

导读: 58 部落是 58 同城旗下的内容社区,基于 58 同城和 58 同镇的广大用户,致力于全链路打通生活服务场景、精准连接用户全场景多维度需求。本文将结合 58 部落的业务特点探讨部落推荐算法选型经验,分享几种跨域推荐算法的落地,并介绍异构内容混合信息流的排序优化方案。
主要分享内容包括:
58 部落的基本情况
58 部落的推荐场景和特点
58 部落的跨域推荐技术
分享跨域推荐技术的实践
多类型混合信息流的实践
01 58 部落
首先和大家分享一下"58 部落"。

人们可能对"58 部落"的了解还比较少。它的前身包括多个产品,包括:同城头条、同城圈、及老的同城部落还有 58 便当,其中同城头条是以资讯为主,同城圈和同城部落则是以圈子为主、58 便当则是以工具文章的形式为主。
去年 5 月份 58 对多个业务线进行了整合,形成了现在的一个统一产品叫作"58 部落"。公司与集团也是对"58 部落"寄予厚望,希望它能打通 58 的各个服务场景,能够连接用户的多种维度的需求。
02 58 部落推荐场景和特点
下面我们来看看"58 部落"的推荐场景都有哪些。
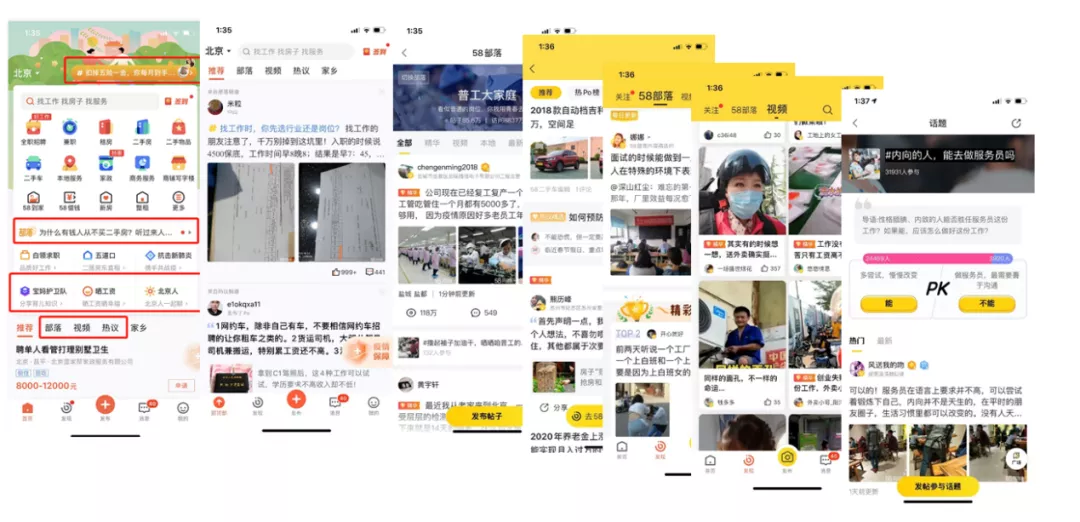
首先进入 58 的 APP,就可以在界面的右上角、腰部还有底下的 feed 部分,都可以看到"58 部落"的入口。同时在推荐 feed 的第二屏就可以直接看到对接"58 部落"的信息流。当从不同的入口进去以后,就可以看到"58 部落"的落地页以及它主热议,也就是它的资讯列表页、视频列表页、话题列表页等等,以上列出的这些都是"58 部落"的展现形式的页面。
通过刚才的简单的介绍,我们可以知道"58 部落"的内容具有自己的特点:
首先,"58 部落"的内容与 58 的业务有比较强的关联。它包括了:房产、招聘、汽车、本地生活等等各种各样的内容。
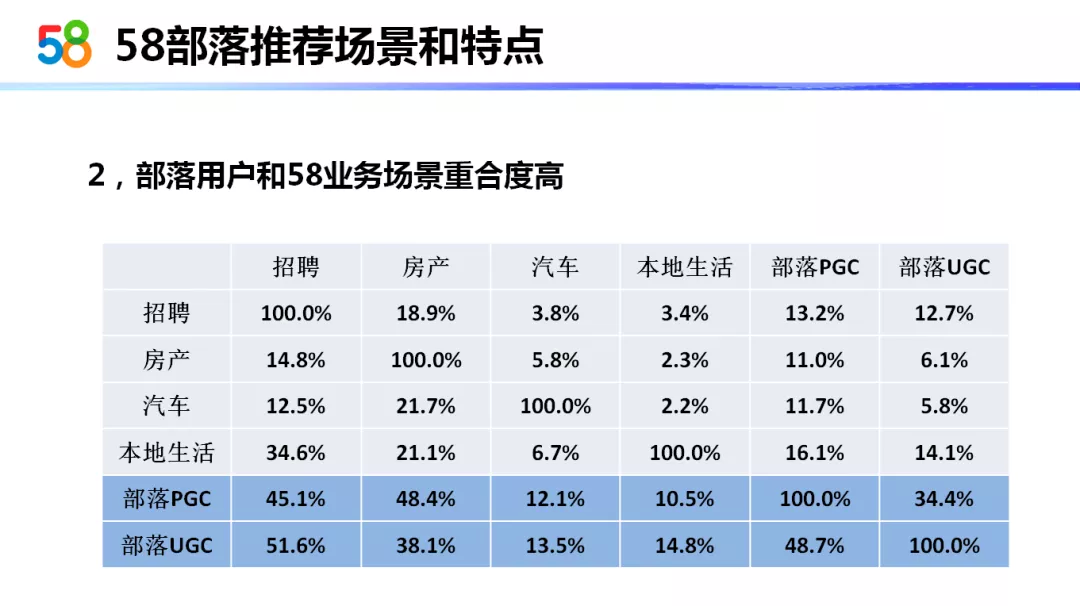
第 2 个特点是部落用户和 58 业务场景重合度是非常高的。底下这张表画了 58 内各个业务线的用户重叠占各个业务线的比例。我们可以看到在"58 部落"与各业务线用户的重叠比例是明显高于其他业务线间的重叠比例的。

第 3 个特点是 58 部落的内容类型非常丰富并且是异构的。从内容的形式上主要分成两种,一种叫 PGC,另一种叫 UGC。PGC 的特点是:"58 部落"从外部的合作部门、合作单位 ( 的网站上 ) 直接抓取过来的内容,包括:资讯、视频,还有音频等等。第二个部分叫作 UGC,UGC 是 58 自身的用户自发产生的内容,它包括:帖子、话题、短视频、直播,还有他们对所有的内容产生的评论。

第 4 个特点是"58 部落"的推荐形式是一种混合信息流的形式,也就是它的 feed 中要包含资讯、帖子、话题等等。一个 feed 流中要包含多种实体。

综合以上特征,我们就可以提炼出"58 部落"推荐可能面临的一些特有问题:
首先是如何借助其他业务线的数据来优化部落的推荐效果?
如何联合部落 PGC 和 UGC 的异构内容,共同提升部落整体的推荐效果?
第三个问题是如何在一个信息流中对多种异构实体进行一种比较合适的混排?
下面我们将针对如何解决以上 3 个问题开始相关的话题讨论。
03 跨域推荐介绍

