

Kylin 在滴滴的应用 &架构
Kylin 在滴滴的三类应用场景
第一类是产品类的需求,这一类需求的特点比较明显,即用户要求整个查询的响应时间非常小,理论上都是秒级而且稳定;同时各产品 RD 的接入成本需要特别低,一般的 RD 可能不是很擅长大数据技术,不太清楚怎么用 Spark、Hbase 进行数据查询,他们通常最擅长就是通过 JDBC 去连接,然后用标准的 SQL 进行操作。引入 Kylin 后可以极大地提高这类用户对接大数据的效率(之前如果产品要通过大数据查询报表数据,一般有两种做法:一种是将数据通过离线算好后再导回 MySQL,另一种是离线算好后灌入第三方存储如 HBase,再通过 KV 或者 Phoenix 查询)。
第二类需求是报表类的需求,在滴滴接入的主要是自定义的报表。滴滴有一个类似于 tableau 报表系统的自研平台,运营分析人员可以在上面自助配置相应的报表,Kylin 主要起到加速作用。
第三类需求是活动营销,包括事前范围分析,以及事后营销结果分析,这也是在 Kylin 上面做的。活动营销这一类的 cube,其生命周期可能不是太长,通常在一到两个月之间。
滴滴 Kylin 集群现状
目前,Kylin 在滴滴一共有六个集群,其中五个在国内,另一个在国外。当前线上的主要版本还是 Kylin 2.0,但滴滴目前正在把 2.0 往 3.0 迁移,所以在国内也搭建了 Kylin 3.0 集群。目前 Cube 数量大概在三千二百个左右,每天构建任务数大约有四千多个,HBase 表规模在五万左右。
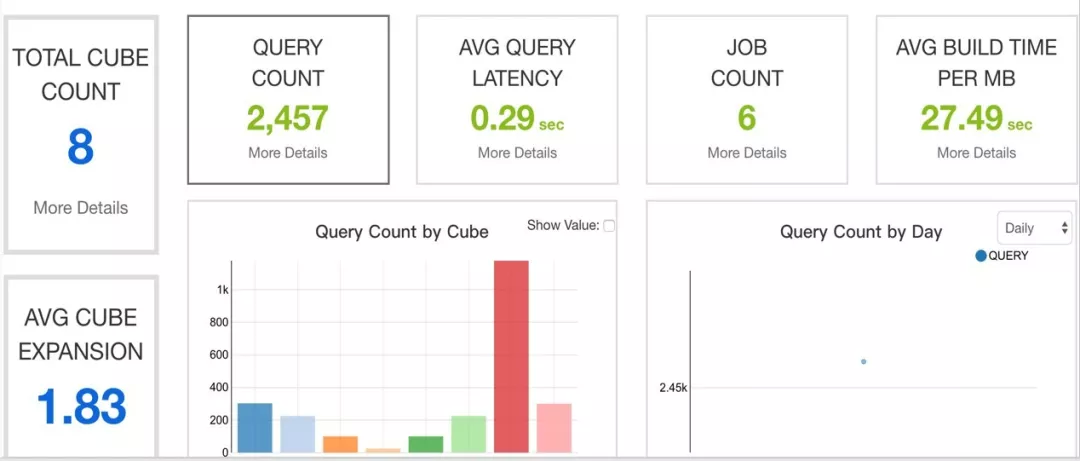
这是 Kylin 3.0 的截图,可以发现它整个查询时延还是非常低的,基本上平均时延在 0.29 秒,而这还可以更快。另外数据膨胀也比较低,差不多是 1.83 的量级。
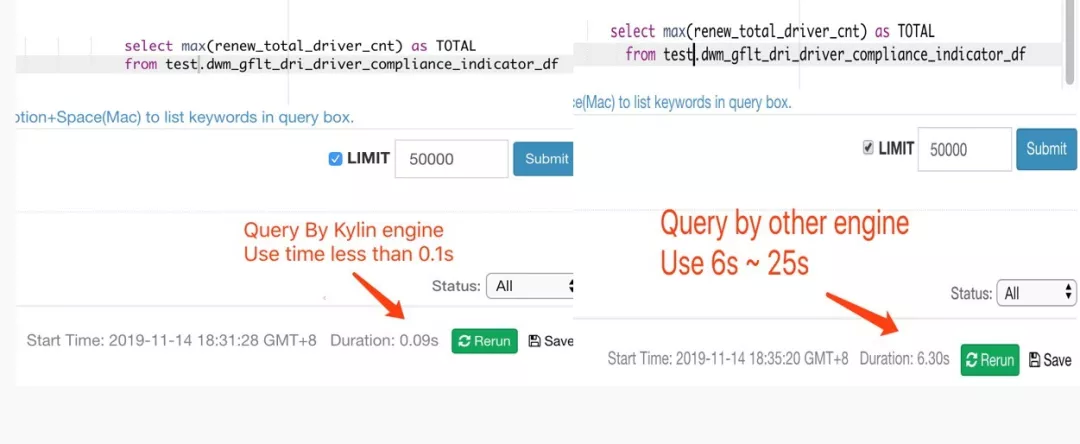
这个是一个 Presto 对比 Kylin 的查询截图,查询数据量不太大。Kylin 稳定在 0.1 秒以内反馈结果,而 Presto 需要 6 到 25 秒,Kylin 对于命中了 Cuboid 的查询在时间和稳定性都表现出色。
目前滴滴 Kylin 3.0 对接了 Presto 作为下推引擎,解决用户提交未建模(Cube)的 SQL 查询时也可以拿到结果的需求,当然响应时长可能会有一定差别。
使用 Kylin 过程中的痛点及解决方式
1. 易用性、灵活性
Kylin 在稳定性和易用性,以及释放数仓人员的双手等方面做了很多工作,但是也会有一些易用性或者灵活性上面的问题。
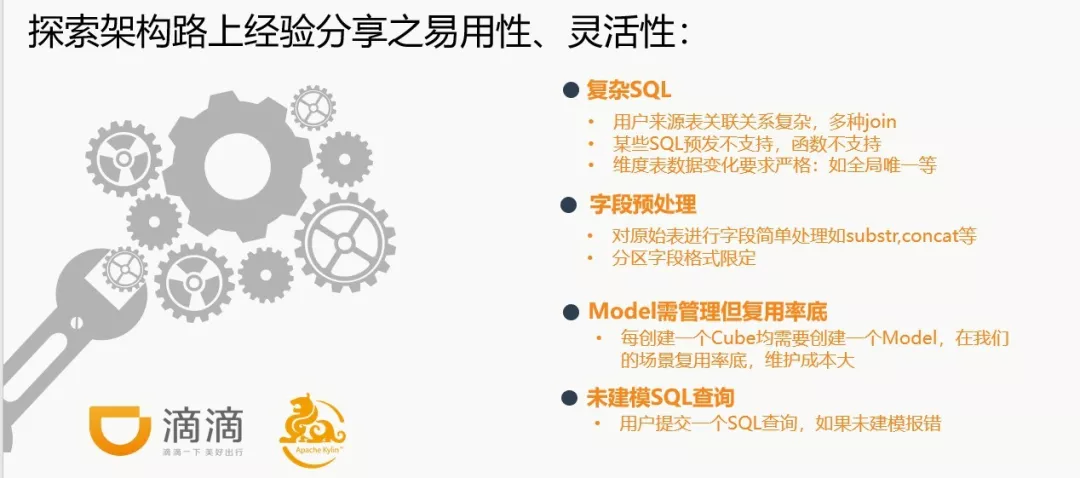
(1)维度表的数据要求严格。比如说维度表里面其中一个要求是 ID 不能重复,且每条数据都必须是唯一的。但是目前滴滴数仓中有一部分维度表,是每天根据分区全量放进 Hive 表的(每个分区都有全量数据)。而这类数据是没有办法直接在 Kylin 中被当做维度表使用的。
(2)没有字段预处理功能。通常来说就算是标准化的表,我们可能也会有对某些字段进行一些简单处理地需求,比如进行 concat、substr 等这样一些操作。
