

推荐系统在今天互联网产品和应用中起着举足轻重的地位。一般的推荐系统是基于云端计算中心到边缘 ( 比如手机、平板电脑等 ) 的结构,这其中会由于网络带宽和延迟等导致结果的延迟。边缘的实时计算可以利用用户的实时信息提供更好的推荐。本次分享题目为 “EdgeRec:边缘计算在推荐系统中的应用”。主要内容包括:
边缘计算背景介绍
端上重排系统
端上混排系统
端上训练与千人千模
边缘计算背景介绍
1. 边缘计算 v.s. 云计算
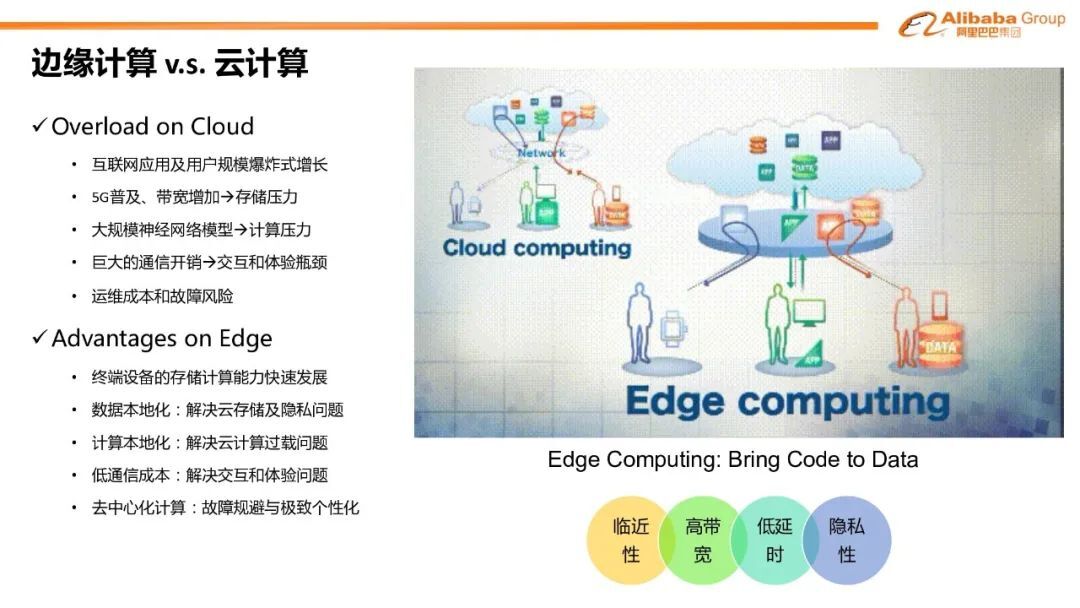
在目前云计算时代,互联网应用和用户的规模呈现爆炸式的增长;同时 5G 的普及和带宽的增加给对云端的整个系统带来了存储的压力;搜索推荐广告的大规模神经网络模型的应用对云端系统造成极大的计算负载压力; 云计算的集中式的计算模式,也增加了运维成本和故障的风险。
边缘计算,对比与传统的云计算,有着以下的优势。首先,目前用户手机等终端设备的计算和存储能力发展迅速;另一方面,数据的本地化可以缓解云存储的压力,同时也增强了数据的隐私;计算的本地化可以缓解云计算过载问题;边缘计算也降低了通信成本,可以增强用户的交互和体验;去中心化也可以规避中心化的故障。总结起来边缘计算的优点就是:稳定性,高带宽,低延时,隐私性。
2. 重新思考工业界信息流推荐?

我们以一个典型的工业界推荐场景为例来回顾一下推荐系统的流程以及信息流推荐和传统搜索引擎推荐的差别。推荐系统是把经过排序的最贴近用户兴趣的推荐列表展示给用户。信息流推荐是一个人机交互系统,其目标是整体收益的最大化。这与传统搜索引擎的目标,比如相关性,有着一定的区别。目前的推荐系统并没有同信息流推荐的场景成长起来,而更多的是借鉴于搜索和广告的技术,比如点击率(CTR)预估等。
3. 推荐系统新架构
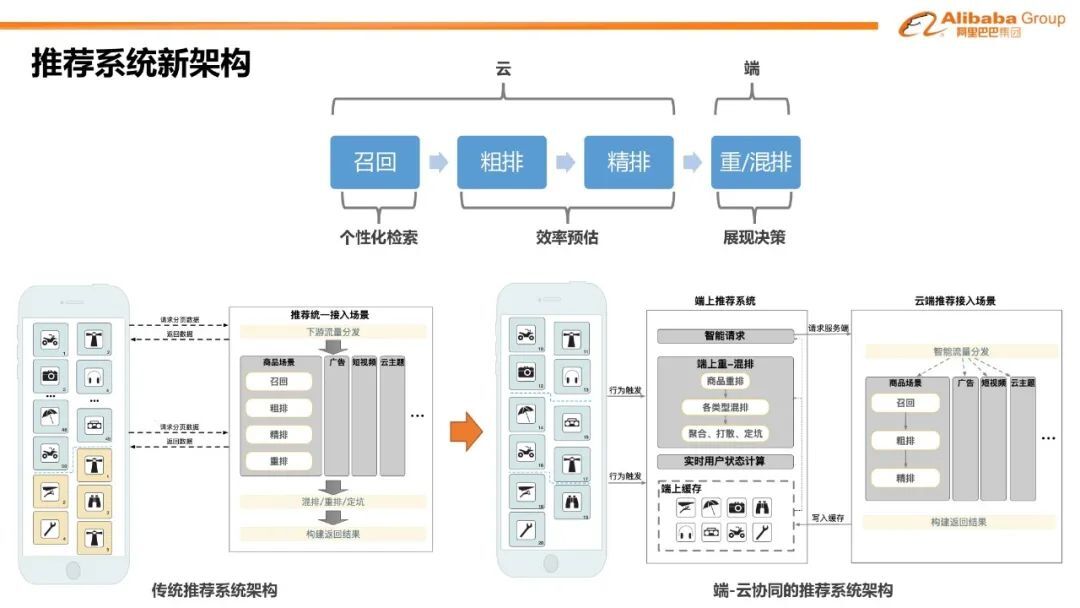
当前工业界主流的推荐系统一般是分层架构。当用户在浏览信息流推荐商品时,客户端通过分页请求机制发起个性化的检索请求;运行在云端的推荐系统经过召回,粗排,精排,重排或者混排五个阶段,将需要展示的结果返回给客户端。如果按照定位来分层,整个推荐体系可以分为个性化检索,效率预估(粗排和精排)和展现决策(重排和混排)等阶段。其中对于效率预估任务,比如点击率(CTR), 转化率(CVR)等展现决策的定位在于如何决策给用户最终的展现列表。信息流推荐的问题在工程系统和算法模型上都面临着严峻的考验。由于其人机交互性,复杂的上下文环境,强调整体的收益等,信息流推荐要求模型在策略复杂度大幅度提升的同时,兼顾系统的实时性与灵活性。
