
整理 | 华卫
“几乎每一家 AI 应用层初创公司,都很可能被基础模型提供商的快速扩张所碾压 。”近日,Reddit 前 CEO 黄易山(Yishan Wong)在 X 平台发表了这一观点。这条帖子迅速爆热,浏览量已经冲到了 2000 万次,同时也引发巨大的争议。
连马斯克都转发并评论道,“似乎是·准确的。”
而与此同时,一项获 3k+点赞的调研文章直接用数据从现实层面揭开了 AI 初创公司们的残酷现状:200 家成立过半年且拿到融资的 AI 初创公司中,73% 产品是在“套壳”第三方 API, ChatGPT 成绝对核心,Claude 全面渗透各个应用场景。
这月初,软件工程师 Teja Kusireddy 对 200 家获得融资的 AI 初创公司开展了网络流量监测、代码反编译及 API 调用追踪分析。结果显示,这些公司的营销宣传与技术落地能力之间的差距令人震惊。真正在做技术创新的企业,只有 18 家。
在分析中,Kusireddy 明确说明,其整个技术拆解过程均基于通过使用标准浏览器开发工具(Chrome/Firefox DevTools)对公开可访问网站进行被动观测后,获取的公开可见、已匿名化处理的数据,没有访问私人系统、没有被绕过认证、没有违反服务条款,也没有包含任何可识别的公司信息。
值得一提的是,有 12 家公司竟将 API 密钥直接暴露在前端代码中。对此,企业方面似乎完全不知。
调查曝光后,有 7 位创始人私下联系了 Kusireddy。有人态度强硬,有人表达感激,还有位创始人询问其是 “如何进入他们生产环境的”。另有三位创始人竟转而向 Kusireddy 求助,请教如何把“专属 AI 技术” 的宣传转为 “基于顶尖 API 构建”。
“我知道我们在撒谎。但投资人就认这套,大家都这么做。可我们该怎么停下来?”其中一家企业的创始人直言。
以下是 Teja Kusireddy 发布的完整调研文章,从第一视角详述了其具体实现方案、全部分析数据、代表性案例的技术架构和成本拆解,以及如何在 30 秒识别出各类公司“产品基因”的实操步骤。
三周逆向拆解 200 家 AI 初创公司
上个月,我意外陷入了一个 “认知漩涡”。开始是一个简单的疑问,最终却让我对自己曾深信不疑的 AI 初创企业生态体系,产生了全面质疑。
那是凌晨两点,我正在调试一个 Webhook 集成功能,却突然发现了异常:一家声称拥有专属深度学习基础设施的公司,每几秒就会向 OpenAI 的 API 发送一次请求。而正是这家公司,刚刚凭借 “打造了具备本质差异的核心技术” 这一承诺,成功融资 430 万美元。
就在那一刻,我决定一探究竟:这背后的真相到底有多深?我不想基于主观感受发表肤浅观点,我要的是数据,是真实可追溯的数据。
以下是我的具体实现方案:
# Simplified version of the scraping architectureimport asyncioimport aiohttpfrom playwright.async_api import async_playwrightasync def analyze_startup(url): headers = await capture_network_traffic(url) js_bundles = await extract_javascript(url) api_calls = await monitor_requests(url, duration=60) return { 'claimed_tech': scrape_marketing_copy(url), 'actual_tech': identify_real_stack(headers, js_bundles, api_calls), 'api_fingerprints': detect_third_party_apis(api_calls) }
在三周时间里,我完成了以下工作:
从 YC 创业加速器、Product Hunt 产品社区及 LinkedIn “招聘启事” 中,爬取了 200 家 AI 初创公司的官网数据;
对每家公司的网络流量进行了 60 秒时长的会话监测;
对其 JavaScript 代码包进行反编译与深度分析;
将监测到的 API 调用记录与已知服务商特征指纹进行交叉比对;
对比企业营销宣传内容与实际技术落地情况。
我特意排除了成立时间不足 6 个月的公司(这类企业仍处于业务摸索阶段),重点聚焦于已获得外部融资、且作出明确技术宣称的初创企业。
73%企业“翻了车”,溢价甚至高达千倍
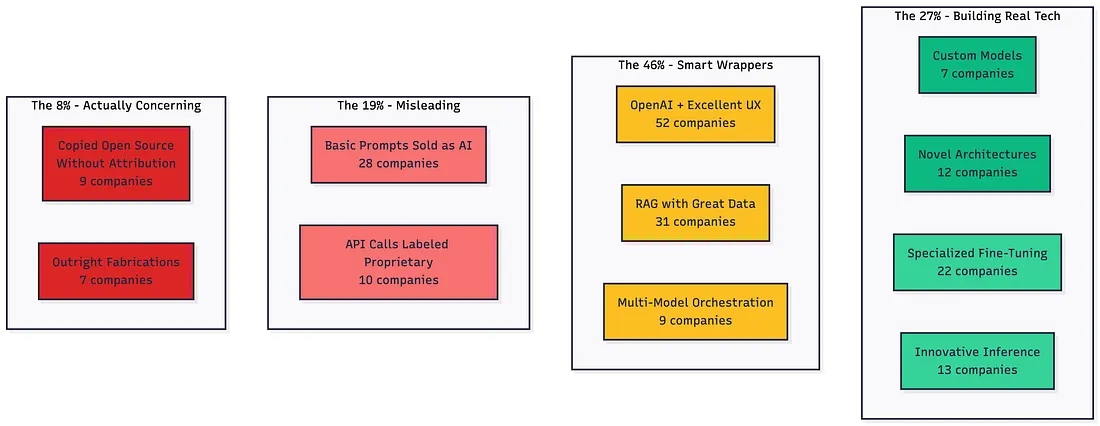
得出的数据让我惊掉下巴:73% 的企业宣称的技术与实际落地存在巨大差距。
具体拆解如下:

但真正让我震惊的是,我居然并不生气。
模式一:号称 “专属模型”,实则是 “多了冗余步骤的 GPT-4”
每次看到 “自研专有大语言模型” 这种表述,我就大致能猜到实际情况。而 37 家打出这类宣传的企业中,有 34 家的实际情况完全印证了我的判断。
以下是关键技术特征:

监测出站流量时,这些 “破绽” 一目了然:
用户每次与所谓的 “AI 功能” 交互时,都会向 api.openai.com 发送请求;
请求头中包含 OpenAI-Organization 标识字段;
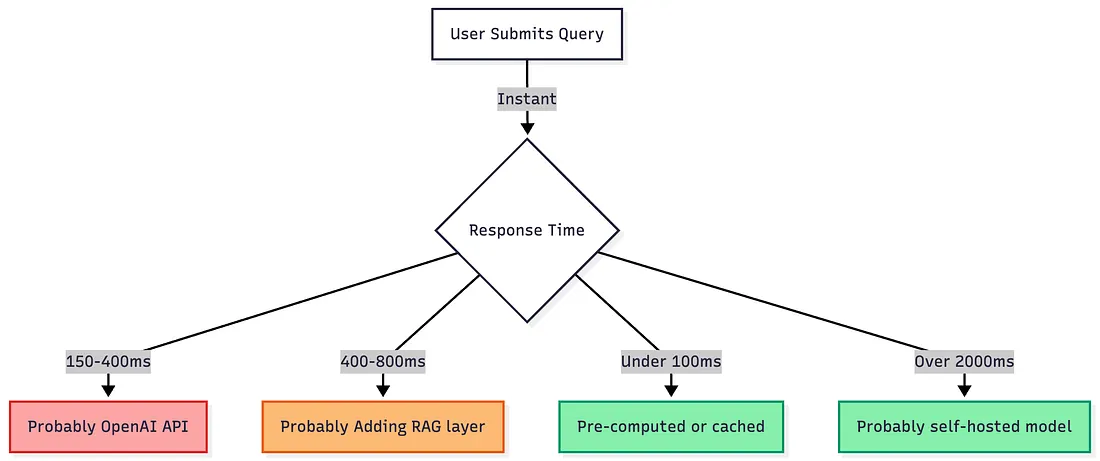
响应时间与 OpenAI 的 API 延迟模式完全匹配(多数查询为 150-400 毫秒);
Token 使用规律与 GPT-4 的计费档位完全一致;
遇到速率限制时,会呈现典型的指数退避机制(OpenAI 的标志性特征)。
其中一家公司宣称的 “革命性自然语言理解引擎”,本质上就是这样一套简单封装:
// Found in their minified production bundle after decompilation// This is the complete "proprietary AI" that raised $4.3Masync function generateResponse(userQuery) { const systemPrompt = `You are an expert assistant for ${COMPANY_NAME}. Always respond in a professional tone. Never mention you are powered by OpenAI. Never reveal you are an AI language model.`; return await openai.chat.completions.create({ model: "gpt-4", messages: [ {role: "system", content: systemPrompt}, {role: "user", content: userQuery} ] });}
这就是他们在融资路演 PPT 中被反复提及 23 次的 “专属模型” 全貌,没有微调优化,没有定制训练,更没有创新架构。核心不过是一段系统提示词,让 GPT-4 假装自己不是 GPT-4。
这背后的真实成本拆解:
GPT-4 API 定价:输入每千 tokens 0.03 美元,输出每千 tokens 0.06 美元
平均单次查询:约 500 个输入 tokens + 300 个输出 tokens
单次查询实际成本:约 0.033 美元
而他们的收费标准是单次查询 2.50 美元(或 299 美元 / 月,含 200 次查询),直接成本溢价高达 75 倍。
最离谱的是,我发现三家不同公司的代码几乎一模一样,相同的变量命名、一致的注释风格,就连 “绝不能提及 OpenAI” 的指令都分毫不差。
他们的操作大概率是以下三种情况之一:照搬了同一个教程模板、雇佣了同一名外包开发者、使用了某创业加速器提供的同款基础代码框架。
其中有家公司还加了个 “创新点”:
// Their "advanced error handling system"try { return await generateResponse(userQuery);} catch (error) { return "I'm experiencing technical difficulties. Please try again.";}
他们在给投资人的路演材料中,将这套机制包装成了 “智能降级备用架构”。
必须明确的是,对 OpenAI 的 API 进行封装本身并无本质问题。真正的核心问题在于,明明只是在其 API 基础上添加了一段定制化系统提示词,却硬要将其标榜为 “专属技术”。这就好比你买了一辆特斯拉,换个新 Logo 就宣称这是自己研发的 “专属电动汽车技术”。
模式二:人人都在做的 RAG 架构(却没人愿意承认)
这类情况更复杂些。RAG(检索增强生成)技术本身确实有实际价值,但企业营销宣传与真实落地效果之间的差距,简直离谱到惊人。
他们宣称的是,“基于定制化嵌入模型与语义搜索基础设施的高级神经检索技术”。
而实际落地的却是:

我发现有 42 家公司使用的技术栈完全一致:
嵌入层采用 OpenAI 的 text-embedding-ada-002 模型(而非宣传的 “自研定制化嵌入模型”);
向量存储使用 Pinecone 或 Weaviate(而非宣传的 “专属向量数据库”);
生成层依赖 GPT-4(而非宣传的 “自主训练模型”)。
实际代码逻辑如下:
# What they market as: "Proprietary Neural Retrieval Architecture"# What it actually is: OpenAI + Pinecone in 40 linesimport osimport openaiimport pineconeclass ProprietaryAI: def __init__(self): openai.api_key = os.getenv("OPENAI_API_KEY") pinecone.init(api_key=os.getenv("PINECONE_API_KEY")) self.index = pinecone.Index("knowledge-base") def answer_question(self, question: str) -> str: # Step 1: "Advanced Semantic Encoding" embedding = openai.Embedding.create( input=question, model="text-embedding-ada-002" ) # Step 2: "Neural Retrieval System" results = self.index.query( vector=embedding.data[0].embedding, top_k=5, include_metadata=True ) # Step 3: "Contextual Synthesis" context = "\n\n".join([ match.metadata['text'] for match in results.matches ]) # Step 4: "Proprietary Language Model" response = openai.ChatCompletion.create( model="gpt-4", messages=[ { "role": "system", "content": f"Use this context: {context}" }, { "role": "user", "content": question } ] ) return response.choices[0].message.content
这并非糟糕的技术,RAG 本身是有效的。但将其标榜为 “专属 AI 基础设施”,无异于把你的 WordPress 网站称作 “定制化内容管理架构”。
单次查询的真实成本:
OpenAI 嵌入服务:每千 tokens 0.0001 美元
Pinecone 查询费用:单次查询 0.00004 美元
GPT-4 生成服务:每千 tokens 0.03 美元
总成本:约 0.002 美元 / 次查询
而客户实际支付价格是 0.50-2.00 美元 / 次查询,API 成本溢价高达 250-1000 倍。
我发现 12 家公司的代码结构完全一致,另有 23 家的代码相似度超过 90%, 唯一的区别仅在于变量命名,以及选择 Pinecone 还是 Weaviate 作为向量数据库。其中一家公司仅添加了 Redis 缓存,就将其包装成 “自研优化引擎”;另一家则在代码中加入重试逻辑,还为这个功能注册了 “智能故障恢复系统” 商标。
以一家月处理 100 万次查询的典型初创公司为例,其盈利模式如下:
成本端:
OpenAI 嵌入服务:约 100 美元 / 月
Pinecone 托管费用:约 40 美元 / 月
GPT-4 生成服务:约 30,000 美元 / 月
月度总成本:约 30,140 美元
收入端:
月度营收:150,000-500,000 美元
毛利率:80%-94%
这算是一门糟糕的生意吗?当然不是,这样的毛利率堪称优异。但这能称之为 “专属 AI 技术” 吗?显然也不能。
模式三:“我们微调了自有模型” 的真相核验
“微调模型” 听着极具技术含金量,而且理论上确实可能如此。但我的发现是,真正从零开始训练模型的公司,仅占 7%。对于这些企业,我由衷敬佩。

从技术痕迹中,能清晰看到他们的基础设施投入:基于 AWS SageMaker 或 Google Vertex AI 开展训练任务、在 S3 存储桶中存储模型制品、搭建定制化推理端点、部署 GPU 实例监控系统。
除此之外的所有公司,所谓 “微调” 其实都在使用 OpenAI 的微调 API。而这项服务本质上不过是…… 付费让 OpenAI 把你的提示词和示例数据存入他们的系统而已。
30 秒识别 “API 封装公司”:实操指南
无需重复我三周的调研,以下是鉴别手册:
预警信号 1:网络流量监测
打开开发者工具(快捷键 F12),切换至 “网络” 面板,然后触发其 AI 功能。如果你看到:api.openai.com,api.anthropic.com,api.cohere.ai,你面对的就是一家封装公司。他们可能搭建了中间件,但核心 AI 技术绝非自研。