(3)Kylin 增量构建的时候,他对分区的格式比较固定且精确到天的分区只能有一个分区字段(如 DT=20190528)一个字符串。但是由于历史原因,滴滴目前有很多的表的分区可能有三层,比如 year 一层,month 一层,day 一层,这种是没有办法直接使用的。
(4)Kylin 对于复杂 SQL 建模支持较弱。另外一个使用场景比较特殊,即 Model 管理,但复用率底。Kylin 要求用户在创建 Cube 前一定要创建 Model, 但是 Model 的复用性在我们公司并不高,Model 和 Cube 的比例基本是 1:1。这导致整个 model 的维护成本较高,因而我们希望用户只暴露 Cube 层。
针对易用性、灵活性问题,滴滴的解决方式如下:
针对复杂 SQL、Model 管理、字段预处理、分区、维度数据有重复等问题,在用户对接 Kylin 的时候,我们在中间增加了”建模转换”层。用户通过在公司自研的数易报表平台进行建模配置,然后由报表系统提交给建模转换层,负责对用户 SQL 进行预处理,主要是将用户的 SQL 转换成 Kylin 可以使用的表:创建一张临时表,而这张临时表就是 Kylin 需要的一张标准表,并调用 Kylin 的 API 进行建模。这样不论用户写多么复杂的 SQL,还有包括刚刚提到的这些字段的转换,都可以通过 Kylin 进行加速。
这个时候用户做的事情就变得很简单,他只需要在报表平台写相关的 SQL,配置维度或度量。剩下的事情就交给建模平台,它会去调相应的 API 创建建模以及打通调度系统,从而屏蔽整个 load table 以及创建 model,cube 等过程,上文提到的那些复杂 SQL 转换也完成了。

2. 广播时延、元数据一致性问题
第二个问题是在较高并发的情况 Kylin 元数据可能会出现一致性和时延问题。
一方面 Kylin 的每个节点的元数据通信是通过广播的机制处理,即在 A 节点做了变更,通过 Api 的方式广播到其他节点,这时 A 和其他节点会有时延,尤其是在较高并发修改元数据时(批量创建或修改 model/cube/table 等),此问题会比较突出;
另一方面,滴滴使用 HBase 作为 Kylin 的存储引擎,Kylin 很多地方在做模型管理的时候分为多个步骤(如:创建 Model 时就有两步需要 update HBase 中的数据。先将 Model 的 schemal 信息保存进 hbase 并广播到其他节点,然后在 update project 的信息并广播到其他节点),由于没有分布式事物,这两步是可能会出现元数据一致性的问题的。
针对时延和元数据一致性问题,滴滴的解决方式如下:
虚拟一个 State 角色,其他平台所有对 Kylin 的元数据的 CUD API 操作,全部都在这样一个角色上运行,这个角色的模式是 standby/active。这只是一个虚拟的角色,并非真实地添加了一个这样的形象,可以把某两个 build 的节点当做 State 角色。另外我们还添加一个元数据补全的 API,当系统发现某个元数据出现问题后,可以调用这个 API 来进修补全操作(之前可能需要人为修改 HBase 中的元数据或者远程 Debug 解决)。
