

实时业务校验平台作为阿里集团老牌的业务审计系统,覆盖了集团绝大部分的业务对账场景,在线上问题及时发现以及减少集团资损上发挥着巨大作用,保障了各个系统的业务稳定性。本文主要介绍实时业务校验平台(以下简称 BCP: Business Check Platform)在智能化方面的创新和实践。
关键词:数值一致性、状态一致性、多值属性、算法加速
一、需求背景
随着业务规模的扩张,阿里集团内部的系统变得越来越复杂,在这种复杂的分布式系统架构下,难免会出现远程调用失败,消息发送失败,并发 bug 等等问题,这些问题最终会导致系统间的数据不一致,导致用户体验受损,用户利益受损,对平台来说就是产生资损。意识好的或者是出过问题的系统,可能会去配置一些校验任务,比如每隔 1 小时,去跑一次离线计算任务,判断这段时间内是不是有数据故障出现,但是这种方式时效性较差,然后每个系统团队的对账方式都比较零散随意,我们没有一套体系化解决数据问题的方案,线上问题又一直存在不断有新的问题产生,处理比较被动,数据质量这块一直是个空白的领域。
BCP 就是在这种背景下产生,用来帮助业务系统实时校验线上的每一笔数据,填补数据质量领域的空白。BCP 主要实现以下 4 个目标:
高实时性的发现线上业务脏数据或者错误逻辑,第一时间发现并及时通知技术保障,而不是等客户反馈。
方便的接入各种业务规则,通过脚本规则编写的方式,让各应用快速接入平台。
整合订正工具,形成规范的脏数据订正流程。
业务上线的实时监控,新上线业务可以很方便的进行校验。
为了更高效率的让应用快速接入业务对账平台,同时减少对应用带来的性能损耗和代码侵入,BCP 通过事件模式,把业务数据变化触发的消息(如 DB 变更日志数据,消息中间件消息)转换成响应业务的事件,放入到事件执行队列进行规则的检查,事件监听框架采用了通用的架构设计,实现了消息的对接,而 DB 日志又可以转接到消息上,实现数据库变更的实时监听。
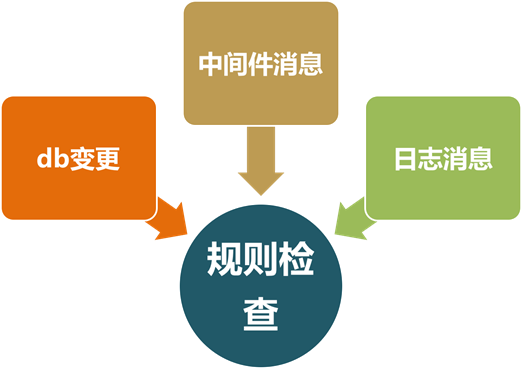
图 1 事件模式
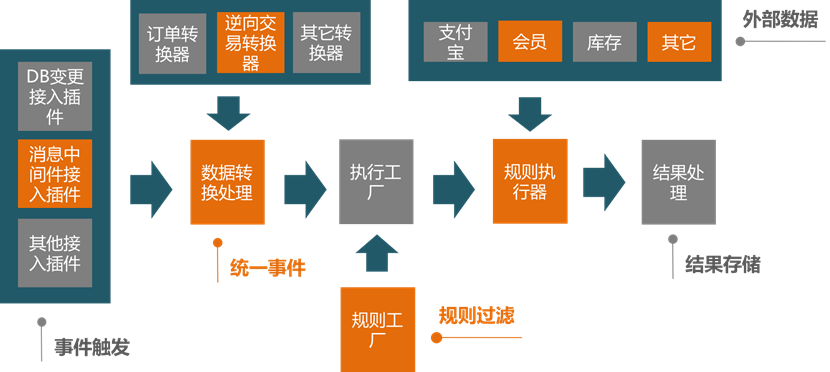
图 2 BCP 系统架构图
BCP 的运行依赖规则,规则是对业务逻辑(规律)的抽象,通过执行规则检查数据,发现问题。所以核心问题是如何定义规则,传统的对账模式一般需要业务方在理解透业务的情况下进行资损点预判与梳理,然后配置手工规则脚本,对数据进行实时校验及时发现异常。
