

关系型数据库已经存在很长时间了。数据的关系模型是 E.F. Codd 在 20 世纪 70 年代提出的,而支撑当今主要关系型数据库管理系统的核心技术是在 1980 到 1990 年代开发的。关系型数据库的基础,包括数据关系、ACID(原子性、一致性、隔离性、持久性)事务和 SQL 查询语言,都经受住了时间的考验。这些基本特性使关系型数据库备受全世界的用户欢迎。它们仍然是许多公司 IT 基础设施的基石。
当然,这并不是说系统管理员一定喜欢处理关系型数据库。几十年来,管理关系型数据库一直是一项高技能、劳动密集型任务,是一项需要专用系统以及数据库管理员全神贯注的任务。在保证容错性、性能和爆炸半径(故障的影响)的同时,扩展关系型数据库一直是管理员面临的一项持久性挑战。
与此同时,现代互联网工作负载的要求越来越高,需要基础设施具备以下几个基本特性:
用户希望最开始能够是很小的内存占用,然后在不受基础设施限制的情况下大规模扩展。
在大型系统中,失败是一种常态,而不是例外。客户工作负载必须与组件故障或系统故障隔离。
爆炸半径小,没有人希望单个系统故障对他们的业务产生很大影响。
这都是些困难的问题,解决这些问题需要摆脱老式的关系型数据库体系结构。当 Amazon 面临 Oracle 等老式关系型数据库的限制时,我们创建了一个现代关系型数据库服务 Amazon Aurora。
Aurora 的设计保留了关系型数据库的核心“事务一致性”这个优势,在存储层进行了创新,创建了一个为云构建的数据库,可以在不牺牲性能的情况下支持现代工作负载。这也是客户喜欢的一点,因为 Aurora 以十分之一的成本提供了商用数据库的性能和可用性。自发布以来,它就一直是 AWS 历史上增长最快的服务。
在这篇文章中,我想简单介绍下我们是如何构建 Aurora 的,同时还会讨论为什么客户采用它的速度比 AWS 历史上任何其他服务都要快。
新概念关系型数据库
首先,我们先来看一下旧式关系型数据库的体系结构:
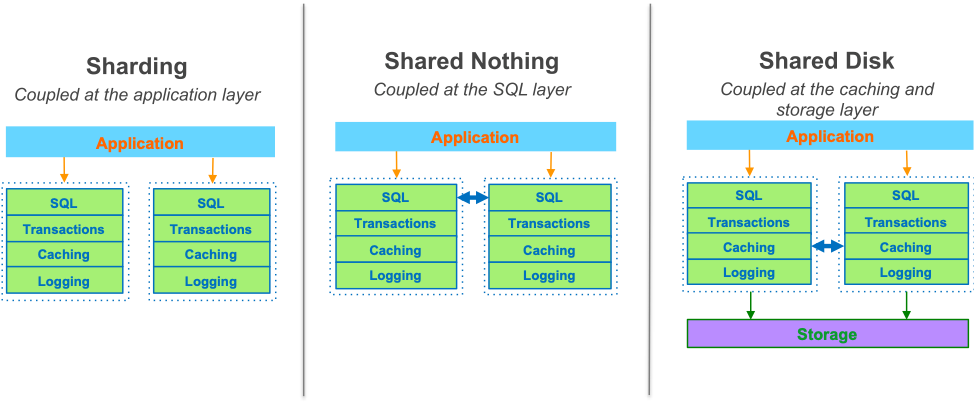
在过去的 30 到 40 年里,这种整体式关系型数据库栈没有发生太大的变化。虽然存在不同的用于扩展数据库的传统方法(例如分片、无共享或共享磁盘),但它们都共享相同的基本数据库体系结构。由于紧耦合的整体式栈的基本限制仍然存在,所以在规模较大的情况下,它们没有解决性能、弹性和爆炸半径的问题。
为了着手解决关系型数据库的限制,我们通过将系统分解为基本的构建块重新定义了栈。我们认识到,缓存层和日志层的创新时机已经成熟。我们可以将这些层移动到一个专门构建的、可扩展的、自修复的、多租户的、数据库优化的存储服务中。当我们开始构建这个分布式存储系统时,Amazon Aurora 就诞生了。
我们挑战了关系型数据库中缓存和日志记录的传统思想,重新设计了数据库 I/O 层,并获得了较大的可伸缩性和弹性优势。Amazon Aurora 具有显著的可伸缩性和弹性,因为它支持卸载重做日志、基于单元的体系结构、仲裁和快速数据库修复。
重做日志卸载:日志即数据库
传统的关系型数据库以页的形式组织数据,当对页进行修改时,必须定期将它们刷新到磁盘。为了提高故障恢复能力和维持 ACID 语义,页修改也记录在重做日志记录中,这些日志记录会以连续流的形式写入磁盘。虽然这种体系结构提供了支持关系型数据库管理系统所需的基本功能,但是效率很低。例如,一个逻辑数据库写操作会变成多个(最多五个)物理磁盘写操作,从而导致性能问题。
数据库管理员试图通过减少页刷新的频率来解决写放大问题。这反过来又加剧了崩溃恢复时长的问题。刷新间隔越长,意味着需要从磁盘读取更多的重做日志记录,并应用重做日志记录来重构正确的页映像。这会导致恢复变慢。