在创建 Model 的时候用户做了两件事情,第一件事情是把 model 存到 HBase 中进行持久化,第二件事是 update HBase 中相关 project 的元数据,删除的时候也是同样的步骤,但是两个步骤有可能没办法全部成功,这样就会导致系统中有脏数据的存在,甚至会引发元数据不一致等问题。而且这种数据是不好清理的,因为它在 HBase 里是一张大表,一条一条地清理会非常麻烦。最开始时,要想清理这样一些数据,只能通过 debug 的方式。
现在采取补全 API 的方式,思路也很简单,既然 Model 不能删除是因为有某个 Cube 依赖(实际这个 Cube 已经不存在了),对此,我们就会通过这个 API 虚拟一个 Cube,相当于把它补全进去,再去调 API,就可以把这个 Model 清除掉了。
3. 集群治理方面的实践

Job 调度
第一个问题是滴滴现在的调度只能调度最近 3 天的 job,为什么只调度最近 3 天的 job?
我们每天的任务数差不多是四千个左右。Kylin 目前的做法是把整个 Job 全部 Load 出来,一个一个的串行判断看能否满足调度需求或者能不能调度,这个调度时间还是比较长的,而且随着 job 数的不断累积,单次轮训一次的时间还会不断增加,最后会导致原本预计的 1 分钟轮训一次,变为 5 分钟甚至 10 分钟还无法完成。我们的做法是,在这里做了过滤,只允许拿出最近三天的任务去调度。另外有一些任务,它可能永远都无法 Build 完成(基数特别大、超多维度等)、或者 Build 的时候总是失败(比如没有权限),这些任务如果不处理就会导致一致占用运行中的任务资源,最后甚至导致耗光所有的 Build 资源(达到 Build 最大任务数)而无法运行新任务。对于这样一些情况,我们目前加了自动处理机制,会自动 Discard 掉用户运行时长大于 24 小时的任务,避免系统中出现僵尸任务。
API 加速
另外还有一些 API,我们将 API 与数据的处理做了分离,如 Purge 或者 Discard 的操作,这些 API 调用的时候时候会真正触发数据的删除或者一系列动作(涉及到数据清除、元数据清理其实会是一个比较耗时的过程),为了提高整个 API 的响应速度,我们目前把所有的 API 与数据操作做了分离,API 调用的时候只是把状态做了一个变更,这样可以大大提供 API 响应速度和成功率。真正的数据清理会放在定期历史数据和元数据清理的任务中去做。
4. 集群运维
配置与代码分离
在运维方面,滴滴把 Kylin 的配置和代码做了分离,因为版本迭代的比较多,但整个配置改动比较少,所以我们将 Kylin 的配置和代码进行分开管理。另外 Kylin 集群上会增加一个负载均衡层。这样,一方面能解决集群的负载均衡情况,另一方面还能在以后 Kylin 版本的升级中做到对用户完全透明。
监控或探活类服务
