
机器翻译是利用计算机将一种自然语言(源语言)转换为另一种自然语言(目标语言)的过程,不同于目前的主流机器翻译,大多是基于神经机器翻译,实现单纯的机器翻译,打造兼具稳定、易用、高效并符合用户需求的工业级翻译产品,要解决很多难题,比如:文档内缩略语如何翻译?小语种低资源翻译问题如何解决?语料如何处理?
在本篇文章中,百分点认知智能实验室基于多年的经验积累,分享了百分点科技在工业级机器翻译领域的技术研究和实践成果。
随着经济全球化及互联网的飞速发展,机器翻译技术在促进政治、经济、文化交流等方面起到越来越重要的作用。但各大领域的翻译需求越来越多,翻译要求也越来越高。
1. 翻译文档越来越多
据统计,美海军“温森斯”(CG—49)导弹巡洋舰维护手册达 23.5 吨,仅空军 F-16 战斗机技术资料约 750000 页;F-18 战斗机的技术资料有 500000 多页,重达 1428.84kg。每天,美军官方和著名的咨询公司每天新发布的装备科技信息相关材料就超过 100 万页。而这些文档涉及的语种,包括最常用的英文、俄文、日文以及德文、法文、意大利文、韩文等,文档格式包括扫描版/电子版 PDF、Word、Excel、PPT 等,以及各种格式的图片(包括但不限于 png, jpg,bmp, tiff 等),甚至手写材料。
2. 材料内容越来越专
各大领域的翻译任务包含大量的专有词汇、缩略语,覆盖航天、电子、船舶等各个业务,谷歌、百度等通用翻译引擎无法满足装备科技信息领域内的个性化需求。同时,业务方对翻译的效果质量要求越来越高,以更准确地了解最新的科技信息。
3. 速度要求越来越高
海量资料的快速翻译需求,对翻译速度的要求越来越快,以更及时地获取信息,支持科学决策。翻译速度不仅和硬件、软件相关,更和模型算法直接相关。在实际中,需通过模型、算法和工程层面的优化,实现翻译速度能够满足技术参数要求。
4. 数据安全和信息安全要求不断提升
不仅需要翻译系统能够在本地化部署、本地化运维,而且需要能在本地自动化加工语料,自动化模型训练、迭代、升级。从而满足整个系统的所有核心环节都能在本地完成,形成语料生产、语料加工、模型训练、模型部署、模型运维的闭环,而不需要相关敏感的业务数据离开本地环境;同时,针对用户自身的特定需求,可以更及时、自动地完成优化和升级,从而提高翻译的效果。
百分点智能翻译系统正是为了应对以上“多、专、快、高”的紧迫需求而产生的。
机器翻译发展及 Transformer 介绍
1. 机器翻译发展
机器翻译技术在近几十年的发展中经历三个主要阶段,依次是基于规则的机器翻译、基于统计的机器翻译和神经机器翻译。基于规则的机器翻译需要人工书写翻译规则,代价过高,并且伴随翻译失败的可能;基于统计的机器翻译完全由数据驱动机器学习,但用短语拼接翻译的基本思想使长句翻译品质不佳,并且带有先验假设。目前主流的机器翻译方法为神经机器翻译,翻译的知识和参数由神经网络自动学习,避免了传统方法的人工干预模块带来的偏差,而且直接把整个句子转化为向量进行翻译,使得模型的特征表示能力更强。
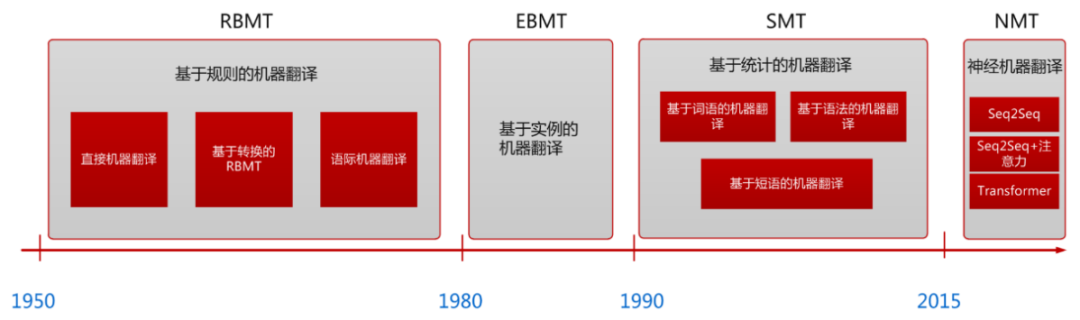