在 Amazon Aurora 中,日志即数据库。数据库实例将重做日志记录写入分布式存储层,存储层根据需要从日志记录构造页映像。数据库实例永远不必刷新脏页,因为存储层总是知道页是什么样子。这改进了数据库多个方面的性能和可靠性。由于消除了写入放大并使用了可扩展存储机群,写入性能大大提高。
例如,与在类似硬件上运行的 Amazon RDS for MySQL 相比,Amazon Aurora MySQL 兼容版在 SysBench 基准上展现出了 5 倍的写 IOPS。数据库崩溃恢复时间大大缩短,因为数据库实例不再需要执行重做日志流重放。存储层负责在页读取时应用重做日志,从而产生一个不受遗留数据库体系结构限制的新存储服务,由此,你可以进行更进一步的创新。
基于单元的体系结构
就像我之前说的那样,任何东西都总是会出现故障。在大型系统中,组件会出现故障,而且会常常出现。整个实例出现故障。网络故障可以隔离大量的基础设施。在少数情况下,整个数据中心会因为自然灾害而变成孤岛或崩溃。在 AWS,我们针对故障进行设计,并依赖基于单元的体系结构在问题发生之前进行处理。
AWS 有多个地理“Region”(20 个并且还在增加),在每个 Region,我们有几个“可用性区域(Availability Zones)”。利用多个 Region 和 Zone,可以在不影响服务可用性的情况下,使设计良好的服务在普通组件故障和较大的灾难中幸存下来。Amazon Aurora 将所有写复制到三个 Zone,以提供更好的数据持久性和可用性。事实上,Aurora 可以在不丢失数据可用性的情况下容忍整个 Zone 的丢失,并且可以从较大的故障中快速恢复。
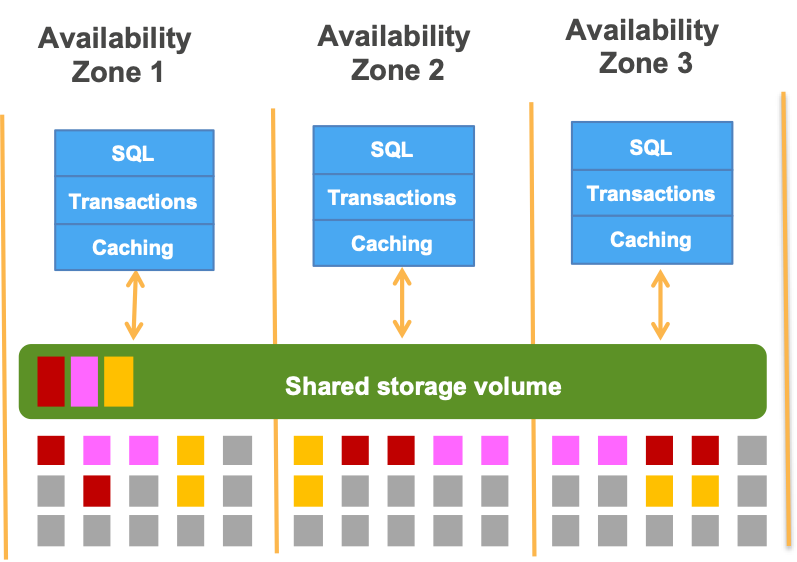
然而,众所周知,复制是资源密集型的过程,那么是什么使 Aurora 能够在提供高性能的同时提供健壮的数据复制呢?答案就在仲裁中。
仲裁之美
任何东西都总是会出现故障。系统越大,某个地方发生故障的可能性就越大:网络链接、SSD、整个实例或软件组件。即使软件组件没有 Bug,它仍然需要定期重启升级。
传统的方法是阻塞 I/O 处理,直到可以执行故障转移(并且在出现故障组件时以“降级模式”运行),这种方法在规模较大时会产生问题。应用程序通常不能很好地容忍 I/O 故障。通过中等复杂的数学计算就可以证明,在大型系统中,随着系统规模的增长,在降级模式下运行的概率接近 1。然后,还有一个非常隐蔽的问题“灰色故障(gray failures)”。当组件没有完全失败,而是变得很慢时,就会发生这种情况。如果系统设计没有预见到这种降级,那么低速齿轮会降低整个系统的性能。
Amazon Aurora 使用仲裁来解决组件故障和性能下降的问题。写仲裁的基本思想很简单:写尽可能多的副本,以确保读仲裁读总是可以找到最新的数据。最基本的仲裁示例是“2 / 3”:
Vw+Vr > V
Vw > V / 2
V=3
Vw=Vr=2
例如,你可能有三个物理写操作要执行,而写仲裁为 2。在逻辑写操作被宣布成功之前,你不必等待这三个操作都完成。如果一个写操作失败或者很慢,也没关系,因为总体操作结果和延迟不会受到异常值的影响。这很重要:即使有的东西坏了,也可以写得又快又成功。
简单的 2/3 仲裁将使你可以容忍整个可用性区域的丢失。但这还不够好。虽然区域丢失是一个罕见的事件,但它并不会降低其他区域的组件失败的可能性。使用 Aurora,我们的目标是可用性区域+1:我们希望能够容忍一个区域的丢失外加一个失败,而不会造成任何数据持久性损失,并且对数据可用性的影响最小。我们使用 4/6 仲裁来达到这个目的:
Vw+Vr > V
Vw > V / 2
V=6
Vw=4
Vr=3
对于每个逻辑日志写,我们发出 6 个物理副本写,并认为当其中 4 个写完成时,写操作就成功了。每个区域使用两个副本,如果整个可用性区域出现故障,仍然需要能够完成写操作。如果某个区域宕机并发生其他故障,你仍然可以实现读仲裁,然后通过快速修复快速恢复写能力。
