

本文由 dbaplus 社群授权转载。
业务背景
随着公司规模越来越大,业务线越来越多,公司的指标规模也在急速增长,现有的基于 storm 实时计算的指标计算架构的缺点越来越凸显,所以我们急需对现有的架构进行调整。
1、基于 storm 的指标平台存在的问题
指标口径不够直观
数据无法回溯
稳定性不够
2、什么是我们需要的?
我们需要一个稳定的、基于 SQL、方便进行数据回溯、并且要足够快速的引擎,支持我们的实时指标平台。
1)稳定性 是最主要的,基于 storm 的架构数据都是存储在内存中的,如果指标配置有问题,很容易导致 OOM,需要清理全部的数据才能够恢复。
2)基于 SQL 是避免像 storm 架构下离线 SQL 到 storm topology 转换的尴尬经历。
3)方便回溯 是数据出现问题以后,我们可以简单的从新刷一下就可以恢复正常,在 storm 架构下有些场景无法完成。
4)快速 那是必须的,指标数越来越多,如果不能再 5 分钟周期内完成所有的指标计算是不能接受的。
clickhouse
1、为什么选择 clickhouse?
足够快,在选择 clickhouse 以前我们也有调研过 presto、druid 等方案,presto 的速度不够快,无法在 5 分钟内完成这么多次的查询。
druid 的预计算挺好的,但是维度固定,我们的指标的维度下钻都是很灵活的,并且 druid 的角色太多维护成本也太高,所以也被 pass 了。
最终我们选择了 clickhouse,在我们使用之前,部门内部其实已经有使用单机版对离线数据的查询进行加速了,所以选择 clickhouse 也算是顺理成章。
2、clickhouse 和 presto 查询速度比较
clickhouse 集群现状:32 核 128G 内存机器 60 台,使用 ReplicatedMergeTree 引擎,每个 shard 有两个 replica。
presto 集群的现状:32 核 128G 内存机器 100 台。
1)最简单的 count()的 case
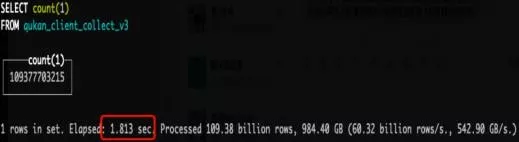
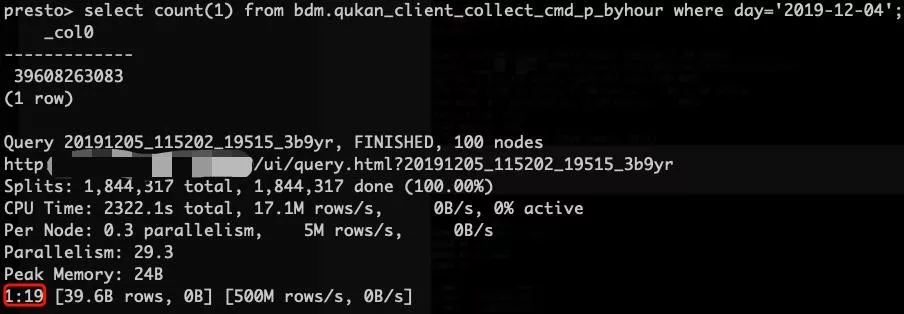
从上图可以看到 clickhouse 在 count 一个 1100 亿数据表只需要 2s 不到的时间, 由于数据冗余存储的关系,clickhouse 实际响应该次查询的机器数只有 30 台(60 / 2),presto 在 count 一个 400 亿的数据表耗时 80 秒左右的时候,100 台机器同时在处理这个 count 的查询。
2)常规指标维度下钻计算 count() + group by + order by + limit

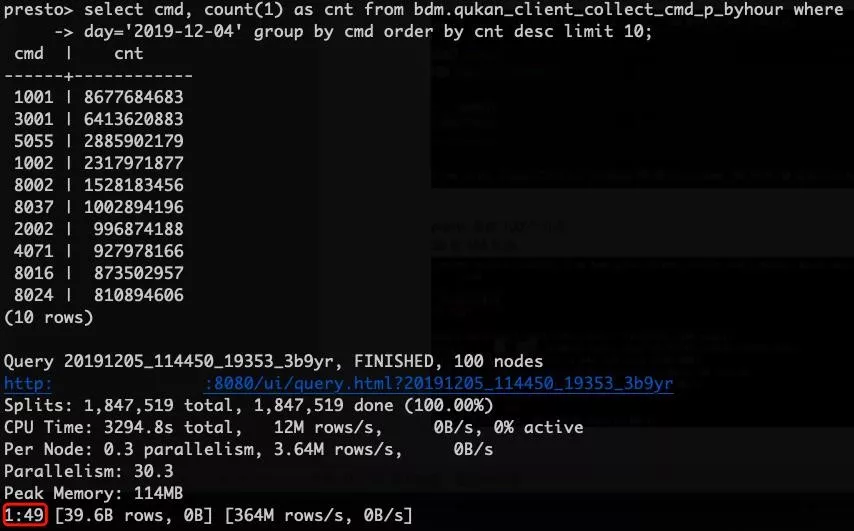
同样在 1100 亿数据表中 clickhouse 在该 case 上面的执行时间也是非常不错的耗时 5s 左右,presto 在 400 亿的数据集上完成该查询需要 100s 左右的时间。
从上面两个常规的 case 的执行时间我们可以看出,clickhouse 的查询速度比 presto 的查询速度还是要快非常多的。
3、clickhouse 为什么如此快
1)优秀的代码,对性能的极致追求
clickhouse 是 CPP 编写的,代码中大量使用了 CPP 最新的特性来对查询进行加速。
2)优秀的执行引擎以及存储引擎
clickhouse 是基于列式存储的,使用了向量化的执行引擎,利用 SIMD 指令进行处理加速,同时使用 LLVM 加快函数编译执行,当然了 Presto 也大量的使用了这样的特性。
3)稀疏索引
相比于传统基于 HDFS 的 OLAP 引擎,clickhouse 不仅有基于分区的过滤,还有基于列级别的稀疏索引,这样在进行条件查询的时候可以过滤到很多不需要扫描的块,这样对提升查询速度是很有帮助的。
