

也许每一个还在追求模型效率与性能的算法工程师,都应该开始考虑将设计公平性引入自己的工作当中。事实上,在国内已经有了一个专有名词来形容这一现象 “大数据杀熟”。近几年,机器学习的公平性广泛地引起了科研与开发人员的关注。简单而言,由于不同的社会环境,导致同样的算法,预测结果可能出现较大差异。为解决公平性这一问题,日前,Google AI 推出了 ML-fairness-gym。
随着人工智能技术的发展,越来越多的机器学习系统被应用于帮助人们进行高影响力的决策,例如确定刑事判决、儿童福利评估、医疗资源分配以及许多其他案例。了解这类系统是否具备公平性至关重要,并且还需要了解模型的短期和长期影响。评估机器学习系统的公平性的常用方法,涉及评估静态数据集上针对系统的各种输入的误差度量的差异。事实上,许多现有的机器学习公平性工具包(例如 AIF360、fairlearn、faimess-indicators、fairness-comparison)都提供了分析工具,可以在现有数据集上执行这种基于误差度量的分析。虽然这类分析可能适用于简单环境中的系统,但在某些情况下(例如,具有动态数据收集或重要反馈循环的系统),算法运行的上下文对于理解其影响,就显得至关重要。在这些情况下,与基于误差度量的技术相比,理想情况下的分析算法决策的公平性,更应考虑环境和时间上下文的因素。
为了在这种更为广泛的背景下促进算法的开发,我们发布了 ML-fairness-gym,这是一套用于构建简单模拟的组件,探索在社会环境中部署基于机器学习的决策系统可能带来的长期影响。在论文《公平性并非静态:通过模拟研究加深对长期公平性的理解》(Fairness is not Static: Deeper Understanding of Long Term Fairness via Simulation Studies)中,对于自动化决策系统对当前机器学习公平性的学术文献中一些既定的长期影响,我们演示了如何使用 ML-fairness-gym 来对这些影响进行研究。
示例:贷款问题
机器学习系统中公平性的经典问题之一是贷款问题,正如 Liu 等人在论文描述的那样。这个问题是放贷过程的高度简化和程式化的表示,我们将重点放在单个反馈循环上,以孤立其影响,并对其进行详细的研究。在这个问题的表述中,个人申请者偿还贷款的概率是他们信用评分的函数。这些申请者也属于任意数量的组之一,他们的组成员资格可由贷款银行观察到。
最有效的阈值设置将取决于银行的目标。一家银行,为了追求利润最大化,银行可以根据申请者偿还贷款的可能性进行评估,设定一个使预期奖励最大化的阈值。另一家银行,力求对两个组都公平,可能会设法设置利润最大化的阈值,同时满足机会均等的要求,其目标是获得相同的真阳率(true positive rates,TPR,也称为召回率或敏感度;衡量本应偿还贷款的申请者中有多少人获得贷款)。在这种场景中,银行利用机器学习技术,根据已发放的贷款及其结果来确定最有效的阈值。然而,由于这些技术通常侧重于短期目标,它们可能会对不同的组产生意想不到的、不公平的后果。
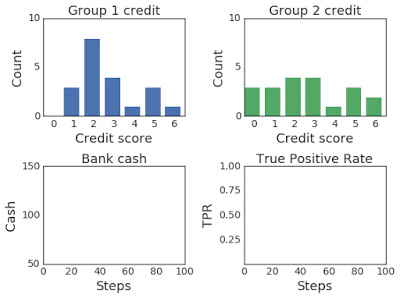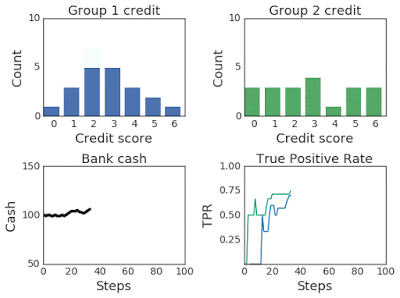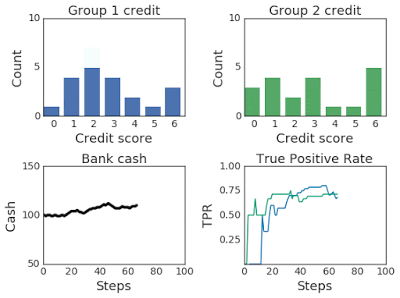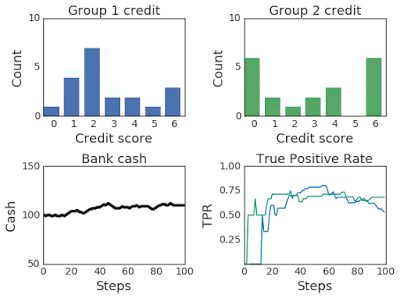
