

本文选自“字节跳动基础架构实践”系列文章。
“字节跳动基础架构实践”系列文章是由字节跳动基础架构部门各技术团队及专家倾力打造的技术干货内容,和大家分享团队在基础架构发展和演进过程中的实践经验与教训,与各位技术同学一起交流成长。
字节跳动存在海量结构化与半结构化数据的诸多存储需求。本文将对字节
概要
分布式表格存储系统在业界拥有广泛的应用场景。Google 先后发布了 Bigtable 和 Spanner 两代分布式表格存储系统,承接了其公司内部和外部云服务中的所有表格存储需求。其中 Bigtable 的开源实现 HBase 在国内外公司中都得到了广泛的使用,并且开源的图数据库 JanusGraph 、时序数据库 OpenTSDB 、地理信息数据库 GeoMesa、关系型数据库 Phoenix 等底层都是基于 HBase 进行数据存储的。字节跳动也大量使用 HBase 作为表格存储服务,HBase 在字节跳动的实践过程中,在极大数据量和极高负载的场景下存在延时长尾较高和可用性不足的问题。为此字节跳动表格存储团队经过大量开源系统调研并最终决定研发一套兼容 HBase 数据模型和语义的高可用、强一致、低延时、高吞吐、全局有序且对 SSD 和 HDD 盘同时友好的分布式表格存储系统,以应对字节跳动业务迅猛发展带来的技术挑战。目前第一代表格存储系统 Bytable1.0 已作为搜索和推荐的底层数据存储稳定运行,我们团队正在此基础上演进第二代表格存储系统 Bytable2.0。
1. 背景
随着头条全网搜索项目的启动和发展,业务需要一个全局有序、容量巨大同时性能高效的表格存储系统以存储整个互联网中所有链接和网页,并保证互联网上发生的所有变更都被能实时的更新到表格存储系统中。在此之前,搜索引擎技术的领导者 Google 为此构建了 Bigtable ,并在其搜索、地球和财经等多个项目中使用。其中搜索业务在其发表的论文中做了主要论述,因而之后很多运营搜索业务的公司都效仿其使用方式。我们团队最初使用 Bigtable 的开源实现 HBase 为搜索业务提供服务。在全网链接关系的实时更新需求下需要提供足够高的可用性和足够低的延时,由于其数据量极其庞大所以会创建极多的数据分片,集群的整体尾延时和可用性会随着数据分片实例数的增多而成指数级别的恶化,因此对每一个分片实例的延时和可用性提出了更高的要求。但由于 HBase 存在尾延时较高和可用性较低的问题,并不能满足我们的需求,于是我们团队开始了调研和技术选型。

2. Bytable1.0 应运而生的第一代表格存储系统
2.1 技术选型
在我们的需求下,面对海量的网页链接和网页数据,数据量非常庞大,全部使用 SSD 盘将极大地增加存储成本,所以我们面向的设备不能只考虑 SSD 盘,需要在 HDD 盘上也提供高效的支持。目前广泛使用的全局有序的开源分布式表格存储系统有 HBase, TiDB, CockroachDB 等。经过验证 HBase 由于其延时长尾和可用性问题满足不了我们的需求。TiDB 和 CockroachDB 在我们的需求下存在:(1)数据迁移时需要多路归并扫描数据;(2)写数据时需要两份日志;这两个引起磁头摇摆对 HDD 盘的不友好的问题。由于这些系统都不能解决我们的问题,最终我们团队决定结合目前公司提供的软硬件资源水平和业务场景,独立研发一套兼容 HBase 数据模型和语义的高可用、强一致、低延时、高吞吐、全局有序且对 SSD 和 HDD 盘同时友好的分布式表格存储系统 Bytable1.0。在设计方案时,我们团队遵循的原则是在满足业务需求的前提下,尽可能的简化设计。业界的分布式表格存储系统往往使用共享存储架构,但在当时公司内部的分布式文件存储系统不能提供足够高的可用性和 SLA。为了满足业务的高可用需求,我们决定不依赖分布式文件存储系统直接管理本地磁盘。
