
导语 | 随着业务的发展,系统日益复杂,功能愈发强大,用户数量级不断增多,设备 cpu、io、带宽、成本逐渐增加,当发展到某个量级时,这些因素会导致系统变得臃肿不堪,服务质量难以保障,系统稳定性变差,耗费相当的人力成本和服务器资源。这就要求我们:要有勇气和自信重构服务,提供更先进更优秀的系统。文章作者:刘敏,腾讯基础架构研发工程师。
前言
自今年三月份以来 天机阁 用户数快速上涨,业务总体接入数达到 1000+,数据进入量更是迎来了爆发式上涨,日均处理量上涨了一个数量级:Trace 数据峰值处理量达到 340 亿/日条,Log 日志数据峰值处理量级达到 140 亿/日条。
面对海量数据,老的实时计算系统处理压力逐渐增加,底层存储系统无论在磁盘、IO、CPU、还是索引上都面临巨大的压力,计算集群资源利用率不高,系统的调整优化迫在眉睫。
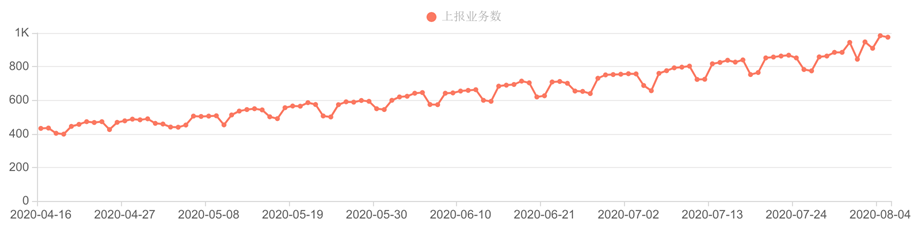
业务接入量
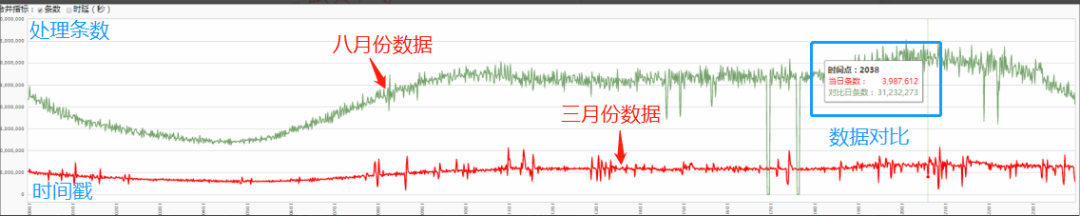
同比日均处理量级
一、什么是天机阁
在传统单机系统的使用过程中,如果某个请求响应过慢或是出错,开发人员可以通过查看日志快速定位到具体服务。
而随着业务的越来越复杂,架构由单体逐渐演变为微服务架构。特别是随着容器, Serverless 等技术的广泛应用,它将庞大的单体应用拆分成多个子系统和公共的组件单元。
这一理念带来了许多好处:复杂系统的拆分简化与隔离、公共模块的重用性提升与更合理的资源分配、大大提升了系统变更迭代的速度以及可扩展性。
但反之,业务架构也随之变的越来越复杂,一个看似简单的业务后台可能有几百甚至几千个服务在支撑,当接口出现问题时,开发人员很难及时从错综复杂的服务调用中找到问题的根源,从而错失了止损的黄金时机,排查问题的过程也需要耗费大量的时间和人力成本。
为了应对这一问题,业界诞生了许多优秀的面向 Devops 的诊断分析系统,包括 Logging、Metric、Tracing。三者关系如图所示:
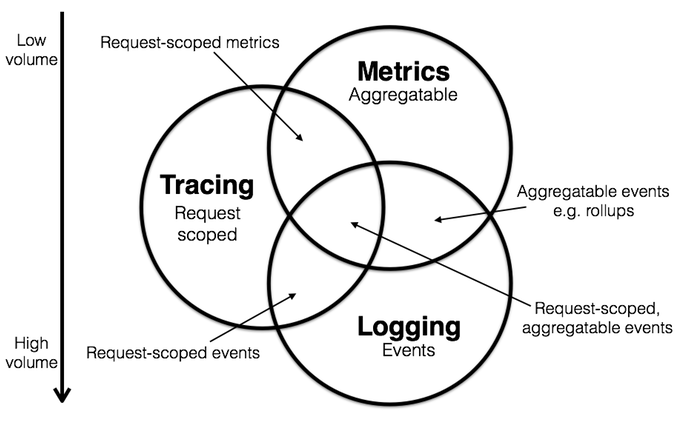
Tracing:一系列 span 组成的树状结构。每个 span 包含一次 rpc 请求的所有信息。从用户发出请求到收到回包,就是通过 trace 来串联整条链路。
Metric:指标数据。是对可观测性指标的一种度量,例如请求数、qps 峰值、函数调用次数、成功率、异常率、接口返回码分布等信息,可用作统计聚合。
Logging:业务日志。
三者互相重叠,又各自专注于自己的领域,将三者结合起来就可以快速定位问题。而已知的业界优秀开源组件有诸如:
Metric: Zabbix、Nagios、Prometheus、InfluxDB、OpenCenus;
Logging: ELK、Splunk、Loki、Loggly;
Treace: jeager、Zipkin、SkyWalking、OpenTracing。
随着时间的推移可能会集成更多的功能,但同时也不断地集成其他领域的特性到系统中来。而 天机阁正是腾讯研发的集三位于一体的分布式链路追踪系统,提供了海量服务下的链路追踪、故障定位、架构梳理、容量评估等能力 。
最近第二代天机阁系统已经建设完成,新天机阁采用 opentelemetry 标准,可以支持更多场景的数据接入,同时在系统稳定性,数据实时性方面都有很大提升。