得力于边缘计算的特点与优势,我们将整个展现决策系统放在离用户交互最近的设备上,并且重新定义了整个信息流推荐的新的体系架构。
端上重排
1. 业务问题-推荐系统输入/反馈实效
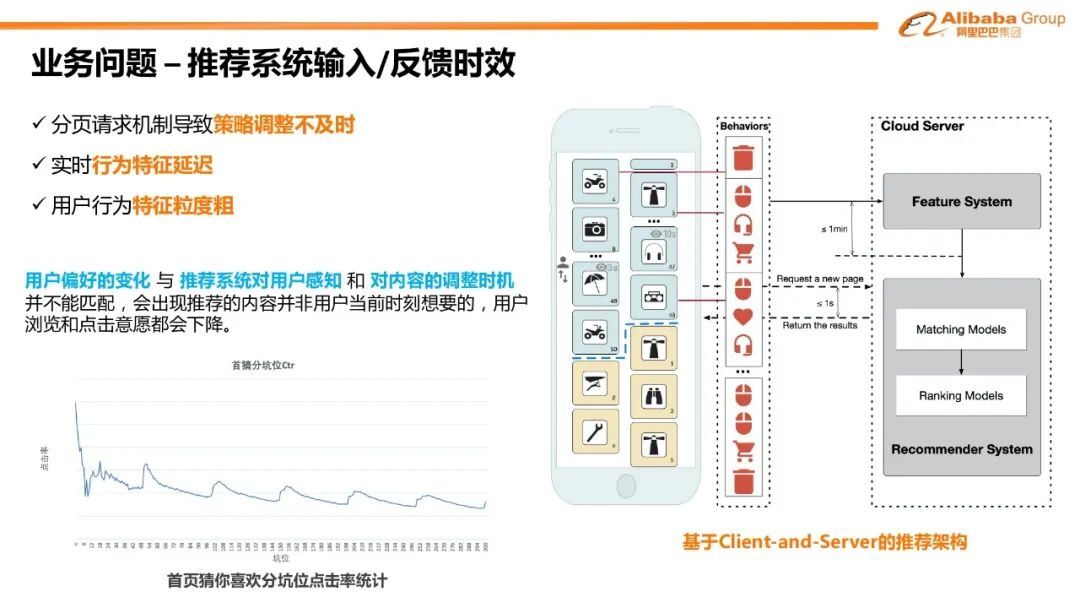
目前已有的整个信息流采用了 Client-and-Server 的推荐架构。这种架构有诸多缺点。首先由于整个系统的每秒查询数(QPS)的限制,人们一般会采用分页请求机制。分页请求会导致策略调整的不及时。比如如果分页请求是 20 页,在分页之前,用户的任何行为都无法对整个推荐结果生产生任何影响。其次推荐模型的个性化强依赖于用户的行为特征, 但目前云端获取用户行为的延迟在秒级甚至分钟级,很多用户细粒度的行为都无法被建模到。最后用户偏好的变化与推荐系统对用户的感知和对内容调整时机并不能产生匹配。这会导致推荐的内容并非用户当前时刻想要看到的,这会导致用户的浏览和点击意愿的下降。
通过“首页猜你喜欢”场景的分坑位点击率统计可以看到一个波峰到波谷的现象,这反映了由于分页请求机制导致的兴趣无法实时匹配问题。
2. 端上实时用户感知

为了解决用户行为延迟和细粒度和粒度粗的问题,我们提出了端上实时用户感知的框架,同时从个性化、正反馈、负反馈、交互动作和实时性这五个方面进行了思考。
首先用户行为数据对于个性化意义重大。比如各种 Deep Interest Evolution Network (DIEN),Deep Interest Network(DIN)等工作。我们之前的工作一般只考虑用户和商品的“正反馈”交互(如点击、成交),而很少考虑到“负反馈”交互(如曝光)。实际上实时的“负反馈”交互非常重要,比如商品多次曝光后点击率会呈明显的下降趋势。同时我们需要考虑用户与商品的交互动作,比如点击后在详情页的行为能反映对商品真正的偏好,也有可能是存在伪点击。个性化的“实时行为”相对于“长期行为”对信息流推荐场景同样重要。
但是如何对用户端上的用户行为进行建模面临着以下两个难点。首先是如何对用户行为的异构性进行序列建模;其次是如何优化端上序列模型推理的性能。

