

本文整理自 2019 年 8 月份举行的 MOGU DDay 分享算法场报告。基本涵盖了蘑菇街内容信息流排序算法一整年的关键算法迭代之路;同时我们所走的演化之路刚好契合召回、排序的各三阶段典型迭代路径。经团队审核资料可以公开,故而整理在此,期望与大家多交流。
介绍
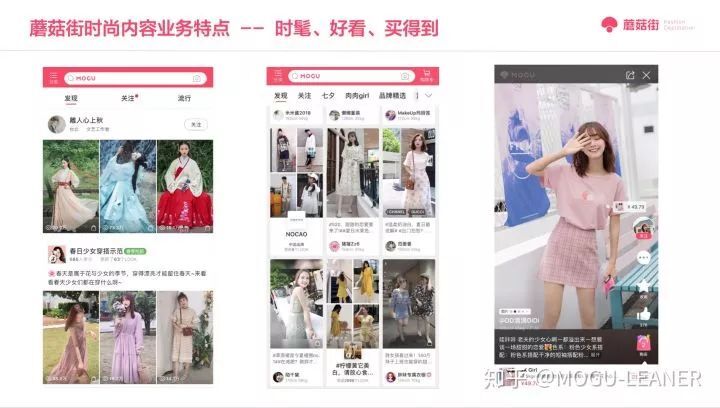
蘑菇街的首页内容秉承为了让更多人因向往时尚而使用蘑菇街的目标,为用户提供时髦、好看、买得到的价值。下面 slide 中前两个图截取了我们 app 早期的一拖三的达人聚合内容形式,到以内容图强瀑布流的形式的变动,这种产品上的变化对我们算法和工程架构的影响还是蛮大的。第三个图就是点击内容的全屏页的效果,用户可以点赞、评论、分享,如果喜欢内容中的单品,还可以被种草而买买买,继续下滑则是可以发现更多惊喜的相关“内容推荐”。
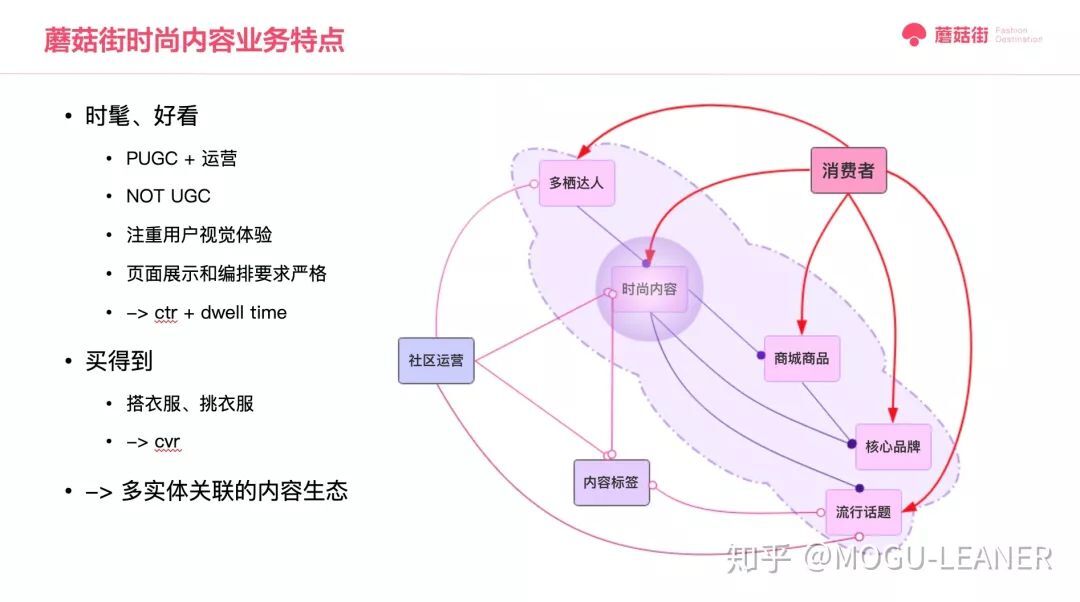
那如何将“时髦、好看、买得到”转化到我们的算法指标呢?内容社区对“时髦好看”这个基本题的解法是 PUGC 运营,即我街给用户呈现的都是所招募的 KOL 发表的、经过运营审核的、满足精选条件的内容,这与知乎、小红书等这种 UGC 的社区生产内容方式是不同的。
在这种模式下,内容排序算法追求的“时髦好看”,我们可以理解为 Ta 的内容力,也就是用户确实喜欢看并且看得多看得久。继续拆解下来,首页的基本指标就是内容点击率(ctr)和用户停留时长(dwell time)。进一步来讲就是:首页曝光 pv+首页点击 pv+点击二级页面停留时长。当然,业务角度考虑用户喜欢则留存、核心用户相关指标十分重要,然而这些指标一方面是中长期指标短期实验不可观测,另一方面 ctr+dwell time 的短期指标与中长期指标也具有一定的相关性。因此,我们与业务方沟通锚定短期指标,持续观察长期指标。
对于“买得到”,就是内容希望能够帮助用户搭衣服、挑衣服,我们可以理解为 Ta 的商品力,也就是内容排序的同时需要考虑内容的买买买价值。这个我们可以转化为内容的 cvr,内容力和商品力双高的内容必然是高价值的,然而现状是部分内容并不关联商品,关联商品的内容的种草也有需要一定的积累阶段,并且从首页内容展示到内容点击再到商品曝光点击,对于关联商品的 cvr 数据链路不同于以往纯电商图强场景。此外,业务为了让达人赚到钱,开启了 cpo 商品分佣计划,则不同商品放到不同内容上的价值考虑就更加多元化了。
