

导读
本文来自 Duke Lee 对 陈丹琦博士 的博士毕业论文 《Neural Reading Comprehension and Beyond》 的翻译。该论文上传仅四天就获得了上千次的阅读量,成为了 斯坦福大学近十年来最热门的毕业论文 之一。
Duke Lee:我一直觉得阅读一本优秀的博士毕业论文是最快了解一个领域的方式。论文中会介绍它的研究的前因后果以及最近和未来的发展趋势,并且,这里面会引用大量的参考文献,这都是宝贵的经过整理的学习资料。
其次,我们可以从行文思路中学习到作者的思维方式,从其发表文章的先后顺序和年代,看到作者的成长,可以借此学习到作者的思维和学习方式。我没有翻译作者的 Acknowledgment,但是我强烈建议大家去读一下,了解一下作者的学习心态。
坦白说,中西方的思维方式 ( 我觉得会反应在语系上 ) 会略有不同,在读硕士研究生的期间,在最初的时候和导师以及一些拉丁语系母语同学的沟通的时候,我会比较难跟上。但是和中国人或者不是英语 native speaker 的人沟通的时候会比较容易一些,按照乔姆斯基的理论来说,我们都在作为“外人”努力学习英语的 generative rules,然后使用英文沟通学习。所以能找到一篇优秀的“中国造”英文博士论文也是很幸运的。希望我们都可以从中学习到很多有意义的东西,欢迎一起讨论一起进步。
本系列共分为基础篇和应用篇俩部分,基础篇如下:
今天将分享应用篇:
5. Open Domain Question Answering
在 PART 1 中,我们描述了阅读理解的任务:它在最近这些年的形成和发展,神经阅读理解的关键组件,以及未来的研究方向。然而,阅读理解究竟只是用来衡量语言理解能力的一个任务还是可以赋能一些有用的应用依然不清晰。在 PART II 中,我们将回答这个问题,并且讨论我们在构建利用神经阅读理解作为核心组件的应用。
在这章中,我们把 open domain question answering 看作一个阅读理解的应用。开放领域的问答在 NLP 的历史上有一个长期存在的问题。开放领域的问答的目标是建立自动化的计算机系统,能够回答任意种类 ( 虚构 ) 的人类可能会问的问题。而这个系统的建立是基于一个大的非结构化的自然语言文档,结构化数据 ( 例如:知识库 ),半监督数据 ( 例如:表格 ) 或者其他形式的数据例如图片和视频。
我们是第一个在开放领域的 QA 框架里测试神经阅读理解方法的性能的。我们相信,当组和有效的信息提取技术结合的时候,这些系统的高性能会是构建新一代开放领域问答系统的关键要素。
这章的组织架构如下:
我们首先给出了 open domain 问答以及历史上著名的系统的概览。
我们介绍了一个我们构建的 open-domain question answering system,DRQA,这个是设计来回答 English Wikipedia 的问题。它本质上组合了一个信息提取模块和我们在 section3.2 中描述的高性能神经阅读理解模块。
我们更进一步讨论了我们要如何改善系统,通过从检索模块创建 distantly-supervised 训练示例。接着,我们提出了一个理解评估,在多个不同的问答 benchmarks。
最后,我们讨论了现在的局限性,接下来的工作以及未来的方向。
5.1 A Brief History of Open-domain QA
问答系统是 20 世纪 60 年代 NLP 系统最早的任务之一。一个早期的系统是 PROTOSYNTHEX 系统 ( Simmons et al., 1964 ),预示了现在基于文本的问答系统。系统首先基于问题中的单词形成一个 query,然后根据与问题重叠的频率加权项检索候选答案句,最终实现依存解析匹配到最终答案。另一个著名的系统 MURAX ( Kupiec, 1993 ),被设计来回答 GROLIER 在线百科全书上的一般知识问题,使用浅层语言处理和信息检索 ( IR ) 技术。
自 1999 年 QA 赛道首次作为年度 TREC 竞赛的一部分被纳入以来,人们对开放领域问答的兴趣有所增加。该任务最初是这样定义的:系统检索包含开放领域问题答案的文本片段。它刺激了广泛的 QA 系统发展。大多数的系统包括两个阶段:一个 IR 系统用于选择和从问题中产生的 query 相匹配的文档或者篇章的 topn,并且一个窗口词评分系统用于查明可能的答案。更多细节请参考 ( Voorhees, 1999;Moldovan 等,2000 )。
最近,随着知识库的发展 ( KBs ) 如 FREEBASE ( 波尔-拉克尔 et al ., 2008 ) 和 DBPEDIA ( 奥尔 et al ., 2007 ),在基于 KBs 的问答系统下,许多创新和资源的创建出现,例如基于 FREEBASE 的 WEBQUESTIONS ( Berant et al.,2013 ) 和 SIMPLEQUESTIONS ( Bordes et al., 2015 ),或者基于 KBs 自动提取的 OpenIE triples 和 NELL ( FADER et al., )。基于知识的问题回答已经取得了很大的进展,主要的方法要么是基于语义分析,要么是基于信息提取技术 ( Yao et al., 2014 )。然而,KBs 有固有的局限性 ( 不完整和固定的模式 ),这促使研究人员最近回到原始文本回答的原始设置。
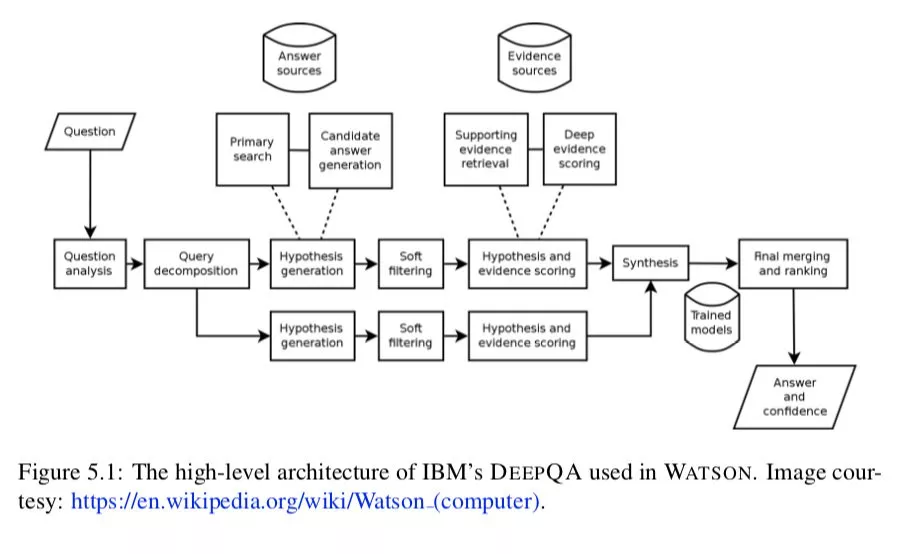
也有一些高开发度的使用无数资源的完整管道 QA 方法,包括文本集合 ( Web 页面、Wikipedia、newswire 文章 ) 和结构化知识库 ( FREEBASE、DBPEDIA 等 )。一些著名的系统——包含微软 ASKMSR ( 布里尔 et al ., 2002 ), IBM 的 DEEPQA ( 费鲁奇 et al ., 2010 )和 YODAQA ( Baudisˇ,2015 )——后者是开源的,因此复现作为对比使用。ASKMSR 是一个基于搜索引擎的 QA 系统,它依赖于“数据冗余,而不是对问题或候选答案进行复杂的语言分析”。DEEPQA 是最具代表性的现代问答系统,它在电视游戏节目《危险边缘》 ( JEOPARDY! ) 2011 年受到了广泛关注。它是一个非常复杂的系统,由管道中的许多不同部分组成,它依赖于非结构化信息和结构化数据来生成候选答案或对证据进行投票。概览结构如图 5.1 所示。YODAQA 是一个模仿 DEEPQA 的开源系统,类似地结合了网站、数据库和 Wikipedia。与这些方法相比,( YODAQA ) 为性能的“上限”基准测试提供了一个有用的数据点。
最后,还有其他基于不同资源类型的问题回答类型,包括 Web 表格 ( Pasupat 和 Liang, 2015 )、图像 ( Antol 等,2015 )、图表 ( Kembhavi 等,2017 ),甚至视频 ( Tapaswi 等,2016 )。由于我们的工作重点是基于文本的问题回答,所以我们不会深入讨论更多细节。
我们的 DRQA 系统 ( 章节 5.2 ) 侧重于使用 Wikipedia 作为唯一的知识来源来回答问题,例如在百科全书中寻找答案时使用 Wikipedia。使用 Wikipedia 作为资源的 QA 以前已经被探索过。Ryu 等人 ( 2014 ) 使用基于 wiki 的知识模型执行开放域 QA。它们将文章内容与基于不同类型的半结构化知识 ( 如信息框、文章结构、类别结构和定义 ) 的多个其他答案匹配模块相结合。类似地, Ahn et al. ( 2004 ) 也将 Wikipedia 作为文本资源与其他资源相结合,在本例中是与其他文档的信息检索相结合的。Buscaldi 和 Rosso ( 2006 ) 也从 Wikipedia 中为 QA 挖掘知识。他们不把它用作寻找问题答案的资源,而是专注于验证 QA 系统返回的答案,并使用 Wikipedia 分类确定一组应该与预期答案相匹配的模式。在我们的工作中,我们只考虑文本的理解,并使用维基百科文本文档作为唯一的资源,以强调阅读理解的任务。我们相信增加其他的知识来源或信息将进一步提高我们系统的性能。
5.2 Our System:DRQA
5.2.1 An Overview
在接下来的文章中,我们将描述我们的系统 DRQA,它专注于使用英文维基百科作为文档的唯一知识来源来回答问题。我们感兴趣的是建立一个通用知识的问题回答系统,它可以回答任何类型的虚构性问题,其中的答案包含在维基百科中,并可以从维基百科中提取。