我们首先引入一个"跨域推荐"的概念。什么是"域"呢?其实我们可以很容易想到,它是通过某种方式聚集在一起的集合。说小一点,我们可以把部落的 PGC 当成一个域、把部落的 UGC 当成一个域。当然我们也可以扩大域的概念,把部落整体当成一个域,把房产当成一个域、把车当成一个域、把招聘当成一个域。这些定义都是可以的,域的概念其实可大可小。
那什么叫"跨域"呢?我们之前做的推荐可能是单域推荐比较多,也就是"房产"只推荐"房产"的部分东西,它基于的数据也都是房产用户本身的东西。但什么是"跨域推荐"呢?比如,我要给部落推荐东西,但是使用的数据不只是部落自己的,它还包括了"房"、“车”、"招聘"等其他域产生的数据。
“域"的话我们先定义两个域的概念:一个叫"源域”,一个叫"目标域"。我们要优化、提升的目标叫作"目标域",比如说我们要提升的"部落域"就是我们的"目标域"。“源域"相当于辅助域,我们会把"房”、“车”、“招聘"等看做辅助域。当然,如果我们将"部落 PGC"当成"目标域”,把"部落 UGC"当成"源域",这样的理解也是可以的。
所以总结下来"域"的概念可大可小,只要是两个不一样的集合之间互相使用数据都可以称之为"跨域"。
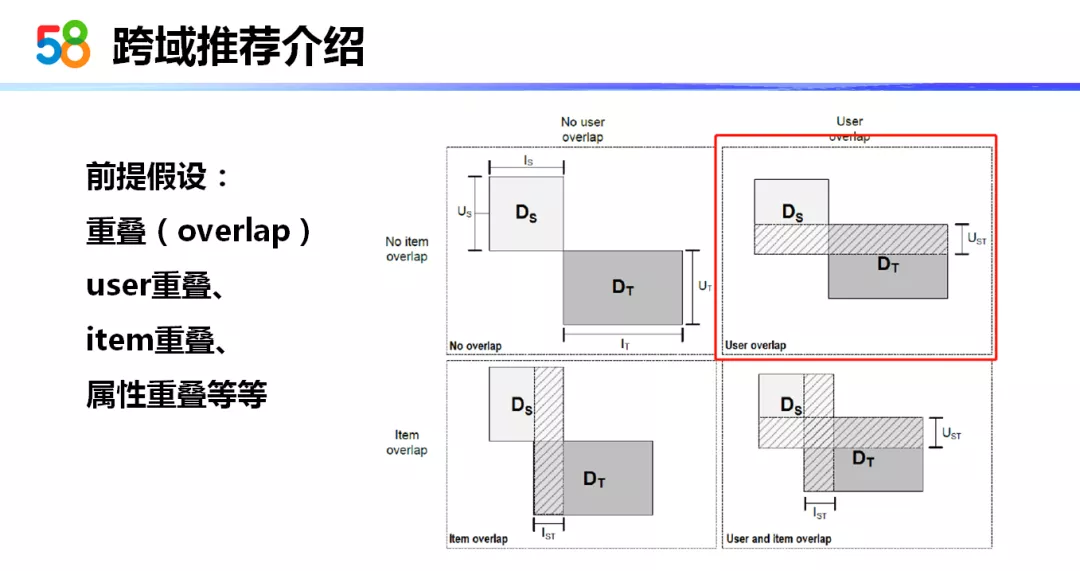
跨域推荐实际是有一种前提的,前提是基于重叠。为什么会有跨域?那是因为有一部分的特征也好、用户也好、物品也好、属性也好,能够有一些重叠,通过重叠的部分找到两个域之间的一些关联。
从右边的 4 个图中我们可以看到,横坐标代表了物品的整个空间,纵坐标代表了用户的整个空间:
第一张图中 ( 左上图 ),用户与物品之间没有交集。
第二种情况 ( 右上图 ) 是用户有部分交集,但物品没有交集。这种情况可以理解成我们的房产用户和部落用户会有部分交集,这部分用户他们既访问了房产的帖子又看了部落 PGC 和 UGC 的内容。
第三种重叠情况 ( 左下图 ) 是用户没有交集,但是物品有交集。举个简单的例子:假设 58 app 和赶集 app 的用户是不一样的,但是他们的帖子内容是一样的,这就满足了第三种情况。
第四种情况 ( 右下图 ) 的重叠度会更高一些,不论是用户还是物品都有一定程度的重叠。可能的场景:58 的 APP 和 58 的微信小程序之间可能有这种关系。
今天我的介绍主要是基于用户重叠的部分,也就是第二种情况。

跨域推荐有哪些的优势呢?
首先,它有冷启动的优势。从上面的图我们可以看到,当一部分用户同时访问两个域的时候,我们就可以学习到两个域之间的联系,进而给没有在这个域中的用户进行推荐。
第二点是提升目标域的推荐效果,这个也是跨域推荐的主要目的。
第三个优势是多样性。因为跨域推荐同时参考了多个域的特征,自然而然会对推荐结果的多样性进行一定的优化。最终,它还会反作用于源域,能够实现源域的推荐与目标的域推荐效果的共同提升。
跨域推荐还需要考虑一定的权衡,因为跨域必然会导致数据的稀疏,处理不当可能会有反作用。我们从前一幅图可以看到:用户空间与物品空间为例,一旦涉及到跨域上下两个方块必然会引入空白,空白的稠密度相当于 0,所以跨域推荐必然会导致数据更加稀疏。所以我们要处理这种数据稀疏,避免产生反作用。
04 跨域推荐实践
下面我介绍一下 58 部落对跨域推荐的一些实践。

第一个我们的实践就是一种叫做跨域协同过滤的算法。说起协同过滤大家应该都非常清楚这是一种非常老的推荐方法。最常用的方法是一种矩阵分解的方式,但是矩阵分解和我们的 FM 是如何联系起来的呢?FM 大家应该也知道,也是一种非常常用的推荐算法。它是通过一种 embedding 內积的方式来实现二阶项的交叉。FM 和矩阵分解是如何联系起来的?我们通过该图的下部分可以看到:矩阵分解相当于把 FM 中的特征域部分,一部分设置成用户的 one-hot ( 特征 )、一部分设置成物品的 one-hot ( 特征 ),如果抛弃后面部分的辅助特征的话,矩阵分解就等效于一种 FM 的训练过程。

那么跨域的协同过滤,如何能基于 FM 的形式来进行呢?它的核心思想就在论文:
《Cross-Domain Collabotive Filtering with Factorization Machines》
它的核心思想就是:除了把用户在源域的物品访问集合的多-hot 编码乘以一个权重系数放在 FM 的右侧作为用户的特征。也就是说,放在上一幅图中,用户在源域的行为作为附属特征放在 ( FM ) 的右侧,这样在训练过程中能够兼顾用户在目标域的行为以及在源域的行为。
这样它的特征向量就分成了 3 部分:
第一部分:用户的 one-hot 编码
第二部分:物品的 one-hot 编码
第三部分:用户在源域的一些访问行为的多-hot 编码
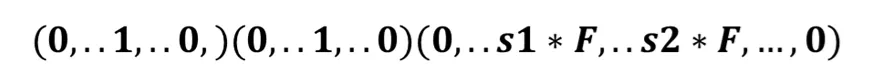
这是一条特征向量,但是这个向量的 label 是如何定义的呢?我们把用户对物品的评分作为 label。比如说点击的值可能被设定为 1,但是点赞或分享这种用户行为更强的会设置成更大的值。

以我们在 58 部落中为例,我们定义一个源域是部落 UGC 部分,然后把目标域定义成部落的 PGC 部分。我们把 label 定义成:1 分是点击、点赞是更强的用户行为定义为 2 分、分享是更强的用户行为定义为 3 分。
比如说有一个样本:一个用户 i 在部落 PGC 点击了资讯 j,同时这个用户在部落 ugc 点击过 m、n 等几个帖子。这样我们就能够得到一条特征向量:
(0,…1,…0)(0…1,…0)( 0,…1*f,…. 1*f,…0)
前面第一部分是用户的 one-hot 编码,第二部分是物品的 one-hot 编码,最后一个部分是用户在源域点击的帖子的多-hot 编码。特别要提一下:这里面会有一个 f 函数,f 函数在论文中被定为调节的常量。在这初期,我们对 f 没有进行特殊的处理,只是当成 1 来直接使用。

通过这种方式训练出来用户和物品的 embedding,直接放入 faiss 库进行召回,效果:相比单域协同过滤转化率提升约 8%。

可以简单说一下,跨域协同过滤在工程上需要一些特殊处理。像这种基于协同过滤的算法有个特点:训练的用户 embedding 和物品的 embedding 是在两个空间里的,没有联系性。所以说我们第一次训练的用户 embedding 和第二次训练的物品 embedding 是没有关系的,是不能放在一起使用的。所以我们采用了一种基于滑动窗口的概念,来存多份 embedding 的数据。比如,物品的 embedding 每次训练出来后都存在一个新 faiss 库中,并且用它的时间戳和版本号来记录 faiss 库。物品 embedding 每次都存一个版本号进行覆盖,这样我们在线上使用的时候每次读出来的时候都是用户最新的 embedding,但是新的用户的 embedding 都要在于其版本号相对应的版本号在 faiss 库中进行查找。
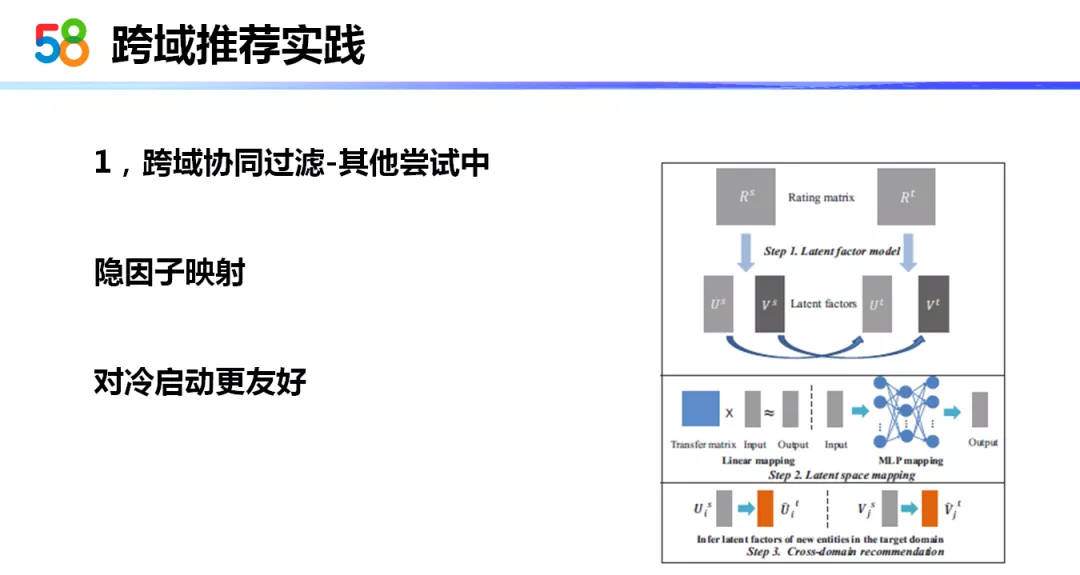
还有一种是我们正在尝试的方法,它是一种叫做隐因子映射的方法。这种方法是更通用的。主要的思想是通过某些方式,如矩阵分解也好、或其他的学习某些方式也好,找到了一个物品的一种隐向量,然后直接通过访问这些物品的人的共现,学习物品隐向量之间的映射。这种方式对冷启动会更加友好。

下面是我们第二种基于跨域推荐的实现方案,它是基于属性标签映射的跨域推荐。我们可以有个前提,58 每天的房、车、招聘、本地生活的帖子非常多,每天有几千万的更新,同时这些帖子点击过的人数据又非常稀疏,比如超过 50%的人写的帖子点击都不超过 3 次。如果单纯用 id 做 ( 特征 ) 的话,会因为数据过于稀疏导致测试集上的数据很难收敛。如何来缓解这个问题?我们放弃了用 id 的映射方式,采用了标签来代替 id。因为标签数据相对较少,很容易把数据控制在万以下的级别,这样就可以缓解 id 造成的数据稀疏性的影响。

基于这个属性映射的是如何实现的呢?它的基本思想是:通过源域的属性标签和目标域的属性标签在用户访问序列上的共现来构造这种属性映射。
我下面会介绍两种映射方式:第一种是简单的通过统计的方法,第二种是通过非常常用的 word2vec 的方法。

首先讲基于统计的方法。
我们假设:源域为 58 业务线,目标域为部落 UGC。58 业务线的 cate,也就是我们基础的类别体系标签,它的数量是在万级别的,比如:保姆、搬家等。部落 ugc 的 tag 的数量是在百级别的,比如:生活、房政策等类似的分类。然后,我们按天取用户的行为序列。比如说:User1 访问了业务线 cate1、cate2 类别的帖子,同时他访问了部落 tag1、tag2 的帖子。User2 访问了业务线 cate3、cate4 类别的帖子,同时他访问了部落 tag1、tag3 的帖子。这样我们就把所有用户访问的内容序列拿出来,作为我们的训练样本。

得到训练样本以后如何来做这个映射呢?第一个种方法是一种非常简单的方法,它是基于统计方法。很容易通过相关性的公式,计算出两个变量 X 和 Y 的相关性。我们如何定义 X 和 Y,X 就定义为业务线的 cate 在用户的行为中出现,Y 定义为部落 UGC 的 tag 在用户的行为中出现。分子上我们需要统计包含了 ( cate1,tag1 )、( cate2,tag1 )、( cate3,tag1 ) 等等所有组合的用户数量作分母就需要统计只要包含 cate1,cate2,。。。tag1,tag2 的用户数作为分母。我们用分子上的用户数量乘以用户的总数,除以分母中计算出的 cate 与 tag 的用户的数量计算出相关性。将相关性经过一定的阈值的截断,作为一种 cate 与 tag 之间的映射,为下一步的召回做准备。

基于 word2vec 的方法其实之前的几位老师也都介绍过了。因为有了这些 ( 用户行为的 ) 序列,它非常满足 word2vec 的训练数据集的要求,所以我们也采用了 skip-gram 的方式,按天划分 session,这样就可以得到源域的 cate 和部落的 tag 的 embedding 向量,通过 embedding 向量的相似度可以得到和 cate 最接近的若干个 tag,为我们后续的召回做准备。

召回部分就比较简单了:
首先,我们可以直接查找用户最近 k 条业务线帖子浏览记录,取访问最多的 cate。
然后,接着查找这些 cate 最相似的 m 个 tag。
最后,直接召回 tag 下的部落的一些帖子。
这种召回效果:uv 转化率大约提升了 4%。

接着还有一些是我们正在进行的一些尝试。上面的基于属性标签映射的方式需要提前准备好需要哪些属性、哪些标签。有些标签的域不是那么长,比如行业,可能只有十几个或者几十个。这种枚举值比较少的情况下可能会对它的个性化效果造成影响。我们通过组合标签的情况可以扩大标签数量。但是我们也要注意将组合标签的数量控制在一个可能的范围内。这样既能提高个性化程度,又能避免数据过于稀疏带来的问题。
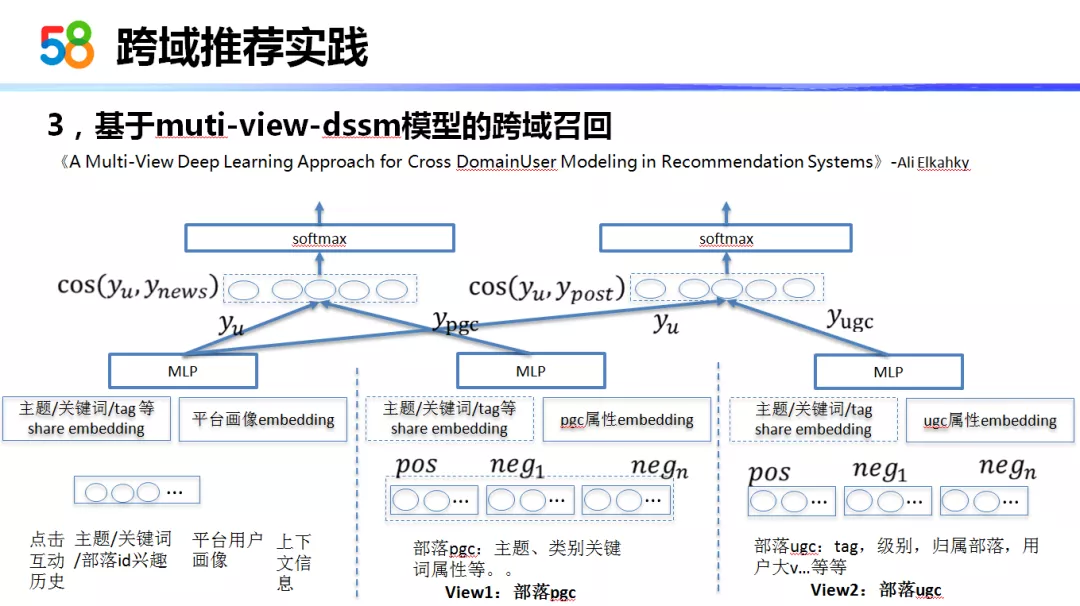
然后我们实践的第三种方法是:基于多视图 dssm 模型的跨域召回,是基于这篇论文:
《A Multi-View Deep Learning Approach for Cross DomainUser Modeling in Recommendation Systems》
其实 dssm 模型之前很多老师也都讲过,它是一种非常常用的方法。但什么是多视图的 dssm 模型呢?就把每个域的物品都训练出来一个 dssm 模型的塔,但是它的用户部分用的是相同的一个塔,这样我们把所有域的塔和用户部分的塔进行共同联合训练。就能同时得到用户与多个域的塔,这样的好处是可以极大利用用户部分和各个域的共享因子。例如:部落 PGC 的影响可能会更新用户的这个塔,但是部落的 PGC 与部落的 UGC 本身是有关联的,部落 PGC 的更新可能会影响部落 UGC 这个塔,因此产生一定的互相优化的作用。在这里我们就采用了每个域是一个塔的结构,同时把每个域里头相同的一些属性,例如一些关键词、共性的 tag 作为完全共享的 embedding,然后用户部分、源域和目标域的 embedding 可以共享。同时各个域之间有它们独立的属性 embedding,我们将其作为其独立的特征并排拼接在上面。这样一次训练就可以得到用户 embedding 和多个域实体的 embedding。

基于多视图 dssm 模型的跨域召回模型 ( 使得 ) 我们线上的 uv 转化效果提升了 2%。
这里要说实现中的几个要点:
为什么会有效?那是因为首先它的用户视图是完全共享的。它的用户视图的向量会同时包含多个域的特点,会学到多个域之间的交叉。
第二 dssm 模型有一种变换,就是它把上层 softmax 损失函数替换成了交叉熵损失函数。但这种方式要根据你的最终目的来决定。在我们实现中(的效果)来看,在资讯这种 feed 中推荐的东西可能和用户的 embedding 比较接近的情况下,采用交叉熵损失函数效果并没有达到理想中的效果,最终我们还是采用的 softmax 损失函数。
下面讲一下采用 softmax 损失函数如何采用负采样。一种是从全局所有的 item 里面随机地负采样,还有一种负采样方式是从点击序列中未产生点击的 item 作为负采样。实际中我们采用的是全局随机负采样的方式。我们分析了一种原因:部落中的标签特征并不能像房、车、招聘等域中的标签那么能确定物品特点,所以采用全局负采样的方式可能效果会更好。
在用户 PGC、UGC 场景,实时数据的重要性其实不输于它的标签。但是如果我们在训练多塔结构时,把实时特征也考虑进去的话需要频繁更新用户物品特征,工程实现上会有相当大的压力,所以这块需要权衡。我们暂时只采用了物品的固有标签作为特征,这也使得多塔结构的物品侧计算不依赖于物品的实时特征,不需要频繁更新。这可能也是我们后续需要优化的一个方向吧。
最后,用户向量的计算方式还有很多种方式。目前,我们在此只采用了一种基于 embedding 拼接的方式,用户向量这方面业界也有非常多的实现方案。比如说,像阿里的用户向量处理 din、dien 更适合处理用户兴趣建模,会比我们现在这种简单的方法更有效,这也是我们后续的一个研究点。
05 异构混合信息流混合排序实践

上面我们介绍的 3 种跨域推荐的方式,自然而然地就会引出一个新问题。我们的信息流中通常有各种各样的内容,但是面对这种混合的信息流如何进行统一的排序呢?这也是我们要考虑的一个问题。
首先混合的信息流可能存在多种类型,每种类型打分模型不一样,不同模型评分不能直接比较。这种情况实际非常常见,不同类型的推荐模型往往是不同同学在做,产生多个模型非常正常。
第二点就是不同算法目标如何衡量。比如说同样是部落的信息流,有资讯、视频、帖子,一种类型物品的展示过多,必然会导致其他类型物品的展示下降。如果我们只看一种物品的提升,可能会认为有效果提升。但是如果整体来看可能是提升较小或者没有什么提升。这种情况也可能说明我们的优化整体意义不明显。
最后一种就是整体的多样性如何权衡。

下面会介绍我们处理这 3 种问题的一些方法:
对于第一个问题,整体上来看我们会通过一种评分对齐的方式,把不同类型的评分对齐处理。
对于第二个问题,我们整体的目的是明确了一种目标,挑出几个业务关注的指标作为我们整体的导向。
对于多样性问题,我们通过 MMR 和 DPP 两种算法结合了 a/b test 方式找对业务目标影响最优的一种组合方式。
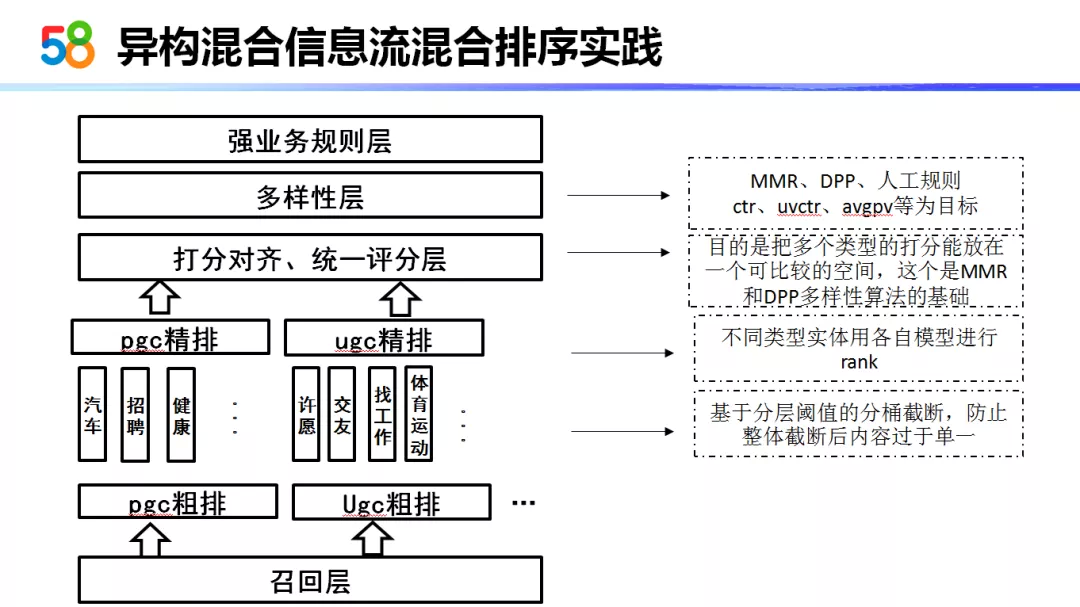
首先我们讲一下混合信息流排序的一个流程:
首先经过召回层以后,不同类型的物品会经过不同类型的模型来进行粗排,以及分桶进行截断,最终进入精排层。在精排层不同类型的物品会有不同的精排模型来处理。最后会有一个统一的打分模块对不同模型打分的物品放入一个可以共同比较的空间中。最后会有一个多样性层,基于 MMR 和 DPP 两种算法以及加入的人工规则,以 ctr、uvctr 以及 avgpv 等为目标来进行优化。
从 ( 该架构的 ) 底向上,我们主要以下几个部分做了工作:
首先是粗排以后,在进入精排以前,我们做了一个分层、分阈值的截断。也就是说它会根据类型进行截断,防止粗排后进行截断就把某一类型的物品全排在后面了这种情况。
第二个问题是我们如何把多个精排的模型整理成一个大模型,( 从而 ) 把多个精排的分数进行统一处理。
最后我会讲 MMR 和 DPP 的一些使用过程。

首先我们看一下评分对齐是如何做的。因为多个模型的打分和预估值并不是在一个空间中的,打出来的分数并不能放在一起比较,而是需要一定的比例系数进行校正。我们有一种假设:就是在 model1 预测值的均值除以 model2 预测值的均值的比值与类型 1 实际点击率均值除以类型 2 实际点击率均值的比值大致是相当的。这种方式的有点就是计算起来非常简单,但是我们后来仔细想了想这种理论并不是特别严谨,而且它直接依赖了精排层,造成了层与层间的耦合,不利于后续迭代。后来我们就选择了将多个类型的精排模型合并成一个统一评分模型,对多个类型的物品同时进行打分的过程。