图 1.机器翻译的发展
神经机器翻译始于 2013 年提出的 Encoder-Decoder 框架,在发展的过程中,大部分模型由 RNN 结构组成,RNN 的序列特性利于自然语言建模的同时也带来无法高效并行化的弊端。2015 年 Attention 概念的提出使得机器翻译的品质大幅度提升,2017 年谷歌在此基础上提出的 Transformer 模型成为当今神经机器翻译模型的基石。
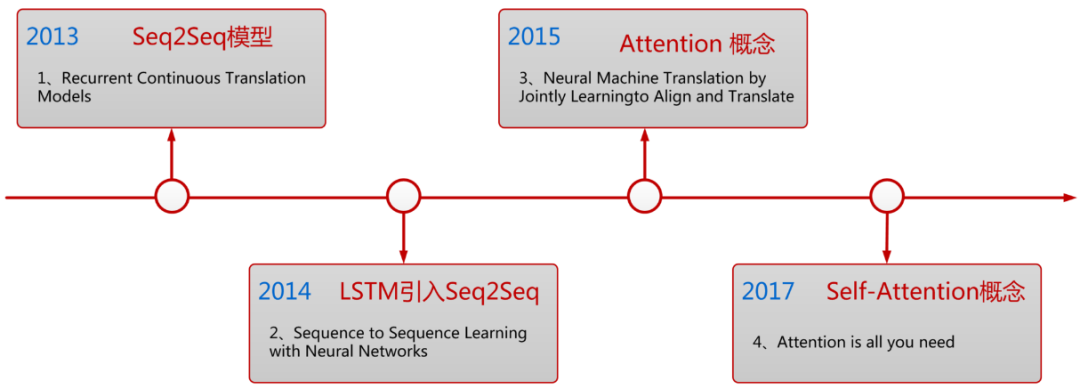
图 2.神经机器翻译的发展
2. Transformer 结构
Transformer 的本质是一个带有自注意力机制的 Encoder-Decoder 结构,具体结构如图所示。从整体上看,左半部分为 Encoder 编码器,右半部分为 Decoder 解码器。编码器读取源语言句子并编码成固定长度的向量,然后解码器将向量解码并生成对应的目标语言翻译。
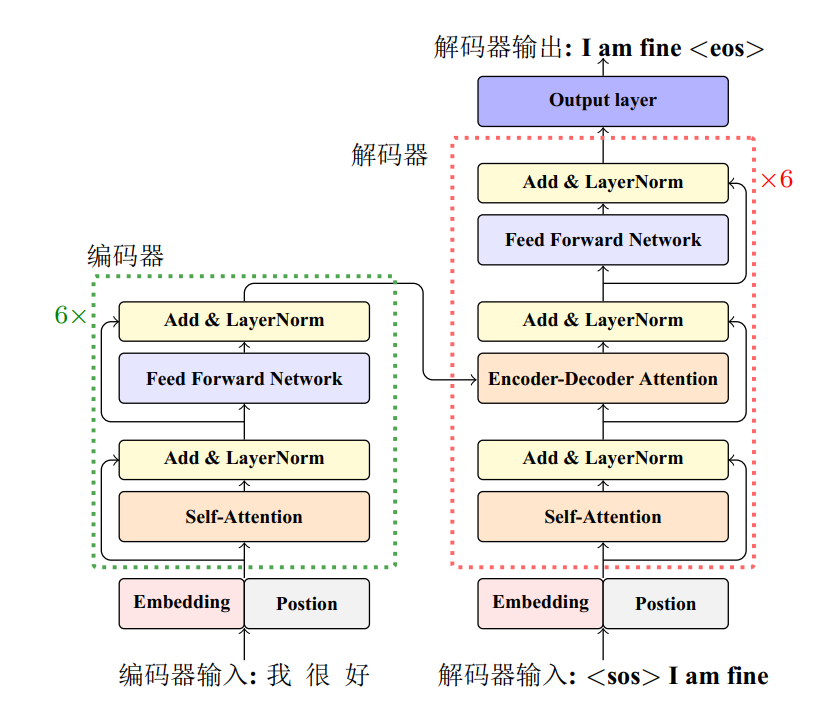
图 3.Transformer 整体结构
编码端和解码端分别由 6 层结构相同的 EncoderLayer 和结构相同的 Decoder Layer 堆叠而成。Encoder 和 Decoder 之间的连接方式为:Inputs 经过各层 Encoder Layer 作用后的输出序列作为 Encoder 的最终结果,分别输入各层 Decoder Layer。
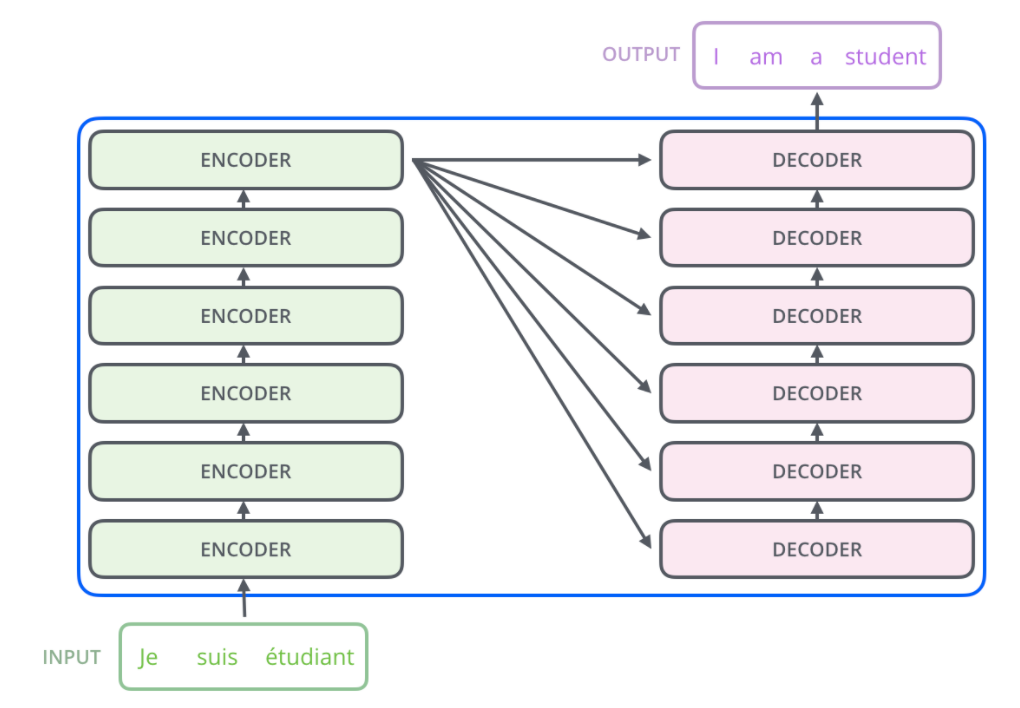
图 4.Transformer 编码端解码端整体结构
具体每个 EncoderLayer 由 2 个 sub-layers 组成,依次为编码器多头自注意力(图左 Encoder 中的 self-attention)、前馈网络(Feed Forward);每个 DecoderLayer 由 3 个 sub-layers 组成,依次为解码器多头自注意力(图右 Decoder 中的 self-attention)、编码器解码器多头自注意力(Encoder-DecoderAttention)和前馈网络(Feed Forward)。
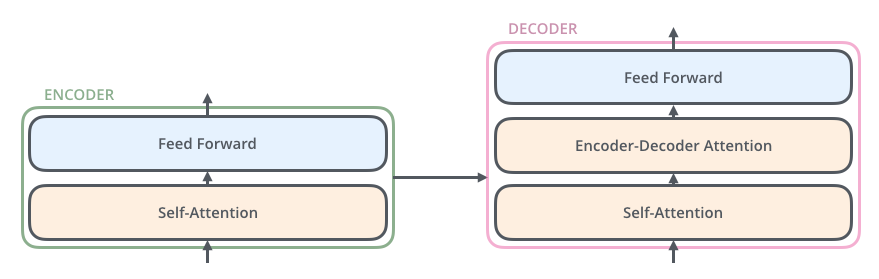
图 5.单层 EncoderLayer-Decoder Layer 结构
下面将详细介绍各个子结构。
2.1 多头自注意力机制
Transformer 的核心在于多头自注意力机制,分为点积注意力计算和多头注意力两大步骤。
(1)点积注意力
点积注意力函数有 3 个输入:Q(请求(query))、K(主键(key))、V(数值(value))。出现在编码器或解码器中不同的注意力计算时,Q,K,V 的表示也有所不同:
在编码器自注意力中,Q=K=V,均是编码端各个位置的表示,来自编码器前一层的输出,使得编码器中的每个位置都可以关注编码器上一层的所有位置;
在解码器中的第一个 sublayer 自注意力中,Q=K=V,均是解码端各个位置的表示,使得解码器中的每个位置可以关注解码器中直到并包括该位置的所有位置;