滴滴还加了一些监控或者是探活类的服务。我们单独加了一个在线看日志和远程重启 Kylin 的小工具。这样当 Kylin 出现问题而电脑又不在身边时,就可以通过这个小工具在手机上实时地看到日志或进行相应的重启操作。这是一个简单又实用的功能。监控方面,除了添加错误日志、正在运行的任务数等一些指标监控外,我们还添加了一个探活服务,实时探测 Kylin 查询是否正常。
使用 Spark Livy 构建
目前,滴滴计算引擎正在大力推 Spark,所以对于 Kylin,我们也推荐使用 Spark 的方式进行构建,Spark Livy 构建方面也是由滴滴贡献到社区。
全局字典构建
全局字典构建方面,尤其是在精准去重耗时优化,去重结果明细钻取方面,我们做了比较多的工作,下面会详细介绍滴滴最新版本的全局字典。
滴滴全局字典最新版本介绍
背景介绍
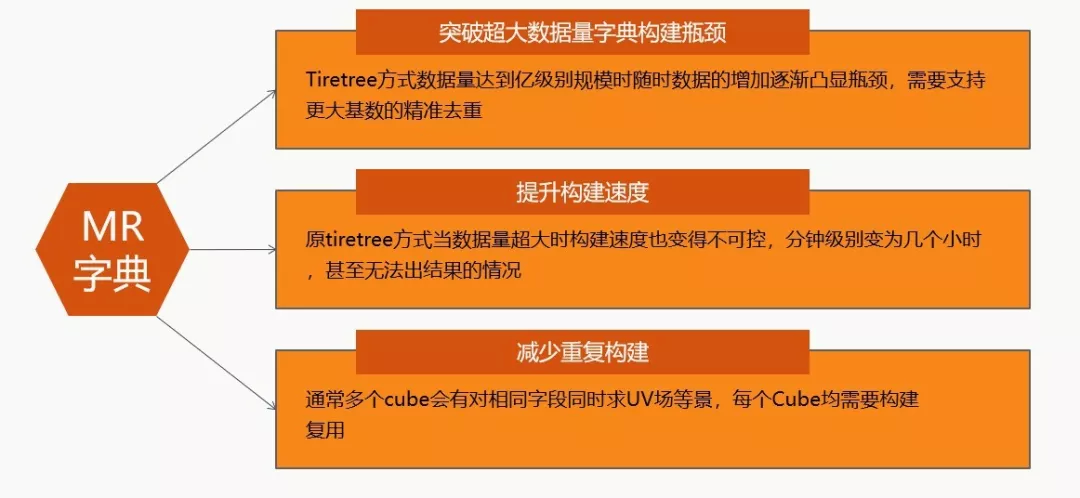
最开始用社区 Tire Tree 方式构建字典,可能遇到这样几个问题:第一个是数据量达到 3-4 亿规模的时候,可能就到达了瓶颈,比如出不来结果,或者对内存的要求特别高。另外构建速度从最开始只需要四五分钟,到后来可能十个小时也出不来结果。另一个需求是我们希望减少重复构建,在社区,单个 cube 内列的复用是有的,但它在整个集群内部是没有的,而我们希望列在整个集群间也可以复用。最后是一个隐性的需求,即目前精准去重的字典是不能反查的。比如说,我们只能求出这个 UV 今天是五十个,但是至于是哪五十个,是不知道的。在这样的背景下,然后我们做了三个版本的迭代。
滴滴全局字典的三个版本迭代
第一个版本是纯 Hive 的实现,已经贡献给社区了。这个版本由于使用了 Hive 的 order by,会随着数据量的增加在 order by 这一步 MR 的 shuffle 过程达到瓶颈(时间和单 MR 的内存),最终无法构建全局字典。
第二个版本是在第一个版本上面做了一些改进,解决全局排序在一个 shuffle 中的问题。这个版本解决了突破单列构建数量的瓶颈,基本上在 Kylin 全局字典目前允许的最大范围(21 亿数据量)内都可以恒定在 15 分钟出结果。
第三个版本在第二个版本又做了一次改进,将第二个版本在同一个 Cube 多列求精准去重由串行改成并行的方式。在理论上实现无论一个 Cube 有多少列精准去重的需求,也不管单列的数据量有多大,都是可以恒定在 15 分钟左右出结果。
接下来大概与大家分享下,全局字典 3 个版本实现逻辑。
通俗而言,字典就是把一个字符串转换成唯一的一个 int 类型编码,这是最终字典要做的事,我们现在的做法如下:

Version 1:
第一步通过 HQL 把本次需要构建字典的增量原始值给取出来,比如说这次需要增量构建的字典原始值有张三、李三,同时会查询此 Cube 之前字典里面的最大编码,比如之前字典中只有王芳,他的编码是 1,则这个 Cube 当前的最大编码即为 1。
第二步通过 HQL 真正编码,我们把第一步得到的增量原始值采用 order by 排序并通过 row number 的方式给每个值一个编码(每个值真正的编码为 row number + 之前字典的 max 编码值)。比如此时李三对应的编码就为 2,张三编码就是 3.
第三步通过 HQL 与之前的字典表做合并,合并后此 Cube 的字典里面有三行记录(王芳,1|李三,2|张三|3),如上图。
最后一步,通过 HQL 用字典表中的字典编码去 replace 掉 Kylin 第一步的临时扁平表的原始值。 即把张三和李三、王芳等,替换成他们的编码。后续关于这一列就无需再编码了(已经是 Int 类型),这是第一版,已经发给社区了。

Version 2:
第二版在增量抽取 Extract、 Merge 和 Replace 步骤与 Version 1 还是一样的,主要改动是在第二步 Dict 编码部分。 Version 1 因为采用 Hive Order by 的形式编码,最后一个 order by shuffle 的过程随着数据量的增加会成为单点,时效和内存则会成为瓶颈。所以 Version 2 我们用 MR total Order Partition 编码替换掉 Hive 的 Order by 编码。TotalOrder Partition 最终求出的顺序和编码值与 Hive Order by 获取的结果一模一样,但是他的整个 map reduce 过程是并行化的,不再受数据量和单节点的限制,基本突破了超高基数字典编码的瓶颈。

Version 3:
第三版本,又在第二版本上面做了迭代,将同一个 cube 多列精准去重由串行改为并行的方式。 第二版本里面因为我们使用了 total Order Partition,这种机制只适合对某一列做排序,做不到多列并行排序,又或改造成本非常大。经过思考,我们发现并非整个字典编码真的需要顺序,只需要满足每个原始值在同一个字典中有一个唯一的 Int 编码,编码最后紧凑就可以了。既然不在乎排序,那我们也不需要用 Total Order Partition 了,普通的 MR 就可以。最后我们采用的 Multiple Output 和自定义 Partitoner 的方式,来处理多列并行编码。理论上,V3 版本无论多少列单个 Cube 求精准去重,只要单列的基数在 Kylin 允许的字典基数(2^31-1)范围内,均可以在 15 分钟能够完成。
另外这种版本的字典编码是可以反查的。 后续我们还可以在全局字典上做更多的事情,如明细钻取、数据反查、数据公海等。数据公海是指我们希望所有 Cube 集群都可以共用这个字典。数据中台提倡 One ID、One Service 这样一些概念,我们未来也可能会在此有一些突破。
当然采用这种方式构建字典目前也还有一些瓶颈,比如在小数据量的情况下,它的构建速度其实是没有社区的 Trie Tree 方式快的,Trie Tree 采用单节点内存中操作,小数据量构建会很快。咱们这种编码方式无论数据量多少可能都需要十来分钟,因为 4 个步骤(Extract、Dict、Merge、Replace)每步都需要启动 MR,后续这块儿也会进行进一步优化。
上述几个步骤都是通过 MR 实现的,未来其实也可以用 Spark 函数来实现,我们现在没有这样做,一方面是基于时间问题,还有一部分原因是他的时效性已经达到我们的要求。但是基于代码优雅性比如说全切 Spark 版本的话,这其实是需要做改善的。
Kylin RT OLAP 探索经验分享
RT OLAP 新引入的两种角色和两种概念