二、系统架构
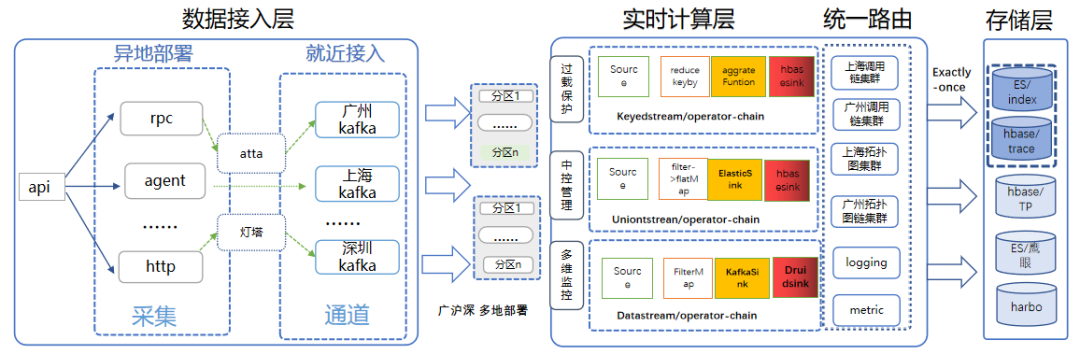
从数据流转角度来看,天机阁整体可以分为数据生产链路与消费链路,其中数据生产链路主要包括数据接入层、数据处理层、数据存储层。整体如下图所示。
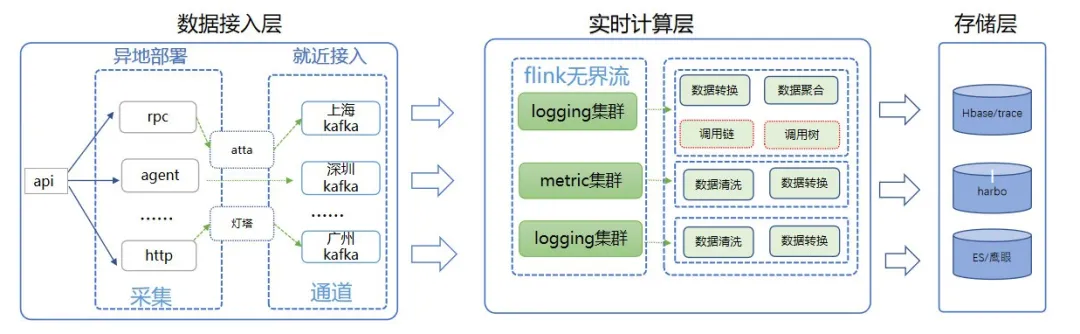
数据生产链路架构图
1. 数据接入层
主要负责数据采集工作,天机阁支持 http+json、http+proto、grpc 等多种数据上报方式,业务可以采用对应语言的 SDK 进行数据上报。根据业务上报环境,可选择 Kafka、虫洞等多种数据接入方式,为减少数据传输耗时,提升系统的容错能力,天机阁提供了上海、广州、深圳等多个不同区域的接入通道,数据接入时会根据 Idc 机器所在区域自动进行“就近接入”。
2. 数据处理层
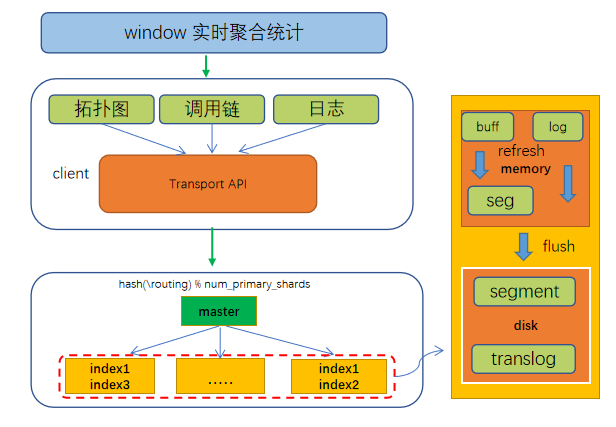
基于 Flink 构建的天机阁流式计算平台。主要处理三部分数据:第一部分是 Metric 模调数据的计算工作,结果同步至 Druid。第二部分是日志数据,基于 DataStream 模式对数据进行实时消费,同步至 ES 日志集群。第三部分是 Trace 数据,基于 KeyedStream 的分组转换模式,根据业务 Traceid 进行 Keyby,将一条 Stream 流划分为逻辑上不相交的分组,把相同 Traceid 的数据实时汇聚到同一个窗口,再对数据进行统计聚合,生成拓扑图、调用链、调用树等数据模型,结果同步至 Hbase 与 ES。
3. 数据存储层
ES 主要用于用于建立热门 Trace 的倒排索引以及存储日志数据,Harbo/Druid 系统用于存储模调数,Hbase 用于存储调用链,拓扑图,关系链等数据。
三、问题回顾
在海量流量的冲击下,日志集群与 Metric 集群一直比较稳定,处理耗时基本在秒级。影响较大的是 Trace 集群,Trace 集群主要通过滚动窗口接收一个 Trace 请求的所有 RPC 的 Span 信息。
由于业务接入量的上涨以及不少业务的放量,Trace 集群的日均处理量由 3 月份的 40 亿/day 爆发式上涨到 340 亿/day,且集群还要经常面临业务热点 push、错误埋点等场景的挑战。
这些问题直接导致数据实时性开始下降,期间经常收到用户反馈数据延时大,数据丢失的问题。而系统层面,则频繁出现集群抖动、延时飙升、Checkpoint 失败等现象。同时存储也面临巨大的写入压力:Hbase 与 ES 均出现写入延时上涨、毛刺的现象,而这些因素最终导致计算集群的处理性能变弱,稳定性下降。产生消费滞后,数据堆积的问题。具体有如下四个表象:
1. 集群抖动
集群毛刺、抖动情况增多,系统处理性能变弱,上游 Kafka 通道出现大量数据堆积情况,系统处理延时上升。
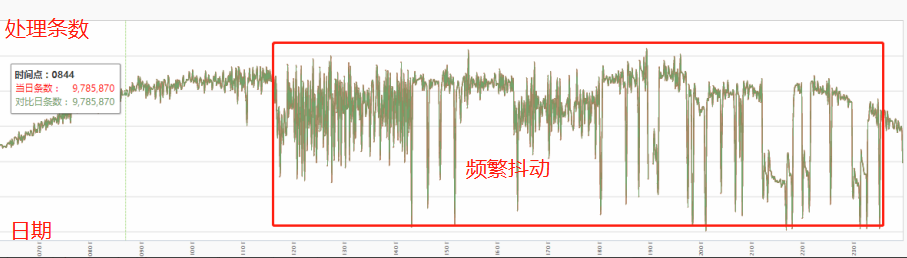
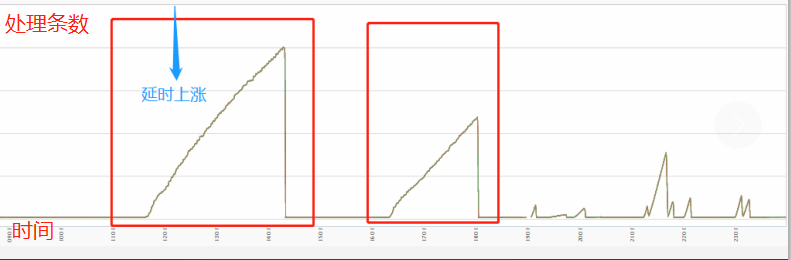
集群抖动,延时上涨
2.资源倾斜
Flink 算子反压严重,部分节点出现 CPU 过载的情况,且各算子的 Checkpoint 时间变长,频繁失败。
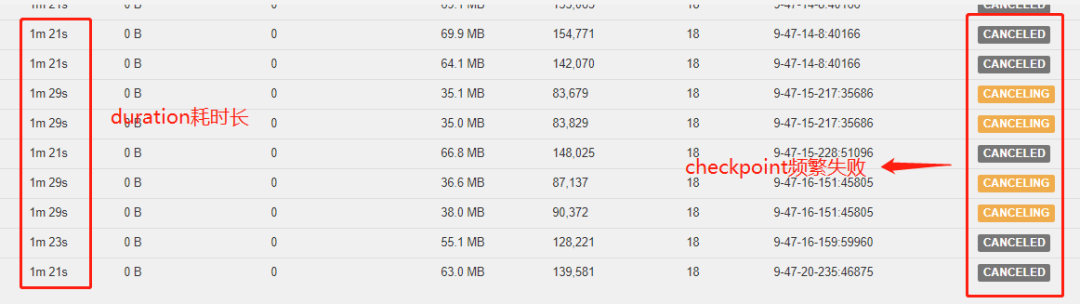
checkpoint 失败
