

这是探索 Kafka 存储层和处理层核心基础系列文章的第三篇。第二篇文章讨论了 Kafka 的存储层:主题、分区和代理,以及存储格式和分区机制。在这篇文章中,我们将介绍流和表、数据契约、消费者群组,以及如何通过这些东西实现大规模数据并行处理。
我们先从存储在主题中的事件开始,看看如何访问这些事件,并把它们转成流和表。
从存储到事件处理
主题位于存储层,是 Kafka“文件系统”的一部分。相反,流和表是 Kafka 处理层的东西,ksqlDB 和 Kafka Streams 会用到流和表。这些工具将“原始”主题中的事件转成流和表,就像关系型数据库将磁盘文件里的字节转成数据库表一样。
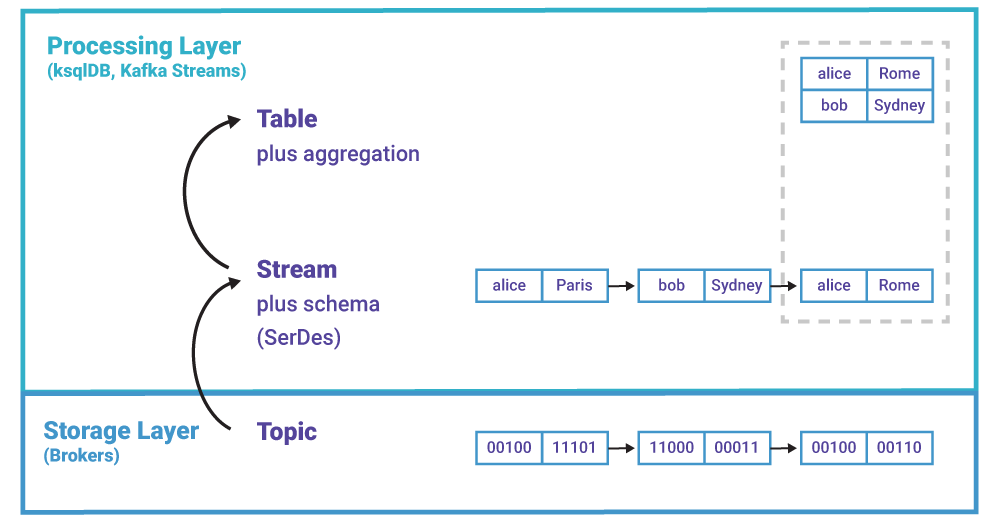
图 1. 主题位于存储层,流和表位于处理层
在 Kafka 中,事件流就是带有 schema 的主题。事件的键和值不再是字节数组,它们具有具体的类型,这样就可以知道数据里包含了什么。与主题一样,流也是没有边界的。
下面的示例使用<eventKey, eventValue>来表示事件的键和值。例如,<byte[], String>表示事件的键是字节数组,事件的值是一个字符串。我们也可以使用更为复杂的数据类型,例如 Avro schema 中定义的 GeoLocation 类型。
示例 1:<byte[], byte[]>类型的主题被消费者客户端反序列化为<String, String>类型的事件流。或者,我们也可以使用更为便利的类型,比如<User, GeoLocation>,我更倾向于选择这种类型。
下面是将主题转为流的示例代码:
ksqlDB:https://gist.github.com/confluentgist/2e9f37db0d9810044f6836f48b267fcd
Kafka Streams:https://gist.github.com/confluentgist/c26c68f18959d1ee8a18a8ac94333d0c
表也就是普通技术意义上的表。在 Kafka 中,表更像是 RDBMS 中的物化视图。与事件流一样,表也是聚合的流。
当然,我们也可以直接基于主题来创建表。在实际当中,表是有边界的,也就是说,数据行是有限的,因为一个公司的客户是有限的,公司产品的数量是有限的。但表也可以是无边界的,就像流那样。例如,我们持续不断地往一个表中加入行(事件),每一行的键都是一个 UUID。
示例 2:<String, String>类型的事件流被聚合成一个<String, String>类型的表,用于追踪用户位置。这个示例如图 1 所示。
