

AI 前线导读: 本文重点介绍了知乎数据分析平台对 Druid 的查询优化。通过自研的一整套缓存机制和查询改造,该平台目前在较长的时间内,满足了业务固化的指标需求和灵活的分析需求,减少了数据开发者的开发成本。
更多干货内容请关注微信公众号“AI 前线”(ID:ai-front)
背 景
知乎作为知名中文知识内容平台,业务增长和产品迭代速度很快,如何满足业务快速扩张中的灵活分析需求,是知乎数据平台组要面临的一大挑战。
知乎数据平台团队基于开源的 Druid 打造的业务自助式的数据分析平台,经过研发迭代,目前支撑了全业务的数据分析需求,是业务数据分析的重要工具。
目前,平台主要的能力如下:
统一的数据源管理,支持摄入离线数仓的 Hive 表和实时数仓的 Kafka 流
自助式报表配置,支持多维分析报表、留存分析报表
灵活的多维度多指标的组合分析,秒级响应速度,支持嵌套式「与」和「或」条件筛选
自助式仪表盘配置
开发平台接口,为其他系统提供数据服务
统一的数据权限管理
目前,业务使用平台的数据如下:
自助式配置仪表盘数:495 个,仪表盘内报表共计:2399 张
日请求量 3w+
为 A/B Testing、渠道管理、APM 、数据邮件等系统提供数据 API
数据分析平台架构
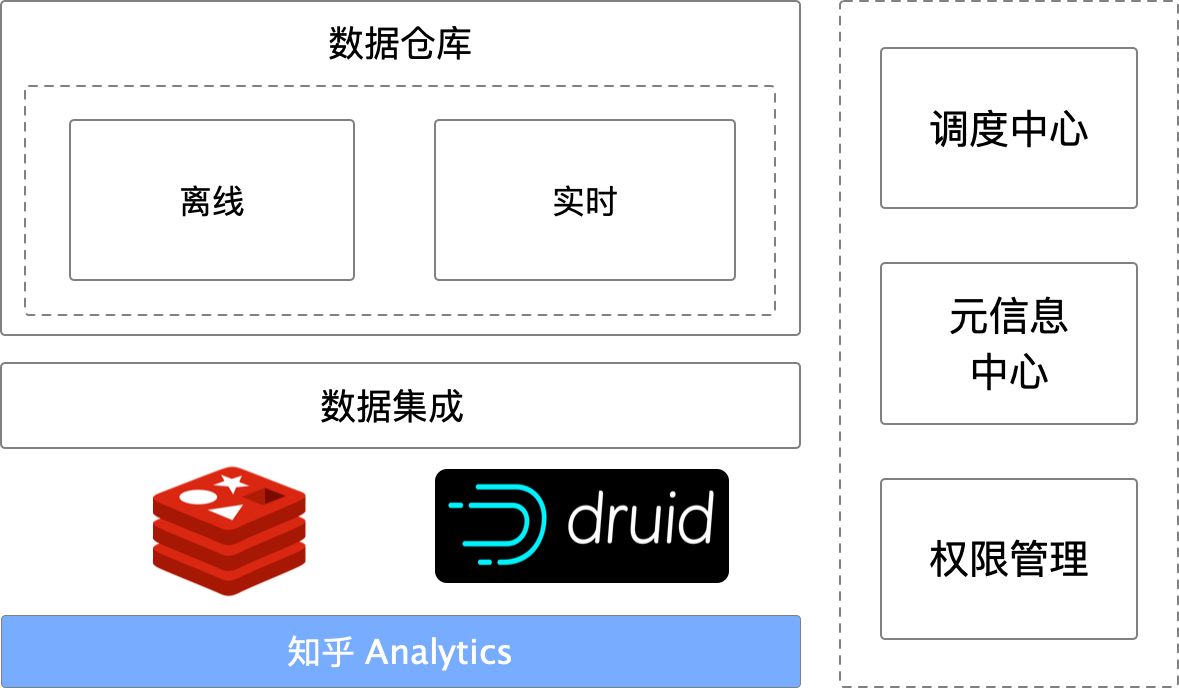
知乎实时多维分析平台架构
技术选型 - Druid
Druid 是一种能对历史和实时数据提供亚秒级别的查询的数据存储。
