

“异构计算”(Heterogeneous computing),是指在系统中使用不同体系结构的处理器的联合计算方式。在 AI 领域,常见的处理器包括:CPU(X86,Arm,RISC-V 等),GPU,FPGA 和 ASIC。(按照通用性从高到低排序)本文是异构计算系列的第三篇文章,重点介绍 Adlik 在深度学习异构计算上的实践。
人工智能领域在近年发展迅速,不论是在图像识别,目标检测,机器翻译,还是语音识别等多个领域,人工智能的表现均已超过人类水平,尤其是在 AlphaGo 战胜了李世石之后,人们对人工智能可达到的成就有了新的认识。
机器学习(Machine Learning,ML)是人工智能的子领域,也是人工智能的核心,就是要设计让机器可以进行自动学习的算法。而深度学习(Deep Learning,DL)是机器学习的一个子类,是一种包含多个隐含层的神经网络结构,人们定义了神经网络中各种神经元的连接方法,以及神经元的激活函数,并利用反向传播技术完成神经网络的训练过程。深度学习技术在众多 AI 领域取得很多成果,解决了很多复杂的模式识别难题,所以也成为最近几年人工智能领域研究和应用上人气最火热的技术。
深度学习模型当前有多种训练框架,如常见的 TensorFlow,PyTorch,MxNet,Caffe,PaddlePaddle 等等,训练时大多是使用 GPU,采用容器云方式,进行大规模并发计算,减少模型训练收敛时间。而在模型的应用上,则要使用深度神经网络的推理能力,完成网络前向计算,并将此计算部署为应用服务,产生商业价值。
Adlik 做了什么?
各种算法在训练框架训练后得到各种模型,其服务应用可能要部署在不同的硬件平台,可能使用不同的推理框架,对应用场景有着不同的要求,如低时延。所以在训练中达到很好的收敛效果的深度学习模型,距离真正的投入应用,还有很多工作要做:
针对不同设备的推理框架有很多,对用户难以选择,要付出较多的学习成本;
不用应用场景的部署条件不同,有基于容器化部署场景,也有基于嵌入式硬件部署的场景,同样的模型服务,不同部署方案要掌握不同的技术;
根据性能需求有很多的模型调优工作;
推理服务应用于不同硬件,需要多类异构计算引擎的支持。
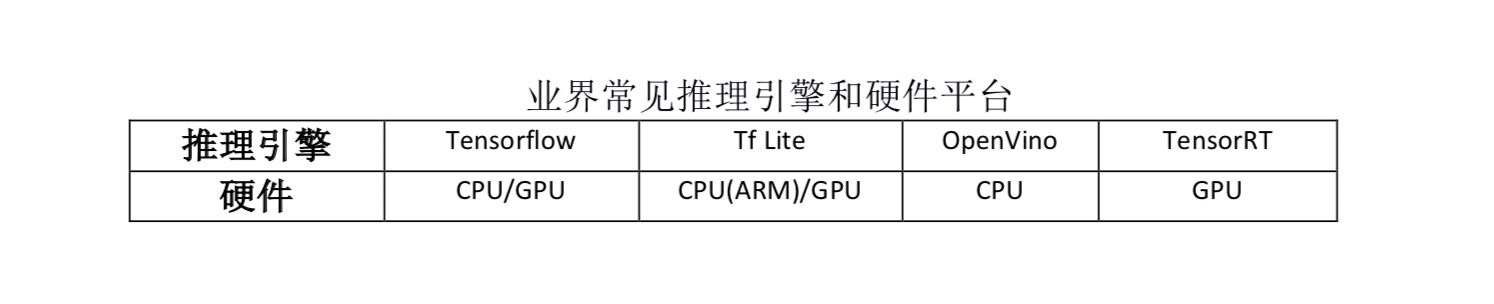
Adlik 就是一种可以将深度学习模型从训练完成,到部署到特定硬件并提供应用服务的端到端工具链,其应用目的就是为了将模型从研发状态快速部署到生产应用环境。Adlik 可以和多种推理引擎协作,支持多款硬件,提供统一对外推理接口,并提供多种灵活的部署方案,以及工程化的自适应参数优化方案,为用户提供快速,高性能的应用服务提供助力。Adlik 的架构如下图:
Adlik 在架构上,可以分为模型优化模块(Optimizer),模型编译模块(Compiler)和推理引擎模块(Inference Engine)。
训练好的模型,通过 Adlik 模型优化模块处理,生产优化后的模型,然后通过模型编译模块,完成模型格式转换,生成最终推理引擎支持的模型格式。
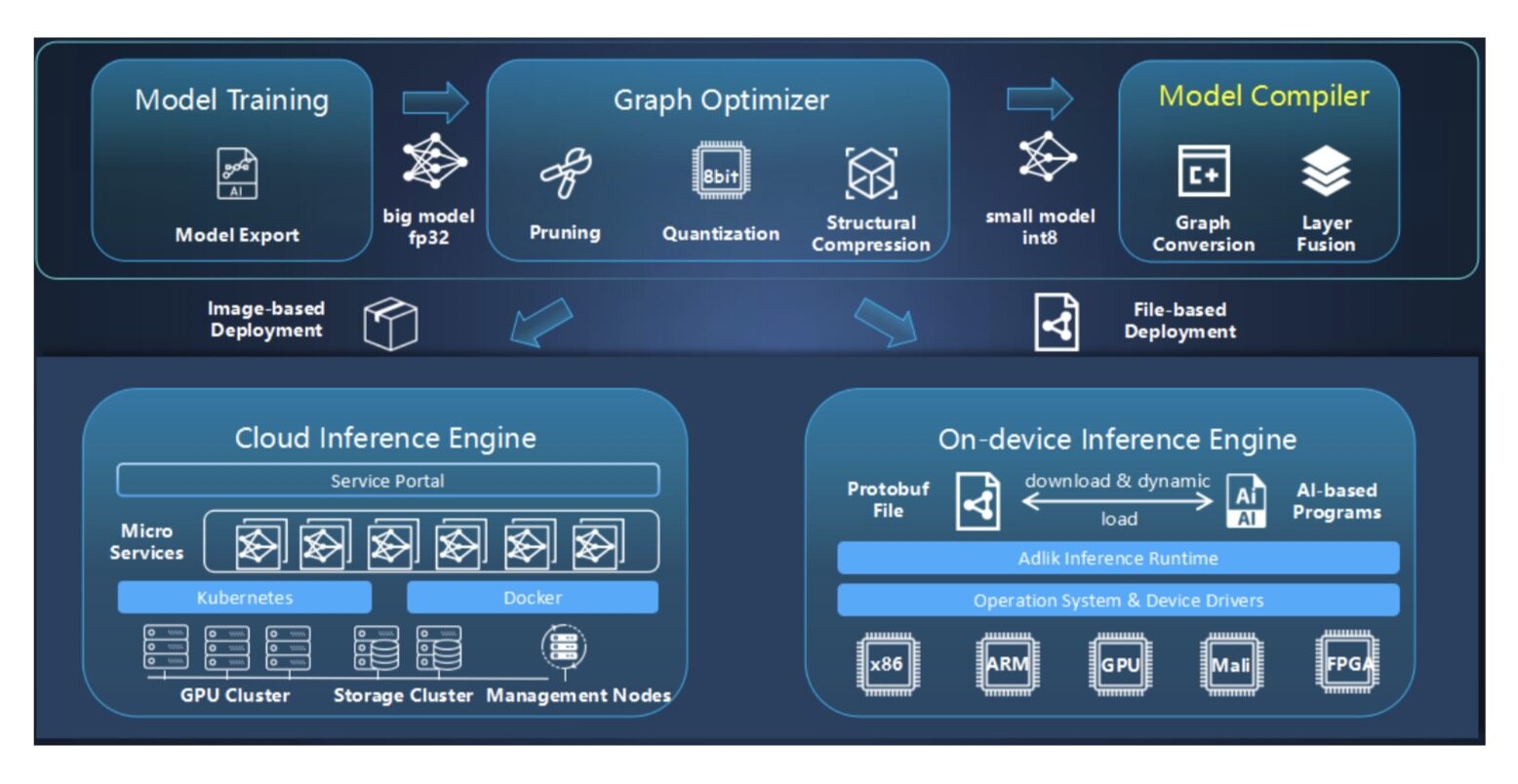
部署方案上,Adlik 支持三种部署场景,并提供相应的特性支持:
1.云侧
Adlik 支持原生容器化部署方案,优化和编译完成的模型,可以和 Adlik Serving Engine 镜像一起打包,发布为应用服务镜像,并在指定硬件的容器云上运行。
2.边缘侧
Adlik 支持在启动的 Adlik Serving Engine 服务上,加载优化和编译完成的模型,并支持模型版本管理,自动升级,以及多模型实例调度功能,减少边缘侧计算资源的占用。
3.端侧