2.2 系统架构
下面我们来介绍 Bytable1.0 的系统架构,如下图所示主要由 Master, PlacementDriver 和 TabletServer 三个模块组成。Client 会跟 Master 通信取得 Tablet (与 Bigtable 类似,使用 Tablet 表示表中的一个数据分片,表示表中的一个 KeyRange 对应的部分数据) 的元信息,以得到对应 Tablet 所在的 TabletServer 的地址,然后 Client 跟对应的 TabletServer 进行通信进行数据读写。类似于 HDFS 的 NameNode 和 DataNode 分别处理控制平面和数据平面的任务,我们将整个 Bytable1.0 划分了控制平面(Master),决策平面(Placement Driver)和数据平面(TabletServer),我们将详细介绍每一个平面的内部设计。
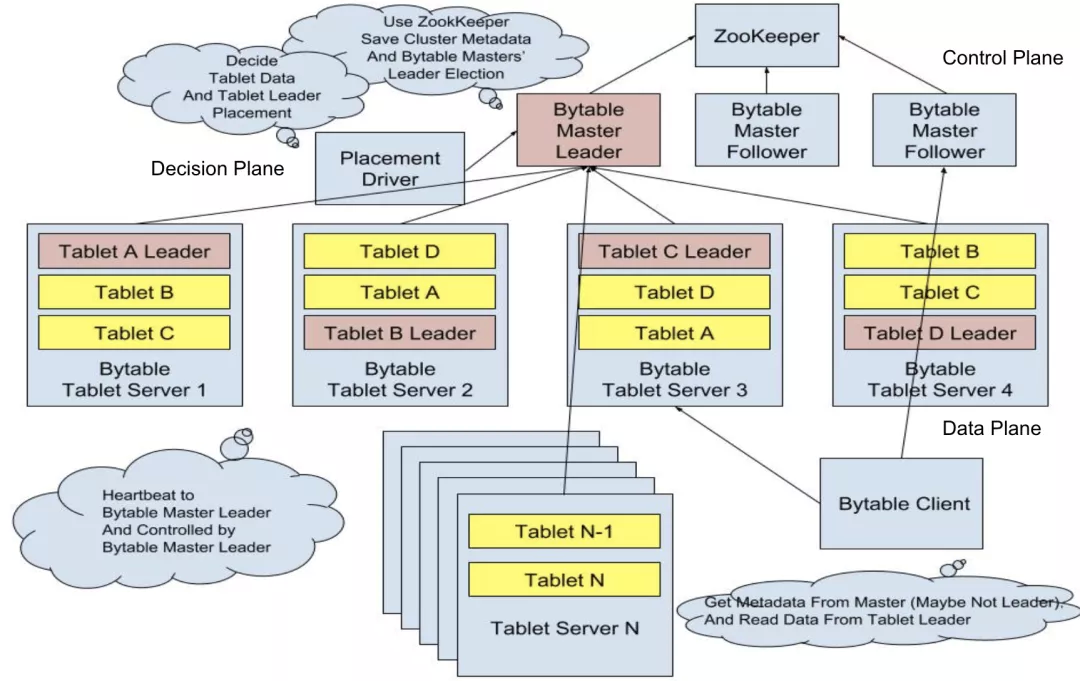
Bytable1.0 Global 架构图
2.2.1 控制平面 Master
Master 控制了 Tablet 主动切主、被动选主、迁移、分裂与合并的具体流程控制,此外 Master 向 Client 暴露 Tablet 分布的位置信息。这里以被动切主为例介绍下大致流程,当 Master 在指定时间内没有收到某 TabletServer 的心跳消息,则将此 TabletServer 判定为 Offline,然后对此 TabletServer 上为 Leader 的 Tablet 发起一轮选主。选主的过程与 Raft 类似仅仅是将这部分逻辑上移到 Master 统一管理,首先收集 Tablet 各个副本的最新日志号,然后选取足够新的副本作为选主目标,向 Tablet 各个副本发起投票,当投票成功后向选主目标发送当主请求。因为 Master 接管了控制平面的所有工作,所以逻辑和 RPC 交互会非常复杂,并且因为对性能没有特别高的要求,所以选择了 Go 语言进行开发,以降低研发成本,提升研发效率。
2.2.2 决策平面 Placement Driver
Master 控制了指定操作的具体流程,但是不对是否发起指定操作(除了被动选主)做决策,而这个决策的任务由 PlacementDriver 来负责。它会扫描 Master 获得分区的负载信息,经过各种策略的计算生成决策信息,发送给 Master 实际执行。因为策略的更新往往更频繁,拆成两个模块的话策略的更新不需要滚动重启 Master,对用户来说可以做到完全无感知。为了降低复杂策略的编写成本,PD 也选择了 Go 语言进行开发。
2.2.3 数据平面 TabletServer
TabletServer 承载了多个 Tablet 的数据存储,并负责进行实际数据的读写操作。每一个 Tablet 都会与其他 TabletServer 上面的对应 Tablet 会组成一个复制组,复制组内的多个成员之间使用简化的 Raft 复制协议进行数据复制。所谓简化的 Raft 复制协议就是只实现了 Log Replication 的功能,将 Leader Election 和 Member Change 的功能移到了 Master 端。这样做分离了其数据平面和控制平面,实现了数据平面的逻辑简化。与此同时将控制平面操作统一到 Master 中便于定制更复杂的选主策略,并借此实现了多组 Raft 的心跳合并到 Master 减小了心跳的额外消耗。
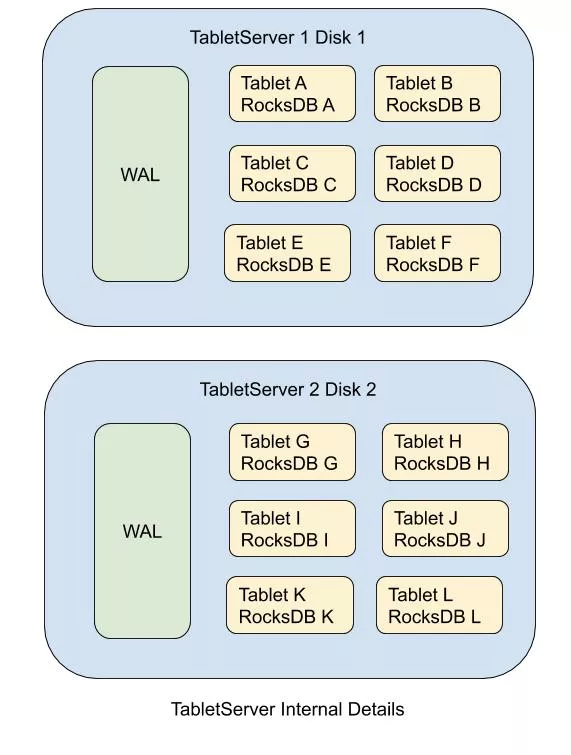