我们选择使用维基百科有以下几个原因:
维基百科是一个不断发展的大型、丰富、详细的信息来源,可以为智能机器提供便利。与诸如 FREEBASE 或 DBPEDIA 之类的知识库 ( KBs ) 不同的是,Wikipedia 包含了人类感兴趣的最新知识。
许多阅读理解数据集 ( 例如,SQUARD ) 都是建立在维基百科上的,这样我们就可以充分利用这些资源,我们很快就会对其进行描述。
一般来说,维基百科的文章干净、高质量、格式良好,对开放领域的问题回答来说是非常有用的资源。
利用维基百科的文章作为知识来源,导致问答题的任务结合大规模开放领域 QA 和文本机器理解的挑战。要回答任何问题,首先必须从 500 多万项中检索出少数相关的文章,然后仔细扫描它们以确定答案。这让我们想起了经典的 TREC QA 系统是如何工作的,但是我们相信神经阅读理解模型将在阅读检索到的文章/段落以获得最终答案时发挥至关重要的作用。如图 5.2 所示,我们的系统基本上由两个组件组成:
① 用于查找相关文章的文档检索模块 DOCUMENT RETRIEVER module。
② 用于从单个文档或少量文档集合中提取答案的阅读理解模型 DOCUMENT READER。
我们的系统把维基百科当作一个文章的集合,不依赖于它的内部图结构。因此,我们的方法是通用的,可以切换到其他文档、书籍甚至每日更新的报纸集合。接下来,我们将详细介绍这两个组件。
5.2.2 Document Retriever
遵循经典的 QA 系统,我们使用一个高效的 ( 非机器学习 ) 文档检索系统,首先缩小搜索空间,只阅读可能相关的文章。相对于内建的基于弹性搜索的 Wikipedia 搜索 API ( Gormley and Tong, 2015 ),一个简单的倒排索引查找,然后是术语向量模型评分,在许多问题类型上都能很好地完成这项任务。将文章和问题作为 TF-IDF 加权 bag-of-word 向量进行比较。
我们进一步完善了该系统,采用 n-gram 特征考虑了局部语序。我们性能最好的系统使用了 bigram 计数,同时通过使用 hashing of ( Weinberger et al., 2009 ) 将 bigram 映射到 224 个带有 unsigned murmur3 hash 的桶 ( bin ),从而保持了速度和内存效率。
我们使用 DOCUMENT RETRIEVER 作为完整模型的第一部分,将其设置为返回给定问题的 5 篇 Wikipedia 文章。然后文档阅读器 ( Document Reader ) 处理这些文章。

5.2.3 Document Reader
Document Reader 阅读维基百科前 5 篇文章,旨在阅读所有的段落图,并从中提取可能的答案。这正是我们在基于西班牙语的阅读理解问题中所做的设置,我们在第 3.2 节中描述的 STANFORD ATTENTION READER 模型可以直接插入到这个管道中。
我们将训练好的 Document Reader 应用于出现在维基百科前 5 篇文章中的每一段,它会预测出一个置信度得分的答案跨度。为了使一个或多个检索到的文档的段落之间的分数兼容,我们使用非标准化指数,并在所有考虑的段落跨度上使用 argmax 作为最终预测。这只是一个非常简单的启发式方法,还有更好的方法聚合不同段落的证据。我们将在第 5.4 节中讨论未来的工作。
5.2.4 Distant Supervision
我们建立了一个完整的管道,集成了经典检索模块和我们之前的神经阅读理解组件。剩下的关键问题是我们如何训练这个阅读理解模块用于开放式的问题回答设置。
最直接的方法是重用 SQUAD 数据集 ( Rajpurkar et al., 2016 ) 作为训练语料库,该语料库也是建立在 Wikipedia 段落之上的。但是,这种方法在以下方面受到限制:
正如我们之前在 4.2 节中所讨论的,SQUAD 中的问题是被众包的,在标注者看到段落之后,要确保这些问题可以通过段落中的跨度得到回答。这种分布是非常具体的,与现实世界中的,当人们首先想到一个问题,并试图从网络或其他资源中找到答案时的问答不同。。
许多 SQUAD 的问题确实与背景有关。例如,在维基百科上哈佛大学的一篇文章中,一个问题 what individual is the school named after?或者另一个根据一段描述马丁·路德的文章的问题是 What did Luther call these donations?基本上,这些问题本身无法理解,因此对于开放领域的 QA 问题毫无用处。Clark 和 Gardner ( 2018 ) 估计,SQUAD 中约有 32.6%的问题依赖于文件或篇章。
最后,SQUAD 的规模是相当小的 ( 80k 训练的例子 )。如果我们能够收集到更多的训练实例,它应该就可以进一步提高系统性能。
为了克服这些问题,我们提出了一个过程,从其他问题回答资源自动创建额外的训练示例。这个想法是为了重用我们建立的有效的信息检索模块:如果我们已经有了一个问答对 ( q,a ) 并且检索模块可以帮助我们找到一个与问题 q 相关的段落以及答案片段 a 出现的段落,那么我们可以创建一个形如 ( p,q,a ) 三元组的 distantly-supervised 训练示例,提供给阅读理解模块进行训练。
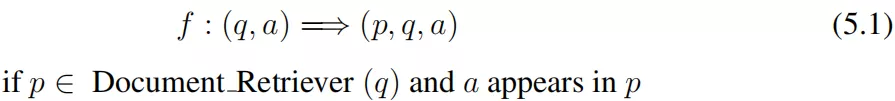
这一想法与使用远程监督 ( DS ) 提取关系的流行方法类似 ( Mintz et al., 2009 )。尽管这些例子可能在某种程度上是有噪声的,但它提供了一个廉价的解决方案来创建远程监督的例子,可以用于开放领域的问题回答,并将是一个有用的补充 SQUAD 的例子。我们将在第 5.3 节中描述这些远程监督示例的有效性。
5.3 Evaluation
我们有了 DRQA 系统的所有基本元素,让我们来看看评估。
5.3.1 Question Answering Datasets
第一个问题是我们应该评估哪些问题回答数据集。正如我们所讨论的,SQUAD 是目前可用来回答问题的最大的通用 QA 数据集之一,但它与开放域 QA 设置有很大的不同。我们认为在别的为开放领域 QA 的开发的数据集上训练和评估我们的系统的话,需要以不同的方式构建 ( 这些数据集 )。因此,我们采用以下三个数据集:
TREC,这个数据集是基于 TREC 的基准测试任务,策划了 Baudisˇ和 Sˇedivy” ( 2015 )。我们使用大的版本,其中包含从 TREC 1999、2000、2001 和 2002 的数据集中提取的总共 2180 个问题。关于问题:when is fashion week in NYC?因此,Sept(ember)?|Feb(ruary)?的答案都被认为是正确的。
WebQustions,Berant 等人 ( 2013 ) 介绍的网络问题,这个数据集是为了回答来自 Freebase 知识库的问题而构建的。它是通过在谷歌 SUGGEST API 中爬取问题创建的,然后使用 Amazon Mechanical Turk 获得答案。我们使用实体名称将每个答案转换为文本,这样数据集就不会引用 Freebase id,而完全由纯文本问答对组成。
WikiMovies,这个数据集是 Miller 等人 ( 2016 ) 引入的,包含电影领域的 96k 个问答对。这些示例最初是从 OMDB 和 MOVIE- LENS 数据库创建的,所以这些例子还可以使用 Wikipedia 的子集作为知识源 ( 电影领域的标题和文章的第一部分 ) 进行回答。
我们想强调的是,这些数据集不一定收集在基于 Wikipedia 的回答上下文中。TREC 数据集主要用于基于文本的问答 ( 主要的 TREC 文档集主要由 newswire 的文章组成 ),而 WEBQUESTIONS 和 WIKIMOVIES 主要用于基于知识的问答。我们将所有这些资源放在一个统一的框架中,并测试我们的系统在回答所有的问题是表现如何——希望它能够反映通用知识 QA 的性能。
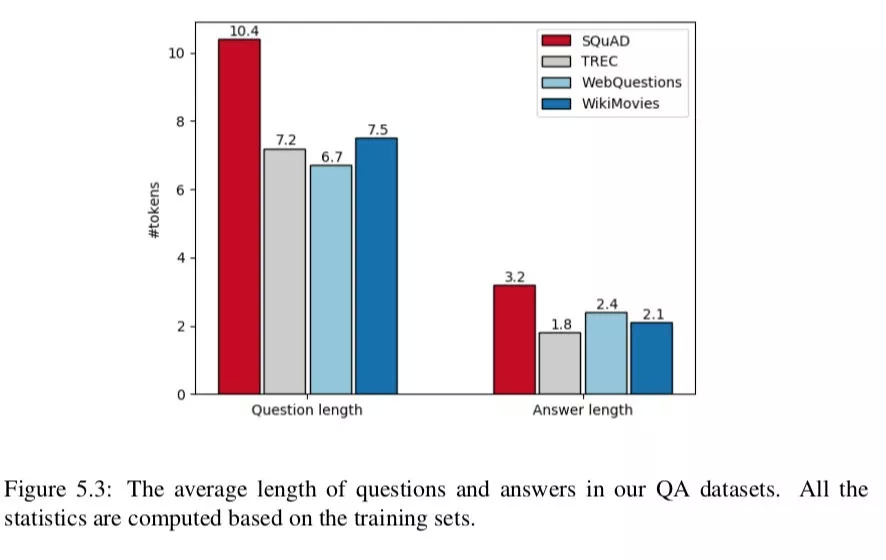
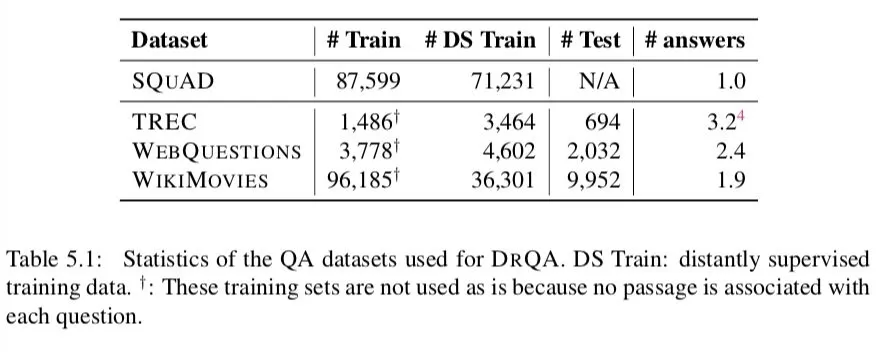
表 5.1 和图 5.3 给出了这些 QA 数据集的详细统计。正如我们所看到的,SQUAD 样本的分布与其他 QA 数据集有很大的不同。由于建造方法的原因,小队有更长的问题 ( 平均 10.4 个 toekns 对 6.7-7.5 个 toekns )。此外,所有这些数据集都有简短的答案 ( 尽管在小队中的答案稍微长一些 ),而且大多数都是虚构的。