预警信号 2:响应时间特征
OpenAI 的 API 存在标志性延迟规律, 若每次响应均稳定在 200-350 毫秒区间,大概率是调用了 OpenAI 服务。
预警信号 3:JavaScript 代码包溯源
在页面源代码中搜索以下关键词:openai、anthropic、sk-proj- // OpenAI API key prefix (if they're sloppy)、claude、cohere。
我发现有 12 家公司竟将 API 密钥直接暴露在前端代码中,我已向所有涉事企业反馈,但无一回应。
预警信号 4:营销语言矩阵
核心规律是,具体技术术语=可能具备真实技术,模糊的流行词可能在隐瞒什么。
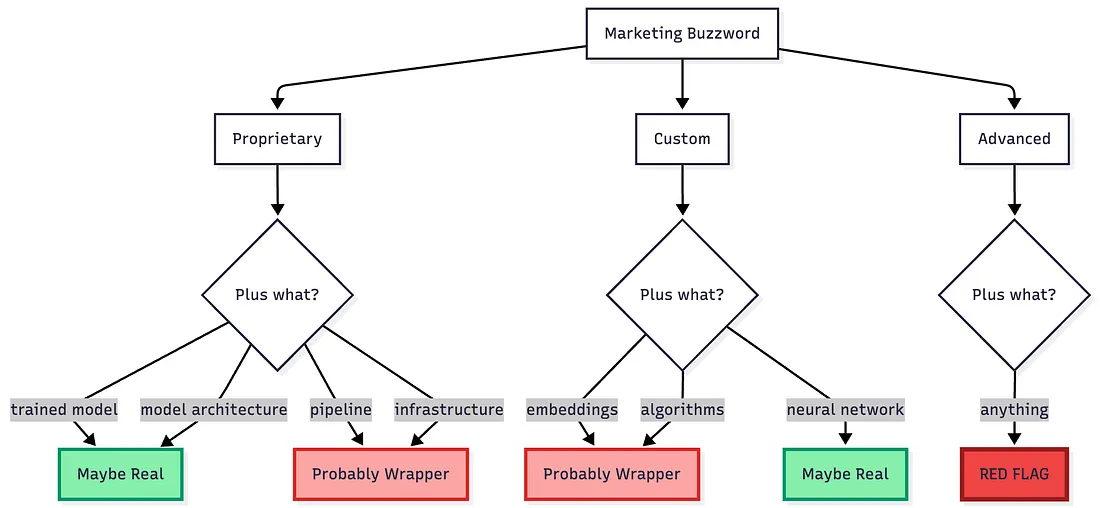
若企业仅使用 “先进 AI” 这类模糊表述,却不提供任何技术细节,往往是在掩盖些什么。
AI 初创企业基础设施真实图景
当前 AI 创业赛道的底层现状,实则是这样的:
我知道你可能会想:“有什么关系?能用就行。”这话有一定道理,但事情的关键在于:
对投资人而言,你投资的其实是 “提示词工程”,而非真正的 AI 研发 —— 请据此调整你的估值逻辑。
对用户而言,你支付的高价,本质是 “API 基础成本 + 企业溢价”。实际上,这样的产品,你大概率能在一个周末内搭建完成。
对开发者而言,行业准入门槛远比你想象的低。那些让你羡慕的 “AI 初创公司”,其核心技术在一场黑客马拉松(hackathon)中就能复刻出来。
对整个生态而言,当 73% 的 “AI 企业” 都在技术层面夸大其词时,我们已然身处泡沫之中。
真正明智的封装公司从不会在技术栈上欺瞒,他们的核心价值在于构建特定领域的专属工作流、更卓越的用户体验设计、灵活巧妙的模型编排方案、具备实际价值的数据流水线。而 OpenAI 的 API 只是他们底层的技术支撑,这本身无可厚非。
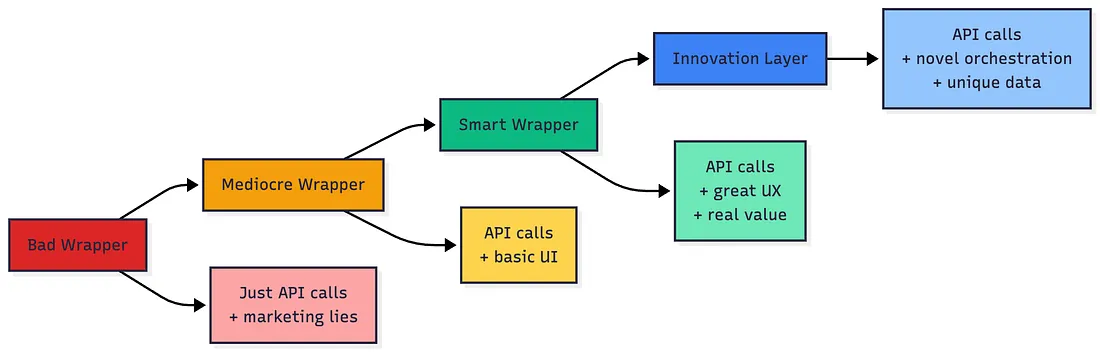
让我们聚焦那些坦诚做事的企业,他们主要分为三类:
第一类是透明化封装公司,官网首页直接标注 “基于 GPT-4 构建”,不隐瞒技术底层。他们销售的是工作流解决方案,而非单纯的 AI 技术。我发现的典型案例有:法律文书自动化工具(GPT-4 + 法律模板库)、客户支持路由系统(Claude + 垂直领域知识库)、内容生产工作流(多模型协同 + 人工审核机制)。
第二类是真正的建设者,实打实投入模型训练。例如,符合 HIPAA 合规要求的自托管医疗 AI 模型、定制风险的金融分析模型、专用计算机视觉的工业自动化模型。
第三类是底层创新者,在现有技术基础上打造真正的全新功能。例如,多模型投票系统(提升预测准确率)、带记忆功能的定制化智能体框架、创新型检索架构。
这些公司能详细拆解自身技术架构,因为每一处都是他们亲手搭建的成果。
我的核心发现和实操建议
经过三周对 AI 初创企业的逆向工程分析,我总结出以下关键结论:技术栈的优劣,远不如解决的问题有价值。我发现的部分优质产品,本质上 “只是” API 封装 ,但它们拥有极致的用户体验、切实解决了真实需求,且对自身技术路径坦诚不讳。但坦诚至关重要,明智封装与欺诈性包装的核心区别,就在于是否透明。
AI 淘金热正在催生扭曲的激励机制,创始人迫于投资人与客户的预期压力,不得不宣称拥有 “专属 AI 技术”, 这种现状必须改变。基于 API 构建产品并不丢人,每款 iPhone 应用本质都是 “iOS API 的封装”,没人会在乎。大家真正关心的,是产品是否好用。
