

1 简介
流式系统持续地从一系列数据源注入并处理数据。这些系统建立在只追加(Append-Only)数据结构之上,实现高效的读写访问,目标在于达到较低的端到端延迟。随着 5G/IoT 边缘计算的客户端数量的不断增长,持续不断产生数据的容量一直在以指数级爆炸性增加[1][2]。这种增长给流式系统带来了很大压力,不仅要求这些系统能够以低延迟处理所有客户端生成的工作负载,还要能够以高吞吐量容纳大容量(PB/EB 级别)数据。
Pravega(梵文“迅速”)是一套我们从头构建的开源流式存储系统,能够持续从数据源注入数据并满足此类流式工作负载的苛刻要求。它通过分层存储为每一个 Stream(对流式数据的抽象,类比 Kafka topic)提供存储无界数据的能力,同时达到弹性、持久性和一致性。Pravega 的读写路径都被精心设计,以满足事件流生产和消费的低延迟和高吞吐。此外,Pravega 还提供诸如长期保留(Retention)和扩展等特性。本文会对 Pravega 进行性能评估,重点关注读写性能。
为了对比不同的设计选择,我们还额外展示了来自其它系统的性能结果:Apache Kafka和Apache Pulsar。Pulsar 和 Kafka 最初都被作为优秀的消息系统而为人熟知,但它们最近都做出了很大努力向存储系统方向发展,这两个系统最近都新增了分层存储的特性。然而,它们的设计选择具有根本性的不同,并导致了不同的行为以及性能特点。我们将会在本文探索这些不同点。
本文的主要的实验参数和结果亮点如下:
整体注入性能。单个 Pravega 的 Writer 可以每秒产生超过一百万小型事件(100 字节),以及为大型事件(10,000 字节)保持 350MB/s 的吞吐量,并且在这两个场景下都能保持个位数毫秒数级的延迟(95%分位数,95th percentile)。
持久性。Pravega 总是在发回确认时保证数据的持久性。对于单 Segment(类比 Kafka partition)的 Stream,Kafka 的写吞吐量至少比 Pravega 低 40%,无论是否对每个消息进行刷新(flush)操作。对于 16 Segment 的 Stream,Pravega 的 Writer 与每消息进行刷新的 Kafka Writer 的吞吐量相仿,但 Pravega 的延迟 更低(几毫秒相比于 Kafka 的超过 1 秒)。
能够动态调整的批处理。Pravega 并不要求为客户端的批处理进行任何复杂配置。Pulsar 可以达到低延迟或者高吞吐,但不能二者兼具。对于 Kafka,当应用程序使用路由键(Routing Key)分区的时候,较大的批对吞吐量的影响很大(对于 16 Segment 的 Stream,吞吐量降低了 80%)。在这两种情况下,强制要求用户静态配置批处理都不是理想的解决方案。
当存在大事件时,注重高吞吐量工作负载的行为。对于 16 Segment 的 Stream 和 10kB 大小的事件,Pravega 取得了高达 350MB/s 的吞吐量。这一吞吐量比 Pulsar 在同配置下高 40%,并与 Kafka 旗鼓相当(约有 6%的差异)。然而,Kafka 在这一配置下的延迟高达 800 毫秒,而 Pravega 却仅有几毫秒。
端到端的延迟。当处于 Stream 的尾部时,Pravega 的 Reader 同样提供仅数毫秒的端到端延迟,同时保持相当高的吞吐量。对于单 Segment 的 Stream,它比 Kafka 的吞吐量更高(大约高 80%)。对于 Pulsar,增加 Partition 和 Reader 使得性能下降(单 Partition 用例所取得的吞吐量是 16 Partition 用例的 3.6 倍)。
路由键(Routing Key)的使用。无论使用还是不使用路由键,Pravega 并未表现出显著的性能差异。对于中高吞吐量的用例,当使用路由键时,Kafka 和 Pulsar 表现出超过两倍的端到端延迟,尤其是对于 Kafka,最大读取吞吐量降低了超过 37%。
追赶(Catch-up)读取和历史读取的分层存储。Pravega 可以在具有 100GB 历史数据并且同时进行 100MB/s 新数据注入的情况下动态进行追赶读取。在相同场景下,Pulsar 开启了分层存储后不能很好地进行追赶读取,表现为积压无限增长。
自动扩展的性能。自动扩展是 Pravega 独有的特性,扩展一个 Stream 可以提供更高的注入性能。我们可以看到,在使用 100MB/s 恒定注入速率的情况下, Stream 自动扩展使得写入延迟下降。
除了在展示时间序列的时候,我们都绘制了延迟随吞吐量的变化曲线。在现有的公开文章中,我们发现了一个普遍问题:它们要么只绘制延迟曲线,要么只绘制吞吐量曲线,然而对于流式负载,这二者其实是相互关联的。例如,当某个配置所得到的最大吞吐量看起来很优秀时,它的延迟很可能已经达到了几百毫秒甚至数秒的数量级。我们通过绘制延迟-吞吐量图像来避免这种具有误导性的结论。此外,我们还提供图表数据点所对应的表格数据作为补充。从完备性方面说,表格数据比图提供了更多信息(例如不同的百分等级)。
2 背景