请注意,这些 QA 数据集中的许多问题可能有多个答案 ( 参见表 5.1 中的 # answers 列 )。例如,对于 what language do people speak in Pakistan,有两个有效的答案:英语和乌尔都语。WEBQUESTIONS。由于我们的系统设计为返回一个答案,所以我们的评估认为,如果预测给出了任何黄金答案 ( 正确答案 ),那么预测都是正确的。
5.3.2 Implementation Details
5.3.2.1 Processing Wikipedia
我们使用 2016-12-21 转存的英文 Wikipedia 作为我们所有完整实验的用于问答知识的来源。对于每个页面,我们仅仅提取纯文本,并且所有的结构化数据片段例如表格和图片都被剥离了。在消除内部歧义、列表、索引和大纲之后,我们保留了 5,075,182 篇文章,其中包含 9,008,962 种独特的无大小写 toekn 类型。
5.3.2.2 Distantly-supervised data
我们对来自每个数据集的训练部分的每个问答对使用以下过程来构建我们的远程监督训练示例。首先,我们对问题运行 DOCUMENT RETRIEVER 来检索维基百科前 5 篇文章。那些文章中没有与已知答案精确匹配的所有段落将直接被丢弃。所有短于 25 或长于 1500 个字符的段落也将被过滤掉。如果在问题中检测到任何命名实体,我们将删除完全不包含它们的任何段落。对于检索到的每个页面中的每个剩余段落,我们使用问题与 20 个 toekn 窗口之间的 unigram 和 bigram 重叠对匹配答案的所有位置进行评分,以保持与重叠最多的前 5 个段落一致。如果没有非零重叠的段落,则丢弃该示例;否则,我们将每个找到的对添加到 DS 训练数据集中。图 5.4 显示了一些示例,表 5.1 ( 列 # DS Train ) 给出了我们为培训创建的远程监督示例的数量。
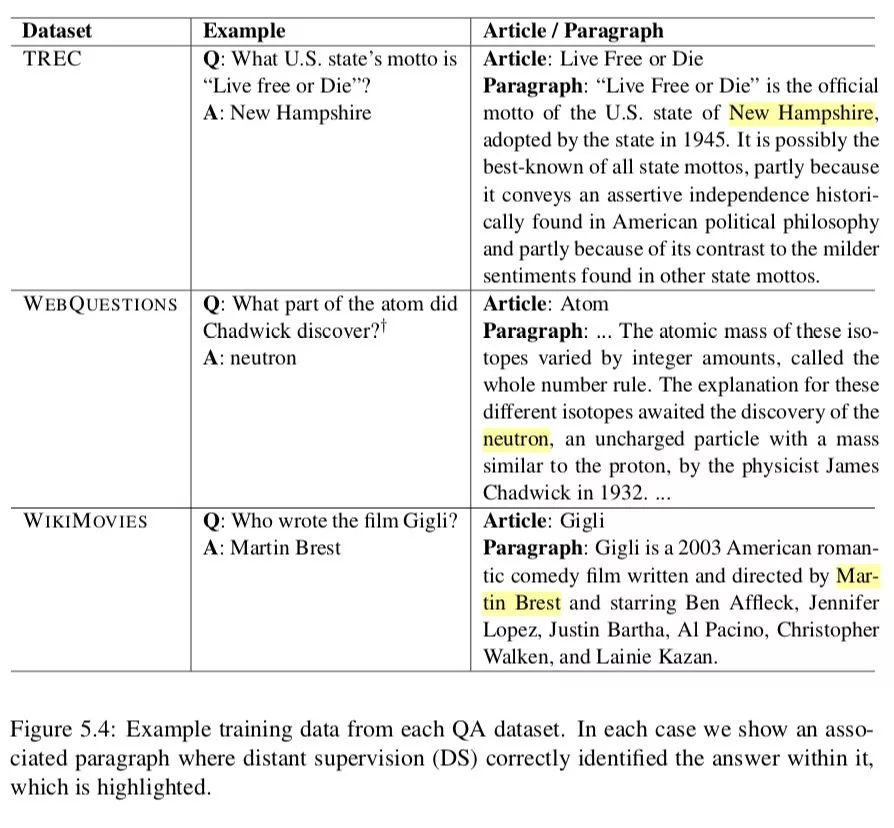
5.3.3 Document Retriever Performance
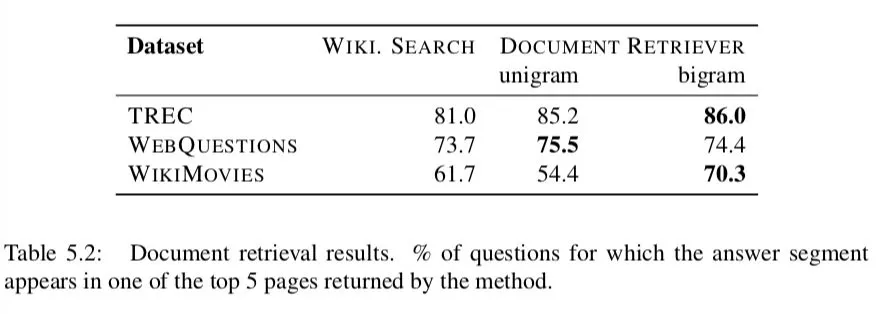
我们首先检查检索模块在所有 QA 数据集上的性能。表 5.2 将第 5.2.2 节中描述的两种方法的性能与 Wikipedia 搜索引擎在查找包含给定问题答案的文章方面的性能进行了比较。
具体地说,我们计算每个系统返回的前 5 个相关页面中,任何相关答案的文本跨度至少出现在其中一个页面中的问题的比例。在所有数据集上的结果表明,我们的简单方法比 Wikipedia 搜索更出色,特别是在 bigram 哈希的情况下。我们还比较了用 Okapi BM25 进行检索,或者在单词 embeddings 空间中使用余弦距离 ( 将问题和文章编码为 bag-of-embeddings ),我们发现这两种方法的性能都更差。
5.3.4 Final Results
最后,我们使用所有这些数据集对全系统 DRQA 进行性能评估,让其作答开放域问题。我们比较了三个版本的 DRQA,它们评估了在提供给 DOCUMENT READER 的训练资源上使用远程监督和多任务学习的影响 ( 在每种情况下 DOCUMENT RETRIEVER 保持相同 )
SQUAD:只在 SQUAD 训练集上训练单一的 DOCUMENT READER 模型,并用于所有的评估集。我们使用了我们在 5.2 节中描述的模型 ( 在 SQUAD 的测试集上,F1 的成绩是 79.0% )。
Fine-tune ( DS ):DOCUMENT READER 模型在 SQUAD 上进行预训练,然后使用其远程监督 ( DS ) 训练对每个数据集进行独立的微调。
多任务 ( DS ):在 SQUAD 训练集和所有的远程监督例子上联合训练一个单一的 DOCUMENT READER。
对于全维基百科设置,我们使用一个流模型而不使用 CORENLP 解析 ftoken 特征,或者辅助引理 fexact match。我们发现尽管在 SQUAD 中有这些更加精确的匹配段落阅读,并不能在全设置下提升结果。额外的,WEBQUESTIONS 和 WIKIMOVIES 提供了候选答案的一个列表 ( WEBQUESTIONS 的 1.6 百万的 freebase 实体串和 WIKIMOVIES 的 76k 电影相关实体 ),并且在预测的时候,我们限制了答案范围必须在这些列表中。
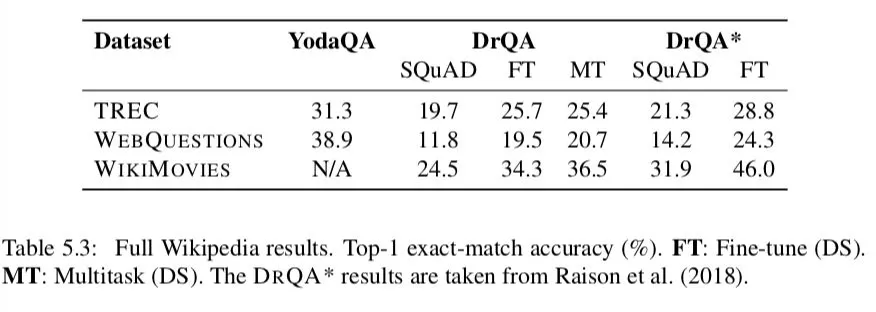
表格 5.3 呈现出了结果。我们仅仅考虑 top 1,精准匹配的准确度,这是非常严苛和具有挑战性的设置。在原始 paper ( Chen et al., 2017 ) 中,我们也评估了 SQUAD 中的 quesiton/answer 对。我们在这里忽略了他们因为至少有三分之一的问题是上下文相关的并且不适合于开放领域的 QA。
尽管和阅读理解任务 ( 给定正确的段落 ) 和没有限制的 QA 任务 ( 使用冗余资源 ) 相比,这个任务很困难,DRQA 依然在所有的四个数据集上表现出了可观的性能。
我们对能够利用 Wikipedia 回答任何问题的,单一的,全系统感兴趣。仅仅在 SQUAD 上面训练的单一模型在所有的数据集上都优于使用远程监督的多任务模型。然而,仅仅在 SQUAD 上面单独训练,性能也并不差,说明存在任务迁移的情况。然而,从 SQUAD 到多任务 ( DS ) 学习的主要提升,可能不是来自任务转换,因为仅使用 DS 对每个数据集进行微调也会带来改进,这表明在同一领域引入额外的数据会有所帮助。然而,我们能找到的最好的单一模型是我们的总体目标,即多任务系统。
给定之前在 TREC 和 WEBQUESTIONS 上面的结果,我们和系统 YODAQA 进行比较 ( Baudisˇ,2015 ) ( 一个利用冗余资源的无约束 QA 系统 )。尽管任务难度在增加,但是我们的性能并没有太落后于 TREC ( 31.3 VS 25.4 ),这一点让我们松了一口气。在 WEBQUESTIONS 上的差距稍微大一些,可能是因为这个数据集是由 YODAQA 直接使用的 FREEBASE 的特定结构创建的。
我们也包括了我们的模型 DRQA* 增强版本的结果,该模型已在 Raison 等人 ( 2018 ) 中提出。最大的变化是这种阅读理解模型是直接在维基百科文章上训练和评估的,而不是在段落上 ( 文档平均比单个段落大 40 倍 )。正如我们所看到的,所有数据集的性能都得到了一致的提高,因此与 YODAQA 的差距进一步缩小。


最近,我们的 DRQA 系统已经在 github 上进行开源。
https://github.com/facebookresearch/DrQA,部署了多任务 ( DS ) 系统。
就像看到的,我们的系统能够针对这些虚构问题返回一个精准的答案并且回答一些比较困难的问题:
① It is not trivial to identify that a computer science discipline within the fields of information retrieval and natural language processing is the complete noun phrase and the correct answer although the question is pretty simple.
② Our system finds the answer in another Wikipedia article Stanford Memorial Church, and gives the exactly correct answer California as the state ( instead of Stanford or United States ).
③ To get the correct answer, the system needs to understand the syntactic structure of the question and the context Who invented LSTM?and a deep learning method called Long short-term memory ( LSTM ), a recurrent neural network published by Sepp Hochreiter & Ju ̈rgen Schmidhuber in 1997.