3. 存储抖动
Hbase 写入延时上涨,高峰期写入延时上涨到 1300ms 左右,写 ES 平均延时上涨到 2000ms,早上 8~10 点出现大面积写入 ES 被拒绝的现象,最终会导致上游集群挂掉。
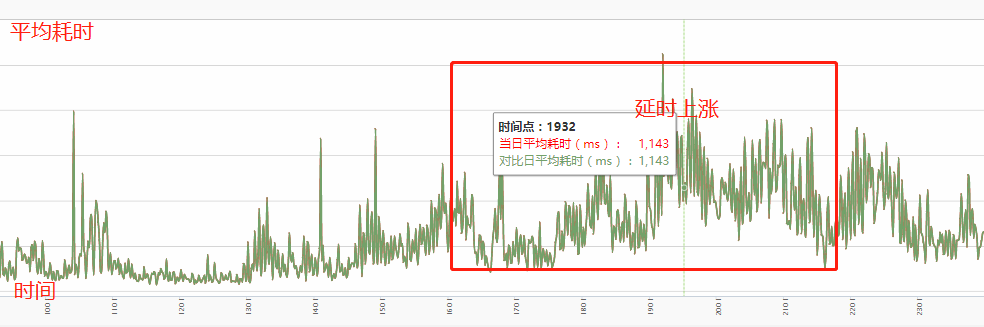
Hbase 写入延时
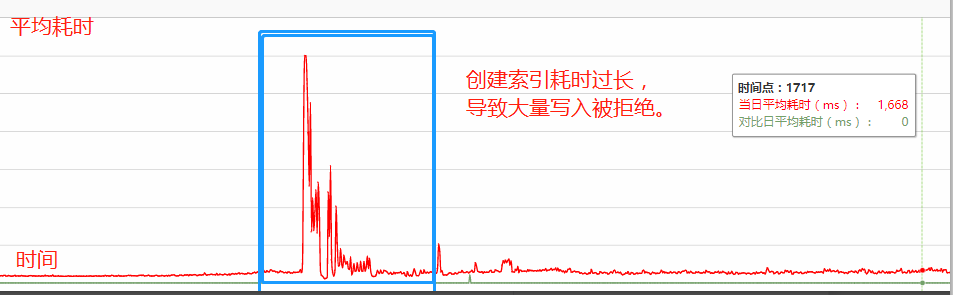
ES 写入延时
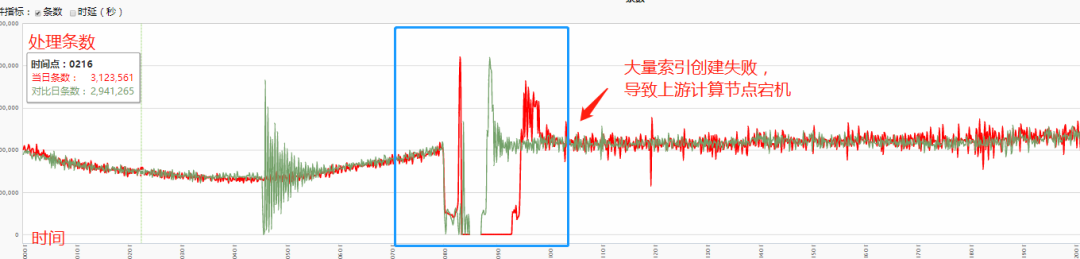
计算集群宕机
4. 系统异常
某些时间点出现系统异常,同时集群处理延时飙升。
本着先抗住再优化的思想,当出现上述问题时,为保证系统的可用性,我们会采取各种快速恢复策略,诸如计算资源扩容、数据降级、关闭数据可靠性等策略来提升集群的处理性能,达到快速恢复的目的。
但这些策略都治标不治本,性能问题周而复始的出现。这不但浪费了大量计算集群资源,集群处理性能,吞吐,稳定性都没有实质上的提升。
四、问题分析
针对上述四种现象,结合业务分别从接入层、存储层、计算层对系统进行了全面分析,找出了目前 Trace 系统存在的问题以及瓶颈,并制定了对应的优化方案:
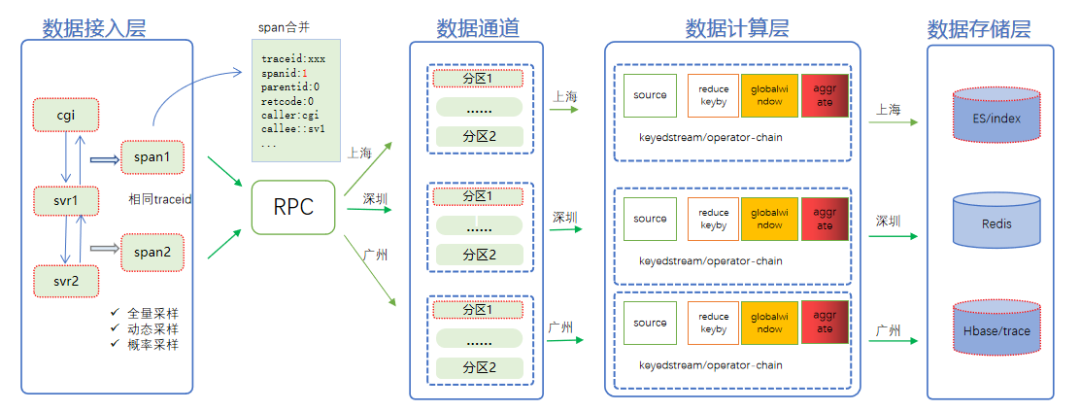
Trace 系统架构图
如上图所示,一次 RPC 的请求和回包最终会合并成一个 Span,而每个 Span 包含 Traceid、Spanid,以及本次 RPC 调用涉及的主被调服务信息。
在接入层进行数据采样上报时,会将相同 Traceid 的 Span 集合路由到同一个数据通道中,而计算层会对不同通道的数据做隔离,不同通道采用不同的计算任务对数据进行处理。
大致流程如下:首先根据 Traceid 高位字节进行 Reducekeby,确保同一个 RPC 请求的数据能路由到同一个窗口,再通过窗口函数对同一个请求的数据集合进行聚合计算,实时生成拓扑图,调用链等数据模型,批量写入 ES 和 Hbase 等列式存储。
在业务量少,集群相对稳定的情况下,Trace 集群平均处理时长在 20-40s 左右,即从一次 Trace 数据的上报到可展示的过程大概要经过半分钟。
当系统不稳定或者处理性能下降时,数据延时会上涨至小时甚至天级别,而主要导致系统不稳定的因素有两种:
数据量的上涨给存储系统带来了较大的摄入压力,底层数据的刷盘时间越来越长;
系统经常要面临业务方错误埋点或热点 Push 产生的热 key、脏数据等场景的考验。
具体表现为:
1. 底层存储数据摄入能力下降
Hbase 写入耗时达到 1300ms ES 写入耗时达到 2000ms。

存储抖动,集群处理耗时上涨
2. 热 key 造成集群资源倾斜
导致集群产生毛刺、吞吐量下降等问题 。

热 key 写入量 1000 万/min
3. 脏数据、代码 bug 造成服务异常,导致集群毛刺增多
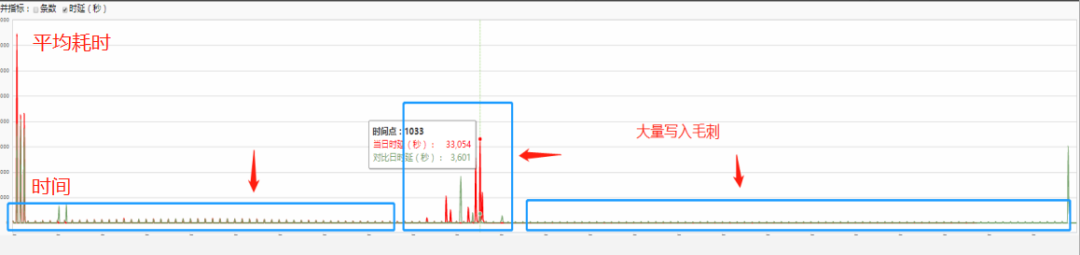
集群毛刺增多
4. 集群缺乏容错能力,过载保护能力 。
天机阁既是一个写密集型系统,也是一个时延敏感型系统,对数据的实时性有比较高的要求。系统的不稳定会导致消息通道大量数据堆积,数据实时性下降,最终影响用户体验,这是不能被容忍的。所以针对上述问题,我们需要对原系统进行全面的优化升级。
五、整体优化思路