Druid 支持低延时的数据摄取,灵活的数据探索分析,高性能的数据聚合,简便的水平扩展。适用于数据量大,可扩展能力要求高的分析型查询系统。
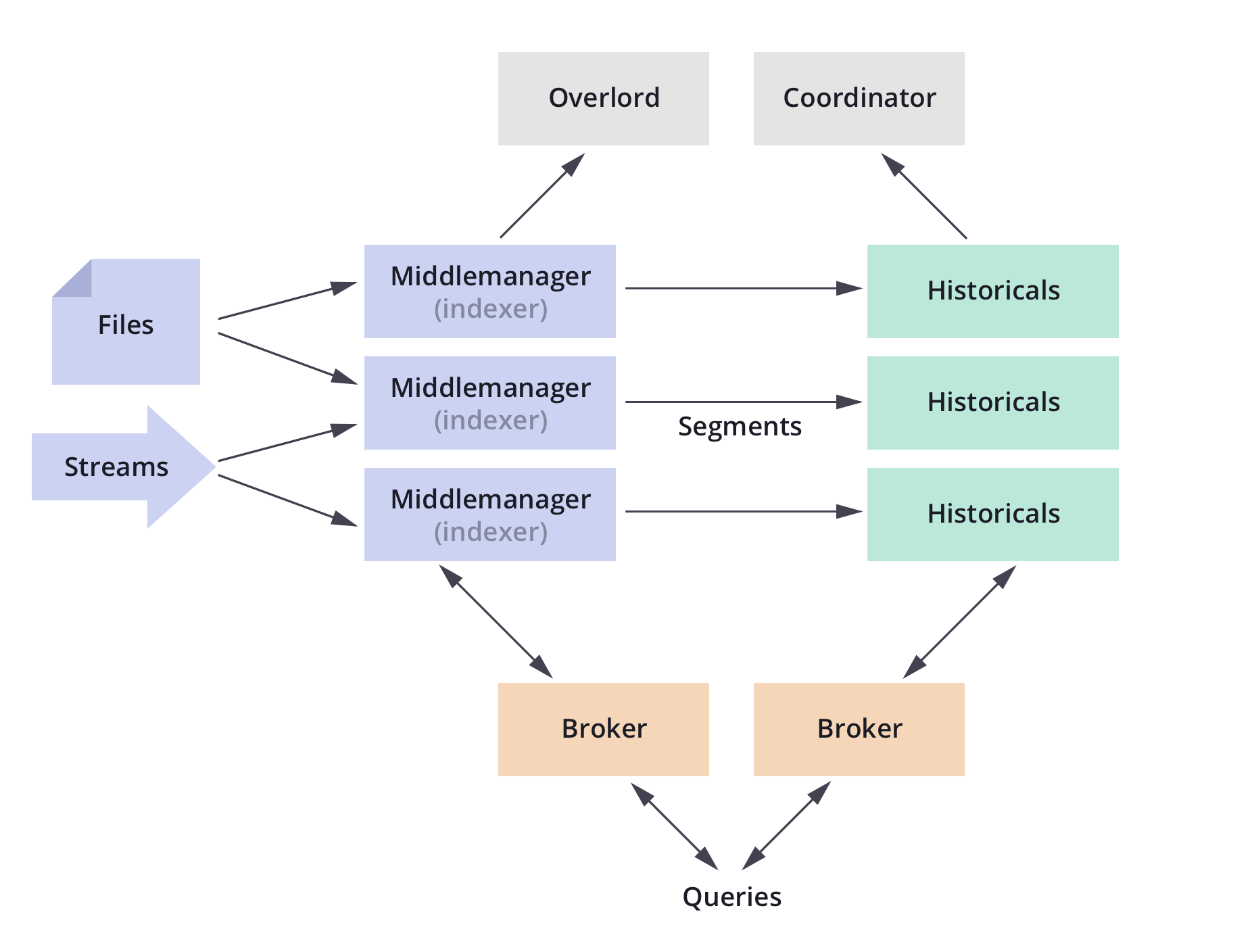
Druid 整体架构
Druid 数据结构和架构简介
Druid 数据结构
DataSource:Druid 的基本数据结构,在逻辑上可以理解为关系型数据库中的表。它包含时间、维度和指标三列。
Segment:Druid 用来存储索引的数据格式,不同的索引按照时间跨度来分区,分区可通过 segmentGranularity(划分索引的时间粒度)进行配置。
查询服务的相关组件
内部组件
Historical:用于加载和提供 Segment 文件供数据查询。
Broker:提供数据查询服务,通过路由查询请求到对应的 Historical 节点并获得数据,合并数据后返回给调用方。
Router:当 Druid 集群到达 TB 级别的规模时才需要启用的节点,主要负责将查询请求路由到不同的 Broker 节点上。
外部组件
Deep Storage:用于存储 Segment 文件供 Historical 节点下载。Deep Storage 不属于 Druid 内部组件,用户可根据系统规模来自定义配置。单节点可用本地磁盘,分布式可用 HDFS。
Metastore Storage:用于存储 Druid 的各种元数据信息,属于 Druid 的外部依赖组件,生产环境中可用 MySQL。
平台的演进
Druid 查询量大