从概念上讲,我们的系统简单而优雅,并且不依赖于任何附加语言分析或外部或手工编码的资源 ( 如字典 )。我们认为这种方法对于新一代开放领域的问题回答系统具有很大的前景。在下一节中,我们将讨论当前的限制和进一步改进的可能方向。
5.4 Future Work
研究结果表明,信息检索与神经阅读压缩相结合是一种有效的开放式问题回答方法。我们希望我们的工作在这个研究方向上迈出第一步。然而,我们的系统还处于早期阶段,许多实现细节还有待进一步完善。
我们认为以下的研究方向将 ( 大大 ) 改善我们的 DRQA 系统,并应作为未来的工作进行。事实上,在我们发布了我们的 DRQA 系统之后,其中的一些想法已经在接下来的一年里得到了应用,我们也将在本节中详细描述它们。
Aggregating evidence from multiple paragraphs。我们的系统采用了最简单和直接的方法:我们对所有检索到的文章的非标准化分数使用 argmax。这并不理想,因为:
这意味着每一篇文章都必须包含正确的答案 ( 例如班例 ),因此我们的系统将为每一篇文章输出一个且仅一个答案。这确实不是大多数检索到的段落的情况。
我们目前的培训模式并不能保证不同篇章的分数具有可比性,导致培训与评估过程存在差距。
对完整的 Wikipedia 文章进行培训是缓解这个问题的一种解决方案 ( 参见表 5.3 中的 DRQA* 结果 ),但是,这些模型运行缓慢,难以并行化。Clark 和 Gardner ( 2018 ) 提出采用修改后的训练目标进行多段训练,其中跨度开始和结束分数在从相同上下文中采样的所有段图中进行标准化。他们证明,这比单独训练单独的段落效果要好得多。同样,Wang et al. ( 2018a ) 和 Wang et al. ( 2018b ) 提出对检索到的文章训练一个显式的段落重新排序组件:Wang et al. ( 2018a ) 将其实现在一个强化学习框架中,从而共同训练重新排序组件和答案提取组件;Wang 等人 ( 2018b ) 提出了一种基于强度的重新排序和基于覆盖度的重新排序,更直接地从多个段落中挖掘证据。
Using more and better training data。第二个影响很大的方面是培训数据。我们的 DRQA 系统只收集了来自 TREC、WEBQUESTIONS 和 WIKIMOVIES 的 44k 个远程监督的培训示例,我们在 5.3.4 节中演示了它们的有效性。如果我们能够利用来自 TRIVIAQA ( Joshi et al., 2017 ) 或来自其他 QA 资源的更多数据生成更多的监督培训数据,那么系统应该得到进一步的改进。此外,这些远距离监督的例子不可避免地会遇到噪音问题 ( 即 Lin 等人 ( 2018 ) 提出了一种去噪的解决方案,对这些远程监督的例子进行了去噪处理,并证明了在评估中取得的效果。
我们还认为,添加负面示例可以显著提高系统的性能。我们可以使用完整的管道创建一些负面示例:我们可以利用文档检索模块帮助我们找到相关段落,而这些段落不包含正确的答案。我们还可以将现有的资源,如 SQUAD 2.0 ( Rajpurkar et al., 2018 ),纳入我们的培训过程,其中包含精心策划的高质量负面例子。
Making the DOCUMENT RETRIEVER trainable。第三个尚未完全研究的有希望的方向是为文档检索模块使用机器学习方法。我们的系统采用了一个直观的、非机器学习的模型,检索性能的进一步提高 ( 表 5.2 ) 将对整个系统进行改进。可以从其他资源或 QA 数据 ( 例如,使用文章是否包含问题的答案作为标签 ) 收集文档检索程序 compo- nent 的培训语料库。文档检索和文档阅读器组件的联合培训将是未来工作的一个非常理想和有前景的方向。
与此相关,Clark 和 Gardner ( 2018 ) 还在搜索引擎 ( Bing web search ) 的基础上构建了一个开放领域的问题回答系统 9,并证明了与我们相比性能优越。我们认为结果是不可直接比较的,这两种方法 ( 使用商业搜索引擎或构建独立的 IR 组件 ) 都有优缺点。构建我们自己的 IR 组件可以摆脱现有的 API 调用,运行速度更快,更容易适应新的领域。
Better DOCUMENT READER module。在我们的 DRQA 系统中,我们使用了神经阅读理解模型,在 1.1 班的测试集上达到了 79.0%的 F1。随着最近神经阅读理解模型的发展 ( 第 3.4 节 ),我们确信,如果我们用最先进的模型替换当前的文档阅读器模型 ( Devlin et al., 2018 ),我们整个系统的性能也将得到改善。
More analysis is needed。另一项重要的缺失工作是对我们当前的系统进行深入分析:了解哪些问题他们可以回答,哪些不能。我们认为,在相同的条件下,将我们的现代系统与早期的 TREC QA 结果进行比较是很重要的。它将帮助我们了解我们在哪里取得了真正的进步,以及我们还可以使用哪些前深度学习时代的技术,以便在未来构建更好的答疑系统。
在我们工作的同时,也有一些与我们类似的工作,包括 SEARCHQA ( Dunn et al.,2017 ) 和 QUASAR-T ( Dhingra et al.,2017b ),它们都为 JEOPARDY 提供了相关的文档。questions ——前者使用 LUCENE 索引从 CLUEWEB 检 索文档,后者使用谷歌搜索。TRIVIAQA ( Joshi et al., 2017 ) 也有一个开放域设置,其中保存所有从 Bing web 搜索中检索到的文档。然而,这些数据集仍然关注从检索到的文档中回答问题的任务,而我们更感兴趣的是构建端到端的 QA 系统。
6 Conversational Question Ansering
在最后一章,我们讨论了如何从神经阅读理解中构建一个通用知识的问答系统。然而,大多数现在的 QA 系统被限制于回答独立的问题,例如,每次我们问一个问题,系统返回一个结果而不具备考虑上下文的能力。在这一章中,我们打算处理另一个具有挑战性的问题 Conversational Question Answering。在这个问题下,机器必须理解一个文本篇章并且回答一系列出现在对话中的问题。
人类通过一系列相互关联的问题和答案的对话来收集信息。因此,为了帮助机器收集信息,有必要使它们能够回答会话问题。图 6.1 显示了正在阅读一篇文章的两个人之间的对话,一个充当提问者,另一个充当回答者。在这个对话中,第一个问题之后的每个问题都依赖于对话的历史。例如,Q5 who?只有一个词,不知道已经说了些什么是不可能回答的。提出简短的问题是一种有效的人类对话策略,但是对于机器来说,这些问题确实很难解析。因此,会话问答结合了对话和阅读理解的挑战。
我们相信建造一个能够回答这样的对话问题的系统能够在我们未来的对话 AI 系统中扮演一个重要的角色。为了解决这个问题,我们需要建造有效的 datasets 以及对话 QA 模型,并且我们将会在这一章中描述它们二者。

本章组织如下。我们首先在第 6.1 节讨论相关工作,然后在第 6.2 节中介绍 COQA ( Reddy et al., 2019 ),这是一个会话性的问题回答挑战,用于测量机器参与问答式对话的能力。我们的数据集包括 127k 问题以及答案,来自七个不同领域的 8k 个文本段落对话。我们定义任务并描述数据集收集过程。我们还对数据集进行了深入的分析,发现会话问题具有现有阅读理解数据集中不存在的挑战性现象,如指代和语用推理。接下来,我们将描述我们在 6.3 节中为 COQA 构建的几个强大的会话和阅读理解模型,并在 6.4 节中给出实验结果。最后,我们讨论会话问答的未来工作 ( 6.5 节 )。
6.1 Related Work
对话性问题的回答与 dialogue 直接相关。自然语言理解的主要目标之一是建立对话代理或对话系统,以便用自然语言与人类对话。最常见的两类对话系统是:任务导向和闲谈对话。任务导向的对话系统是为特定的任务而设计的,用于进行简短的对话 ( 例如,预订机票或预订餐馆 )。它们是根据任务完成率或任务完成时间来评估的。相比之下,闲谈聊天对话系统是为扩展的、非正式的对话而设计的,没有特定的目标。通常,用户参与和交互的时间越长,这些系统就越好。
