
人工智能并不像某些资料中宣传的那样真正理解人类的语言。
本文最初发表于 Towards Data Science 博客,经原作者 Tolga Akiner 授权,InfoQ 中文站翻译并分享。
在你看今天那些铺天盖地的关于“人工智能将会危害人类”的讨论时,你有没有问过“怎么会呢”?据谷歌一位副总裁说,当你对着最先进的语言模型询问“内布拉斯加以南是哪个州”时,它会回答“南内布拉斯加”。
这样的科技水平,真的能超越我们所知的宇宙中最聪明的物种,即智人,达到更聪明的程度吗?嗯,我们从青铜时代一直到现在,所以答案可能是肯定的,指的是将来的某个时候。但是,要提升当前的人工智能,还需要克服太多的障碍。
不得不承认,当我第一次接触 “迁移学习”时,我非常兴奋。当有人看到像 ImageNet 和 BERT 这样的模型,读到一些关于这些模型上的“炒作”文章,我想,我们其实已经非常接近电影《她》(Her)那样的场景了。
之后,我开始在企业环境中作为数据科学家工作,并接触了医疗行业中的一些关键业务问题,我意识到,在现实世界中的应用涉及到一些不同于 SOTA 或 GLUE 这样的标准任务。当我将他们的模型应用到一些不同的数据集时,我看到不同的迁移学习包、创业公司和潜在的厂商公司所报告的关于不同任务的 95% 以上的准确性,而所有这些花哨的模型都以某种角度和 / 或某种方式失败了。
因此,对于我来说,这幅图景变得更清晰了,我从自然语言处理领域的迁移学习中得到了一个更实际的结论:那些令人着迷的人工智能的结果大多只适用于非常特定的测试集,而这些测试集可能都是经过精心挑选的。
在一个与语言学有关的例子中(我的知识主要涉及自然语言处理,对计算机视觉也不太熟悉,所以我将仅举这一领域的例子),我们可以认为,人工智能并不像某些资料中宣传的那样真正理解人类的语言,例如,一些新闻文章中,人工智能仅仅理解它之前看到的语料的某些方面,并试图将其理解推论到一个新的数据点。
这一观点可能被某些人认为是多余的,我们不应该等待人工智能给出一些与训练集有很大不同的数据的神奇答案。我当然同意,但是,如果我们想要迈向更广泛、更实用的人工智能应用,并且在迁移学习方面取得更好的成果,那么作为一个社区,我们最好有一个坚实的路线图,并且对此提出坚实的问题。
在最近几个月,随着迁移学习应用的兴起,训练数据的重要性越来越受到人们的关注,特别是在自然语言领域。你还可以通过观察越来越多的众包或数据标签初创公司在市场中的业务来把握这个趋势。ACL2020上最近发表的一篇论文《走向自然语言理解:数据时代的意义、形式与理解》(Climbing towards NLU:On Meaning, Form, and Understanding in the Age of Data)提出了一种非常有趣的方法,我发现它与以往完全不同。
尽管这一研究可能被认为是在语言学领域对科学哲学和一些严格定义的术语(如意义、形式和交际意图)的极大关注,它还是得出了一个非常明确的结论:BERTology 论文中有证据表明,大规模语言模型可以学习语言形式结构的各个方面,并使用训练数据中的人工产物,但是它们并不了解人类如何沟通,也不记住事实知识,也不了解你的问题背后的意图。一些快速失败的例子(用 GPT2 生成),关于这句话,在另一篇有趣的文章《为什么人工智能会被语言所困惑?这都是心智模型的问题》(Why is AI so confused by language? It’s all about mental models.)中可以找到,作者提出了一个名为“心智模型”的概念,它模仿人类大脑如何在迁移学习协议中消化语言。
这种观点是基于这样一个事实:我们可以根据非常不同的因素给句子和短语赋予非常不同的意义。比方说,让我们看一看这一句:“… Micheal Jordan now if he gets Bryon Russel with a quick crossover look at Bryon Russell slips and Micheal pulls and buries the shot…”我假设那个铃声已经响了,让一些人想起了 1998 年的 NBA 总决赛,即使你对此并不感兴趣,“Bryon Russel”、“Micheal Jordan”、“cross-over”和“shot”也许会告诉你,这个句子实际上是在描述一个发生在过去的事件,而这个事件发生在一座挤满了成千上万人的体育馆里,而且是在犹他州或者芝加哥。
即便迁移学习模型通过从不同的角度看整句话,能够在一定程度上理解每个词和模式,但它们并不知道这些明显的(对人来说肯定的) 细节和联系,这就是为什么“心智模型”能够提供一些解决障碍的初步办法。尽管如此,我还是希望能在另一篇文章中深入探讨这个新的想法。