Pravega 是一个复杂的系统,因此我们推荐读者深入阅读我们的文档,包括先前的博客文章。在这里,我们仅提供关于读写路径的简要概括,同时还有 Kafka 和 Pulsar 的一些要点。
2.1Pravega 的写路径
Pravega 提供不同的 API 实现将数据加入 Stream。在本小节,我们主要关注事件流API。
事件流 Writer 将事件写入 Stream。一个 Stream 可以有数个并行的 Segment,并且根据自动扩展策略,这些 Segment 还可以动态变化。当一个应用提供了路由键,Pravega 客户端就以此将事件映射到 Segment。如果在事件写入时没有提供路由键,那么客户端就随机选取一个 Segment。
客户端会适时地批处理事件数据,将事件成批写入某个 Segment。客户端控制着何时新开一个批以及何时关闭一个已有的批,但是同一批数据还是会在服务器端积累。在 Pravega 中,管理 Segment 的组件称作Segment Store。Segment Store 接收对 Segment 的写请求,同时把这些数据加入一个缓存和追加到一个持久化日志中,该日志目前由Apache BookKeeper实现。当追加到持久日志时,Segment Store 会进行第二轮批处理。对于那些消息尺寸很小并且消息很不频繁的场景,我们通过这种二层聚合来保持高吞吐量。
日志保证了持久性:一旦事件在日志中被持久化,Pravega 便对事件进行确认,而这些日志仅在故障恢复时才使用。由于 Segment Store 在缓存中对写入数据保留了一份副本,它需要异步地将这些数据从缓存刷入底层存储,称作长期存储(Long-Term Storage,LTS)。
BookKeeper 将自身的存储划分为日志(Journal)、条目记录器(Entry Logger)和索引(Index)三部分。其中,日志是一种只追加的数据结构,并且它是写路径上的重要组件。条目记录器和索引则在 BookKeeper 的读取路径上使用。对于 Pravega 来说,BookKeeper 的读取路径仅在 Segment Store 的故障恢复阶段才发生。因此,如果排除那些偶发性的干扰,写路径的容量主要依赖于日志而不是其它两个组件。
2.2Pravega 的读路径
应用程序使用事件流 Reader 的实例独立进行事件读取。事件流 Reader 是 Reader Group 的组成部分之一,而 Reader Group 则在内部负责协调 Segment 的分配。Reader 从被分配到的 Segment 中读取事件,并且它们是从 Segment Store 主动拉取数据。Reader 每次拉取 Segment 数据时,都会尽可能多地获取可用数据,最大上限为 1MB。
Segment Store 总是从缓存中进行数据服务。如果缓存命中,那么响应读请求不再需要额外的 IO 操作。否则,Segment Store 从长期存储中以 1MB 为单位拉取数据,填充缓存,然后响应客户端。Segment Store 并不是从持久化日志中读取数据然后响应读请求的。
2.3Pulsar 和 Kafka
Pulsar 和 Kafka 都将自己定义为流式平台。Pulsar 基于 Apache BookKeeper 实现了一个消息代理。这一代理是建立在一个托管分类账簿(Ledger)的抽象之上,具体而言,是由一系列顺序组织的 BookKeeper ledger 组成的无边界日志。BookKeeper 是 Pulsar 的主要数据存储,尽管最近的一个新特性允许用户可选地将数据分层存储到长期存储中去。
Pulsar 对外暴露 Topic 抽象,并允许 Partition。Pulsar 的生产者向 Topic 中生产消息。Pulsar 为消息的收取和消费提供了不同选项,例如不同的订阅模式以及从 Topic 中手动读取等。
Kafka 同样实现了消息代理,并且暴露 Topic 与 Partition。Kafka 并不像 Pravega 和 Pulsar 那样使用外部的存储依赖,它使用本地存储代理作为系统的主要存储。的确有人提议为Kafka增加开源的分层存储,但据我们所知,该特性目前仅是Confluent platform的预览特性。因此,我们只与 Pulsar 做分层存储的对比。
Pulsar 和 Kafka 都实现了客户端批处理,并允许对这种批处理进行配置。对于二者来说,有两个主要参数控制着客户端批处理:
最大批尺寸:这一数值指的是对于某一个批,客户端可能积累的最大数据量。
最大等待或徘徊时间:这一数值指的是客户端在关闭并提交一个批之前的最大等待时间。
最大批尺寸和最大等待时间之间存在一种内在的权衡关系:较大的批对吞吐量有利而对延迟不利,而较小的等待时间则有着相反的效果。如果批能够积累得足够快,那么是有可能同时做到高吞吐与低延迟的。然而,对于单一客户端而言,很难持续地在短时间内构建出足够大的批,因此不得不在低延迟和高吞吐之间做出妥协。通常,应用程序很难调优这些参数或者事先选定一个合适的值。对于 Pravega,我们决定不对应用程序开放这些配置,而是根据负载动态并且透明地自动调整。