数据路径是这个系统关键路径,需要更高的性能以提升吞吐和减低延时,在语言层面我们选用了 C++ 以便提供高效与可预测的性能,此外我们还在日志引擎和数据引擎等方面进行了大量的优化。当前市面上大部分系统比如 MySQL, MongoDB, TiDB, CockroachDB 等,在写日志时都会写入复制日志和引擎日志两份日志,在 HDD 盘的场景下往往会造成分别写入两份日志时写流量放大一倍并且使磁头频繁发生摇摆,制约写入性能。因此在我们的实现中规避了引擎日志仅使用了复制日志,避免了磁头的摇摆问题。此外在 TiDB 和 CockroachDB 的方案中,使用了 RocksDB 作为多组复制日志的合并存储的方案,但其会引入其非必要的 MemTable 插入和 SST Flush & Compaction 开销,不够高效。因此我们团队研发了一套 WAL 存储引擎,进行多组复制日志的合并,实现了仅一次的日志写入,不会造成 HDD 盘磁头摇摆,不进行 Compaction 时也可以打满 HDD 盘的写入带宽。
数据存储引擎方面我们团队采用了业界流行和广泛验证过的 RocksDB 作为存储引擎。与 TiDB, CockroachDB 不同的是,Bytable1.0 的每一个 Tablet 都对应一个 RocksDB 实例,在数据迁移的过程中可以直接进行 RocksDB 的文件读取、传输与写入,不需要额外的扫描、文件生成和文件注入,避免了扫描时多文件归并引起的磁头移动问题、RocksDB 文件注入操作误入 L0 潜在的 Write Stall 问题和 RocksDB 文件注入操作不允许存在并发的普通写入的卡顿问题,实现了快速轻量的数据迁移。此外还可以合理的控制一个 LSMTree 的大小,避免 LSMTree 大小变化后与 RocksDB 参数不匹配的问题。
Split 和 Merge 操作的高效实现则是一个 Tablet 对应一个 RocksDB 实例使用方式引入的难题。对于 Split 操作来说,需要将原先的一个 RocksDB 实例分裂为两个 RocksDB 实例,在我们的实现中利用了 LSMTree 的特性,首先会进行一轮全量的引擎文件硬链,然后停写,再进行一轮增量的引擎文件硬链并打开写入,不可用时间为增量的少量硬链操作所需要的时间。对于 Merge 操作来说,我们对 RocksDB 进行了改造,在文件注入时将是否是注入进来的文件以及 GlobalSequence 都存储在 Manifest 中以便允许直接注入另外一个 RocksDB 实例中文件。与 Split 的过程类似,Merge 的过程也使用了增量的策略进行注入以减少不可用时间。
对比多个 Tablet 公用一个 RocksDB 实例的实现方式,Bytable1.0 的方案在迁移的稳定性和效率与单个 LSMTree 的大小控制上都更有优势,但在分裂与合并的引起的抖动上存在一定的劣势。
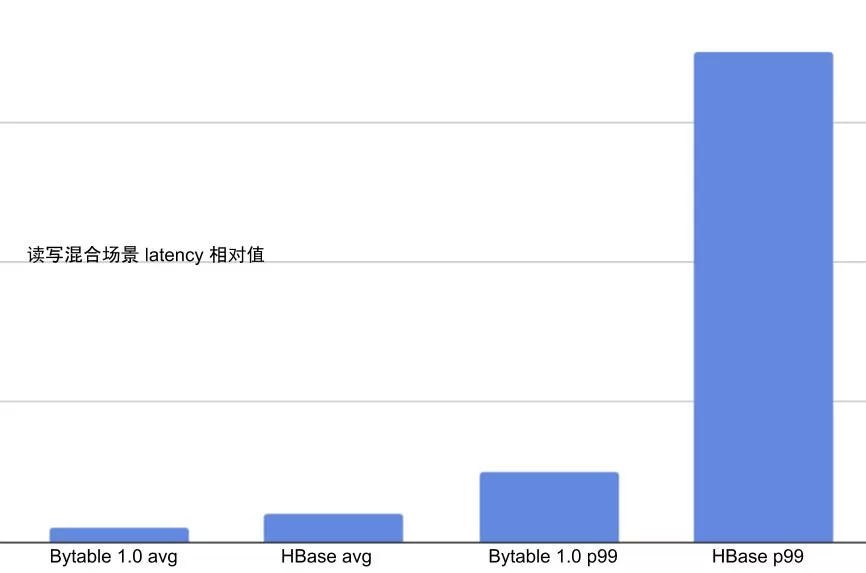
下图列举了在相同机器环境下,读写混合场景(读 50%,写 50%)下,Bytable1.0 TabletServer 与 HBase RegionServer 的延时对比。可以看出,Bytable1.0 在平均延时和 p99 延时上均有大幅降低。
2.3 优化细节
2.3.1 点读优化
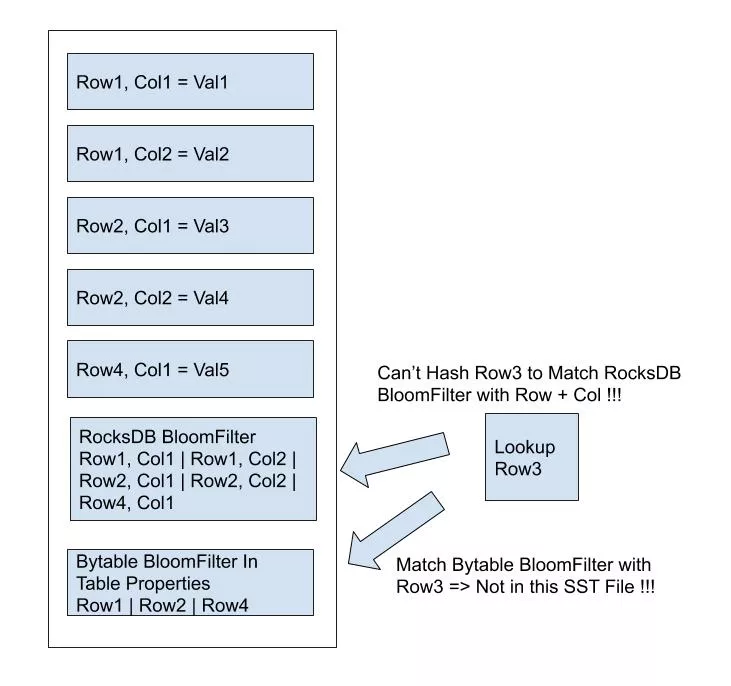
因为我们在 RocksDB 的 KV 模型之上封装了 Table 数据模型,所以无法利用其内置的 BloomFilter 以优化点读性能,我们为每一个 SST 在 Flush 和 Compaction 的过程中手工生成一个 BloomFilter 存储在其 TableProperty 中,并关闭了内置的 BloomFilter 以节省空间。在查询时利用 TableFilter 功能,查找到 SST 对应的手工生成 BloomFilter 进行判断,以优化点读的性能。