回答问题也是对话系统的一个核心任务,因为人类与对话主体互动最常见的需求之一就是寻找信息,提出各种话题的问题。基于 qa 的对话技术已经在自动化的个人助理系统中得到了广泛的发展,比如亚马逊的 ALEXA、苹果的 SIRI 或谷歌 assistant,这些系统要么基于结构化的知识库,要么基于非结构化的文本集合。现代对话系统大多建立在深度神经网络之上。对于不同类型对话系统的神经方法的全面调查,我们建议读者参考 ( Gao et al., 2018 )。
我们的工作和 ( Das et al., 2017 ) 的 Visual Dialog 任务以及 ( Saga et al ., 2018 ) 的 Complex Sequential Question Answering 任务非常相关,这两个任务分别在图像和知识图谱上面进行了会话性的问答,后者关注通过套用模版获得的问题。图 6.2 分别展示了每个任务的一个例子。我们关注的是一段文字的对话,这需要阅读理解的能力。
另一个相关的研究是 sequential question answering ( Iyyer et al., 2017;Talmore and Berant, 2018 ),在这个问题中一个复杂的问题被拆解为一系列简单的问题。例如,问题 What super hero from Earth appeared most recently?可以被拆解为以下三个问题:
Who are all of the super heroes?
Which of them come from Earch?
Of thos, who appeared most recently?
因此,他们的关注点是如何通过连续的问答回答一个复杂的问题,而我们更感兴趣的是自然存在的各种话题的对话,而问题可以依赖于对话的历史。译者注:他们研究的是解决一个复杂的问题,但是自然对话往往直接是由一系列的问题回答构成的,这才是我们 ( cdq ) 要解决的问题
6.2 CoQA:A Conversational QA Challenge
在这个小节,我们介绍 COQA,用于建造 Conversional Question Answering systems 的新数据集。我们开发 COQA 有三个主要目标:
第一个是关注人类对话中问题的本质。就像在图 6.1 中可以看到的一个例子,在这个对话中,第一个问腿之后的每一个问题都依赖于对话历史。现在,没有大型阅读理解数据集包含依赖于对话数据集的问题并且这个是 COQA 开发的主要目的。
第二个目标是保证对话中的回答的自然性。就像我们在之前的章节中讨论过的,大多数现存的阅读理解数据集要么将答案限制在给定篇章的一个连续范围内,要么就允许存在不太像人类说出的自由形式的答案 ( e.g. NARRATIVEQA )。我们的愿望是:
① 答案不应该只基于范围获取,这样任何问题都可以问,对话也可以自然进行。例如,对于 Q4 How many?如图 6.1 所示。
② 仍然支持具有强力人类性能的可靠的自动评估。因此,我们提出答案可以是自由形式的文本 ( 抽象的答案 ),而提取范围作为实际答案的依据。因此,Q4 的答案就是简单的 Three,而它的基本原理是跨越多个句子的。
COQA 的第三个目标是支持构建性能可靠的跨领域 QA 系统。目前的阅读理解数据集主要集中在单一领域,难以对现有模型的泛化能力进行测试。因此,我们从七个不同的领域收集数据——儿童故事、文学、初中和高中英语考试、新闻、维基百科、科学文章和 Reddit。最后两个用于域外评估。
6.2.1 Task Definition
我们首先正式的定义我们的任务。给定一个段落 P,对话由 n 个回合组成,每个回合由 ( Qi, Ai, Ri ), i = 1,…n,其中 Qi 和 Ai 表示第 i 个回合的问题和答案,Ri 是支持答案 Ai 的基本原理,并且必须是文章的单个跨度。这个任务被定义为根据到目前为止的对话回答下一个问题 Qi:Q1, A1,…Qi−1 Ai−1。值得注意的是,我们收集 Ri 的目的是希望它们能够帮助理解答案是如何产生的,并改进我们的模型的培训,而在评估过程中没有提供这些模型。
对于图 6.3 中的示例,对话以问题 Q1 开始。根据文章中的证据 R1,我们用 A1 回答 Q1。在这个例子中,回答者只写了 Governor 作为答案,但选择了一个更长的理由,The Virginia governor’s race。当我们讲到 Q2 时 where?我们必须回顾谈话的历史,否则它的答案可能是 Virginia or Richmond。在我们的任务中,会话历史对于回答许多问题是必不可少的。我们使用会话历史 Q1 和 A1 来回答 Q2 和 A2 基于证据 R2。对于一个无法回答的问题,我们给出 unkonwn 作为最终答案,不强调任何理由。

在这个例子中,我们观察到焦点的实体随着谈话的进展而变化。提问者在 Q4 中用 his 代表 Terry,在 Q5 中用 he 代表 Ken。如果不能正确地解决这些问题,我们将得到不正确的答案。问题的会话性质要求我们从多个句子中推理 ( 当前的问题和之前的问题或答案,以及文章中的句子 )。常见的情况是,一个问题可能需要跨越多个句子的基本原理 ( 例如图 6.1 的 Q1 Q4 和 Q5 )。我们在 6.2.3 中描述了附加的问答类型。
6.2.2 Dataset Collection
我们将数据集收集过程详细描述如下。每段对话都有两个注释者,一个提问者和一个回答者。这种设置比使用一个注释器同时充当提问者和回答者有几个优点:
当两个注释器谈论一篇文章时,他们的对话流与自言自语相比是自然的;
当一个注释者回答一个模糊的问题或一个不正确的答案时,另一个注释者可以升起一个标志,我们用它来识别坏工人;
当两个注释者有不同意见时,他们可以通过单独的聊天窗口讨论指导方针。这些措施有助于防止垃圾邮件,并获得高协议数据。
我们使用 Amazon Mechanical Turk ( AMT ) 对通道 a 上的工人进行配对,并使用 ParlAI Mturk API ( Miller et al., 2017 )。平均来说,每一篇文章需要 3.6 美元用于收集对话,另外 4.5 美元用于为开发和测试数据收集另外三个答案。
Collection interface。我们为提问者和回答者提供了不同的界面 ( 图 6.4 和图 6.5 )。提问者的角色是提出问题,而回答者的角色是除了强调基本原理之外,还要回答问题。为了增加词汇的多样性,我们希望提问者避免在文章中使用精确的词汇。当他们输入一个已经出现在文章中的单词时,我们提醒他们如果可能的话重新解释问题。对于答案,我们希望答题者坚持使用文章中的词汇,以限制可能答案的数量。我们鼓励这一点,自动复制突出显示的文本到答案框中,并允许他们编辑复制的文本,以生成一个自然的答案。我们发现 78%的答案至少有一次修改,比如改变一个单词的大小写或添加标点符号。

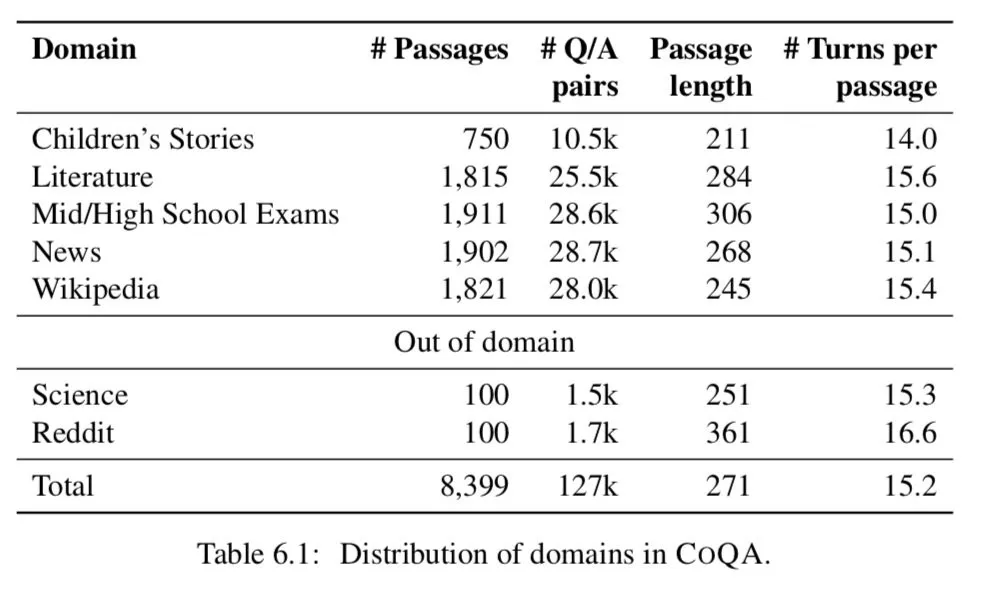
Passage selection。我们从七个不同的领域选择段落:儿童故事从 mct ( Richardson et al., 2013 ),文学从项目 Gutenberg4,初中和高中英语考试从种族 ( Lai et al ., 2017 ),从 CNN 新闻文章 ( Hermann et al ., 2015 ),从维基百科的文章,文章从 AI2 科学问题 ( Welbl et al ., 2017 ) 和 Reddit 的文章写作提示数据集 ( Fan et al ., 2018 )。
并不是所有这些领域的文章都适合生成有趣的转换。只有一个实体的文章常常会引发完全集中在那个实体上的问题。我们选择了包含多个实体、事件和代词引用的段落—— ing Stanford CORENLP ( Manning et al., 2014 )。我们把长篇大论的文章截短到前几段,大约有 200 个字。
表 6.1 显示了域的分布。我们保留科学和 Reddit 做的主要领域外的评估。对于每个在域的数据集,我们分布有 100 个通道的数据。在开发集,100 通道的测试集,训练集,其余的。相比之下,对于每个范围之外的数据集,我们只有 100 个篇章测试集没有任何 training 或者 developing set。
