
Cloudflare 最近经历了一次由数据库权限更新引起的全球中断,在其 CDN 和安全服务中引发了广泛的 5xx 错误。
中断开始于 11 月 18 日 11 点 20 分左右,阻塞了客户站点的访问,甚至 Cloudflare 自己的团队也无法访问他们的内部仪表板。根据首席执行官 Matthew Prince 发布的事后分析,根本原因是在对ClickHouse数据库集群进行例行改进时出现了细微的退化。
工程师们推出了一项旨在通过让用户显式访问表来提高安全性的更改。然而,这个更新对Bot管理系统产生了糟糕的、意料之外的副作用。一个元数据查询,一个历史上返回默认数据库中列的干净列表的元数据查询突然开始从底层 r0 数据库分片中拉取重复行。
Prince 在博客文章中解释了技术细节:
这个变更...导致所有用户都能访问到他们有权访问的表的准确元数据。不幸的是,过去的假设认为,像这样的查询返回的列列表只包括“默认”数据库。
这些额外的数据导致“特性文件”(一个用于跟踪机器人威胁的配置集)的大小增加了一倍。Cloudflare 的核心代理软件为这个文件预分配内存以优化性能,但它有一个硬性安全限制,即 200 个特性。当膨胀的文件进入网络时,它突破了这个限制,导致 Bot 管理模块崩溃。
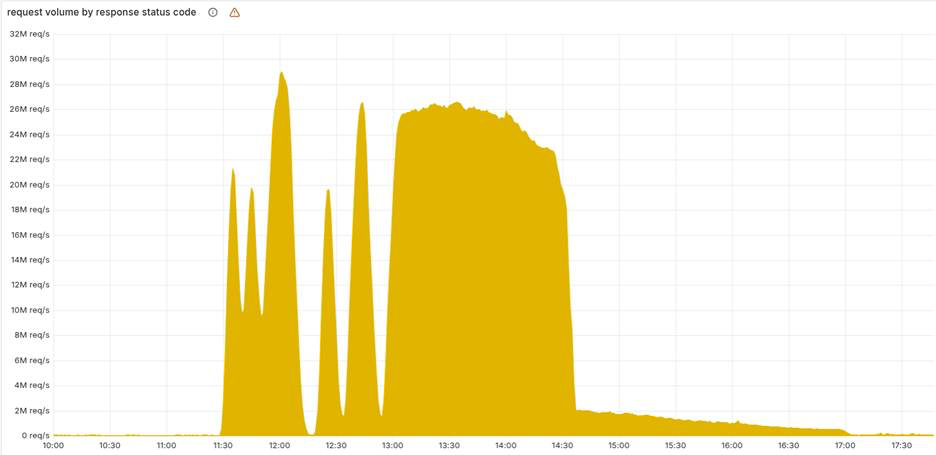
(来源:Cloudflare博客文章)
由于其表现,这次事件很难诊断。由于数据库更新是逐步推出的,系统每几分钟就在“好”状态和“坏”状态之间切换。这种不稳定的行为最初让工程团队相信他们正在对抗一场超大规模的 DDoS 攻击,而不是内部错误。当 Cloudflare 的外部状态页面也崩溃时,混乱达到了顶峰,这是一个完全的巧合,导致一些人认为支持基础设施正在被攻击。
Reddit 上的一个评论者在讨论中评论道:
你不会意识到有多少网站使用 Cloudflare,直到 Cloudflare 停止工作。然后你尝试查找有多少网站使用 Cloudflare,但你不能,因为所有会回答你问题的 Google 结果也在使用 Cloudflare。
“我们的网络有一段时间无法路由流量,这对我们团队的每个成员来说都是非常痛苦的,”Prince 写道,他指出这是自 2019 年以来公司最严重的服务中断。
当用户努力应对服务中断时,Syber Couture 的 CEO Dicky Wong 将这一事件视为多供应商策略的验证。他回应这一事件时评论说,尽管 Cloudflare 提供了一套出色的工具,“爱情与没有婚前协议的婚姻不同。”Wong 认为,风险管理需要向积极的多混合策略转变,以避免定义这次服务中断的“单点物理故障”。
r/webdev subreddit上的用户 crazyrebel123 也表达了这种情绪,他指出了当前互联网格局的脆弱性:
如今的问题是,只有少数几家大公司运营或拥有互联网上的大部分内容。所以当其中一个坏了,整个互联网都会坏掉。大多数网站现在都运行在 AWS 或其他形式的云服务上。
高级技术领袖 Jonathan B.在LinkedIn上加强了这一观点,他批评了组织倾向于为了“简单”而将所有赌注押在单一供应商上。
这很简单,是的——直到那个供应商成为每个人都在推特上谈论的服务中断...人们称混合型为“老派”,但说实话?这只是负责任的工程。这是承认服务中断会发生,无论云的侧面标志有多大。
最终,通过手动将配置文件的已知正确版本推入分发队列,服务得以恢复。流量在 14:30 UTC 时恢复正常,事件在下午晚些时候完全解决。Cloudflare 表示,它现在正在审查其所有代理模块的故障模式,以确保内存预分配限制在未来更优雅地处理不良输入。
原文链接:
https://www.infoq.com/news/2025/11/cloudflare-global-outage-cause/