这就是我们统一评分模型的一种思想。首先的前提是我们已经有不同类型的模型,然后我们把处理不同类型的模型的特征工程部分也好、以及它的原始 embedding 部分也好等等,只要是可以通过类似拼接、复用的地方都拿出来共同组合成一个新的评分模型。
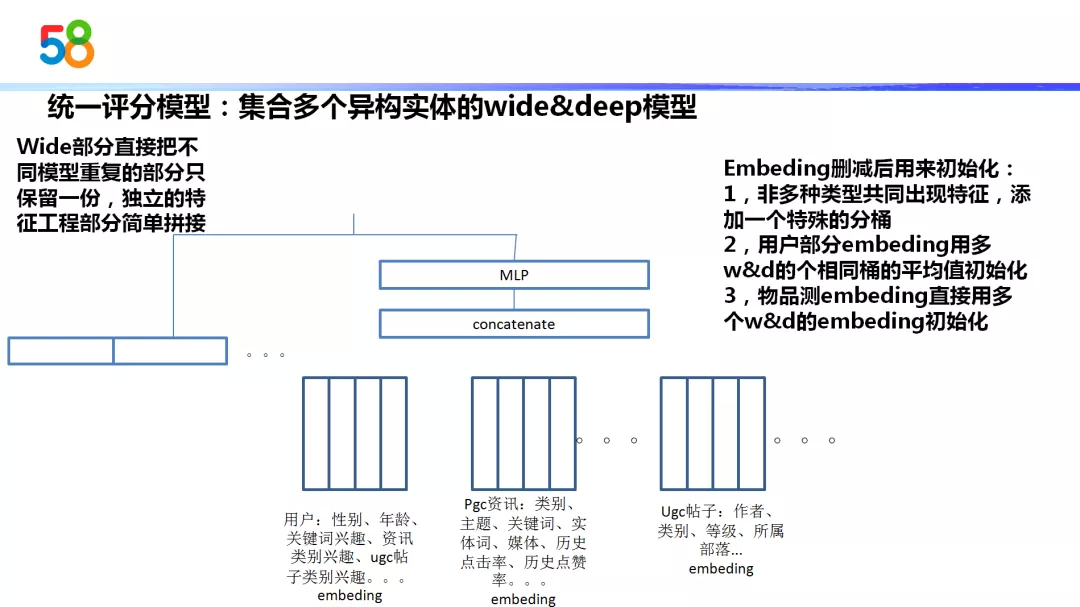
然后我们使用的是什么方法呢?因为我们的精排层采用的是 wide&deep 模型,这样我们每个类型都有一个 wide&deep 模型,我们如何把这多个 wide&deep 模型组合成一个?
首先在 wide 部分,我们把所有模型重复的部分只保留了一份,同时把他们独立的特征工程部分直接复用过来,然后进行一些简单的拼接。在它的 deep 部分,我们把 embedding 进行了一些删减,删减是如何做的呢?
我们首先把没有在多个域中出现的特征添加一个分桶,分桶就表示这个特征没有在其他域中出现,作为一种相当于缺失值吧。
第二个是用户部分的 embedding 和多个 wide&deep 模型的属性和特征相同的桶,我们可以直接把属性和特征拿过来进行复用。还有一种就是用户部分以及多个域之间的 embedding 它是重复训练的,也就是 embedding 在多个域中是有多份,我们采用了取平均值的方法来作为初始化。采用这种结构后它的架构以及 embedding 的初始值很多都是复用了原始的 wide&deep 模型,所以它的训练代价是可控的,同时这一个模型也同时能做到同时对多个域的模型进行打分的效果。
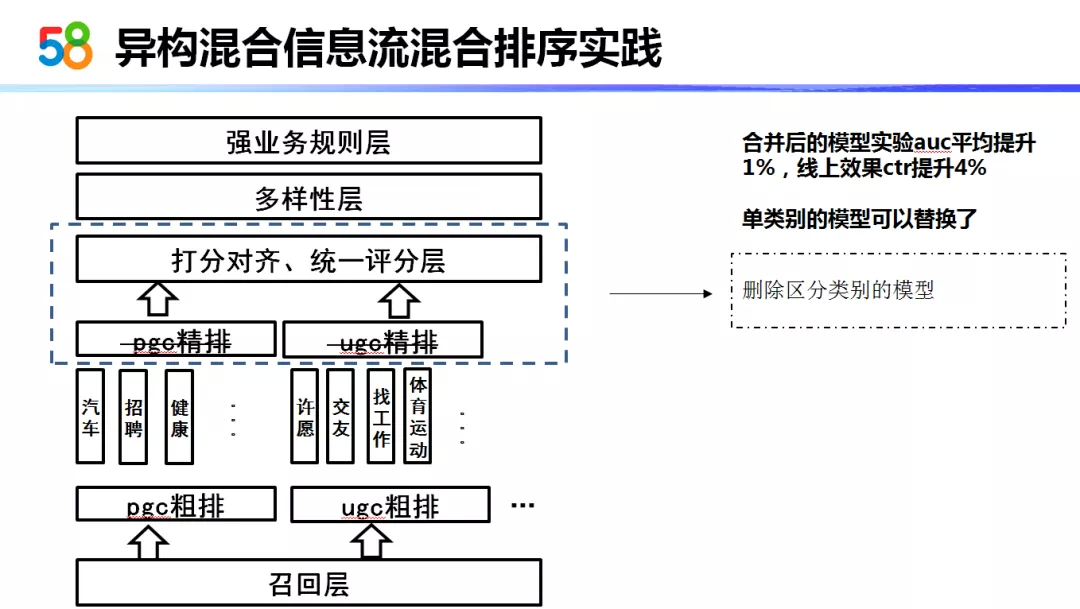
我们实际线上评价以后,我们新的、统一的 wide&deep 模型相比其他各个类型的 wide&deep 模型它的 auc 提升了 1%,同时线上效果 ctr 提升 4%。所以这样一看,后续的各个层的精排模型暂时不需要存在了。为了性能考虑,我们精排层拿掉,只保留了一个统一评分层。

下面讲一下多样性,多样性并不是我们信息流中优化的目标,而是我们希望通过多样性的手段提高业务指标。经过和产品 ( 同学 ) 的探讨,我们把业务目标定义为 3 个:点击率、uv 转化率以及人均浏览条数。其中,提高点击率的目的可以认为是提高用户尽量提高用户的点击概率,提高 uv 转化率的目的可以认为是吸引更多的没有点击的人产生点击,提高人均浏览条数的目的实际是让人们在 feed 流中能够停留更久、看的条数更多。
第一期我们采用的是分类别、交替融合的方式。这种方式相比于直接采用精排分数排序,ctr 和 uvctr 都有一些下降。但是这种结果我们认为是不能接受的,我们发现已经有文献指出多样性和准确性并非完全矛盾。因为,在 feed 中用户没有点击并不一定是 ctr 预估不好,而是用户已经点击了类似的东西,这才导致了下一条内容没有点击。所以我们二期的目的就是找到使得多样性与精确性同时提升的手段。