在解码器中的第二个 sublayer 编码器-解码器注意力中,Q 来自解码器的上一个 sublayer,是解码端各个位置的表示,K=V,来自编码器的最终输出,是编码端各个位置的表示,使得解码器中的每个位置能关注到输入序列中的所有位置。
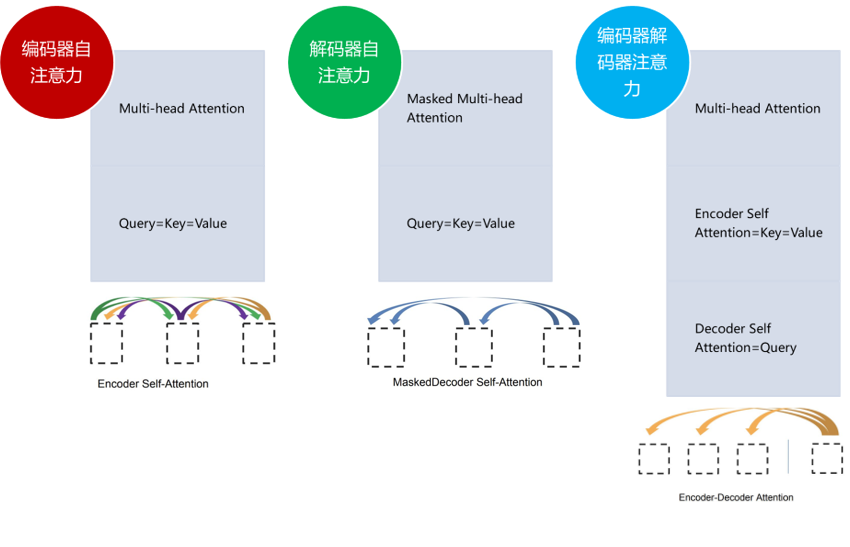
图 6.Transformer 的三种自注意力
点积注意力具体计算公式如下:
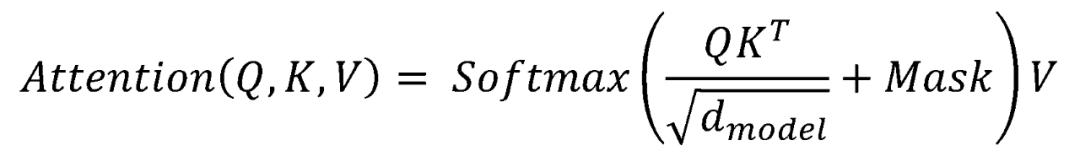
第一步,对𝑄和𝐾的转置进行点乘操作。此为利用点积的方式计算相关性系数,表示一个序列上任意两个位置的相关性。
第二步,通过系数
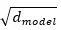
进行放缩操作,防止过大的输入进入 Softmax 函数的饱和区造成梯度过小等问题。
第三步,与掩码矩阵𝑀𝑎𝑠𝑘相加,从而对句子序列中 Padding 的位置屏蔽,以及解码器自注意力中需额外对目标语言序列未来位置的信息进行屏蔽。
第四步,使用 Softmax 函数对相关性矩阵在行的维度上进行归一化操作,结果对应𝑉中的不同位置上向量的注意力权重。
第五步,和𝑉进行矩阵乘法,即对 Value 加权求和。
(2)多头注意力
将𝑄、𝐾、𝑉与参数矩阵
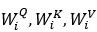
对应做线性变换映射为子集,分别进行点乘注意力操作得到,然后拼接这个头并再次映射。多头注意力机制的公式如下:

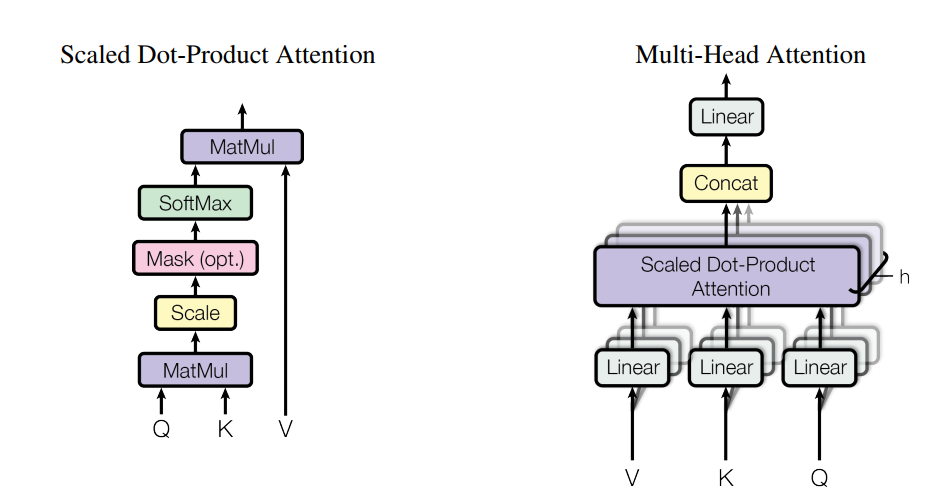
图 7.点乘注意力
2.2 前馈神经网络
该网络独立且相同的应用于每个编码层及解码层的最后一个子层,包含两个线性变换,中间有一个 ReLU 激活函数。
2.3 残差正则化
为防止梯度消失或者梯度爆炸并加快模型收敛,在每个子层均使用残差链接和层归一化操作:𝐿𝑎𝑦𝑒𝑟𝑁𝑜𝑟𝑚(𝑥 + 𝑆𝑢𝑏𝑙𝑎𝑦𝑒𝑟(𝑥))
2.4 位置编码
为捕捉句子序列的位置顺序信息,将编码端输入的 InputEmbedding、解码端输入的 OutputEmbedding 均与位置编码的对应位置嵌入相加。
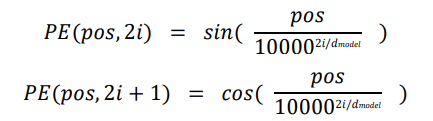
其中𝑝𝑜𝑠为位置,𝑖为维度。
以上是对 Transformer 结构的介绍。
2.5 创新点总结
Transformer 的创新点在于提出的自注意力机制。
第一,不采用 RNN 和 CNN 的结构,具有并行运算的能力,体现在编码器的所有词向量以矩阵的形式并行进行注意力计算,改进了此前 RNN 最被人诟病的训练慢的缺点。
第二,在计算复杂度方面,Self-Attention 层将所有位置连接到恒定数量的顺序操作,而循环层需要 O(n) 顺序操作。 对于每层复杂度,当序列长度 n 小于表示维度 d 时,自注意力层比循环层快。
表 1.不同图层类型最大路径长度、复杂度、最少顺序操作数对比表

其中,n 为序列的长度,d 为表示的维度,k 为卷积的核的大小,r 为受限 self-attention 中邻域大小.