Adlik 可以为用户提供 C/C++的 API 接口,支持用户直接在计算引擎上调用完成了优化和编译的模型,并提供了模型编排能力,具备低延时和小体积的特性,可以在指定硬件运行模型应用。
Adlik 目前的定位是深度学习模型工程化使用的工具链,是模型应用落地的加速器,包括端到端编译优化能力,主流深度学习推理引擎的集成,支持多种灵活部署方式,以 SDK 方式提供用户可扩展实现推理运行时的自定义开发能力,可以实现多模型协作推理,在工程化角度,Adlik 还会引入工程参数自动优化的能力,提升易用性,给用户提供训练模型到推理应用上线的端到端优化能力。
Adlik 在支持异构硬件计算的设计思路
目前 Adlik 支持的推理引擎,包括常见的用于深度学习推理的 TensorFlow Serving,TensorRT,OpenVINO,以及 CNNA(FPGA 特定运行时),并计划支持 Tf Lite。而支持的异构硬件包括了 GPU,CPU(x86),以及 FPGA,计划支持 CPU(ARM)。Adlik 在框架层上提供了多种形式,支持用户扩展异构硬件的运行和部署。
Adlik Serving 提供了模型的推理服务。它以插件的方式部署和隔离各种运行时的环境。Adlik Serving 内置常见的运行时组件,包括 TensorFlow Serving,OpenVINO,TensorRT,CNNA(FPGA 特定运行时),Tf Lite 等,各类应用可按需加载,开箱即用。
部署推理引擎时,需要根据具体场景灵活选择推理运行时,及其相应的异构硬件。例如,在 CPU 嵌入式环境下部署,因为只存在 CPU 环境,此时用户可以选择 TensorFlow Serving on CPU,或 OpenVINO on CPU 等两种部署方式,如果环境使用 ARM 的 CPU 架构,那么也可以选择 Tf Lite on CPU(ARM)的部署方式。