在 Druid 成为主力查询引擎之后,我们发现大查询量的场景下直接查 Druid 会有一些弊端,其中最大的痛点就是查询响应慢。
缓存查询结果
为了提高整体查询速度,我们引入了 Redis 作为缓存。
使用 Redis 来缓存查询结果
最简单的缓存设计,是将 Druid 的查询体(Request)作为 key,Druid 的返回体(Response)作为 value。上述的缓存机制的缺点是显而易见的,只能应对查询条件完全一致的重复查询。在实际应用中,查询条件往往是多变的,尤其是查询时间的跨度。
举个例子,在相同指标维度组合下用户发起两次查询,第一次查询 10 月 1 日到 10 月 7 日的数据,Druid 查出结果并缓存到 Redis。用户调整时间跨度到 10 月 2 日到 10 月 8 日,发起第二次查询,这条请求的不会命中 Redis,又需要 Druid 来查询数据。
从例子中,我们发现两次查询的时间跨度交集是 10 月 2 日到 10 月 7 日,但是这部分的缓存结果并没有被复用。这种查询机制下,查询延时主要来自于 Druid 处理重复的请求,缓存结果没有被充分利用。
提高缓存的复用
为了提高缓存复用率,我们需要增加一套新的缓存机制:当查询在 Redis 没有直接命中时,先扫描 Redis 中是否已缓存查询中部分时间跨度的结果提取命中的结果,未命中再查询 Druid。在扫描的过程中,被扫描的对象是单位时间跨度的缓存。
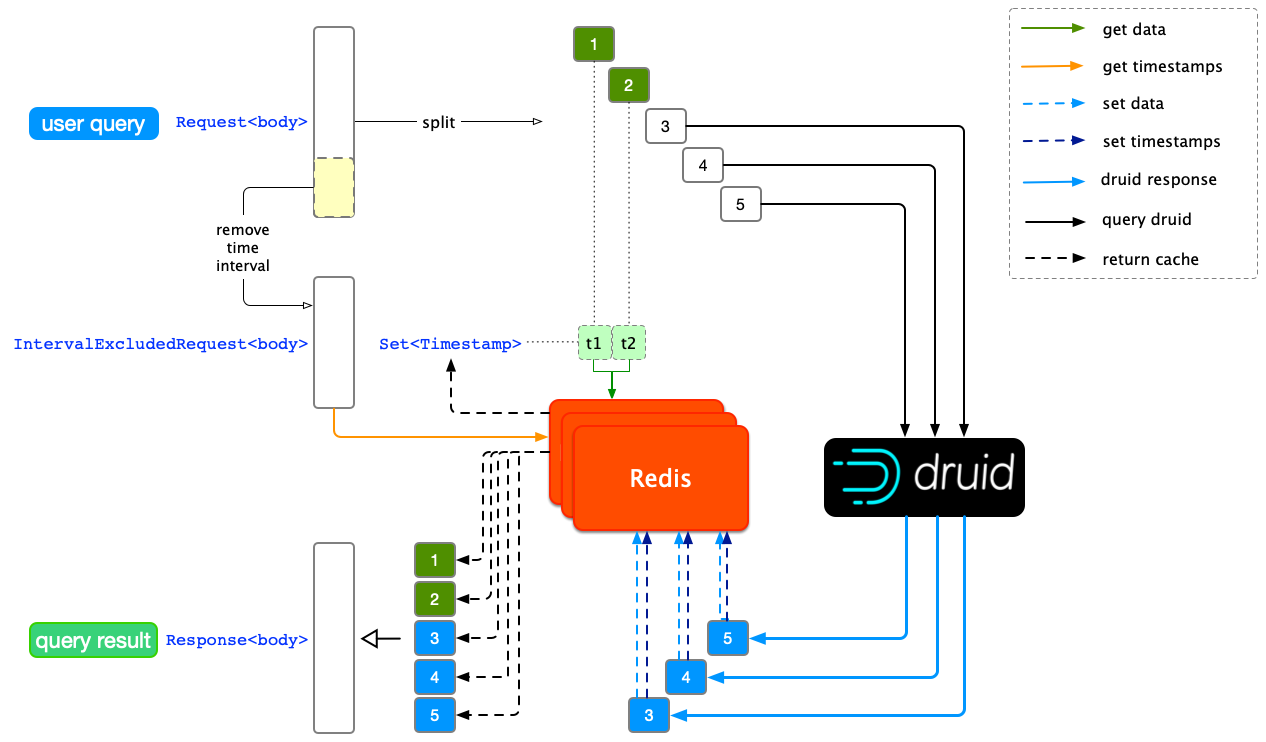