随着业务规模的扩张,业务变更变得愈发频繁,我们需要不断的增加新的校验规则以适应新业务的对账需求,这里面需要业务开发、业务测试以及技术支持共同来梳理,消耗非常多的人力,这种方法已经越来越不适应各种复杂业务场景的需要,而且很多情况下即使是提前进行预防梳理,仍然不能覆盖住所有可能的资损场景。极端一点的情况是,我们很多的资损点都是通过“踩坑"踩出来的,即发生了资损问题之后再去编写对账逻辑亡羊补牢,所以传统的对账模式暴露出了如下几个问题:
过于依赖专家知识和经验,对于每个新场景都需要人工生产规则,效率低通用性差。
无法及时适应大规模数据的变化,特别是当数据、规律发生变化时。
漏报,极端情况甚至是在系统出了故障“踩坑”后才触发某些规则的发现。
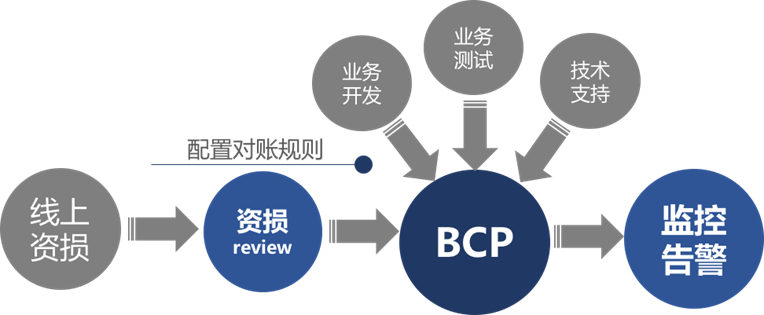
图 3 传统的配置规则方式
目前 BCP 接收了集团内大部分的业务数据,如何将这些数据产生更大的价值,是我们一直在思考的问题,智能化就是其中的一个方向。
我们希望通过智能化的方式让机器自动去发现业务数据之间的规律与异常数据,帮助业务方进行资损点梳理与监控,让资损防控的工作变得更加简单和高效,解决上面提到的若干问题。
二、智能化
定位
BCP 要实现智能化,首要目标就是找清楚自己的定位,而机器学习从学习形式上,可以分为监督学习和非监督学习,监督学习是在学习过程中通过提供对错标注指示,让机器自我减少误差的过程;相对的,由于人工标注成本较高的原因,让机器从类别未知的没有对错指示的训练样本中进行模式识别的问题称为非监督学习。
由于规则本身的逻辑问题或者业务的变化,不可避免的要带来误报警的干扰,当然这还是在 BCP 传统手工规则的时代,业务方非常清楚自己的业务逻辑的情况下发生的。如果引入智能化对账,所有的对账逻辑都由机器自己去发现然后自动进行异常数据告警,误报的可能性一定是非常高的,所以我们在设计之初就把这个问题定位为了监督学习的问题。
既然是监督学习,就要有标注的工作,标注的工作由谁来做?BCP 作为一个业务下层的统一平台不理解业务,做不了这个事,那只能交给业务开发方自己来做。标注什么内容?是异常数据还是机器发现的对账逻辑?如果是异常数据,首先数据量比较大标注的任务会比较多,其次单独看一条数据是否有异常从成本上来讲也比较高,所以我们选择的是直接标注由机器发现的对账逻辑。
目标
BCP 实现智能化,主要完成两个目标:
1.自动识别资损点,即从业务数据中发现潜在的规律。
2.自动识别异常数据,即找出不符合业务数据规律的异常点。
核心思想
BCP 智能化的核心思想是,基于大部分数据正常的原则来找规律和异常数据。即我们假设大部分的业务数据都是正常的,只有极少部分的数据存在问题。
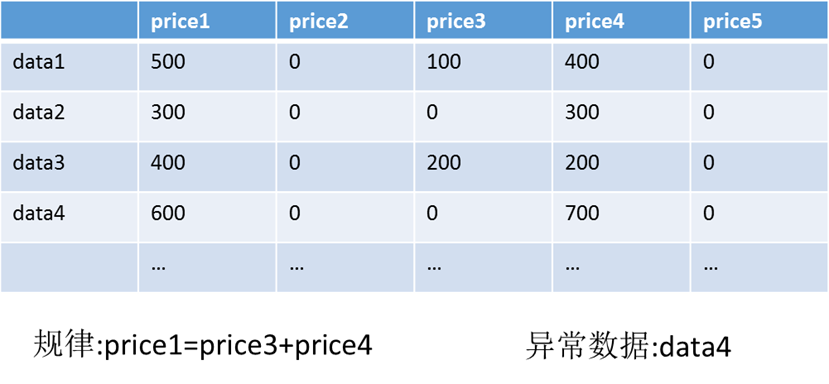
智能化例子
上图是一个简单的例子,我们通过四条数据就可以找出可能的数据之间的线性规律和对应的异常数据。
而对应的,我们可能会想到一些极端场景:
1.由于开发核心业务逻辑编写的错误,可能导致大部分业务数据都是错误的,且存在同样的错误逻辑,这种场景智能化对账并不能起到应有的作用,但是会给出相应的错误逻辑规律,给业务方来参考评估。
2.由于跨部门对账的需求,会存在不同业务逻辑的数据混杂在一起的情况,如果不对这种数据进行清洗归类,智能化对账很难找到数据之间的规律,所以为了产生最好的效果,需要保证数据之间是具有共性的。
具体流程
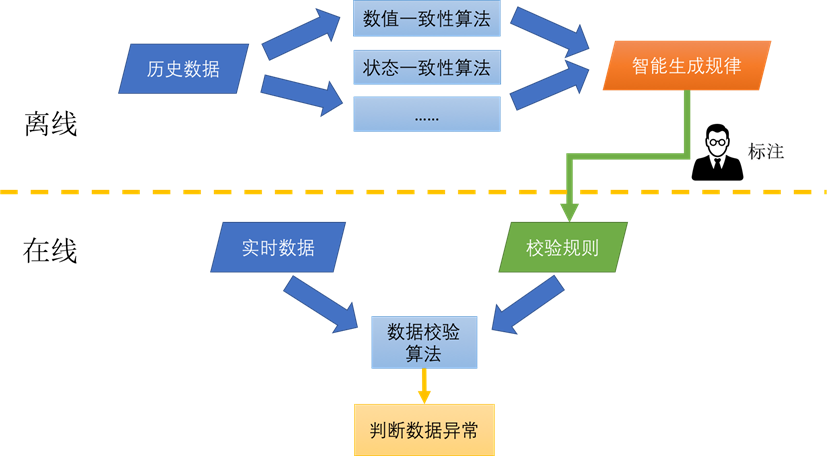
总体流程图
我们利用了 BCP 之前沉淀的大量历史业务数据,将这些数据通过不同的算法进行离线分析,生成规则(规律),同时为了减少误报的发生,使用者可以对生成的规律进行人工确认(标注),确认后会生成校验规则,进行线上数据的实时校验。
三、应用场景
下面我们介绍 BCP 中两种不同模式的智能化场景:1)数值一致性场景;2)状态一致性场景。之后我们具体介绍如何在两种场景产生规律。注意,实际中算法的应用并不局限于电商交易数据,而是可以解决所有有属性关联数据这一类场景的异常检测需求。
数值一致性场景
数值一致性场景对应于连续性变化数据(continuous data),主要解决具有线性关系的对账场景,比如和价格,积分有关的相关计算场景,如之前图 4 中的例子。我们将找到的线性关系作为规律,违背该规律的就可以认为是异常数据;我们的目标是利用大量历史数据,智能的找出以上规律,通过人工确认校验规则,然后利用校验规则来检测异常。
算法介绍
针对连续变化数据,我们考虑 N 条数据 x:1,⋯,x:N,其中每条数据都有 D 个数值属性 p1,p2,⋯,pD 参与找规律。我们可以将数据记做维度为 N×D 的矩阵 X=[x1:,x2:,⋯,xD:], 其中 xi:∈RN(i=1,⋯,D) 。为简化标注我们后面记 xi=xi:∈RN 。我们的目标是从数据 X 中找出 D 个属性之间的线性规律。每一则规律可以表示为一个向量 r=[a1,a2,⋯,aD], 其中 ai(i=1,⋯,D)代表线性规律的系数。如规律 p1=2p2+p3 可表示成 r= [−1,2,1,0,⋯,0] (共有 D−3 个 0) 。我们用−r 可以表示同样的规律,我们这里约定让规律表达中有尽可能多的正数。上面的线性关系可以使用矩阵的形式表示为: Xr=0.
在实践中,我们的目标是找到所有线性规律的集合。事实上,该问题可以建模为一个对数据在低维度空间线性分解的,找到属性之间的关系(下图红色部分表示低维空间的的线性关系),同时还要容忍数据中少量存在的异常(即下图灰色部分的稀疏矩阵)。
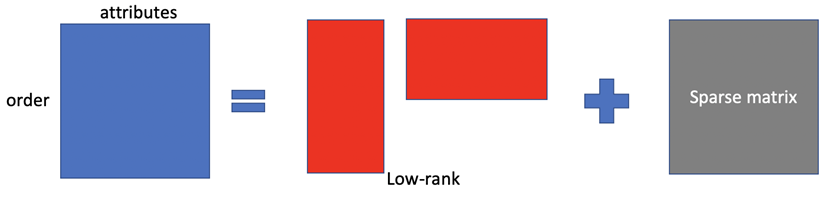
图 7 数据模型
理想情况下,我们观察到的数据事实上是可以用一个低秩矩阵来表示。但是在实际中,观察到的数据在很多时候是受到异常污染的,所以除了低秩矩阵外,我们还需要使用一个稀疏矩阵来表示受污染的情况:稀疏矩阵中的非零值表示该行数据不满足某些线性规律,零值表示为正常数据。从数学上看,每个规律对应于 X 中一组线性相关的列。我们使用线性回归算法可以简单的检验一组列是否存在线性关系。
这里我们举一个简单的例子:假如数据中存在规律 p1=2p2+p3,或者写成 p3=p1−2p2,那么我们可以线性回归研究 XS=[x1,x2],yS=x3 的关系找到该规律(即系数)。但是在实际中,直接使用线性回归很难得到较好的效果,因为实际数据中会可能会存在少量异常数据,因此有少量数据不满足 p3=p1−2p2 的规律,从而导致直接使用实际数据进行线性回归时会产生偏差,进而不能找到真正的规律。
为了解决这个问题,我们提出了迭代线性拟合(Iterative Linear Regression)的算法来从含有异常的数据中找到规律。该算法的基本思想是当我们进行线性拟合时,异常的数据必然会带来较大的残差,那么我们在拟合后根据较大的残差将异常的数据剔除,再进行新一轮的线性拟合,直到所有数据的残差都很小才停止迭代。如果有规律,那回归中所得的系数最后会收敛到规律系数;如果没有规律,则迭代会因为一些条件而提前终止。算法大致流程可参考下图。
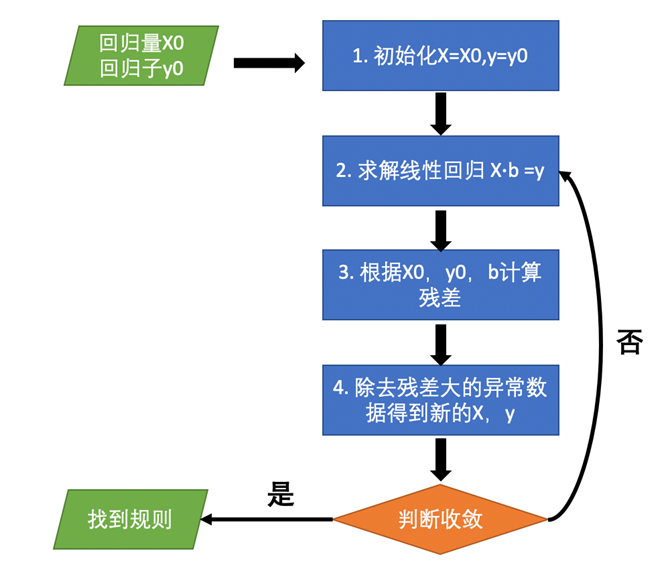
图 8 迭代线性拟合流程
该算法可以用来寻找特定属性之间的关系,为了找全量数据 X 中的所有规律,我们通过维持一组线性无关的基,然后不断的与新属性调用迭代线性拟合流程,根据找到规则决定是否添加属性扩展该组基。我们随机选取初始基并重复该过程从而找到所有关心的规律,具体细节在此不赘述。
状态一致性场景
状态一致性场景对应于分类型数据(categorical data),主要是用来做数据属性状态的识别和一致性判断,状态一致性仅考虑状态,针对于分类变量属性之间的 if-then 关系。类似的,违背该 if-then 关系的数据可以认为是异常。
状态一致性对账可以细分为 4 个种类的对账:
1.某个属性等于一个固定值,此类对账一般用来判断数据是否正确响应,标记位是否正确。例如:
response.code=200,
responseDataObject.success=true,
bizOrder.attributes.unity=1
2.某个属性虽然不是 100%等于一个固定值,但是在某种条件下是 100%等于一个固定值,此类对账一般用来解决数据状态是否正确跃迁,多份数据属性一致性的检测,例如:
if attributes.bizCode=refund,then attributes.status=0 and attributes.forOdrRcv=14
3.某个属性出现的情况和另一个属性出现的情况完全一致,此类对账一般用来解决数据标是否存在,红包是否漏发,属性是否缺失等等,例如:
if exists credit_buy,then exists rev
4.上述 3 类对账的混合情况,并且引入针对特殊数据的筛选逻辑,支持更精细的一致性对账,例如:
if bizorder.attributes.ptl contains(‘COUPON’),then attributes.peer =true and bizorder.attributes.item contains(‘80194’)
算法介绍
针对分类变量的数据,我们同样考虑 N 条数据 x:1,⋯,x:N,其中每条数据都有 D 个分类变量属性 p1,p2,⋯,pD 参与找规律,对于 i=1,⋯,D, 每个属性 pi 都可以取对应分类变量集合 Vi 中的值。这里我们记 Vi={ai1,⋯,aini }代表属性 pi 可以有 ni 个不同的分类变量可取的值的集合。我们的目标是从数据 X 中找出 D 个属性之间的关联规律。每一则规律可以表示为一个集合映射
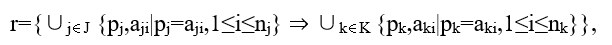
其中 J∩K=∅ 。例如,规律“当 p1 是 a12, p2 是 a21,那么 p3 是 a31” 可以表达为
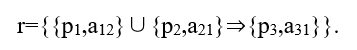
同样,我们需要找到的规律就是一个集合 R={r(1),r(2),⋯ }包含尽可能多的规律。
从问题定义来看,这是一个可以转化为关联分析挖掘(association rule mining)的问题。关联分析最初是用来找交易数据中产品的规律的。例如,从大量交易数据中发现规律{网球拍}⇒{网球},则表明顾客如果买了网球拍,有很大概率也会买网球。常见的关联规律是布尔关联规律(Boolean association rules),即考虑的数据项是布尔型,只有存在或不存在两种状态(如前面的购买网球拍只有存在和不存在两种状态)。假设我们对分类变量规律进行简化,所有属性 pi 都只有两种状态,即 ai1=0 不存在, ai2=1 存在, 其中 ni=2,∀i=1,⋯D 。那么我们的问题可以完全转化为关联分析来解。
但是,在实际应用时,还有两个问题需要解决:
关联分析一般用来处理“布尔”类型,即属性只能有两种取值状态,我们实际应用中属性会有多种状态