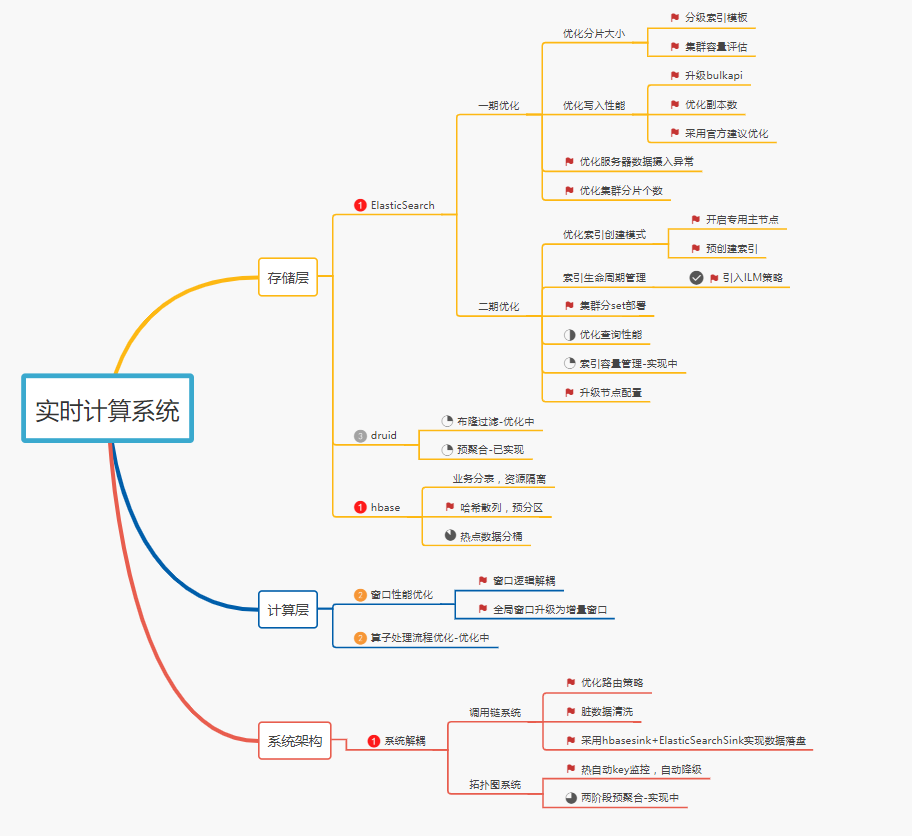
优化思路拓扑图
六、ES 优化
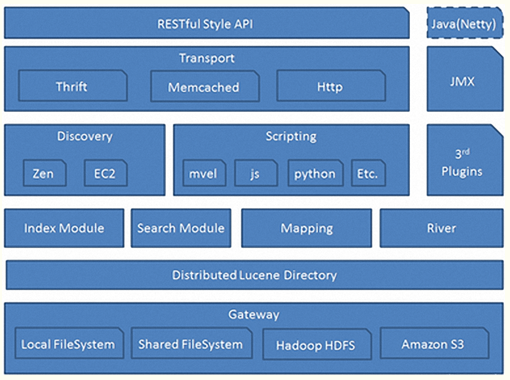
Elasticsearch 是一个实时的、Restful 风格的分布式搜索数据分析引擎,内部使用 lucene 做索引与搜索,能够解决常规和各种类型数据的存储及检索需求,此外 ES 还提供了大量的聚合功能可以对数据进行分析,统计,生成指标数据等。典型的应用场景有:数据分析,站内搜索,ELK,电商等,主要特点为:
灵活的检索、排序策略;
集群分布式,易扩展,平行扩缩容;
数据分片主备机制,系统安全高可用;
准实时索引;
高性能的检索,易用的接口(REST 风格);
丰富的生态 kibana 可视化界面 。
1. 业务背景
天机阁使用腾讯云的 ES 组件,专门用于建立热门 Trace 倒排索引,用户在使用天机阁进行链路追踪查询时,首先可以指定 Tag 或者染色 Key 查询到任意时刻上报的 Trace 元数据,天机阁会根据查询到的 Trace 数据绘制出完整的服务调用过程。同时在 UI 上可以支持瀑布、调用树的多种样式的数据展示。如下图所示:
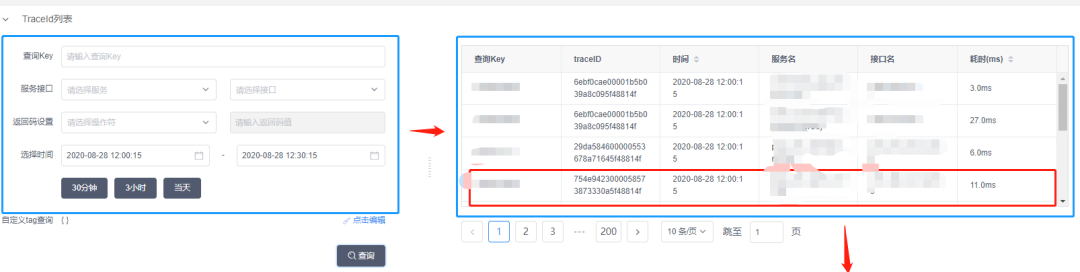

天机阁调用链
2. 存在的问题
随着进入量的上涨,ES 集群内部写入峰值达到 80w/s,日均文档总量达到 280 亿,索引占用总量达到 67T,每天新增索引量达到 1000+,而每日文档新增存储总量达到 10T。
机器配置采用为:64 个 4C 16g 的数据节点,平均 CPU 使用率在 45-50%之间;最大 CPU 使用率在 80%左右;内存使用率 60%左右,而磁盘平均使用率达到了 53%,整体流程为。
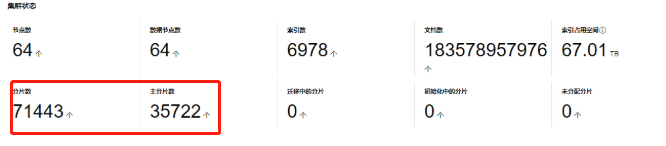
天机阁是基于业务 Appid 维度按天索引的策略,而伴随业务量的极速上涨主要暴露出来的问题为:
(1)集群内部分片过多
ES 分片过多
分片过多的缺点主要有以下三个方面:
ES 每个索引的分片都是一个 Lucene 索引,它会占用消耗 CPU、内存、文件句柄;
分片过多,可能导致一个节点聚集大量分片,产生资源竞争;
ES 在计算相关度词频统计信息的时候也是基于分片维度的,如果分片过多,也会导致数据过少相关度计算过低。
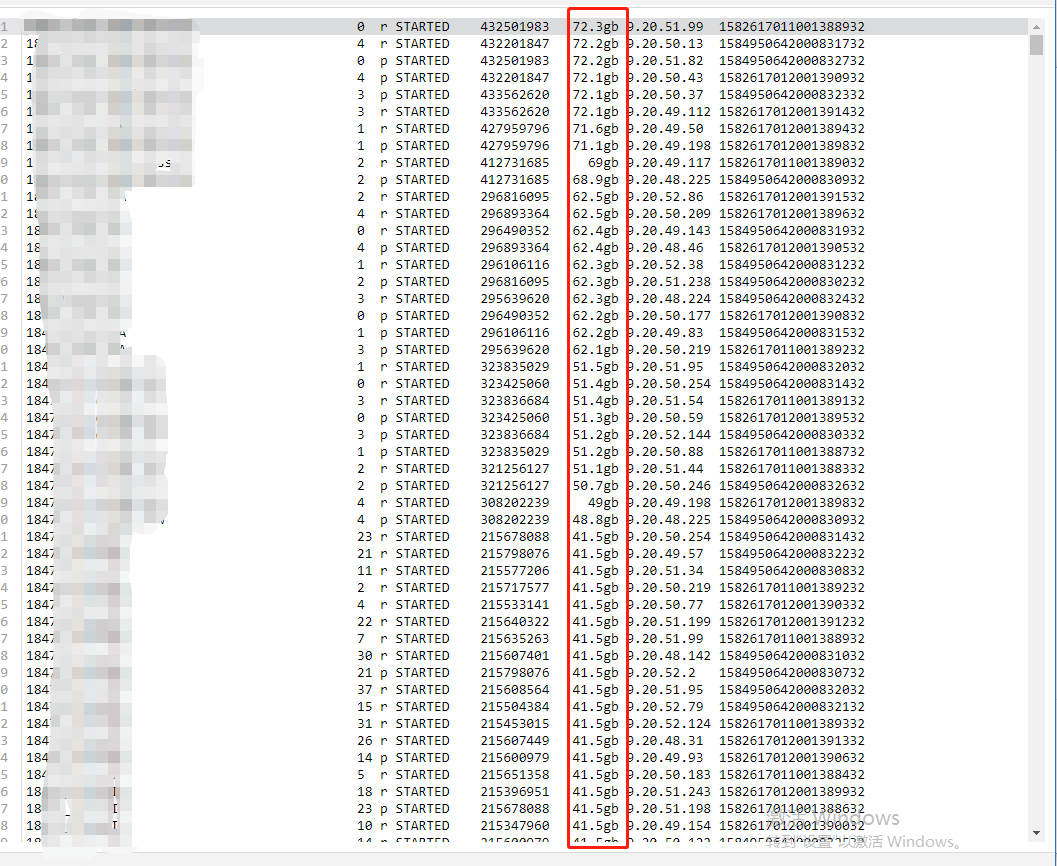
(2)分片大小不均匀
部分索引的分片容量超过 50G,侧面反应了这些索引分片策略的不合理,最终会导致索引的查询性能变慢。
ES 分片过大
(3)写入耗时过大,部分索引查询性能慢
ES 写入耗时达到(1500ms-2000ms),此外分片过大也直接影响到索引的查询性能。
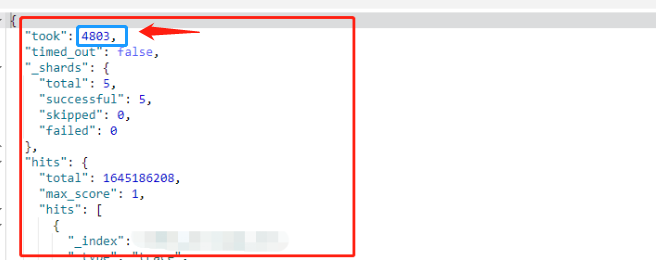
大索引查询超时(4800ms)
(4)索引创建过慢(1 分钟),大量写入被拒绝
集群没有设置主节点,导致创建索引时,数据节点要充当临时主节点的角色,写入量较小的时候,影响不大,当写入压力过大时,会加剧数据节点的负载,影响索引的创建速度。
当出现密集型索引创建时,这个问题被无限放大,索引创建同时也会伴随大量的元数据移动,更加剧了节点负载,从而导致大量数据写入被拒绝现象。
