
提供机器学习解决方案远不止仅提供模型那么简单。机器学习运维 (MLOps) 的基础理论可以帮助数据科学团队更快、更有信心地交付模型,其涉及版本控制、测试和流水线这三个关键概念。
MLOps(https://ml-ops.org/)是指机器学习运维。这是一种旨在使机器学习在生产中高效、流畅的实践。尽管 MLOps 这个术语相对比较新,但我们可以将它与 DevOps 做个类比,它不是一项单独的技术,而是对如何正确做事的共同理解。
MLOps 引入的共享原则(https://valohai.com/mlops/)鼓励数据科学家将机器学习视为一个持续的过程,开发、运行和维持机器学习能力,供现实世界使用,而不是与世隔绝的科学实验。
机器学习应该是协作的、可重复的、持续的,以及经过测试的。
MLOps 的实际实现包括采用某些最佳实践和为支持这些最佳实践搭建的基础设施。让我们来看一下,MLOps 改变机器学习如何开发的三种方式:它对版本控制的影响,如何构建保障措施,以及关注机器学习流水线的必要性。
1. 版本控制不仅仅适用于代码
一谈到在组织内利用机器学习,就应该最先考虑版本控制。然而,这个理念并不仅仅适用于驱动模型的代码。
机器学习版本控制应该涉及在训练算法时使用的代码、底层数据和参数。这个过程对于确保可伸缩性和再现性(https://www.wired.com/story/artificial-intelligence-confronts-reproducibility-crisis/)至关重要。
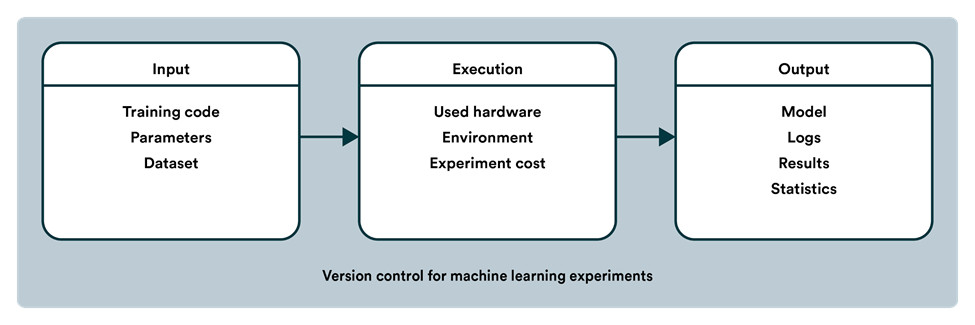
ML 的版本控制并不像传统软件那样只局限于代码。可以从建立再现性检查表(https://www.cs.mcgill.ca/~jpineau/ReproducibilityChecklist.pdf)开始,它是一个很好的起点,有助于你了解你的 MLOps 配置应该能够把哪些内容记录下来。
首先,让我们来讨论一下代码中的版本控制,因为大多数数据科学家都对它很熟悉。无论是用于系统集成的实现代码,还是允许你开发机器学习算法的建模代码,所做的任何变更都应该有明确的文档记录。例如,应用 Git 通常能够充分满足这一领域的需要。
还应该针对用于训练模型的数据进行版本控制。场景和用户在不断变化和调整,因此你的数据也不会一成不变。这种持续的变化意味着我们必须对模型进行一遍又一遍的重新训练,并验证它们对于新数据仍然是准确的。因此,需要适当地进行版本控制以维持再现性。
不仅我们用来构建模型的数据在演变,元数据也在演变。元数据指的是所收集的关于底层数据和模型训练的信息——它告诉我们如何进行模型训练过程。是否按预期使用了数据?这个模型达到了什么样的精度?
即使底层数据没有变化,元数据也可以改变。元数据需要严格的版本控制,因为你希望以后训练模型的时候有一个基准。
最后,必须对模型本身进行适当的版本控制。作为一名数据科学家,你的目标是不断提高机器学习模型的准确性和可靠性,因此进化算法需要有自己的版本控制。这通常被称为模型注册表。
MLOps 实践建议将上面提到的针对所有组件进行版本控制作为一种标准实践,而且在大多数 MLOps 平台上都很容易实现这一点。通过适当的版本控制,你可以确保任何时候都具有可再现性,这对于治理和知识共享是至关重要的。
2. 在代码中构建保障措施
当涉及到在机器学习过程中构建保障措施时,应该让它们出现在代码中,而不仅仅是停留在你的大脑里!