4)存储执行耦合
存储和执行分离是一个趋势,但是存储和执行耦合也是有优势的,避免了网络的开销,CPU 的极致压榨加上 SSD 的加持,每秒的数据传输对于网络带宽的压力是非常大的,耦合部署可以避免该问题。
5)数据存储在 SSD,极高的 iops。
4、clickhouse 的 insert 和 select
1)clickhouse 如何完成一次完整的 select
这里有个概念需要澄清一下,clickhouse 的表分为两种,一种是本地表另一种是分布式表。本地表是实际存储数据的而分布式表是一个逻辑上的表,不存储数据的只是做一个路由使用,一般在查询的时候都是直接使用分布式表,分布式表引擎会将我们的查询请求路由本地表进行查询,然后进行汇总最终返回给用户。
2)索引在查询中的使用
索引是 clickhouse 查询速度比较快的一个重要原因,正是因为有索引可以避免不必要的数据的扫描和处理。传统基于 hdfs 的 olap 引擎都是不支持索引的,基本的数据过滤只能支持分区进行过滤,这样会扫描处理很多不必要的数据。
clickhouse 不仅支持分区的过滤也支持列级别的稀疏索引。clickhouse 的基础索引是使用了和 kafka 一样的稀疏索引,索引粒度默认是 8192,即每 8192 条数据进行一次记录,这样对于 1 亿的数据只需要记录 12207 条记录,这样可以很好的节约空间。
二分查找+遍历也可以快速的索引到指定的数据,当然相对于稠密索引,肯定会有一定的性能损失,但是在大数据量的场景下,使用稠密索引对存储也是有压力的。

下面我们通过举例看下索引在 clickhouse 的一次 select 中的应用,该表的排序情况为 order by CounterID, Date 第一排序字段为 CounterID,第二排序字段为 Date,即先按照 CounterID 进行排序,如果 CounterID 相同再按照 Date 进行排序。
场景 1 where CounterId=’a’
CounterID 是第一索引列,可以直接定位到 CounterId=’a’的数据是在[0,3]数据块中。
场景 2 where Date=’3’
Date 为第二索引列,索引起来有点费劲,过滤效果还不是特别的好,Date=’3’的数据定位在[2,10]数据块中。
场景 3 where CounterId=’a’ and Date=’3’
第一索引 + 第二索引同时过滤,[0,3] 和 [2,10]的交集,所以为[2,3]数据块中。
场景 4 where noIndexColumn=’xxx’
对于这样没有索引字段的查询就需要直接扫描全部的数据块[0,10]。
3)clickhouse 如何完成一次插入
clickhouse 的插入是基于 Batch 的,它不能够像传统的 mysql 那样频繁的单条记录插入,批次的大小从几千到几十万不等,需要和列的数量以及数据的特性一起考虑,clickhouse 的写入和 Hbase 的写入有点”像”(类 LSM-Tree),主要区别有:
没有内存表;
不进行日志的记录。
clickhouse 写入的时候是直接落盘的, 在落盘之前会对数据进行排序以及必要的拆分(如不同分区的数据会拆分成多个文件夹),如果使用的是 ReplicatedMergeTree 引擎还需要与 zookeeper 进行交互,最终会有线程在后台把数据(文件夹)进行合并(merge),将小文件夹合并生成大文件夹方便查询的时候进行读取(小文件会影响查询性能)。
5、关于集群的搭建
1)单副本
缺点:
集群中任何一台机器出现故障集群不可用;
如果磁盘出现问题不可恢复数据永久丢失;
集群升级期间不可用(clickhouse 版本更新快)。
2)多副本