第三,多头自注意力机制使得 Transformer 可以学习到丰富的上下文信息。由于自注意力的计算直接将句子中任意两个单词的关系通过同一种操作(Query 和 Key 的相关度)处理,将信息传递的距离拉近为 1,所以可以更好的捕获远距离依赖的特征,如:同一个句子中单词之间的句法特征,包含指代关系的语义特征等。同时,多头机制将模型分为多个头,分别在不同的表示子空间学习,使得模型在各个子空间关注不同方面的信息,有的头可以捕捉句法信息,有头可以捕捉词法信息,最后综合得到更丰富全面的信息。
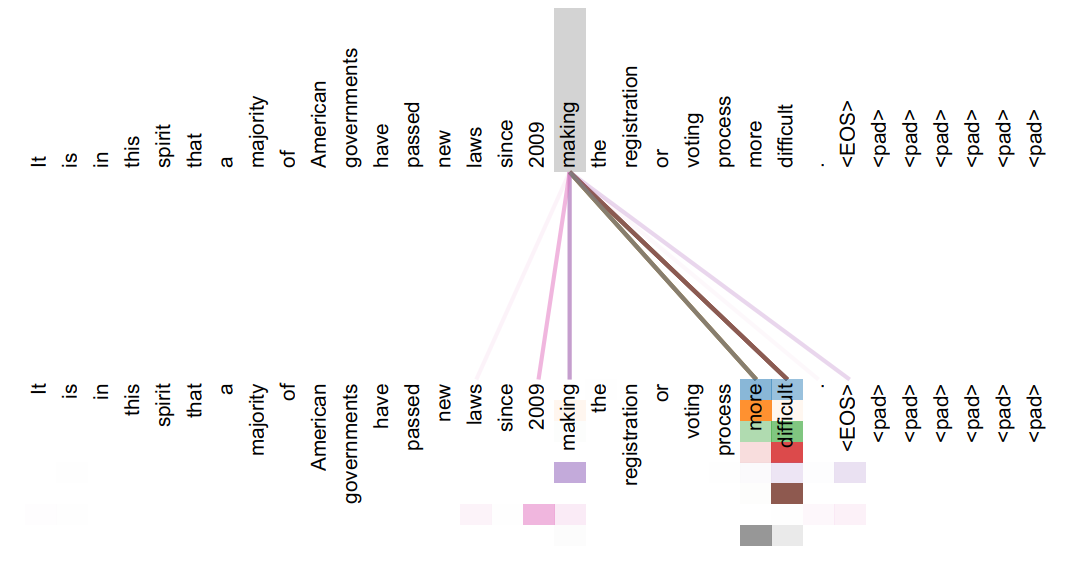
图 8.捕捉语法信息
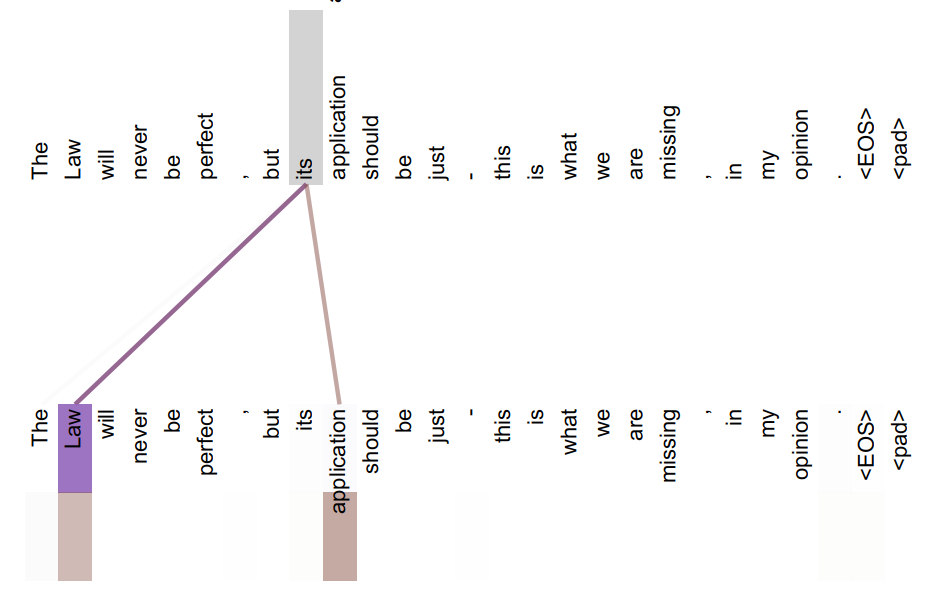
图 9.捕捉语义信息
另一方面,Transformer 可以增加到非常深的深度,使得表层的词法信息随着模型的逐步加深组合为更加抽象的语义信息。Transformer 充分发掘 DNN 模型的特性,为模型准确率带来提升,这也是其性能优越的原因之一。
百分点科技智能翻译实践
1. 产品逻辑架构
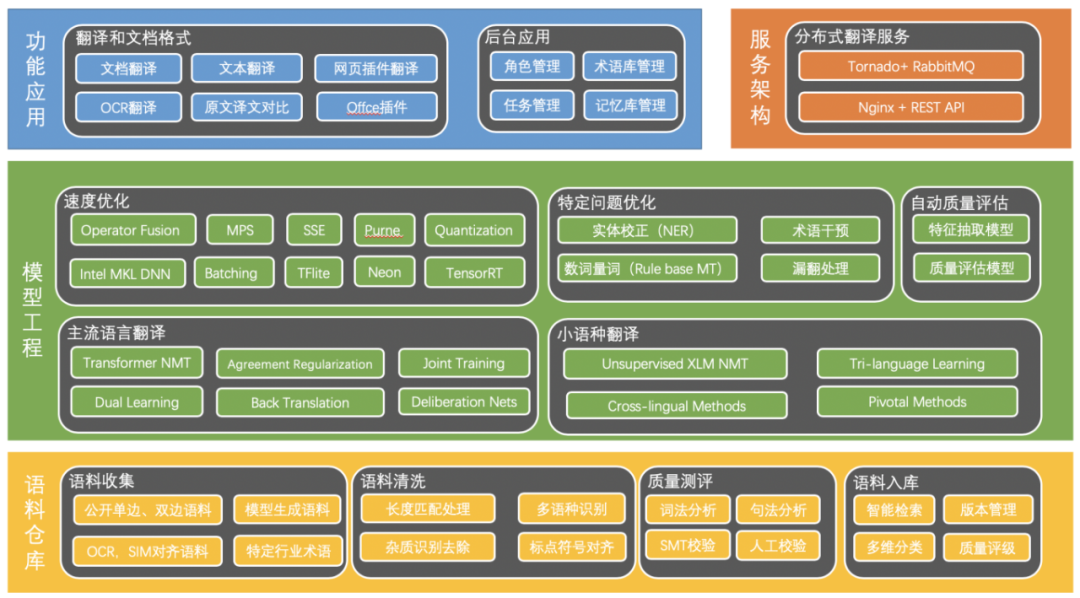
图 10.产品逻辑架构图
下面详细阐述各个逻辑层及其子层。
1.1 语料仓库
该层包括语料收集、语料清洗、质量评测、语料入库四个子层次。其中:
语料收集:机器翻译模型的效果同训练语料数量成正相关。为了充分发掘自有数据的价值,并灵活应对未来的个性化挑战,我们必须持续收集各类语料库。百分点科技在国内外多语言舆情分析、文本分析、机器翻译的项目中,积累了大量的多语言语料,为机器翻译的效果奠定了坚实的数据基础。
语料清洗:语料清洗是举足轻重的关键步骤,它决定着一个好的模型训练难易程度,也是决定特定领域模型效果好坏的又一重大因素。语料质量越高模型翻译效果越好。对收集来的语料要经过诸如长度失衡处理、杂质识别去除、语种识别、标点符号对齐等步骤处理。
质量评测:为使模型效果更专业、更符合特定领域场景。我们需要质量评测来选取高质量语料作为模型训练数据。对于清洗好的语料要进行质量评测,便于优化调整语料清洗步骤,通常这些评测手段包括:词法分析、句法分析、SMT 校验以及人工校验等。
语料入库:为适应特定领域语言规律的发现、规则的制订与挖掘、语言知识的发现等深层次研究,需要质量评估合格的语料录入到数据库中,便于后续对语料进行智能检索、版本管理、多维分类、质量评级等多种操作。
1.2 模型工程
模型工程是翻译系统的核心处理功能。包括主流语言翻译模型的构建、训练及针对特定问题的优化。
主流语言翻译:为满足各大领域对非结构化文档数据的高质量翻译要求,我们构建先进的深度神经网络 Transformer 结构作为翻译模型,并通过回译等方式提升翻译效果。模型效果的提升,也是翻译产品专业化的保证。
小语种翻译:在各类翻译场景中,也存在对小语种的需求,对此我们的解决方式是:无监督学习方法、跨语言学习翻译等。
特定问题优化:为适应特定领域场景,我们需要针对性优化翻译模型效果。对这些特定问题归类,解决方式如:实体校正、术语干预、数词量词校正、漏译补全等。