在这篇文章《我们训练人工智能的方式存在根本性的缺陷》(The way we train AI is fundamentally flawed)中,作者讨论了另外一个非常有趣的概念,即 “压力测试”,它的理念是,除了标准的验证和测试集外,对模型进行更广泛的测试。
这听起来很好,但是我个人更愿意从真实世界的应用程序的角度来评价模型。如果我们对每个迁移学习模型都有详细的实际效果报告的话,我想这会很棒。这听起来似乎很需要数据,但这只是一个想法,我将在这篇文章中试着做一个压力测试,希望能有点意思。
对于不同的想法、观点,以及人工智能对未来的影响,我喜欢用相对简单易于理解的模型来进行讨论,但是这可能已经够多了,让我们来讨论一下这个模型。迄今为止,我的重点是介绍并讨论了训练的重要性,以及如何将这一基本部分的各个方面引入当前的迁移学习研究与可能更广泛的应用之间的鸿沟。
通过对以上问题的阅读和思考,我想对一些语言模型进行一次非常快速、特别的压力测试(多亏了 HuggingFace 的强大功能,它可以确定不同训练集对相同语言模型架构的影响,如果只使用 Tensorflow 或 PyTorch 的话)。
本文所要展示的就是,对于由不同语言的微调集合所引起的一些基于 BERT 的掩蔽语言模型的差异,我试图给出一个直观的解释。通过研究不同语言的语言模型,我希望可以巩固训练集的重要性。
因为在不同的训练集中,我需要训练多少个 BERT 模型,所以我考虑了不同的语言。我们的目的是通过一些主观的问题来对不同的语言模型(不同的语言)进行压力测试,同时利用非常易于使用的 Transformer管道。
BERT 针对不同的任务进行了微调,包括但不限于掩蔽标记预测、文本分类、名称实体识别和问题回答;但是,由于问题提取需要上下文输入,我决定使用与掩蔽语言模型相似的程序。
这样,我通过掩蔽其中一个标记(理想中引入句子主观性的标记)生成了 15 个相对较短的句子,并将所有这些被掩蔽的句子分别输入到基于 BERT 的掩蔽语言模型中,分别对英语、德语、法语和土耳其语进行训练。我认为,呈现代码将是描述此工作流程的最好方法,因此,我只想通过显示这些包和句子来了解:
import pandas as pdfrom transformers import pipelinefrom transformers import BertTokenizerfrom google_trans_new import google_translator# Our 15 test sentencessentences = ['The most delicious food in the world is [MASK].','The best vacation spot in the world is [MASK].','When I grow up, I want to be [MASK].','[MASK] won the Cold War.','The most powerful nation in the world is [MASK].','The cleanest energy source is [MASK].','The most exciting artificial intelligence application is [MASK].','The best smartphone in the market is [MASK].','Weed is [MASK] for your health.','Religions are [MASK] for society.','The most cheerful color is [MASK].','The most fascinating field of science is [MASK].','The average temperature of the earth is going to [MASK] in the future.','The highest paid job of the 21st century is [MASK].','Mathematics is useful for [MASK].']正如你所看到的,我试着给出一些或多或少的主观臆断和正在进行的辩论问题(如果不是全部,也是上面的大部分),它们可以用一个词来回答。这个想法就是观察不同的语言模型(在不同的语言上训练)如何预测这些标记。
在训练语料中,我最初的一个期望就是通过模型输出是否反映出与文化、习惯或社会有关的差异。由于这是训练集如何影响迁移学习预测的重要证据。虽然我没有百分之百肯定我是否做到了,但是我希望你们能够确定并告诉我!