快速恢复并加紧弥补
数据复制有不同的做法。在传统的存储系统中,数据镜像或擦除编码发生在整个物理存储单元的级别,多个单元组合成一个 RAID 数组。这种方法使修复变得缓慢。RAID 阵列重建性能受阵列中少量设备的能力限制。随着存储设备变大,重建期间需要复制的数据量也会变大。
Amazon Aurora 使用完全不同的复制方法,基于分片和可扩展架构。Aurora 数据库卷逻辑上分为大小为 10-GiB 的逻辑单元(保护组),每个保护组通过六路复制到物理单元(段)中。单个存储段分布在一个大型分布式存储机群中。当故障发生并取出一个段时,单个保护组的修复只需要移动大约 10 GiB 的数据,这在几秒内就可以完成。
此外,当必须对多个保护组进行修复时,整个存储机群将参与修复过程。这提供了巨大的带宽,从而可以完成整个批次的快速修复。因此,如果一个区域丢失之后又出现另一个组件故障,对于给定的保护组,Aurora 可能会丢失几秒钟的写仲裁。然而,一个自启动的修复其后会以极快的速度恢复可写性。换句话说,Aurora 存储器能迅速自我修复。
如何能够对数据进行六路复制并保持高性能的写操作?这在传统的数据库体系结构中是不可能的,因为在传统的数据库体系结构中,全部页或磁盘扇区都会被写到存储中,网络将被淹没。相比之下,在 Aurora 中,实例只将重做日志记录写入存储器。这些记录要小得多(通常是几十到几百个字节),这使 4/6 写仲裁成为可能,而且不会使网络过载。
写仲裁的基本思想意味着某些段可能不会总是在一开始就接收所有的写。这些段如何处理重做日志流中的缺口?Aurora 存储节点之间会不断地“传播”以填补漏洞(并执行修复)。日志流的处理过程是通过日志序列号(LSN)管理紧密协调的。我们使用一组 LSN 标记来维护每个单独段的状态。
读取呢?读仲裁的代价很高,最好避免。客户端 Aurora 存储驱动程序会跟踪哪些写入成功了。它不需要在常规页读取上执行仲裁读,因为它总是知道从哪里获取页的最新副本。此外,驱动程序跟踪读取延迟,并始终尝试从过去已经证明的延迟最低的存储节点读取。惟一需要读仲裁的场景是在数据库实例重新启动期间的恢复过程。LSN 标记的初始集必须通过询问存储节点来重构。
创新基础
分布式、自修复的存储体系结构为许多引人注目的 Aurora 新特性提供了直接支持。举几个例子:
读可扩展性:除了主数据库实例之外,还可以跨 Aurora 中的多个区域提供多达 15 个读副本,以实现读可伸缩性和更高的可用性。读副本使用与主服务器相同的共享存储卷。
连续备份和时间点还原:Aurora 存储层连续透明地将重做日志流备份到 Amazon S3。你可以在配置好的备份窗口中对任何时间戳执行时间点还原。不需要对快照创建进行调度,当快照距离我们感兴趣的时间点较远时,不会丢失任何事务。
快速克隆:Aurora 存储层可以快速创建卷的物理副本,而不需要复制所有页。页最初是在父卷和子卷之间共享的,当页被修改时,就完成了写时复制。在克隆卷时没有重复开销。
回溯:一种使数据库及时回到特定位置的快速方法,不需要从备份中进行完全恢复。不小心丢了一张表?你可以用 Aurora 回溯让时间倒流。
在 Aurora 存储引擎的基础上,还有很多关系型数据库的创新。我们都进入了关系型数据库的新时代,Aurora 只是一个开始。另外,也得到了客户的认可,Capital One、道琼斯、Netflix 和 verizon 等所有行业的领导者都将关系型数据库的工作负载迁移到 Aurora。
查看英文原文:Amazon Aurora ascendant: How we designed a cloud-native relational database

暂无签名

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论 1 条评论