Kafka 和 Pulsar 以批的形式传递并存储客户端产生的消息。Pravega 与此不同,它并不以消息或者事件为单位进行存储,而是直接存储事件的字节序列,并且对事件帧的分界不可知。它在数据路径上通过两阶段聚合形成更大的批:Writer 进行第一阶段聚合,而 Segment Store 进行第二阶段聚合。适时地进行两阶段批处理允许系统在多个客户端之间进行聚合,这对那些无法独立形成较大批的客户端非常有利,例如某些处理小型事件的应用,或者某些具有大量客户端而每个客户端又以低频率产生事件的应用。一些物联网应用就具有这些特征。
2.4 先前的文章
现有的两篇文章对我们的配置选取产生了较大影响:
与该文章相同,我们分别使用单 Partition 和 16 Partition 配置,并且选取 100 字节和 10,000 字节两种大小的事件。我们选择绘制 95%分位数而不是 99%分位数,因为我们发现这对于应用需求来说更具代表性,尽管如此,我们仍然在对应的表格数据中保留了 99%分位数用于比较。
我们使用该文章中所述的对 Open Messaging Benchmark 的修改,进行我们的相关实验,例如:对基准数据集和 Kafka 驱动的通用修改。
3 简明实验搭建和图表
在此,我们对搭建在 AWS 上的实验环境和配置进行简要描述。在原文的附录中拥有更详细的实验环境配置和测试方法介绍。
对于所有实验,我们都使用相同的副本配置策略,即要求每一个消息/事件的写操作完成至少需要获得来自三个副本中的两个的确认。我们将 Pravega 配置成使用 AWS 的 EFS 作为长期存储,将 Pulsar 配置成将数据卸载到存储(AWS S3),而对于 Kafka,直至本文写作时这一特性依旧尚未在其开源版本中实现。注意,除了本文提及以外的配置值,都将保持其在OpenMessaging Benchmark仓库中的官方默认值。所有这些信息都总结在下表中。

表 1 基准数据集的配置
我们的工作负载在进行写操作时默认使用路由键(即 OpenMessaging Benchmark 中的 RANDOM_NANO 键分布模式)。我们使用这一选项来保证每一个键的事件顺序,这是流式应用程序保证正确性的常用需求。为了与先前文章中的结果保持一致,我们同样还使用了不带路由键的工作负载(即 OpenMessaging Benchmark 中的 NO_KEY 键分布模式),以便评估路由键所带来的潜在影响。
为展示三个系统中写路径的高效程度,我们为 Pravega 和 Pulsar 的 BookKeeper 分配了单一的驱动器,为 Kafka 的代理日志也分配单一驱动器,基于此进行比较。
我们为所得到的结果绘制了延迟随吞吐量变化的图像。在所有的图像中,y 轴使用对数刻度,而 x 轴则根据吞吐量是用事件数表示还是数据量表示,分别使用对数和线性刻度。我们希望在低吞吐量和高吞吐量的情况下,图像都能保持较高的视觉区分度,但这在线性刻度的条件下是无法实现的。图表中的实线对应系统的默认配置(见上表),而虚线则代表某一特定配置,该配置会标注特别说明。对于所有的实验图表,我们都提供对应的表格数据、其它百分位数(例如 50%和 99%)的延迟数据,以及基准数据集的原始输出。最后请注意,由于 AWS 的多租户特性,本文所绘制的结果图表虽具有代表性,但多次执行结果仍可能出现变化(请参阅原文附录获取更多有关该期望变化性的更多信息)。相对于受控的本地环境,这种变化性在云环境中会更加普遍。
4 无界的 Pravega Stream
注入和存储无界数据流允许应用程序读取和处理最近数据和历史数据。从应用程序的角度看,与 Pravega 交互时有五个相关点:
数据注入:随着数据源持续产生数据,Pravega 必须有效捕获并持久存储这些数据。
尾部读取:应用程序通常对延迟十分敏感,Pravega 必须以低延迟端到端地交付数据,并保证顺序。
追赶读取:应用程序的某个进行尾部读取的 Reader 进程可能重启或者从头读取,这种场景并不罕见。在这种情况下,Reader 必须能够以高吞吐量进行读取并最终追赶上 Stream 的尾部。
历史读取:尽管流式处理通常指的是处理 Stream 的尾端,但人们同时也希望能够处理历史数据,可能是以验证为目的,也可能是用作数据深入分析的线下处理。
弹性:随着注入负载的波动,某个 Stream 可以自动通过扩展或者收缩来增大或者减小并行度。

图 1 Pravega 的注入,尾部读取,追赶读取和历史读取。
在接下来的章节中,我们会从性能角度逐一探索这些点。
5 往 Stream 注入数据
5.1 低注入延迟和高注入吞吐
我们首先分析在不同事件大小以及不同 Segment 数目的条件下,延迟(95%分位数)与吞吐量的函数变化图像。
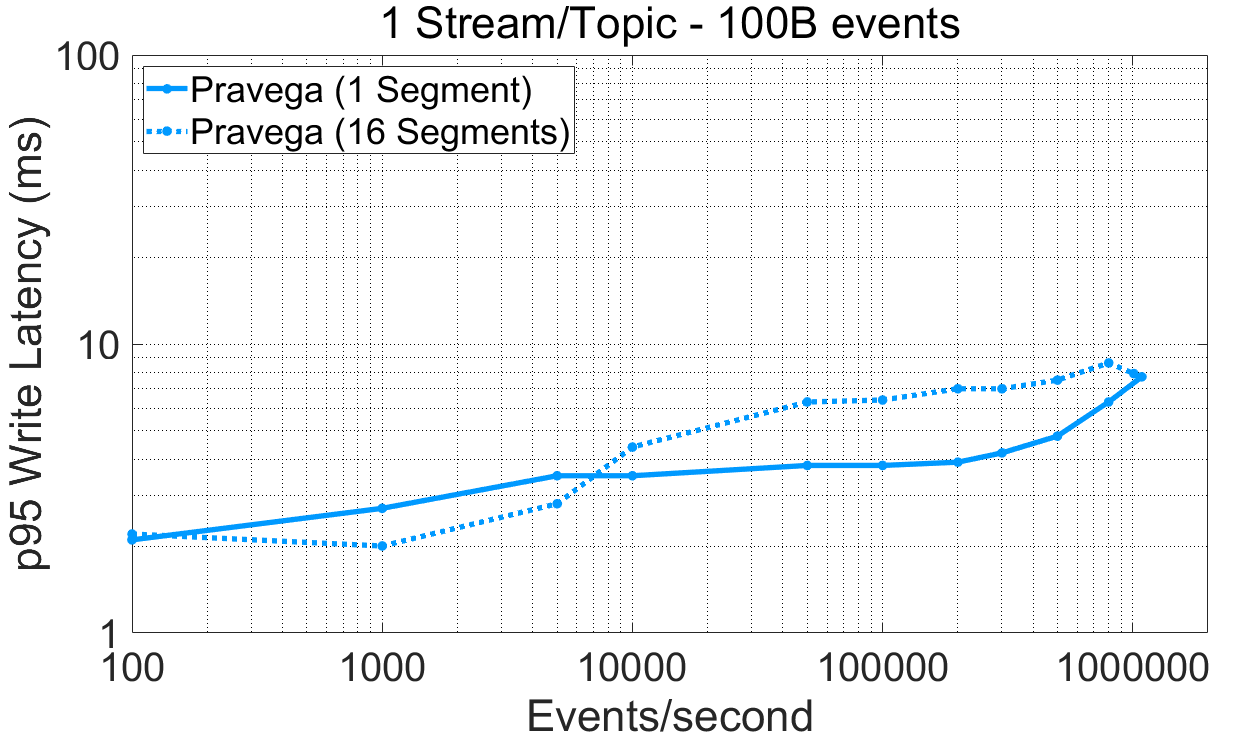
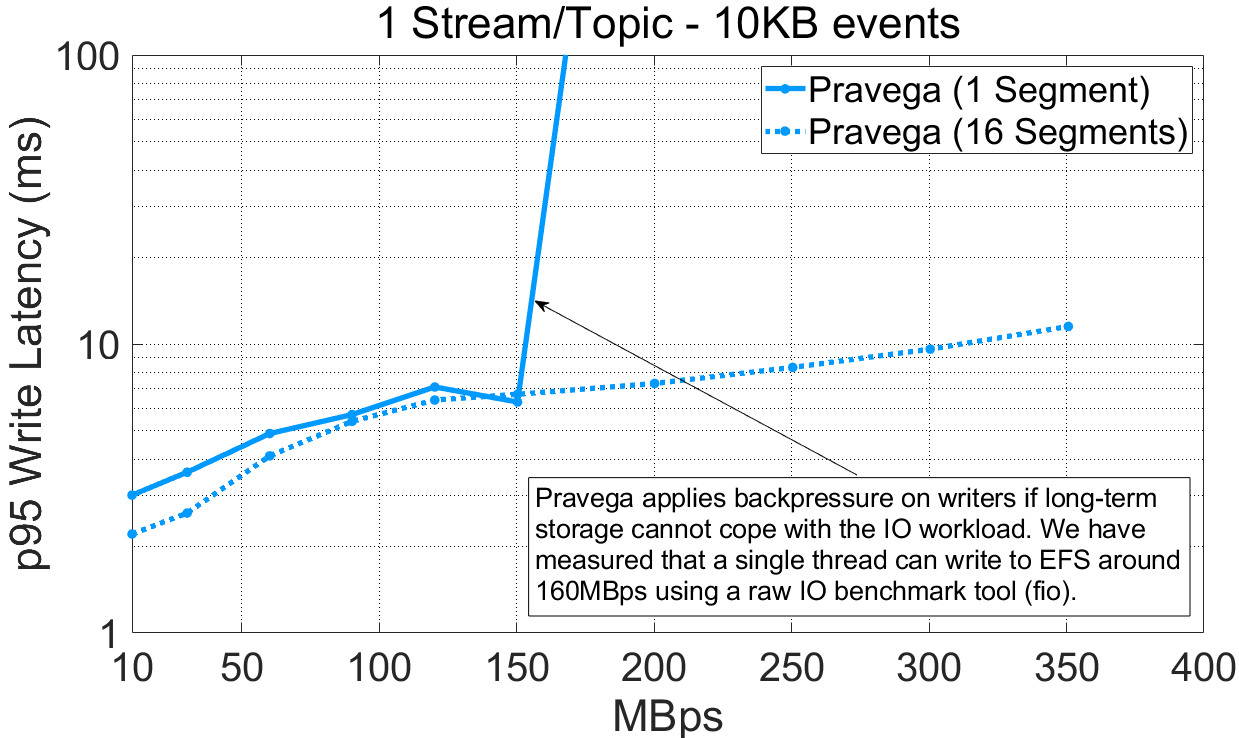
图 2 在不同事件大小以及不同 Segment 数目条件下,Pravega 的注入性能。对应的表格数据链接:表格数据。
对于 Pravega,该实验可以使用工作负载文件和配置文件作为输入,通过P3测试驱动复现。基准数据集的原始输出可以从以下链接获取:原始输出。