而写入被拒绝最终会导致上游 Flink 集群剧烈抖动(写入失败抛出大量异常),以致于索引创建高峰期经常出现 2-3 小时的集群不可用状态。
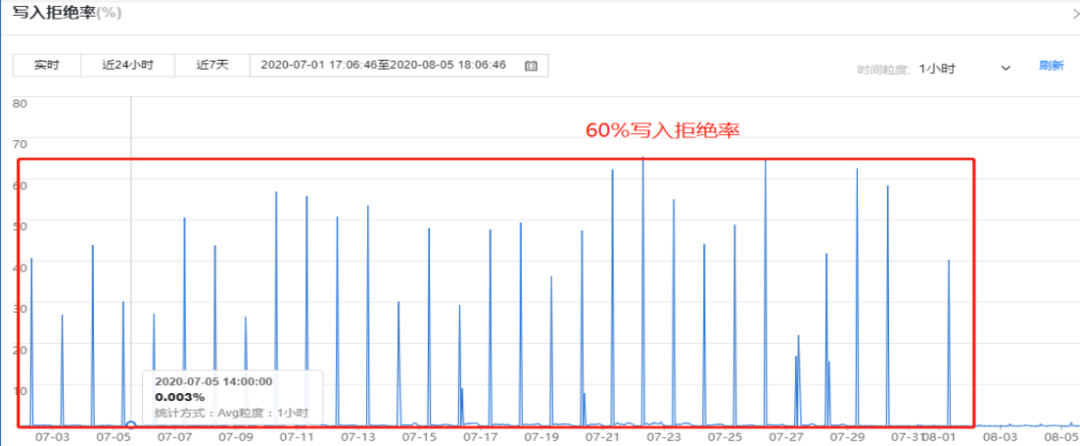
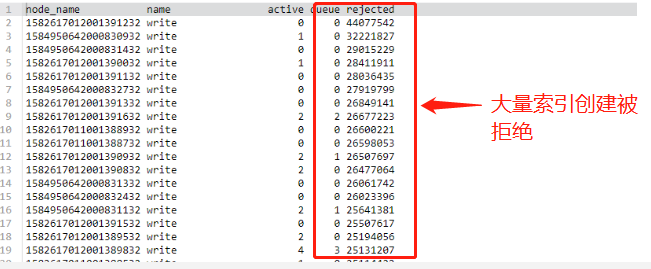
ES 写入被拒绝
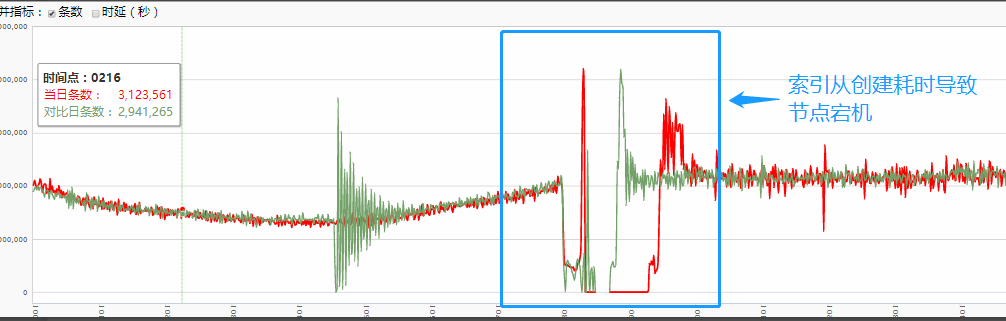
导致上游节点宕机
(5)系统出现大量异常日志
ES 服务器异常,主要分为两类,一类是:数据解析异常,另一类是:Fields_limit 异常。
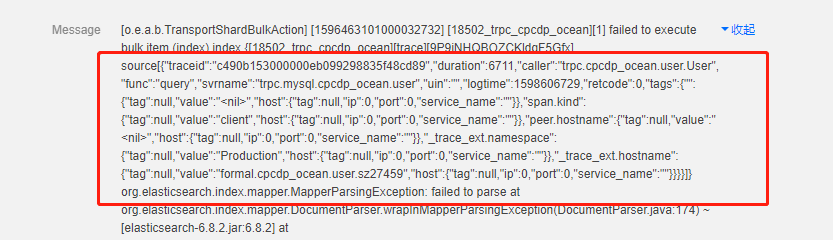
ES 服务器大量异常
(6)索引的容量管理与维护困难
主要是解决大规模以及日益增长数据场景下,集群的自动化容量管理与生命周期管理的问题。
3. 优化一期
优化点 1:优化集群内部分片过多、分片不合理、节点负载不均等问题。
其中主要涉及了二个问题:
如何确定索引单个分片大小?-> 小于 40G
如何确定集群中分片数量?-> 节点堆内存节点数 200 = 2 万左右
上述问题可以阅读 ES 官方文档和腾讯云 ES 文档得到全面的答案,这里不再赘述,总而言之,查询和写入的性能与索引的大小是正相关的,要保证高性能,一定要限制索引的大小。
而索引的大小取决于分片与段的大小,分片过小,可能导致段过小,进而导致开销增加,分片过大可能导致分片频繁 Merge,产生大量 IO 操作,影响写入性能。通过阅读相关文档,我提炼了以下三条原则:
分片大小控制 50G 以内,最好是 20-40G,以均衡查询和写入性能。
每个节点可以存储的分片数量与可用堆内存成正比,一条很好的经验法则:“确保每个节点配置的每 G 堆内存,分片数在 20 个以下”。
分片数为节点数整数倍,确保分片能在节点之间均衡分布。
当然最好的方法是根据自身业务场景来确定分片大小,看业务是注重读还是注重写以及对数据实时性、可靠性的要求。
天机阁的索引设计模式是非常灵活的,属于典型的时序类型用例索引,以时间为轴,按天索引,数据只增加,不更新。
在这种场景下,搜索都不是第一要素,查询的 QPS 很低。原先的分片策略针对容量过低的索引统一采用 5 个分片都默认配置,少数超过 500G 的大索引才会重新调整分片策略。
而随着近期接入业务的不断增多以及索引进入量的暴涨,集群内部出现了许多容量大小不一,且分布范围较广的索引。老的配置方式显然已经不太合理,既会导致分片数急剧增长,也影响索引的读写性能。
所以结合业务重新评估了集群中各个索引的容量大小,采用分级索引模版的分片控制策略,根据接入业务每天的容量变化,实现业务定制化的自适应分片。
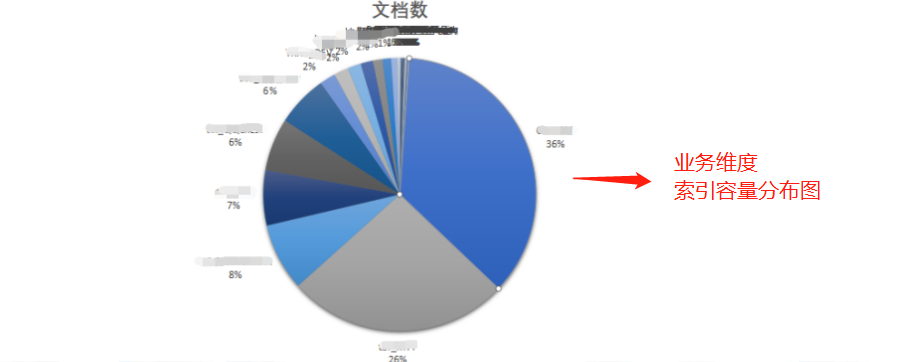
业务索引容量分布图
索引调整策略表
一般而言:当用户遇到性能问题时,原因通常都可回溯至数据的索引方式以及集群中的分片数量。对于涉及多租户和用到时序型索引的用例,这一点尤为突出。
优化点 2:优化写入性能。
减少集群副本分片数,过多副本会导致 ES 内部写扩大。ES 集群主用于构建热门 Trace 索引用于定位问题,业务特性是写入量大而数据敏感度不高。所以我们可以采用经济实惠的配置,去掉过多副本,维护单副本保证数据冗余已经足够,另外对于部分超大索引,我们也会采用 0 副本的策略。