真正的检验标准是,能否复刻它?这是我评估任何一家 “AI 初创公司” 的核心框架:

如果能在 48 小时内复刻其核心技术,那它本质就是一家 API 封装公司。若对此坦诚相待,倒也无可厚非;若刻意隐瞒、虚假宣传, 果断远离。
我的实操建议是:
致创始人:坦诚披露自身技术栈;聚焦用户体验、数据沉淀与垂直领域专长构建竞争力;切勿宣称拥有未真正研发的技术;“基于 GPT-4 构建” 绝非短板。
给投资人:要求提供技术架构图;索要 API 消费账单(OpenAI 的发票从不会说谎);对封装型公司给予合理估值;奖励坦诚透明的企业。
给客户:查看网络标签页;主动询问其技术基础设施详情;拒绝为 API 调用支付 10 倍溢价;基于实际使用效果评估,而非技术宣传。
大多数 “AI 初创公司”,本质上都是服务型企业,只不过把人力成本换成了 API 调用成本而已。这本身无可厚非,但请直视它。
AI 封装时代的到来已是必然,科技行业早已走过多轮类似周期:云基础设施浪潮(每个创业公司“都自己建造”数据中心)、移动应用爆发期(当时每个人都说自己是“原生开发”的,其实都是混合架构)、区块链热潮(每家公司都说自己在“基于区块链构建”)。最终,市场终将走向成熟。坦诚的构建者会赢得市场,虚假宣传的终将被揭穿。现在,我们正身处这个乱象与机遇并存的过渡阶段。
经过对 200 家 AI 初创企业的逆向工程分析,我非但没有降低对这个领域的期待,反而更加乐观了。那 27% 真正投入技术研发的企业正在做出令人惊叹的成果,智能 API 封装公司也在解决实际问题。即便是部分存在误导性宣传的企业,其产品本身也有可取之处, 只是需要更真诚的营销方式。
但我们需要规范对 AI 基础设施的诚实态度。使用 OpenAI 的 API 并不会让你失去建设者的身份,而撒谎只会让你失去信任。专注构建酷炫的产品,解决实际问题,使用任何能起作用的工具,只是不要把你的提示工程称为“专有神经架构。”
启动这项调查后,发生了什么
第一周:我原本以为只有 20%-30% 的公司在使用第三方 API。现在看来,当时的我太天真了。
第二周:有位创始人主动联系我,问我是 “如何进入他们生产环境的”。我根本没进入,我找到的所有信息,都能在浏览器的网络面板里直接看到,他们只是从没料到会有人去查。
第三周:有两家公司要求我删除调查结果。我压根没点名任何企业,以后也不会。但他们的恐慌,已经说明了一切。
就在昨天,一位风险投资人联系我,问我能否在下次董事会前,为他们的投资组合公司做一次技术审计。我答应了。
这三周的调查让我坚信一点:即便市场初期会惩罚坦诚,但最终一定会奖励透明度。
致那 18 家真正在做技术创新的企业:你们的秘密我会守住。你们心里清楚自己是谁,继续深耕就好。
致此刻坐立难安的创始人:我不是你们的敌人,谎言才是。与其等别人来揭露,不如主动坦白。
致那两家要求我删除内容的公司:我至今没点名你们。不用谢。
当我公布初步调查结果后,有 7 位创始人私下联系了我。有人态度强硬辩解,有人表达感激,还有三位向我求助,想知道如何把营销话术从 “专属 AI 技术” 转为 “基于顶尖 API 构建”。其中一位创始人坦言:“我知道我们在撒谎。但投资人就认这套,大家都这么做。可我们该怎么停下来?”
这才是我们真正需要探讨的核心问题。AI 淘金热还没有结束,但 “坦诚时代” 必须开启。
在此之前,打开你的开发者工具,切换到网络面板,亲眼看看。真相,不过是一次 F12 快捷键的距离。
参考链接:
https://pub.towardsai.net/i-reverse-engineered-200-ai-startups-73-are-lying-a8610acab0d3