Collecting multiple answers:COQA 中的一些问题可能有多个有效答案。例如,图 6.3 中 Q4 的另一个答案是共和党候选人。为了解释答案的变化,我们为开发和测试数据中的所有问题收集了三个额外的答案。由于我们的数据是对话式的,问题影响答案,答案又影响后续问题。在前面的例子中,如果最初的答案是共和党候选人,那么下面的问题是他属于哪个党派?一开始就不会发生。当我们将已有对话中的问题展示给新回答者时,很可能会偏离原来的答案,从而使对话变得不连贯。因此,重要的是使它们与最初的答案达成共识。
我们通过将收集答案的任务转换为预测原始答案的游戏来实现这一点。首先,我们向新回答者显示一个问题,当她回答时,我们显示原始答案,并要求她验证她的答案是否与原始答案匹配。对于下一个问题,我们让她猜出最初的答案,并再次验证。我们重复这个过程,直到对话结束。在我们的实验中,当我们使用这个验证设置时,人类 F1 得分增加了 5.4%。
6.2.3 Dataset Analysis
什么使得 COQA 数据集与现有的阅读理解数据集 ( 如 SQUAD ) 相比更具会话性?对话是如何从一个转到另一个的?COQA 中的问题表现出什么样的语言现象?我们在下面回答这些问题。
Comparison with SQUAD 2.0:下面,我们将对 COQA 和 SQUAD 2.0 进行深入比较 ( Rajpurkar 等,2018 )。图 6.6 显示了 fre- quent 三元组前缀的分布。虽然在 SQUAD 2.0 中不存在 COQA 的引用,但是 COQA 的几乎每个部分都包含 COQA 的引用 ( 他、他、她、it、他们 ),这表明 COQA 是高度可会话的。由于答案的自由形式,我们期望在 COQA 中有比 SQUAD 2.0 更丰富的问题。尽管有近一半的 SQUAD 2.0 问题由什么问题主导,但是 COQA 的分布分布在多个问题类型中。前缀 did、was、is、does 和 does 在 COQA 中经常出现,但在 SQUAD 2.0 中完全没有。
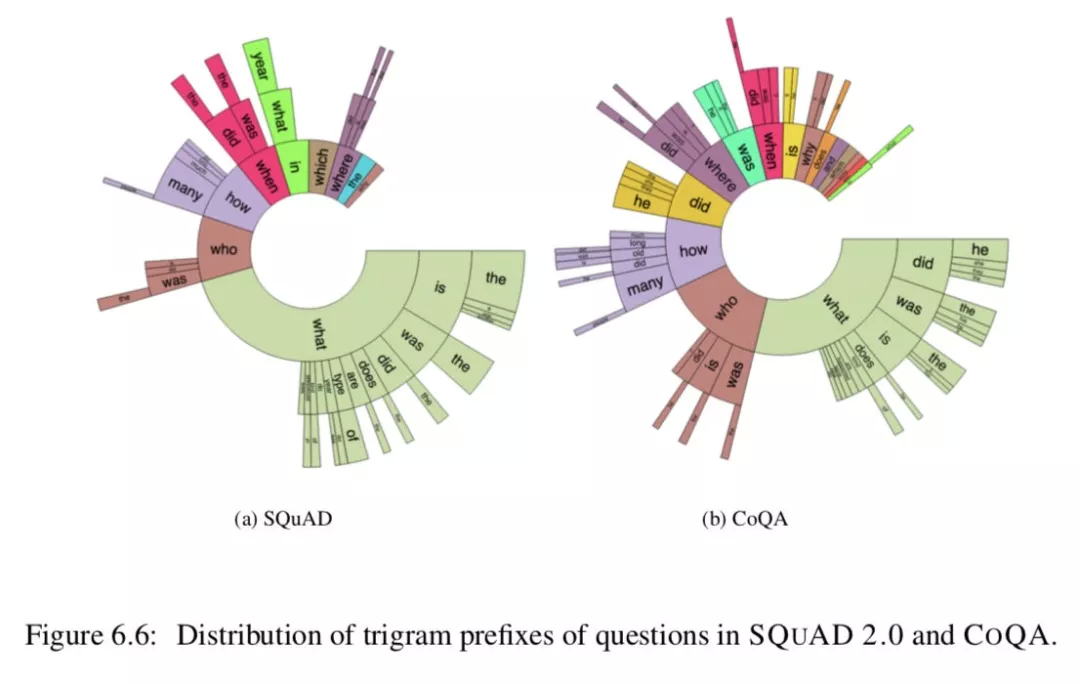
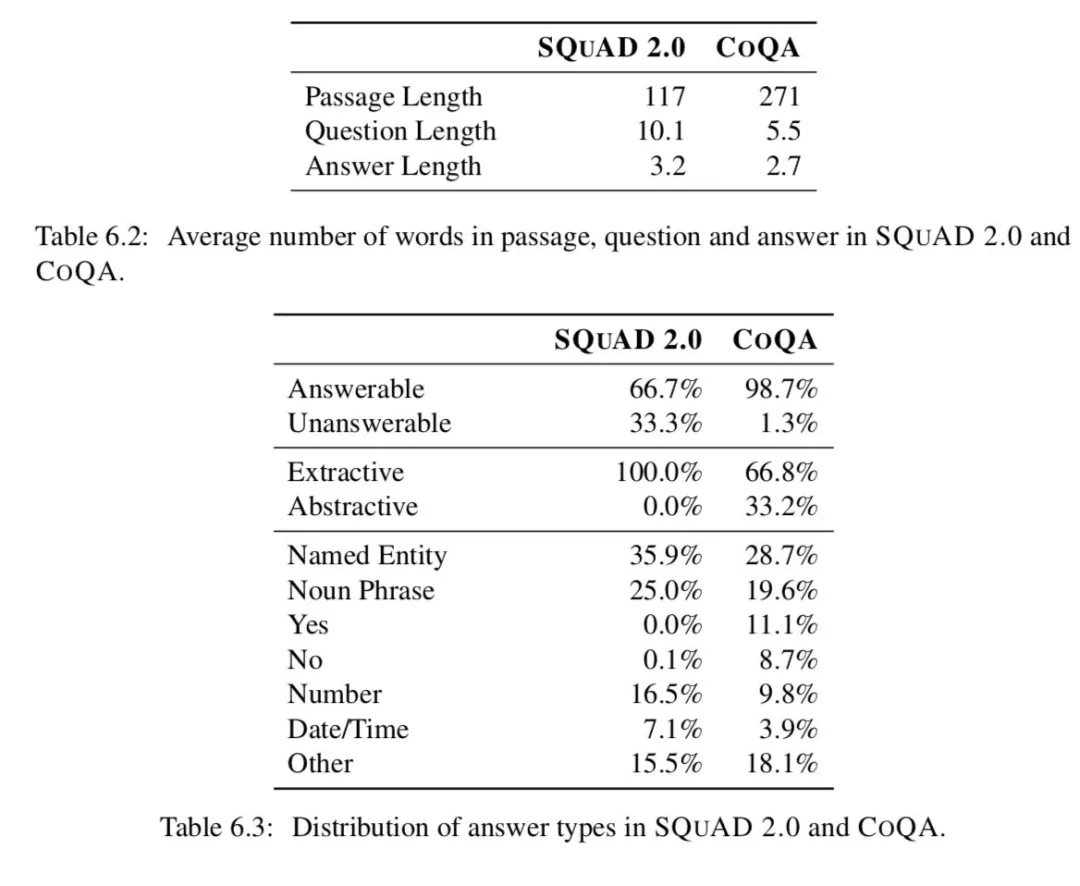
因为一个对话散布在多轮中,我们期望对话的问答能够被缩短到一个独立的交互中。事实上,COQA 的问题能够备用一两个单词构造 ( Who?When?Why?)。就像在 Table6.2 中看到的,COQA 中的为问题长度平均为 5.5 个单词,但是 SQUAD 的平均长度为 10.1。而 COQA 中的答案通常比 SQUAD 中的短 2.0。
表 6.3 提供了关于 SQUAD 2.0 和 COQA 中答案类型的见解。尽管 SQUAD2.0 的原始版本并没有任何不可回答的问题,SQUAD 单一地集中在获取他们以导致了比 COQA 中更高的频率。SQUAD2.0 中全部都是提取答案,而 COQA 中有 66.8%的答案可以在忽略标点和大小写之后可以被提取。这高于我们的预期。我们的猜想是人类因为工资这样的人为因素会影响工人提出的能够通过选择文本更快回答的问题值得注意的是,COQA 有 11.1%以及 8.7%的问题是 yes 或者 no 这样的答案,而 SQUAD2.0 一个都没有。这两个数据集都有大量的命名实体和名词短语作为答案。
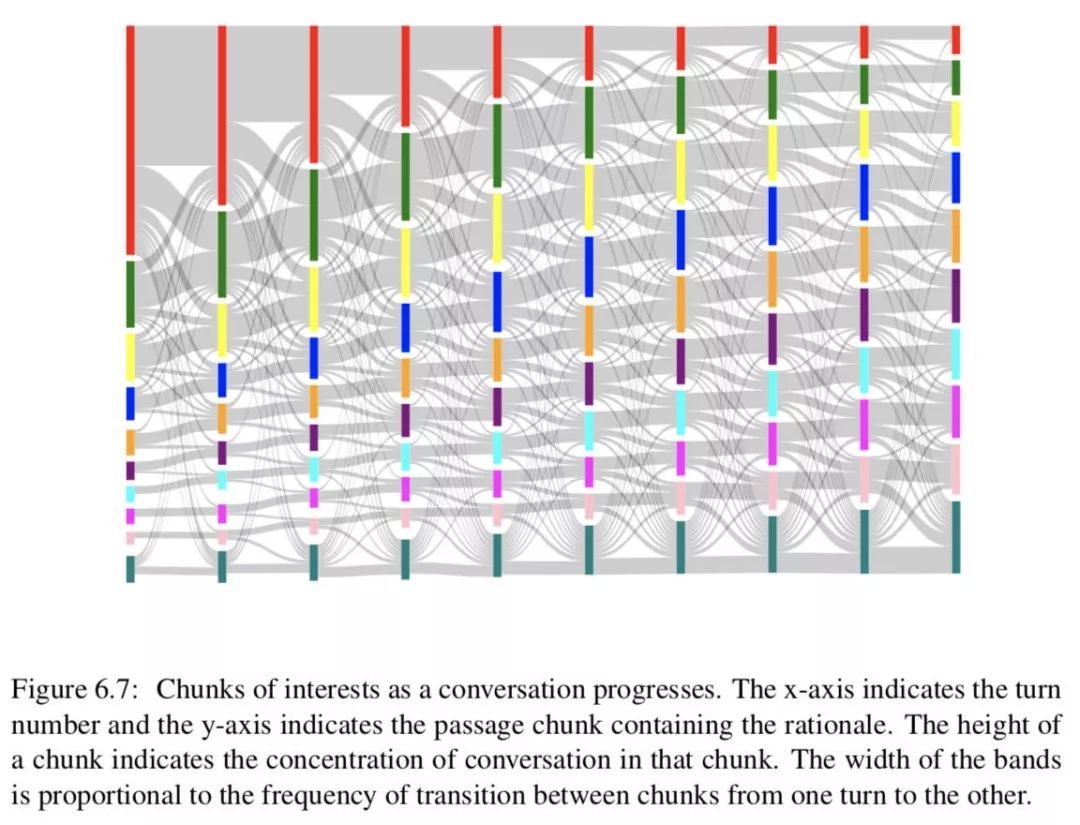
Conversation flow:连贯的谈话必须有平稳的转折。我们希望文章的叙述结构能影响我们的对话流。我们将文章分成 10 个统一的块,并根据基本原理的跨度来确定某个转弯的兴趣块及其转换。
图 6.7 描绘了前 10 个回合的对话流。开始的时候,人们往往会把注意力集中在开始的几句话上,随着谈话的进行,注意力会转移到后面的几句话上。此外,转弯过渡是平滑的,焦点通常保持在同一块或移动到相邻块。最频繁的转换发生在第一个和最后一个块上,同样,这些块也有不同的外部转换。译者:看起来我们可以通过一个 window 来圈定上下文的范围
Linguistic phemnomena。我们进一步分析了它们与篇章和会话历史的关系问题。我们在开发集中抽取了 150 个问题,并对各种现象进行了注释,如表 6.4 所示。
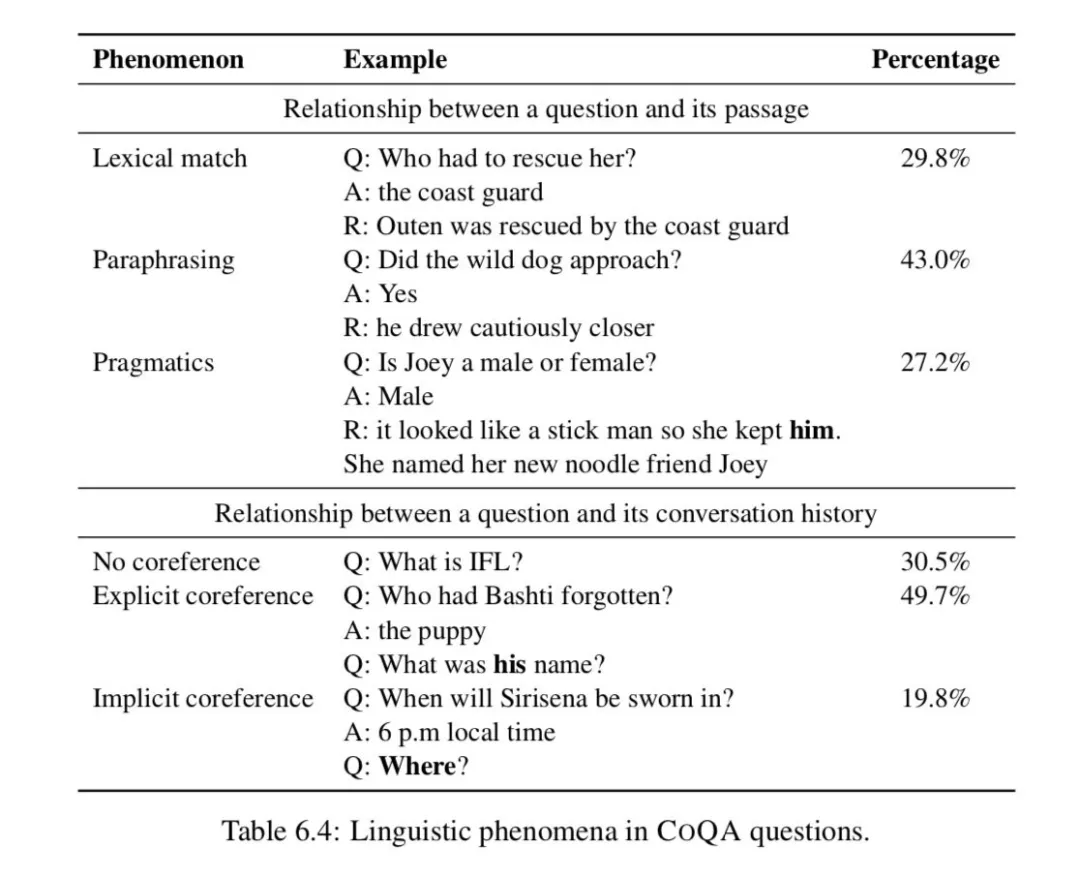
如果一个问题至少包含一个出现在文章中的实义词,我们将其归类为 lexical match ( 词汇匹配 )。这些问题约占问题总数的 29.8%。如果没有词汇匹配,而是对 rational 的释义,我们将其归类为 paraphrasing ( 释义 )。这些问题包括同义、反义、下义、否定等现象。这些构成了 43.0%的问题。剩下的 27.2%的问题,不是词汇匹配,我们将他们归类到 prgmatics ( 实际的实用的 ) 这些包括常识类现象和假定现象。例如,问题 was he loud and boisterous?并不是 he dropped his feet with the lithe softness of a cat 的背后原理的直接转述,但是组成这个世界知识的原理可以回答这个问题。
对于一个问题和它的会话历史之间的关系,我们将问题分为依赖于会话历史还是独立于会话历史。如果不确定,则询问是否包含显式标记。
因此,约有 30.5%的问题不依赖于与会话历史的相互参照,而是可以自己回答。几乎一半的问题(49.7%)包含明确的共同参照标记,如 he, she, it。它们要么引用对话中引入的实体,要么引用对话中引入的事件。其余 19.8%没有显式的协引用标记,而是隐式地引用实体或事件。
6.3 Models
给出一个段落 p,对话历史 {q1, a1,…qi - 1, ai - 1} and a question qi, the task is to predict the answer ai。我们的任务可以建模为会话响应生成问题或阅读理解问题。我们评估来自每一类模型的强基线,以及 COQA 上这两种模型的组合。
6.3.1 Conversational Models
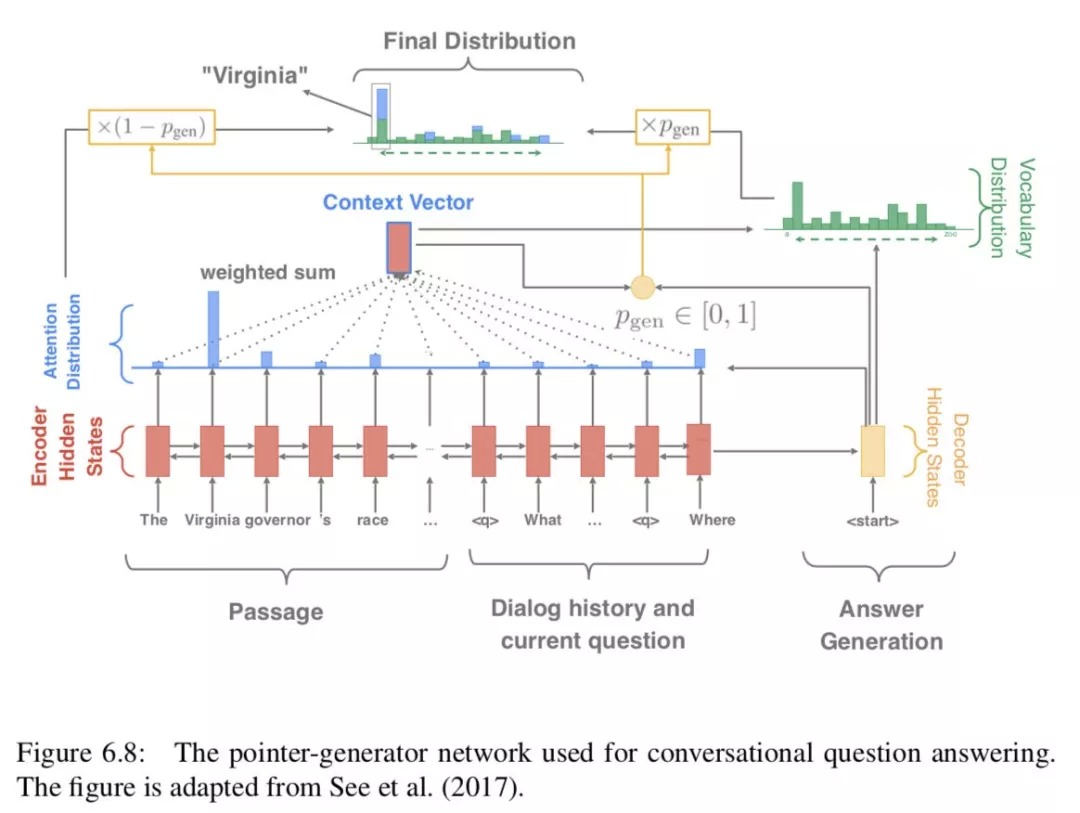
会话模型的基本目标是根据会话历史预测下一个话语。序列到序列 ( seq2seq ) 模型 ( Sutskever et al., 2014 ) 在生成会话响应方面显示出了良好的结果 ( Vinyals 和 Le, 2015;李等,2016;张等,2018 )。由于他们的成功,我们使用了一个标准的序列到序列模型,其中包含一个生成答案的注意机制。我们附加了段落、会话历史 ( 最后 n 轮的问题/答案对 ) 和当前的问题,p <q> qi-n <a> ai-n. . . <q> qi-1 <a> ai-1<q> qi,并将其输入一个双向 LSTM 编码器,其中和是用作分隔符的特殊令牌。然后,我们使用 LSTM 解码器生成答案,该解码器负责处理编码器的状态。
此外,由于答案很可能出现在原文中,我们在解码器中采用了一种复制机制,用于总结任务 ( Gu et al., 2016;See et al., 2017 ),它允许 ( 可选地 ) 从文章和对话历史中复制一个单词。我们将这个模型称为 Pointer-Generator 网络 ( See et al., 2017 ), PGNET。图 6.8 展示了 PGNET 的完整模型。正式说来,我们用 {h̃i} 表示编码器隐藏向量,ht 表示在 timestep t 时候的解码器状态,以及 Xt 作为输入向量,注意力方程给予 {h̃i}、ht 和α来计算(equation 3.13)。上下文向量用公式 3.14 计算:
对于复制机制,它首先计算生成概率 pgen ∈ [0, 1],pgen ∈ [0, 1] 控制从完整词汇表 V ( 而不是复制一个单词 ) 生成单词的概率:
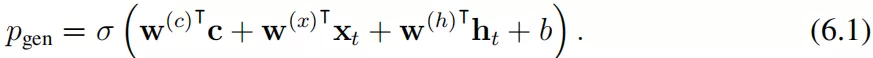
生成单词 w 的最后概率分布计算如下:
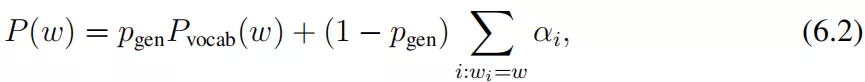
where Pvocab(w) is the original probability distribution ( computed based on c and ht ) and {wi} refers to all the words in the passage and the dialogue history. For more details, we refer readers to ( See et al., 2017 ).