上图是我们在端上建设的用户实时行为的特征体系,其中包含了 20 多种细粒度用户行为动作特征。这其中分为两类:第一类是用户在商品的上的曝光行为动作特征,比如曝光时长、滚动速度等;第二类是用户在点击商品后详情页的行为动作特征,比如各区块是否点击、详贴页的停留时长等。
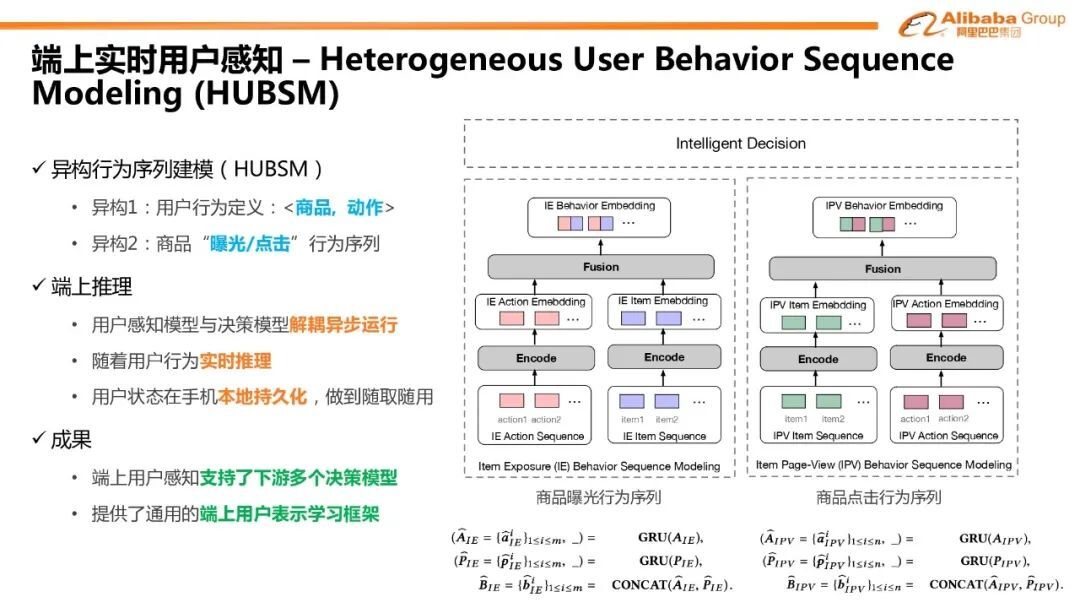
在异构行为的序列建模中,用户行为被定义成<商品,动作>的 2 元组。我们同时建模了商品曝光和点击两类行为特征。对于模型的设计,这里重点提两点,第一是我们把商品曝光行为序列和商品点击行为序列先分别单独进行建模。这是因为点击行为一般比较稀疏,而曝光行为非常多。如果先融合成一条行为序列再进行建模,很有可能模型会被曝光行为所主导。第二是,我们事先分别对商品特征和动作特征 encode 然后再进行 fusion。这里主要考虑商品特征和行为动作特征属于异构输入。如果下游任务需要对商品特征进行 attention,只有对同构的输入才有意义。在端上推理过程中,我们做了三方面的优化来保证序列模型的运行效果。首先是用户感知模型与决策模型解耦异步运行;同时随着用户的行为进行实时推理;并且将得到的用户状态在手机本地进行持久化,做到随取随用。在这样的框架下,端上用户感知支持了下游多个决策模型,并且提供了端上通用的端上用户学习框架。
3. 端上重排-Context-aware Reranking with Behavior Attention Networks (CRBAN)
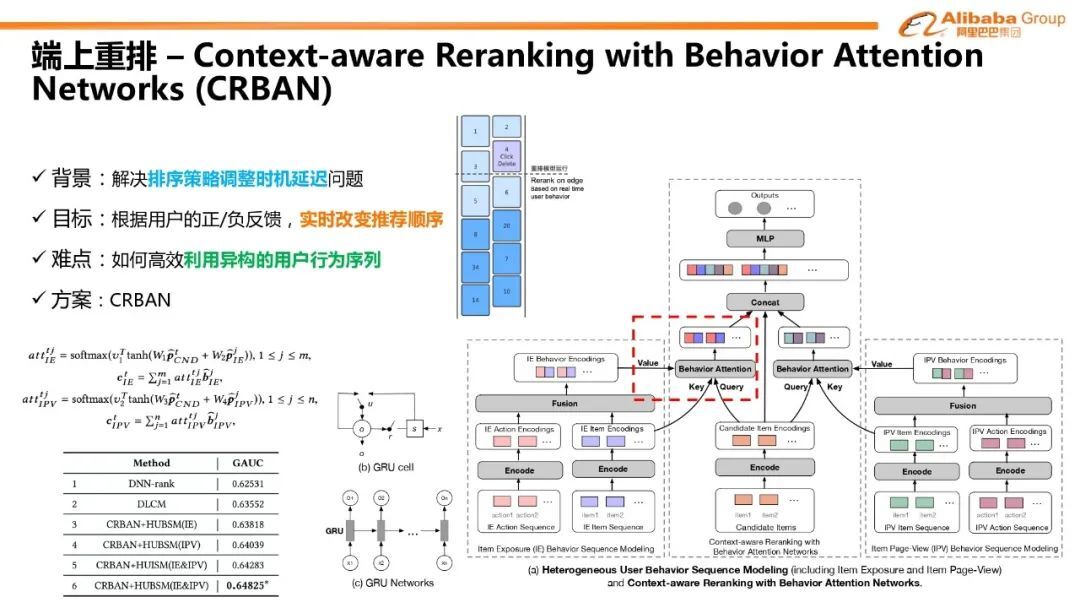
为了解决排序策略调整实际延迟的问题,我们提出了以下端上重排方案。其目标是根据用户的正负反馈来实时改变信息流的推荐顺序。其难点在于如何高效的利用异构用户行为序列进行建模。因此我们提出了 Context-aware Reranking with Behavior Attention Networks (CRBAN)模型,其特点是在重排模型的框架下引入了用户实时行为上下文。相比于 DNN 一类的模型,我们除了考虑用户交互商品的特征,也会考虑用户交互商品的行为动作特征。基于前文介绍的异构行为序列建模,我们可以看到在重排任务中,attention 的 query 和 key 分别是待排序商品和行为序列商品,而 value 是行为商品和行为动作 fusion 之后的结果。