为了能获得到任意一个单位时间跨度内的缓存,除了在 Redis 中缓存单条查询的结果之外,需要进一步按时间粒度将总跨度等分,缓存所有单位时间跨度对应的结果(如下图所示)。
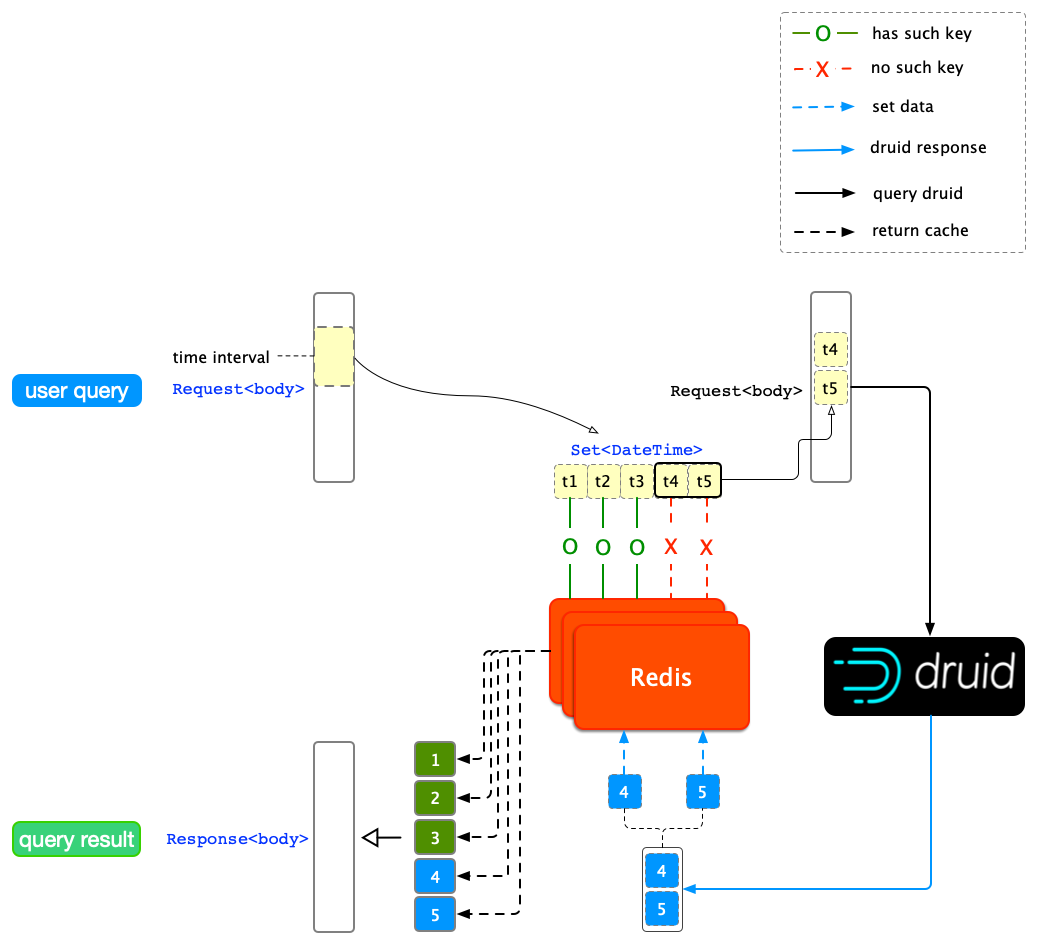
Druid 结果按时间粒度缓存
减少 Redis IO
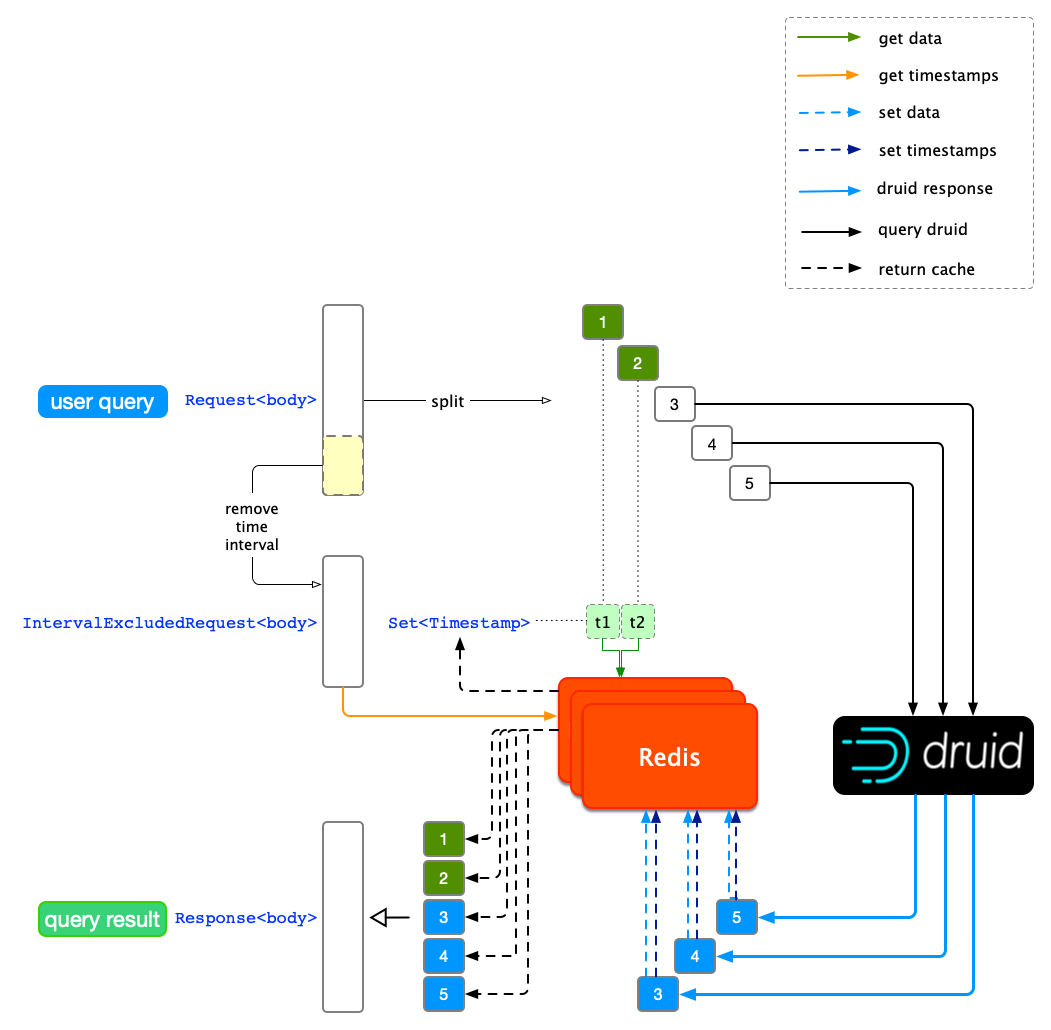
从上图中我们发现,对每个单位时间跨度的结果判断是否已被缓存都需要对 Redis 进行一次读操作,当用户查询量增大时,这种操作会对 Redis 集群造成比较大的负担,偶尔会出现 Redis 连接超时的情况。为了减少对 Redis 的 IO,我们对时间跨度单独设计了一套缓存机制。基于减少读操作的想法,我们设计了通过一次读操作就可得到已经被缓存的所有时间跨度,然后再一次性地将所有缓存的结果读出。
要实现一次性获得缓存的所有时间跨度,我们需要在每次缓存 Druid 查询结果后,再缓存查询请求和它覆盖的时间跨度,在 Redis Key-Value 规则上,我们先把查询体(Request)剔除时间跨度,生成一个时间无关的查询体(IntervalExcludedRequest)作为缓存的 key;提取查询粒度(Granularity),把剔除出来的时间跨度按粒度分隔开(Set)作为 value。
要实现一次性读出所有缓存结果,通过 Redis 的 MGET 获得 IntervalExcludedRequest 对应的各个时间戳。
判断当前请求的所有单位时间跨度是否命中缓存,命中的结果会被直接返回。优化后缓存机制如下图所示:
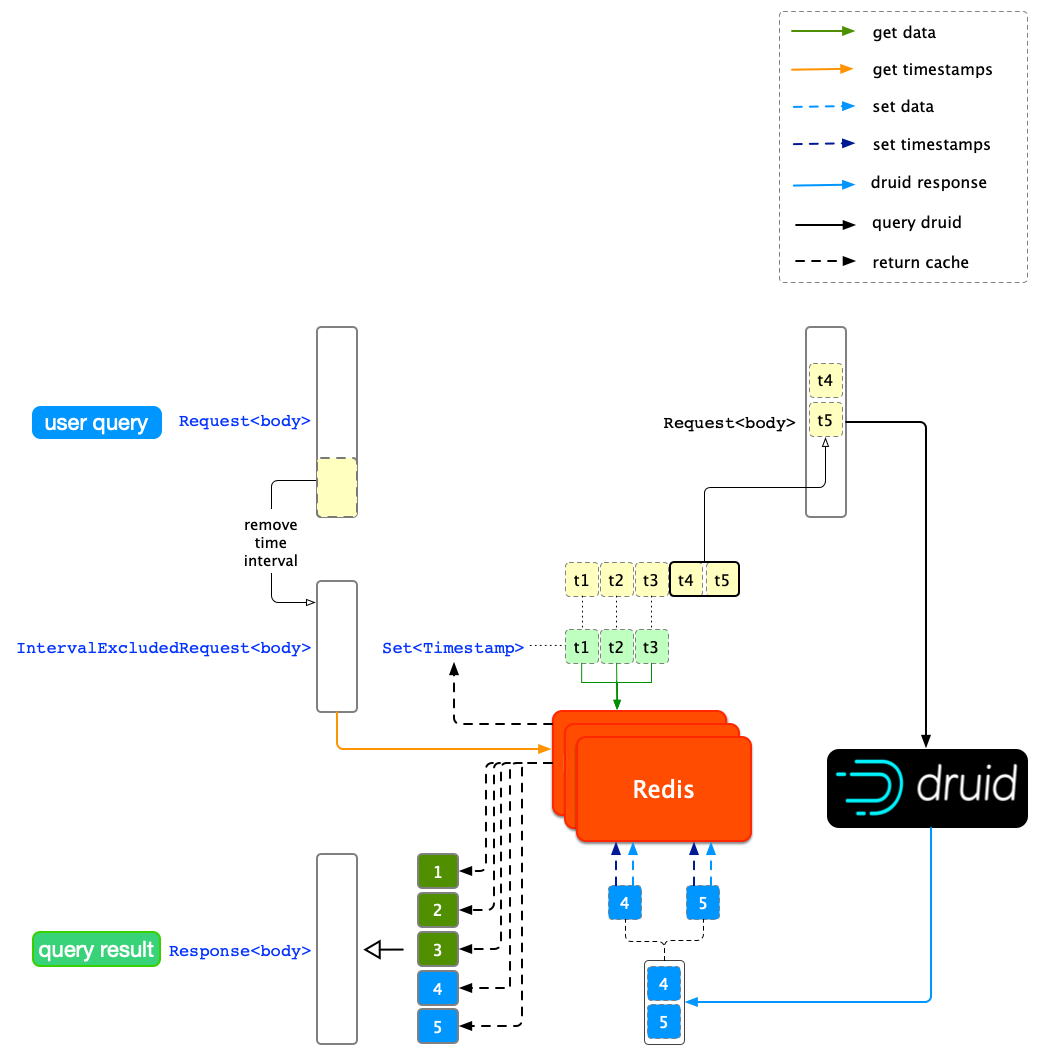
Redis 读操作优化
Druid 查询时间跨度长
在未命中缓存的情况下,设置较长的查询时间跨度(长时间跨度:2 周以上),Druid 经常会出现返回速度变慢,甚至阻塞其他查询请求的现象。
我们测试了长时间跨度的查询请求对集群整体的影响,通过对 Druid 集群的监控数据的分析,我们发现被长时间跨度查询命中的 Broker 节点会出现内存消耗过大的问题,并且随着时间跨度的增大,内存消耗跟着提高,甚至出现内存不足导致 Broker 节点无响应的问题。
一个 Broker 处理一个请求
在调研了 Druid 执行原理以后,我们发现一个查询请求只会被 Router 路由到一个 Broker 节点,经由 Broker 节点去 Historical 节点上查找目标数据在 Deep Storage 的存储位置,最后返回的数据也是经过 Broker 节点来合并返回结果。查询的时间跨度越长,对 Broker 的压力也越大,内存消耗越多。
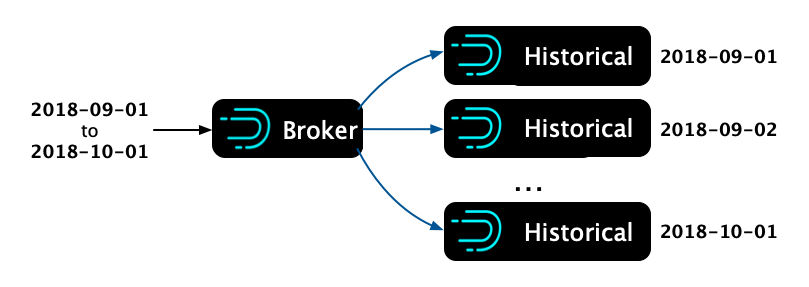
单个 Broker 处理长时间跨度查询
多个 Broker 处理一个请求
单个 Broker 的性能无法满足长时间跨度的查询,为了让提高查询性能,我们尝试把一个查询 N 天数据的请求,拆分成 N 个查询,每个只查询一天,然后异步地将这些请求发出,结果这 N 个请求都被很快得返回了。和拆分前的查询耗时相比,拆分后的耗时大大减小。
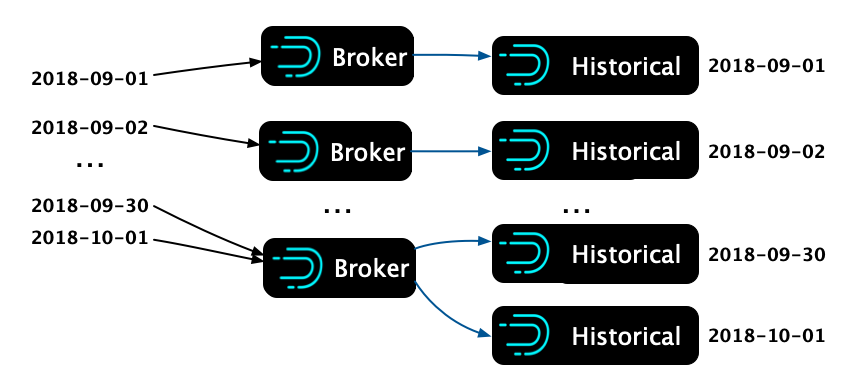
多个 Broker 处理长时间跨度查询
从 Broker 节点的监控来看,当一个长时间的查询请求被多个 Broker 一起处理,可以减少单个 Broker 内存消耗,并且加快了整体的查询速度 。提速程度请参考下图的测试比对,测试用例采用平台一天的所有查询,测试方式是在不命中 Redis 的情况下异步地「回放」这些查询到 Druid。
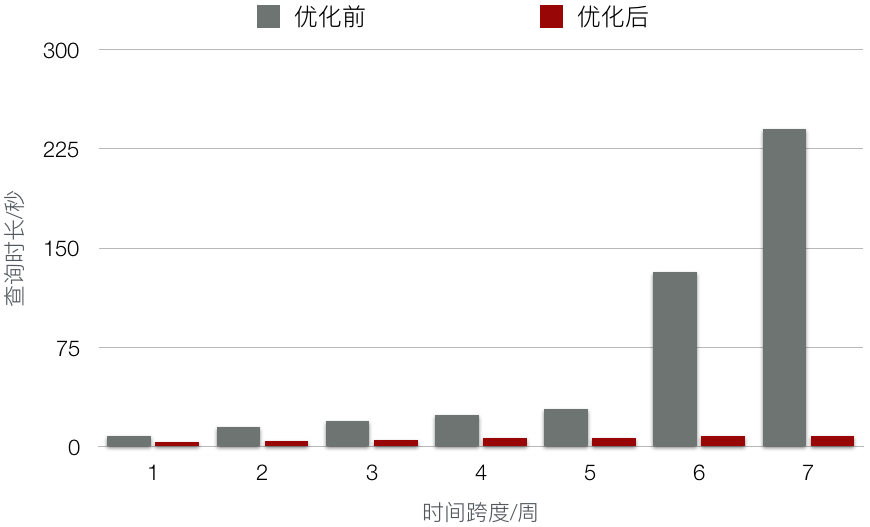
benchmark
根据上述 Broker 在查询过程中的工作原理,想达到长时间跨度查询的提速,我们需要在用户发起查询之后把请求拆分。拆分的机制是根据每个查询请求的查询时间粒度而定,例如上述中的一个 N 天跨度的天粒度请求,在查询到达 Druid 集群之前,我们尝试把它拆分成 N 个 1 天跨度的天级别粒度请求。整个查询从拆分到命中 Druid 的过程如下图所示(在 Druid 内部的工作细节请参考上文)。
按时间粒度拆分用户查询请求
缓存结果过期
前两步的演进完成了从高负载下查询性能低、查询时间跨度长而速度慢、Redis 复用率低,到查询性能高、Redis IO 稳定。
分析平台的数据源来自于离线数仓的 Hive 和实时数仓的 Kafka。重新摄入上游数据到 Druid 后, 对应时间列的 Segment 文件会进行重建索引。在 Segment 文件索引重建之后,对应的 Druid 查询结果也会发生改变。当这个情况发生时,用户从 Redis 获取到的结果并没有及时得到更新,这时就会出现数据不一致的情况。因此一套平台用户无感的缓存自动失效机制就显得尤为重要。