速度优化:为更广范围地获取最新态势,及时响应特定领域场景翻译需求,我们需要对模型翻译进行速度优化。优化包括如:减少浮点数精度,模型压缩等。
1.3 服务架构
在应用服务部署的方式上,我们采用 Nginx+ Tornado + RabbitMQ,简单快速部署模型。在对外访问接口的方式上,我们采用 RESTAPI 提供高效、标准的服务调用方式。接口按照协议类型来看,可以包括但不限于 HTTP。
1.4 功能应用
功能应用即客户终端,这里将客户终端划分为翻译终端和管理终端。翻译终端为用户(游客、注册用户)提供文本及文档翻译服务;管理终端为注册用户提供词库管理、句库管理、任务管理、工具箱、权限管理等相应服务。
2. 语料搜集及处理
2.1 语料搜集及产生来源
训练语料是模型的基础,此外翻译模型效果还依赖于语料的质量和分布,因此我们在语料收集阶段在保证语料规模的同时平衡经济、政治、科技、生活、文化等各大领域的比例,使训练语料尽可能覆盖实际使用中的语言场景。
语料收集渠道包括:
在业务中积累的双语数据;
公开供研究使用的数据集;
网络爬取,新闻、字幕、例句等;
语料商城购买;
双语书籍的计算机辅助和人工对齐等。
除了获取全世界互联网上开放的语料库资源,开发团队设计一种从电子文档中的单边语料构建领域平行语料的模型与工具,可较为高效地构建高质量的行业领域平行语料支撑模型训练。百分点认知智能实验室团队提出通过给译文分类的方式学习语义相似性:给定一对双语文本输入,设计一个可以返回表示各种自然语言关系(包括相似性和相关性)的编码模型。利用这种方式,模型训练时间大大减少,同时还能保证双语语义相似度分类的性能。由此,实现快速的双语文本自动对齐,构建十亿级平行语料。
2.2 语料对齐和管理
在语料库建设过程中,需要充分利用自然语言处理以及相关技术开发语料库自动加工工具,提高语料库对齐建设效率,提升平行语料质量,提高语料库规模。
百分点智能翻译系统,可以对语料进行全流程科学管理,从而支撑模型的本地化、个性化训练和升级,及时提高翻译效果。
语料库自动加工工具系统涵盖从语料的 OCR、转换、清洗、对齐、校对、标签、管理、检索、分析、训练等多个子系统。
2.3 语料处理
神经机器翻译需要大量的训练语料,这些语料来源范围广,格式种类多,所以数据处理的第一步是将不同来源不同格式的数据统一处理,合并多源数据。
与统计机器翻译一样,神经机器翻译也需要对输入和输出的句子进行分词,目的是得到翻译的最基本单元。但是,这里所说的单词并不是语言学上的单词,更多的是指面向机器翻译任务的最小翻译片段。
自然语言的表达非常丰富,因此需要很多的单词才能表达不同的语义。但是,神经机器翻译系统对大词表的处理效率很低,比如,输出层在大规模词表上进行预测会有明显的速度下降,甚至无法进行计算。因此,在神经机器翻译中会使用受限的词表,比如包含 30000-50000 个单词的词表。另一方面,翻译新的句子时,受限词表会带来大量的未登录词(Outof Vocabulary Word,OOV Word),系统无法对其进行翻译。产生未登录词一方面的原因是词表大小受限,另一方面的原因在于分词的颗粒度过大。对于后者,一种解决方法是进一步对“单词”进行切分,以得到更小的单元,这样可以大大缓解单词颗粒度过大造成的数据稀疏问题。这个过程通常被称作子词切分(Sub-wordSegmentation)。以 BPE 为代表的子词切分方法已经成为了当今神经机器翻译所使用的标准方法,翻译效果显著超越基于传统分词的系统。