第三部分主要分享 Kylin 社区目前主推的实时 OLAP 的探索过程。整个探索也是从今年 8 月底、9 月份的时候开始的。
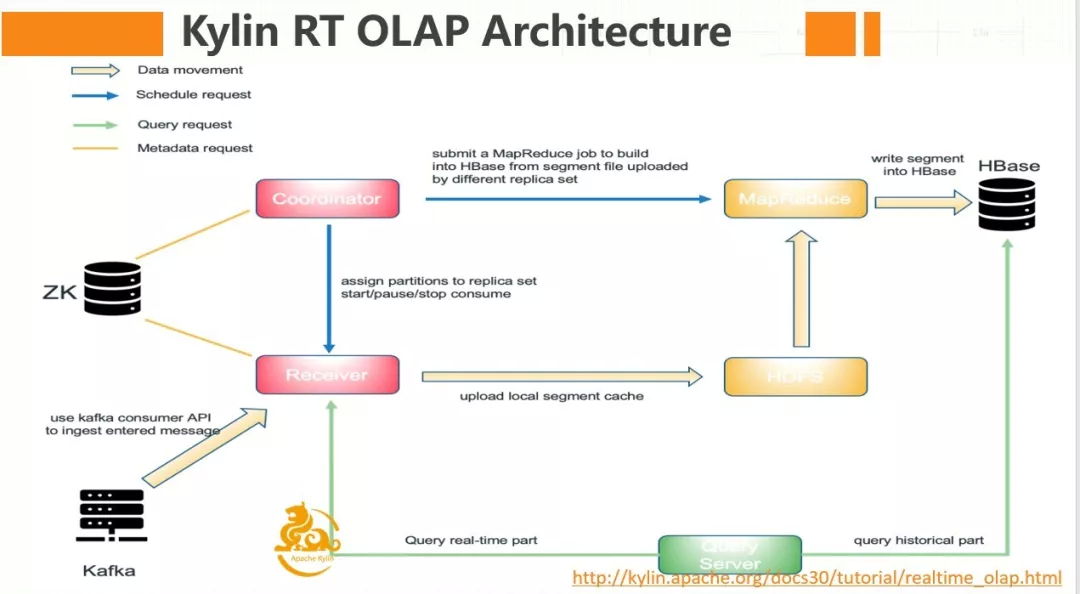
社区截图
实时 OLAP 模块在架构上主要增加了两个角色,一个是 Coordinator,一个是 Receiver。Coordinator 类似于一个 Master 的角色,它会负责 receiver 的管理、分配/解除分配 topic 的 partition 到指定的 replica set, 停止或重启消息的消费 , 提交构建任务等。Receiver 负责真正的从 kafaka 中消费数据并做基本的计算,是真正干活的节点。因为添加了实时的链路,查询时会根据时间区间决定去历史部分还是实时部分查询,历史部分还是和原来一样,去 HBase 上面去查询,实时部分则会相应的 Receiver 节点查询。
下面这个图,主要详细讲解 Coordinator 和 Reciver 两种角色与 Kafka topic 、Assignment、Replica Set 之间的关系:
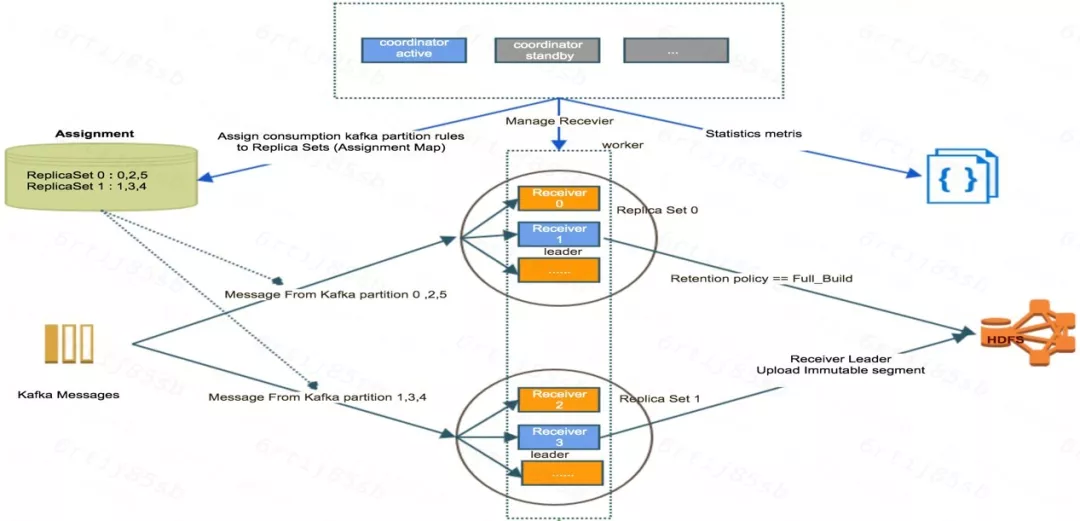
Coordinator 节点采用的是 Standby/Active 的架构,节点可以有 N 个,但是同时对我提供的服务只有一个,即通过 ZK 选举产生 Master 节点。Coordinator 首先会负责管理这些 Receiver 的节点,以及某个 Kafka partition 到底由哪些 Receiver 去消费,还会负责去提交 Build 任务即把实时部分的数据进行进一步预计算后存储到 Hbase 里面去,另外 Coordinator 还会做一些 metrics 信息采集的工作。
上面已经提过了,Receiver 是真正负责消费的角色,消费过程如下:Kylin 实时 OLAP 增加了一个 Replica Set 的概念类似于副本组,每个 Replica Set 是由 N 多个 Receiver 节点组成,同一个 Replica Set 里面的 Receiver 负责消费同样的数据,类似于一组 Receiver 结点去负责消费某些 Kafka 中的某些 partition 数据。另外每个 Replica Set 里面会有一个 Receiver 节点是这组的 Master 节点,这个被选中为 Master 节点的 Receiver 除了做消费的活以外,可能还会做一些额外的事情,比如说帮助用户把这个构建的历史数据上传到 HDFS 上去。
第二个概念是 Assignment。Assignment 属于 Cube 层面的一个属性,通俗一点讲,Assignment 保存了某个 Cube 的实时数据由哪些 Replica Set 负责消费,每个 Replica Set 负责消费这个 Cube 中 Kafka topic 中的哪些 partition。如上图左上角,某个 Cube 由 ID 为 0 和 1 的这两个 Replicat Set 负责消费,其中 Replica set 0 负责消费 topic 的 partition ID 为 0、2、5 的消息,Replica set 1 负责消费 topic 的 partition ID 为 1、3、4 的消息.