在上述图表中,我们强调如下几点:
Pravega 的 Writer 在不同吞吐率条件下都取得了毫秒数量级的写延迟(95%分位数),并且与事件大小和 segment 数目无关。
对于 100 字节大小的事件,单一 Pravega Writer 能够取得大约每秒一百万个事件写入。
对于小型事件(100 字节),在 Pravega 中使用多个并行 Segment 能够在低吞吐量情况下提供低延迟,而使用单一 Segment 可以在高吞吐量的情况下取得低延迟。
对于大型事件(10,000 字节),写入多个 Segment(350MB/s)可以取得比单一 Segment(160MB/s)更高的吞吐量。单一 Segment 的吞吐量瓶颈在于长期存储的吞吐量,对于本次实验的部署,也就是 EFS。我们使用fio工具测量了 EFS 在单线程情况下的最大吞吐量,结果是大约 160MB/s。因此该实验也证明了,一旦 Pravega 达到了长期 存储层的最大吞吐量,就会正确触发并应用反压机制。
当从任意数据源注入数据时,吞吐量非常重要。为延迟敏感的应用以低延迟交付近期数据也同样重要。想象一下这样一个工业物联网应用,它包含大量机器,每台机器都装有大量传感器。它们持续产生数据,并且需要在最短的时间间隔内被注入和处理。在注入一系列不同大小事件的情况下,Pravega 可以同时满足这些需求。同时,如果长期存储饱和了,Pravega 会对 Writer 施加反压,保护系统不会出现无限增长的数据积压。
5.2 注入的持久性
通常,一个应用程序会很自然地做出这样的期望:一旦收到了对写入数据的确认,那么这些数据就应当能够被读出,除非出现了失败。持久性对于应用程序衡量正确性来说至关重要。在此,我们展示延迟(95%分位数)和吞吐量来比较不同的持久化选项对性能可能造成的影响。具体而言,我们进行如下实验:
比较 Pravega 开启和关闭持久化特性后的性能,也就是开启和关闭持久化日志(Apache BookKeeper,默认开启)上的日志刷新(Flush)。
与 Apache Kafka 在开启和关闭持久化特性两种情况下进行比较。Kafka 默认并不保证在收到确认后数据能够写入持久化介质。
注意,Kafka 假设代理故障是相互独立的,也就是说,类似所有副本都一起停止或崩溃这样的相关故障概率是小到可忽略的。这样的假设对于任何企业级应用来说都是不符合需求的,因为相关故障确实会发生,并且服务器并不总是能够进行优雅关闭 [3]。越来越多的流式应用正在为企业而构建,并且任何企业级的产品都需要提供持久化特性。
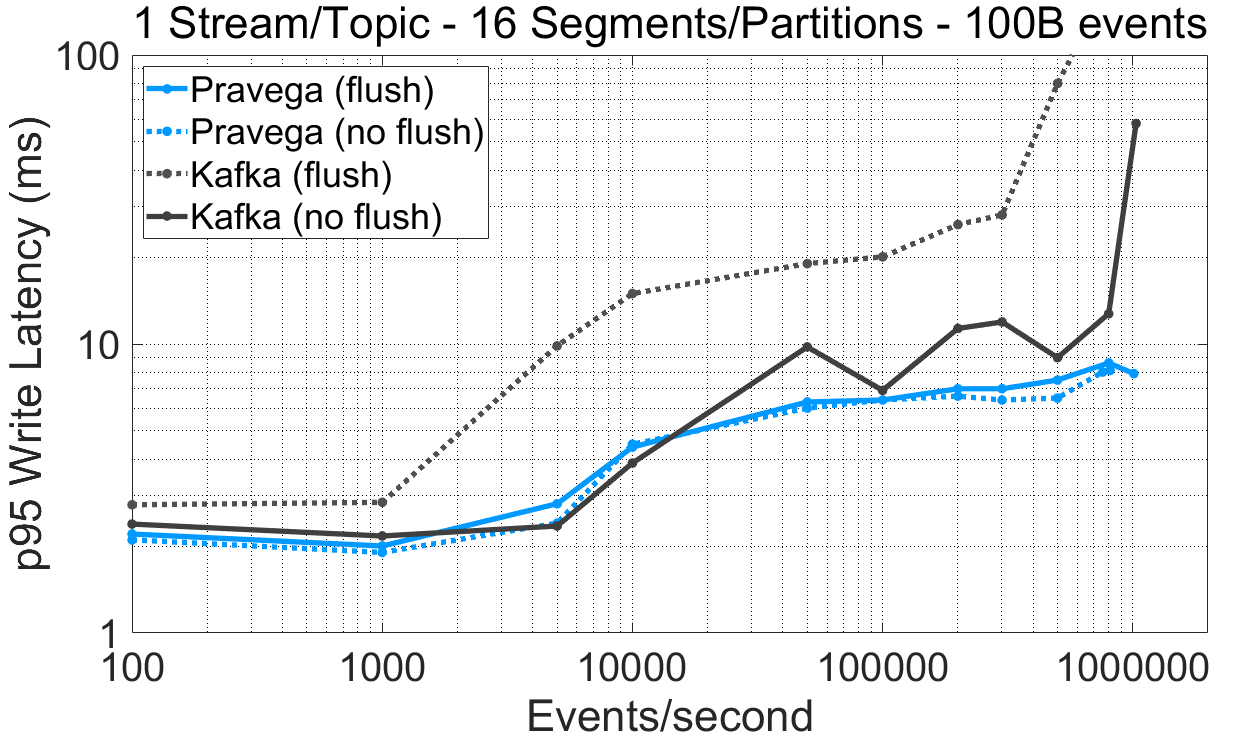
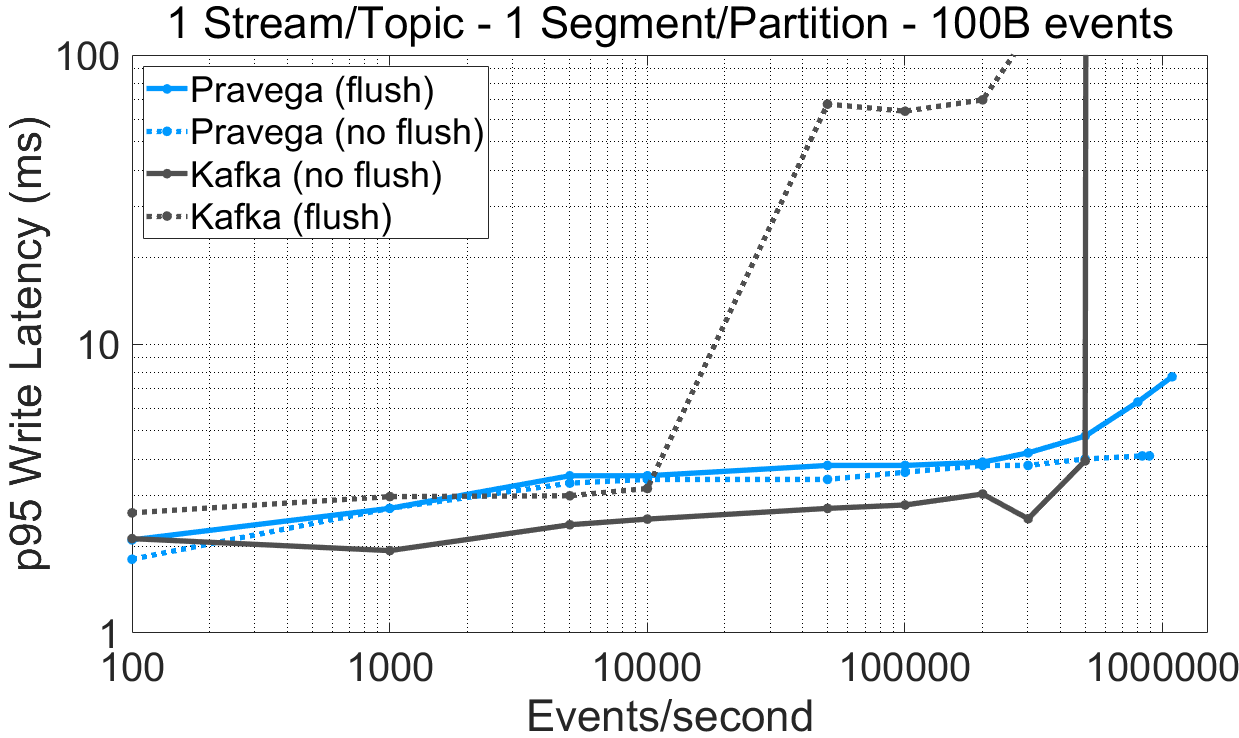
图 3 在不同持久化选项下各系统的延迟随吞吐量的变化曲线。对应的表格数据链接:表格数据。
对于 Kafka,该实验可以使用负载文件(变化持久性设置)和配置文件,通过P3测试驱动进行复现。基准数据集的原始输出可以从以下链接获取:Kafka-randomkey-sync,Pravega-randomkey-nosync,Kafka-randomkey-nosync。
从实验数据中我们可以得出如下观测结果:
对于单一 Segment/Partition 的 Stream/Topic,Pravega Writer(有刷新)达到的最大吞吐量比 Kafka(无刷新)高 73%。对于 16 Segment/Partition 的实验,Pravega 和 Kafka 的最大吞吐量很接近(超过每秒百万事件)。
为 Kafka 强制开启数据持久化特性(有刷新)后,写入延迟受到极大的影响。对于中高吞吐率,这一现象尤其明显。Kafka 根据时间间隔(log.flush.interval.ms)或者消息间隔(log.flush.interval.messages)进行消息刷新。当消息间隔设置为 1,则所有消息都会在确认前各自被进行刷新,这将导致显著的性能衰退。对于 BookKeeper 来说,数据在确认前已经完成了持久化,但这些数据会适时地进行成组刷新 [4]。
把 Pravega 设置成让 BookKeeper 不要将数据刷新到持久化介质上所获得的延迟收益并不高,这也证明了 Pravega 默认提供持久化特性的合理性。
对于单 Segment/Partition 场景下的延迟,在小于 500,000 事件/s 吞吐量的情况下,Kafka(无刷新)的写延迟比 Pravega(有刷新)更低(95%分位数低约 1 毫秒)。对于所有其它场景,Pravega 比 Kafka(无刷新)显示出了更低的延迟。
直至性能饱和点,默认的 Kafka 生产者(无刷新)相比于 Pravega 生产者取得了相近的写延迟(差异小于 1 毫秒),但吞吐量更低,同时还牺牲了数据持久性。当 Kafka 保证数据持久性时(有刷新),性能开始显著下降,无论是在单 Segment 还是 16 Segment 的情况下,都开始出现过早性能饱和以及高延迟的现象,尤其是在 16 Segment 的场景下。
5.3 动态客户端批处理与“绳结”(knobs)机制