更为高级地,用户也可以通过 Adlik 提供的 Serving SDK,开发用户自定义推理运行时环境,并在 Adlik Serving 框架下执行推理服务,满足极高的时延性的部署环境。Adlik Serving SDK 提供了模型上载,模型升级,模型调度,模型推理,模型监控,运行时隔离等基础模型管理的功能特性,及其用户定制与开发推理服务的 C++ API。用户要根据自己的需求,定制开发自己的模型和运行时。Serving SDK 提供了标准的扩展点,方便用户高效地定制新的模型和运行时环境。基于 Serving SDK,用户也可以开发组合式的模型,在进程内控制多模型之间的交互,而模型之间的运行时可以相互独立。例如,模型 1 的输出可以作为模型 2 的输入,模型 1 和模型 2 分别 TensorFlow Serving 和 TensorRT 运行时的模型。
默认地,Adlik Serving/Serving SDK 不包含任何运行时组件,实现最小的依赖管理,应用根据部署环境灵活选择组装。也就是说,Adlik Serving/Serving SDK 可以提供不同运行时组合的镜像集合,应用根据具体的部署环境选择合适的基础镜像。
以新增一款运行时引擎为例,介绍一下 Adlik 的框架是如何支持创建新运行时的,这对很多有自定义运行时和指定硬件平台的场景有重要的意义。假设 A 是要支持的新运行时。
定义 A_Model 类。这个指定的 A_Model 就是要创建的新运行时
定义具体计算引擎的实现类,A_Processor 类,A_Processor 类可以直接调用 A 计算引擎的执行 API
调用 Adlik 提供的 API 接口,将 A_Processor 类其注册到 Adlik 运行时调度器,作为可调度的一个推理引擎
调用 Adlik 提供的 API 接口,将 A_Model 类注册到 Adlik 系统,这样 Adlik 在启动后就能够使用基于 A_Model 的运行时来执行推理任务
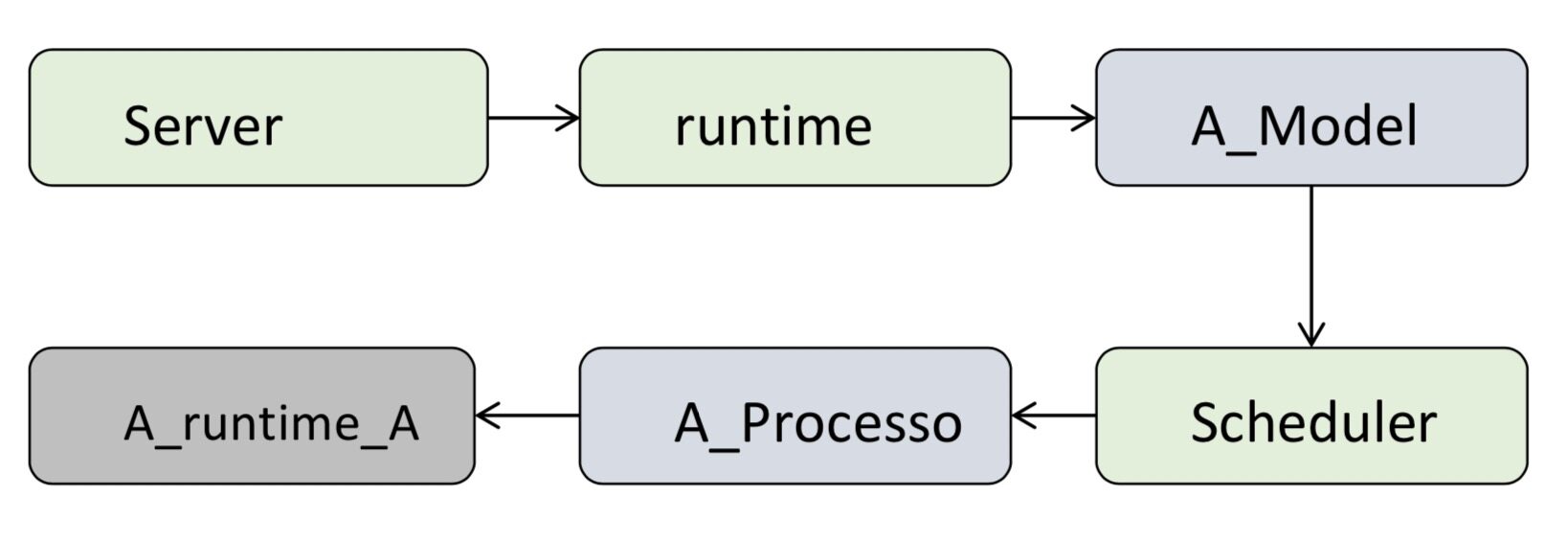
在上面简单的流程示意图中,Server 收到推理请求后,runtime 可以识别到 A_Model 运行时的请求数据,就通过调度器和具体调度算法,找到注册在调度器的 A_Processor 实现类,最终调到 A 引擎提供的计算 API,完成整个推理过程。框架提供了丰富的管理和运行时调度功能,用户只需要关注计算引擎实现即可。
实现上述代码后,用户可以根据指定硬件平台依赖的编译器对代码进行编译,即可生成指定硬件上可执行的推理应用程序,完成对异构硬件的支持。
Adlik 在支持 FPGA 异构计算上的实践
在计算密集型任务中(在深度学习模型推理领域),相比起仅具有数据并行能力的 GPU,FPGA 基于特定的门阵列硬件结构,可以同时实现数据并行和流水线并行,使得计算的延迟更小;对于特定结构的硬件电路,FPGA 的计算延迟也相对稳定。同时,与 CPU 和 GPU 相比,FPGA 具有较低的功耗,这在大规模的计算中具有一定的优势。此外,FPGA 还具有动态可重配置逻辑资源的功能,可以根据不同的配置文件,加载相应的编译文件,比 ASIC 更具灵活性。因此 FPGA 深度学习模型推理领域日益受到重视,并在 CNN 网络的实现领域中占据了很重要的位置。
FPGA 的特点是善于进行并行乘加计算,所以在实施深度学习计算时,我们要考虑将深度学习算法进行适当优化,将卷积、池化、下采样等大运算量的算子在 FPGA 中实现,从而提升整体计算引擎的效率和算力。在实践种,我们在 xilinx zcu102 单板上实现了卷积神经网络中卷积算子、池化算子、下采样算子以及全连接算子。此外,如 resnet 网络中涉及的 scale 和 batchnorm 算子也在建模中进行了适当优化,得以在 FPGA 中实现。
我们采用了深鉴科技的笛卡尔架构进行了研究和实践。笛卡尔架构,如下图,是典型的 zynq 工程架构。片上 ARM 与逻辑资源之间由 AXI 接口连接,网络配置信息由 axi-lite 接口传送,图像数据和权重则通过 DMA 由 PS 传送至 PL 外挂的 DDR 中,在卷积计算中由 PL 与 DDR 通过 AXI4 协议通信存取。
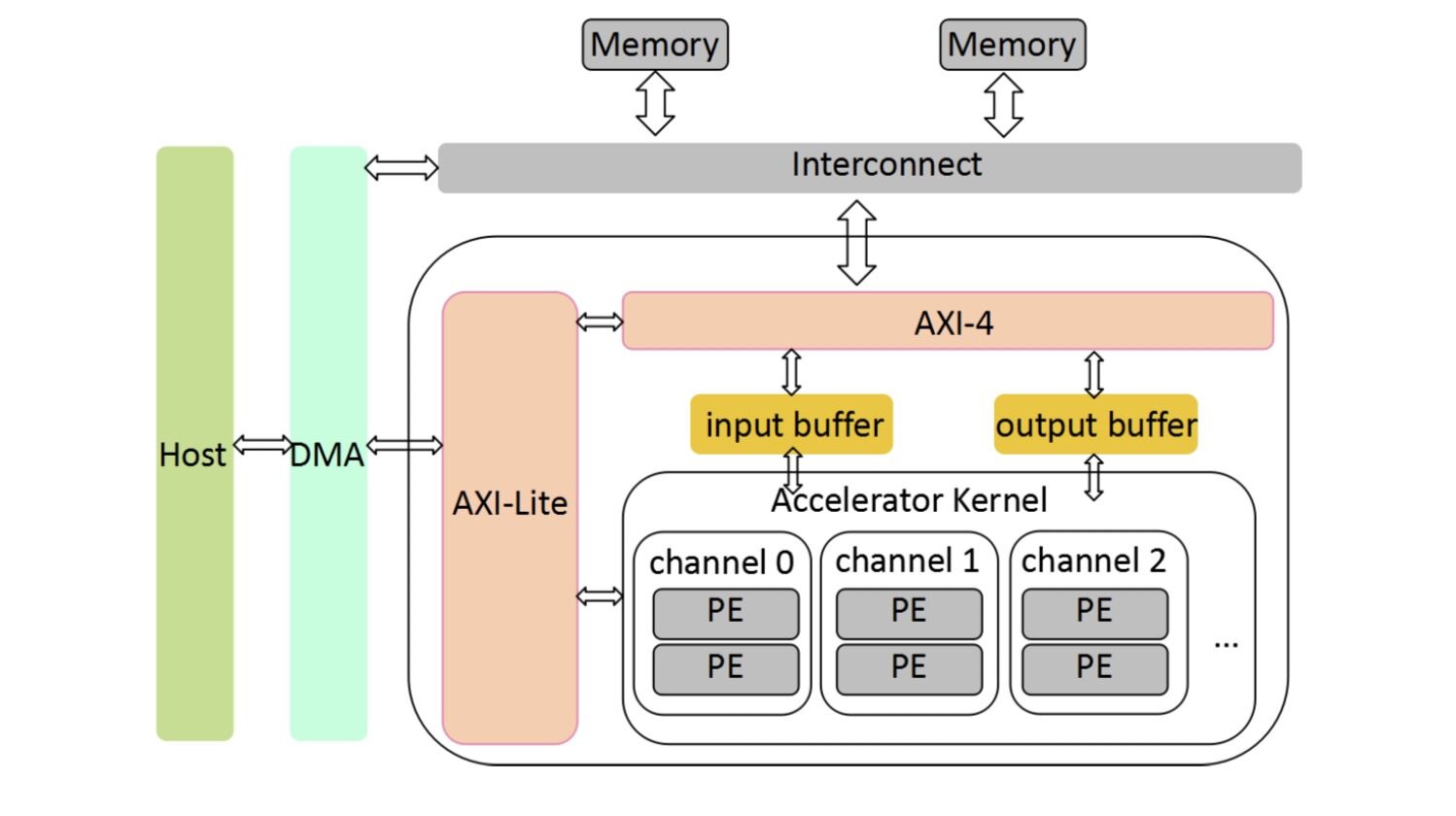
在整体设计上,我们考虑使用了 int8 量化和 DSP 复用技术,多点滑窗卷积计算以及多算子融合技术,结合 FPGA 传统设计中常用的流水线及乒乓存取技术,使加速器获得了更高的算力,以及更短的网络处理时间。
1.Int8 量化和复用 DSP 技术
基于 Xilinx xczu9eg 系列芯片中的 DSP 资源的特点,可以实现 DSP 的乘加复用。该系列芯片的 DSP 资源可以实现 27×18bit 的乘法计算,且某一级 DSP 的乘法输出结果可以级联到下一级 DSP 的加法输入端,从而实现乘加级联功能,无需额外使用逻辑资源搭建加法器。
如果将输入的图像和权重信息量化为 int8 格式,则可以使用权重移位的方式将某一权重左移 18 位后与另一权重相加,作为乘法器 27bit 的输入数据,从而使用一个 DSP 实现两次乘加计算,可以做到算力加倍。
2.基于 multi-sliding 的卷积计算
传统的二维卷积计算中,每个时钟沿参与卷积的因子为 M 个输入通道图像中的某个单点与对应输出通道的卷积核的对应单点相乘加,得到对应 N 个输出通道中对应位置的单点部分和。如下图,完成一个卷积核为 3×3 的卷积计算,需要 9 个时钟沿。如果 stride=1,则完成一行输出图像的计算需要 9×6=54 个时钟沿。