索引设计方面,id 自动生成(舍弃幂等),去掉打分机制,去掉 DocValues 策略,嵌套对象类型调整为 Object 对象类型。此处优化的目的是通过减少索引字段,降低 Indexing Thread 线程的 IO 压力,经过多次调整选择了最佳参数。
根据 ES 官方提供的优化手段进行调整,包括 Refresh,Flush 时间,Index_buffer_size 等。
上述优化,其实是对 ES 集群一种性能的取舍,牺牲数据可靠性以及搜索实时性来换取极致的写入性能。但其实 ES 只是存储热门数据,天机阁有专门的 Hbase 集群对全量数据进行备份,详细记录上报日志流水,保证数据的可靠性。
客户端 API 升级,将之前 ES 原生的批量 API 升级为 Transport API,策略为当数据缓存到 5M(灵活调整)大小时,进行批量写入(经过性能测试)。
优化点 3:优化索引创建方式。
触发试创建索引改为预创建索引模式。
申请专用主节点用于索引创建工作。
优化点 4:优化 ES 服务器异常。
调整字段映射模式,Dynamic-Mapping 动态映射可能导致字段映射出现问题,这里修改为手动映射。
调整 Limit Feild 限制,修改 ES 索引字段上限。
业务层加入数据清洗算子,过滤脏数据以及埋点错误导致 Tag 过多的 Span,保护存储。
4. 一期优化展示
cpu 使用率:CPU 使用率 45% => 23%,内部写入量从 60 万/s => 40 万/s。
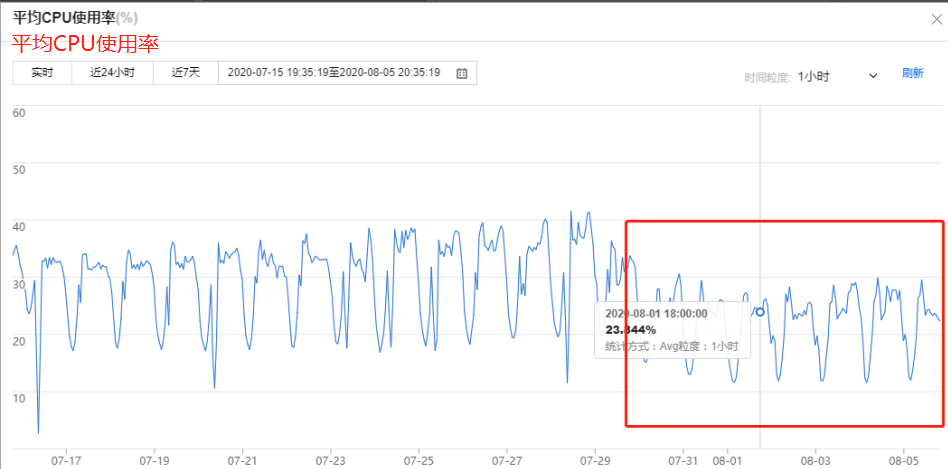
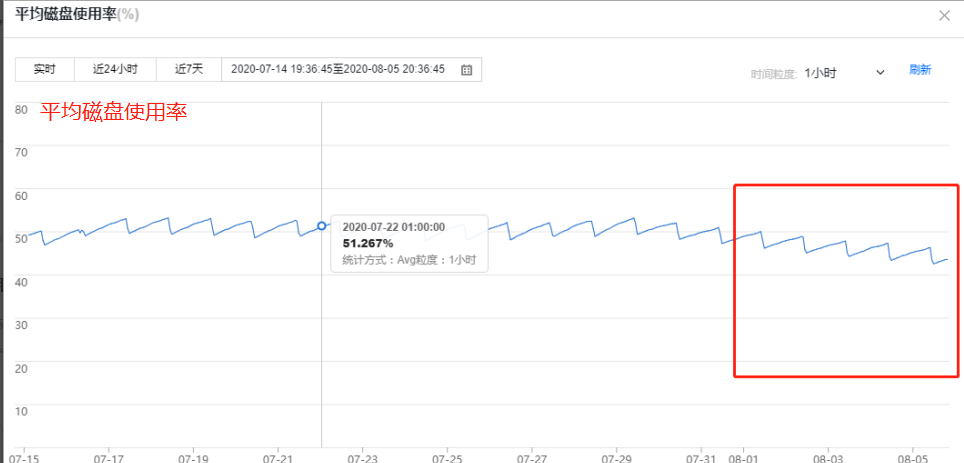
磁盘使用率:53% => 40%。
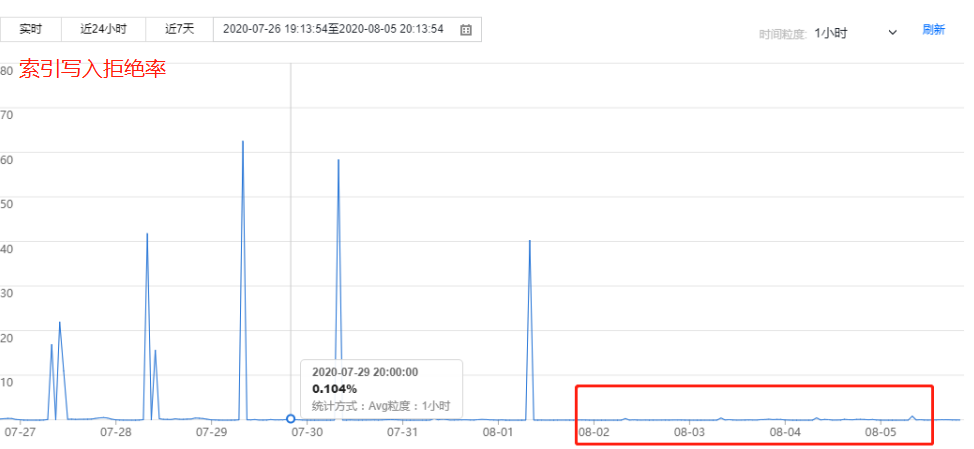
写入拒绝率:索引写入拒绝率降为 0。
集群宕机问题被修复:
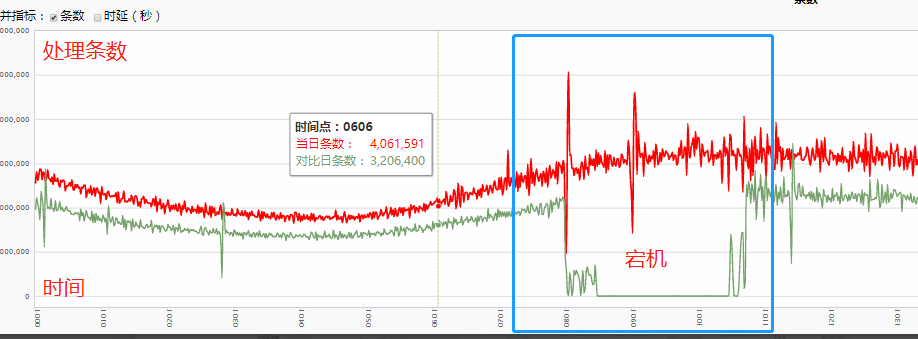
查询耗时:大索引跨天级别查询在 500ms 左右。
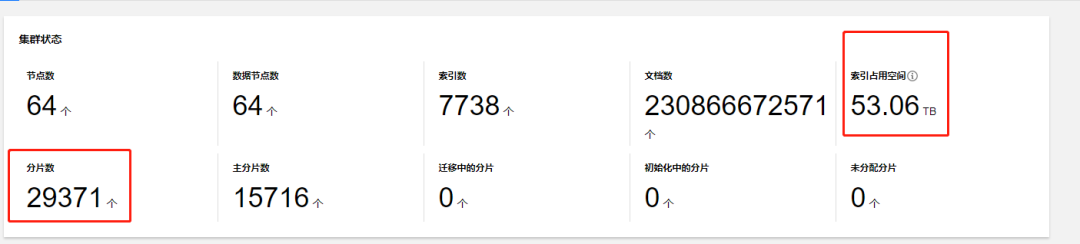
分片数量:7 万 => 3 万,减少了 50%,同时索引存储量优化了 20%。
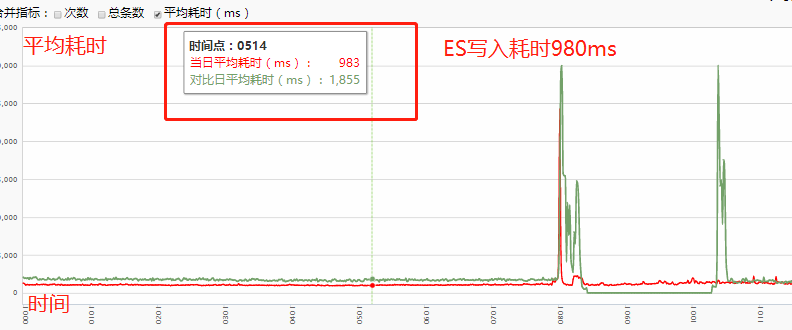
写入耗时:从 2000ms => 900ms 左右。
5. 优化二期
经过一期的优化 ES 写入性能有了明显提升,但还存在一些痛点,包括:
写入延时还是过大,没有达到预期效果。
分片数 3 万+ 还是过多,同时索引创建时间仍然过长(1 分钟)。
索引容量管理以及生命周期管理困难。
6. 优化方案
(1)升级硬件配置
4C16G 升级为 16C 32G, 节点总数由 64 降为 48,开启专用主节点。默认情况下集群中的任何一个节点都有可能被选为主节点,为了确保一个集群的稳定,当节点数比较多时,最好是对生产环境中的节点进行职责划分,分离出主节点和数据节点。
天机阁采用 3(防止脑裂)台低配置的节点作为专用主节点,负责索引的创建、删除、分片分配等工作,数据节点专门用来做数据的索引、查询、更新、聚合等工作。
(2)ES 集群分通道部署
目前天机阁只有一个公共集群,所有业务都在同一个集群中创建索引,这种方式虽然具备了一定的可扩展性。但是随着业务量的进一步增长,集群规模也会逐渐变的巨大,从而容易达到系统的性能瓶颈,无法满足扩展性需要,且当大集群中有索引出现问题时,容易影响到其他业务。