批处理允许在吞吐量和延迟之间做出权衡。理想情况下,应用程序无需推断复杂的参数设置来从批处理中获益,这种推断应该是客户端和服务器端自己完成的。这一目标正是 Pravega 在 Writer 中引入的启发式批处理动态调整。
在此,我们绘制延迟(95%分位数)关于吞吐量的函数图像来理解 Pravega Writer 的批处理对性能的影响。我们将 Pravega 与 Apache Pulsar 和 Apache Kafka(默认无刷新)进行对比,而这两个系统都要求应用程序自己选择是否开启批处理以及进行相应配置。
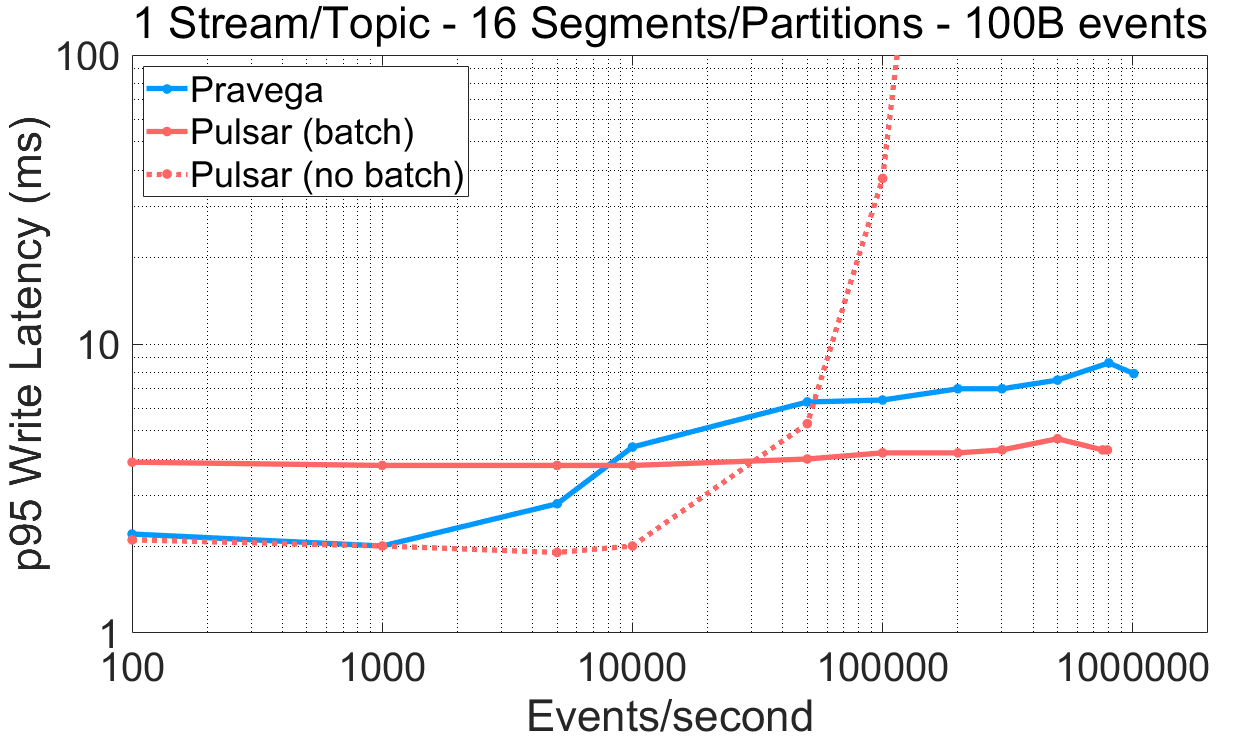
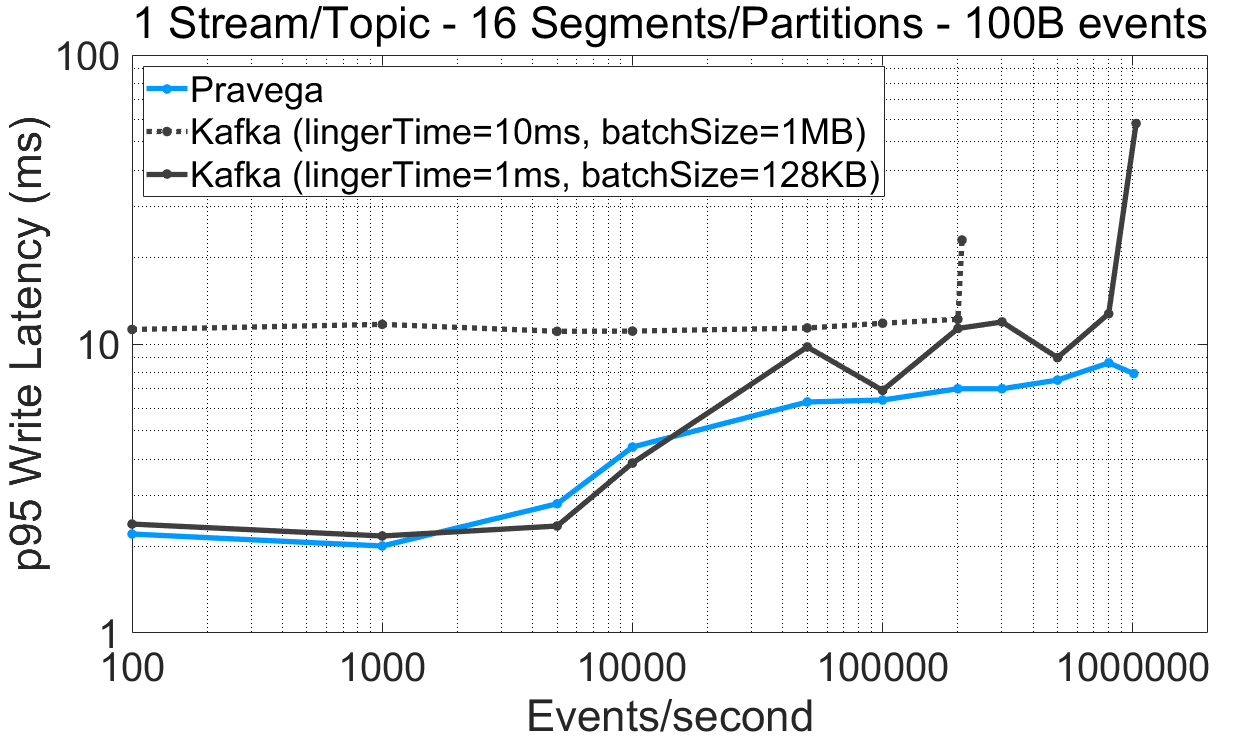
图 4 批处理机制对系统性能的影响。对应的表格数据链接:表格数据。
对于 Pulsar,该实验可以使用负载文件(变化批处理标志)和配置文件,通过P3测试驱动进行复现。基准数据集的原始输出可以从以下链接获取:pulsar-nobatch,pulsar-batch,kafka-largebatch。
基于以上结果,我们强调如下要点:
Pulsar 生产者被设计成以低延迟或者高吞吐为目标,但不可二者兼得。这样的设计强迫用户在面向延迟(无批处理)与面向吞吐量(有批处理)的配置之间做出抉择。
在吞吐率坐标的低端(例如,小于 10,000 事件/s)Pravega 取得了比 Pulsar(有批处理)更低的写延迟,同样,在吞吐率坐标的高端,Pravega 比 Pulsar(无批处理)的写延迟更低。
为 Kafka 增大批尺寸和徘徊时间(10 毫秒徘徊时间与 1MB 批尺寸)以便允许更积极的批处理,竟然起到了与预期相反的效果。与 1 毫秒徘徊时间与 128KB 批尺寸的配置相比,吞吐量反而下降了。为了弄清这一结果,我们使用相同的批处理配置,检查了 Kafka 生产者写入 16 Partition 的 Topic 的最大吞吐量,但在写入时不使用路由键(OpenMessaging Benchmark 中的 NO_KEY 选项)。在这种情况下,客户端的写入吞吐量从 20MB/s 提升到了 120MB/s。于是,我们将先前观测到的低性能归因为使用了随机路由键。
Pravega 中的动态批处理机制允许 Writer 在延迟与吞吐量之间做出合理的折中:它在低吞吐量和高吞吐量场景下都取得了毫秒数量级的延迟,而当注入速率增大时又能够平滑地用延迟换取吞吐量。Pravega 不要求用户事先确定 Writer 的性能配置,并且使用路由键不会影响其机制。
5.4 大事件与高字节吞吐量
在真实的应用中,事件通常都很小,比如说 1KB 或者更小,但现实中同样不乏大型事件的用例。对于这些场景,批处理不再那么有效,并且我们所能达到的注入字节速率此时成为了最相关的指标。对于这部分的实验,我们使用 10KB 大小的事件,并与 Pulsar 和 Kafka 进行对比。我们绘制延迟(95%分位数)随吞吐量的变化曲线,但我们在 x 轴上使用以字节为单位的吞吐量而不再以事件数为单位。
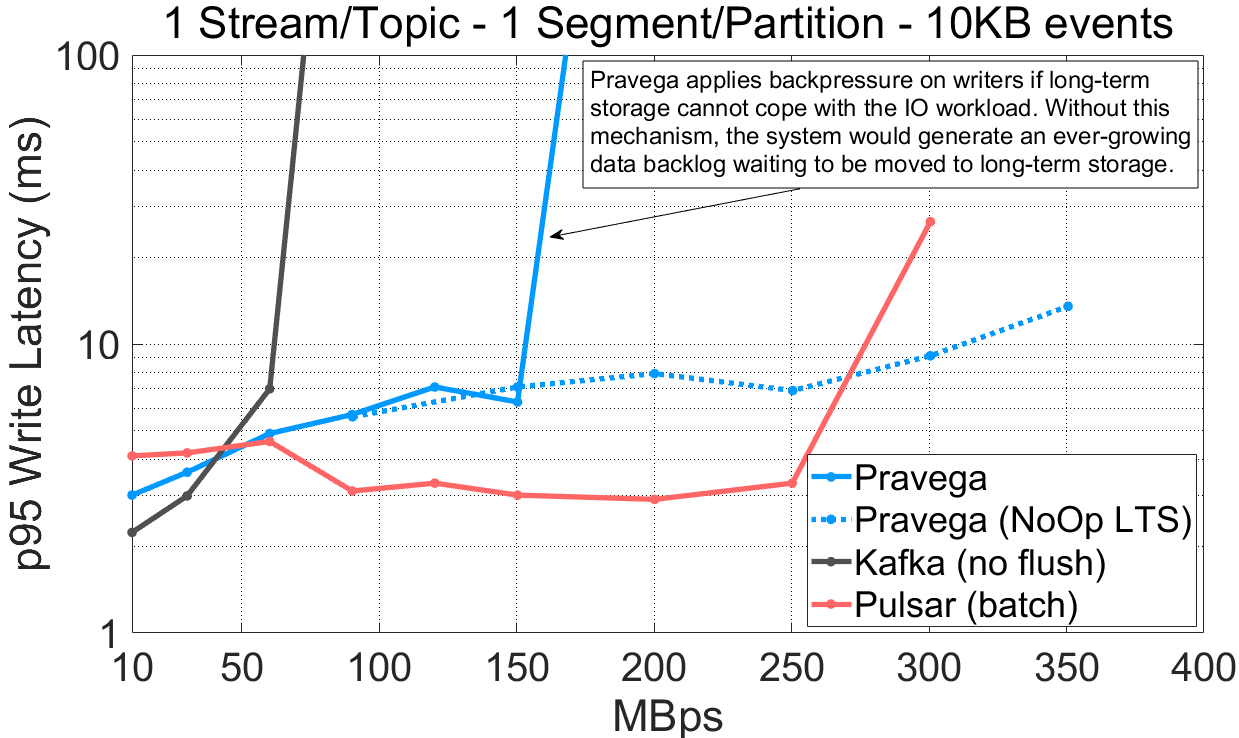
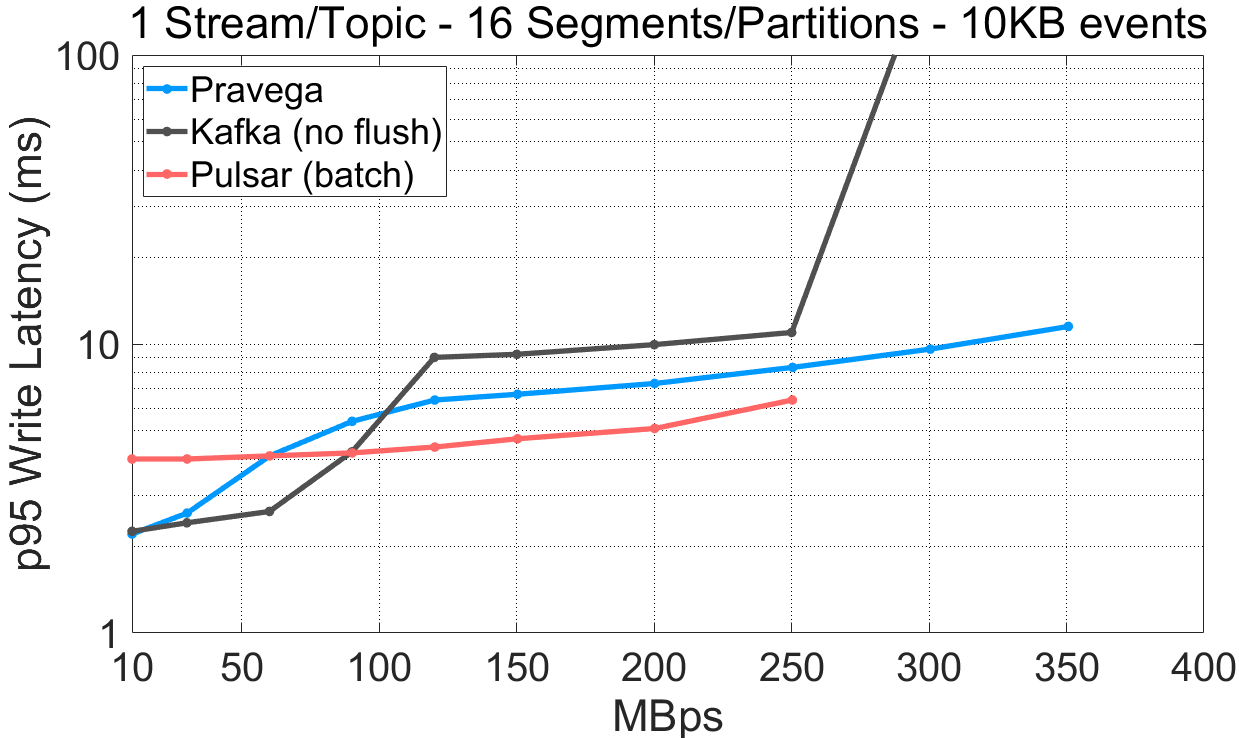
图 5 各系统在大事件(10KB)条件下的性能。
观察上述实验结果,我们发现:
对单 Segment/Partition 的 Stream/Topic,Pravega(160MB/s)和 Pulsar(300MB/s)相比于 Kafka(70MB/s)取得了高得多的吞吐量。
对于 16 Segment/Partition 的 Stream/Topic,Pravega(350MB/s)相比于 Kafka(330MB/s)和 Pulsar(250MB/s)取得了最高吞吐量。
从视觉上看,Pravega 似乎在单一 Segment 的场景中的写吞吐量无法超过 160MB/s,这仍然归因为 AWS EFS 的瓶颈。为了验证这一假设,我们进行了一个附加实验,开启测试特性(NoOp LTS)使得 Pravega 只会将元数据而不是完整数据写入长期存储。从结果上看,跳过了对长期存储的数据写入使得 Pravega 的吞吐量大大提升(350MB/s)。
在单一 Segment 的条件下,Pulsar 开启分层存储后的性能比其它二者都高,因为当分层存储饱和后它不会进行限流。稍后,当我们展示历史读取的相关结果时,这个问题会变得更加明显。
相比于 Kafka 和 Pulsar,Pravega 在使用多 Segment 的情况下取得了很高的写入吞吐量。Pravega 的吞吐量在很大程度上依赖于长期存储的吞吐容量,当长期存储饱和时,Pravega 会施加反压以避免数据积压。长期存储是 Pravega 架构的组成部分之一,而 Pravega 会根据长期存储来调整系统的整体性能。
6 尾部读取
6.1 低延迟的并行读取
对于许多应用,要求事件从生成到被读取和处理之间的时间间隔必须很短。我们将这一时间间隔称作端到端的延迟。流式缓存,即 Segment Store 所使用的自研缓存,在端到端延迟中起着关键作用。我们在 100 字节事件大小的条件下,绘制端到端延迟随吞吐量的变化曲线,并与 Pulsar 和 Kafka 进行性能对比。
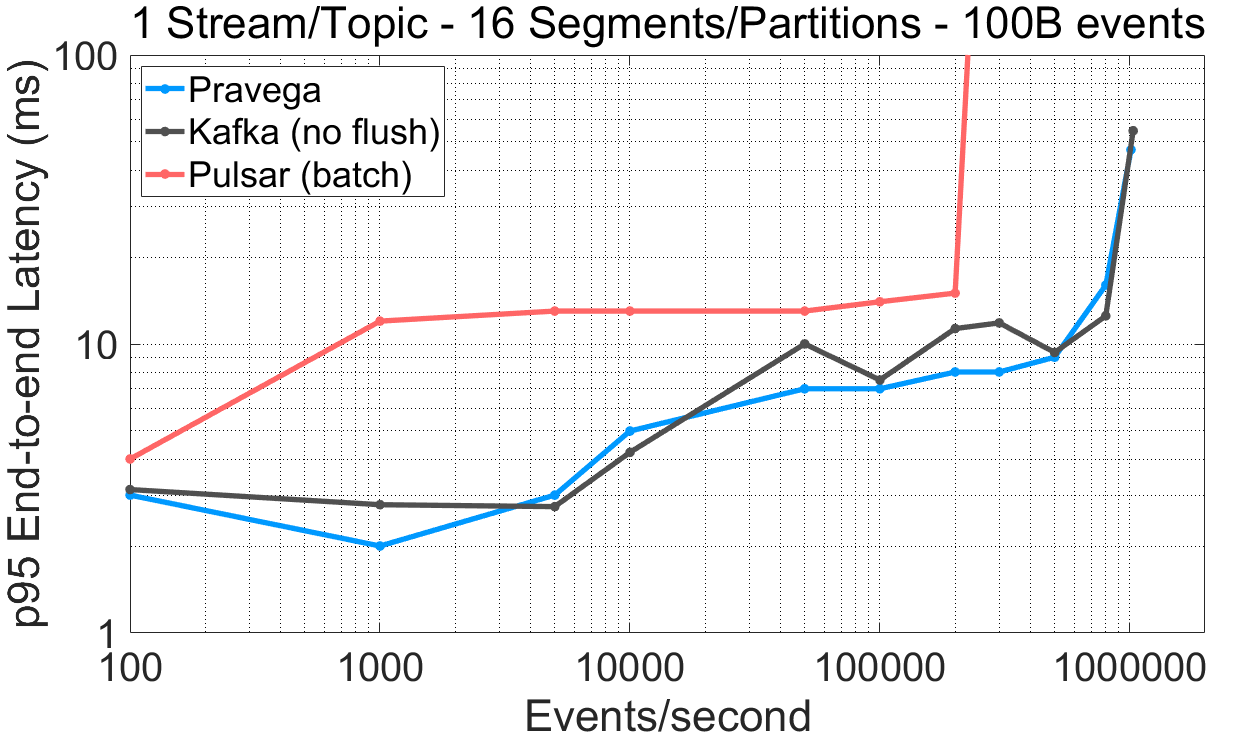
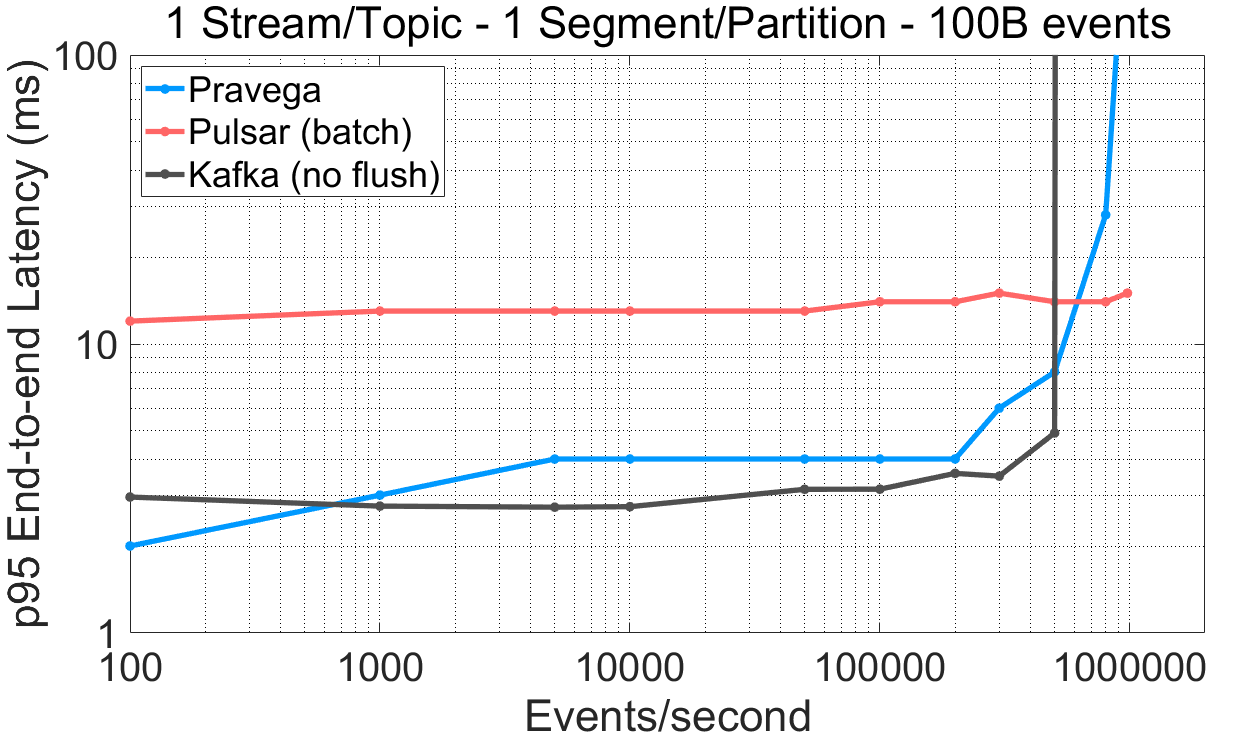
图 6 各系统的端到端延迟随吞吐量的变化曲线。
在这些实验中,我们强调如下要点:
对于单一 Segment/Partition 的 Stream/Topic,Pravega 与 Kafka 直至性能饱和点都展现出比 Pulsar 更低的端到端延迟。Pulsar 甚至在批处理开启的情况下都未能取得小于 12 毫秒(95%分位数)的端到端延迟。
对于单一 Segment/Partition 的 Stream/Topic,Pravega 的读取吞吐量比 Pulsar(56%)和 Kafka(72%)高许多。
有意思的是,在 16 Segment/Partition 场景下,Pulsar 相比于单一 Segment/Partition,读取吞吐量下降了 76%,尽管在所有系统中我们都配置了每 Segment/Partition 一个消费者线程(更高的并行度)。在 Kafka 的用例中,管理多个 Segment 增加了端到端延迟。
对于 16 Segment/Partition,Pravega 取得了与 Kafka 相近或更优的端到端延迟。注意,Pravega 的流式缓存并发地服务于尾部读取以及长期存储的异步写,而 Kafka 不进行任何分层存储操作。
相比于 Kafka 和 Pulsar,Pravega 提供更低的端到端延迟,因此能够满足那些延迟敏感的应用对尾部注入数据的需求。
6.2Reader 的读取顺序保证
许多应用需要对具有相同键的事件保证顺序,以便能够在保证事件正确处理的前提下提升并行度。Pravega、Pulsar 和 Kafka 三者都使用路由键,并保证每键的全序关系。
接下来,我们比较 Pravega、Pulsar(有批处理)和 Kafka(无刷新)三者在 OpenMessaging Benchmark 分别关闭路由键(NO_KEY)与使用随机键(RANDOM_NANO,所有实验默认使用)两种情况下的读取性能。
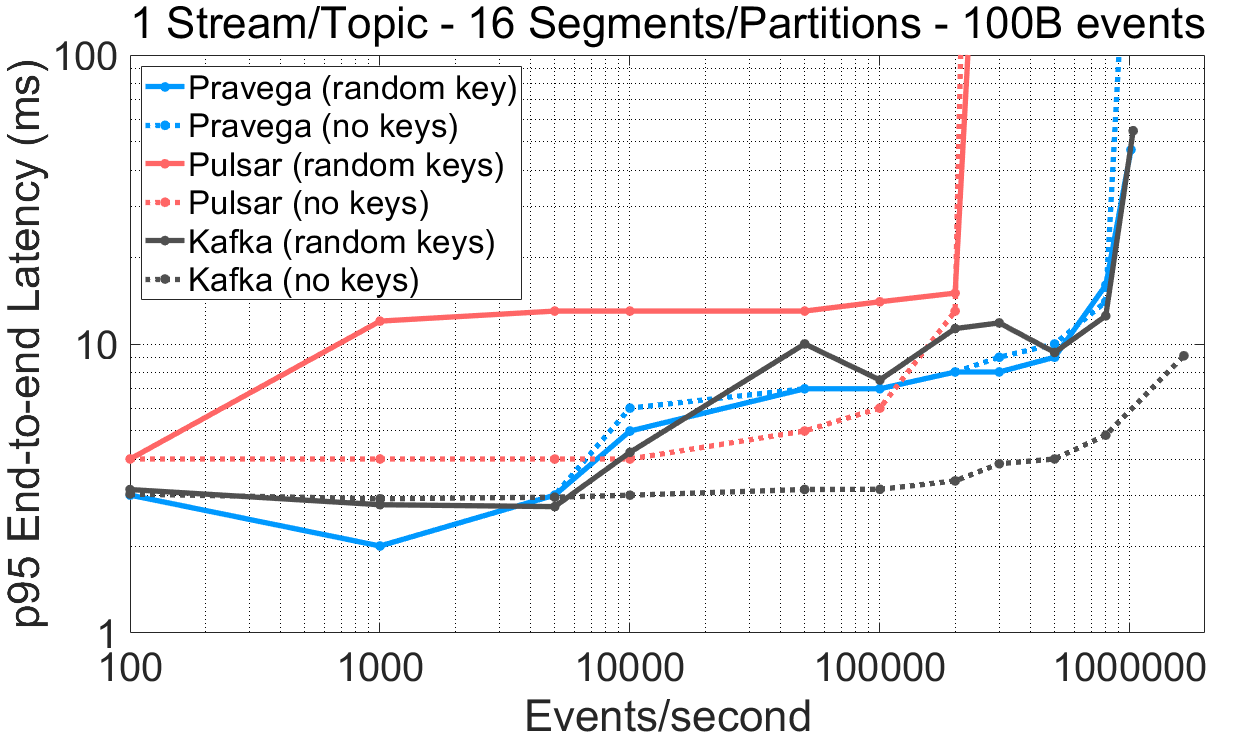
图 7 路由键对性能的影响。原始表格数据连接:表格数据。
该实验与先前实验相同,仅仅将 OpenMessaging Benchmark 中的路由键方案由 RANDOM_NANO 变更为 NO_KEY。基准数据集的原始输出连接如下:kafka-nokey-nosync,pulsar-nokey-batch,pravega-nokey。
以上结果揭示了不同系统在有无路由键条件下的性能差异:
对于 Pulsar 来说,与不使用路由键相比,使用跨 Partition 的多个路由键会招致显著的读取延迟开销。无论在大事件还是小事件的条件下,这一现象都非常明显。
对于 100 字节的事件,当 Kafka 不保证顺序(NO_KEY)和持久性(无刷新)时,在 16 Segment 场景下的读写性能更高,无论是延迟还是吞吐量。
根据Pulsar和Kafka的文档,当不使用路由键时,它们的客户端会采用批处理机制,因为它们是基于批而不是事件将负载分发到不同 Partition(循环方式)。这一决策似乎同时还影响了 Reader 的性能。
如果应用程序需要跨多个 Segment 的路由键来保证顺序,Pravega 似乎并未受到显著影响,这使得它的性能在多个应用场景下表现一致。
Kafka、Pulsar 和 Pravega 都基于路由键保证严格的事件顺序。然而,当一个工作负载在 Pulsar 或 Kafka 中交替使用多个路由键写入事件时,性能会比不使用路由键低。当存在多个并行的 Segment/Partition 时,这一观测结果尤为明显。相反,Pravega 的性能无论使用还是不使用路由键都表现一致。由于许多应用都使用路由键确定顺序,因此突出不使用路由键与使用不同分布(例如,均匀分布,重尾分布,严格子集等等)的路由键所带来的性能差异就显得非常重要。我们并非宣称 RANDOM_NANO 是现实场景中的具有代表性的选择,但相比于 NO_KEY 选项它确实表现出一些不足,并且进一步给系统带来了压力。
7 历史读取和追赶读取
在这一组实验中,我们分析了 Pulsar 和 Pravega 的 Reader 从长期存储请求历史数据时的性能(直到本文写作时,Kafka 仍旧没有在其开源版本中提供此功能)。我们设计实验如下:
OpenMessaging Benchmark 有一个名为 consumerBacklogSizeGB 的选项,允许起始时暂停 Reader 直到 Writer 写入了指定数量的数据。Reader 随后开始运作,并且当积压消息被全部消费后,实验结束。我们配置 Writer 以恒定 100MB/s(10KB 事件大小)速率向一个 16 Segment/Partition 的 Stream/Topic 写入数据直至积压值达到 100GB。注意,当 Reader 开始运作时,Writer 仍继续写入数据,因此 Reader 的读取速率需要超过写入吞吐量才能完成追赶。
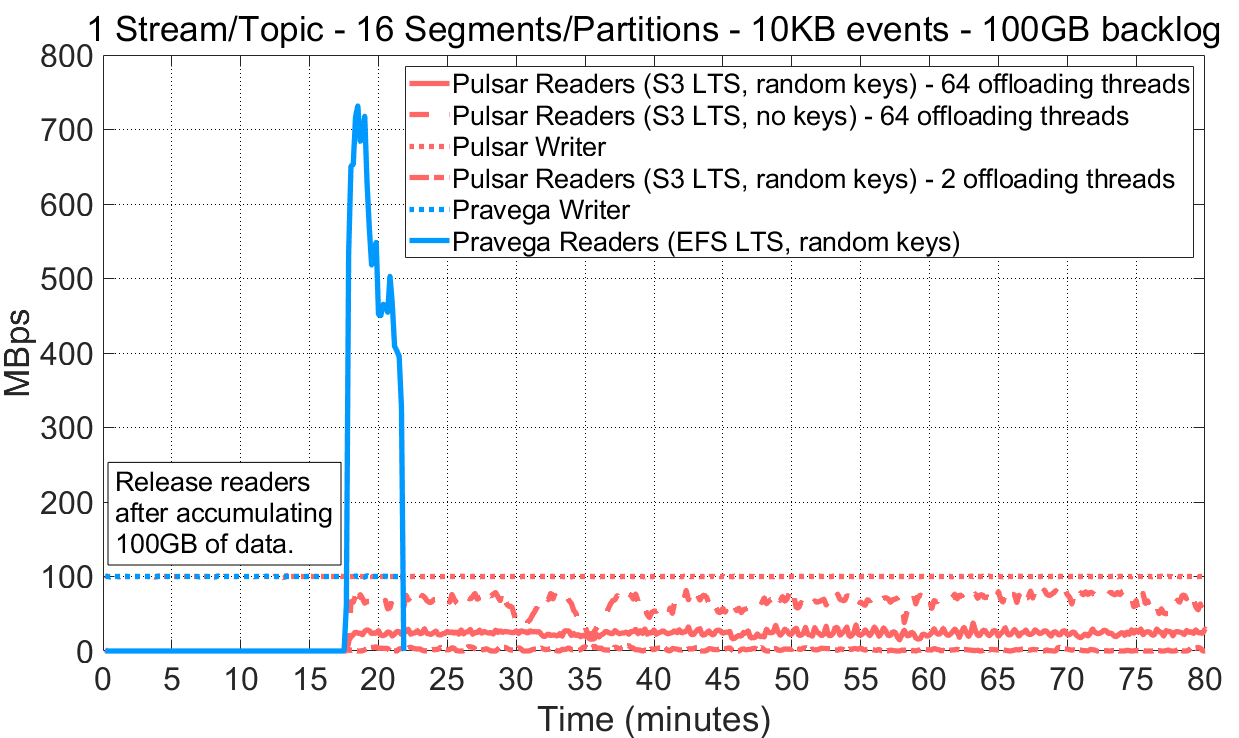
图 8 历史读取与追赶读取的性能。
该实验可以使用Pulsar的工作负载文件和Pravega的工作负载文件作为输入,通过P3测试驱动进行重现。基准数据集的原始输出链接如下:pulsar-nokey-64threads-historical,pulsar-randomkey-64threads-historical,pulsar-randomkey-2threads-historical,pravega-randomkey-historical。
在观察了 Reader 从长期存储读取数据的行为之后,我们强调如下要点:
相比于 Pulsar,Pravega 取得了高得多的长期存储读取吞吐量。对于 Pulsar,我们尝试了不同的分层存储配置参数(例如分类账簿的翻转等),但得到的结果都是相似的。同时,我们比较了 EFS 和 S3 的吞吐量,得到了与单文件/对象传输类似的吞吐率(大约 160MB/s)。这意味着三个系统之间如此巨大的历史读取性能差异并不是长期存储导致的。
当长期存储无法吸纳注入流量时,Pravega 能够对 Writer 进行限流。Pulsar 并未实现该机制,这将导致不同存储层之间出现不均衡的情况。如上述结果所示,Writer 的写入比 Reader 的读取更快,因此待读取的消息开始出现无限积压。
从图中可见,诸如数据卸载线程数以及路由键此类的配置会显著影响 Pulsar 的历史读取性能。然而,Pulsar 目前却没有明确的指南指导用户该怎样配置分层存储。
Pravega 和 Pulsar 都提供了将历史数据移动到长期存储层的方法。Pravega 相比于 Pulsar 达到了更高的历史读取吞吐量,并且允许对各层的 IO 访问进行控制,因此避免了注入积压的发生。Pravega 无需用户干预或者复杂的配置就能够透明地做到这一点。如前文所述,我们目前尚没有开源版本的 Kafka 可用于同类比较。
8 Pravega 的自动扩展机制:让 Stream 具有弹性
通过 Stream 的自动扩展机制实现随时间对负载波动进行适配是 Pravega 特有的功能。在大数据注入面前,Pulsar 和 Kafka 此类系统由于该特性的缺失,会给用户带来极大的运维负担,尤其是在应用规模较大的情况下。
我们在本小节将专注于 Stream 的自动扩展机制对性能带来的影响。我们在 OpenMessaging Benchmark 的 Pravega 驱动中开启自动扩展标志(enableStreamAutoScaling)。我们设置每个 Segment 上的目标事件吞吐率为 2,000 事件/s(也就是 20MB/s,因为本次实验的事件大小为 10KB)。基准测试集工具以 100MB/s 的速率写入。注意,为了生成如下图表,我们使用了导出到 InfluxDB 和 Grafana(每次实验都会部署,用作分析)的一些 Pravega 指标数据。
下面的三张图表显示了 Stream 扩展的不同方面:1)每个 Segment Store 的写负载;2)流中的 Segment 数目;3)OpenMessaging Benchmark 感知到的写延迟。
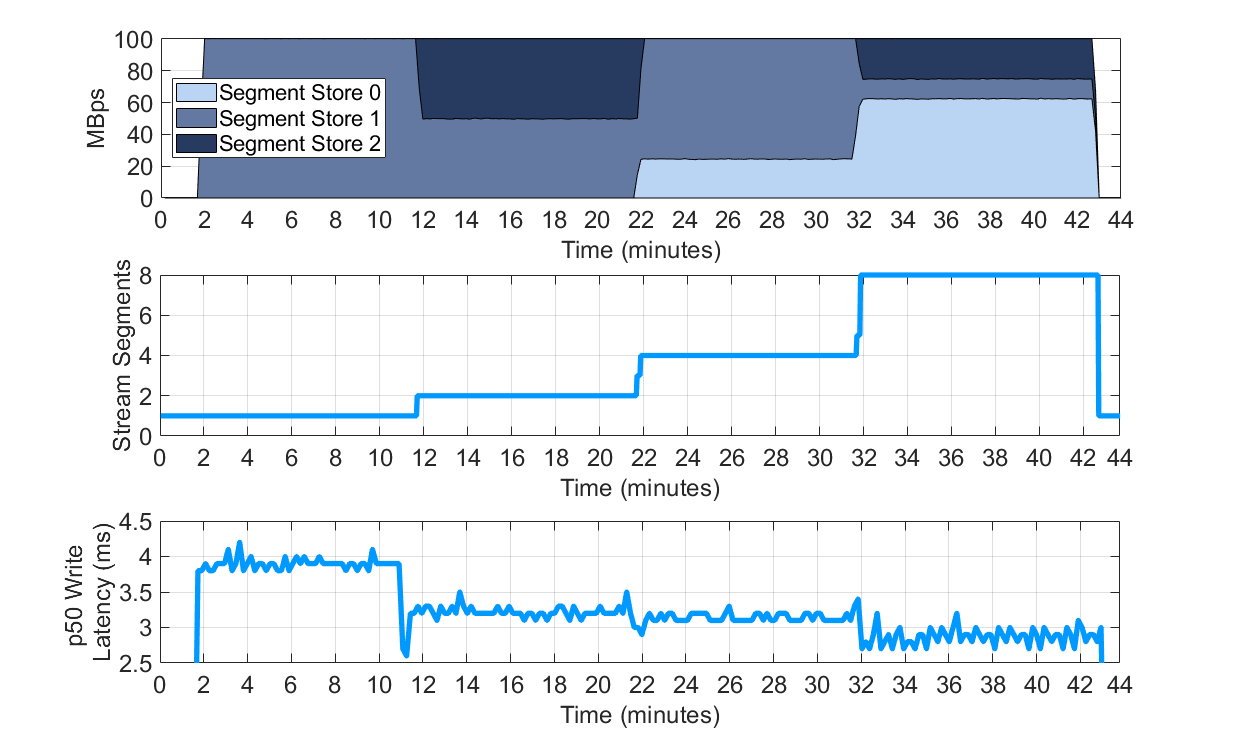
图 9 Pravega 的 Stream 自动扩展机制对性能的影响。
该实验可以使用 Pravega 的工作负载文件和配置文件,通过P3测试驱动进行重现。基准数据集的原始输出链接如下:原始输出。
我们强调本次实验的一些要点:
直至本文写作时,Pravega 是唯一能做到基于目标速率动态、透明地对 Stream 进行重分区并同时保证 Segment 顺序的系统。诸如Pulsar和Kafka此类的系统,对 Topic 重分区需要人工干预。
随着 Pravega 分裂并加入更多的 Segment,当前负载被分布到各个可用的 Segment Store 上,使得延迟大大降低。
Pravega 中的 Segment 分布是无状态的,基于一致性哈希方法。
Stream 在系统内的精确分布依赖于可用的 Segment Store 数目以及 Segment 容器的配置。只要 Segment 容器还有空闲空间,让多个 Segment 落在同一个 Segment 容器内就能够为 Stream 提供额外的容量。为某个部署添加更多的 Segment 容器能够增加并行度,因为不同的 Segment 容器会写入各自独立的持久化日志,并且能够增加 Stream 扩展时两个 Segment 落在不同 Segment 容器的概率。较大的 Segment 数目同时还增加了负载在各个 Segment Store 和 Segment 容器上均匀分布的概率。
9 总结