6.3.2 Reading Comprehension Models
我们评估的第二类模型是神经阅读理解模型。特别是跨预测问题的模型不能直接应用,因为大部分 COQA 问题在文中没有一个跨作为答案,如图 6.1 中的 Q3、Q4、Q5。因此,我们针对这个问题修改了我们在 3.2 节中描述的 STANFORD 细心读者模型。由于模型在训练过程中需要文本跨度作为答案,所以我们选择了词汇重叠程度最高的跨度 ( F1 分 ) 作为黄金答案。如果答案在故事中出现多次,我们就用基本原理找到正确的答案。如果在文章中没有出现任何答案,我们就回到另一个未知的标记作为答案 ( 大约 17% )。我们在每个问题前加上过去的问题和答案,以说明会话历史,类似于会话模型。
6.3.3 A Hybrid Model
最后一个模型是一个混合模型,结合了上述两种模型的优点。阅读理解模型可以预测一个答案的文本跨度,但不能生成与文章不重叠的答案。因此,我们将斯坦福大学的细心读者与 PGNET 相结合来解决这个问题,因为 PGNET 可以有效地生成自由形式的答案。在这个混合模型中,我们使用阅读理解模型首先指向文本中的答案证据,然后 PGNET nat- uralize 将证据转化为最终答案。例如,对于图 6.1 中的 Q5,我们期望阅读理解模型首先预测出她的孙女 Annie 下午过来的原因,Jessica 非常高兴见到她。她的女儿媚兰和媚兰的丈夫约什也要来。然后 PGNET 从 R5 生成 A5 Annie, Melanie 和 Josh。
我们基于经验表现对这两个模型进行了一些更改。对于 STANFORD ATTENTIVE READER 模型,我们只使用基本原理作为非抽取答案的问题的答案。对于 PGNET,我们只提供当前的问题和斯坦福关注读者模型的跨度预测作为编码器的输入。在培训期间,我们将 oracle span 输入 PGNET。
6.4 Experiments
6.4.1 Setup
对于 SEQ2SEQ 和 PGNET 实验,我们使用 OPENNMT 工具包 ( Klein et al., 2017 )。在阅读理解实验中,我们使用了与 SQUAD 相同的实现 ( Chen et al., 2017 )。我们对开发数据调优超参数:会话历史中使用的轮数、层数、每层包含的单元数和 dropout 比率。我们使用 GLOVE ( Pennington et al., 2014 ) 对会话模型初始化单词映射矩阵,使用基于经验性能的 FASTTEXT ( Bojanowski et al., 2017 )对阅读理解模型初始化单词投影矩阵。我们在训练期间更新映射矩阵,以便学习分隔符的嵌入。
在 SEQ2SEQ 和 PGNET 的所有实验中,我们都使用了 OPEN- NMT 的默认设置:两层 LSTMs,编码器和解码器都有 500 个隐藏单元。利用 SGD 对模型进行优化,初始学习率为 1.0,衰减率为 0.5。所有层的 dropout 比率为 0.3。
在所有的阅读理解实验中,我们发现最好的配置是 3 层 LSTMs,每层包含 300 个隐藏单元。所有 LSTM 层的 dropout 率为 0.4,word 嵌入层的 dropout 率为 0.5。
6.4.2 Experimental Results
表 6.5 给出了模型在开发和测试数据上的结果。参照测试集的结果,SEQ2SEQ 模型表现最差,不管这些答案是否出现在文章中,都会生成频繁出现的答案,这是会话模型的一个众所周知的行为 ( Li et al., 2016 )。PGNET 通过关注文章中的词汇量来缓解频繁应答问题,并且性能优于 SEQ2SEQ 17.8 分。然而,它仍然落后于 STANFORD ATTENTIVE READER 8.5 分。原因之一可能是 PGNET 在回答问题之前必须记住整篇文章,这是 STANFORD ATTENTIVE READER 避免的巨大开销。但 STANFORD ATTENTIVE READER 在回答自由形式的问题时却不幸地失败了 ( 参见表格 6.6 中的 Abstractive )。当 STANFORD ATTENTIVE READER 送入 PGNET 的时候,我们增强了 STANFORD ATTENTIVE READER 和 PGNET —— STANFORD ATTENTIVE READER 在产生自由形式的答案方面,PGNET 在关注篇章背后的原理方面。这个组合要优于 PGNET 和 STANFORD ATTENTIVE READER 分别 21.0 以及 12.5 分。
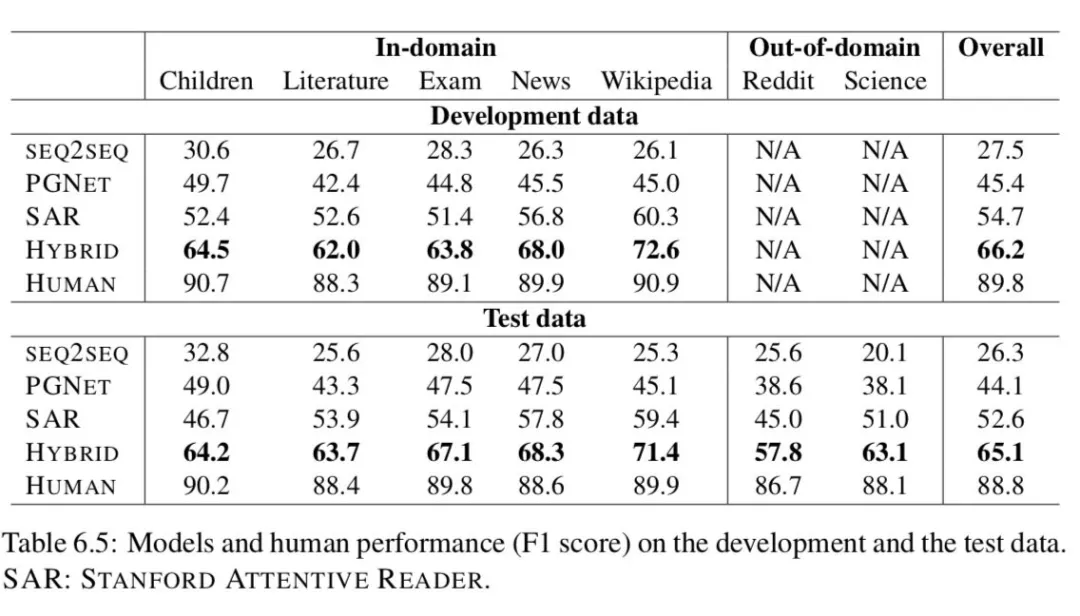
Models vs. Human:测试数据的人为性能为 88.8 F1,很好地说明 COQA 的问题有具体的答案。我们最好的模型比人类落后 23.7 分,这表明用目前的模型很难完成这项任务。我们预计,使用最先进的阅读理解模型 ( Devlin et al., 2018 ) 可能会将结果提高几个百分点。
In-domain vs Out-of-domain:与域内数据集相比,所有模型在域外数据集上的性能都更差。最好的模型下降了 6.6 点。对于领域内的研究,最好的模型和人类都发现文学领域比其他领域更难,因为文学词汇要求精通英语。对于域外结果,Reddit 域显然更困难。这可能是因为 Reddit 需要对较长的段落进行推理 ( 参见表 6.1 )。
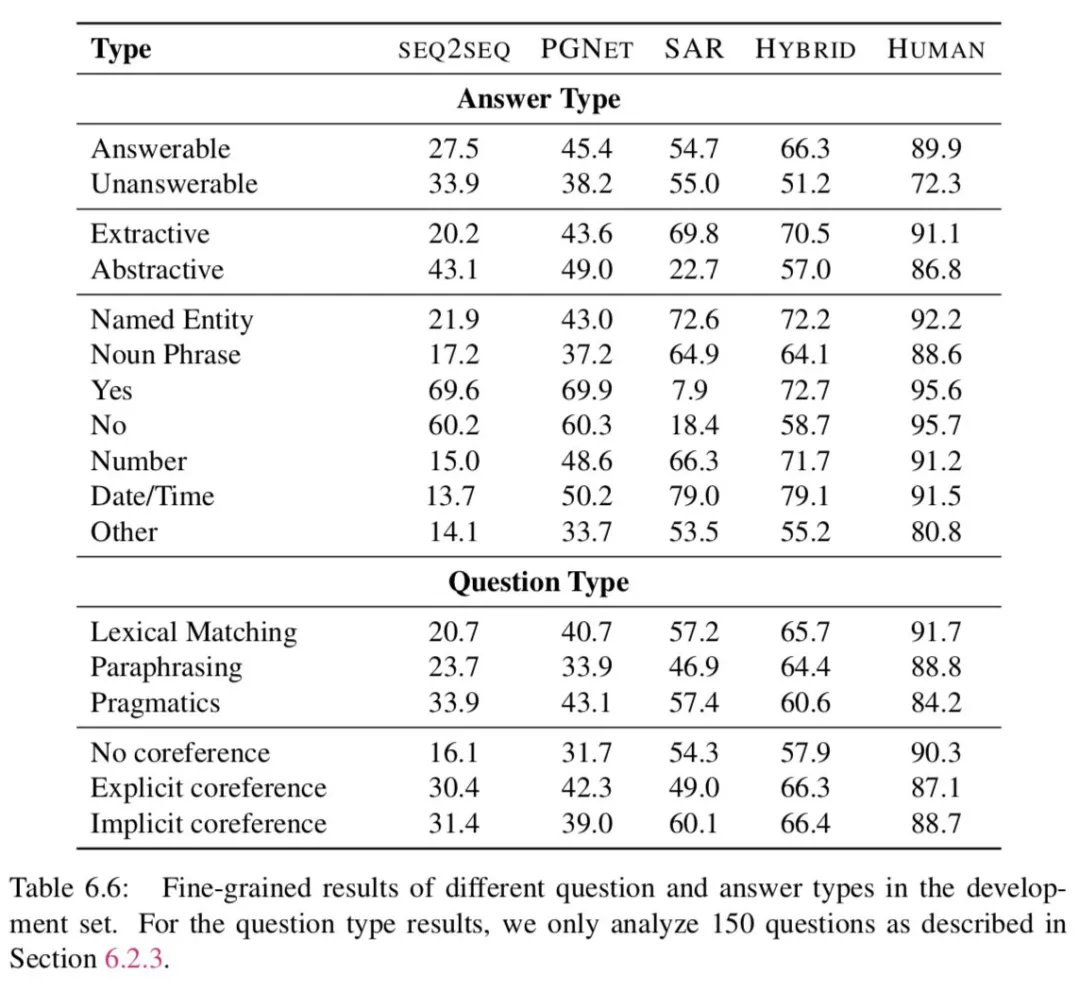
虽然人类在儿童故事方面取得了很高的成绩,但模型的表现却很差,这可能是因为与其他领域相比,该领域的训练例子较少。人类和模型都觉得维基百科很简单。译者,这就很扯淡了,,,很明显 high-level 的读者应该向下兼容,然而在这里模型却不是这样,说明并没有“学会”语言,只是在“模仿”。想象一下,看得懂 NLP paper 的人,不一定看得懂英语童话故事。似乎也有一定的合理性。。。比如,dog day 基本不会出现在学术论文中,虽然 NLP 的论文确实有可能在分析语言现象,但是小孩子的读本就有可能了
6.4.3 Error Analysis
表 6.6 给出了开发集中模型和人员的细粒度结果。我们观察到,在无法回答的问题上,人类的分歧最大。有时,即使文章中没有给出答案,人们也会猜测答案,例如,图 6.1 中 Annie 的年龄可以根据她祖母的年龄来猜测。人类对抽象答案的认同低于对提取式答案的认同。这是符合预期的,因为我们的评估指标是基于单词重叠而不是单词的含义。例如,Did Jenny like her new room?人类的答案,she loved it 以及 yes 都是可以被接受的答案。
为抽象的回答寻找完美的评价指标仍然是一个具有挑战性的问题 ( Liu et al., 2016 ),超出了我们的工作范围。对于我们的模型的性能,SEQ2SEQ 和 PGNET 在抽象答案的问题上表现良好,而 STANFORD ATTENTIVE READER 由于各自的设计,在抽取答案的问题上表现良好。组合模型对这两种类型都进行了改进。
在词法问题类别上,人类发现词汇匹配且伴随着解释的问题是最容易的,而涉及到语用学的问题是最难的——这是符合预期的,因为涉及词汇匹配以及解释的问题和篇章之间有相似性,因为使得回答他们要比语用问题相对简单。最好的模型也遵循同样的趋势。虽然人类发现没有指代性的问题比那些有指代性的问题 ( 显式或隐式 ) 更容易,但是模型的行为是断断续续的。目前还不清楚为什么人类发现隐式引用比显式引用更容易。有一种推测是,隐式引用直接依赖于前一个回合,而显式引用可能对对话有长距离依赖。
Importance of conversation history。最终,我们检验了数据集中对话历史的重要性。表 6.7 显示了使用不同数量的先前回合作为会话历史的结果。所有模型都成功地利用了历史,但最多只能利用一个前一回合的历史 ( PGNET 除外 )。令人惊讶的是,使用更多的对话回合可能会降低性能。
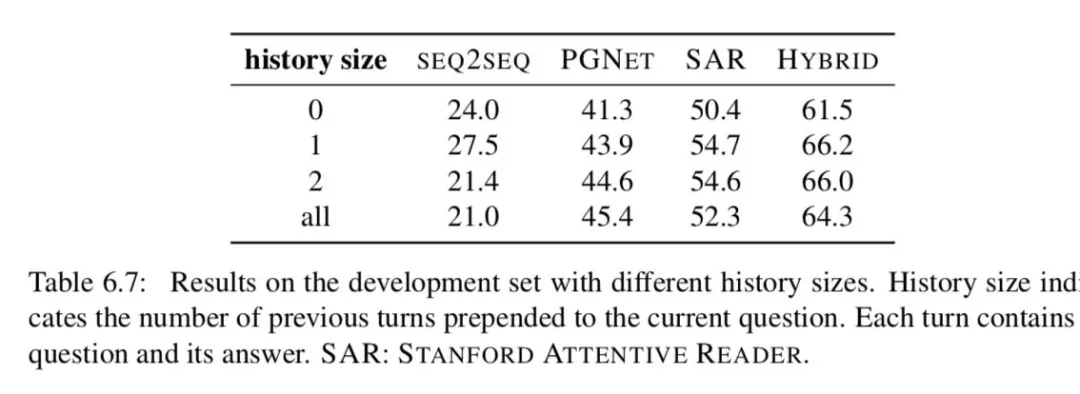
我们还对人类进行了一项实验,以衡量他们的表现和之前显示的轮次之间的平衡。基于短问答可能依赖于会话历史的启发,我们抽取了 300 个一两个单词的问题作为样本,并收集了这些问题的答案,这些问题的答案与前面显示的不同。
当我们不显示任何历史记录时,人类性能下降到 19.9 F1,而完整历史记录显示时为 86.4 F1。当显示前一个问题和答案时,他们的性能提升到 79.8 F1,说明前一个转弯在理解当前问题上发挥了重要作用。如果显示最后两个问题和答案,则可以达到 85.3 F1,几乎接近显示完整历史记录时的性能。这表明,对话中的大多数问题在两个回合内都有有限的依赖性。
6.5 Discussion
到目前为止,我们已经讨论了 COQA 数据集和几个基于会话模型和阅读理解模型的竞争性基线。我们希望我们的努力能够成为构建会话 QA 代理的第一步。
一方面,我们认为 COQA 的性能还有很大的提升空间:我们的混合动力系统 F1 成绩为 65.1%,仍然落后于人类的 23.7 分 ( 88.8% )。我们鼓励我们的研究团队研究这个数据集,并推动会话问题回答模型的极限。我们认为有几个方面需要进一步改进:
我们构建的所有基线模型都只使用对话历史,方法很简单,就是将前面的问题和答案与当前的问题连接起来。我们认为应该有更好的方式把历史和当前的问题联系起来。对于表 6.4 中的问题,我们应该建立模型来真正理解问题中他的名字是什么?指的是小狗,而问题在哪里?意味着西里塞纳将在哪里宣誓就职?事实上,最近的一个模型 FLOWQA ( Huang et al., 2018a ) 提出了一种解决方案,可以沿着会话流有效地堆叠单轮模型,并在 COQA 上展示了最先进的性能。
我们的混合模型旨在结合跨度预测阅读理解模型和指针生成网络模型的优点,解决抽象答案的不足。然而,我们将其实现为管道模型,因此第二个组件的性能取决于阅读理解模型能否从文章中提取正确的证据。我们认为构建一个端到端模型是可取的,它可以提取基本原理,同时将基本原理重写为最终的答案。
我们认为我们收集的原理可以被在训练模型的时候更好的利用。