尽量避免手工或不一致的流程。所有收集数据、数据测试和模型部署的过程都应该写入代码,而不是过程文档,这样你就可以确信模型的每一次迭代都将遵循所需的标准。例如,训练机器学习模型的方式非常重要。因此,训练模型的任何微小变化都可能导致该模型的预测出现问题和不一致性。鉴于这种风险,所以极有必要将这些保障措施直接构建到代码中。
数据测试通常会以一种专门的方式进行,但它应该予以程序实现。应该在机器学习流水线中编写代码,以保证训练数据应该是什么样的 (训练前测试) 和训练模型应该如何执行 (训练后测试)(https://www.jeremyjordan.me/testing-ml/)。这包括为预期的预测设置参数,这样你就可以放宽心了,因为生产模型遵循你设定的所有规则。实现 MLOps 平台的伟大之处在于,所有这些步骤都是自动编写和可重用的——至少代码是自动编写的。这些保障措施很容易就可以用于其他机器学习用例,并且可以应用相同的标准,例如模型精度。
3. 流水线是产品,而不是模型
应该认识到的第三个 MLOps 概念是,机器学习流水线是产品,而不是模型本身。这种实现通常表现为成熟度模型的特征,在该模型中,组织从手动流程转变为自动化流水线。(https://cloud.google.com/solutions/machine-learning/mlops-continuous-delivery-and-automation-pipelines-in-machine-learning)
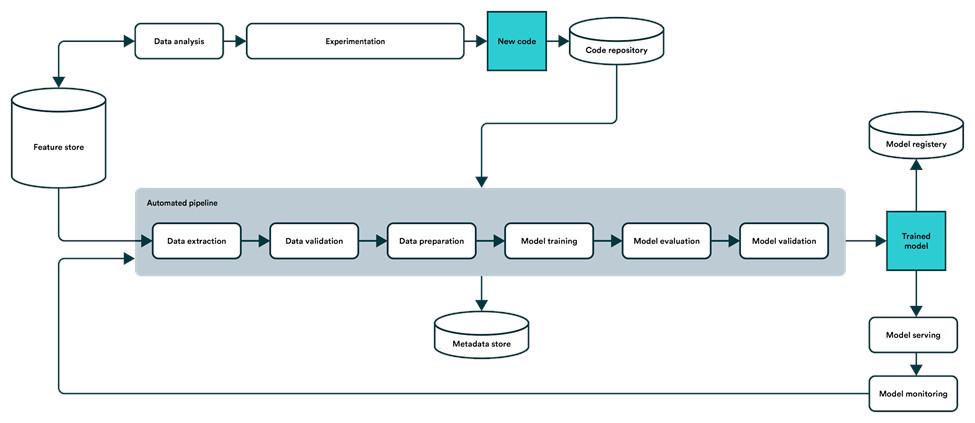
机器学习流水线(https://valohai.com/machine-learning-pipeline/)的最终目标是实现自修复的机器学习系统。
机器学习模型对于克服业务挑战和满足组织的即时需求非常重要。然而,有必要承认模型只是暂时的,不像产出它的系统(https://www.analyticsinsight.net/forget-the-models-you-need-a-machine-learning-pipeline/)。
支持模型的底层数据会迅速变化,模型也会漂移。这意味着最终,将不得不重新训练和调整模型,以在新的环境中提供准确的结果。因此,产生准确有效的机器学习模型的流水线应该是数据科学家关注的焦点。那么,到底什么是机器学习流水线呢?
如果没有 mlop 和建立的机器学习流水线,更新模型将即耗时又很困难。流水线消除了这个问题,而不是临时完成这些任务,只在出现问题时解决问题。它为模型更新和变更提供了一个清晰的框架和管理。
机器学习流程包括收集和预处理数据、训练机器学习模型、将其投入生产,以及在准确率下降时对它持续监控以重新启动训练。一个构建良好的流水线可以帮助你在整个组织中扩展此流程,以便你可以最大化地使用生产模型,并确保这些功能始终符合标准。
开发的机器学习流水线还允许你控制如何在业务中实现和使用模型。它还可以改善部门间的沟通,使其他人能够评审流水线 (而不是手工工作流),以确定是否需要进行更改。同样,它减少了生产瓶颈,并允许你最大限度地利用数据科学能力。
总之,每个人都应该理解这三个基本的 MLOps 概念:
在整个机器学习过程中,版本控制是必不可少的。这不仅涉及代码,还涉及数据、参数和元数据。
应该建立自动工作的保障措施——不要依赖人工或不一致的过程,从而使机器学习模型的结果存在风险。
最后一点,流水线是产品,而不是机器学习模型。一条成熟的流水线是长期支持生产机器学习的唯一途径。
作者简介:
Henrik Skogstrom(http://www.valohai.com/)带头采用了 Valohai MLOps(https://valohai.com/mlops/)平台,并就生产中机器学习的最佳实践撰写了大量相关文章。在加入 Valohai 之前,亨里克曾在 Quest Analytics 担任产品经理,致力于改善美国的医疗保健普及性。Valohai 成立于 2017 年,是 MLOps 的先驱,帮助 Twitter、乐高集团 (LEGO Group) 和 JFrog 等公司更快地将模型投入生产。
参考资料:
MLOps——“为什么需要它?”和“它是什么?”(https://www.kdnuggets.com/2020/12/mlops-why-required-what-is.html)
数据科学与 Devops: MLOps 与 Jupyter、Git 和 Kubernetes(https://www.kdnuggets.com/2020/08/data-science-meets-devops-mlops-jupyter-git-kubernetes.html)
端到端机器学习平台之旅(https://www.kdnuggets.com/2020/07/tour-end-to-end-machine-learning-platforms.html)
原文链接:
译者简介:冬雨,小小技术宅一枚,从事研发过程改进及质量改进方面的工作,关注编程、软件工程、敏捷、DevOps、云计算等领域,非常乐意将国外新鲜的 IT 资讯和深度技术文章翻译分享给大家,已翻译出版《深入敏捷测试》、《持续交付实战》。