我只在迁移学习部分使用了Transformers,google-translator只用于将预测的标记翻译为英语。第一个翻译是用 Transformer 在局级级别完成的,除了我的母语土耳其语外,这对我来说更容易手动翻译。
还有一点很重要,那就是我已经和我的前同事和朋友 Emir Kocer 和 Umut Soysal 一起做过德语和法语的翻译工作,并且试着尽量减少因翻译而产生的掩蔽标记的错误预测。
# We'll translate to German and French firsttranslator_de = pipeline('translation_en_to_de')translator_fr = pipeline('translation_en_to_fr')# Create De and Fr sentencesde_sents = []fr_sents = []for eng in sentences:de_sents.append(translator_de(eng)[0]('translation_text'))fr_sents.append(translator_fr(eng)[0]('translation_text'))# Change [MASK] to <mask> for Frenchfr_sents_mod = [sents.replace('[MASK]','<mask>') for sents in fr_sents]# I did not use translation (neither did I trust) for my mother-tongue. With weird letters such as ü,ğ,ş,ı.tr_sents = ['[MASK] dünyadaki en lezzetli yiyecektir.','[MASK] dünyadaki en guzel tati yeridir.','Ben büyüyünce [MASK] olmak istiyorum.','Soğuk savaşı [MASK] kazandı.','[MASK] dünyadaki en güçlü millettir.','[MASK] en temiz enerji kaynağıdır.','[MASK] en heyecan verici yapay zeka uygulamasıdır.','[MASK] piyasadaki en iyi akıllı telefondur.','Kenevir sağlığınız icin [MASK].','Dinler toplumlar icin [MASK].','[MASK] en neşeli renktir.','[MASK] bilimin en büyüleyici alanıdır.','Dünyanın ortalama sıcaklığı gelecekte [MASK].','21. yüzyılın en yüksek maaşlı işi [MASK].','Matematik [MASK] için kullanışlıdır.']下一步就是将这些句子输入到相应的掩蔽语言模型中,提取掩蔽的标记预测,并将其转换为英文,这样我们就可以更方便、更全面地评估结果。由于最后一个翻译阶段是在单词级别,所以我使用了谷歌翻译。要知道,有时候你只是想测试一个新的包,即使它做同样的工作……
# Create the fill mask objectsfill_mask_eng = pipeline("fill-mask",model="bert-base-uncased",tokenizer='bert-base-uncased')fill_mask_de = pipeline("fill-mask",model="bert-base-german-cased",tokenizer='bert-base-german-cased')fill_mask_fr= pipeline("fill-mask",model="camembert-base",tokenizer="camembert-base")fill_mask_tr = pipeline("fill-mask",model="dbmdz/bert-base-turkish-cased",tokenizer='dbmdz/bert-base-turkish-cased')# Run the fill-mask pipelines for each language and translate German and French back to Englishtranslator = google_translator()eng_res = []de_res = []fr_res = []tr_res = []for i,sents in enumerate(sentences):res_eng = fill_mask_eng(sents)res_de = fill_mask_de(de_sents[i])res_fr = fill_mask_fr(fr_sents_mod[i])res_tr = fill_mask_tr(tr_sents[i])eng_res.append(', '.join([j['token_str'] for