2.3.2 热点写入优化
因为我们使用了 Raft 作为副本复制协议,而 Raft 的 Apply 流程是串行的,当出现写入热点时需要通过热点 Tablet 分裂来扩展性能。因为我们的分裂合并操作相对比较重,热点分裂的决策并不适合过于实时和敏感,为了扩展单个 Tablet 的写入性能,我们实现了一种新型的 RocksDB MemTable,写入时仅写入队列中实现了 O(1) 复杂度的在线写入,靠后台线程池将数据并发的写入实际的 SkipList 中,在读取的时候使用 ReadIndex 的机制进行等待。将单线程的最大承载能力扩展到单机的最大承载能力。
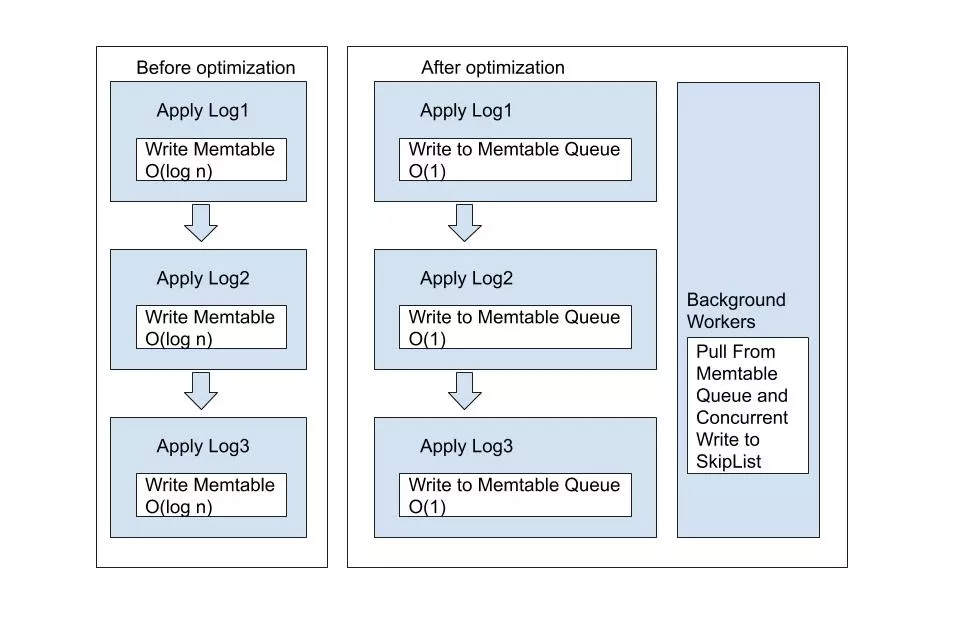
2.3.3 写入反压优化
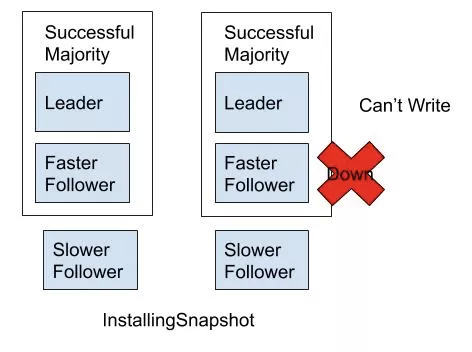
当单个 Tablet 写入过快时,由于硬件资源的略微差距总会有一个副本的速度赶不上其他副本,逐渐累积引起慢副本重装快照。当出现这种情况的时候,如果速度快的两个副本有一个副本机器 Down 机,就会出现这个 Tablet 的短期不可写的情况(其中一个副本正在重装快照)。为了避免这种情况,我们会在一定的条件下进行慢节点反压,限制整体的写入速度,防止慢副本落后过多,实现了极限情况下的可用性提升。此外,我们会设定一定的限制避免磁盘降速故障引起的慢节点反压。
2.4 分布式事务
目前有些业务场景下存在分布式事务的使用需求,我们团队按照 Percolator 的事务模型,在 Bytable 上层实现了一套分布式事务解决方案,相关内容将在后续专题文章中详细描述。
3. Bytable2.0 追求极致的第二代表格存储系统
随着 Bytable1.0 的上线与稳定,业务对表格存储系统的成本、稳定性和性能都有了更高的要求。从成本角度来考虑,目前使用三副本方式来存储数据相比分布式文件系统的 EC(Erasure Code) 方案需要多消耗将近一倍的存储空间,此外目前存在三副本独立 Compaction 的情况多消耗了两倍的 CPU。从资源利用率的角度来考虑,目前存在读写请求和磁盘空间占用不匹配的情况,会出现 CPU 资源剩余但磁盘空间用尽或者 CPU 资源用尽但磁盘空间剩余的情况。从与离线 Hadoop 生态系统打通的角度来看,现在做备份、导出和数据加载都比较麻烦。从稳定性的角度来考虑,目前在分裂与合并的过程中仍然存在一定的延时抖动,我们也希望将尾延时优化到极致。从运维复杂度的角度来考虑,基于分布式文件系统可以将我们的服务无状态化,结合 K8S 的调度技术,我们不再需要考虑机器和磁盘的故障报修和重新上线,将极大地降低我们的运维成本。因此设计和实现基于共享存储的分布式表格存储系统势在必行。
3.1 技术选型
与 Bytable1.0 设计目标仅仅是希望满足当前业务需求不同的是,我们希望可以在更大的范围内寻求最优解,构建世界领先的分布式表格存储系统。随着字节跳动分布式文件存储系统逐渐向在线模式演进,我们拥有了可供在线使用的分布式文件存储系统 ByteStore。此外字节跳动还研发了使用 Quorum 协议的分布式日志存储系统 ByteJournal ,它拥有类似 Paxos 的日志乱序复制和提交的特性以尽可能的降低延时。此外 ByteJournal 还能提供总共 5 副本写入 2 副本成功即可提交,但需要 4 副本 Recover 的高级特性,以提供比 Paxos 协议更加极致的尾延时优化。这一次我们选择站在巨人的肩膀上,使用 ByteStore 存储引擎文件,使用 ByteJournal 管理复制日志,依赖这两个分布式存储系统实现基于共享存储的第二代表格存储系统 Bytable2.0。此外,国际化业务也拥有全球一致的表格存储需求,并希望可以细粒度的设置和变更部分数据的复制配置,借此控制对应数据在访问时的读写延迟(通过访问数据时的距离)。