可以说我们服务的业务的特点是:内容生态是多实体关联的、我们的优化是多目标并进的。这里简单画出整个内容生态的各种实体及关系。从消费者视角来看,可见实体包括:多栖达人(图文 look 达人、短视频达人、直播达人)和这些达人在平台上生产的时尚内容(包括主播达人的直播间),达人在生产内容的同时会选择内容中的商城商品、对应的时尚品牌、和达人自选的内容标签。社区运营会综合社区调性和内容的各方面情况审核内容并对内容打标签。除此外,社区运营会定期将标签和内容组织相应的流行话题,以将当下具有话题性的、潮流的、专题性的内容以聚合的形式展示出来。
总体来说,首页算法综合进行排序的实体包括:时尚内容、直播间、核心品牌、流行话题,而排序的过程中需要考虑到达人、商品、标签在内的各实体的关联关系。
因为商品排序也是我们团队负责的,那不可避免地我们会想:内容信息流排序与商品排序有何异同呢?
相同的地方很明显:他们都是排序问题。既如此,那整体的架构和方案就具有相似性。都可以采用推荐的两步曲:matching + ranking。既然内容和商品排序可以落入相同的框架下,那么我们就可以复用以往的经验、可以沿着共同的技术演进路径,在每个迭代点上可以借鉴以往的经验做决策。
But,事实上呢,毕竟“No Free Lunch”!前面提到了我们的内容社区的特点和整个生态组成,大家可以看出相对于商品排序,用户对内容的可能就是预期不一样的。内容消费的用户成本就很不相同。也就是说业务形态不同,我们所关注的指标不同,所梳理的评估体系也有不同,我们的实践中确实也遇到过多次“相同的执行路径在商品和内容排序得到不同的结果”的经历。

我们看一下业界的主流推荐框架 Marching + Ranking。这个主流程我们就借用 YouTube 里的流程图表示。当用户请求时,matching 先根据用户的历史行为和场景等上下文从较大物料池子选出较小的候选集,然后再综合候选集合数据和用户行为进行 ranking。
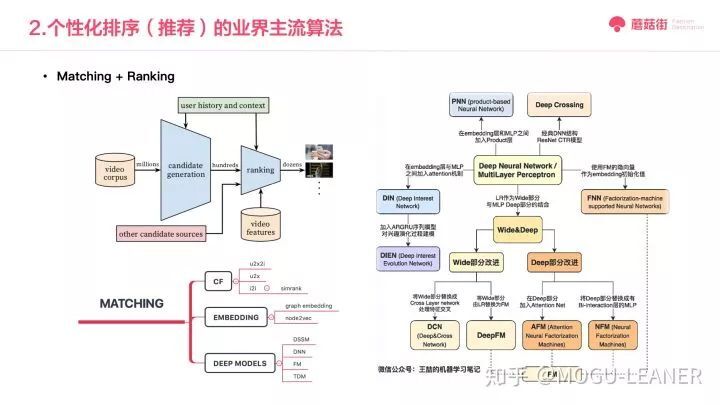
Matching 的主流演进路径如下:
第一代是协同过滤方法及其变型,包括 swing、simrank 等,主要就是根据启发式规则定义出两个物料的相似度并离线算出每个物料最相似的物料,则用户点击过物料 A 就可以召回其相似物料;
第二代是 embedding 及其变型,包括 graph embedding、node2vec 等,就是脱离规则和直接用物料 id 表示的方法,模型将每个物料学习一个低维表示,模型保证相似的物料在这个低维空间里距离很近,通过这些方法可以更好地算出给定物料的相似物料;
第三代召回模型是深度模型,包括 dssm、YouTubeDNN、TDM 等,因为第二类方法还是学习一个物料的表示么,那第三类方法就研究怎么给你一个用户直接算出来应该召回哪些物料,而不是事先计算好,因为刻画能力强和结构表达性而效果更佳。
对于 Ranking,这里就偷懒借用 @王喆同学整理的第一版笔记,他主要整理的在 wide&deep 基础上的各种模型变种;因为与我们尝试的路径匹配度比较高,至于后期的 transformer 及 lifelong modeling 我们未取得线上结果而暂不表。总体上来说我们的排序模型的演化与业界的 ctr 预估 max 模型的三代变更也是高度一致。这方面知乎区里已经有很多小伙伴进行了很多更详细的梳理,因而就不再赘述。
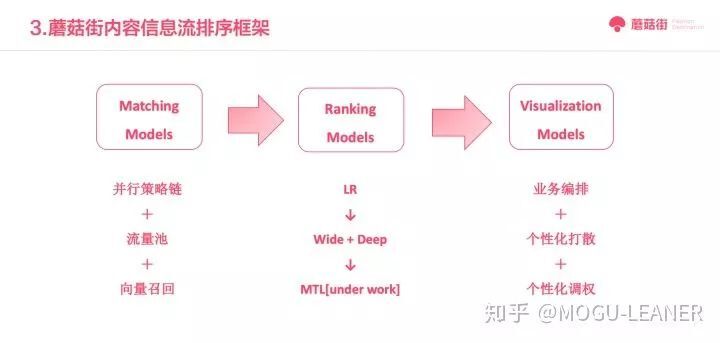
我们把首页内容框架分为三部分,在 matching 和 ranking 的基础上加了一个 visualization 层,包括:业务编排、个性化打散、个性化调权等功能,以满足首页的多类型多实体多业务目标的调整。在 matching 层,我们做了并行策略链组合流量池和向量召回的布局,以解决高效个性化、多样性、内容时效性、特殊业务扶持等多目标要求。在 ranking,我们从 LR 到 WideLR、WIDE+Deep 模型的尝试,并尝试多目标学习排序,总体上来说持续优化匹配效率,让用户能够匹配到最适合的 KOL、内容、话题等。
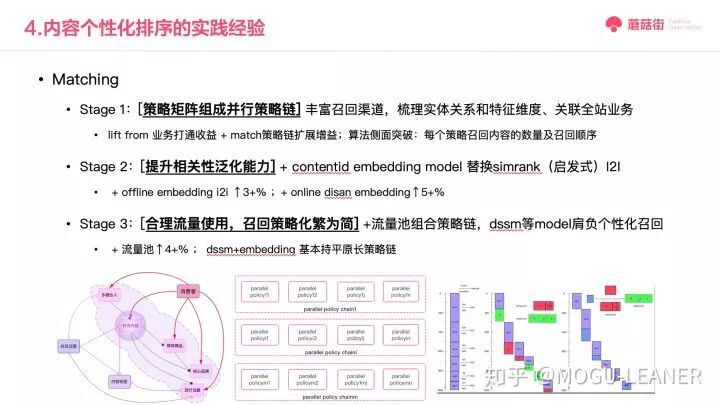
在召回环节,我们最先根据商品推荐的思路,部署了策略矩阵组成的并行策略链,根据梳理的实体关系和相关维度,关联到全站业务数据,打通各个业务场景的数据链路。这个阶段,算法的收益主要来自于新增召回策略带来的增益以及调控策略的顺序和比例,以最简单易并行的方式铺开特征,解决业务覆盖问题。然后,为了进一步提升相关性的泛化能力,我们尝试了利用内容 embedding 模型替换 simrank 这一启发式 i2i 方法,这其中又包括离线的 embedding 方法和在线的 embedding 方法,前后分别带来了线上 3%和 5%的提升。
最后,为了合理流量利用效果,考虑将召回策略化繁为简,从视频推荐开始,我们着手进行流量池召回方案,兼顾个性化、时效性、多样性、特殊业务扶持等目标,解决以往为保证时效性、业务扶持做的全局加权带来的整体线上指标下降问题,带来了线上 4%的效果提升;在此基础上,我们继续尝试将原个性化流量池下的冗长个性化策略链进行精简,通过 deep model 方式召回以替代原数十个策略也未必兼顾到各个属性维度的问题,最终 dssm+embedding 与原策略链效果持平,这为我们后续进一步通过模型优化召回开启了新的篇章。