此外,机器翻译依赖高质量的训练数据。在神经机器翻译时代,模型对训练数据很敏感。由于神经机器翻译的模型较为复杂,因此数据中的噪声会对翻译系统产生较大的影响。特别是在实际应用中,数据的来源繁杂,质量参差不齐。因此,往往需要对原始的训练集进行标准化(Normalization)和数据清洗(DadaCleaning),从而获得高质量的双语数据用于模型训练。
以上这些内容统称为数据处理。下图展示了百分点智能翻译系统数据处理流程,主要步骤包括分词、标准化、数据过滤和子词切分。

图 11.机器翻译数据处理流程
3. 模型训练
Transformer 的训练流程:首先对模型进行初始化,然后在编码器输入包含结束符的源语言单词序列。解码端每个位置单词的预测都要依赖已经生成的序列。在解码端输入包含起始符号的目标语序列,通过起始符号预测目标语的第一个单词,用真实的目标语的第一个单词去预测第二个单词,以此类推,然后用真实的目标语序列和预测的结果比较,计算它的损失。Transformer 使用了交叉熵损失(CrossEntropy Loss)函数,损失越小说明模型的预测越接近真实输出。然后利用反向传播来调整模型中的参数。由于 Transformer 将任意时刻输入信息之间的距离拉近为 1,摒弃了 RNN 中每一个时刻的计算都要基于前一时刻的计算这种具有时序性的训练方式,因此 Transformer 中训练的不同位置可以并行化训练,大大提高了训练效率。
需要注意的是,Transformer 包含很多工程方面的技巧。首先,在训练优化器方面,需要注意以下几点:Transformer 使用 Adam 优化器优化参数;Transformer 在学习率中同样应用了学习率预热(Warm_up)策略。
另外,Transformer 为了提高模型训练的效率和性能,还进行了以下几方面的操作:
小批量训练(Mini-batchTraining):每次使用一定数量的样本进行训练,即每次从样本中选择一小部分数据进行训练。这种方法的收敛较快,同时易于提高设备的利用率。每一个批次中的句子并不是随机选择的,模型通常会根据句子长度进行排序,选取长度相近的句子组成一个批次。这样做可以减少 padding 数量,提高训练效率。
Dropout:由于 Transformer 模型网络结构较为复杂,会导致过度拟合训练数据,从而对未见数据的预测结果变差。这种现象也被称作过拟合(OverFitting)。为了避免这种现象,Transformer 加入了 Dropout 操作。Transformer 中这四个地方用到了 Dropout:词嵌入和位置编码、残差连接、注意力操作和前馈神经网络。
标签平滑(LabelSmoothing):在计算损失的过程中,需要用预测概率去拟合真实概率。在分类任务中,往往使用 One-hot 向量代表真实概率,即真实答案位置那一维对应的概率为 1,其余维为 0,而拟合这种概率分布会造成两个问题:
无法保证模型的泛化能力,容易造成过拟合;
概率值 0 和 1 鼓励所属类别和其他类别之间的差距尽可能加大,会造成模型过于相信预测的类别。
因此 Transformer 里引入标签平滑来缓解这种现象,简单的说就是给正确答案以外的类别分配一定的概率,而不是采用非 0 即 1 的概率。这样,可以学习一个比较平滑的概率分布,从而提升泛化能力。
4. 翻译效果
4.1 低资源翻译优化
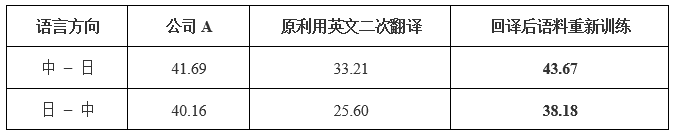
机器翻译依赖于大量高质量的平行语料,然而对于小语种,存在数据量小,平行语料难以搜集问题。针对数据稀疏问题,百分点科技使用了回译来进行语料扩充,进而提高翻译效果。以日中模型为例,通过回译方法,将原有的 3308 万平行语料扩充到 6700 万语料左右,然后再训练。通过此种方式,中日方向 bleu 较通过英文作为中间语言方式提升了 10.4,日中方向 bleu 提升了 12.5,对比结果如下表。
表 2.两个方向 BLEU 和公司 A 对比表
4.2 术语翻译优化
翻译过程中,越来越多的笔译工作者选择调用和参考机器翻译结果,并在机翻译文的基础上进行编辑修改。这种新型翻译模式就是 MTPE(机器翻译+译后编辑),能够有效提升翻译效率。不过,常有译员被机翻译文里不准确的术语翻译“拖了后腿”。每当发现机翻译文与给定术语、常用译法或专有名词不一致时,译员都要花费大量时间手动查找替换,十分麻烦。
术语干预功能可以提高公司名称、品牌名称、行业缩写等术语机翻结果的准确度,减轻译者手动填充术语的负担。机器翻译+术语干预的翻译新模式有效确保了译文表达的一致性,大大提升了译员和审校的工作效率和翻译质量。
百分点智能翻译系统对文档内缩略语动态提取,然后以缩略语+全称形式翻译出来,效果如下图:
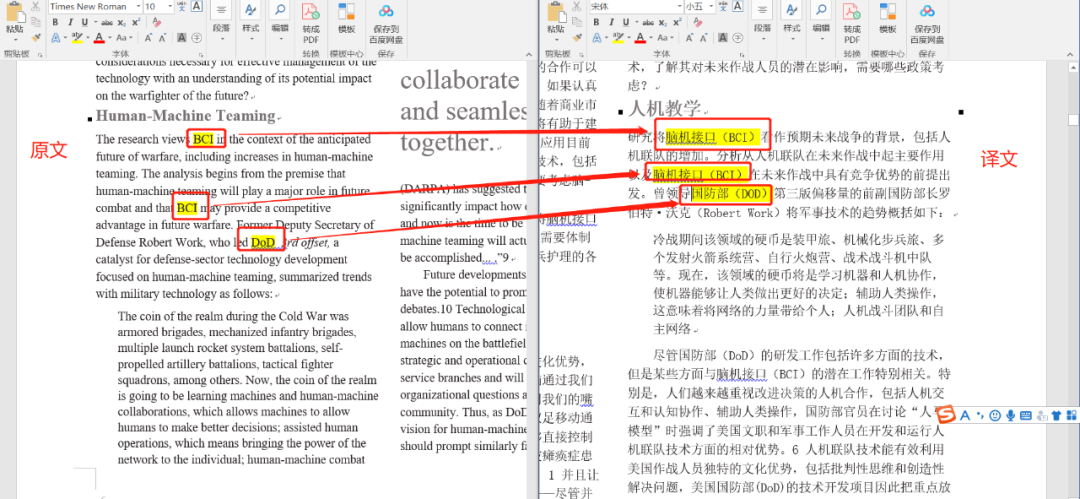
图 12.百分点智能翻译系统缩略语翻译示例图
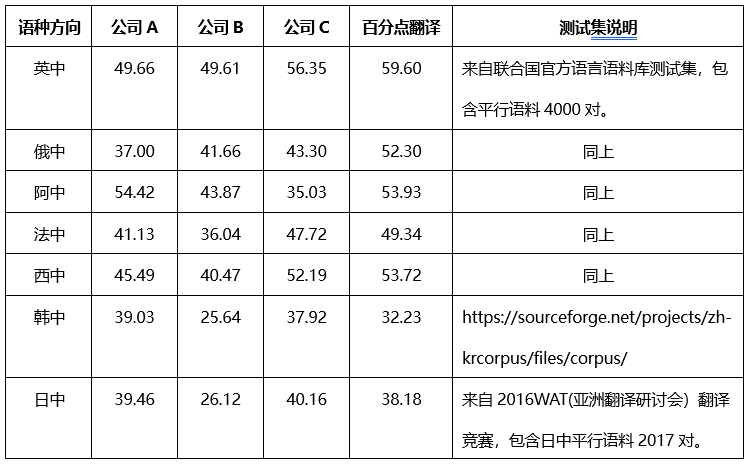
4.3 百分点翻译效果
表 3.百分点智能翻译系统评测 BLEU 得分表
5. 翻译特色
百分点智能翻译系统经过迭代打磨,积累了以下 6 大特色:
支持涵盖中文、英文、俄文、法文、西班牙文、阿拉伯文、德文、日文、韩文等多语种互译。
具有文档翻译、文本翻译、文档转换、图表提取等四大功能。
混合语言翻译。支持混合语种文档的自动识别和翻译,即上传混合语种文档,翻译为指定语言的译文。
术语干预翻译。系统支持词库、句库、缩略语库干预神经机器翻译结果。
缩略语自动识别。支持对文档中缩略语的自动识别、提取匹配和智能翻译,即文档中某一处出现了缩略语的简写以及对应的全文,在其他仅出现缩略语的地方也能给出缩略语对应全文的译文。
支持本地化和 saas 部署。
三、结束语
机器翻译算法发展非常快,随着全球信息交流的加快,要求翻译形态更趋于多元化,人们对于翻译效果要求越来越高。百分点科技将在机器翻译效果优化上持续发力,尝试融合语音、图像的多模态翻译、元学习、迁移学习等方法,追踪前沿技术,践行用认知智能技术服务社会发展的使命。