3.2 系统架构
在 Bytable2.0 的系统设计中借鉴了 Google 第二代分布式表格存储系统 Spanner 的设计思路。在本节中我们将介绍 Bytable2.0 的系统架构,如下图所示我们将 Bytable2.0 划分为数据读写层(TabletServer)、全局管理层(GlobalMaster),计算调度层(GroupMaster)和数据调度层(PlacementDriver)。
Bytable2.0 与 Bytable1.0 的主要不同有如下几处:
与 Bytable1.0 中将 Tablet 分布信息存储在 Master 中不同,Bytable2.0 为每一张表都会建立一个对应的 MetaTable 存储在 TabletServer 中。这样做一个好处是可以为每一个表的 Tablet 分布信息访问做好隔离,另一个好处是如果 MetaTable 成为瓶颈可以在以后的实现中加入 RootTable 使其可分裂。
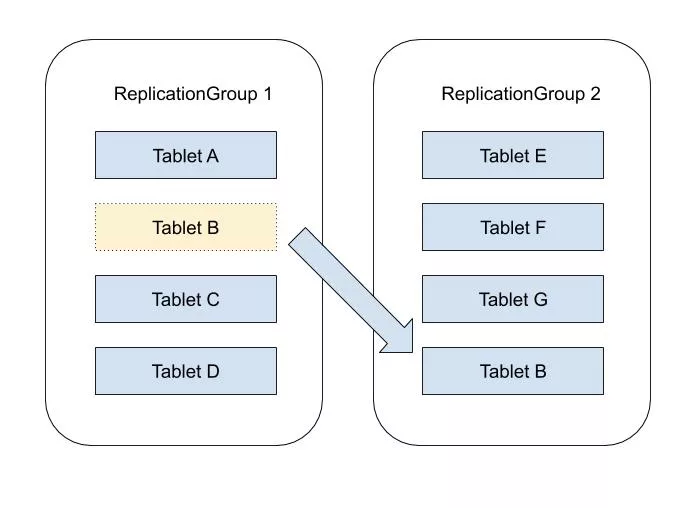
与 Bytable1.0 中一个 Tablet 即对应一个复制组不同,Bytable2.0 中一个复制组中会包含多个 Tablet。最终表现为一个 TabletServer 拥有多个 ReplicationGroup 的某一 Replica (Replica 是 ReplicationGroup 的一个副本),一个 ReplicationGroup 拥有多个 Tablet。这样做的好处是允许将多个不连续 KeyRange 的数据放置在同一个 ReplicationGroup 中,以方便极细粒度的分区,并允许不连续 KeyRange 的数据进行单 ReplicationGroup 的局部事务处理。将 ReplicationGroup 的复制能力和 KeyRange 的切分解耦,即使 KeyRange 的切分非常多依然可以使 ReplicationGroup 的数量保持收敛。
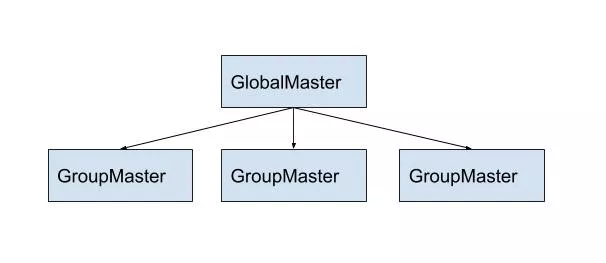
与 Bytable1.0 中仅有一个 Master 不同,Bytable2.0 引入了 GlobalMaster 和 GroupMaster 两个组件。GlobalMaster 负责记录所有 Table 和 ReplicationGroup 的元信息。GroupMaster 不断同步 GlobalMaster 管理的元信息,在本地冗余保存,它只管理自己对应 Region 内 TabletServer 实例的探活与 Replica 分配,实现了 Region 内部的自治,去除了 Region 间网络状况对 Region 内部可用性的影响。
Bytable2.0 与 HBase 的主要不同之处有如下几处:
HBase 仅支持同步或异步的主从复制,读取时仅保证集群内一致不保证集群间一致。而 Bytable 2.0 可以支持跨 Region 的 Quorum 数据复制,保证全球一致。
HBase 中 Region 和 KeyRange 的映射关系是一一映射,因此如果希望细粒度的设置 KeyRange 的复制关系则会创建大量的小 Region,而这对 HBase 则是不友好的。而 Bytable 2.0 可以支持细粒度的 Tablet 数据复制关系设置。
Client 读写数据的时候会首先跟 GroupMaster 通信获得要访问数据对应表的 MetaTable 对应的 ReplicationGroup 各个 Replica 的位置信息,然后请求对应的 MetaTable 从中定位对应的 Tablet 所属 ReplicationGroupId,然后根据其去 GroupMaster 查询对应 ReplicationGroup 各个 Replica 的位置信息,最终根据此位置信息找到对应的 TabletServer 进行读写。
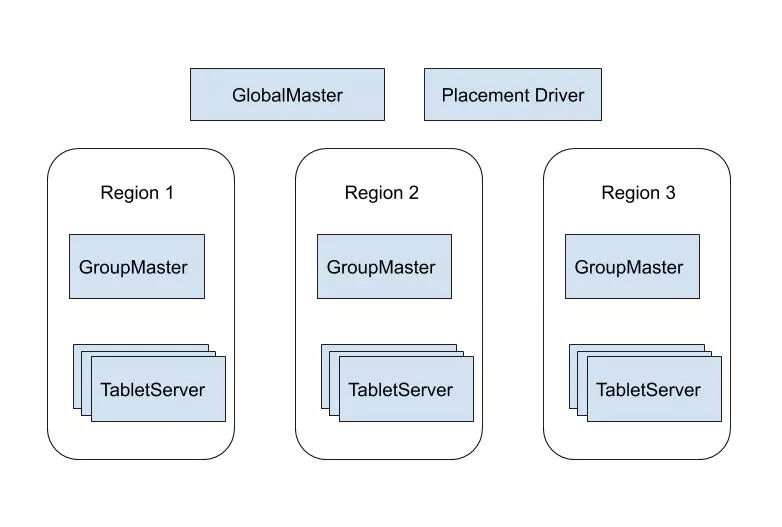
Bytable2.0 Global 架构图
在单机房部署的场景下,上面的架构就显得过于臃肿,因为我们实现时模块化做的足够好,所以可以将 GlobalMaster, GroupMaster 和 PlacementDriver 三个模块编译到同一个 Master 二进制文件中,以降低部署和维护的复杂度,如下图所示,部署时一个集群中可以仅拥有 Master 和 TabletServer 两种服务。
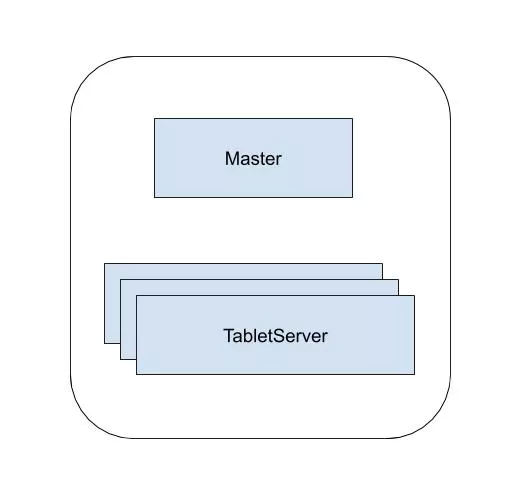
Bytable2.0 精简部署
3.2.1 数据读写层 TabletServer
与 Bytable1.0 中 ReplicationGroup 与 Tablet 的一一对应关系不同, Bytable2.0 的一个 TabletServer 中包含若干 ReplicationGroup 的 Replica,每一个 ReplicationGroup 中包含了若干 Tablet。这样的设计可以使 Tablet 的分裂与合并变得非常轻量,仅仅是修改元数据,不需要任何停顿。在这种设计下迁移不再是将一个 Tablet 从一个 TabletServer 迁往另外一个 TabletServer,而是从一个 ReplicationGroup 将这个 Tablet 的对应数据导入另外一个 ReplicationGroup,我们使用 SST 文件 Range 抽取的方式轻量地完成对应的工作。
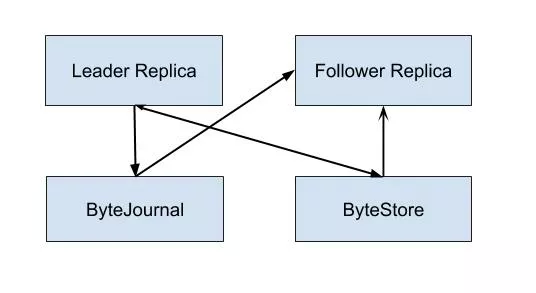
在写入的流程中 Leader Replica 首先通过 ByteJournal 写入 WAL,当日志写入成功后写入 MemTable。Follower Replica 从 ByteJournal 中读取 WAL 并写入 MemTable。Leader Replica 定期进行 Checkpoint 和 Compaction 操作,将 SST 文件写入 ByteStore 中。在 Leader Replica 和 Follower Replica 共享分布式文件系统的时候,仅仅 Leader Replica 进行 Checkpoint 和 Compaction 操作。当 Leader Replica 和 Follower Replica 不共享分布式文件系统时,则在每一个分布式文件系统上都会选出一个 Compaction Leader 分别进行 Checkpoint 和 Compaction 操作。这样我们就解决了之前多副本分别 Compaction 引入的额外 CPU 损耗,于此同时我们也可以拥有 Follwer Replica 解决了早期 HBase 版本存在的没有主从冗余的问题。
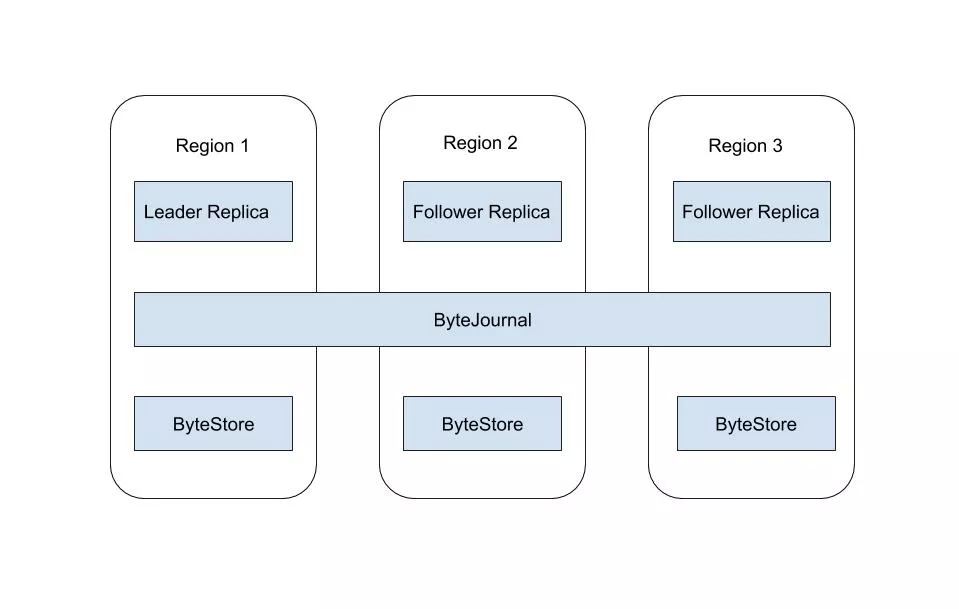
在读取流程中,Leader Replica 和 Follower Replica 都从对应的 ByteStore 中将 SST 数据读取出来与内存中的 MemTable 归并最后返回给用户,其中 Follwer Replica 可以指定版本进行读取,也可以使用 ReadIndex 的方式从 Leader Replica 获取最新的日志号并等待其在本地 Apply 后进行读取。
3.2.2 全局管理层 GlobalMaster