下面是将主题转为表的示例代码:
ksqlDB:https://gist.github.com/confluentgist/450505b3c4d08c6c641d272d63234349
Kafka Streams:https://gist.github.com/confluentgist/3b25acf0d1d723dfcdacc7f00e23f296
示例 3:<String, String>类型的流被聚合成<String, Long>类型的表,用于追踪用户访问过的位置的数量。聚合操作持续不断地计算位置数量,并更新表。
数据契约和 schema
之前已经说过,消费者客户端基于某种 schema 将 Kafka 消息从原始字节反序列化成事件。schema 可以是正式的 Avro 或 Protobuf,也可以是非正式的 JSON 格式。
问题是,一个消费者客户端怎么知道该如何反序列化保存在主题里的事件?因为事件通常是由不同的客户端生成的。答案是:生成者和消费者必须达成某种数据契约。Gwen Shapira 之前写了一篇文章,介绍了数据契约和schema管理,我在这里就不再累述了。总的来说,最简单的办法是使用 Avro 和 Confluent Schema Registry。
Confluent Platform 5.4 及以上版本支持在代理端进行集中式的 schema 验证,这样客户端就不会违反数据契约:服务器端在将事件保存到主题之前会进行验证。
处理层也是分区的
在 Kafka 里,处理层也是分区的,就像存储层那样。主题里的数据是按分区来处理的,这种方式也适用于流和表的处理。为了更好地理解这种处理机制,我们需要先了解 Kafka 的消费者群组概念。
Kafka 支持大规模数据并行处理,而并行处理是通过运行大量分布式应用程序实例来实现的。
这些应用程序实例需要动态组成 Kafka 消费者群组,通过协作的方式读取同一个主题的数据。在 Kafka Streams 应用程序中,群组的成员关系是通过 application.id 来设置的,在 ksqlDB 集群中,成员关系是通过 ksql.service.id 来设置的,而在其他 Kafka 消费者客户端中,成员关系是通过 group.id 来设置的。
假设我们开发了一个 Kafka Streams 分布式欺诈检测应用程序,用于并行处理 payments 主题里的海量数据,所有应用程序实例都属于 fraud-detection-app 群组。应用程序与 Kafka 集群部署在一起,通过网络读取和写入事件。
