前段时间的 QCon 北京 2011 大会里面有个探索式测试的分享,是 Erik Petersen 演讲(资料下载)的,我由于一些原因,没有在现场向大师学习,之后发现他讲的非常好,效果也很好,引起了很多人对于探索式测试的兴趣。这里也感谢 InfoQ 的给力,我把了 Erik 的 PPT 看了两遍,有非常深刻的体会。也确实在某些方面开导了我。自己本身学习探索式测试快一年有余了,也不乏和国外的 ET 的一些大师 (James Bach, CemKaner) 进行交流。
这里我先抛一个问题出来:为什么产品提交到测试这边,我们的测试工程师可以发现很多开发或用户都发现不能的 Bug 呢?大家可能觉得这个原因肯定有很多,比如有这些:
- 我们是测试工程师,我们是专门干这个的
- 我们很好地理解了需求,我们使用了很多且很好的测试设计技术
- 我们有较多时间进行测试执行
- 开发人员或用户没有时间去进行测试
- 开发人员或用户没有时间不知道怎么去进行测试
- 我们的运气好,突然发现了这些好的 Bug
(当然还有很多其他的因素,这里就不列出所有的了)
那么再有一个问题出来:为什么有些测试人员能发现其他测试人员不能发现的 Bug 呢?大家可能觉得这个原因肯定有很多,比如有这些:
- 其他测试人员对于业务需求不熟悉,该测试人员对于业务非常精
- 其他测试人员没有很好的状态,注意力不够集中
- 其他测试人员的测试经验较少,该测试人员测试经验非常丰富
- 其他测试人员的运气不怎么好,该测试人员是突然灵感出来发现的
- 其他测试人员的测试环境和测试数据不一样
(当然还有很多其他的因素,这里就不列出所有的了)
同样的问题还有很多,比如:为什么我们很多好的 bug 都不是通过我们已经写好的测试用例发现的呢?其实这里面我并不是想去搞清楚很多不同的原因,根据 80/20 原则,我只想关注一个主要的,那就是经验丰富的测试工程师是如何进行测试的,是如何进行探索式测试的,他们的思维过程到底是什么样的,和我们通常的测试有什么不一样的。
很多人都会问到底什么是探索式测试,也有很多人知道很多时候我们就是在做探索式测试 (只是我们自己不知道而已),不管怎样,我们都期望把很好的测试方法或手段传承下去,让新加入测试行业的同学都可以吸收这个武林秘籍。根据看 Erik 的 PPT,我这边大概抽象了下探索式测试的思维过程:
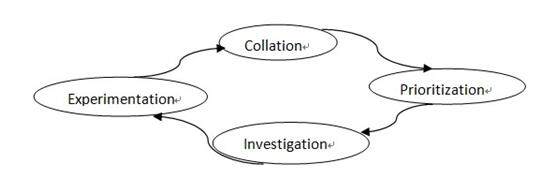
这个思维模型简称为 CPIE
简要说明:Collation,这个 action 注意就是我们需要收集所有关于 SUT 的所有信息,去了解和理解。
Prioritization,我们要对所有需要测试的任务或模块或特性进行优先级的划分,这里不说划分原则。
Investigation,划分好后,就需要对应确定即将测试的任务进行仔细的分析并预测其可能输出的结果。
Experimentation,这个 action 就是需要我们实际的去进行测试,看看我们的预测是否正确,我们的信息是否正确,就会变化到去影响 Collation 阶段。
这里面部分人看的出来,还是有点站在整个项目或产品测试的角度去进行测试,那实际上对于某个小的需求和功能,是如何进行探索式测试的呢?
