
引言
在 AI 项目中使用 Docker 镜像有两个重要的原因:它能够正常运行,忠实地执行你的模型;并且可以精心打造,这意味着它体积轻巧、构建迅速且部署高效。这两个原因看起来似乎并是不相关,就像一个强大的引擎和一个流线型的底盘。然而,我不这么认为。我认为一个精心打造的镜像更有可能在软件工程和 AI 的严苛世界中可靠地运行并优雅地扩展。
本文的目标是将我们的 Docker 镜像从不透明、出奇庞大的黑盒转变为更精简的形式。为什么要费此周折?因为在 AI 领域,迭代速度至关重要,云服务费也高得惊人,一个 5GB 的镜像如果构建和部署需要很长时间,带来的不只是不便,更是对进展的拖累以及部署成本的增加。
在优化之前,我们必须先诊断。我们需要成为 Docker 镜像的侦探,仔细审视镜像的每一个角落,了解这些数字容器是如何构建的,一层一层地剖析,精准定位到底哪里存在臃肿、低效和无用的数字垃圾。
为何要优化 AI Docker 镜像?
人类是工具的创造者;Docker 是用于打包和部署我们 AI 成果的出色工具。但和任何工具一样,其效果取决于我们如何使用它。在 AI 工作流程中使用未优化的 Docker 镜像可能会导致诸多问题。
更慢的开发周期
我们相对简单的双向编码器表示来自 Transformer(BERT)分类器的简单演示镜像,我们将在下面进行详细剖析,其大小为 2.54GB,在现代机器上构建大约需要 56 秒。现在想象一下,一个实际的生产服务,它有更多的依赖项,也许还有更大的自定义库,以及捆绑了更广泛的辅助数据。对于这个玩具示例来说,56 秒的构建时间很容易就会延长到几分钟甚至几十分钟,对于生产镜像来说更是如此。再想象一下,这种情况在团队中蔓延,每个开发人员每天都要多次重新构建。这不仅仅是浪费了几秒钟,还实实在在地拖慢了迭代速度和开发人员的工作节奏。
低效的 CI/CD 管道
每次将 2.54GB 的镜像通过持续集成和部署系统进行推送和拉取都会消耗时间和带宽。虽然对于不频繁的部署来说 2.54GB 可能是可以接受的,但生产系统通常需要更频繁地更新模型、修补库或推出新功能。如果你的生产镜像膨胀到 5GB、10GB 或更大(这并非罕见),这些持续集成和持续交付(CI/CD)操作就会成为明显的瓶颈,延迟发布并消耗更多资源。
更高的云成本
在容器注册中心存储多吉字节的镜像并非免费之举,尤其是在管理众多项目中的多个版本时。将我们 2.54GB 的镜像压缩,能立即节省存储成本。更重要的是,这种对效率的追求与现代的可持续发展目标相契合。通过减少推送、拉取和扩展事件期间的数据传输量,我们降低了云基础设施的能耗以及相关的碳足迹。打造一个轻量级的 Docker 镜像,这不仅是技术或财务上的优化,更是朝着构建更负责任、更“绿色”的 AI 系统迈出的切实一步。
一个不那么“干净”的状态
一个更精简的镜像本质上更安全。一个膨胀的 Docker 镜像,就其本质而言,包含的不仅仅是你的应用程序。它通常携带一个完整操作系统的工具、shell、包管理器(例如,apt 和 pip)以及并不严格必需的库。每个组件都代表了一个潜在的攻击向量。如果在 curl、bash 或任何其他数百个操作系统工具中发现漏洞,而这些工具在你的镜像中,那么你的部署现在就变得脆弱了。通过积极精简容器内容,我们在文件系统层面践行了最小权限原则,这极大地缩小了攻击面,并减少了潜在入侵者可利用的工具。这种对“干净”状态的追求将优化从单纯的性能调整转变为一项基本的安全最佳实践。
我们的目标不仅仅是让事情变得更小,而是让我们的整个 AI 开发和部署生命周期更快,更高效,最终更健壮。“做小”原则是现代云运维的基本原则,这正是为什么像 AWS、微软 Azure 和谷歌云这样的超大规模企业投资创建和推广自己的精简 Linux 发行版(如 Bottlerocket OS 和 CBL-Mariner)的原因。他们知道,在镜像传输和启动过程中节省的每兆字节、增加的每一毫秒,都会在成本、性能和安全性方面带来显著提升。通过优化我们自己的 AI 镜像,我们正在应用同样的经过实战考验的逻辑,这些逻辑驱动着世界上最大的云基础设施。
我们的样本:朴素 BERT 分类器
让我们介绍下今天诊断环节的“病人”。这是一个简单的文本分类应用,使用了来自 Hugging Face Transformers 的流行的 bert-base-uncased 模型。
本演练在Github上有一个存储库,其中展示了我们的“naive_image”。
配料很简单:
requirements.txt 文件(位于我们项目的 naive_image/ 目录中)
# 核心依赖transformers==4.52.3torch==2.7.0torchvision==0.22.0torchaudio==2.7.0# 服务器的Web框架flask==2.3.3# 开发/运行时依赖pandasnumpy==1.26.4requests==2.32.3pillowscikit-learn# 开发/分析依赖pytestjupyteripythonmatplotlibseabornblackflake8mypy一个“有问题的”Dockerfile
这个文件构建了我们的 bert-classifier-naive 镜像。它是实用的,但我们故意留下了一些常见的错误,使我们的诊断之旅更具启发性。
# naive_image/Dockerfile# 这是最初的,朴素Dockerfile.# 它的目标是简单和实用,但没有针对大小或速度进行优化。# 使用一个标准的,通用的Python镜像FROM python:3.10RUN apt-get update && apt-get install -y curl# 设置容器内的工作目录# 所有后续命令将从这个目录运行WORKDIR /app# 先复制requirements.txt以获得更好的层缓存 COPY naive_image/requirements.txt ./requirements.txt# 安装requirements.txt中列出的所有依赖RUN pip install --no-cache-dir -r requirements.txt# 复制应用代码和数据COPY naive_image/app/ ./app/COPY naive_image/sample_data/ ./sample_data/RUN echo "Build complete" > /app/build_status.txt# 当容器启动时运行应用的命令。# 这是运行预测器脚本和样本文本文件CMD ["python", "app/predictor.py", "sample_data/sample_text.txt"]当我们构建这个镜像时,我们创建了一个 2.54GB 的镜像。
docker build -t bert-classifier-naive。现在,让我们打开它。
诊断工具包:层层剥离
不要把 Docker 镜像想象成一个整体,而是一堆透明的工作表,每个工作表代表一个更改或添加。我们的工具将帮助我们检查这些表格。
第一瞥
Docker 镜像是
这是你的快速称重。
Docker image ls bert-classifier-naive
输出立即将我们的 bert-classifier-naive 镜像标记为 2.54GB。这是一个明确的信号,表明还有改进的空间。
> docker images bert-classifier-naive REPOSITORY TAG IMAGE ID CREATED SIZEbert-classifier-naive latest b0693be54230 About a minute ago 2.54GB命令日志
docker history bert-classifier-naive
如果 docker image ls 显示了镜像的最终总大小,docker history 分解了这个总数。它列出了你的 Dockerfile 中的每个命令,并确切地显示了每个步骤对大小的贡献。
docker history bert-classifier-naive
输出将类似于这样:

从这段历史中,我们可以看到两件事。首先,来自 pip install 命令的 1.51GB 层是我们直接操作的主要贡献者。接下来,基础镜像本身的贡献也很大,仅一层就有 560MB,我们的 apt-get install curl 又增加了 19.4MB。这个历史视图告诉我们哪些命令是重量级的。
深度检查
divebert-classifier-naive
现在,让我们来看我们诊断节目的明星:dive。dive 是一个开源的命令行工具,用于探索 Docker 镜像、层内容,并发现缩小镜像大小的方法。
Homebrew是安装 dive 最简单的方式。
brew install dive
用以下命令启动它:
dive bert-classifier-naive
让我们使用 dive 浏览我们的 bert-classifier-naive 镜像:
基础——基础镜像层
在左侧的层列表底部选择一个最大的层。例如,docker 历史记录告诉我们的是 560MB 的那个。在右侧,你将看到文件系统结构。这是 python:3.10 基础镜像(一个完整的 Debian 操作系统)、Python 标准库等的大部分内容。这就像是你只需要一个特定的房间,但却买了一套带家具的房子。
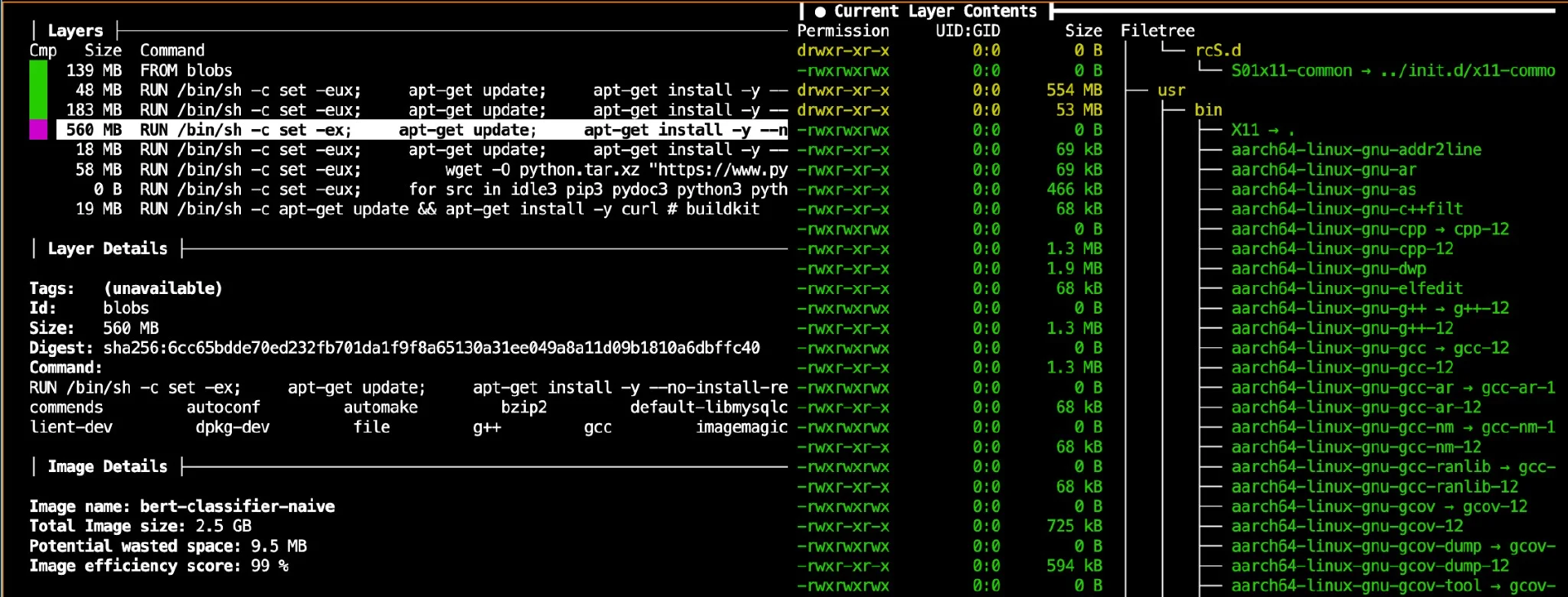
图 1:bert-classifier-naive 的 dive 视图
apt-get install curl 层(19.4MB)
导航到这一层。在右侧,dive 将显示 curl 及其依赖项被添加。重要的是,如果你浏览 /var/lib/apt/lists/ ,你会发现里面填充了包的元数据。因为我们没有在同一层清理这些数据,这些数据虽然在运行时没有用,但仍然是该层对镜像大小贡献的一部分。请注意,dive 甚至显示有一个“潜在浪费空间”指标(左下角,你的显示了 9.5MB),它经常标记这样的遗漏。
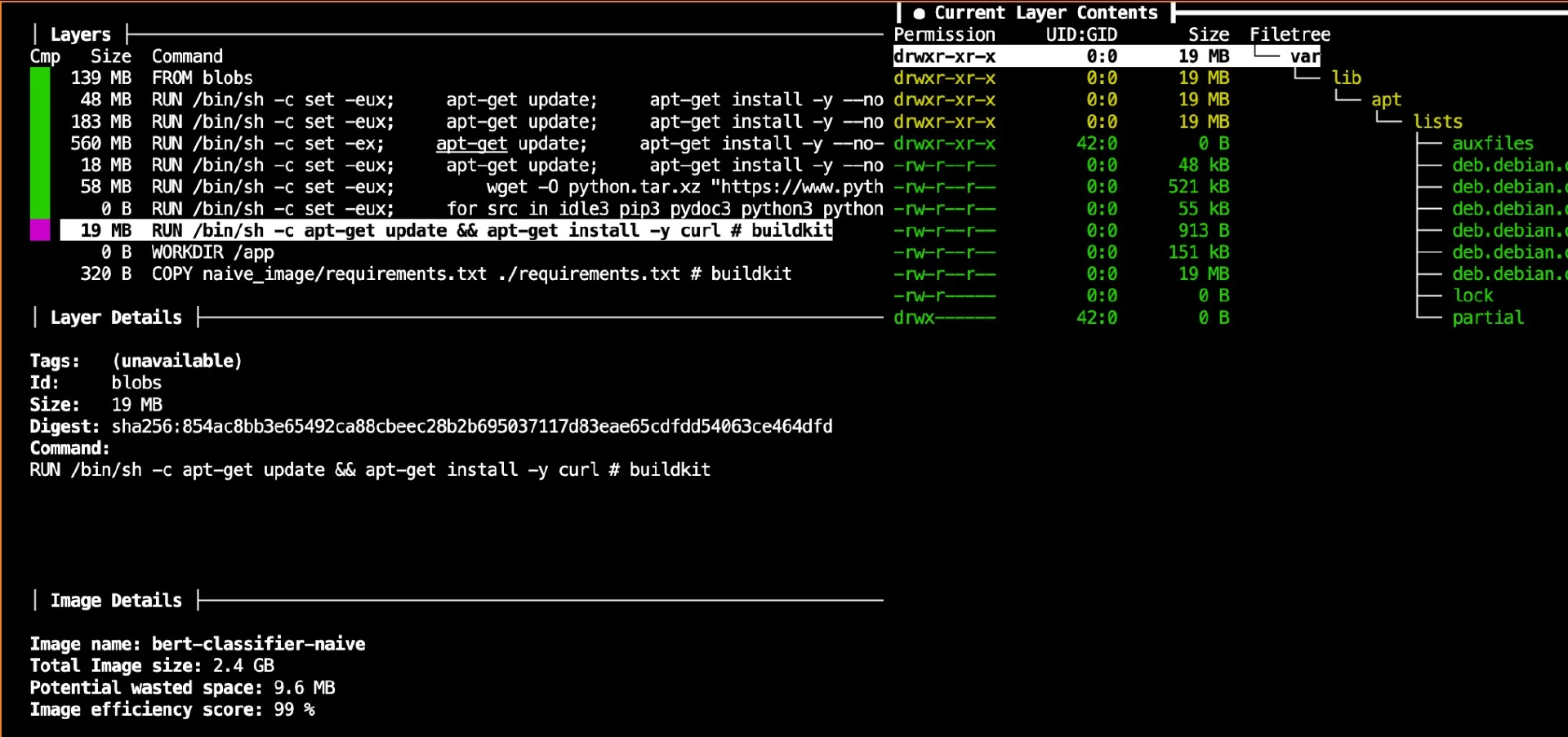
图 2:bert-classifier-naive 镜像中 apt-get 安装层的 dive 视图
pip install 层(主要事件)
选择这一层。这是我们的 AI 特定依赖项隆重登场的地方。在右侧展开 /usr/local/lib/python3.10/site-packages/ 。你将看到罪魁祸首:大量的 torch、transformers、numpy 及其相关产品的目录。这并不是不必要的“膨胀”(我们需要这些库),但它们的庞大体积是我们需要注意的一个主要因素。

图 3:pip install 层的 dive 视图,显示了 bert-classifier-naive 镜像的大部分
COPY 层
在我们的例子中,COPY naive_image/requirements.txt ./requirements.txt 、 COPY naive_image/app/ ./app/ 和 COPY naive_image/sample_data/ ./sample_data/ 层很小(分别为 320B、12.2kB 和 376B)。然而,dive 会明显揭示如果我们忘记了 .dockerignore 文件,并意外复制了我们的整个.git 历史、本地虚拟环境或这些源目录中的大型数据集。一个 COPY . . 命令,没有vigilant.dockerignore,可能是膨胀的特洛伊木马。

图 4:Dockerfile 中 COPY 和 RUN 命令的 dive 视图,显示了它们添加/修改的文件
使用 dive 将抽象的层概念转化为一个具体的、可探索的文件系统。它让我们精确地看到每个 Dockerfile 命令的作用,它消耗了多少空间,以及效率低下的地方在哪里。
探索代码库
所有代码,包括我们今天剖析的 naive_image Dockerfile 和应用程序文件,都可以在相应的GitHub代码库中找到。
该代码库还包含其他几个目录,如 slim_image 、 multi_stage_build 、 layered_image 和 distroless_image ,它们展示了为我们 BERT 应用构建更精简容器的不同方法。这为你提供了一个完美的沙箱来练习你的新诊断技能。我们鼓励你利用其他的这些 Dockerfiles 来构建镜像,并自己运行 dive,以精确了解它们的结构、大小和组成与我们的 naive 起点有何不同。这是巩固你对 Dockerfile 更改如何反映在最终镜像层理解的绝佳方式。
轮到你使用 dive 了
我们对 bert-classifier-naive 的研究表明:
我们的镜像总共 2.54GB。
我们 BERT 模型的 Python 依赖项(torch、transformers 等)占了巨大的 1.51GB。
python:3.10 基础镜像本身贡献了数百兆字节的操作系统和标准库组件。
即使是较小的操作,如安装 curl 而不清理包管理器缓存,也会增加不必要的重量(我们的 19.4MB 层包含了约 9.5MB 的“浪费空间”)。
现在我们清楚地知道千兆字节的位置。这种详细的诊断是所有有效优化的基础。有了像 dive 这样的工具,你现在可以解剖你自己的镜像并识别这些相同的模式。在任何优化过程中,合乎逻辑的下一步自然包括仔细检查基础的选择,如基础镜像,并探索将构建时需求与运行时基本要素隔离的技术。
我鼓励你拿起 dive,指向你自己的 Docker 镜像。你会发现什么惊喜?
原文链接:




