
整理 | 华卫、核子可乐
近日,微软的研究人员声称,他们已经开发出了迄今为止规模最大的原生 1-bit 人工智能模型。该模型名为 BitNet b1.58 2B4T,仅使用 0.4GB(约 409.6MB)内存,可以在包括苹果 M2 芯片在内的 CPU 上运行。评估结果显示,该模型在各种任务中与同等规模的领先开源权重全精度大语言模型表现近乎相当,同时在计算效率方面具有显著优势,包括大幅减少内存占用、能耗以及解码延迟。
目前,该模型 100% 开源,可供在 MIT 许可协议下公开使用。在 Hugging Face 上,微软还提供了 BitNet b1.58 2B4T 多个版本的模型权重,包括经过打包的 1.58 bit 权重、BF16 格式的主权重和 GGUF 格式的模型权重。
_模型权重:_https://huggingface.co/microsoft/bitnet-b1.58-2B-4T
_试用链接:_https://bitnet-demo.azurewebsites.net/
有网友评价该模型道,“如果它真的匹配全精度模型性能,那就太不可思议了。”“BitNetb1.58 2B4T 的发布是 LLM 发展历程中的一个里程碑,其性能和效率令人印象深刻。”
值得一提的是,BitNetb1.58 2B4T 成果背后这支来自 Microsoft Research 的技术团队,全员都是中国人。

据了解,论文一作马树铭(Shuming Ma)是北京大学电子工程与计算机科学学院(EECS)的一名硕士研究生,目前处于研三阶段,从事自然语言处理和机器学习方面的研究工作。二作王鸿钰(Hongyu Wang)是中国科学院 (CAS) 的三年级博士生,2021 年 8 月至今在微软亚洲研究院 GenAI 团队担任研究实习生, 在韦福如(Furu Wei )和马树铭的指导下开展工作。
韦福如现任微软杰出科学家,领导团队从事基础模型、自然语言处理、语音处理和多模态人工智能等领域的研究。近年来,他还致力于领导和推进通用型人工智能的基础研究和创新。韦博士还担任西安交通大学和中国科技大学兼职博士生导师,香港中文大学教育部 - 微软重点实验室联合主任。此前,他分别于 2004 年和 2009 年获得武汉大学学士学位和博士学位。
性能与同等参数模型相当,速度甚至是其两倍
作为首个具有 20 亿参数(“参数”在很大程度上与“权重”同义)的 BitNet,BitNet b1.58 2B4T 在包含 4 万亿个 token 的数据集上进行了训练(据估算,这大约相当于 3300 万本书的内容),并在涵盖语言理解、数学推理、编码能力和对话能力等方面的基准测试中经过了严格评估,在各个方面的性能都与类似规模的同类模型近乎相当,同时显著提升了效率。