这是整个实时的新引进的两个角色和两种概念的介绍。
Segment 状态的流转过程
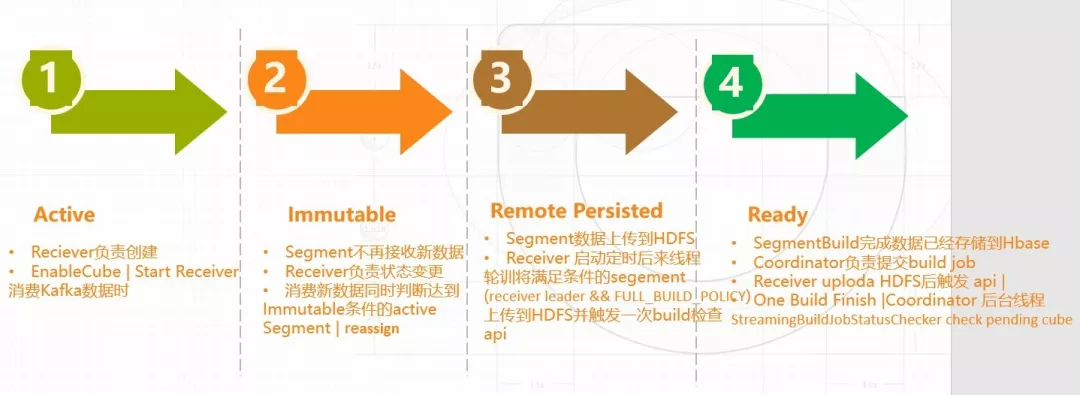
在实时方面, segment 的增加了 3 种新的状态:Active、Immutable 以及 Remote Persisted,Ready 是之前的离线 OLAP 也有的。
Active 状态是由 Receiver 在消费 Kafka 数据的时候创建的, 当消费到某一条数据发现它不属于已经创建的 Segment 的时间范围,它就会创建一个新的 Segment,状态为 Active。只有属于 Active 状态的 Segment 才会接收新的数据,只要是在这个区间以内的数据都会放在这个 Active 的 segment 里面去,当到达一定时间、一定状态以后,状态就会变成 immutable 的状态。
变成 immutable 状态的数据不能再接收新的数据。 Active 状态变更为 Immutable,是由 Receiver 在消费每条数据的时候判断,这条数据对应的 active segment 是否已经创建,如果没有,它就要创建一个新的 active segment,这时同时也会去判断是否有处于 Active 状态的 Segment 达到了变成 Immutable 状态的一个条件,如果达到了则将这个 Segment 由 Active 变更为 Immutable 状态。除了这种情况下 Active 会变成 Immutable 状态外,另外当我们在做 Re-assign 的时候,即更换某个 Cube 的消费 Receiver 节点时,不再继续负责消费此 Cube 的 Receiver 节点上处于 Active 状态的 Segment 会全部变成 Immutable 状态。
第三个状态是 Remote Persisted,当某个 Segment 变更为 Immutable 状态后,表示此 Segment 不再接收新的数据,接下来就需要把处于 Immutable 状态的 Segment 进行历史化处理,并构建到 HBase 里面去。 在此之前,首先要把本地 Receiver 上面的数据上传到 HDFS 上面,上传完成后,则 Segment 相应的状态将变成 Remote Persisted。Receiver 会启动一个后台的定时轮询线程,负责将 Cube 的 Build 策略配置为 Full_Build 的 Immutable 状态的 Segment 上传到 HDFS,当然真正上传数据的只有 Replica Set 中处于 Master 节点的 Receiver 上传。
第四个就是 ready 状态,Segment 变更为 Ready 状态后表示这部分数据已经转换为离线部分数据,并已经存入到 HBase 中了。 当 Receiver 把某个 Segment 数据上传到 HDFS 以后,Receiver 会调用一次 Coordinator 的 API,通知 Coordinator 这个 Cube 现在可以去做 Build 操作(启动 MR Build 任务将实时数据进一步处理如字典合并,然后把相应数据转换成 HFile 存入 HBase 中);同时 Receiver 还会把一些有关此 Segment 的一些元数据信息写入 ZK 中,供 Coordinator 启动 Build 任务时使用。当 Build 任务构建成功后,Segment 的状态将会由 Remote Persisted 状态变更为 Ready。这就是整个 Segment 状态的流转过程。
滴滴调研 Kylin 实时 OLAP 过程中的问题
第一个是整个 Kylin 实时 OLAP 每个 Segment 各个状态的流转和处理都是通过时间顺序串行处理的。 这可能会引发一些问题,比如只要一旦有一个 Segment 在某步出了问题,则整个 Cube 可能都不再工作了。