所以我们从业务维度对公共集群进行解耦,按通道做 set 化部署,将不同通道业务,就近路由到不同集群,各集群可按需灵活扩展。
(3)基于 ILM + Rollover + 别名实现索引自动化生命周期管理与容量管理
天机阁是典型的日志型时序索引,根据应用 Appid 按天定时生成索引,索引的生命周期默认为 7 天,其中当天的数据会被频繁写入与查询,第二、三天的数据偶尔被查询,后面几天的数据只有少数重度业务使用者才会查询到。
这样的特性会衍生出来几个问题:
ES 索引分片数一旦创建便无法更改,这种机制无法应对业务忽然放量导致的索引容量激增的问题,通常只能通过手动 Reindex 来解决,而 Reindex 过程也会影响到业务写入性能。
根据日志索引存储具备的特点,不同时间阶段可以重新对分片数、副本数、Segment 进行针对性调整,对冷数据进行归档处理,从而更好的利用机器资源。
需要创建额外的定时任务来删除索引,特别是当集群中索引过多时,密集型的索引删除操作,短时间内也会造成集群的波动。
我们希望构建一个优雅的索引 自动化运维管理系统 ,而这个系统主要解决两个问题:
自动化索引生命周期管理: 创建索引生命周期管理,并定义不同阶段的索引策略,以此来实现 ES 索引自动化优化与生命周期管理而不需要引入第三方服务。
自动化索引容量管理:当集群索引超过设定容量大小时,可以自动进行滚动,生成新的索引,而上游业务不需要感知。
7. 索引自动化管理优化
ES 在索引管理这一块一直在进行迭代优化,诸如 Rollover、日期索引、Curator 等都是对索引管理的一种策略,但是这些方式都不够自动化。
直到 ES6.7 以后,官方推出了 ILM(index lifestyle management)索引生命周期管理策略,能同时控制多个索引的生命流转,配合索引模板、别名、Rollover 能实现自动化索引生命周期与容量的管理闭环。
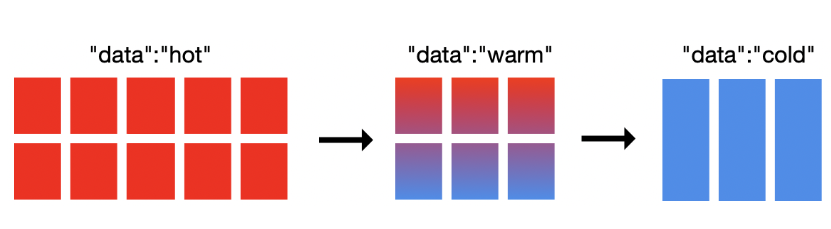

ILM 策略主要有四个阶段:
Hot 阶段:可读,可写,索引会被频繁查询。
Warm:可读,不可写,此时可对数据进行归档,采用 Shrink 与 Forcemerge,减少索引副本与主分片数,并强制进行 Segment 合并,能够减少数据内存与磁盘的使用。
Cold:不可写入,很久没被更新,查询慢。可对索引进行冻结操作,此时集群将对索引进行落盘操作,业务需要指定特定的参数才能查询到数据。
Delete:删除操作。将触发索引删除事件。
8. 天机阁索引管理实践
天机阁使用 ILM 策略配合分级索引模板可以比较优雅的实现索引的自动化管理过程。
ILM 策略主要分为四个阶段:热、温、冷和删除。对于定义好的各个阶段的相应策略,ILM 会始终顺序执行。我们只需要根据索引每个阶段的数据特性定义合适的管理方式,诸如:索引滚动更新用于管理每个索引的大小;强制合并操作可用于优化索引;冻结操作可用于减少集群的存储压力。
天机阁通过 Flink Stream 读取 Kafka 数据实时写入 ES,峰值 QPS 接近 35w,每天新增索引超过 1000+。
在这么大数据量上进行操作是一件很麻烦的事。我们希望 ES 能够自动化对分片超过 100G 的索引进行滚动更新,超过 3 天后的索引进行自动归档,并自动删除 7 天前的索引,同时对外以提供索引别名方式进行读写操作。