需要明确的是,BitNet b1.58 2B4T 并非完全胜过与之竞争的拥有 20 亿参数的模型,但它的表现似乎的确不俗。根据研究人员的测试,该模型在包括 ARC-Challenge、OpenbookQA、 BoolQ、GSM8K(小学水平数学问题的集合)和 PIQA(测试物理常识推理能力)等在内的基准测试中,超过了 Meta 的 Llama 3.2 1B、谷歌的 Gemma 3 1B 和阿里巴巴的 Qwen 2.5 1.5B。
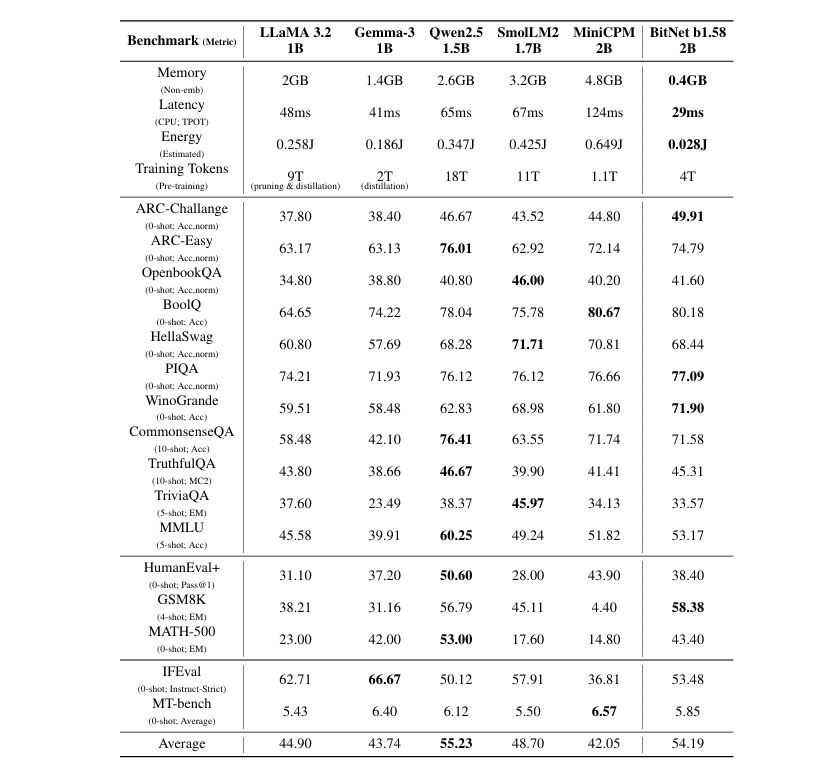
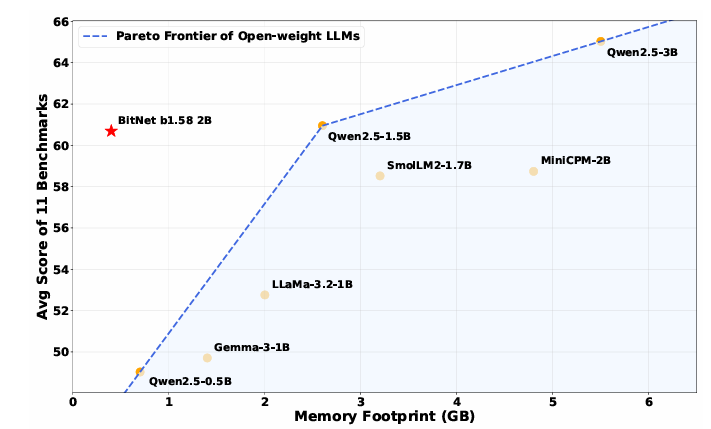
图:BitNet b1.58 2B4T 与类似尺寸(1B-2B 参数)的领先开放权重全精度 LLM 在各种基准测试中的效率指标和性能的比较
更令人印象深刻的是,BitNet b1.58 2B4T 的运行速度比其他同等规模的模型更快,在某些情况下的速度甚至能达到其他模型的数倍,同时内存占用却只是后者的一小部分。BitNet b1.58 2B4T 的内存大小仅为 0.4GB,CPU 推理延迟是 29ms;而其他同等规模的模型需要 1.4-4.8GB,CPU 推理延迟在 41ms-124ms。
从微软在技术报告中放出的对比图可以看到,BitNet b1.58 2B4T 在性能上几乎与 Qwen 2.5 1.5B 相当,但内存大小仅为后者的 1/6,速度提高了 2 倍。并且,其性能优于需 2GB 内存的 Llama 3.2 1B 模型,且 BitNet b1.58 2B4T 处理 token 的速度还要快 40%。
此外,具有 1000 亿(100B)参数的 BitNet b1.58 模型可以在单个 CPU 上运行,速度可与人类阅读速度相媲美(每秒处理 5-7 个 token),这一结果极大地增强了在本地设备上运行 LLM 的可能性在 Github 上,微软还放出了在苹果 M2 上运行 BitNet b1.58 3B 模型的演示视频:
据介绍,Bitnet 本质上是专为在轻量级硬件上运行而设计的压缩模型。微软表示,在 BitNet 和 BitNet b1.58 上取得的这一新进展,为在速度和能耗方面提高大语言模型(LLM)的效率提供了一种可行的方法,还使得 LLM 能够在广泛的各类设备上进行本地部署。
_开源项目地址:_https://github.com/microsoft/BitNet
技术架构的核心创新
微软在技术报告中介绍,BitNet b1.58 2B4T 完全是从零开始训练的,架构源自标准 Transformer 模型,其中包含基于 BitNet 框架的重大修改。核心创新在于,将标准的全精度线性层 (torch.nn.Linear) 替换为自定义 BitLinear 层。
传统大模型依赖 32 位或 16 位浮点数存储权重,而该模型将权重压缩至 1.58 位,这是使用绝对平均值 (absmean) 量化方案实现的,将权重量化为三个值:-1、0 和 1,大大减小了模型大小并实现了高效的数学运算。由于三元权重无法使用标准数据类型进行高效存储,因此微软将多个权重值打包成一个 8 位整数并存储在高带宽内存(HBM)当中。这采用了绝对最大 (absmax) 量化策略,应用于每个 token。
从理论上讲,这使得其比当今的大多数模型都更加高效。在标准模型中,权重(定义模型内部结构的值)通常是量化的,因此模型在各种机器上表现良好。对权重进行量化会减少表示这些权重所需的比特数(比特是计算机能够处理的最小单位),从而使模型能够在内存较小的芯片上更快速地运行。
至关重要的是,该模型是使用这种量化方案从头开始训练的,而不是训练后才进行量化的。除了 BitLinear 层之外,该模型还集成了激活函数 (FFN)、位置嵌入和偏差消除几种已建立的 LLM 技术以提高性能和稳定性。
训练过程中,BitNet b1.58 2B4T 涉及三个不同的阶段:大规模预训练,然后是监督微调 (SFT) 和直接偏好优化 (DPO):预训练时使用两阶段学习率和权重衰减计划,在公开的文本 / 代码数据以及合成数学数据上进行大规模训练;监督微调 (SFT)过程中,使用损失求和聚合方法以及特定的超参数调整,在遵循指令和对话相关的数据集上进行微调;利用偏好数据直接优化语言模型,来使其符合人类在有用性和安全性方面的偏好。
背后是微软定制框架,硬件兼容性可能受阻
微软称,要使 BitNet b1.58 2B4T 模型实现技术报告中所展示的效率优势,必须使用专门的 C++ 实现方案,即 bitnet.cpp。当前商用 GPU 架构在设计上并未针对 1 bit 模型进行优化,itnet.cpp 提供经过优化的内核,可以确保此模型能够在缺少强大 GPU 加持的设备(如边缘设备、笔记本电脑、标准服务器等)上部署以实现广泛可及。
据介绍,bitnet.cpp 是一个微软专门定制的用于 1-bit LLM 的推理框架,基于 llama.cpp 框架,旨在在优化速度和能耗的同时释放 1-bit LLM 的全部潜力。具体来说,他们在 T-MAC 中开创的 Lookup Table 方法之上开发了一套内核,支持在 CPU 上对 BitNet b1.58 这种三权重值的 LLM 进行快速且无损失地推理。对于三权重值之外的一般低 bit LLM,微软则建议使用 T-MAC 来做推理。
在公开披露的技术报告中,微软从推理速度和能耗两个方面对 bitnet.cpp 进行了评估,并针对参数大小从 125M 到 100B 的各类模型展开了全面测试。微软还分别在 ARM 和 x86 架构上进行了系统测试,在 ARM 这边,选择搭载有苹果 M2 Ultra 处理器及 64 GB 内存的 Mac Studio 进行了三轮端到端测试;在 x86 这边,使用的则是搭载英特尔酷睿 i7-13700H 处理器(14 核,20 线程)加 64 GB 内存的 Surface Laptop Studio 2。
此外,微软分别在两台设备上测试了两种场景:其一是将推理限制在两个线程之内,其二则不设线程限制,以求得出最佳推理速度。据悉,此举旨在考虑本地设备上的可用线程数量有限这一现实情况,希望更准确地评估 BitNet b1.58 在本地环境中的性能表现。
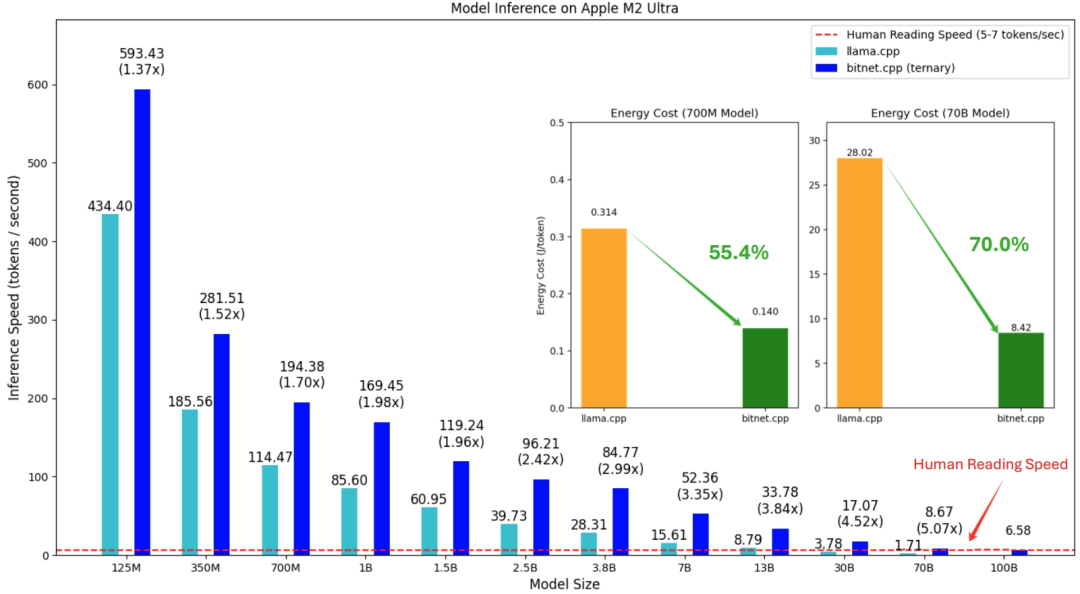
图:使用 llama.cpp (fp16)与 bitnet.cpp 在 Apple M2 Ultra (ARM CPU) 上、各种 BitNet b1.58 模型大小的推理速度和能耗比较
结果显示,bitnet.cpp 在 ARM CPU (苹果 M2)上实现了 1.37 倍到 5.07 倍的显著提速效果,将能耗降低了 55.4% 到 70.0%,进一步提高了整体效率。在 x86 CPU (英特尔 i7-13700H)上的提速范围为 2.37 倍到 6.17 倍,能耗降低在 71.9% 到 82.2% 之间。
并且,bitnet.cpp 在 ARM 与 x86 CPU 上的性能均显著优于 llama.cpp,且优势随模型规模增长进一步提升,速度从 1.37 倍到 6.46 倍不等,具体视模型与架构而定。在苹果 M2 且线程数量不受限的情况下,速度比峰值可达到 5.07 倍;而在英特尔 i7-13700H 且线程受限的情况下,bitnet.cpp 的速度比最高可达 6.46 倍,意味着其在资源受限的本地系统推理运行中特别有效。
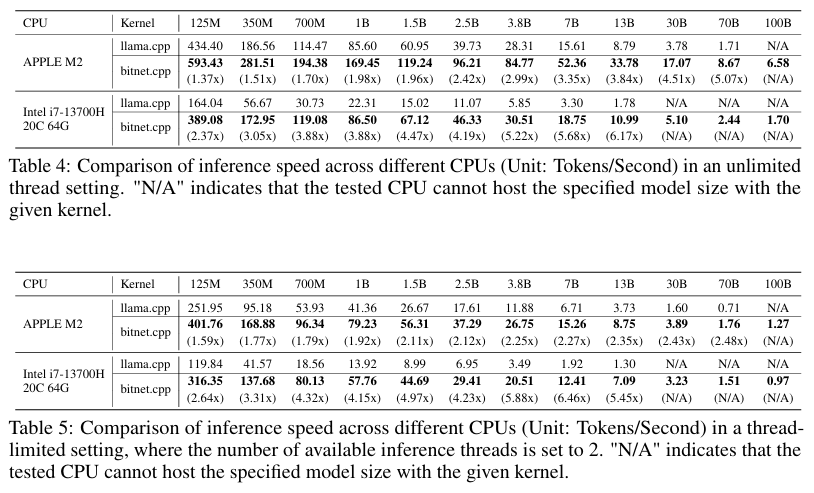
图:在无限线程和线程受限设置中不同 CPU 的推理速度比较
除了性能差异之外,带宽限制在不同架构的 bitnet.cpp 的不同功效中起着重要作用,尤其是在比较 苹果 M2 和 Intel i7-13700H 时。由于 苹果 M2 的带宽更大,与 Intel i7-13700H 相比,bitnet.cpp 的速度提升明显更快,尤其是在运行大体量模型时。
在对比能耗成本时,微软分别运行了参数为 700M、7B 和 70B 的模型。在苹果 M2 上,随着模型体量的增加,bitnet.cpp 的能效提升亦更加显著。这凸显了 bitnet.cpp 在速度和能源使用方面更高效地部署大规模推理的能力,这对于移动设备或边缘计算等能源受限的环境至关重要。在英特尔 i7-13700H 芯片上,使用 bitnet.cpp 的节能效果更为显著。虽然目前尚无 70B 模型在该英特尔 CPU 上运行的直接能耗数量,但对较小模型进行测试的结果清晰表明,bitnet.cpp 能够显著降低大语言模型在高性能多核心处理器上执行推理时的能耗需求。