参考资料
[1]Sutskever I, Vinyals O, Le Q V. Sequence to sequence learning with neuralnetworks[C]//Advances in neural information processing systems. 2014.
[2]Dzmitry Bahdanau, Kyunghyun Cho, and Yoshua Bengio. Neural machine translationby jointly learning to align and translate. CoRR, abs/1409.0473, 2014.
[3]Cho K, Van Merriënboer B, Gulcehre C, et al. Learning phrase representationsusing RNN encoder-decoder for statistical machine translation[J]. arXiv, 2014.
[4]Yonghui Wu, Mike Schuster, Zhifeng Chen, Quoc V Le, Mohammad Norouzi, WolfgangMacherey, Maxim Krikun, Yuan Cao, Qin Gao, Klaus Macherey, et al. Google’sneural machine translation system: Bridging the gap between human and machinetranslation. arXiv preprint arXiv:1609.08144, 2016.
[5]Jonas Gehring, Michael Auli, David Grangier, Denis Yarats, and Yann N. Dauphin.Convolutional sequence to sequence learning. arXiv preprint arXiv:1705.03122v2,2017.
[6]Ashish Vaswani, Noam Shazeer, Niki Parmar,Jakob Uszkoreit, Llion Jones, Aidan N Gomez, L ukasz Kaiser, and IlliaPolosukhin. Attention is all you need. In Advances in neural informationprocessing systems, pages 5998–6008, 2017.
[7]肖桐, 朱靖波. 机器翻译统计建模与深度学习方法.
[8]Vaswani A , Shazeer N , Parmar N , et al.Attention Is All You Need[J]. arXiv, 2017.
本文转载自:百分点认知智能实验室(ID:baifendian_com)




