

本文最初发布于 Towards Data Science。
简介
在这篇文章中,我将展示如何使用经过优化的、基于转换器的命名实体识别(NER)以及 spaCy 的关系提取模型,基于职位描述创建一个知识图谱。这里介绍的方法可以应用于其他任何领域,如生物医学、金融、医疗保健等。
以下是我们要采取的步骤:
在 Google Colab 中加载优化后的转换器 NER 和 spaCy 关系提取模型;
创建一个 Neo4j Sandbox,并添加实体和关系;
查询图,找出与目标简历匹配度最高的职位,找出三个最受欢迎的技能和共现率最高的技能。
要了解关于如何使用 UBIAI 生成训练数据以及优化 NER 和关系提取模型的更多信息,请查看以下文章。
职位描述数据集可以从Kaggle获取。
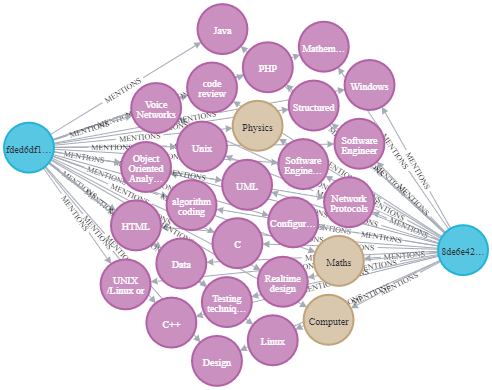
在本文结束的时候,我们就可以创建出如下所示的知识图谱。
命名实体和关系提取
首先,我们加载 NER 和关系模型的依赖关系,以及之前优化过的 NER 模型本身,以提取技能、学历、专业和工作年限:
加载我们想从中提取实体和关系的职位数据集:
从职位数据集中提取实体:
在将实体提供给关系提取模型之前,我们可以看下提取出的部分实体:
我们现在准备好预测关系了;首先加载关系提取模型,务必将目录改为 rel_component/scripts 以便可以访问关系模型的所有必要脚本。
Neo4J
现在,我们可以加载职位数据集,并将数据提取到 Neo4j 数据库中了。
首先,我们创建一个空的Neo4j Sandbox,并添加连接信息,如下所示:
接下来,我们将文档、实体和关系添加到知识图谱中。注意,我们需要从实体 EXPERIENCE 的 name 中提取出整数年限,并将其作为一个属性存储起来。
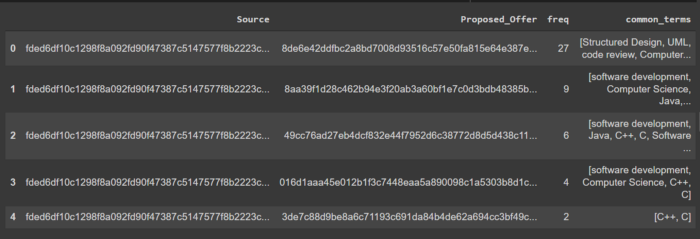
现在开始进入有趣的部分了。我们可以启动知识图谱并运行查询了。让我们运行一个查询,找出与目标简历最匹配的职位:
以表格形式显示的结果中的公共实体:
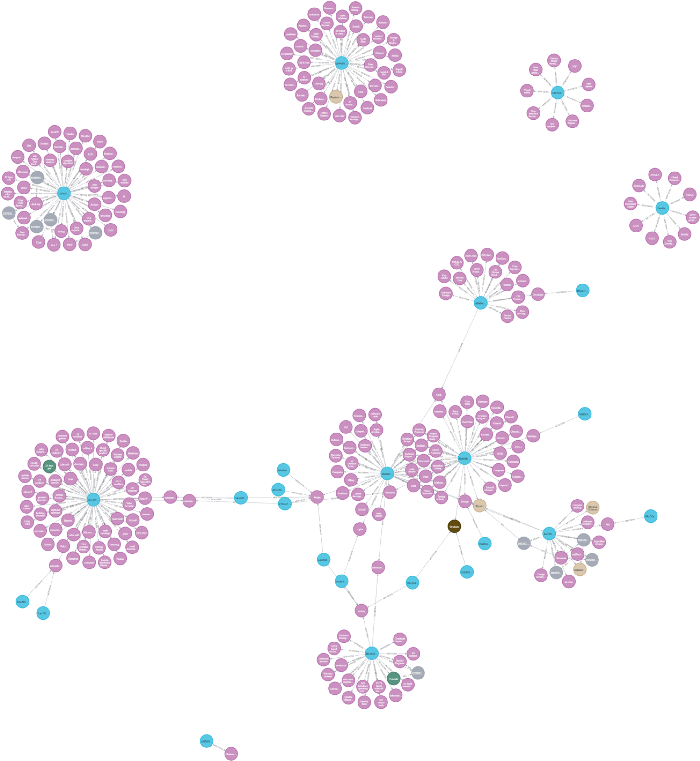
以可视化形式显示的图:
虽然这个数据集只有 29 个职位描述,但这里介绍的方法可以应用于有成千上万个职位的大规模数据集。只需几行代码,我们立马就可以提取出与目标简历匹配度最高的工作。
下面,让我们找出最需要的技能:
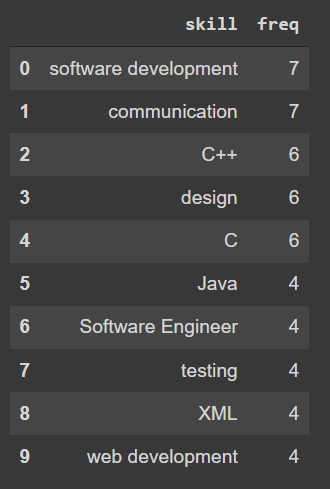
以及需要最高工作年限的技能:

Web 开发和技术支持需要的工作年限最高,然后是安全设置。
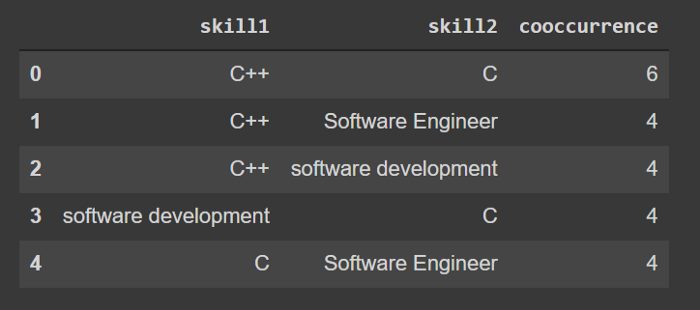
最后,让我们查下共现率最高的技能对:
小结
在这篇文章中,我们描述了如何利用基于转换器的 NER 和 spaCy 的关系提取模型,用 Neo4j 创建知识图谱。除了信息提取之外,图的拓扑结构还可以作为其他机器学习模型的输入。
将 NLP 与图数据库 Neo4j 相结合,可以加速许多领域的信息发现,相比之下,在医疗和生物医学领域的应用效果更为显著。
如果你有任何问题或希望为具体用例创建自定义模型,请给我们发邮件(admin@ubiai.tools),或是在 Twitter 上给我们留言(@UBIAI5)。
原文链接:How to Build a Knowledge Graph with Neo4J and Transformers
公众号推荐:
跳进 AI 的奇妙世界,一起探索未来工作的新风貌!想要深入了解 AI 如何成为产业创新的新引擎?好奇哪些城市正成为 AI 人才的新磁场?《中国生成式 AI 开发者洞察 2024》由 InfoQ 研究中心精心打造,为你深度解锁生成式 AI 领域的最新开发者动态。无论你是资深研发者,还是对生成式 AI 充满好奇的新手,这份报告都是你不可错过的知识宝典。欢迎大家扫码关注「AI前线」公众号,回复「开发者洞察」领取。


分布式云行业实践指南(2023)
业内首个分布式云行业实践方法论、工具箱。







评论