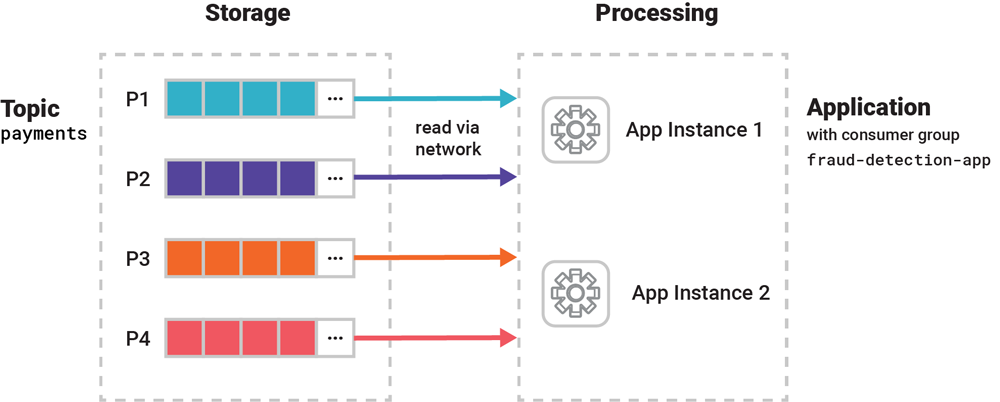
图 2. 这个分布式应用程序有两个实例,组成了一个 Kafka 消费者群组。它们共同协作并行处理输入数据。
在一个群组中,每个消费者实例分到一部分数据(一个或多个分区),各个消费者之间的数据是独立的。Kafka 的消费者群组协议会自动监测是否有新的消费者加入群组或者是否有消费者离开群组,然后自动重新分配负载和分区,这样就可以继续处理数据。
在 Kafka 中,这个协调过程叫作再均衡,是消费者群组协议的一部分。当一个新的 ksqlDB 服务器加入到 ksqlDB 集群中时会触发再均衡,或者当一个 Kafka Streams 应用程序实例宕机也会发生再均衡。再均衡是在应用程序运行时完成的,不会造成数据丢失或导致数据处理不正确。
stream 任务是并行处理的最小单元
图 2 的内容经过了简化,我们需要进一步把应用程序实例放大了来看。实际上,并行处理的最小单元并不是应用程序,而是 stream 任务。一个应用程序可以运行零个、一个或多个 stream 任务。主题、流或表的分区按照 1 比 1 的比例分配给这些任务。借助 Kafka 的消费者群组协议,当一个应用程序实例加入或离开群组,就会触发再均衡,这些 stream 任务被重新分配给应用程序实例。
例如,假设应用程序处理的主题有 4 个分区,从 P1 到 P4,那么就会有 4 个 stream 任务分别处理这 4 个分区。这 4 个任务被均匀地分配给应用程序实例。如果有 2 个应用程序实例,每个实例将运行 2 个任务。
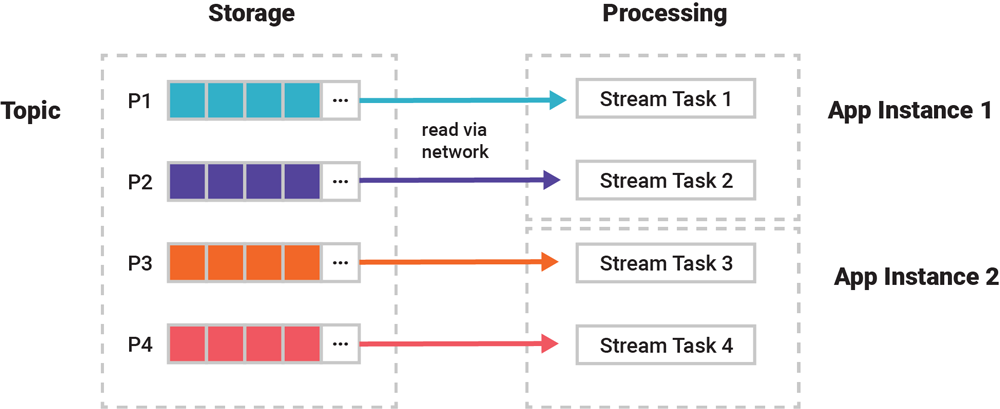
图 3. 分区按照 1 比 1 的比例分配给 stream 任务
这种 1 对 1 分区到任务的分配方式说明主题中的数据是按分区来处理的。在第一篇文章中,我们说“将具有相同键的事件保存到同一个分区”。现在我们知道,将“相关事件”保存到同一个分区有多重要了,因为如果不这么做,我们就没有办法统一处理它们,而且在大多数情况下没有办法按顺序处理它们。
在介绍了 Kafka 消费者群组和 stream 任务的概念之后,我们再来看看这些对于流和表来说意味着什么。
流是分区的,处理过程也是
简单地说,流就是带有 schema 的主题,所以流的处理与之前讲的差不多,唯一的额外步骤是应用程序会应用 schema,将主题里的数据转为“类型”流,或者将流里的数据写入主题。其他的东西,比如每一个 stream 任务负责处理自己的流分区、在应用程序加入或离开时重新分配任务,这些与之前讲的都一样。