另一个是分布式事务问题,因为 Kylin RT OLAP 的元数据一部分在 HBase 中,一部分在 ZK 中,还有一部分在内存,但是整个是没有分布式事物的,某些地方也没有冥等性策略,这是极有可能出现元数据与实际不一致的情况,一旦出现了数据不一致,就可能导致某个 Segment 无法按照整个正常的流程流转导致这个 Segment 不能变更为 ready,同时因为 Segment 的时间顺序处理,进而导致后续此 Cube 的 Segment 也没有办法进一步变更成 ready,最终只能将此 Cube Disable 和数据 purge 掉后重新消费解决,这对生产实时场景来说是不可接受的。这里我们在一些关键元数据管理的步骤加入了冥等性策略,大部分也已经反馈给社区了。调整过一版本后,目前没有发现 Segment 因为元数据不一致而导致失败的情况。
第三个是将实时部分数据通过 MR build 转换成离线存入 HBase 的过程, 这个 Build 任务可能会遇到永远无法 Build 成功的 bad case(比如代码的 Bug 或者上传到 HDFS 上的数据被删除了等),通常来说如果是离线 OLAP 我们只需要把这个 Segment 的 Build job discard 掉后重新提交一个 Build 任务就可以了。但是对于实时 OLAP 之前是没有 disable 功能的,再加上上面的时间顺序问题会导致整个 Cube 都只能 disable 、purge 掉数据后重头再来 Cube。现在我们在这个地方加了相应的一个机制,Segment 可以 discard,discard 后可以自动重新提交 Build 任务进行恢复。
另外的遇到的一个问题就是时区的问题,总是会差 8 个时区。 我们和社区对于时区的问题都改了一个版本,社区是在查询端改的,每次查询的时候在用户的 SQL 上把时间列自动偏移 8 个小时。这种改法对代码优雅性而言是很好的,但是可能会遗留另外一些问题,比如说涉及到跨天,查询出来的数据可能就不是正确的了;另一个是对每一条查询出的结果里面所有的时间列也还需要在转换一次 8 小时偏差才会是用户想要的结果。我们的改法是在入库的时候就把时间纠正成用户想要的正确时间点,比如差 8 个小时就加 8 个小时,这样对于入库的点直接作一个纠正,用户在查询的时候,就会得到真正想要这样结果。而这种对于代码优雅性来说未必合适,因为 Kylin 存储的是 timestamp,我们相当于在 timestamp 上加了 8 小时,不过这种改法比较简单对后续的查询也比较彻底。
此外,还有一个 Build 时长的问题,把 Remote Persisted 数据转换成 Ready,这个 Build 过程还是挺长的,当然也得看数据量以及配的 Segment 窗口时间有多少,这一块需要上线测一下,根据自己的实际情况进行配置,正常情况下 Build 时间一定要小于 Segment 窗口时间,否则长期累积会达到此 Cube 的最大 Build 并发的限制,严重的时候会导致不在消费新的 Kafka 中的数据了(因为阻塞了太多 Segment 没有变成 ready 状态),所以大家在上线前尽量去测试一下, Segment 窗口期到底多长是比较合适的。
期待 Kylin 早日发布实时 OLAP 稳定版本(已于 19 年 12 月 20 日发布),对真正实现离线、实时 OLAP 统一引擎具有非常重大的意义。
本文转载自公众号 apachekylin(ID:ApacheKylin)。
原文链接:

腾讯大规模云原生技术实践案例集
本案例集详细阐释了 QQ、腾讯会议、和平精英、小红书、斗鱼、微盟等十多个亿级用户产品背后的大规模云原生...













评论