这里面还需要强调的是探索式测试是一个测试方法,不是测试技术,大家都知道有很多测试技术,特别是测试设计技术,这样的话,就意味着进行着探索式测试,就可以完全使用这些测试技术,可以融合这些测试技术。
下面来看下 ET 的大师 James Bach 是怎么来看待 ET 的思维过程的:
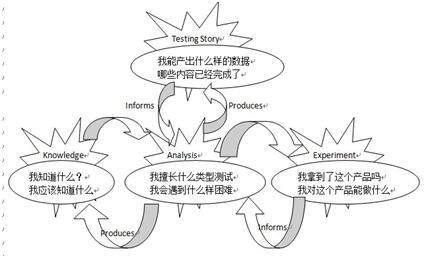
这里面可以看到和 Erik 的观点还是有很多类似的地方的,都强调 Experiment,也就是说之前我们做的再好的测试设计和用例,只要在测试执行的时候才知道好还是不好,还有没有更好的测试思路。同样可以发现这些都是一个循环的过程,ET 过程中,测试设计和测试执行是互相驱动和完善的过程,这也是和我们平时的 SBT(Script Based Testing) 的最大区别。
个人认为之所以优秀的测试人员能发现一些隐含比较深的 bug,主要有以下几个关键的因素:
- 对于基本的测试设计技术的使用达到炉火纯青的地步
- 对于错误猜测测试方法有一定的理解和应用
- 对于开发思维习惯和异常的用户使用思路有一定的了解
这里面谈到了错误猜测方法,Erik 也提到了,这个方法在 ET 过程中使用得非常普遍,也许很多人会认为该方法很大程度上依赖于个人的测试经验积累,不错,但不意味着新的测试人员不能很好地使用该方法去进行 ET。这是又回到了模型的概念了,个人理解的模型有三个层面,如下:
-
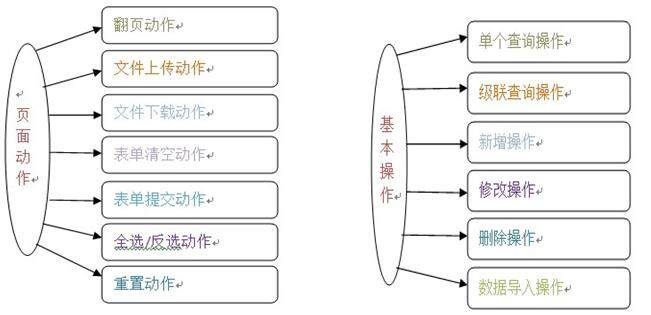
功能测试模型:一些常用功能的测试思路的大集合 (增删改查,web 页面测试等)
-
线下 bug 模型:基于线下测试发现的优秀 bug 抽象的模型 (主要针对于常出现 bug 的地方,提出注意事项)
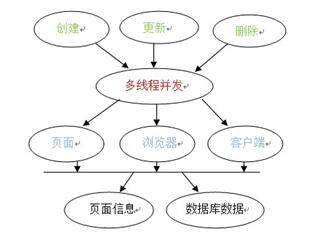
模型解释:
- 多线程创建,更新,删除某类数据, 多线程方式包括同时打开多个页面或浏览器;使用工具多线程并发操作来校验数据操作的原子性
- 多浏览器或一个浏览器里多个 Tab 进行测试,考虑 cookie 里面的值的变化是否影响后续的操作;或使用场景探索模型去多角度校验页面信息和数据库数据的正确性
- 线上故障模型:基于线上事故产生的原因进行抽象的模型 (环境较复杂和特殊,完善我们的测试设计思路和创新出新的测试方法)
目前淘宝也在做这三方面的测试模型,以应用于 ET 的培训资料,使测试经验不丰富的同学也能够快速掌握错误猜测方法去进行 ET 测试,把这些模型完全掌握且能够应用得好,那我们还怕我们的功能覆盖率不够全吗。
说到覆盖率,接下来说下 ET 在 Coverage 上是怎么考虑的。我们说的 Coverage 一般就是 Product coverage,同样也是这个被测产品的一部分。那么对于 Product coverage 又包括哪些方面的 coverage 呢?