上图:在 100 个模拟步骤中改变两组的信用评分分布。下图:左图为银行现金,右图为真阳率,在模拟过程中,第一组为蓝色,第二组为绿色。
静态数据分析的不足之处
在机器学习中,评估像贷款问题这样场景的影响,有一个标准实践做法是:保留一部分数据作为“测试集”,并使用它来计算相关的性能度量。然后,通过观察这些性能度量,在不同显著组之间的差异来评估公平性。然而,我们很清楚这一点:在有反馈的系统中使用这样的测试集,存在两个主要问题。如果测试集是由现有系统生成的,那么它们可能是不完整的,或者反映了这些系统固有的偏见。在贷款这一例子中,测试集有可能是不完整的,因为它可能只有已获得贷款的申请者是否拖欠或偿还的信息。因此,这一数据集可能不包括贷款尚未获批或以前未获得贷款的个人。
第二个问题是,由机器学习系统的输出所通知的行为可能会影响它们未来的输入。机器学习系统确定的阈值用于发放贷款。人们是否拖欠或偿还这些贷款,都会影响他们未来的信用评分,然后将其反馈到机器学习系统中。
这些问题凸显了在静态数据集中评估公平性的缺点,并激发了在部署算法的动态系统的情况下分析算法公平性的需求。我们创建了 ML-fairness-gym 框架,以帮助机器学习从业者将基于模拟的分析引入到他们的机器学习系统中,这种方法在许多领域中被证明是有效的,可用于分析难以进行封闭式分析的动态系统。
ML-fairness-gym :可长期分析的模拟工具
ML-fairness-gym 使用 Open AI 的 Gym 框架模拟序贯决策。在这个框架中,智能体以循环的方式与模拟环境进行交互。在每个步骤中,智能体都会选择一个动作,然后影响环境的状态。然后,环境会显示一个观察结果,智能体会使用这个观察结果来告知其随后的动作。在这个框架中,环境对问题的系统和动态进行建模,观察结果作为数据提供给智能体,而智能体可以被编码为机器学习系统。
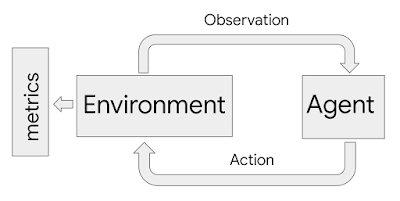
模拟框架中使用的智能体 - 环境交互循环流程示意图。智能体通过选择的动作来影响环境。环境会随着动作的的变化而变化,并作为观察的结果产生部分内在状态。度量标准检查环境的历史以评估结果
在贷款的例子中,银行充当智能体的角色。它以观察环境的形式接收贷款申请者、他们的信用评分和他们的组成员资格,并以二元决策的形式采取动作来接收或拒绝贷款请求。然后,环境对申请者是否成功还款或拖欠进行建模,并相应地调整他们的信用评分。ML-fairness-gym 模拟结果,以便评估银行政策对申请者组公平性的长期影响。
公平性并非静态:将分析延伸到长期
自从 Liu 等人最初提出贷款问题以来,他们只考察了银行政策的短期后果:包括短期利润最大化政策(称为最大奖励智能体)和受机会均等(Equality of Opportunity,EO)等约束的政策——我们使用 ML-fairness-gym 通过模拟将分析延伸到长期(许多步骤)。
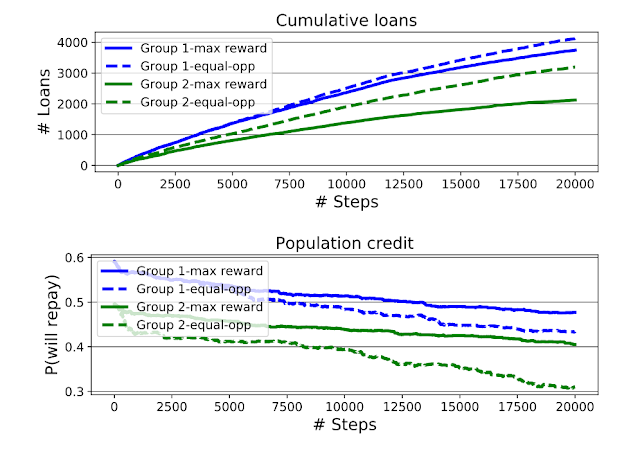
上图:最大奖励和机会均等的智能体批准的累积贷款,按申请者的组身份划分。下图:随着模拟的进展,组平均信用评分(以组条件还款概率量化)。机会均等智能体增加了第二组的贷款机会,但也扩大了两组之间的信用差距
我们的长期分析发现了两个结果。首先,正如 Liu 等人所发现的那样,机会均等智能体(EO agent)与弱势群体(即第二组,最初的平均信用评分较低)存在重叠,因为有时候对该组应用的阈值要低于最大奖励智能体所应用的阈值。这导致第二组的信用评分比第一组下降更多,导致两组之间的信用评分差距比使用最高奖励智能体的模拟更大。然而,我们的分析还发现,虽然使用机会均等智能体似乎会使第二组的情况更糟,但从累积贷款图中可以看出,处于弱势的第二组从机会均等智能体那里获得的贷款明显更多。根据福利指标是信用评分还是收到的贷款总额,可以认为,机会均等智能体比最大奖励智能体更好或更有害于第二组。
第二个发现是,在模拟过程中机会均等的约束,即在每个步骤中在群体之间实施均衡的真阳率,并不能使总体上的真阳率均衡。这个或许有违直觉的结果,可以被认为是辛普森悖论(Simpson’s paradox)的一个例子。如下表所示,两年中每一年的真阳率相等并不意味着总体上真阳率相等。这表明,当潜在人群不断发展时,机会均等度量标准是如何难以解释的,并建议需要更仔细的分析,以确保机器学习系统具有预期的效果。
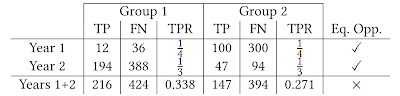
辛普森悖论的一个例子。TP 为真阳性分类,FN 为假阴性分类,TPR 为真阳率。在第 1 年和第 2 年,贷款人采用的政策是在两个组之间实现同等的真阳率。这两年的总和并不具有相等的真阳率
总结与今后工作
在本文中,我们集中讨论了关于贷款问题的发现,而 ML-fairness-gym 可以用来解决各种各样的公平性问题。我们的论文扩展了先前在学术界关于机器学习公平性的文献中已经研究过的另外两个场景的分析。ML-fairness-gym 框架也足够灵活,可以模拟和探索“公平性”研究不足的问题。例如,在一篇题为《社会网络中的公平治疗分配》(Fair treatment allocations in social networks)的支持性论文中,我们探索了流行病控制的程式化版本,我们称之为精确疾病控制问题,以更好地理解社会网络中个人和社区之间的公平概念。
我们对 ML-fairness-gym 的潜力感到振奋,因为它可以帮助其他研究人员和机器学习开发者更好地理解机器学习算法对我们社会的影响,并为开发更负责任、更公平的机器学习系统提供信息。你可以在 ML-fairness-gym 的 GitHub 仓库中找到代码和论文。
作者介绍:
Hansa Srinivasan,Google Research 软件工程师。
原文链接:
https://ai.googleblog.com/2020/02/ml-fairness-gym-tool-for-exploring-long.html
公众号推荐:
跳进 AI 的奇妙世界,一起探索未来工作的新风貌!想要深入了解 AI 如何成为产业创新的新引擎?好奇哪些城市正成为 AI 人才的新磁场?《中国生成式 AI 开发者洞察 2024》由 InfoQ 研究中心精心打造,为你深度解锁生成式 AI 领域的最新开发者动态。无论你是资深研发者,还是对生成式 AI 充满好奇的新手,这份报告都是你不可错过的知识宝典。欢迎大家扫码关注「AI前线」公众号,回复「开发者洞察」领取。


InfoQ 主编

分布式云行业实践指南(2023)
业内首个分布式云行业实践方法论、工具箱。







评论