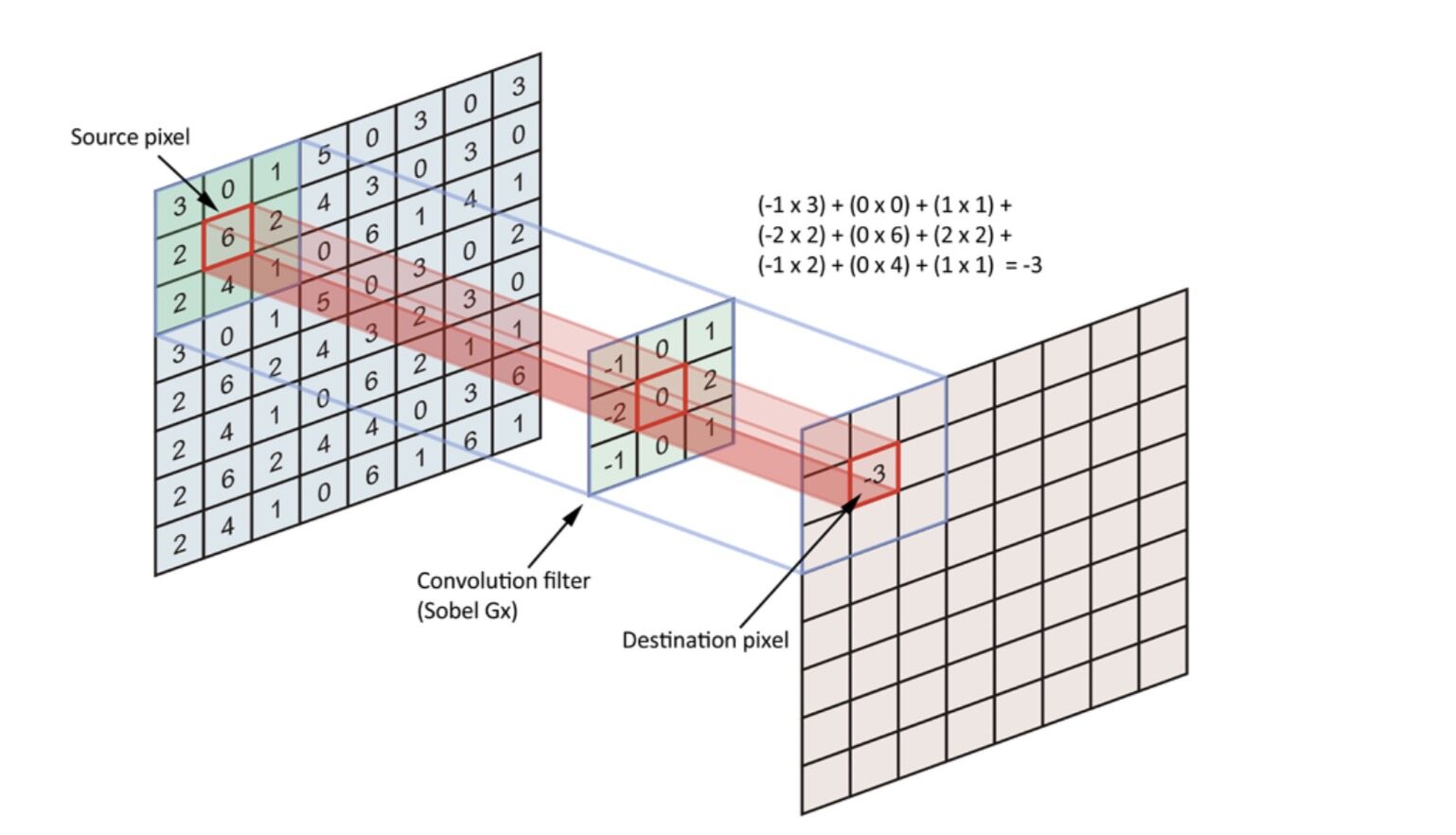
传统的卷积单点计算示意图
使用 multi-sliding window 的卷积方式,引入 PIX 变量,表示每个时钟沿里,每个输入通道的图像参与卷积的像素点数,传统卷积中的 PIX 通常为 1,即每个输入通道只有一个像素点参与乘加计算,而现在 PIX 可以取大于 1 的其他值,这样就使每个时钟沿参与卷积的图像像素点得到了伸展。
如下图,当卷积计算的参数 pad=1,kernel=7,stride=1,ciWidth=28,PIX=8 时,每输入通道在每个时钟沿里参与卷积的像素点数扩展为 8,与对应的卷积核相乘加,作为对应输出通道的部分和。
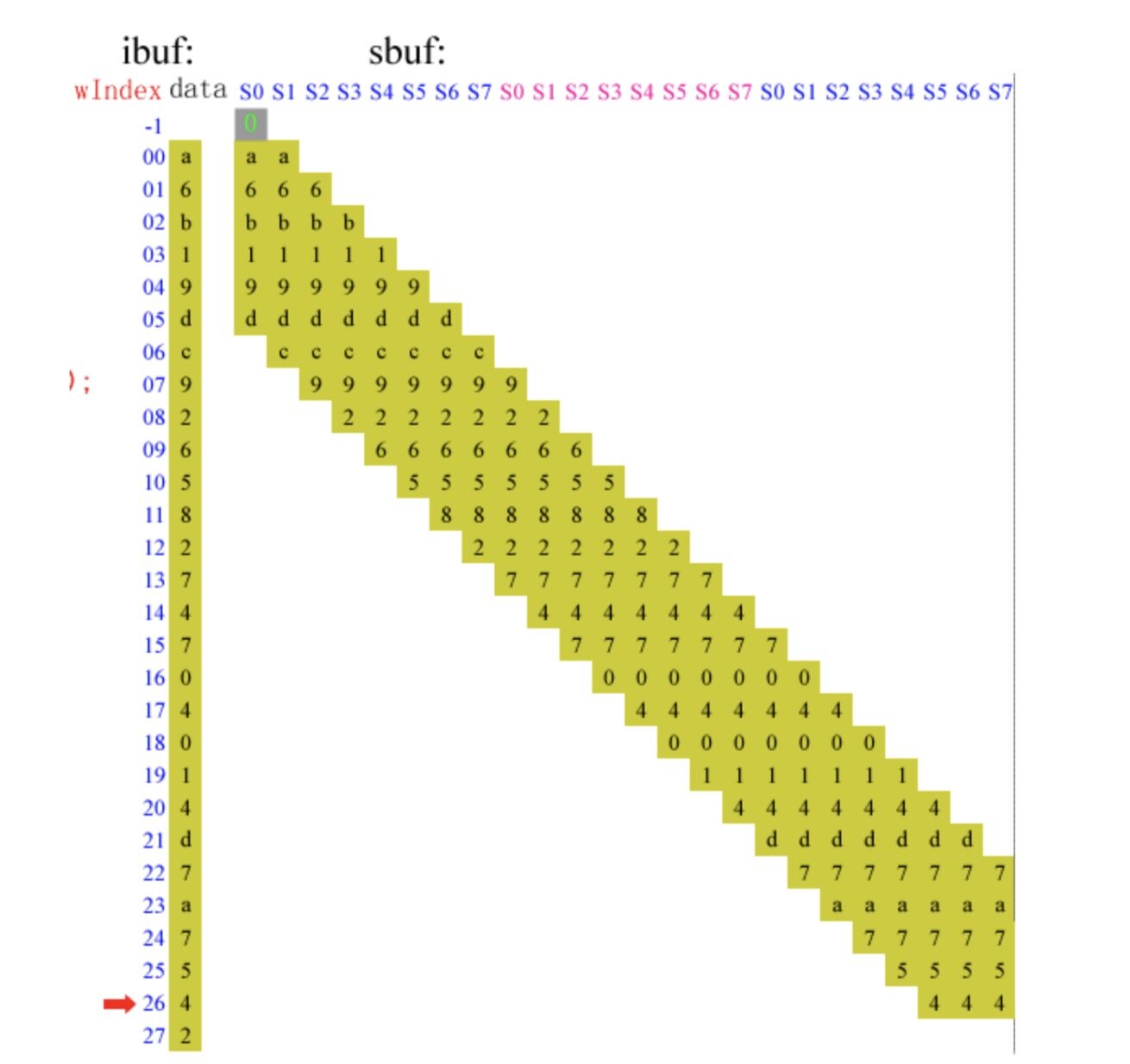
multi-sliding window 卷积计算示意图
如图,对于 ibuf 中的某一个输入通道中的每一行输入图像,每个时钟沿都有 PIX 个像素点参与卷积计算。随着 sbuf 中的权重由行首滑窗至行尾,每一个滑窗经过的像素点会在一个时钟沿的时间里完成所有在这一里要参与的卷积计算,不会在之后的时钟沿里被重复使用,使得整行的计算时间是传统的卷积方式的 1/PIX,大大缩短了计算时间。
3.多算子融合
推理时的 BatchNorm 算子运算非常耗时,但由于其是线性运算,可以在建模初期将 BatchNorm+Scale 的线性变换参数融合到卷积层,替换原来的 weights 和 bias。与单独计算 BatchNorm 相比,这种算子融合大大减少了内存的读写操作,有效提高了处理帧率。
4.流水线计算和乒乓加载技术