这个场景可以通过 ILM 配置来实现,具体策略是:对于一些小于 40G 的索引,在 Warm 阶段执行 Shrink 策略压缩成单分片,并设定写入低峰期执行 Forcemerge 操作合并集群中小的段,Cold 阶段可以执行 Allocate 操作来减少副本数,而针对集群内部 1%的大索引,可以执行 Freeze 操作来释放部分存储空间。具体策略如下表所示:
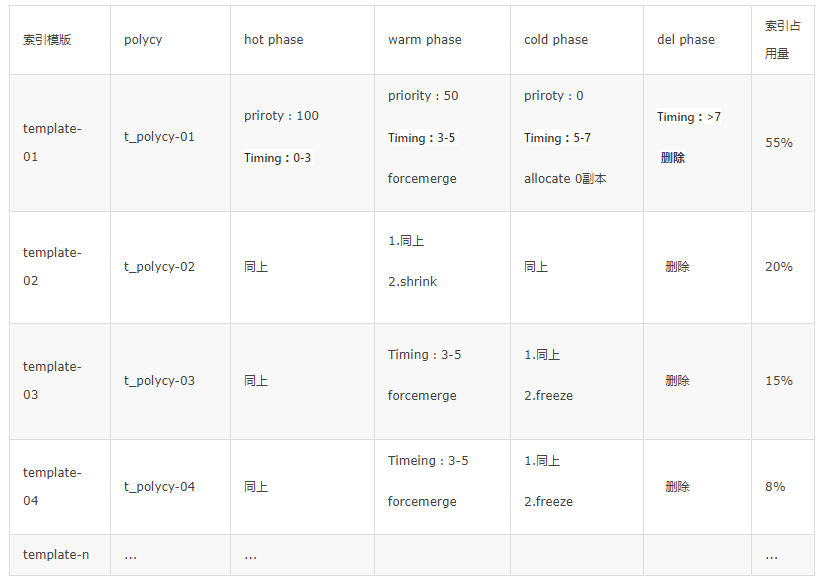
天机阁索引 ILM 策略
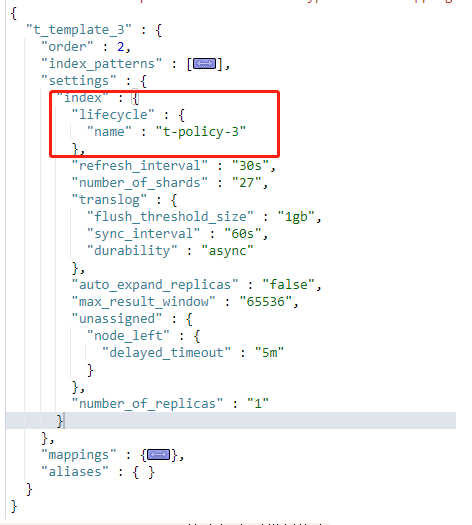
索引模板配置
ILM 可以高效的进行索引生命周期与容量自动化管理,使用起来也很简单。但是还是有不少要注意的地方。
切换策略后索引不会马上生效,旧数据仍然写入旧索引,只有触发 Rollover 生成新索引,新策略才会生效。
每个阶段的生效时间是以 Hot 阶段触发 Rollover 为起始时间的基础上再加业务配置时间。
如果不想使用 Rollover,可以直接进行关闭,也可以实现只对索引进行生命周期的管理操作。
腾讯云 ES 最好采用 白金版 + 6.8 以上版本。
后续优化:ILM + 冷热架构,ILM 可支持为时序索引实现热温冷架构从而节约一些成本。
9. 最终优化效果
写入耗时:2500 万/min 写入量 2000ms - > 320ms。
分片数量:7.2 万 -> 2 万 分片数量减少 70%。
索引存储总量:67T -> 48T 节约存储 30%。
创建索引速度:分钟级 -> 秒级。
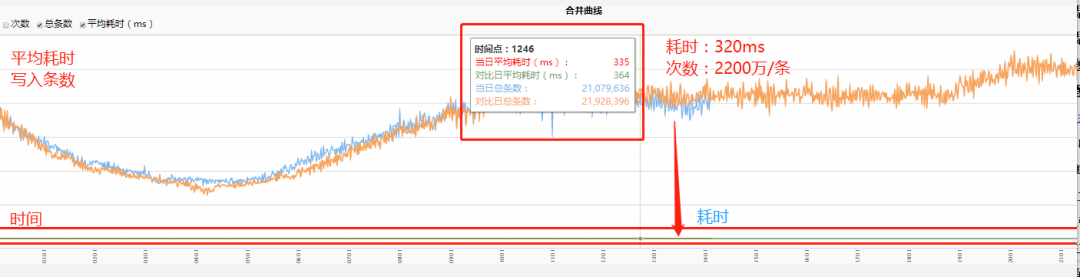
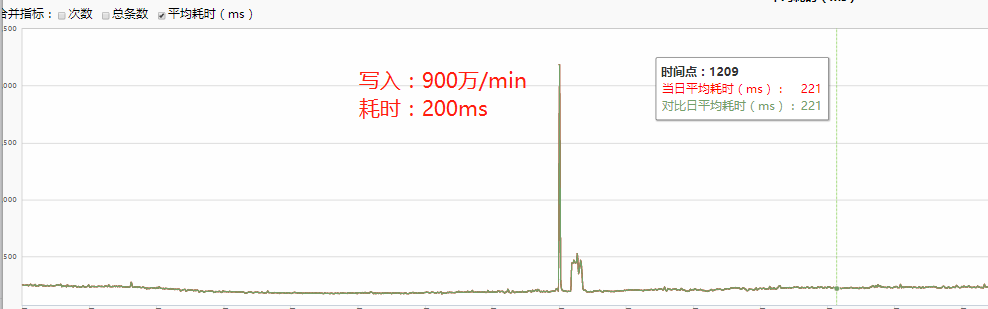

七、优化后整体架构图
Flink 实时计算系统是天机阁链路追踪平台的重要组成部分,数据经过 Flink 窗口进行实时计算聚合最终 sink 到 ES 与 Hbase 等底层存储,而日益增长的数据量给计算集群带来了很大的挑战。
面对这些问题,我们重新梳理了整个链路架构,找到系统的瓶颈所在,并展开了一系列有效的优化措施。而在未来,我们会继续在大数据领域的探索研究工作,更进一步的打磨系统数据处理能力,提供更好的服务。
整体从计算层、存储层、架构、服务质量等几个维度对系统进行了优化,同时也加强了系统的容灾能力
自定义计数器实现热 Key 自动发现与降级。
存储过载保护,当 QPS 超过压测阈值时,触发降级逻辑。
通过 druid 预聚合方式完善对业务的多维监控。
结语
性能是用户体验的基石,而性能优化的最终目标是优化用户体验,俗话说:“天下武功,唯快不破”,这句话放到性能优化上也是适用的。
我们优化 ES, Habse 存储摄入速度,优化 Flink 的处理速度以及接入层的数据采集能力,都是为了保证数据的“快”。而优化的过程则需要我们做好打持久战的准备,既不能过早优化,也不能过度优化。
最好的方式是深入理解业务,了解系统瓶颈所在,建立精细化的的监控平台,当系统出现问题时,我们就可以做到有条不紊,从应用,架构,运维等层面进行优化分析,设定一些期望的性能指标,并对每次优化措施和效果做总结思考,从而形成自己的方法论。
本文转载自公众号云加社区(ID:QcloudCommunity)。
原文链接:




