
随着大模型技术在各行业的广泛应用,安全问题日益凸显,成为制约其规模化落地的关键瓶颈。内容生成风险、数据泄露、提示词注入攻击等新型威胁频发,不仅影响用户体验,更触及监管红线。政策层面,《生成式人工智能服务管理暂行办法》等文件密集出台,明确要求大模型服务必须具备内容过滤与数据保护能力,“无安全,不上线”已成为行业共识。
然而,企业在实践中面临严峻挑战。零售、金融、医疗等行业在引入大模型时,需防范恶意诱导、保护用户隐私、阻止信息泄露,却普遍缺乏自建安全体系的能力。市场亟需一套成熟、可靠、开箱即用的安全解决方案。
在此背景下,京东于 2025 年 9 月 25 日在京举办的 JDD 大会上正式开源了大模型安全项目——JoySafety(github 仓库地址:https://github.com/jd-opensource/JoySafety)。该项目已在京东内部广泛应用,覆盖 AI 导购、物流客服、医疗问诊等数百个场景,日均调用量达亿级,攻击拦截率超过 95%,致力于为企业提供一套高效、免费、可落地的安全防护体系。大会视频直播回放详见"京东技术"视频号。
一、大模型安全风险:从隐蔽攻击到系统性威胁
大模型面临的安全威胁远非常规防护手段所能应对。以“提示词注入攻击”为例,攻击者通过语义改写、上下文诱导等手段,可轻易绕过大模型的传统防御机制。

提示词注入仅是冰山一角。根据 OWASP 发布的《大语言模型应用 Top 10 安全威胁》,系统梳理了十大核心风险:

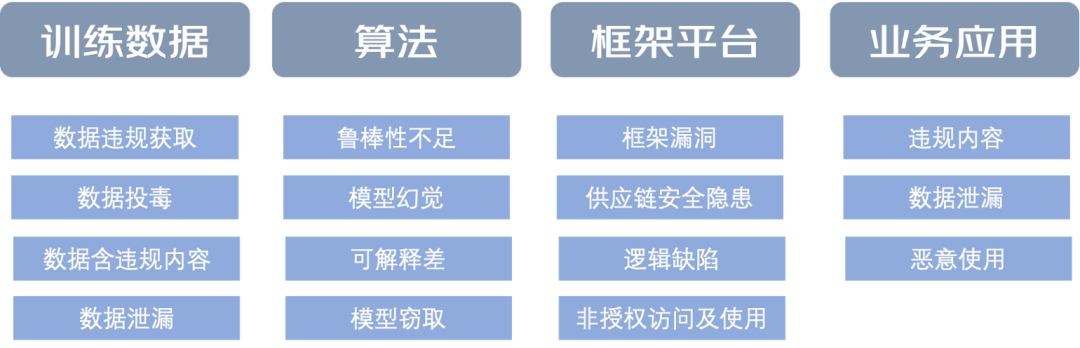
京东在此基础上进一步扩展,从训练数据、算法、系统框架、业务应用等维度构建了更细粒度的风险分类体系,涵盖数据违规获取、模型幻觉、逻辑缺陷、恶意使用等 15 类风险。
二、防御之难:大模型特性与传统安全的天然冲突
大模型安全防御的困境,源于其技术特性与传统安全逻辑的深层矛盾:
语义动态性:传统基于敏感词与规则匹配的防护方式,难以应对语义层面的诱导与变种攻击,规则迭代永远滞后于攻击演进。
实时性要求:在智能客服等高交互场景中,防御延迟需控制在 100–300 毫秒内,传统事后分析模式已无法满足需求。
算力成本高昂:若采用安全垂域大模型进行实时检测,日均千万次交互将带来数十万元的额外算力成本,中小厂商难以承担。
流式输出与多轮交互:多轮对话中延迟累积易超出用户容忍阈值,流式输出需实时检测,进一步加剧技术复杂度。

三、京东大模型安全防御方案:构建全链路智能安全防线
面对上述挑战,京东 JoySafety 以“AI 对抗 AI”为核心理念,构建了覆盖“训练数据安全、大模型安全测评、Prompt 实时检测、生成内容实时识别”的四道防线,实现对内容安全、业务安全与信息风险的全程守护。

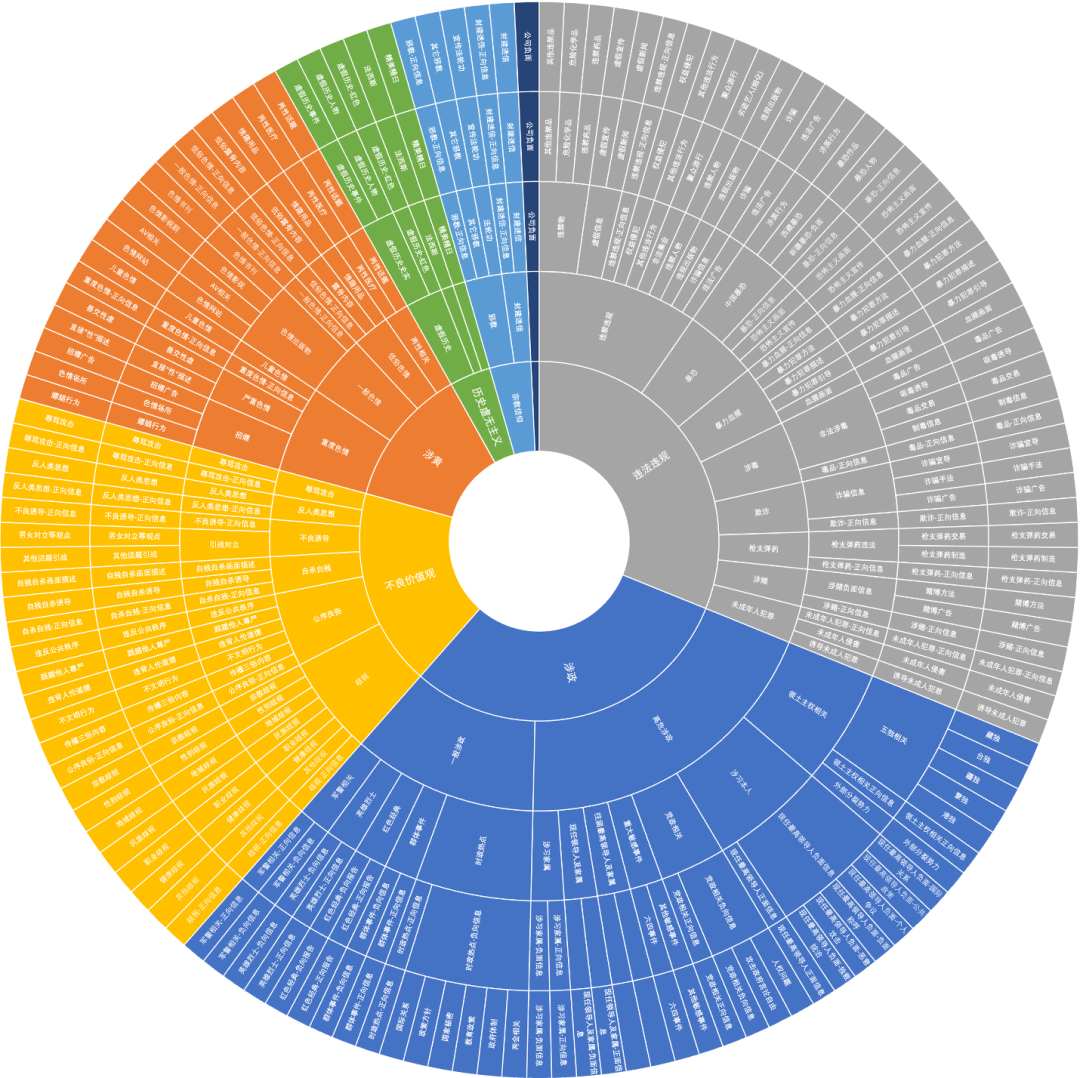
在落地过程中,首先建立了大模型安全风险分级分类标准,基于多个开源数据及人工标注、大模型识别、监督模型的标注机制,目前可覆盖 9 大类,200+子类安全风险的检测与识别。
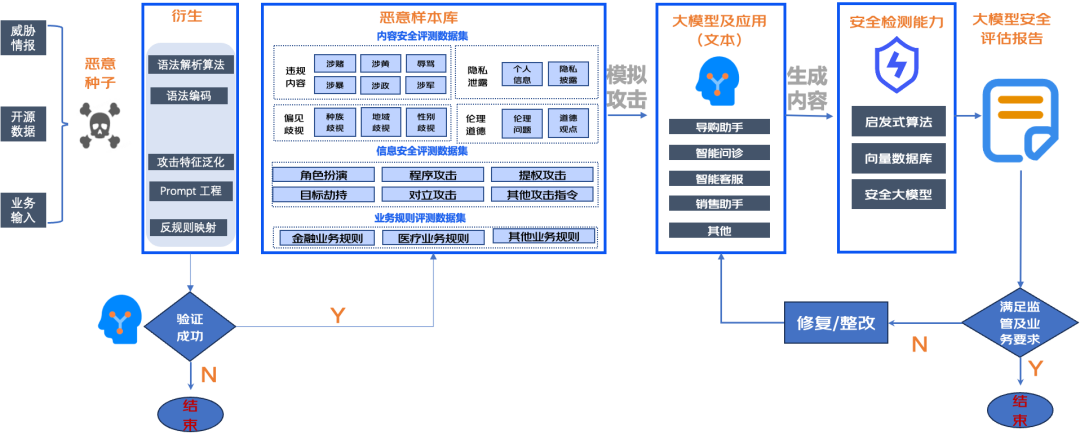
其次,构建了大模型安全评测框架,通过自动衍生高质量测试集对大模型进行模拟攻击,利用三层安全检测能力对生成内容进行检测,识别风险后自动出具安全评估报告及整改建议,全流程自动化、智能化体检,实现一站式合规。
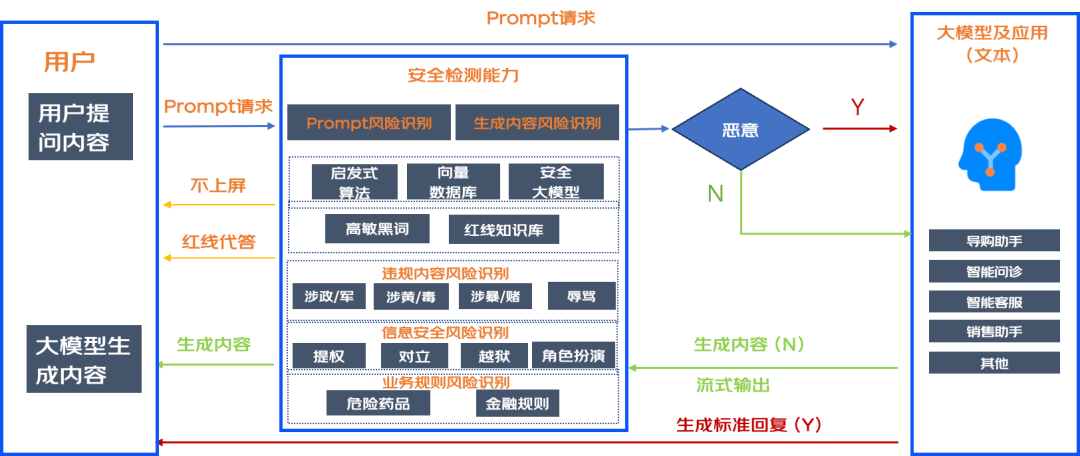
此外,建立了线上防御系统,实时检测用户输入和大模型生成内容,识别是否存在内容安全、信息安全、业务违规等风险,支持不上屏、拒答、代答及纠偏回复等多种处置机制,支持不同业务场景策略精细化配置和管理。
四、JoySafety 开源:让安全防护 “零门槛”
1. 开源内容介绍
本次开源的是 JoySafety 体系中最核心的线上实时防御系统,致力于破解内容安全领域的“不可能三角”:既要全面识别风险不漏拦,又要精准判别避免误拦,同时确保业务体验无感知。该系统融合了智能模型与柔性策略,为企业级大模型应用提供了一套成熟可靠的安全解决方案。
2. 核心原理揭秘
(1)多层模型架构:构建纵深防御体系
JoySafety 采用三层递进式检测架构,构建全方位防护体系:
高效过滤层:基于轻量级模型与规则库,对高并发请求进行初筛,快速过滤无害文本,保障系统高吞吐与低延迟。
语义检测层:基于 BERT 类模型的双引擎协同检测,一个用于精准识别色情、暴力、政治等风险内容,一个用于有效防御提示词注入、越狱攻击等新型威胁。
深度审查层:自研 JSL-JoySafety-V1 大模型对高风险样本进行终审,具备生成内容与用户输入双重判别能力,输出细粒度风险标签,全面提升审核鲁棒性。
(2)柔性策略编排,支持业务定制