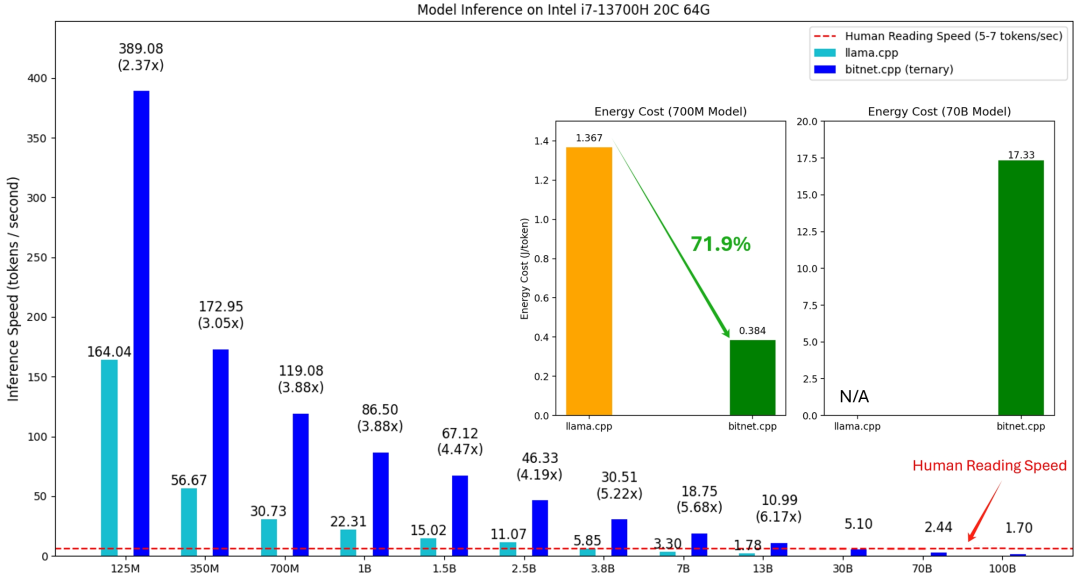
图:不同 CPU 之间的能耗成本比较(单位:焦 /token),“N/A”代表测试的 CPU 无法使用给定核心运行指定大小的模型
为了评估推理准确性,微软从 WildChat 中随机选取了 1000 条提示词,使用到 700M BitNet b15.8 模型,并将 bitnet.cpp 及 llama.cpp 生成的输出与 FP32 内核生成的输出进行了比较。评估工作是逐个 token 进行的,每个模型输出最多 100 个 token,且仅在推理样本与全精度输出完全匹配时方认定该样本为无损。结果证实,bitnet.cpp 能够对 1-bit LLM 实现准确、无损的推理。
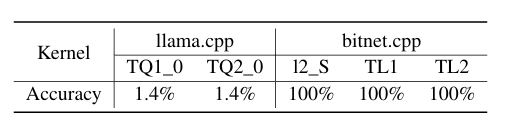
图:llama.cpp 与 bitnet.cpp 之间的推理准确率对比
然而,需要一提的是,bitnet.cpp 框架目前只能在特定的硬件上运行。在其支持的芯片列表中,并不包括在 AI 基础设施领域占据主导地位的图形处理器(GPU)。也就是说,BitNet 或许前景可期,特别是对于资源受限的设备来说,但硬件兼容性可能仍然会是一个很大的发展阻碍因素。
不过,微软在技术报告中表示,他们已在对 bitnet.cpp 进行扩展,以支持更广泛的平台和设备,其中包括移动设备(如苹果手机和安卓设备)、神经网络处理器(NPU)以及图形处理器(GPU)。未来,微软还将致力于 1-bit LLM 的训练优化工作以及定制化硬件和软件栈的协同设计。
结语
BitNet b1.58 2B4T 代表一项令人信服的概念验证,对在大规模大语言模型(LLM)中实现高性能必须依赖全精度权重这一观点提出了挑战,为在资源受限环境中部署强大语言模型开辟了新的道路,解决了原有模型在此类环境中难以实现的问题,有望推动先进 AI 进一步实现大众化普及。
微软表示,除了当前的性能结果,BitNet b1.58 2B4T 还展现出以下几个令人兴奋的研究方向,包括研究原生 1 bit 大模型的缩放特性、扩展序列长度、多语言能力、多模态架构集成等。
参考链接:
https://arxiv.org/pdf/2504.12285
https://arxiv.org/pdf/2410.16144
声明:本文为 InfoQ 整理,不代表平台观点,未经许可禁止转载。




