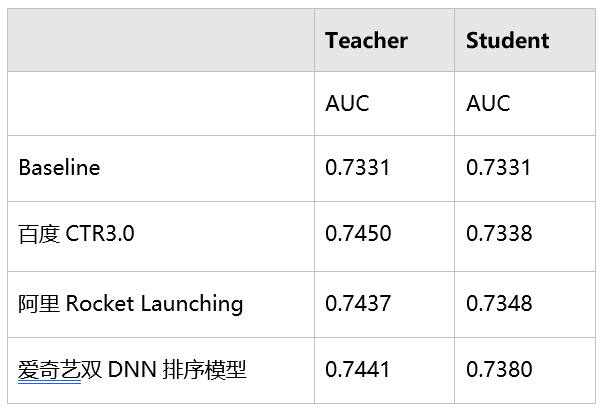
Co-Train 和两阶段训练(类似于百度 CTR3.0)效果对比:Co-Train 模式下右侧模型和左侧模型的差距缩小明显, student 的能力更接近 teacher。
总结
爱奇艺提出了一种新的在线知识蒸馏方法,不同于以往的知识蒸馏进行两阶段训练,而是进行联合训练,让 teacher 网络在训练过程中指导 student 网络的训练,与此同时做到不受 student 网络的影响。目前,双 DNN 排序模型的方法在短视频信息流和图文信息流场景实现落地,这也佐证了这一方法的优越性。未来会继续推动落地一些前沿的排序模型研究成果,让 teacher 网络变的更宽更深,进一步提升排序模型的精度。
参考文献
Lian, Jianxun &Zhou, Xiaohuan & Zhang, Fuzheng & Chen, Zhongxia & Xie, Xing &Sun, Guangzhong. (2018). xDeepFM: Combining Explicit and Implicit FeatureInteractions for Recommender Systems. 1754-1763. 10.1145/3219819.3220023.
Chen, Qiwei &Zhao, Huan & Li, Wei & Huang, Pipei & Ou, Wenwu. (2019). Behaviorsequence transformer for e-commerce recommendation in Alibaba. 1-4.10.1145/3326937.3341261.
Cheng, Heng-Tze &Koc, Levent & Harmsen, Jeremiah & Shaked, Tal & Chandra, Tushar& Aradhye, Hrishi & Anderson, Glen & Corrado, G.s & Chai, Wei& Ispir, Mustafa & Anil, Rohan & Haque, Zakaria & Hong, Lichan& Jain, Vihan & Liu, Xiaobing & Shah, Hemal. (2016). Wide &Deep Learning for Recommender Systems. 7-10. 10.1145/2988450.2988454.
Guo, Huifeng &Tang, Ruiming & Ye, Yunming & Li, Zhenguo & He, Xiuqiang &Dong, Zhenhua. (2018). DeepFM: An End-to-End Wide & Deep Learning Frameworkfor CTR Prediction.
Wang, Ruoxi & Fu,Bin & Fu, Gang & Wang, Mingliang. (2017). Deep & Cross Network forAd Click Predictions. 1-7.
Hinton, Geoffrey &Vinyals, Oriol & Dean, Jeff. (2015). Distilling the Knowledge in a NeuralNetwork.
爱奇艺个性化推荐排序实践.
在线学习在爱奇艺信息流推荐业务中的探索与实践。
AI 筑巢:机器学习在百度凤巢的深度应用。
Rocket Launching: AUniversal and Efficient Framework for Training Well-Performing Light Net GuoruiZhou, Ying Fan, Runpeng Cui, Weijie Bian, Xiaoqiang Zhu, Kun Gai
本文转载自公众号爱奇艺技术产品团队(ID:iQIYI-TP)。
原文链接:

Java 避坑指南:Java 高手笔记代码篇
本迷你书包括 86 个业务开发中常见踩坑点。每一个知识点都相当的实用,是程序员业务开发中的必备避坑指南...











评论