另一方面,COQA 当然有其局限性,我们应该在未来探索更具挑战性和更有用的数据集。一个明显的限制是,COQA 中的转换只是问答对的转换。这意味着回答者只负责回答问题,而她不能问任何澄清问题或通过对话与提问者沟通。另一个问题是 COQA 很少有 ( 1.3% ) 无法回答的问题,我们认为这在实际的逆向 QA 系统中是至关重要的。
在我们的工作之外,Choi 等人 ( 2018 ) 还创建了一个文本段落问答形式的对话数据集。在我们的界面中,我们向提问者和回答者都显示了一段话,而他们的界面只显示了提问者的标题和对回答者的完整段落。由于他们的设置鼓励回答者为下面的问题透露更多的信息,他们的答案平均长达 15.1 个单词 ( 我们的是 2.7 个 )。在我们的测试集中,人类的性能是 88.8 F1,而他们的性能是 74.6 F1。此外,虽然 COQA 的答案可以是抽象的,但它们的答案仅限于提取文本范围。我们的数据集包含了来自七个不同领域的文章,而他们的数据集仅来自维基百科上关于人的文章。与此同时,Saeidi 等人 ( 2018 ) 还为税收和签证法规等监管文本创建了对话式 QA 数据集。他们的回答仅限于“是”或“不是”,同时也有一个积极的特点,即当某个问题无法回答时,他们可以提出澄清性的问题。
7. Conclusions
在这篇论文中,我们对神经阅读理解的基础 ( 第一部分 ) 和应用 ( 第二部分 ) 进行了全面的概述,以及自 2015 年末神经阅读理解出现以来,我们是如何为这一领域的发展做出贡献的。
在第二章中,我们回顾了阅读理解的历史,这可以追溯到 20 世纪 70 年代。当时,研究人员已经认识到它作为测试计算机程序语言理解能力的一种适当方法的重要性。然而,直到 2010 年代,阅读理解才开始被表述为一个监督学习问题,以三组 ( 短文、问题、答案 ) 的形式收集人类标记的训练例子。自 2015 年以来,通过对大规模监督数据集的创建,以及神经阅读理解模型的开发,该领域已经完成了重塑。尽管到目前为止只有 3 年的时间,但这个领域的发展速度惊人。在建立更好的数据集和更有效的模型方面的创新也相继出现,它们都对该领域的发展做出了贡献。我们还正式定义了阅读理解的任务,并描述了四种最常见的问题类型:完形填空、多项选择、跨度预测和自由形式的答案及其评价指标。
在第三章中,我们涵盖了现代神经阅读理解模型的所有要素。我们介绍了斯坦福专注读者,这是我们首先为 CNN/每日邮报的完形填空任务提出的,是该领域最早的神经阅读压缩模型之一。我们的模型在其他完形填空和多项选择题中得到了广泛的研究。后来我们将其应用到球队数据集中,并取得了当时最先进的性能。与传统的基于特征的模型相比,该模型不依赖于任何下游语言特征,所有参数共同优化。通过实验和仔细的手工分析,我们得出结论,神经模型在识别词汇匹配和释义方面更强大。我们还讨论了最近在开发神经阅读理解模型方面的进展,包括更好的单词表示、注意机制、LSTMs 的替代品,以及其他进展,如训练目标和数据增强。
在第四章中,我们讨论了该领域未来的工作和有待解决的问题。我们检查了 SQUAD 的错误案例 ( 对于我们的模型和超越人类表现的最先进的模型 )。我们的结论是,这些模型对文本进行了非常细致的匹配,但它们仍然难以理解实体与文本中所表达的事件之间的内在结构。我们稍后讨论了模型和数据集的未来工作。对于模型,我们认为除了精确性之外,还有其他被忽略的重要方面,这些方面是我们在未来需要改进的,包括速度和可伸缩性、健壮性和可解释性。我们也相信未来的模型将需要更多的结构和模块来解决更困难的阅读理解问题。对于数据集,我们讨论了最近在 SQUAD 之后的数据集开发——这些数据集要么需要通过句子或者文档进行更加复杂的推理,要么需要处理更长的文档,或者需要生成自行形式的答案,而不是直接提取一个范围,或者当文档中没有正确答案时进行预测。最后,我们检测了几个我们认为对于未来的神经阅读理解比较重要的问题。
在第二部分中,我们想要回答的关键问题是:阅读理解仅仅是衡量语言理解的一个任务吗?如果我们能够构建一个高性能的阅读理解系统,能够在短时间内回答理解问题,那么它是否能够实现有用的应用呢?
在第五章中,我们展示了我们可以结合信息检索技术和神经阅读理解模型来构建一个开放领域的问答系统:在大型百科全书或网络上回答一般问题。特别地,我们在 DRQA 项目中实现了这个想法,这是一个大型的、基于英语维基百科的真实问题回答系统。我们在多个问题回答基准上对系统进行了评估,证明了该方法的可行性。我们还提出了一个程序,从其他问答资源中自动创建额外的远程监督培训示例,并证明了该方法的有效性。我们希望我们的工作在这一研究方向上迈出第一步,这种信息检索和神经阅读理解相结合的新范式最终将导致新一代开放领域的问题回答系统。
在第 6 章中,我们讨论了会话问题的回答问题,即计算机系统需要理解文本段落并回答会话中出现的一系列问题。为了解决这个问题,我们构建了 COQA:一个会话性问题回答挑战,用于测量机器参与问答式对话的能力。我们的数据集包含 127k 个带答案的问题,来自七个不同领域的 8k 个关于文本段落的对话。基于会话和阅读推理模型,我们还为这项新任务建立了几个具有竞争力的基线。我们相信,构建这样的系统将在我们未来的会话人工智能系统中发挥至关重要的作用。
总之,我们对过去三年在这一领域取得的进展感到非常兴奋,并很高兴能够为这一领域作出贡献。同时,我们也深信,要达到真正的人的阅读理解水平还有很长的路要走,我们仍然面临着巨大的挑战,还有很多悬而未决的问题需要我们在未来加以解决。一个关键的挑战是,我们仍然没有好的方法来达到更深层次的阅读理解——这些问题需要理解文本的推理和含义。通常这种情况会发生在“如何”或“为什么”的问题上,比如在故事中,“辛西娅为什么对她的母亲不高兴?,约翰试图怎样弥补他最初的错误?“ ( In the story, why is Cynthia upset with her mother? How does John attempt to make up for his original mistake? ) 在未来,我们必须解决所讨论内容的基础科学问题以达到这种阅读理解的水平,而不仅仅是通过文本匹配来回答问题。
我们也希望鼓励更多的研究人员致力于应用,或将神经阅读理解应用于新的领域或任务。我们相信,它将引导我们构建更好的问答和会话代理,并希望看到这些想法在行业应用中得到实现和发展。
参考文献















结束感想
时间:三个月翻译,一个月修理格式。也是够慢的。可以 del 掉这个 alias 了。
坦白说,翻译这个事情还真的挺累的,有时候下班太累了就不想看了。有时候看了就不想写了。有时候没看懂,也不知道该咋写,经常借助有道词典。最近工作紧张起来,也没有很多时间仔细看论文,越往后越累,越难,好忧桑。。。周末赶紧加班弄好,喝了一天的红茶,终于搞定了。虽然有点累,不过挺开心。
有很多时间花在公式、格式上了。以为之前翻译过一本书,再来弄这个会容易很多,我还是太年轻了。
文章中讨论的知识很全面,我想可以作为一个参考书性质的东西,遇到问题的时候回头来看看,查找一下解决方案。有时候也不是你没学过,学过会忘记啊。最近遇到一个问题没有数据集,我也很头疼,就随便翻翻这本论文,就看到 back trans,emmm,尽管我已经读过这个了。。。。我之前咋就没想到[可能是我太傻了]
anyway,这个过程也复习了英语,也全面预习了一下神经阅读理解的内容,也熟悉了一下 markdown、readdocs 以及公式编辑器,还有 typora 这个挺好用的 markdown 编辑器。读论文读的我都想回炉继续进修了。特别是最近又在看 Cho 的 Natural Language Uniderstanding with Distributed Representation,开头第一句就很有趣,总感觉在这一点上老师和我能聊在一起。什么 the road we will not take,还把乔姆斯基以及 Yoav Goldberg 大肆夸奖了一番。还有 github 上的有趣的 readme。
最近在跟 stanford cs224n 的课程,感兴趣的同学可以到这里:
https://github.com/DukeEnglish/cs224n_learning_note
虽然学过了,咋感觉都忘记了呢。对不起我的研究生导师。。。
这个课程的 default final 是 squad2。到时候回来再借鉴一下这个论文吧。
再次感谢作者的这篇论文,收获很多。也很感谢其对 NLP 的贡献。
大家加油,与君共勉。
啊,好好学习,天天向上吧!!!
关于这篇论文的中文翻译在这里:
https://chendq-thesis-zh.readthedocs.io/en/latest/
同时我强烈推荐 phD Grind:
http://www.pgbovine.net/PhD-memoir.htm
这篇文章,也是讲述了斯坦福大学的博士生的学习心路历程。推荐理由引用其中的一段话:有些人可以通过博士的学习生涯学习到一种思维方式,有的人没有通过博士的学习生涯,但是通过别的方式同样达到了这样的高度。
NLP 领域逐渐进入人们的视野,从 word2vec 到 BERT 再到后来提出的一些模型,都是在 dig 预训练这个环节。
在未来,有时间的情况话,我会对文中提到的一些有代表性的论文进行解读。部分论文会进行复现。
才疏学浅,有不足之处,还望指出。谢谢。可以直接提出 issue 或者通过邮件联系:4ljy@163.com。
本文翻译已经咨询过原作者。
本文仅供学习交流所用,一切权利由原作者及单位保留,译者不承担法律责任。
论文原文地址:
https://www.cs.princeton.edu/~danqic/papers/thesis.pdf
陈丹琦博士个人主页:
https://www.cs.princeton.edu/~danqic/
译者介绍:
Duke Lee。前美团点评 NLP 算法工程师。曾负责自然语言处理平台。
本文来自 DataFun 社区
原文链接:

Java 避坑指南:Java 高手笔记代码篇
本迷你书包括 86 个业务开发中常见踩坑点。每一个知识点都相当的实用,是程序员业务开发中的必备避坑指南...











评论