

引言
随着大数据技术架构的演进,存储与计算分离的架构能更好的满足用户对降低数据存储成本,按需调度计算资源的诉求,正在成为越来越多人的选择。相较 HDFS,数据存储在对象存储上可以节约存储成本,但与此同时,对象存储对海量文件的写性能也会差很多。
腾讯云弹性 MapReduce(EMR) 是腾讯云的一个云端托管的弹性开源泛 Hadoop 服务,支持 Spark、Hbase、Presto、Flink、Druid 等大数据框架。
近期,在支持一位 EMR 客户时,遇到典型的存储计算分离应用场景。客户使用了 EMR 中的 Spark 组件作为计算引擎,数据存储在对象存储上。在帮助客户技术调优过程中,发现了 Spark 在海量文件场景下写入性能比较低,影响了架构的整体性能表现。
在深入分析和优化后,我们最终将写入性能大幅提升,特别是将写入对象存储的性能提升了 10 倍以上,加速了业务处理,获得了客户好评。
本篇文章将介绍在存储计算分离架构中,腾讯云 EMR Spark 计算引擎如何提升在海量文件场景下的写性能,希望与大家一同交流。文章作者:钟德艮,腾讯后台开发工程师。
一、问题背景
Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎,可用来构建大型的、低延迟的数据分析应用程序。Spark 是 UC Berkeley AMP lab (加州大学伯克利分校的 AMP 实验室)所开源的类 Hadoop MapReduce 的通用并行框架,Spark 拥有 Hadoop MapReduce 所具有的优点。
与 Hadoop 不同,Spark 和 Scala 能够紧密集成,其中的 Scala 可以像操作本地集合对象一样轻松地操作分布式数据集。尽管创建 Spark 是为了支持分布式数据集上的迭代作业,但是实际上它是对 Hadoop 的补充,可以在 Hadoop 文件系统中并行运行,也可以运行在云存储之上。
在这次技术调优过程中,我们研究的计算引擎是 EMR 产品中的 Spark 组件,由于其优异的性能等优点,也成为越来越多的客户在大数据计算引擎的选择。
存储上,客户选择的是对象存储。在数据存储方面,对象存储拥有可靠,可扩展和更低成本等特性,相比 Hadoop 文件系统 HDFS,是更优的低成本存储方式。海量的温冷数据更适合放到对象存储上,以降低成本。
在 Hadoop 的生态中,原生的 HDFS 存储也是很多场景下必不可少的存储选择,所以我们也在下文加入了与 HDFS 的存储性能对比。
回到我们想解决的问题中来,先来看一组测试数据,基于 Spark-2.x 引擎,使用 SparkSQL 分别对 HDFS、对象存储写入 5000 文件,分别统计执行时长:
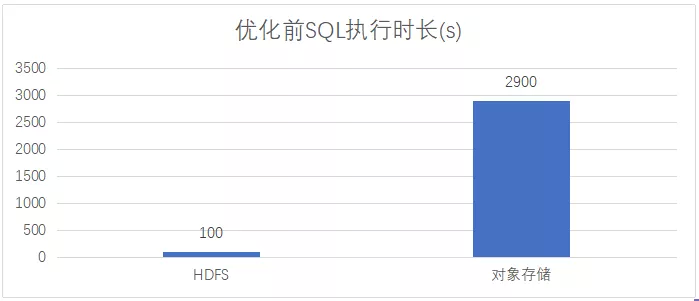
从测试结果可以看出,写入对象存储耗时是写入 HDFS 的 29 倍,写入对象存储的性能要比写入 HDFS 要差很多。而我们观察数据写入过程,发现网络 IO 并不是瓶颈,所以需要深入剖析一下计算引擎数据输出的具体过程。
二、Spark 数据输出过程剖析
1. Spark 数据流
先通过下图理解一下 Spark 作业执行过程中数据流转的主要过程:
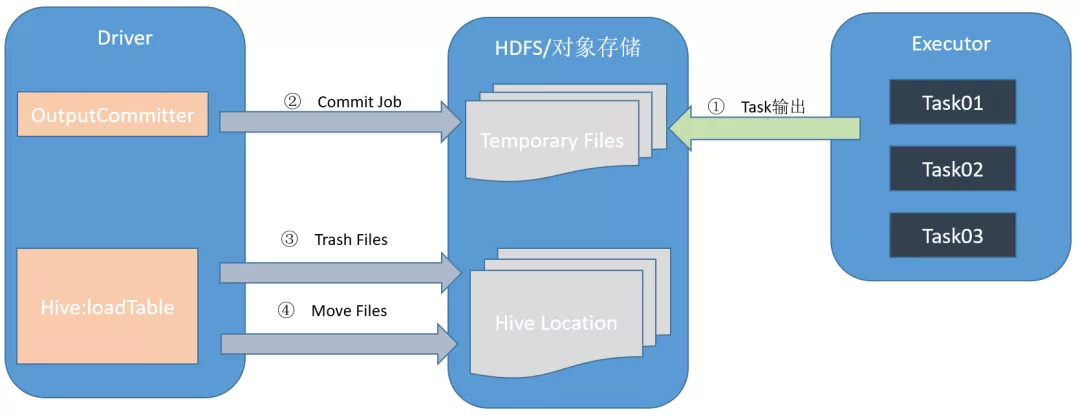
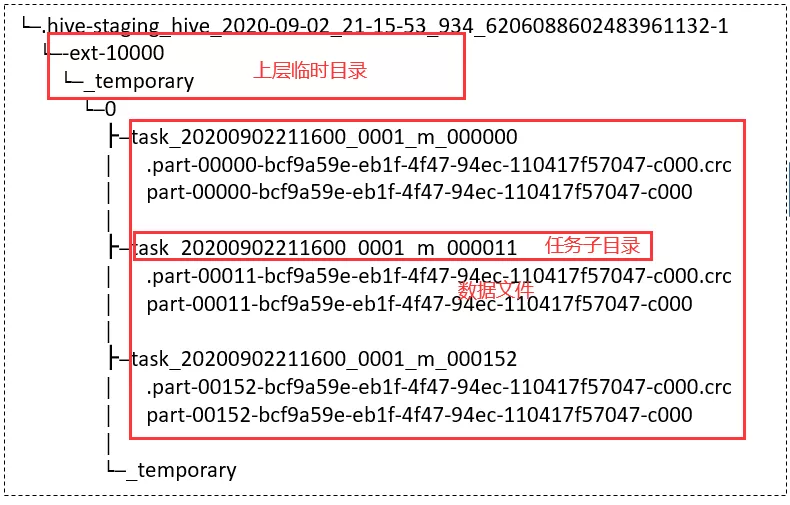
首先,每个 task 会将结果数据写入底层文件系统的临时目录 temporary/task[id],目录结果示意图如下所示:
到此为止,executor 上的 task 工作其实已经结束,接下来将交由 driver,将这些结果数据文件 move 到 hive 表最终所在的 location 目录下,共分三步操作:
第一步,调用 OutputCommiter 的 commitJob 方法做临时文件的转存和合并:

通过上面示意图可以看到,commitJob 会将 task_[id] 子目录下的所有数据文件 merge 到了上层目录 ext-10000。
接下来如果是 overwrite 覆盖写数据模式,会先将表或分区中已有的数据移动到 trash 回收站。
在完成上述操作后,会将第一步中合并好的数据文件,move 到 hive 表的 location,到此为止,所有数据操作完成。
2. 定位分析根因
有了上面对 Spark 数据流的分析,现在需要定位性能瓶颈在 driver 端还是 executor 端?观察作业在 executor 上的耗时:


发现作业在 executor 端执行时长差异不大,而总耗时却差异却非常大, 这说明作业主要耗时在 driver 端。
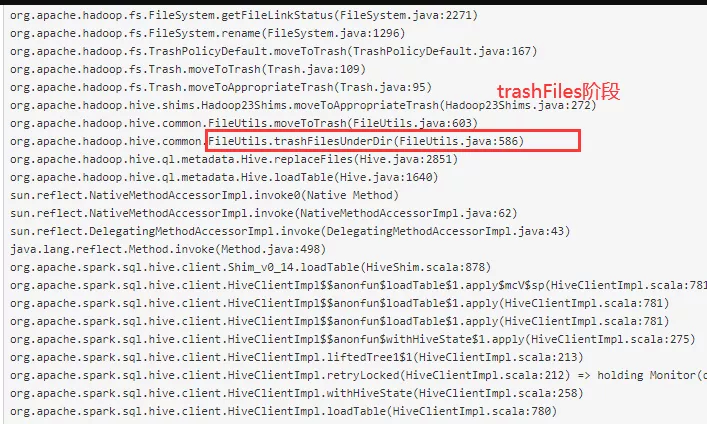
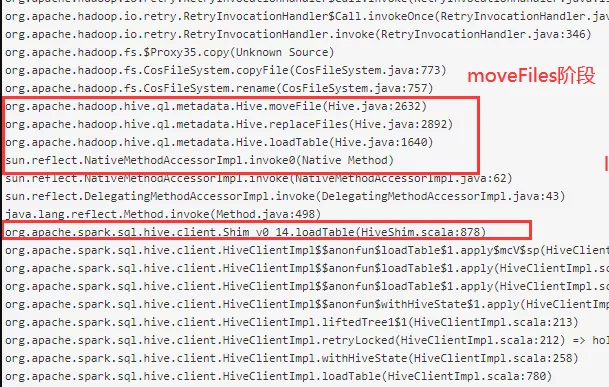
在 driver 端有 commitJob、trashFiles、moveFiles 三个操作阶段,具体是在 driver 的哪些阶段耗时比较长呢?
我们通过 spark-ui 观察 Thread dump (这里通过手动刷新 spark-ui 或者登录 driver 节点使用 jstack 命令查看线程堆栈信息),发现这三个阶段都比较慢, 下面我们来分析这三部分的源码。
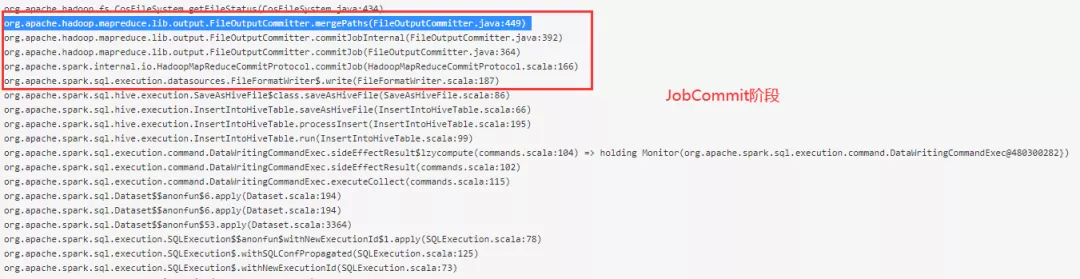
3. 源码分析
(1)JobCommit 阶段
Spark 使用的是 Hadoop 的 FileOutputCommitter 来处理文件合并操作, Hadoop 2.x 默认使用 mapreduce.fileoutputcommitter.algorithm.version=1,使用单线程 for 循环去遍历所有 task 子目录,然后做 merge path 操作,显然在输出文件很多情况下,这部分操作会非常耗时。
特别是对对象存储来说,rename 操作并不仅仅是修改元数据,还需要去 copy 数据到新文件。
(2)TrashFiles 阶段
trashFiles 操作是单线程 for 循环来将文件 move 到文件回收站,如果需要被覆盖写的数据比较多,这步操作会非常慢。
(3)MoveFiles 阶段
与前面问题类似,在 moveFiles 阶段也是采用了单线程 for 循环方式来 move 文件。
4. 问题小结
Spark 引擎写海量文件性能瓶颈在 Driver 端;
在 Driver 的 CommitJob、TrashFiles、MoveFiles 三个阶段执行耗时都比较长;
三个阶段耗时长的原因都是因为单线程循环挨个处理文件;
对象存储的 rename 性能需要拷贝数据,性能较差,导致写海量文件时耗时特别长。
三、优化结果
可以看到社区版本大数据计算引擎在处理对象存储的访问上还在一定的性能问题,主要原因是大多数数据平台都是基于 HDFS 存储,而 HDFS 对文件的 rename 只需要在 namenode 上修改元数据,这个操作是非常快的,不容易碰到性能瓶颈。
而目前数据上云、存算分离是企业降低成本的重要考量,所以我们分别尝试将 commitJob、trashFiles、moveFile 代码修改成多线程并行处理文件,提升对文件写操作性能。
基于同样的基准测试,使用 SparkSQL 分别对 HDFS、对象存储写入 5000 个文件,我们得到了优化后的结果如下图所示:
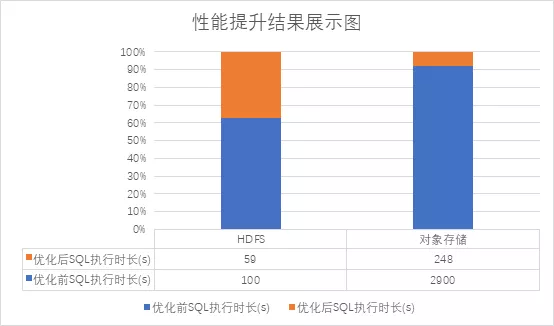
最终写 HDFS 性能提升 41% ,写对象存储性能提升 1100% !
四、结语
从上述的分析过程看到,问题的关键是 Spark 引擎某些处理部分的单线程限制造成的。单线程限制其实是比较常见的技术瓶颈。虽然我们在一开始也有猜测这种可能性,但具体限制在哪一部分还需要理清思路,踏实的查看源代码和多次调试。
另外分析中也发现了对象存储自身的限制,其 rename 性能需要拷贝数据,导致写海量文件耗时长,我们也还在持续进行改进。
对存储计算分离应用场景深入优化,提升性能,更好的满足客户对存储计算分离场景下降本增效的需求,是我们腾讯云弹性 MapReduce(EMR) 产品研发团队近期的重要目标,欢迎大家一起交流探讨相关问题。
本文转载自公众号云加社区(ID:QcloudCommunity)。
原文链接:
存算分离下写性能提升10倍以上,EMR Spark引擎是如何做到的?

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论