第一个就是Structure,也就是产品的一个因素,对于这个 Structural Coverage,我们到底是测试什么呢?我们到底要 cover 什么呢?我们要测试的就是这个产品是怎么构成的,我们要 cover 的就是构成这个产品的部分。下面以打印机产品为例,看看 Structural Coverage 到底要考虑什么:
- 打印需要用到的文件
- 实现打印功能的代码模块
- 在这个模块里面的代码语句
- 在这个模块里面的代码分支
可以看到这个时候我们关注的是产品的内部结构。
第二个就是Function,也是产品的一个因素,对于这个 Functional Coverage,我们到底是测试什么呢?我们到底要 cover 什么呢?我们要测试的就是这个产品能够做什么?我们要 cover 的就是这个产品做得什么样。同样以打印机产品为例,看看 Functional Coverage 到底要考虑什么:
- 打印,页设置,打印预览
- 打印 range,打印复制,zoom
- 打印所有的,当前页,或指定的 range
可以看到这个时候我们关注的是产品的功能或特性。
第三个就是Data,也是产品的一个因素,对于这个 Data Coverage,我们到底是测试什么呢?我们到底要 cover 什么呢?我们要测试的就是这个产品能够对数据方面有什么考虑?我们要 cover 的就是这个产品能够处理什么样的数据。同样以打印机产品为例,看看 Data Coverage 到底要考虑什么:
- 打印文档的类型
- 文档里面的元素,文档的大小和结构
- 关于怎么打印的数据 (比如 zoom factor; no. of copies)
可以看到这个时候我们关注的是产品使用过程中不同的数据处理。
第四个就是Platform,也是产品的一个因素,对于这个 Platform Coverage,我们到底是测试什么呢?我们到底要 cover 什么呢?我们要测试的就是这个产品依赖什么才能使用?我们要 cover 的就是这个产品怎么处理不同的依赖的。同样以打印机产品为例,看看 Platform Coverage 到底要考虑什么:
- 打印机,Spoolers,network behavior
- 计算机
- 操作系统
- 打印机驱动程序 / 设备
可以看到这个时候我们关注的是产品使用过程中不同的环境和依赖。
第五个就是Operation,也是产品的一个因素,对于这个 Operations Coverage,我们到底是测试什么呢?我们到底要 cover 什么呢?我们要测试的就是这个产品怎么使用的?我们要 cover 的就是这个产品使用的步骤是否合理 / 正确。同样以打印机产品为例,看看 Operations Coverage 到底要考虑什么:
- 默认情况下使用
- 真实环境下使用
- 真实的场景下使用
- 复杂的流程下使用
可以看到这个时候我们关注的是产品使用的场景 (包括稳定性,可用性,安全性,可扩展性,性能,可安装性,兼容性,可测性,维护性,本地性等)。
第六个就是Time,也是产品的一个因素,对于这个 Time Coverage,我们到底是测试什么呢?我们到底要 cover 什么呢?我们要测试的就是这个产品在什么时间情况下会受影响?我们要 cover 的就是这个产品在不同的时间下会表现什么样。同样以打印机产品为例,看看 Time Coverage 到底要考虑什么:
- 尝试在不同的网络或端口的速度使用
- 一个文档打印完,紧接着打印另一个文档,或隔很长时间再打印
- 尝试与时间相关的限制,比如使用 spooling, buffering, timeouts
- 尝试 hourly,daily,月底,或年底打印报告
- 尝试从不同的 2 个工作站同时打印
可以看到这个时候我们关注的是产品使用的时候是否受时间影响。
上面我们可以看到 ET 在考虑覆盖率上还是有一点自己独特的角度,但感觉不是很具体,无细节,对于某一个类型的 Coverage 需要做出全面的分析,还有一个就是这些不同类型的 coverage 会经常组合在一起来使用的。至于组合的策略,需要在实际项目过程才能体会。
感谢张凯峰对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家加入到 InfoQ 中文站用户讨论组中与我们的编辑和其他读者朋友交流。