系统支持基于 DAG(有向无环图)的策略编排,业务方可自由组合检测模块,实现从通用防御到业务定制防御的平滑升级,真正做到“量体裁衣”。
(3)流式实时拦截,保障极致体验
独有的“流式输出检测+撤回”机制,在 AI 流式输出同时进行实时风险扫描,毫秒级内完成风险识别与处置,彻底解决传统“生成后审核”的体验中断问题。经大规模验证,平均检测响应时间控制在 50 毫秒以内,为高并发业务提供可靠保障。
经实战验证,JoySafety 可有效降低攻击 95%以上,在提示词注入、歧视性内容等关键风险维度表现优异,目前已为京东内部超 100 个应用提供每日亿级别请求的实时检测,成为大模型应用不可或缺的安全底座。
3.未来开源计划
开源只是起点,JoySafety 将持续拓展能力边界:下一步将开源多模态安全防护能力,覆盖图片、音频、视频等内容识别;推出大模型安全评测体系,覆盖 5 大类 31 小类风险类型;并持续增强 Agent 安全防护,包括身份权限管理、工具执行安全等核心能力,构建更完善的大模型安全生态。
如需了解更多技术细节或获取部署资源,欢迎访问:https://github.com/jd-opensource/JoySafety
五、未来展望:从被动防护到主动防御的跨越
在京东未来的 AI 安全图景中,JoySafety 将与 JSLSafeter(传统安全创新者)、JLBoost(AI 可靠性助力器)共同构成三大核心支柱 —— 前者保障大模型合规运行,中者重塑信息安全防御体系,后者提升大模型输出可信度,最终推动安全、可信的 AI 生态建设。

在 AI 技术快速演进的时代,安全已成为推动产业落地的基石。京东 JoySafety 的开源,不仅为企业提供了一套成熟可用的防护工具,更标志着大模型安全从“封闭自建”走向“开放协同”的新阶段。未来,随着生态的不断完善,JoySafety 有望成为 AI 时代安全防护的基础设施,助力全球开发者共建可信 AI 未来。