GlobalMaster 是整个集群全局的管理模块,负责对运维人员暴露操作接口,主要负责表和 ColumnFamily 的创建和删除。其中存储了所有表和 ColumnFamily 的元信息,同时保存了每个表包含的所有 ReplicationGroup 的元信息。GroupMaster 从 GlobalMaster 同步这些元信息,以便获取需要其调度的 Replica,以便管理 ReplicationGroup 在对应 Region 内的副本放置。
3.2.3 计算调度层 GroupMaster
GroupMaster 是某个 Region 内的管理模块,管理 Region 内多个 TabletServer 实例和各个 ReplicationGroup 在本 Region 内分配的 Replica。除了注册到这个 GroupMaster 的多个 TabletServer 的心跳与保活的工作,它还要根据从 GlobalMaster 同步的元信息中得出需要其调度的 Replica 信息,在注册到这个 GroupMaster 的多个 TabletServer 上进行调度,告知 TabletServer 打开或关闭对应的 Replica。
3.2.4 数据调度层 PlacementDriver
PlacementDriver 是进行数据调度的决策模块,其会和 TabletServer 通信,收集各个 TabletServer 的负载信息并扫描各个表对应的 MetaTablet,进行负载均衡计算,最终进行决策需要是否需要对某些 Tablet 进行分裂、合并或迁移操作。
3.3 未来展望
3.3.1 离线 Compaction
Compaction 操作和流式的数据读写相比,其实是一个 Batch 类型的离线操作,而这个离线作业跑在在线服务中,往往会降低在线服务的有效资源利用率和 Qos。所以,我们计划允许将这个 Compaction 过程的执行递交给 Yarn 或其他离线作业运行平台,以降低其对在线服务 CPU 的消耗。Aliyun X-Engine 团队使用的 FPGA 的方案,将本机的 Compaction CPU 负载 Offload 给 FPGA,也是利用类似的方式。不过其对特定机型和硬件依赖较重,可以考虑利用 Yarn 调度平台对 FPGA 资源进行调度的方式更加合理与充分对其资源进行利用。
3.3.2 分析型列存引擎
在 Spanner: Becoming a SQL system 的论文中提到,目前 Spanner 提供了一套块内列存的分析型引擎,在部分场景下取得了不错的效果。TiDB 也通过为 Raft 挂一个 ClickHouse (Yandex 开源的分析型数据) 从节点的方式提供了分析型查询的解决方案。Bytable2.0 也有一些分析型的使用场景,我们计划将来提供一套分析型列存的引擎,逐步发展为一个 HTAP 的系统。
3.3.3 多模数据库
目前数据库市场上拥有多种多样的 API 接口,比如 Redis, MongoDB,MySQL 等。与此同时,在开源市场中,图数据库 JanusGraph 、时序数据库 OpenTSDB 、地理信息数据库 GeoMesa、关系型数据库 Phoenix 等数据库底层都是基于 HBase 进行数据存储的。这给我们带来了一些启示,Bytable2.0 将来也可以作为通用的底层存储服务,在上层实现各种各样的 API 层,为这些 API 的服务提供大容量低成本的解决方案。
3.3.4 新型分布式事务机制探索
分布式事务在业界的实现中,往往需要在吞吐和延时中进行权衡。在 Bytable 的分布式事务解决方案中,使用了 Percolator 事务模型,其依赖了单点授时服务 TSO,在吞吐和延时之间做了一定权衡。在后续 Bytable2.0 的分布式事务方案中,我们希望进一步优化 Bytable1.0 分布式事务方案中 Percolator 模型的吞吐问题和跨 Region 延时问题,探索新的解决方案。