j in res_eng]))de_res.append(', '.join([translator.translate(j['token_str'],lang_src='de',lang_tgt='en') for j in res_de]))fr_res.append(', '.join([translator.translate(j['token_str'].replace('▁',''),lang_src='fr',lang_tgt='en') for j in res_fr]))tr_res.append(', '.join([translator.translate(j['token_str'],lang_src='tr',lang_tgt='en') for j in res_tr]))# Push the results into a dataframeresult_df = pd.DataFrame(list(zip(sentences,eng_res,de_res,fr_res,tr_res)),columns=['Sentence','English','German','French','Turkish'])对于这些结果,我不能说它是开创性的,但是具有争议性的,我很喜欢进一步的头脑风暴和建设性的批评。这里有我的发现和一些浅显的观察,希望能在这张奇怪的桌子上找到答案。因为这篇文章比我预期的要长,所以我只谈了几个数据点。别忘了,这是完整代码,你可以下载看看。
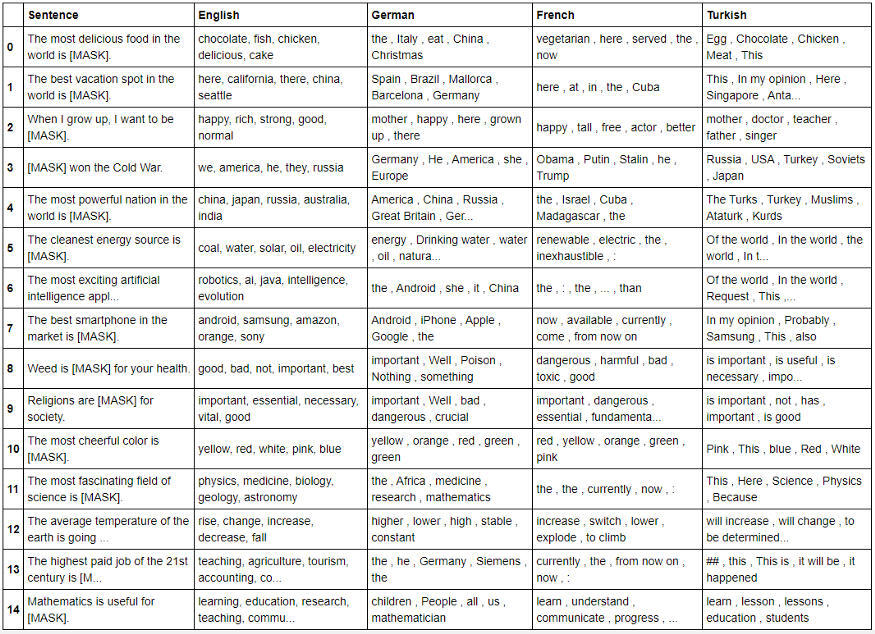
“here”标记仅以法语出现在第 0 行的食物上,这似乎是非常有趣的开始,我找不到快速的高亮数据,所以我无法在这里进行数据驱动(惭愧),但是还有一个quora 问题:“Why do the French think they have the best cuisine on planet Earth?”。
对于德国来说,假设“Italy”这个词指的是这句话中的意大利食物,我发现这项调查显示,在德国,意大利菜比德国菜更受欢迎。你能说社会中的这些趋势是基于迁移学习?也许吧……
对于英文中的“chocolate”,我唯一的解释是,根据Statista的数据,美国在零食消费方面有明显的优势,但这可能是一个弱关系,所以我实际上只是想用这个来……
在第 1 行关于度假的句子中,“here”这个词在英语、法语和土耳其语中都出现过,根据《世界旅游晴雨表》(World Tourism Barometer),这些国家是世界前六名中的三个。因此,另一个线索表明,这些国家的某些特征差异可能已经从训练语料迁移到模型预测中。
Turkish BERT 在第 2 行预测了“doctor”的标记,立刻引起了我的共鸣,因为我的经验也告诉我,土耳其这个国家是多么地迷恋医生这个职业。这句话不是我凭空说的,也不是因为我在土耳其长大,这里是调查报告。
从第 9 行与宗教相关语句来看,“bad”和“dangerous”标记仅在德语和法语中输出,这两个国家的宗教重要性方面的排名远低于美国和土耳其。另一个潜在的信息流,可能是通过训练数据和迁移学习,从社会思维转向机器学习预测。
这一结果的数据框架中有许多东西需要解释,同时也有一些我目前无法解释的非常奇怪的预测。举例来说,只有土耳其语中的 yellow 没有出现在最悦目的颜色中,德语中的 Iphone 是最好的智能手机预测,尽管英语中的 BERT 似乎对冷战的胜利者充满信心,而 USA 却不是它预测的最强国家,只有法国的语言模型对 cannabis 有着强烈的憎恨。当然,更不用说掩蔽标记的一些停用词预测了,这可能是由于语法或翻译错误造成的。
通过对不同语言语料的比较,我相信我们也可以讨论数据偏差在这些结果中的作用,事实上,训练数据偏差也是另外一个很大的讨论主题,但是我不想做过多的讨论,我现在只是想给大家介绍一下与此相关的观点(不确定我是否会再为此写一篇博文,也许会吧……)。
你们也许会得出一个与我截然不同的解释,请记住,我也很想听到更多。所以,让我总结一下最终降落这架飞机的一些关键要点:
自然语言处理是人工智能的一个快速兴起的领域,最近在支撑研究和企业级应用方面取得了显著的进展。但目前的研究中存在着大量的夸大现象,忽略了训练语料选择的重要性,依附性和后果性。
关于有监督的自然语言处理的训练语料方面,如压力测试,已经有不同的观点和讨论,本文背后的动机是在同一迁移学习架构上应用一种非常短的压力测试,来识别训练数据在预测中引起的差异。
我想提供一个关于迁移学习的引人注目的例子,着重于由于训练集的差异而产生的差异。通过输入不同的主观掩蔽句,选择了不同语言的语言模型,并进行了测试。
对于统一句子,不同语言的语言模型的标记预测存在较大差异。关于这些差异,我已经找到了一些额外的数据,但并非全部,希望本文的数据能引起你的思考,并得出结论:训练数据是迁移学习模型在广泛应用中的有效性和有效性的界限。
作者介绍:
Tolga Akiner,博士,数据科学家,机器学习从业者,专注于医疗保健中的自然语言处理领域。LinkedIn:https://www.linkedin.com/in/tolga-akiner/
原文链接:





{kind=link}