其动机可以解释为对待排序商品集合中的某一个商品,模型先学习用户交互过的商品的特性,然后重点关注相关的商品。与此同时我们再观察用户在这些商品上的具体的动作表现是什么,比如曝光时长、经验的行为等。我们把以上特征综合起来一起作为待排序商品的打分参考。在整个控制变量的离线实验中表明我们提出的不同组件非常有效。
4. 端上重排-系统设计
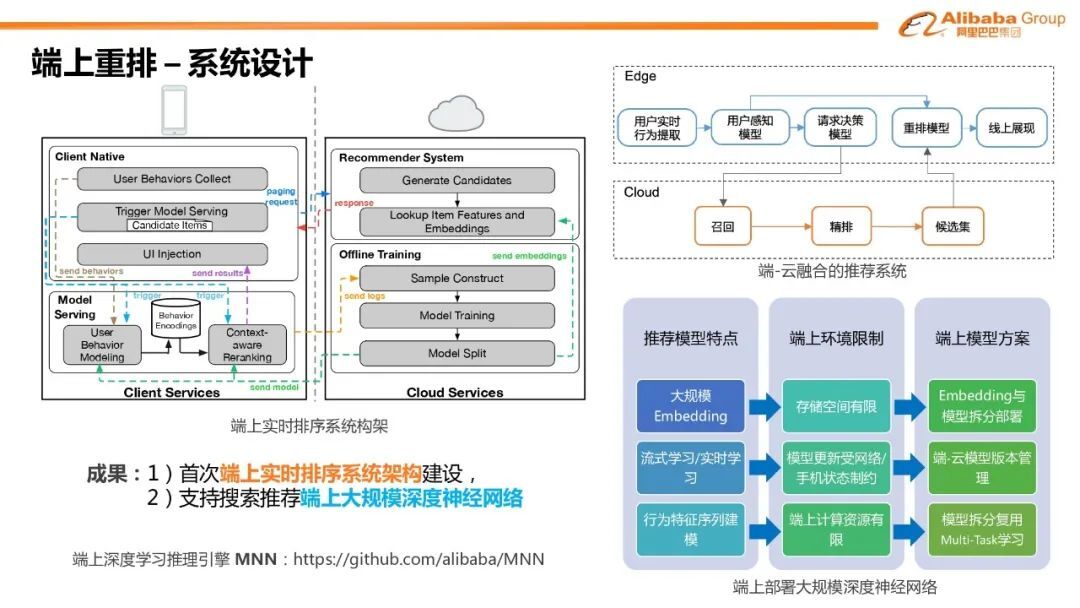
除了算法模型创新优化,我们也首次提出并建设了端上的实时排序系统架构。该系统融合了端和云的各自优势,并且并不影响对目前已有云端的推荐链路——支持端上推荐系统的热插拔。另一方面面对搜索推荐深度学习模型的特点和端上环境的限制,我们构造了一套端上支持部署大规模神经网络的解决方案。尤其值得着重提出的是,推荐模型一般会达到几百 GB 甚至 TB 的大小。如此大的模型存储量目前不可能部署到用户的手机端。实际上商品的 embedding 矩阵,比如商品 ID,占了整个模型存储的大部分。但排序的候选商品相对稀疏。因此我们提出了将模型中的 embedding 矩阵重新拆分部署到云端,并通过云端返回相应的商品带回到端上,然后再在端上通过模型重新组织图关系来进行 inference 打分。我们目前用 MNN 作为目前整个端上的深度学习推进引擎。
5. 端上重排-业务效果
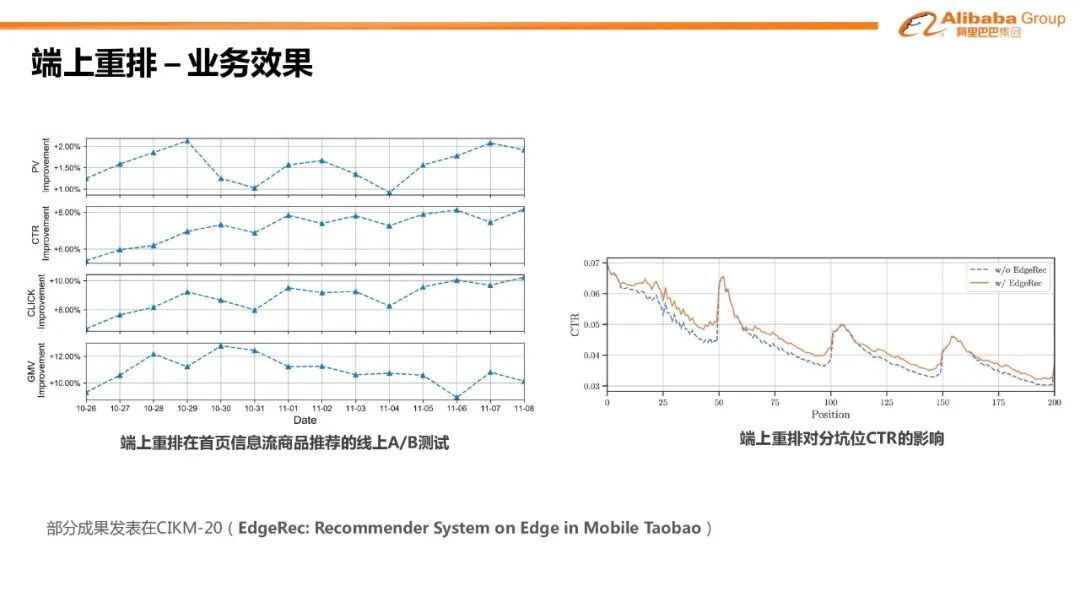
上图左部分显示了端上重排取得了显著的业务效果提升;右部分显示的端上重排对首页信息流分坑位 CTR 的影响。我们可以看到端上重排一定程度上缓解了由于分页请求带来的效果衰减。部分成果及技术细节发表在 CIKM-2020。
6. 端上重排 2.0-生成式排序
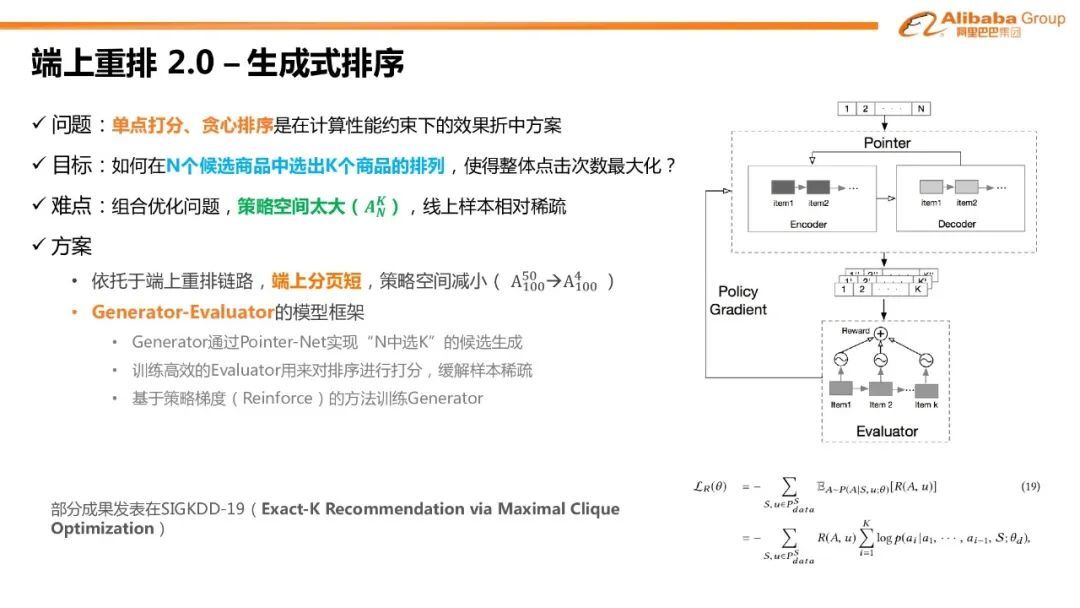
重排任务本质上是希望在整个推荐体系多轮排序的最后一轮能够找到最好的商品的排序结果给用户进行展示。但是目前无论是从粗排,精排,还是 learning-to-rank 等重排模型,都依赖于单点打分,贪心排序。它们都只是在整个计算性能约束下的效果折中方案。而我们实际上想要达到的目标是如何在 N 个候选商品中找出 K 个商品的排列,使得整体的点击次数最大化。这是一个组合优化问题,其难点在于整个策略空间非常大(A_N^K)。