表是分区的,处理过程也是
表则更为有趣一些。如果一个应用程序为了处理下一个事件必须记住上一个事件的某些东西,我们就它叫作有状态的应用程序,被记住的东西叫作状态。
表就是应用程序状态的一种形式。假设你要计算各个地区总销售额的聚合表,就要记住当前德国(状态)的总销售额,然后在后面再加入德国地区的新销售额(新的事件),并将其更新。在分布式系统中,要维护好状态,并在面临基础设施可能发生故障的情况下维护大规模的状态是一个巨大的挑战。这也就是为什么像 Cassandra 这样的 NoSQL 数据库会崛起,传统的 RDBMS 数据库无法满足现今海量数据的伸缩需求。接下来我们来看看 Kafka 中的表是如何进行状态管理的。
与流一样,表也是分区的。我们之前讨论的流的分区处理方式同样适用于表。但与流不一样的是,表需要维护事件之间的状态,这样才能进行聚合操作(比如 COUNT())。表的状态管理是通过状态存储实现的,它实际上是轻量级的键值存储。
每个表都有自己的状态存储。针对表的每一个操作,比如查询、插入或更新,都对应状态存储的一个操作。状态存储位于应用程序的本地磁盘或 ksqlDB 服务器上。把状态保存在本地的好处是不需要把表和其他状态放到内存中,这个好处在需要处理大量状态(几十 GB 或更多)或在便宜云实例上运行应用程序时得以体现。
为了支持容错和弹性,状态存储被保存在远程的 Kafka 中,稍后我们会讲到。也就是说,Kafka 是表数据的事实来源,就像流那样。之前提到的本地物化表(使用内置的 RocksDB 作为默认引擎)对于数据“安全性”来说并不是实质性的。我之所以强调这一点,因为我经常会被问到与 RocksDB 相关的问题,这就好比说,降落伞的颜色与它安不安全其实没有什么关系。
表的状态存储也被分成了多个分区(在 Kafka 官方文档中,这种分区被称为状态存储实例),如果一个表有 10 个分区,那么它的状态存储也会有 10 个分区。在处理过程中,每个 stream 任务负责维护一个状态存储分区,所以我们可以说 stream 任务是有状态的。
在下图中,任务 1 将从蓝色的分区 P1 读取事件。在 Kafka 中,分区的概念无处不在。这种基于分区的非共享分布式设计让 Kafka 的处理层具备了很强的伸缩性。
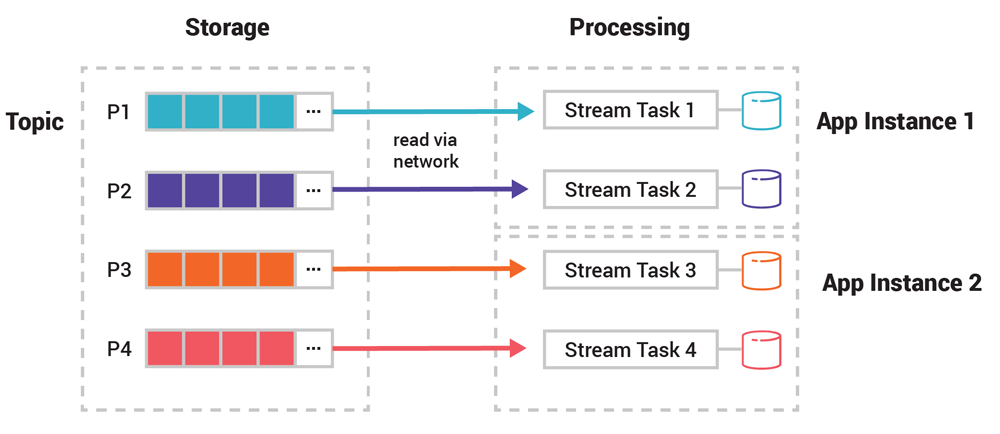
图 4. 在处理表时,每一个 stream 任务需要维护一个状态存储
你可能会想,那么表和状态存储之间有什么区别呢?首先,每张表通常只有一个状态存储,但反过来并不成立。Kafka Streams 应用程序开发者可以借助 Processor API 直接操作底层的状态存储,不需要用到表。但如果你使用的是 ksqlDB,那就不能这么做,因为状态存储只是其内部的实现细节。其次,正如之前所说的那样,表是不能直接修改的,就像 RDBMS 的物化视图一样。状态存储为开发者提供了读写能力,比如 put(key, value)或 get(key),可以用它们来查询、插入、更新或删除数据。
那么,应用程序或 ksqlDB 服务器中的一张表会占用多大空间?我们假设把一个包含 4 个分区的主题的数据读取到一张表中,数据大小为 12GB,这些数据会被分到表的 4 个分区中,每个分区的大小因数据的特征而有所不同:第二个分区可能是 3GB,第三个分区可能是 5GB。分区函数ƒ(event.key, event.value)是决定数据分布最关键的因素。
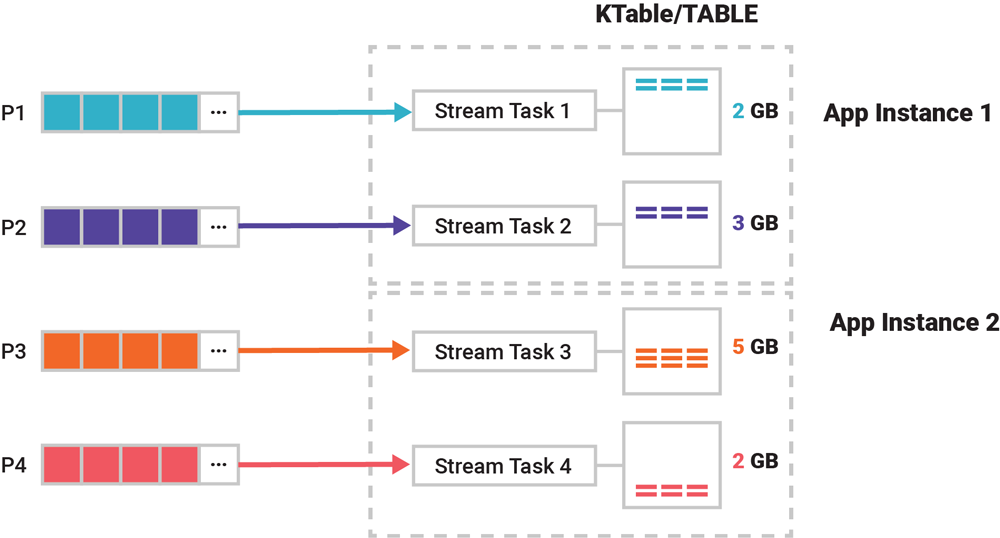
图 5. 应用程序将主题中的数据转成表
全局表不是分区的
Kafka 处理层的分区设计对于伸缩性和性能来说起到非常关键的作用。但在某些情况下,我们需要操作所有的事件,这个时候需要用到全局表。与一般的表不一样,全局表不是分区的。对于之前的那个示例,每个任务需要处理所有的 12GB 数据。如果你要向所有任务广播信息,或者希望在不对输入数据进行分区的情况下进行连接,那么全局表就非常有用。但要注意,目前只有 Kafka Streams 支持全局表,ksqlDB 还不支持。
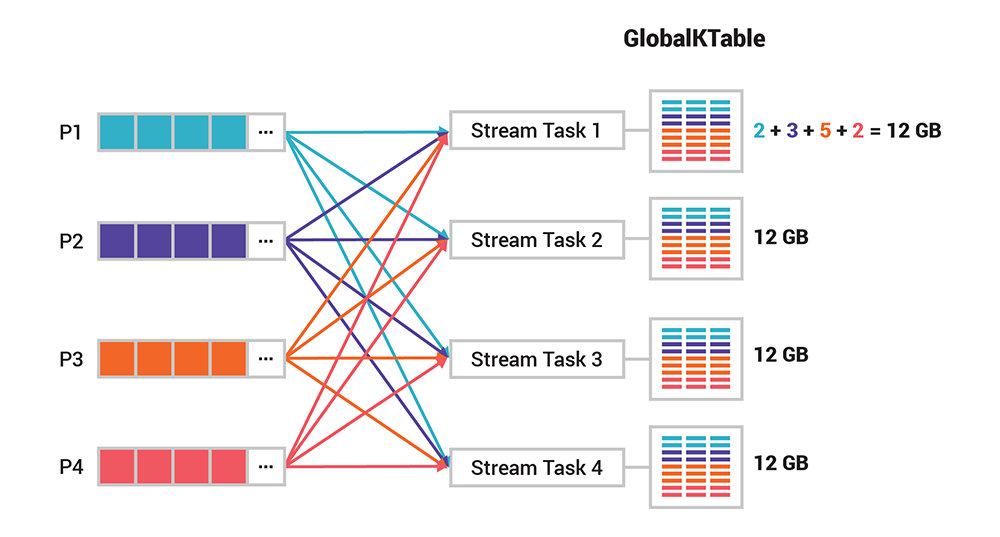
图 6. 与普通的分区表不一样,每一个 stream 任务都可以访问全局表的所有数据
流、表和主题的对比
让我们快速回顾一下到目前为止所讲的东西:
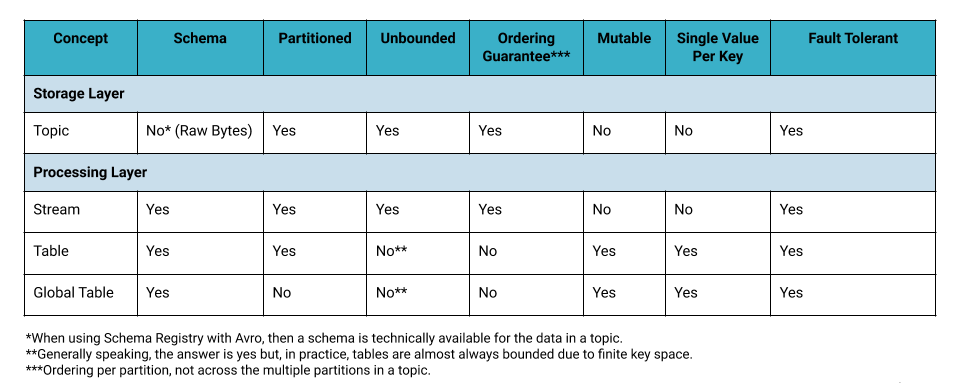
总结
在这篇文章中,我们介绍了 Kafka 的处理层,了解了流和表,以及 Kafka Streams 和 ksqlDB 的分布式处理架构。在下一篇文章中,我们将回顾本文的内容,并深入了解 Kafka 的弹性伸缩能力和容错能力。
原文链接:
https://www.confluent.io/blog/kafka-streams-tables-part-3-event-processing-fundamentals/
系列文章:

Java 避坑指南:Java 高手笔记代码篇
本迷你书包括 86 个业务开发中常见踩坑点。每一个知识点都相当的实用,是程序员业务开发中的必备避坑指南...










评论