流水线技术和乒乓加载技术是 FPGA 设计中常用的手段。使用流水线可以使串行计算并行化,大大减少运算时间,乒乓加载技术则利用片上存储器实现了输入图像和权重的预加载,使输入图像由 FPGA 片外 DDR 传至片上的时间被卷积计算时间覆盖,同样起到了减小图像处理时间的作用。
结语
在深度学习计算这类计算密集型的应用场景下,通用硬件设计中的某些特点,如复杂任务调度等,很可能会成为计算瓶颈,导致降低计算效率,所以针对应用部署硬件的特征完成异构硬件上的计算优化,在当前已经成为研究的热点。Adlik 首先在架构上支持多类异构硬件和计算引擎,也在 FPGA 异构计算上完成了一些技术实践,后续将继续进行特定硬件上的计算优化技术的研究,来加速推动 AI 模型的工程应用。
参考文献:
[1] https://github.com/Adlik/Adlik
[2] Xilinx-ug579-UltraScale Architecture DSP Slice User Guide
[3] Xilinx-WP486-Deep Learning with INT8 Optimization on Xilinx Devices
[4] Google Inc. Quantization and Training of Neural Networks for Efficient Integer-Arithmetic-Only Interface.
作者简介:
[1]刘涛,中兴通讯算法高级系统工程师,Adlik 开源项目负责人。
[2]李莹,中兴通讯技术规划部 FPGA 工程师,负责对 FPGA 加速器时序优化。
相关文章:

中国开发者画像洞察研究报告 2024
分析开发者的行为模式、工作价值、职业发展等内容,帮助整个行业生态更深入地理解开发者,为他们提供更精准...













评论