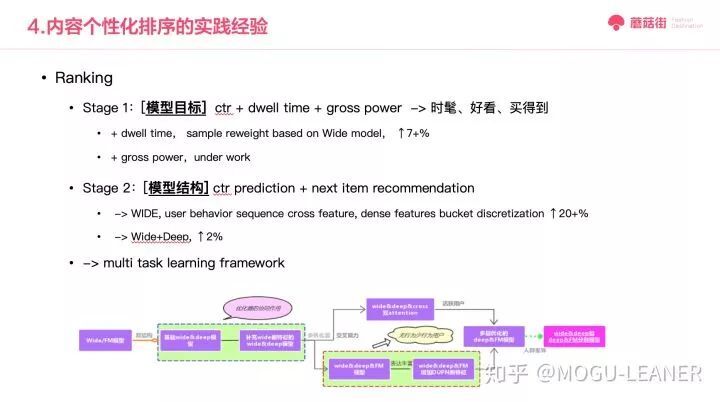
在排序环节,最初我们采用了商品推荐排序经典思路,即稠密特征加简单 LR 的方法,这个思路快速上线,且特征可以复用召回环节。同时,我们开始与业务梳理内容的整体模型目标,在 ctr 基础之上增加停留时长的模型,最初我们通过新增特征和模型也带来了停留时长,但是却是因为 ctr 增长带来的。在确定停留时长的关键指标后,我们着手将停留时长加入模型优化目标,通过在 WIDE 模型基础之上进行 reweight 样本将其引入到目标函数,带来了 7%的停留时长提升。在模型结构方面,借鉴商城的做法,通过行为序交叉的大规模离线特征 LR,带来了线上 20%的提升;进一步将模型扩展到商城比较成功的 Wide+Deep 模型,线上仅带来 2%的提升,这方面我们还需要结合首页业务和特点进一步探索与尝试。
在整个实践过程中有一些经验与大家共享,相对于算法模型细节方面,更重要的点在于:
第一要务,就是数据埋点和日志打点,正确且合理地埋点异常重要,实时特征打点异常有用。这是产品、客户端、后端、质控、数仓、BI、以及算法共同参与的、琐碎繁杂的工作。
第二要务,就是要基于产品形态特点选择构建样本和模型,毕竟 No Free Lunch。产品和交互的重要性我们都能理解,我们都是基于产品特点做模型;而用户体验的反馈也是雪中送炭,珍视每一次用户反馈以及反馈问题的小伙伴。
第三要务,就是吾之利器投向何方,需要对业务问题的理解以及与业务同学的充分沟通和共识达成,当然在这个过程里,在确定了要解决什么业务问题的首要任务后,模型的可解释性就特别重要了,总之我们还是要对自己的定位和价值心里有点数的。
最后,以上工作系我街推荐小分队工作共同努力的结果。回顾内容排序算法这一整年,小分队可以说做到了在关键节点上都取得了结果并提升了业务目标、在高强度支持了 30 多个班车功能的同时团队能够持续技术迭代和多面成长。虽然也存在一些遗憾和短板之处,但我相信这些会驱动我们在未来走的更远!
本文授权转载自知乎专栏“深度推荐系统”。原文链接:https://zhuanlan.zhihu.com/

Java 避坑指南:Java 高手笔记代码篇
本迷你书包括 86 个业务开发中常见踩坑点。每一个知识点都相当的实用,是程序员业务开发中的必备避坑指南...











评论