流式数据处理要求达到低延迟和高吞吐,Pravega 可以同时达到这两个需求。单个 Pravega 的 Writer 可以持续产生超过每秒一百万事件,95%分位数的延迟小于 10 毫秒。它能根据注入负载自适应地调整批处理,无需用户事先为应用选择配置高吞吐或者低延迟。将流数据分层存储到长期存储中是 Pravega 架构的组成部分之一,这对历史数据的处理来说是必需 。Pravega 允许 Reader 对大量积压数据进行追赶读取,同时 Writer 保持每秒数百兆字节的写入,并且保证长期存储能够支撑这样的注入速率。无论使用还是不使用路由键,Pravega 都能保持上述性能特征。
当把 Pravega 的性能结果与其它系统(即 Kafka 和 Pulsar)进行对比时,我们发现这两个系统在使用和不使用路由键两种情况下的性能有着很大差异。对于这两个系统,当使用路由键的时候,延迟增长了一倍,尤其是 Kafka,读取吞吐量下降了三分之一。
Kafka 现有的持久化特性并不十分有效,因为相比于 Pravega 它表现出相似或者更低的吞吐量,但延迟更高,而 Pravega 总是保证数据的持久性。Pulsar 要求应用程序在低延迟和高吞吐量之间做出选择,并且在多 Partition 的情况下提供了更低的端到端延迟。
类似分层存储和扩展机制这样的特性在处理历史数据和提供流弹性方面是十分有效的。在本文涉及的三个系统中,Pravega 是最先提供分层存储特性的,其它两个系统随后效仿。我们测试了 Pulsar 的分层存储实现,但始终无法获得合理的吞吐量,并且还观测到了数据积压。Stream 扩展目前仍旧是 Pravega 独有的特性。
尽管本文已经覆盖了相当多的内容,但性能评测并不是一项简单的任务,因为有太多不同的维度需要覆盖,并且系统性能也会随着源码变化而向前演化。本文仅仅专注于基本的读写功能,因为我们相信这是一个流存储系统最为基础最为重要的功能。
最后,期待我们未来新的功能和新的文章吧。
References
[1] J. Paulsen, “Enormous Growth in Data is Coming — How to Prepare for It, and Prosper From It,” April 2017. [Online]. Available:https://blog.seagate.com/business/enormous-growth-in-data-is-coming-how-to-prepare-for-it-and-prosper-from-it/.
[2] S. Condon, “By 2025, nearly 30 percent of data generated will be real-time, IDC says,” Novenber 2018. [Online]. Available:https://www.zdnet.com/article/by-2025-nearly-30-percent-of-data-generated-will-be-real-time-idc-says/.
[3] S. Condon, “By 2025, nearly 30 percent of data generated will be real-time, IDC says,” Novenber 2018. [Online]. Available:https://www.zdnet.com/article/by-2025-nearly-30-percent-of-data-generated-will-be-real-time-idc-says/.
[4] N. Yigitbasi, M. Gallet, D. Kondo, A. Iosup and D. Epema, “Analysis and modeling of time-correlated failures in large-scale distributed systems,” in11th IEEE/ACM International Conference on Grid Computing, 2010.
[5] F. P. Junqueira, I. Kelly and B. Reed, “Durability with BookKeeper,”*ACM SIGOPS Operating Systems Review,*vol. 47, no. 1, pp. 9-15, 2013.
[6] A. Iosup, N. Yigitbasi and D. Epema, “On the performance variability of production cloud services,” in11th IEEE/ACM International Symposium on Cluster, Cloud and Grid Computing, 2011.
[7] R. Gracia-Tinedo, “SDGen: Mimicking datasets for content generation in storage benchmarks,” in13th USENIX Conference on File and Storage Technologies (FAST’15), 2015.

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论 1 条评论