关联分析的搜索空间巨大,数据量大时搜索复杂度指数级增长
为了解决这两个问题,我们:
对数据进行转化,有 n 种状态的属性被拆为 n 个不同的属性,每个属性变为“布尔”类型
针对 BCP 的特殊场景,用户只关心数据全部都符合的规律,我们对算法做了优化,相比传统对 Apriori 及 FP Growth 算法,可以达到 50-100 倍的提速,从而在数据量大属性多的场景也可以运行
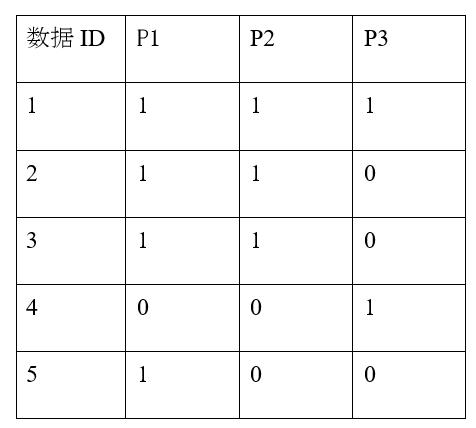
我们后面会对这两点再做介绍,首先我们介绍一下传统的找关联规则的方法思想。考虑如下例子,假设我们有 5 条数据,3 个属性,如下表所示:
我们将所有交易记做 X,每一条数据记作 x, 定义以下基本概念:
项集(itemset): 项的集合 S,包含 k 个项的称为 k−项集。如{ p1,p2}为二项集。
支持度(support): 描述一个项集在所有数据中出现的频繁程度,定义为 supp(S)=|x∈X;S⊆x|/|X| 。上例中项集{p1}的支持度为 4/5=0.8,项集{ p1,p2}的支持度为 3/5=0.6。
置信度(confidence):描述一条规律被满足的频繁程度,假设一条关于项集的规律 P⇒Q ,则该条规律的置信度为 conf(P⇒Q)=supp(P∪Q)/supp§。如上例中我们发现规律 p1⇒p2, 则该规律的置信度为 supp(p1,p2)/supp(p1)=0.6/0.8=0.75。
现在,我们讲述关联分析找规律的方法,主要包括以下两步:
频繁项集的产生:找到数据集中支持度大于某个阈值(min_support)的所有项集,该阈值叫做最小支持度;
规则的产生:从第一步的频繁项集中,根据 k-项集和比 k 高的项集联合,找到规则置信度大于某个阈值所有规则。
其中第一步的计算开销一般远大于第二步,很多算法都集中在第一步中如何更高效的产生频繁项集,主要有先验算法(Apriori)与频繁模式增长(FP Growth),我们用比较成熟的 Apriori 算法来解决。
多值属性
以上我们仅考虑了布尔关联规律场景,属性只有存在/不存在两种状态,实际应用中属性往往可以取多个值,为此我们对数据进行转化,假如我们有以下 5 条数据,2 个属性 p1,p2,其中属性 p1 是匿名状态有两种状态分别为 a11=匿名, a12=实名,属性 p2 是评价积分有三种状态分别为 a21=好评, a22=中评, a23=差评。那么我们有分类变量数据如下
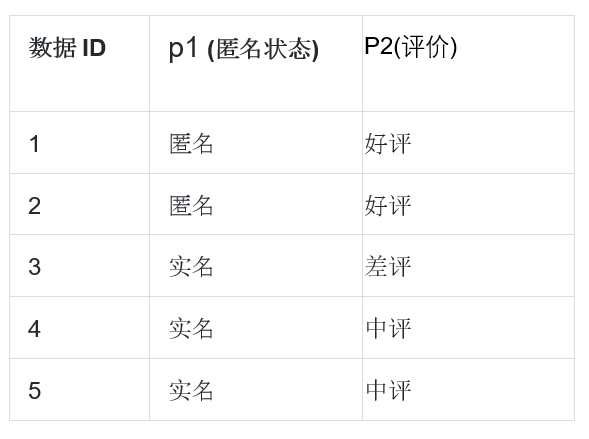
通过转换,我们可以将以上多状态值的分类变量数据转化为布尔型:
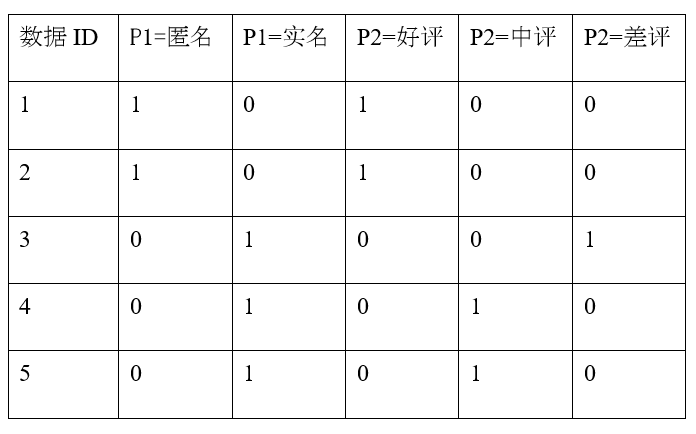
经过转换我们就可以用同样的方法解决实际数据中的属性多状态值问题。
算法加速