多副本可以完美的解决单副本的所有的问题,多副本有 2 个解决方案:
RAID 磁盘阵列;
使用 ReplicatedMergeTree 引擎,clickhouse 原生支持同步的引擎(基于 zookeeper)。
两种方案的优缺点:
基于 RAID 磁盘阵列的解决方案,在版本升级,机器 down 机的情况下无法解决单副本的缺陷;
基于 zookeeper 的同步,需要双倍的机器(费钱),同时对 zookeeper 依赖太重,zookeeper 会成为集群的瓶颈,当 zookeeper 有问题的时候集群不可写入(ready only mode);
副本不仅仅让数据更安全,查询的请求也可以路由到副本所在的机器,这样对查询并发度的提升也是有帮助的,如果查询性能跟不上添加副本的数量也是一个解决方案。
6、常见的引擎(MergeTree 家族)
1)(Replicated)MergeTree
该引擎为最简单的引擎,存储最原始数据不做任何的预计算,任何在该引擎上的 select 语句都是在原始数据上进行操作的,常规场景使用最为广泛,其他引擎都是该引擎的一个变种。
2)(Replicated)SummingMergeTree
该引擎拥有“预计算(加法)”的功能。
实现原理:在 merge 阶段把数据加起来(对于需要加的列需要在建表的时候进行指定),对于不可加的列,会取一个最先出现的值。
3)(Replicated)ReplacingMergeTree
该引擎拥有“处理重复数据”的功能。
使用场景:“最新值”,“实时数据”。
4)(Replicated)AggregatingMergeTree
该引擎拥有“预聚合”的功能。
使用场景:配合”物化视图”来一起使用,拥有毫秒级计算 UV 和 PV 的能力。
5)(Replicated)CollapsingMergeTree
该引擎和 ReplacingMergeTree 的功能有点类似,就是通过一个 sign 位去除重复数据的。
需要注意的是,上述所有拥有"预聚合"能力的引擎都在"Merge"过程中实现的,所以在表上进行查询的时候 SQL 是需要进行特殊处理的。
如 SummingMergeTree 引擎需要自己 sum(), ReplacingMergeTree 引擎需要使用时间+版本进行 order by + limit 来取到最新的值,由于数据做了预处理,数据量已经减少了很多,所以查询速度相对会快非常多。
7、最佳实践
1)实时写入使用本地表,不要使用分布式表
分布式表引擎会帮我们将数据自动路由到健康的数据表进行数据的存储,所以使用分布式表相对来说比较简单,对于 Producer 不需要有太多的考虑,但是分布式表有些致命的缺点。
数据的一致性问题,先在分布式表所在的机器进行落盘,然后异步的发送到本地表所在机器进行存储,中间没有一致性的校验,而且在分布式表所在机器时如果机器出现 down 机,会存在数据丢失风险;
据说对 zookeeper 的压力比较大(待验证)。
2)推荐使用(*)MergeTree 引擎,该引擎是 clickhouse 最核心的组件,也是社区优化的重点
数据有保障,查询有保障,升级无感知。
3)谨慎使用 on cluster 的 SQL
使用该类型 SQL hang 住的案例不少,我们也有遇到,可以直接写个脚本直接操作集群的每台进行处理。
8、常见参数配置推荐
1)max_concurrent_queries
最大并发处理的请求数(包含 select,insert 等),默认值 100,推荐 150(不够再加),在我们的集群中出现过”max concurrent queries”的问题。
2)max_bytes_before_external_sort