比如如果从 100 个商品里面选 50 个,那么策略空间就是(A_150^100)的排列数。策略空间大会带来线上样本稀疏的问题。目前基于监督学习的方法只能做到在有限的监督样本里探索有限的自由排序。我们的方案是依托于端上重排的链路。由于端上的触发时机非常实时,端上分页策略会非常短,整个策略空间就会小很多,比如从 A_100^50 降到 A_100^40;另一方面端上不需要和云端交互,同时不需要依赖云端负载的计算,由于都是本地打分,对复杂模型的支持会更好。
同时在模型上我们提出了 Generator-Evaluator 的模型架构。Generator 通过 Pointer-Net 实现“N 中选 K”的候选生成,同时训练 Evaluator 用来对排序进行打分,最后通过 Policy Gradient 的梯度策略方法来训练整个 Evaluator。我们提出这种生成式重排相比于线上贪心排序的提升效果非常显著。部分技术细节发表在 SIGKDD-2019。
7. 端上重排 2.0-序列检索系统
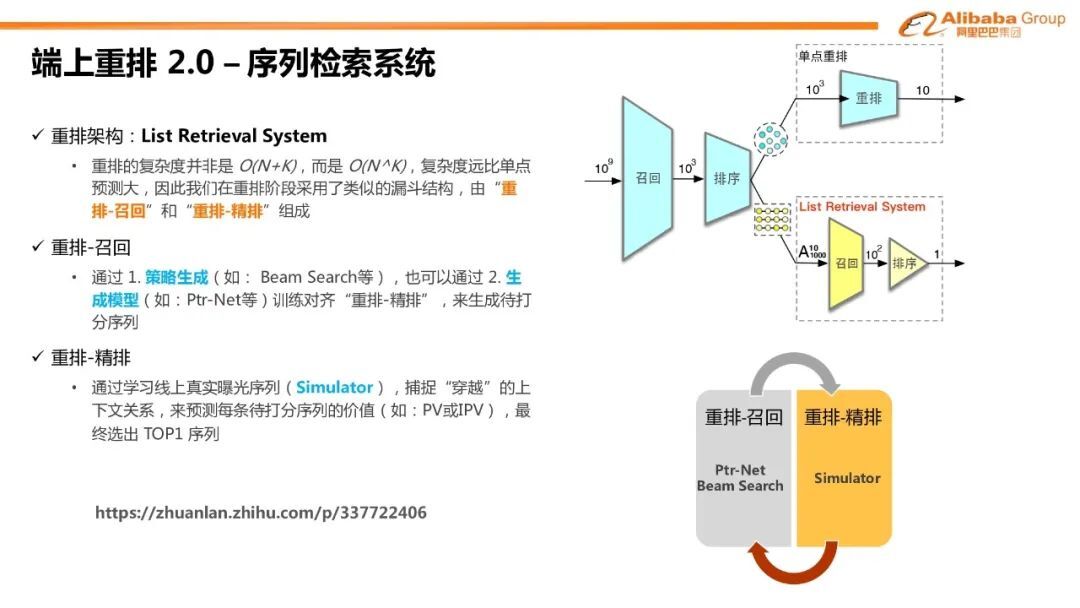
在实践重排的过程中,我们可以将整个重排架构统一成序列检索系统。重排复杂度是指数的,比其他单点预测,比如精排,要大很多。因此我们将重排任务采用了类似漏斗的结构:分别由“重排-召回”和“重排-精排”组成。在重排-召回阶段,我们通过策略生成,比如 Beam Search 的策略,来生成候选序列,也可以使用上面提到的生成模型,如 Ptr-Net,来训练对齐重排-精排。通过这两种方式都可以来生成代打分序列。重排-精排可以通过监督任务来学习线上真实的曝光序列,我们称其为推荐系统的 Simulator。Simulator 可以完整的拿到整个曝光上下文的“穿越”信息。通过 Simulator 也可以预测每条待打分序列的价值,比如 PV 或者 IPV,最后选出 TOP1 的序列。
重排的架构非常类似于召回和精排的关系:召回可以给精排提供候选集,同时精排也可以通过类似于蒸馏的方法来训练整个召回网络。
此策略也对我们的整个场景带来了显著的业务效果提升。
端上混排系统
1. 信息流中的多元异构内容

这里介绍我们在端上混排的工作。目前信息流已经成为业界推荐产品的主流形式。上图展现了在手淘首页信息流、手淘搜索和美团首页信息流的形式。我们可以发现信息流推荐并不只是单一内容的聚合,而是集合非常多的多元异构形式来对用户进行展示。比如在首页信息流里,我们会插入短视频、内容、广告等多元内容。因此信息流推荐里混排相比于重排已经成为业务中不可缺少的模块。
2. 业务问题-推荐系统上下文环境
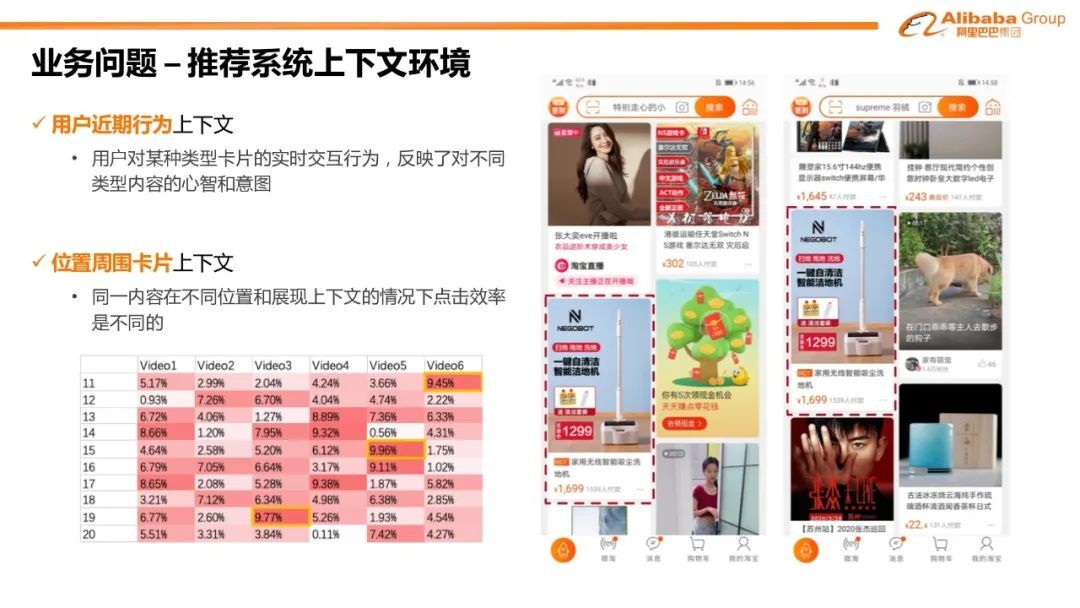
信息流推荐是人机交互的系统,并有各种无法忽略的上下文环境。在信息流推荐里,上下文主要包含以下两个方面:首先是用户近期行为的上下文,它反映了用户对某种类型卡片的实时交互行为及用户对不同类型内容的意图;其次位置周围卡片的上下文。同样的内容在不同的位置和展现上下文下的情况下点击效率是不同的。比如上图中红框标志的同样的广告卡片,左边卡片周围是包含直播视频活动等各种异构卡片,中间第二个卡片周围大部分主要是正常的商品。我们可以预见到两个相同卡片的点击率是不同的。周围的信息会对卡片的点击率造成很大的影响。
3. 端上混排架构
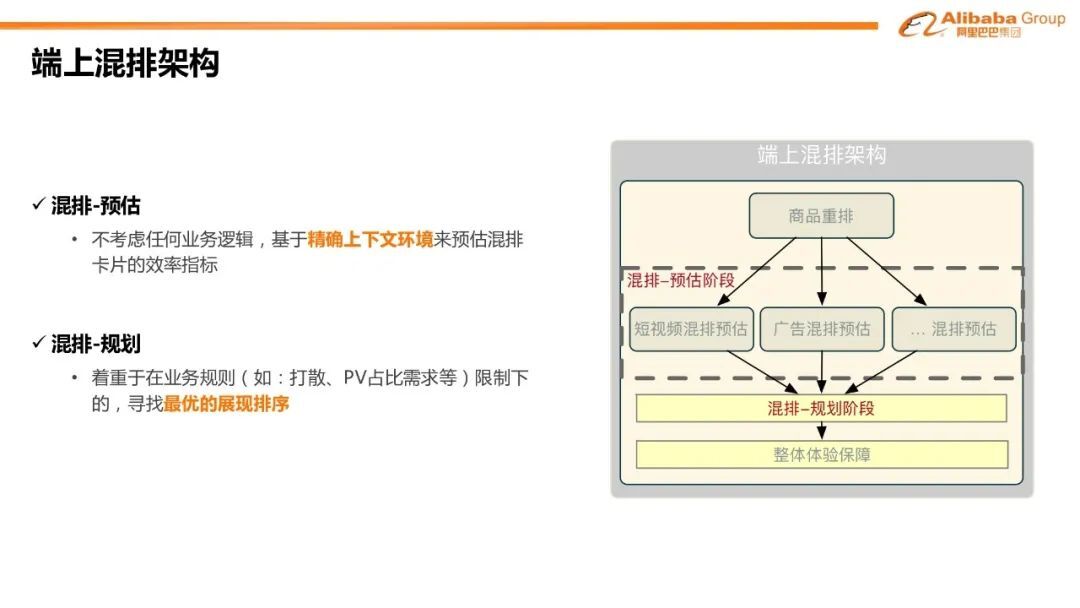
每次展现决策都需要尽量的贴近符合用户最近的意图。这对重排和混排都是一样的。我们首次提出了端上混排架构。该架构包含了两个阶段:首先是混排-预估阶段,其重点在于不考虑任何组合的业务逻辑,基于精确的上下文来预估混排卡片的效率指标;其次是混排-规划阶段,其着重于在业务规则限制下,比如同种类型卡片的打散规则,卡片的曝光占比等需求的限制下,寻找最优的展现排序。
4. 端上动态混排算法
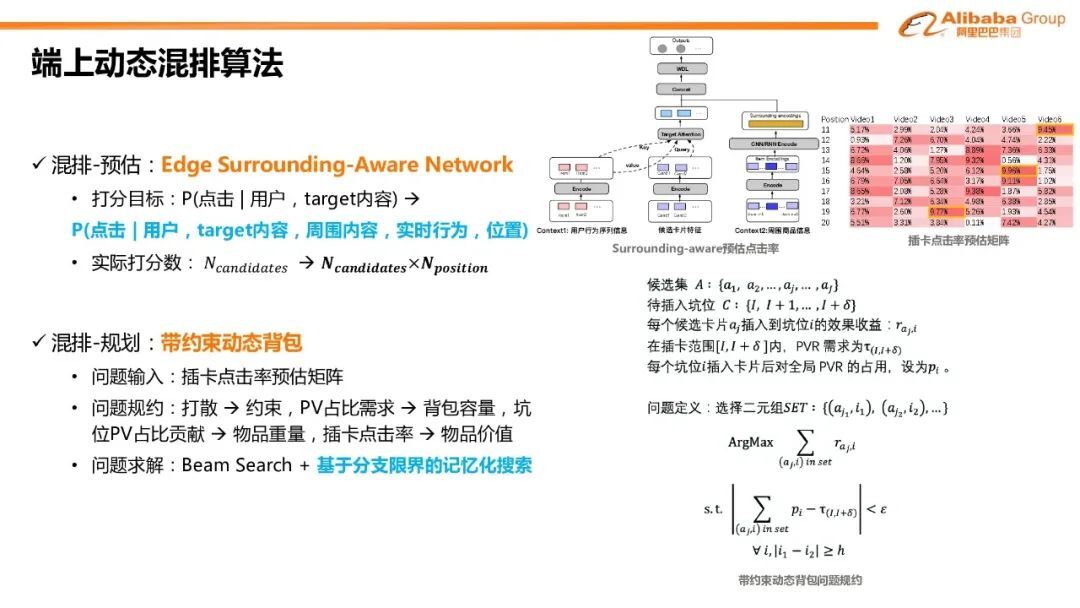
在混排预-估阶段,我们提出 Edge Surrounding-Aware Network(ESAN)模型。该模型重点建模了位置周围的内容和用户实时行为这两种上下文来预估 target 内容的点击率。
整个模型引入了端上的用户行为序列信息和周围商品的信息作为待插入内容的上下文特征。因此整个模型的实际打分数变成了候选的混排内容数与待插入位置数的乘积。这样的打分数,相比于待排序内容的 candidates 数量会成倍增加,这会对整个打的压力造成一定的影响。因此我们把打分放到了用户的手机端上。ESAN 的模型会输出插卡点击率的预估矩阵。在混排规划阶段,我们需要重点关注两个业务规则。首先是 PV 占比业务规则,它需要定量控制各业务卡片在整个信息流的曝光比例。第二是打散:为了保持用户的体验,同种的业务卡片在信息流的坑位需要有一定的间隔。因此混排规划的问题是在满足上面两个约束的情况下,如何规划混排卡片的插入坑位,使整体的混排效率预估最大化。我们把这个问题归约成带约束动态背包的问题,其中问题的输入是 ESAN 输出的插卡点击率矩阵,在问题的规约上,我们把打散作为约束;PV 占比的需求,可以看作是背包容量;坑位的 PV 贡献占比,可以看作是物品的重量;每个位置的插卡点击率,可以看作是物品的价值。这是一个整数规划问题,问题的解空间是指数级的。在线上我们采用 beam search 和基于分支限界的记忆化搜索的方法来进行求解。在信息流短视频的混排效果上,CTR 有 7%的显著提升。
端上训练与千人千模
1. 业务问题-千人一模与数据隐私
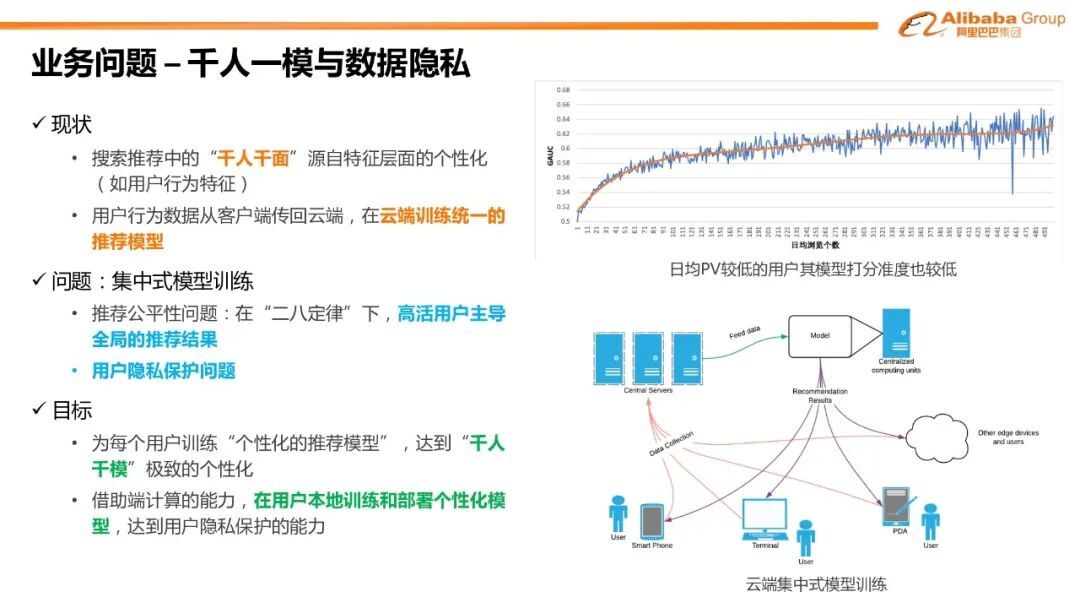
下面介绍我们在端向训练和千人千模的探索工作。首先目前搜索推荐中的个性化和千人千面,都还只是特征层面的个性化,比如我们都会普遍使用的用户历史行为特征,而模型都是统一的模型;用户的各种行为数据都是从客户端传给服务端,并在云端训练统一的推荐模型。这是集中式模型训练的方式。第一个问题是推荐公平性的问题,在二八定律下,20%的高度用户贡献了 80%的样本,因此高活用户会主导全局的推荐结果。上面曲线图显示日均 PV 较低用户的样本量比较少因而其模型打分准度也比较低。同时集中式训练也会有数据隐私的问题。我们的目标是尝试为每个用户训练单独的个性化的推荐模型,以此来真正做到“千人千模”极致的个性化。但以目前首页信息流约 1.2 亿日活,“千人千模”这种模式在云端训练和存储并不现实。因此我们希望借助端计算的能力,在用户的手机本地来训练和部署整个性化的模型,同时这也能达到一定的用户隐私的保护。
2. 千人千模-端上训练
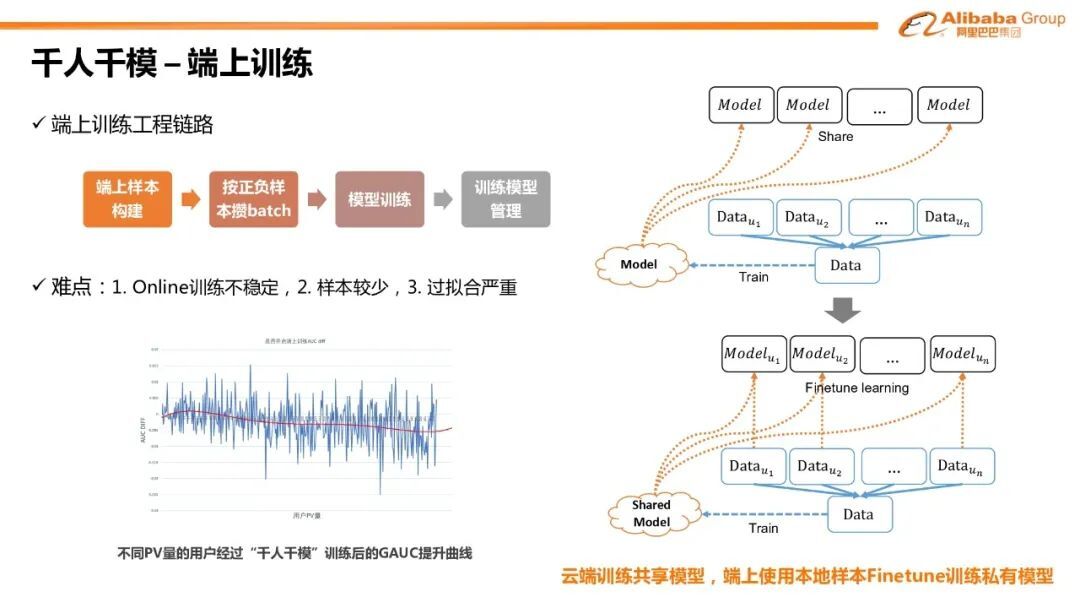
我们首先采用了云端训练共享模型,使用用户本地样本端上训练私有模型的模式实现千人千模。在这个过程中,我们搭建了端上训练的工程链路,包括端上的用户样本构建,batch 策略模型训练和模型管理总组件。目前端上训练已上线并取得了一定的效果提升。但同时也面临着需要持续优化的一些难点:第一是 online 训练不稳定;第二因为训练到用户个人的样本非常稀疏,也会导致模型训练的过拟合非常严重。从不同批量的用户经过千人千模训练的 GAUC 提升的曲线可以看到千人千模训练对低活用户(PV 量比较少的用户)有明显的正向效果。但是由于 online 训练问题也会对高活的用户损失比较大。这驱动我们重点优化端上训练的稳定。