下面我们将介绍 2 种多样性算法。第一种多样性算法叫做 MMR 算法。MMR 算法的全称是最大边缘相关算法,是一种以减少冗余、保证相关的贪心排序算法。它的主要公式分为两部分:
一部分 Sim 部分,Sim 部分代表了用户和物品的相关度,Sim 部分直接使用了用户与物品统一排序的打分作为用户和物品的相关度。
第二部分实际上就是物品与物品间的相似度。
通过 MMR 算法要找到一个排序结果,既能一定程度上保证内容与用户的相关性,同时在一定程度上保证选出的物品之间的距离要足够大。
这就是 MMR 整体的思想。但其实在实际使用中,我们对 MMR 做了一定的修改。从公式的右侧可以看出,它是采用了物品与物品最大的距离。但实际使用中,我们采用的是每次往里面添加物品时使用的是添加的物品与已在这个集合中物品的平均距离。这样可能会在全局性上保证类别的样数会更多一些。
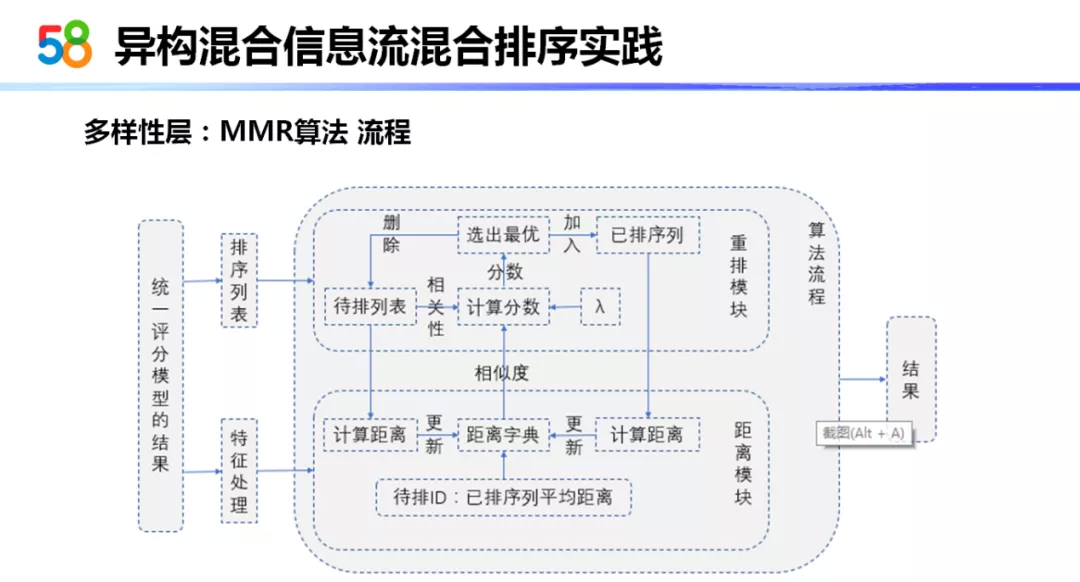
这就是 MMR 算法的整体流程。首先它会有一个计算距离的概念,距离 ( 的计算法方法 ) 我会在下一页 ppt 中介绍。MMR 的整体过程:它会使用贪心的算法,不停地根据λ值计算出的分数选出一个最优,将最优加入排序结果,再重复此选择过程。最终产生一个同时兼顾相关性与多样性的结果。
对于相似度的概念,其实物品与物品的相似度也有很多衡量方法。但是我们在信息流里面处理的是异构的东西,异构的东西我们可能很难通过一种固定的、简单的距离 ( 算法 ) 来衡量物品的相似度。所以我们采用了自定义的距离的方式。
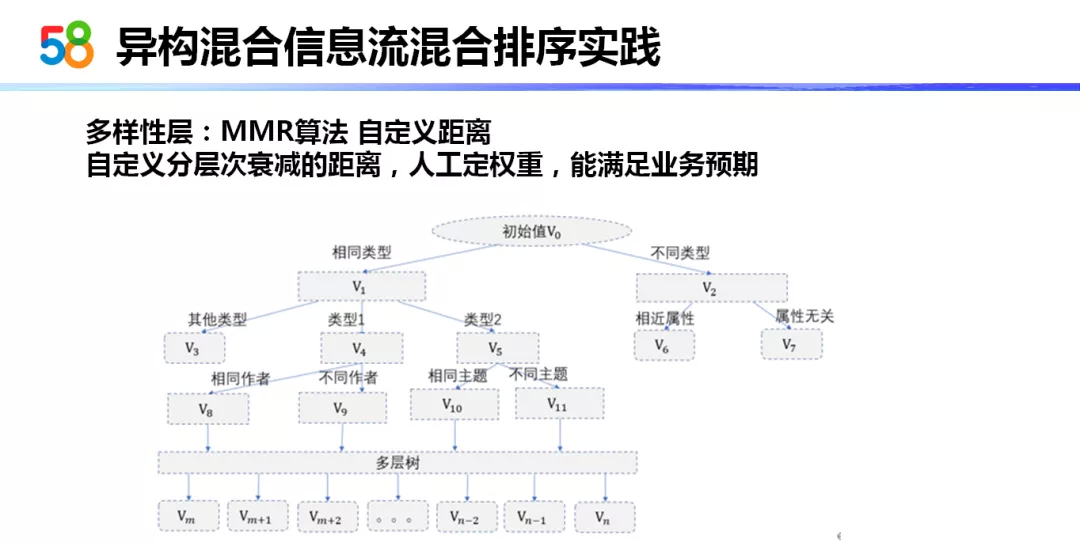
我们自定义距离采用的是一种人工层次来定义距离的方式。我们会设定一个初始值,比如说是 1,当遇到相同类型或不同类型时,我们会设定一种节点上设定一种衰减的方式,下面我们会定义是否满足了处理条件,这些处理条件是符合业务预期然后人工标定的。比如,业务上可能认为如果视频类型和文章类型都是谈论的房产话题就具有一定的相似度。所以我们基于这种树状结构定义了他们 ( 物品 ) 的距离。
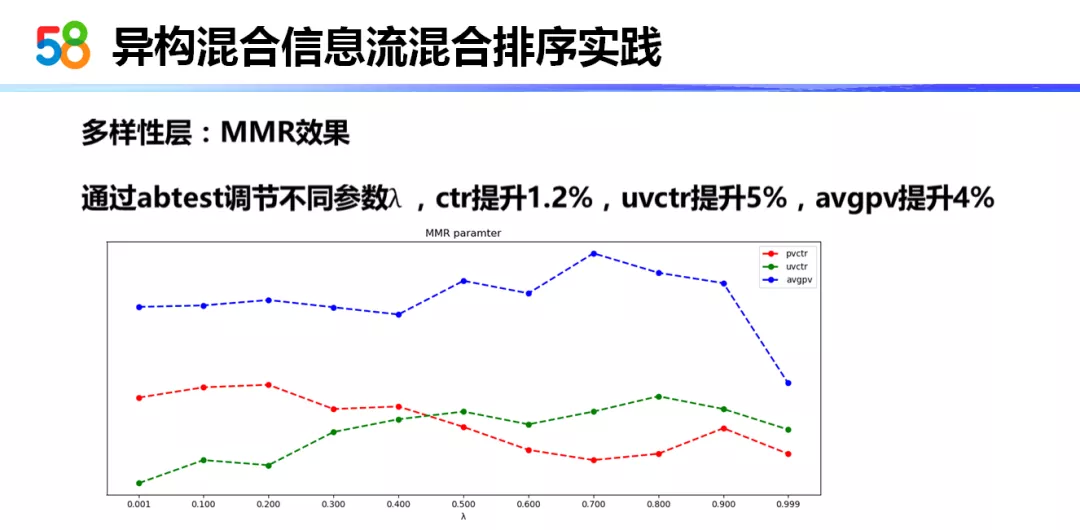
最终我们是通过调节λ值,控制相关性的大小以及相关性和多样性的权衡。这种图中的λ与原始公式中的λ正好相反。也就是说此处的λ正好是对应于多样性逐渐提升的情况。也就是说随着多样性的提升,人均的浏览条数基本是在稳定地增加的。但是我们的点击率会在 0.2 的时候会达到最大值,随着之后多样性的增加,点击率会逐渐下降。但是有一点很特殊的是 UV 转换率,UV 转换率会随着多样性的增加而持续增长,直到在 0.8 左右才开始下降。因此,我们会选择在 0.2 到 0.8 之间的值,这个值会根据产品的目标而进行选择。最终,ctr 可以提升 1.2%,uvctr 提升 5%,人均浏览数提升 4%。