实际应用中,业务方往往更关心置信度为 100%的规律,而算法在搜索的时候,如果还是简单的采用不停产生规律然后计算置信度将非 100%置信度的规律剔除这种做法,运行时间会非常久。这里我们对算法做了优化,通过对搜索路径的更改,让算法在产生规律时就只搜索 100%置信度的规则,从而加快运行时间提升效率,达到相比之前 50-100 倍的提速。
因此,实际中算法的大致流程如下图所示。

图 9 算法流程
应用
以上介绍的两种算法目前已经稳定运行在 BCP 平台,并且大量应用在集团的业务对账场景中,日均调用量在亿级别次,每日发现几十到上百例数据质量问题,通过检测出异常及时进行告警避免了资产的损失。
四、结语
对于阿里巴巴而言,今年是 BCP 智能化的元年,通过智能化我们整体提升了业务对账的效率,使得实时业务校验这项工作变得更加简单。
但是,未来的路还很长,在海量的业务数据中,还有很多潜在的规律可以挖掘,数值类和状态类的智能化只是我们实现智能对账的第一步,后面我们还会准备在更多的对账领域实现智能化,让机器智慧给业务带来更多红利。
参考文献
[1]Böhm, C., Kailing, K., Kröger, P., & Zimek, A. (2004). Computing Clusters of Correlation Connected Objects. In Proceedings of the 2004 ACM SIGMOD International Conference on Management of Data (pp. 455–466). New York, NY, USA: ACM.
[2]Agrawal, R., & Srikant, R. (1994). Fast Algorithms for Mining Association Rules in Large Databases. Journal of Computer Science and Technology, 15(6), 487–499.
[3]Li, J., Zhang, X., & Dong, G. (1999). Efficient Mining of High Confidence Association Rules without Support Thresholds. Principles of Data Mining and Knowledge Discovery, (September 1999), 283–288.
作者简介(按姓氏拼音排序,排名不分先后)
高超(龙多):阿里巴巴集团安全生产高可用架构组技术专家。
高靖昆(井乾):阿里巴巴达摩院机器智能技术算法专家。
孙亮(图宇):阿里巴巴达摩院机器智能高级技术算法专家。

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论 2 条评论