3. 千人千模-Meta-Learning
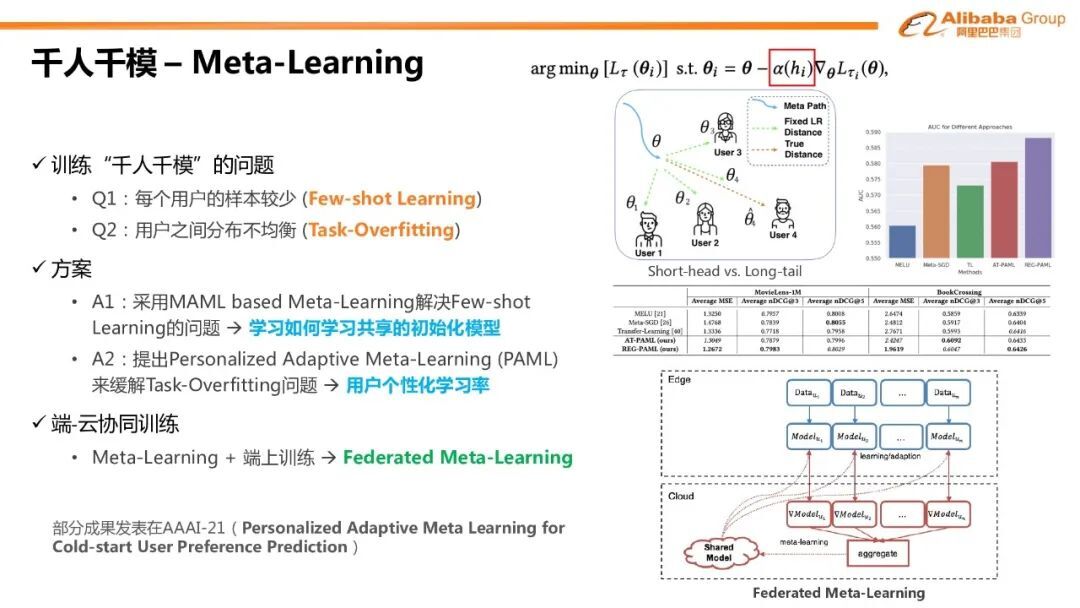
在训练千人千模的过程中,我们在云端会训练一个共享模。对与千人千模训练,每个用户的样本非常少。因此我们采用了基于 MAML 的 Meta-Learning 的方法来学习如何训练这种共享的初始化模型,使得每个用户在端上 fine-tune 了有限的个性化样本后,也能达到很好的收敛。上图右边显示我们把每个用户看成是 few-shot learning 中的 task。但是应用传统的 MAML 的模型也有一定的问题。在推荐的数据中,用户之间的分布极不均衡,会存在大量的长尾用户。在应用原始的 MAML 方法时会出现 task-overfitting 的问题。比如如果有四个用户,其中三个是年年轻人,一个是老年人,可以认为年轻人的数据分布较为相似,而且会占样本的多数,我们称为 short-head,而老年人相反,我们称为 long-tail。MAML 的模型会倾向于学到如何适应这三个年轻人的分布,就能达到很好的效果。基于这个问题,我们提出了 PAML 的方法,直观来讲,就是学习每个用户对应的学习率。比如对于 long-tail 的用户,可以采用较大的学习率来有助于 meta model 更多的关注该任务的梯度方向。该工作也发表在 AAAI-2021。
今天的分享就到这里,谢谢大家。
嘉宾介绍:
龚禹 ( 花名:凛至 ),阿里巴巴算法专家,2017 年硕士毕业于上海交通大学。曾在 SIGIR、KDD、AAAI 等发表多篇论文,其中 IRGAN 曾获 SIGIR2017 最佳论文提名。研究方向包括了推荐系统与自然语言处理等,目前专注于边缘计算与推荐系统的结合,主导的 EdgeRec 系统已经在手淘推荐场景大规模落地。
本文转载自:DataFunTalk(ID:dataFunTalk)

中国开发者画像洞察研究报告 2024
分析开发者的行为模式、工作价值、职业发展等内容,帮助整个行业生态更深入地理解开发者,为他们提供更精准...













评论