当 order by 已使用 max_bytes_before_external_sort 内存就进行溢写磁盘(基于磁盘排序),如果不设置该值,那么当内存不够时直接抛错,设置了该值 order by 可以正常完成,但是速度相对存内存来说肯定要慢点(实测慢的非常多,无法接受)。
3)background_pool_size
后台线程池的大小,merge 线程就是在该线程池中执行,当然该线程池不仅仅是给 merge 线程用的,默认值 16,推荐 32 提升 merge 的速度(CPU 允许的前提下)。
4)max_memory_usage
单个 SQL 在单台机器最大内存使用量,该值可以设置的比较大,这样可以提升集群查询的上限。
5)max_memory_usage_for_all_queries
单机最大的内存使用量可以设置略小于机器的物理内存(留一点内操作系统)。
6)max_bytes_before_external_group_by
在进行 group by 的时候,内存使用量已经达到了 max_bytes_before_external_group_by 的时候就进行写磁盘(基于磁盘的 group by 相对于基于磁盘的 order by 性能损耗要好很多的),一般 max_bytes_before_external_group_by 设置为 max_memory_usage / 2,原因是在 clickhouse 中聚合分两个阶段:
查询并且建立中间数据;
合并中间数据 写磁盘在第一个阶段,如果无须写磁盘,clickhouse 在第一个和第二个阶段需要使用相同的内存。
这些内存参数强烈推荐配置上,增强集群的稳定性避免在使用过程中出现莫名其妙的异常。
9、那些年我们遇到过的问题
1)Too many parts(304). Merges are processing significantly slower than inserts
相信很多同学在刚开始使用 clickhouse 的时候都有遇到过该异常,出现异常的原因是因为 MergeTree 的 merge 的速度跟不上目录生成的速度, 数据目录越来越多就会抛出这个异常, 所以一般情况下遇到这个异常,降低一下插入频次就 ok 了,单纯调整 background_pool_size 的大小是治标不治本的。
我们的场景:
我们的插入速度是严格按照官方文档上面的推荐”每秒不超过 1 次的 insert request”,但是有个插入程序在运行一段时间以后抛出了该异常,很奇怪。
问题排查:
排查发现失败的这个表的数据有一个特性,它虽然是实时数据但是数据的 eventTime 是最近一周内的任何时间点,我们的表又是按照 day + hour 组合分区的那么在极限情况下,我们的一个插入请求会涉及 7*24 分区的数据,也就是我们一次插入会在磁盘上生成 168 个数据目录(文件夹),文件夹的生成速度太快,merge 速度跟不上了,所以官方文档的上每秒不超过 1 个插入请求,更准确的说是每秒不超过 1 个数据目录。
case study:
分区字段的设置要慎重考虑,如果每次插入涉及的分区太多,那么不仅容易出现上面的异常,同时在插入的时候也比较耗时,原因是每个数据目录都需要和 zookeeper 进行交互。
2)DB::NetException: Connection reset by peer, while reading from socket xxx
查询过程中 clickhouse-server 进程挂掉。
问题排查:
排查发现在这个异常抛出的时间点有出现 clickhouse-server 的重启,通过监控系统看到机器的内存使用在该时间点出现高峰,在初期集群"裸奔"的时期,很多内存参数都没有进行限制,导致 clickhouse-server 内存使用量太高被 OS KILL 掉。
case study:
上面推荐的内存参数强烈推荐全部加上,max_memory_usage_for_all_queries 该参数没有正确设置是导致该 case 触发的主要原因。
3)Memory limit (for query) exceeded:would use 9.37 GiB (attempt to allocate chunk of 301989888 bytes), maximum: 9.31 GiB
该异常很直接,就是我们限制了 SQL 的查询内存(max_memory_usage)使用的上线,当内存使用量大于该值的时候,查询被强制 KILL。
对于常规的如下简单的 SQL, 查询的空间复杂度为 O(1) 。
对于 group by, order by , count distinct,join 这样的复杂的 SQL,查询的空间复杂度就不是 O(1)了,需要使用大量的内存。
如果是 group by 内存不够,推荐配置上 max_bytes_before_external_group_by 参数,当使用内存到达该阈值,进行磁盘 group by
如果是 order by 内存不够,推荐配置上 max_bytes_before_external_sort 参数,当使用内存到达该阈值,进行磁盘 order by
如果是 count distinct 内存不够,推荐使用一些预估函数(如果业务场景允许),这样不仅可以减少内存的使用同时还会提示查询速度
对于 JOIN 场景,我们需要注意的是 clickhouse 在进行 JOIN 的时候都是将"右表"进行多节点的传输的(右表广播),如果你已经遵循了该原则还是无法跑出来,那么好像也没有什么好办法了
4)zookeeper 的 snapshot 文件太大,follower 从 leader 同步文件时超时
上面有说过 clickhouse 对 zookeeper 的依赖非常的重,表的元数据信息,每个数据块的信息,每次插入的时候,数据同步的时候,都需要和 zookeeper 进行交互,上面存储的数据非常的多。
就拿我们自己的集群举例,我们集群有 60 台机器 30 张左右的表,数据一般只存储 2 天,我们 zookeeper 集群的压力 已经非常的大了,zookeeper 的节点数据已经到达 500w 左右,一个 snapshot 文件已经有 2G+左右的大小了,zookeeper 节点之间的数据同步已经经常性的出现超时。
问题解决:
zookeeper 的 snapshot 文件存储盘不低于 1T,注意清理策略,不然磁盘报警报到你怀疑人生,如果磁盘爆了那集群就处于“残废”状态;
zookeeper 集群的 znode 最好能在 400w 以下;
建表的时候添加 use_minimalistic_part_header_in_zookeeper 参数,对元数据进行压缩存储,对于高版本的 clickhouse 可以直接在原表上面修改该 setting 信息,注意修改完了以后无法再回滚的。
5)zookeeper 压力太大,clickhouse 表处于”read only mode”,插入失败
zookeeper 机器的 snapshot 文件和 log 文件最好分盘存储(推荐 SSD)提高 ZK 的响应;
做好 zookeeper 集群和 clickhouse 集群的规划,可以多套 zookeeper 集群服务一套 clickhouse 集群。
直播回放
作者介绍:
王海胜,趣头条数据中心大数据开发工程师
8 年互联网工作经验,曾在 eBay、唯品会、趣头条等公司从事大数据开发相关工作,有丰富的大数据落地经验。
原文链接:
https://mp.weixin.qq.com/s/egzFxUOAGen_yrKclZGVag

Java 避坑指南:Java 高手笔记代码篇
本迷你书包括 86 个业务开发中常见踩坑点。每一个知识点都相当的实用,是程序员业务开发中的必备避坑指南...











评论