第二种多样性的方法就是 DPP 的方式。DPP 的方式之前 Datafun 的老师已经有介绍过了。我们主要是实现了:
《Fast Greedy MAP Inference for Determinantal Point Process to Improve Recommendation Diversity》
这篇论文里面的算法。简单说一下,DPP 的核心思想是通过子行列式来衡量子集合中的概率大小,通过行列式的大小来衡量子集合的多样性。具体过程由于时间关系在此就不仔细介绍了。
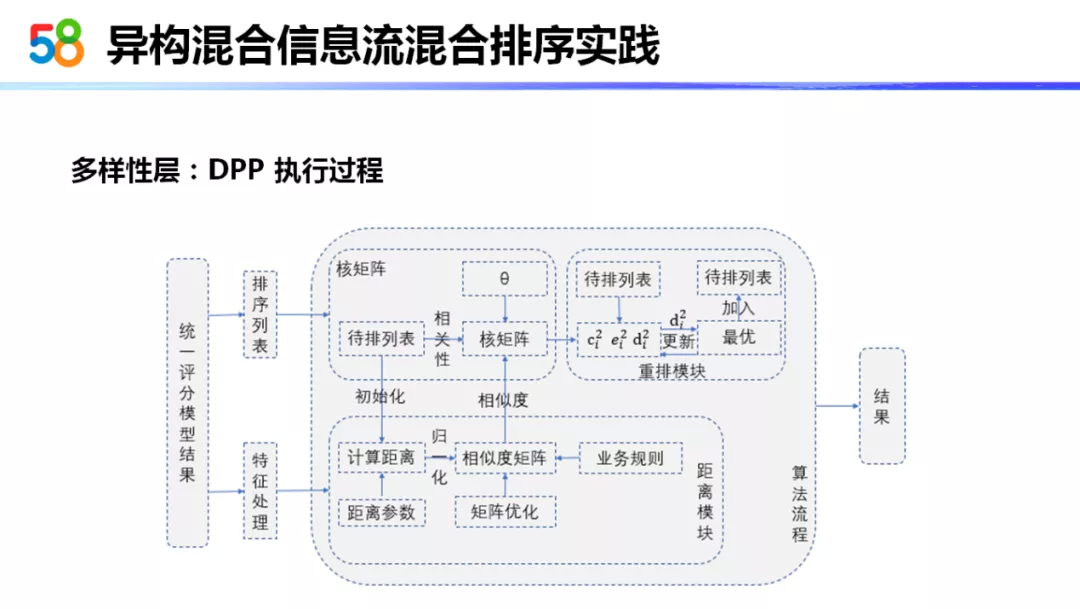
DPP 的执行过程实际上也 MMR 也是类似的。它会通过多样性与相关性间的一个Θ参数来更新核矩阵,也是通过贪心的算法来选择列表。
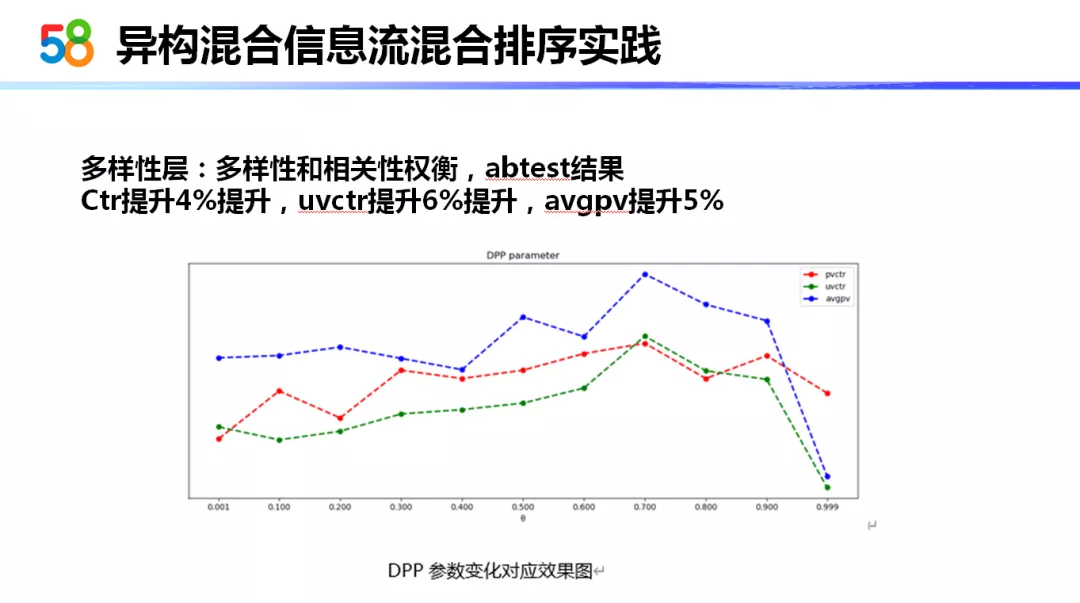
DPP 算法从整体效果上看比 MMR 要好一些。在最好的参数设置情况下,ctr 提升 4%提升,uvctr 提升 6%提升,用户平均浏览数也提升了 5%,整体上应该是优于 MMR 的。我们猜想可能是因为 DPP 相对于 MMR 是通过行列式的方式 ( 优化 ),更考虑了行列式整体的多样性的原因。
06 总结

首先,跨域推荐应该算是是一种思想,它和多任务学习、迁移学习都是有共同点的,其实是殊途同归。
第二点是我们选择算法要有一定的侧重点,要和业务的特点进行结合。比如,我们部落的特点就是它的数据、用户和业务线的重叠非常高;同时我们部落的愿景是它能够打通所有的业务线,所以我们把跨域推荐的技术当成了我们的一个方向。
第三点是算法部门优化方向要和业务部门一致。比如说我们不能因为单纯优化多样性目标反而带来业务目标的下降。还有就是我们的优化方向是要提高业务整体的指标,不能只优化其中一点,导致把另一个地方的流量搬运到了这个地方,这样也是不合适的。
最后一点还是多样性,多样性作为手段。多样性也有很多指标,我们并没有强调要将多样性的指代做到具体多少。因为我们通过部落中有人工体验师发现:在人看来多样性只要达到了一定的程度,多样性高一点或低一点其实在人看来没有太大区分度。所以我们并不过分追求多样性,而是将其作为手段用以提升业务指标。
今天的分享就到这里,谢谢大家。
作者介绍:
周建斌,58 同城算法架构师
58 部落推荐算法策略负责人,目前负责 58 部落推荐算法相关的整体建设和优化,包括部落画像建设、内容分析、召回、排序等,致力于提升 58 部落的用户活跃度和用户粘性,以及配合传统业务线提升整个 58 的用户体验。
本文来自 DataFunTalk
原文链接:

中国开发者画像洞察报告 2022
本次报告为你深度解读开发者人群背景,分析开发者群体面临的挑战,洞察开发者人群特征,预测开发者生态发展...









评论