缓存自动失效
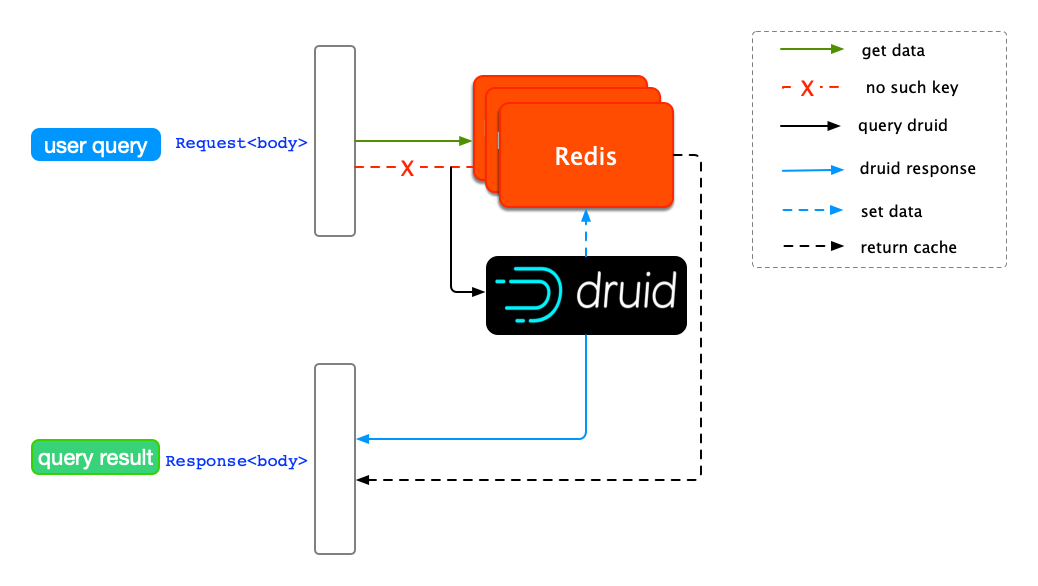
在 Druid 查询链路下,数据源的最近成功摄入的时间可以被抽象为它的最新版本号,利用这一的思想,我们可以给每个数据源都打上数据版本的标签,在数据更新后,给更新的数据源替换新的标签。这样一来,每次校验 Druid 查询结果是否过期时就有了参照对象。
Druid 支持 MySQL 存储元数据信息(Metastore Storage),元数据中的时间戳就恰好可以作为数据版本。在用户查询请求发起后,先后取出 Redis 缓存结果中携带的时间戳和 MySQL 元数据版本,然后比较两个时间。Redis 缓存的时间较新的话说明缓存未过期,可以直接返回缓存结果;反之,说明 Redis 缓存数据已经过期,这一对 Key-Value 会被直接删除,然后去查询 Druid。
在添加了数据版本校验后,一个请求的整个生命周期如下图所示。
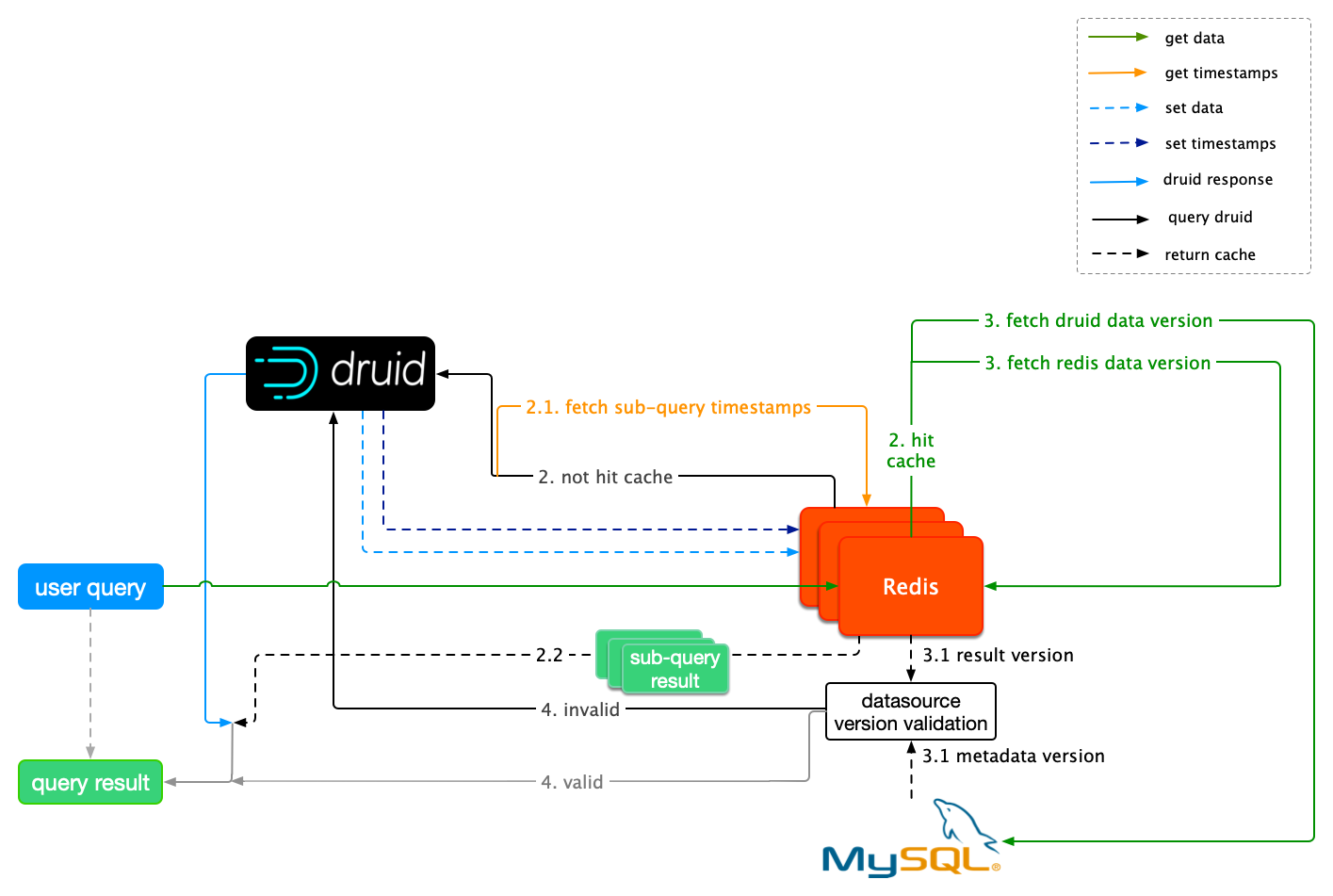
缓存自动失效机制
总 结
本文重点介绍了知乎数据分析平台对 Druid 的查询优化。通过自研的一整套缓存机制和查询改造,该平台目前在较长的时间内,满足了业务固化的指标需求和灵活的分析需求,减少了数据开发者的开发成本。