4. 总结
随着字节跳动搜索和推荐场景的飞速发展和业务需求的不断丰富,我们在前期快速的构建了第一代分布式表格存储系统 Bytable1.0,解决了大量的业务问题。但同时因为一期系统的简化和权衡,仍然存在一些需要优化的成本和扩展性等问题,我们在第二代类 Spanner 的表格存储系统 Bytable2.0 中解决这些问题。欢迎感兴趣的同学们加入表格存储团队打造极致的分布式表格存储解决方案,一起构建字节跳动坚实的基础设施,为公司的高速发展的保驾护航。
5. 参考文献
[1] Chang, Fay, et al. “Bigtable: A distributed storage system for structured data.” ACM Transactions on Computer Systems (TOCS) 26.2 (2008): 1-26.
[2] Apache HBase: An open-source, distributed, versioned, column-oriented store modeled after Google’ Bigtable.
[3] TiDB: An open source distributed HTAP database compatible with the MySQL protocol.
[4] Taft, Rebecca, et al. “CockroachDB: The Resilient Geo-Distributed SQL Database.” Proceedings of the 2020 ACM SIGMOD International Conference on Management of Data. 2020.
[5] Dong, Siying, et al. “Optimizing Space Amplification in RocksDB.” CIDR. Vol. 3. 2017.
[6] Corbett, James C., et al. “Spanner: Google’s globally distributed database.” ACM Transactions on Computer Systems (TOCS) 31.3 (2013): 1-22.
[7] Bacon, David F., et al. “Spanner: Becoming a SQL system.” Proceedings of the 2017 ACM International Conference on Management of Data. 2017.
[8] Huang, Gui, et al. “X-Engine: An optimized storage engine for large-scale E-commerce transaction processing.” Proceedings of the 2019 International Conference on Management of Data. 2019.
本文转载自公众号字节跳动技术团队(ID:toutiaotechblog)。
原文链接:
https://mp.weixin.qq.com/s/oV5F_K2mmE_kK77uEZSjLg

Java 避坑指南:Java 高手笔记代码篇
本迷你书包括 86 个业务开发中常见踩坑点。每一个知识点都相当的实用,是程序员业务开发中的必备避坑指南...











评论