数据分析平台在上线后,提供了非常灵活的能力。在实践中,我们发现过度的自由未必是用户想要的。适当的流程约束,有助于降低用户的学习成本,以及大幅度改善业务在该平台上的查询体验。早期我们对数据的摄入并没有做过多的约束,在整个数据稳定性提升过程中,通过和数仓团队的大力配合,我们对摄入的数据源做了优化,包括限制高基数维度等治理的工作。本文的缓存思想不仅仅可以用在 Druid 上,同样可以用在 ClickHouse,Impala 等其他的 OLAP 引擎的查询优化上。
团队介绍
知乎的大数据平台团队,属于知乎的技术中台。面对业务的多元化发展和精细化运营,数据的需求变得越来越多,大数据平台团队主要负责:
搭建公司级可视化分析系统和数据服务
维护全端数据的采集、集成和数据仓库,对接业务系统
管理数据生命周期,提供一站式的数据开发、数据权限、元信息管理和任务调度平台
提供 AB Testing 实验平台,系统化集成实验分析框架,推动业务增长
随着知乎业务规模的快速增长,以及业务复杂度的持续增加,我们团队面临的技术挑战也越来越大,欢迎对技术感兴趣、渴望技术挑战的小伙伴加入我们,一起建设知乎的数据平台。
参考引用[1] http://druid.io/docs/latest/design/
会议推荐
12 月 20-21,AICon将于北京开幕,在这里可以学习来自 Google、微软、BAT、360、京东、美团等 40+AI 落地案例,与国内外一线技术大咖面对面交流。

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论